



Python面向对象编程
一、面向对象基础
1、面向对象
(1)面向对象与面向过程的区别
面向过程
需要实现一个功能时,着重的是过程,分析出一个个步骤,并把一个个步骤用一个个函数实现,再依次调用一个个函数即可。
面向对象
需要实现一个功能时,看重的是谁去帮我做这件事情。
2、类和对象
类是一系列具有相同属性和行为的事物的统称,不是真实存在的事物。
对象是类的具体实现,是类创建出来的真实存在的事物,面向对象思想的核心。
在开发中,先有类,再有对象
(1)类的三要素
1、类名(要符合标识符规定,遵循大驼峰命名法,见名知义)
2、属性:对象的特征描述,用来说明是什么样子的
3、方法:对象具有的功能(行为),用来说明能够做什么
举例
类名:人类
属性:身高、体重、年龄
方法:走路、说话、学习
(2)定义类
基本格式
class 类名:
代码块
类属性:即类所拥有的的属性
查看类属性:类名.属性名
新增类属性:类名.属性名 = 值
举例
class Washer:
height = 800 #类属性
print(Washer.height)
Washer.width = 450
print(Washer.width)
(3)创建对象
创建对象的过程也称实例化对象
实例化对象的基本格式:对象名 = 类名()
举例:实例化一个洗衣机对象
#第一次实例化
wa = Washer()
print(wa) #显示的是对象在内存中的地址
#第二次实例化
wa2 = Washer()
print(wa2)
输出结果

由输出结果不同,即内存地址不同,说明是不同的对象,所以可以实例化多个对象
(4)实例方法和实例属性
1、实例方法
实例方法:由对象调用,至少有一个self参数,执行实例方法的时候,自动调用该方法的对象赋值给self
对象调用类中方法基本格式:对象名.方法名()
class Washer:
height = 800 #类属性
def wash(self):
print("我在洗衣服")
print(self)
wa = Washer()
wa.wash()
print(wa)
输出结果

由输出结果,print(self)和print(wa)输出的结果一样,同时也说明self代表对象本身
关于self
self参数是类中实例方法必须具备的
self表示当前调用方法的对象
self代表对象本身,当对象调用实例方法时,python会自动将对象本身的引用作为参数,传递给实例方法的第一个参数self里面
2、实例属性
基本格式: self.属性名
class Person:
name = 'zct' #类属性
def introduce(self): #实例方法
print('我是实例方法')
print(f'{Person.name}的年龄:{self.age}') #self.age---实例属性
pe = Person()
pe.age = 18
pe.sex = '女' #实例属性
print(pe.sex) #根据对象名访问实例属性
#print(Person.sex) #报错,实例属性只能由对象名访问,不能由类名访问
pe.introduce()
#访问类属性,类可以访问到,实例对象也可以访问到
print(Person.name) #类访问
print(pe.name) #实例对象访问
pe2 = Person()
# print(pe2.sex) #报错,pe.sex='女',是给pe对象新增的属性,其他对象依然是没有这个属性的
pe2.sex = '男' #每实例化一次,就需要添加一次这个实例属性
print(pe2.sex)
由此,类属性和实例属性的区别
1、类属性属于类,是公共的,大家都能访问到的,实例属性属于对象的,是私有的
2、类属性,类可以访问到,实例对象也可以访问到;实例属性只能由对象名访问,不能由类名访问
3、构造函数__init__()
(1)初始化方法__init__()
Python里的内置方法
作用:通常用来做属性初始化或者赋值操作
注意:在类实例化对象的时候,会自动调用
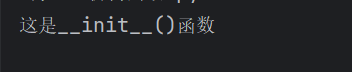
class Test:
def __init__(self): #self--实例方法
print('这是__init__()函数')
te = Test() #在实例化对象时,就自动调用了__init__()实例方法
输出结果
(2)在初始化方法内部定义属性
在__init__()方法内部,使用self.属性名 = 属性的初始值定义属性。在实例化对象后,对象就拥有该属性
class Person: #人类
def __init__(self):
self.name = 'zct' #实例属性
self.age = 18
self.height = 183
def play(self):
print(f"{self.name}在打王者荣耀")
def introduce(self):
print(f"{self.name}的年龄是{self.age},身高是{self.height}cm")
#实例化对象
pe = Person()
pe.play()
pe.introduce()
输出结果

缺点:实例属性的值固定,创建新的对象时,实例属性不能改变,不灵活。
(3)使用形参的方式
class Person: #人类
def __init__(self,name,age,height):
self.name = name #实例属性
self.age = age
self.height = height
def play(self):
print(f"{self.name}在打王者荣耀")
def introduce(self):
print(f"{self.name}的年龄是{self.age},身高是{self.height}cm")
#实例化对象
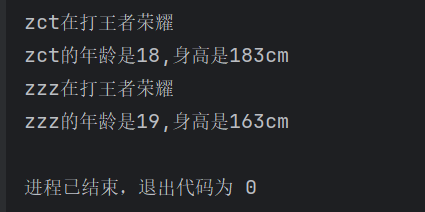
pe = Person('zct',18,183)
pe.play()
pe.introduce()
#实例化第二个对象
pe2 = Person('zzz',19,163)
pe2.play()
pe2.introduce()
输入结果
4、析构函数__del__()
del()主要是表示该程序块或者函数已经全部执行结束
删除对象的时候,解释器会默认调用__del__()方法
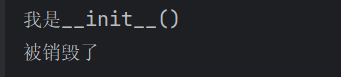
class Person:
def __init__(self):
print('我是__init__()')
def __del__(self):
print('被销毁了')
p = Person()
输出结果
正常运行的时候,不会调用__del__(),执行结束后系统会自动调用__del__(),程序执行顺序如下输出结果所示:
class Person:
def __init__(self):
print('我是__init__()')
def __del__(self):
print('被销毁了')
p = Person()
print("这是最后一行代码")
输出结果

del p 执行的时候,内存会立即被回收,会调用对象本身的__del__()方法,此时程序执行顺序如下输出结果所示:
class Person:
def __init__(self):
print('我是__init__()')
def __del__(self):
print('被销毁了')
p = Person()
del p #删除p对象
print("这是最后一行代码")
输出结果

二、面向对象的三大特性
面向对象三大特性:封装、继承、多态
1、封装
封装是指隐藏对象中一些不希望被外部所访问到的属性或方法
(1)私有属性(受保护的属性)
①私有属性
私有属性是指只允许在类的内部使用,无法通过对象访问的属性。隐藏属性会在属性名或者方法名前面加上两个下划线__。
class Person:
name = 'zct' #类属性
__age = 28 #私有属性
pe = Person()
print(pe.name)
print(pe.__age) #报错
输出结果

因为name是类属性,可以在类外由对象访问,而__age是私有属性,只允许在类的内部使用,无法通过对象访问。
②使用对象名._类名__属性名访问私有属性(了解)
print(pe._Person__age)
pe._Person__age = 18 #对隐藏属性修改
print(pe._Person__age)
输出结果

③在类的内部访问私有属性(推荐使用的方法)
通过在实例方法内部直接通过类名.__私有属性访问
class Person:
name = 'zct' #类属性
__age = 28 #私有属性
def introduce(self): #实例方法
Person.__age = 18
print(f"{Person.name}的年龄是{Person.__age}") #在实例方法中访问私有属性
pe = Person()
pe.introduce()
输出结果

(2)隐藏属性
①单下划线开头、双下划线开头、无下划线属性的区别
1、无下划线属性
普通属性/方法,完全公开,可被外部直接访问或修改
2、双下划线开头
私有属性和方法,外部不能直接访问,需要通过名称修饰机制来访问。
子类不能直接继承父类的私有属性和方法,因为名称修饰机制会改变属性和方法的名称。
在另一个py文件中通过from xxx import *导入的时候,可以导入,因为Python 的 all 列表默认不会排除双下划线开头的成员
魔法方法和属性是双下划线开头且双下划线结尾,而双下划线开头但不双下划线结尾的是私有成员
3、单下划线开头
隐藏属性,如果定义在类中,外部可以直接访问,但不建议这么做
子类可以继承父类单下划线开头的属性和方法
另一个py文件中通过from xxx import *导入的时候,默认一般不会导入。
主要是作为一种约定,提示开发者这是类内部使用的成员
class Person:
name = 'zct'
__age = 22 #私有属性(双下划线)
_sex = '男' #隐藏属性(单下划线)
pe = Person()
#print(pe.sex) #报错
#使用对象名._属性名调用
print(pe._sex)
访问隐藏属性,使用对象名._属性名方式
(3)私有方法
①私有方法
class Man:
def __play(self): #私有方法
print('玩手机')
def funa(self): #普通的实例方法
print('普通的实例方法')
ma = Man()
ma.funa()
ma.__play() #报错
输出结果
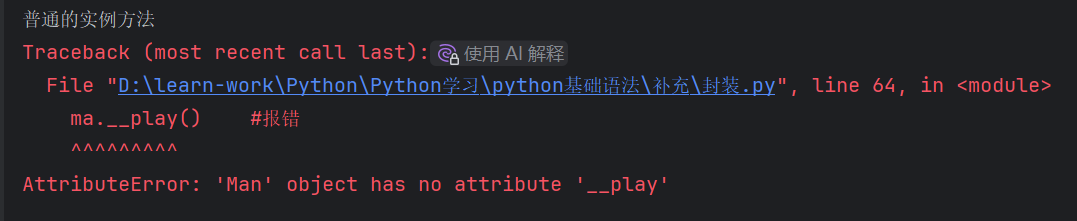
因为私有方法,外部不可以访问
②通过对象名._类名__私有方法调用(不推荐)
ma._Man__play()
输出结果

③在实例方法中**类名.__私有方法(self)**调用私有方法(不建议)
class Man:
def __play(self): #私有方法
print('玩手机')
def funa(self): #普通的实例方法
print('普通的实例方法')
Man.__play(self) #在实例方法中调用私有方法 ----不推荐
ma = Man()
ma.funa()
④在实例方法中通过**self.__私有方法()**调用私有方法(推荐)
class Man:
def __play(self): #私有方法
print('玩手机')
def funa(self): #普通的实例方法
print('普通的实例方法')
self.__play() #推荐使用,更简便
ma = Man()
ma.funa()
(4)隐藏方法
class Girl:
def _buy(self): #隐藏方法
print('整天买买买')
girl = Girl()
girl._buy()
隐藏方法可以在外部通过**对象名._隐藏方法()**调用(不建议)
2、继承
(1)继承概念
类的继承是一种面向对象编程的重要特性,允许一个类(子类、派生类)继承另一个类(父类、基类)的属性和方法。子类可以复用父类已有的代码,避免重复编写。子类能在继承父类的基础上,添加新的属性和方法,或者对父类的方法进行重写(覆盖),以实现特定功能。
(2)继承方式
①单继承
class Person:
def eat(self):
print('我会吃饭')
class Girl(Person):
pass #占位符,代码里面类下面不写任何东西,会自动跳过,不会报错
class Boy(Person):
pass
girl = Girl()
girl.eat()
boy = Boy()
boy.eat()
由此也可知,子类可以继承父类的属性和方法,即便子类自己没有,也可以使用父类的
②多继承
多继承指一个子类可以同时继承多个父类,并且具有所有父类的属性和方法。
在Python中,一个类可以通过在类定义时在括号中指定多个父类来实现多继承,多个父类之间使用逗号分隔。
多继承的缺点:容易引发冲突;会导致代码设计的复杂度增加
class Father(object):
def money(self):
print('拥有一百万财产需要被继承')
class Mother(object):
def appearance(self):
print('绝世容颜需要被继承')
class Son(Father,Mother):
pass
son = Son()
son.money()
son.appearance()
输出结果

当多继承中,不同的父类存在同名的方法时,子类调用父类方法时采用就近原则,括号的父类哪一个离的最近,就优先调用哪个方法(在开发中尽量避免这种情况),例如:
class Father(object):
def money(self):
print('拥有一百万财产需要被继承')
class Mother(object):
def money(self):
print('拥有一百二十万财产需要被继承')
def appearance(self):
print('绝世容颜需要被继承')
class Son(Father,Mother):
pass
son = Son()
son.money()
son.appearance()
输出结果

因为在搜索方法时,父类的money()方法在前面,故优先继承父类的money()方法。
补充:方法的搜索顺序(了解)
python中内置属性 __mro__可以查看方法搜索顺序,搜索方法时,会先按照__mro__的输出结果,从左往右的顺序查找,如果找到最后一个依旧没有找到,就会报错。例如:
print(Son.__mro__)
输出结果

举例:
class Father(object):
def money(self):
print('拥有一百万财产需要被继承')
class Mother(object):
def money(self):
print('拥有一百二十万财产需要被继承')
def appearance(self):
print('绝世容颜需要被继承')
class Son(Father,Mother):
# pass
def money(self):
print('十万')
son = Son()
son.money()
son.appearance()
输出结果

因为由上面print(Son.mro)输出结果可知,如果子类中有同名方法,优先调用子类的该方法,所以输出“十万”。
③继承的传递性
C类继承B类,B类继承A类,C类具有A类和B类的属性和方法。继承的传递性,即子类拥有父类以及父类的父类中的属性和方法。
class Father:
def eat(self):
print('吃饭')
def sleep(self):
print('睡觉')
class Son(Father):
pass
class Grandson(Son):
pass
son = Son()
son.eat()
son.sleep()
grandson = Grandson()
grandson.eat()
grandson.sleep()
输出结果

(3)覆盖父类方法(重写)
重写指的是子类重新定义父类中已有的方法,子类的方法会覆盖掉父类的同名方法。当调用该方法时,执行的是子类中重写后的方法逻辑,而非父类原有的逻辑。
class Person:
def money(self):
print('一百万需要被继承')
class Man(Person):
def money(self):
print('自己赚一千万')
man = Man()
man.money()
输出结果

(4)扩展父类方法
扩展父类方法通常是指在子类中既保留父类方法的原有功能,又添加新的功能。
调用在子类中添加的方法的方式有三种:
1、父类名.方法名(self)
2、super().方法名() ----推荐使用
3、super(子类名,self).方法名()
class Person:
def money(self):
print('一百万需要被继承')
def sleep(self):
print('睡觉了')
class Man(Person):
def money(self):
Person.money(self) #第一种方法
print('自己赚一千万')
man = Man()
man.money()
class Person:
def money(self):
print('一百万需要被继承')
def sleep(self):
print('睡觉了')
class Man(Person):
def money(self):
super().money() #第二种方法
super().sleep() #可以调用父类中的其他方法
print('自己赚一千万')
man = Man()
man.money()
class Person:
def money(self):
print('一百万需要被继承')
def sleep(self):
print('睡觉了')
class Man(Person):
def money(self):
super(Man,self).money() #第三种方法
print('自己赚一千万')
man = Man()
man.money()
(5)新式类写法
Python中的类(class)有两种:
#经典类
class A:
pass
#新式类
class A(object):
pass
在Python 2中,新式类是通过继承自object类来定义的,而经典类类(也称为旧式类)则不继承自任何基类。
从Python 3开始,所有的类都默认是新式类,即使它们不显式地继承自object。不过,为了兼容性和明确性,在Python 3中仍然推荐显式地继承自object。
3、多态
(1)多态概念
多态是指同一种行为具有不同的表现形式。
多态的前提:继承、重写
举例:
class Animal(object):
'''父类:动物类'''
def shout(self):
print('动物叫')
class Cat(Animal):
'''子类1:小猫类'''
def shout(self):
print('小猫喵喵喵')
class Dog(Animal):
'''子类2:小狗类'''
def shout(self):
print('小狗汪汪汪')
cat = Cat()
cat.shout()
dog = Dog()
dog.shout()
输出结果

子类继承了父类,但对某些方法进行了重写(override),不同的子类可以有不同的实现。
(2)多态性
多态性:定义一个统一的接口,一个接口多种实现。也即一种调用方式,会有不同的执行结果。如下:
class Animal(object):
def eat(self):
print('我会干饭')
class Pig(Animal):
def eat(self):
print('猪吃猪伺料')
class Dog(Animal):
def eat(self):
print('狗吃狗粮')
def test(obj):
obj.eat()
animal = Animal()
test(animal)
pig = Pig()
test(pig)
输出结果

在这个例子中,test函数并不关心是什么类型的动物,什么动物都有吃的能力,只要有一个eat方法就行。test函数传入不同的对象,就可以执行不同对象的eat方法。
4、静态方法
(1)静态方法的基本概念
静态方法是通过 @staticmethod 装饰器定义的方法。静态方法既不需要传递实例对象,也不需要传递类对象,即没有self,cls参数的限制。静态方法与类无关,可以被转换成函数使用。
(2)静态方法的定义格式
class 类名:
@staticmethod
def 方法名(形参):
方法体
(3)静态方法的调用格式
静态方法既可以使用类访问,也可以使用对象访问
类名.方法名(实参)
对象名.方法名(实参)
举例:
class Person(object):
@staticmethod #静态方法
def study(name):
print(f'{name}人类会学习')
#静态方法既可以使用对象访问,也可以使用类访问
Person.study('zct')
pe = Person()
pe.study('zct') #调用方法时传参数
输出结果

(4)静态方法的使用场景
不需要访问实例对象或实例属性,也不需要访问类属性或类方法或不需要创建实例的时候,可以使用静态方法,这样取消不必要的参数传递,有利于减少不必要的内存占用和性能消耗。
5、类方法
(1)类方法的基本概念
类方法是定义在类中的方法,通过装饰器@classmethod来标识。它的第一个参数是cls(表示类本身),而不是实例对象。类方法可以访问类的属性,并且可以在没有实例的情况下被调用。
(2)类方法的定义格式
class 类名:
@classmethod
def 方法名(cls,形参):
方法体
(3)类方法的使用方式
类方法可以类名或实例对象来调用
类名.方法名()
对象名.方法名()
举例:
class Person(object):
@classmethod
def sleep(cls):
print("cls:",cls) #cls代表类对象本身,类本质上就是一个对象
print('人类在睡觉')
print(Person)
Person.sleep() #通过类名调用类方法
输出结果

由cls和Person打印出来的结果是一样的,也可说明cls代表类对象本身。
另外,类方法内部可以使用cls.类属性名访问类属性,或者调用其他的类方法。如下例:
class Person(object):
name = 'zct' #类属性
@classmethod
def sleep(cls):
print(cls.name) #类方法内部访问类属性name
Person.sleep()
输出结果

(4)类方法的应用场景
当方法中需要使用到类对象(如访问私有类属性等)时,定义类方法。因此类方法一般是配合类属性使用。
6、实例方法、静态方法、类方法的区别
1、实例方法,第一个参数为self,可以访问实例属性或类属性,必须通过类实例调用。
2、静态方法,使用@staticmethod装饰器修饰,无默认参数,不需要访问实例属性或类属性,因为静态方法与类无关,访问没有意义,但可以通过类名.类属性访问类属性,但无法访问实例属性,可以通过类或实例调用。
3、类方法,使用@classmethod装饰器修饰,第一个参数为cls,只能访问类属性,可以通过类或实例调用。
class Person(object):
name = 'zct' #类属性
def eat(self): #实例方法
print(self.food) #可以访问实例属性
print(Person.name) #可以访问类属性,不建议使用self.name,虽然也可以访问到
@staticmethod #静态方法
def sing(song):
print(f'我在唱{song}') #不能访问实例属性或类属性
@classmethod #静态方法
def sleep(cls):
print(cls.name) #只能访问类属性
pe1 = Person()
pe1.food = '香蕉' #实例属性
pe1.eat() #通过实例调用
#Person.sing('儿歌') #通过类调用
pe2 = Person()
pe2.sing('儿歌') #通过实例调用
#Person.sleep() #通过类调用
pe3 = Person()
pe3.sleep() #通过实例调用
7、单例模式
(1)什么是单例模式
单例模式可以理解为一个特殊的类,这个类只存在一个对象。即每次实例化所创建出来的对象都是同一个,内存地址都是同一个。
优点:可以节省内存空间,减少了不必要的资源浪费
缺点:多线程访问时容易引发线程安全问题
(2)new()
①__new__()作用
new()是object基类提供的内置的静态方法。
其作用:1、在内存中为对象分配空间;2、返回对象的引用。
②__new__()与__init__()
一个对象实例化过程:
首先执行__new__(),如果没有写__new__(),默认调用object里面的__new__(),返回一个实例对象, 传给__init__()中的self,然后再去调用__init__(),对这个对象进行初始化。
new()与__init__()区别:
1、new()是创建对象,init()是初始化对象
2、new()是返回对象引用,init()定义实例属性
3、new()是类级别的方法,init()是实例级别的方法
举例:
class Person(object):
def __new__(cls, *args, **kwargs):
print("这是new方法")
res = super().__new__(cls)
#print("返回值:", res)
return res
def __init__(self,name):
self.name = name #实例属性
print("名字是:",self.name)
pe = Person('zct')
输出结果

(3)单例模式的实现方式
1、通过@classmethod
2、通过装饰器实现
3、通过重写__new__()实现(重点)
4、通过导入模块实现
①通过重写__new__()实现单例模式
设计流程:
1、定义一个类属性,初始值为None,用来记录单例对象的引用(内存地址)
2、重写__new__()方法。注意一定要return super().new(cls), 否则python解释器得不到分配空间的对象引用,就不会调用__init__()。
3、进行判断,如果类属性是None,把__new__()返回的对象引用保存进去
4、返回类属性中记录的对象引用(内存地址)
举例:
class Singleton(object):
#记录第一个被创建的对象的引用
obj = None #类属性
def __new__(cls, *args, **kwargs):
print("这是__new__()方法")
#判断类属性是否为空
if cls.obj == None:
cls.obj = super().__new__(cls)
return cls.obj
def __init__(self):
print("我是__init__()")
s = Singleton()
print("s:",s)
s2 = Singleton()
print("s2:",s2)
s3 = Singleton()
print("s3:",s3)
输出结果
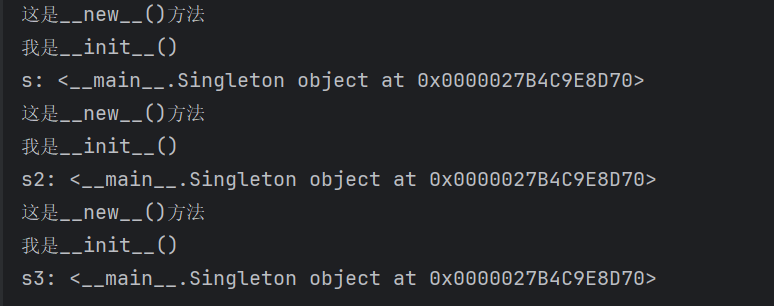
有输出结果可知,s,s2,s3的内存地址一样,即是同一个对象,实现了单例模式。
(4)单例模式的应用场景
1、回收站对象
2、音乐播放器(一个音乐播放软件负责播放的对象只有一个,即同一时间只能播放一首歌曲)
3、开发游戏软件 场景管理器
4、数据库配置、数据库连接池的设计
8、魔法方法和魔法属性
(1)魔法属性
①__doc__
类的描述信息,例如:
class Person(object):
'''人类---类的描述信息''' #只能使用多行注释,单行注释无效
pass
print(Person.__doc__)
输出结果

②__module__与__class__
__module__表示当前操作对象所在的模块
__class__表示当前操作对象所在的类
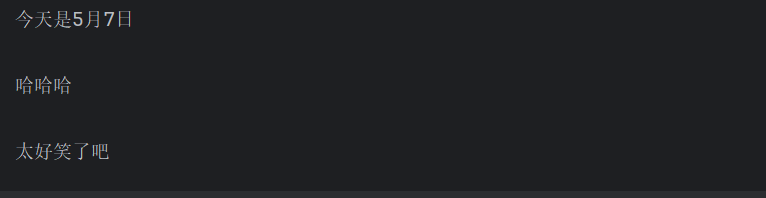
'''pytest01.py'''
class B:
def funa(self):
print("哈哈哈")
import pytest01
b = pytest01.B()
print("b:",b)
# b.funa()
print("对象b所在的模块:",b.__module__) #输出模块
print("对象b所在的类:",b.__class__) #输出类
输出结果

(2)魔法方法
①__str__()
对象的描述信息。如果类中定义了此方法,那么在打印对象时,默认输出该方法的返回值,也就是打印方法中return的数据
注意:str()必须返回一个字符串
class C:
def __str__(self):
return "这里是str的返回值" #这个方法必须要有返回值,并且一定是字符串类型
# return 123
c = C()
print(c)
输出结果

②__call__()
使一个实例对象成为一个可调用对象,就像函数那样可以调用。
可调用对象:函数、内置函数和类都是可调用对象,凡是可以把一对()应用到某个对象身上都可以称为可调用对象。
判断一个对象是否是可调用对象可用callable(),是返回True,否则返回False。
def func():
print("呵呵呵")
func()
print(callable(func)) #True
name = 'zct'
# name() #报错
print(callable(name)) #False
class A:
pass
a = A()
# a() #报错,实例化对象是不可调用的
print(callable(a)) #False
class A:
def __call__(self, *args, **kwargs):
print("这是__call__()")
a = A()
a() #调用一个可调用的实例对象,其实就是在调用它的__call__()方法
a2 = A()
a2()
print(callable(a)) #True
由上可知,使用了__call__(),使一个实例对象成为一个可调用对象。
9、文件
(1)文件
①什么是文件
文件就是存储在某种长期储存在设备上的一段数据。
②文件操作
文件操作的过程即打开文件—>读、写文件—>关闭文件。
③文件对象的方法
1、open():创建一个file对象,默认以只读模式打开
2、read(n):n表示从文件中读取的数据的长度,没有传n值就默认一次性读取文件的所有内容
3、write():将指定内容写入文件
4、close():关闭文件
④文件名的属性
文件名.name: 返回要打开的文件名,可以包含文件的具体路径
文件名.mode: 返回文件的访问模式
文件名.closed: 检测文件是否关闭,关闭就返回True
# # 1.打开文件
# f = open('test.txt')
# print(f.name) #返回文件的文件名
# print(f.mode) #文件访问模式
# print(f.closed) #False
# # 2.关闭文件
# f.close()
# print(f.closed) #True
(2)读写操作
①read(n)
n表示从文件中读取的数据的长度,没有传n值或者传的是负值就默认一次性读取文件的所有内容。
f = open("test.txt")
f = open(r'D:\learn-work\Python\test.txt')
# print(f)
print(f.name) #文件所在的具体路径(绝对路径)
print(f.read()) #一次性把文件内容都读取出来了
# print(f.read(5)) #最多读取5个数据
f.close()
输出结果

②readline()
一次只读取一行内容(行末的换行符也一并读取进来),方法执行完,会把文件指针移到下一行,准备再次读取。
f = open("test.txt",encoding = 'utf-8')
# print(f.readline())
# print(f.readline())
# print(f.readline())
while True:
text = f.readline() #读取一行内容
# 读不到内容退出循环
if not text:
break
print(text)
f.close()
输出结果
③readlines()
按照行的方式把文件内容一次性读取,返回的是一个列表,每一行的数据就是列表中的一个元素。
f = open("test.txt",encoding = 'utf-8')
text = f.readlines()
print(text)
print(type(text))
for i in text:
print(i)
f.close()
(3)访问模式
1、r:只读模式(默认模式),文件必须存在,不存在就会报错
2、w:只写模式,文件存在就会先清空文件内容,再写入添加内容,不存在就创建新文件
3、r+:可读写文件,文件不存在就会报错
4、w+:先写再读,文件存在,就重新编辑文件,不存在就创建新文件
(4)文件定位操作
只要用到tell()和seek()方法。tell()用于显示文件内当前位置,即文件指针当前位置;seek(offset,whence)用于移动文件读取指针到指定位置,其中offset表示偏移量,即表示要移动的字节数,whence:起始位置,表示移动字节的参考位置,默认是0,0代表文件开头作为参考位置,1代表当前位置作为参考位置,2代表将文件结尾作为参考位置。如seek(0,0)就会把文件指针移动到文件开头。
f = open("test.txt",'w+')
f.write('hello Python')
pos = f.tell()
print("当前文件指针所在的位置:",pos)
f.seek(0,0) #把文件指针移动到文件开头
pos2 = f.tell()
print("移动后所在位置:",pos2)
print(f.read())
f.close()
输出结果

(5)with open与编码格式
with open作用:代码执行完,系统会自动调用f.close(),可以省略文件关闭步骤。
with open("test.txt",'w') as f: #f是文件对象
f.write("ememem...")
print(f.closed) #False
print(f.closed) #True
由结果可知,在with open 里面打印f.closed是False,说明此时文件是打开状态的,在with open外面打印f.closed是True,说明此时文件已关闭了,不用自己使用f.close()关闭文件了。
使用encoding = 'utf-8’来设置编码格式,windows默认编码格式是gbk。
(6)目录常用操作
目录操作要导入模块import os。
1、文件重命名 os.rename(旧名字,新名字)
2、删除文件 os.remove
3、创建文件夹 os.mkdir()
4、删除文件夹 os.rmdir()
5、获取当前目录 os.getcwd()
6、获取目录列表 os.listdir(),其中os.listdir(‘…/’)获取上一级目录列表
10、可迭代对象、迭代器、生成器
(1)可迭代对象
①什么是可迭代对象
可迭代对象Iterable。迭代(遍历),即依次从对象中把一个个元素取出来的过程。数据类型为str、list、tuple、dict、set等一般是可迭代对象。
②可迭代对象的条件
1、对象实现了__iter__()方法
2、iter()方法返回了迭代器对象
③for循环的工作原理
1、先通过__iter__()获取可迭代对象的迭代器
2、对获取到的迭代器不断调用__next__()方法来获取下一个值并将其赋值给临时变量i
④使用isinstance(o,t)判断是否是可迭代对象或者是否是一个已知的数据类型。o是对象,t是数据类型。
print(isinstance(123,Iterable)) #False
print(isinstance(123,int)) #True
print(isinstance('123',(str,int))) #True
(6)迭代器
①什么是迭代器
迭代器 Iterator。是一个可以记住遍历位置的对象,在上次停留的位置继续做一些事情。
②如何创建迭代器
使用**iter()来获取可迭代对象的迭代器,使用next()**来一个个去取元素,取完元素后会引发一个异常。
li = [1,2,3,4,5]
# 1、创建迭代器对象
li2 = iter(li)
print(li2)
# 2、获取下一条数据
print(next(li2))
print(next(li2))
print(next(li2))
print(next(li2))
print(next(li2))
# 3、取完元素后,再使用next()会引发StopIteration异常
#print(next(li2)) #StopIteration异常
创建迭代器对象,并获取元素步骤:
1、iter()调用对象的__iter__(),并把__iter__()方法的返回结果作为自己的返回值
2、next()调用对象的__next__(),一个个取元素
3、所有元素都取完了,next()将引发StopIteration异常
li = [1,2,3,4,5]
li2 = li.__iter__()
print("li2:",li2)
print(li2.__next__())
print(li2.__next__())
print(li2.__next__())
print(li2.__next__())
print(li2.__next__())
#print(li2.__next__()) #StopIteration异常
③可迭代对象iterable和iterator
凡是可以作用于for循环的都属于可迭代对象
凡是可以作用于next()的都是迭代器
from collections.abc import Iterable,Iterator
name = 'zct'
print(dir(name))
print(isinstance(name,Iterable)) #True
print(isinstance(name,Iterator)) #False
输出结果
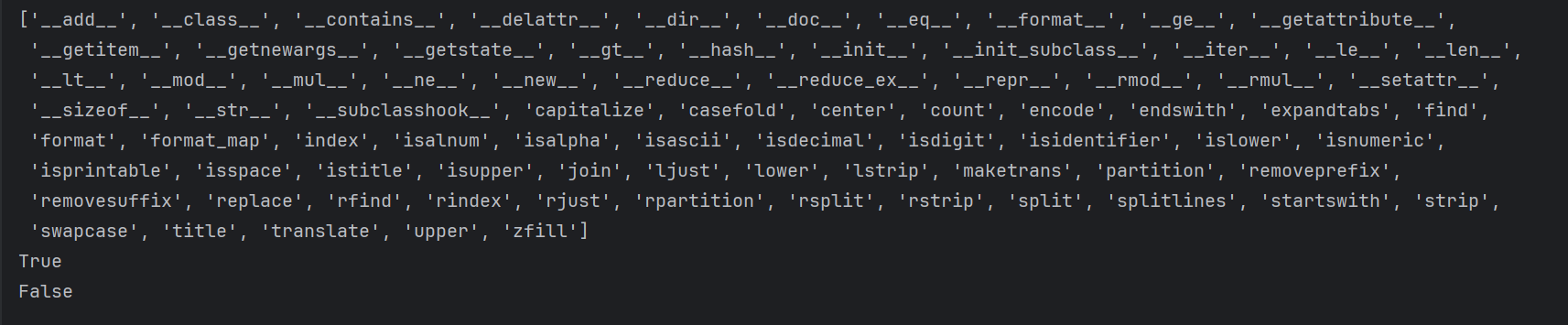
由结果可知,字符串name是可迭代对象,不是迭代器对象;另外由dir(name)打印结果中有__iter__,而没有__next__,也说明了name是可迭代对象,不是迭代器对象。故可迭代对象并不一定是迭代器对象。
name2 = iter(name) #将name转换成迭代器对象
print(dir(name2))
print(isinstance(name2,Iterable)) #True
print(isinstance(name2,Iterator)) #True
输出结果

由结果可知,name2经iter()方法转换为迭代器对象,并且由dir(name2)的输出结果可知,既有__iter__,也有__next__,也可以说明是迭代器对象。同时,也可得出迭代器对象一定是可迭代对象。
总结:
1、可迭代对象可以通过iter()方法转换成迭代器对象
2、如果一个对象拥有__iter__(),是可迭代对象,如果一个对象拥有__next__()和__iter__()方法,是迭代器对象
3、dir():查看对象中的属性和方法
④迭代器协议
对象必须提供一个next方法,执行该方法要么就返回迭代中的下一项,要么就引发StopIteration异常,来终止迭代。
⑤自定义迭代器类
迭代器的两个特性: iter()和__next__()
class MyIterator:
def __init__(self):
self.num = 0
def __iter__(self):
return self
def __next__(self):
if self.num == 10:
raise StopIteration("终止迭代,数据已经被取完了")
self.num += 1
return self.num
mi = MyIterator()
print(mi)
for i in mi:
print(i)
输出结果
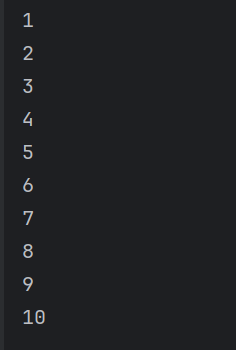
(6)生成器
①什么是生成器
生成器 generator。Python中一边循环一边计算的机制,叫做生成器
②生成器表达式
将列表推导式的[]改成()就成了生成器表达式。
gen = (i * 5 for i in range(5)) #列表推导式的[]改成()就成了生成器表达式
print(gen)
print(next(gen))
print(next(gen))
print(next(gen))
print(next(gen))
print(next(gen))
# print(next(gen)) #StopIteration
输出结果

③生成器函数
Python中使用了yield关键字的函数就称之为生成器函数。
yield的作用:
1、类似return,将指定值或者多个值返回给调用者
2、yield语句一次返回一个结果,在每个结果中间,挂起函数,执行next(),再重新从挂起点继续往下执行
是函数中断,并保存中间的状态。
def gen():
print("开始了")
yield 'a' #返回一个a,并暂停函数,在此处挂起,下一次再从此处恢复执行
yield 'b'
yield 'c'
gen_01 = gen()
print(gen_01)
print(next(gen_01))
print(next(gen_01))
第一次print(next(gen_01)),输出a,第二次print(next(gen_01)) ,输出b。
def test_a():
yield 1
yield 2
yield 3
print(test_a())
ta = test_a()
print(next(ta)) #从对象中取值
print(next(ta))
print(next(ta))
print(next(test_a())) #加括号就是调用函数,会重新调用
print(next(test_a()))
print(next(test_a()))
输出结果

注意:print(next(ta)) 和print(next(test_a())) 的区别,前者是从对象中取值,后者是函数的调用,每次调用都会有一个新的对象,每个对象都是从1开始取值,故后者打印出来的始终是1。
(7)可迭代对象、迭代器、生成器三者区别
1、可迭代对象:指实现了python迭代协议,可以通过for…in,循环遍历的对象,比如list、dict、str…、迭代器、生成器。
2、迭代器:可以记住自己遍历位置的对象,直观体现就是可以使用next()函数返回值,迭代器只能往前,不能往后,当遍历完毕之后,next()会抛出异常。
3、生成器:特殊的迭代器,需要注意迭代器并不一定是生成器,它是Python提供的通过简便的方法写出迭代器的一种手段。
4、包含关系:可迭代对象 >迭代器>生成器
11、线程
(1)什么是线程
执行一个程序时,默认情况下会创建一个进程,在一个进程里面又会创建一个线程,线程是可以真正工作的单位,而进程是为线程提供资源的单位。程序,进程和线程三者的关系就类似于工厂、车间和工人的关系。
(2)多线程
多线程即同时运行多个线程。
使用import threading,导入线程模块
1、target:执行的任务名
2、args:以元组的形式给任务传参
3、线程.name:获取线程的名字
4、线程.name = 值:更改线程的名字
5、join():暂停的作用,等子线程执行结束后,主线程才会继续执行,必须放在start()后面
6、线程.daemon = True:守护线程,必须放在start()前面。主线程执行结束,子线程也会跟着结束
举例:
def sing(name):
print(f"{name}在唱歌")
time.sleep(2)
print("唱完歌了")
def dance(name2):
print(f"{name2}在跳舞")
time.sleep(2)
print("跳完舞了")
#主程序入口
if __name__ == '__main__':
# 1、创建子线程
t1 = threading.Thread(target = sing,args = ('zct',)) #已元组的形式传参
# print(t1)
t2 = threading.Thread(target=dance,args = ('zzz',))
# 3、守护线程,必须放在start()前面:主线程执行结束,子线程也会跟着结束
t1.daemon = True
t2.daemon = True
# 2、开启子线程
t1.start()
t2.start()
# 4、阻塞主线程join():暂停的作用,等子线程执行结束后,主线程才会继续执行,必须放在start()后面
t1.join()
t2.join()
# 5、获取线程名字
# print(t1.getName()) #已被弃用
# print(t2.getName())
print(t1.name)
print(t2.name)
# 6、更改线程名
t1.name = "子线程一"
t2.name = "子线程二"
print(t1.name)
print(t2.name)
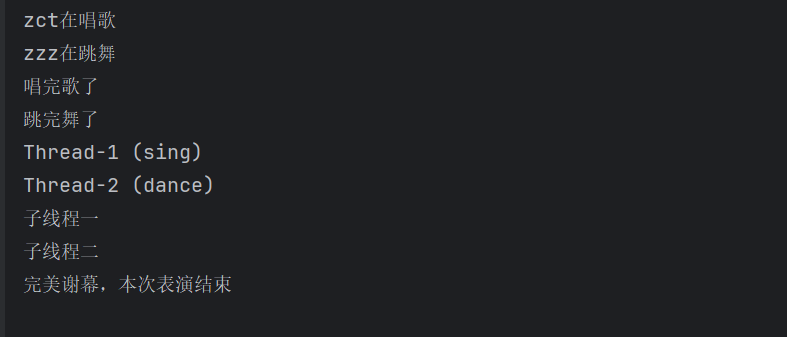
print("完美谢幕,本次表演结束")
输出结果
(3)线程之间的执行是无序的
线程执行是根据cpu调度决定的。
def task():
time.sleep(1)
print("当前线程是:",threading.current_thread().name) #显示当前线程对象名
if __name__ == '__main__':
for i in range(5):
#每循环一次就创建一个子线程
t = threading.Thread(target = task)
#启动子线程
t.start()
输出结果

每次执行的结果可能不同。
(4)线程之间共享资源(全局变量)
li = []
#写入数据
def wdata():
for i in range(5):
li.append(i)
time.sleep(0.2)
print("写入的数据是:",li)
def rdata():
print("读取的数据是:",li)
if __name__ == '__main__':
#创建子线程 线程名 = Thread(target = 函数名,args = (参数1,参数2,...)),线程会执行这个函数,以此完成这件事
t1 = Thread(target = wdata)
t2 = Thread(target = rdata)
#开启子线程(让线程开始工作)
t1.start()
#阻塞线程
t1.join() #第一种方法:加了join()就会等待t1任务执行结束
#time.sleep(0.8) #第二种方法:写线程程写四个数据时,读线程就开始读了,因此读线程只读到了四个数据,但写线程还在继续写,直到写完,即写了5个数据
t2.start()
# t2.join()
输出结果

(5)资源竞争
a = 0
b = 1000000
#循环一次就给全局变量a+1
def add():
for i in range(b):
global a #如果在函数内部直接修改全局变量(如 a += 1),必须先用 global 声明该变量为全局变量。如果只是读的话,就不用global
a += 1
print("第一次:",a)
def add2():
for i in range(b):
global a # 如果在函数内部直接修改全局变量(如 a += 1),必须先用 global 声明该变量为全局变量。如果只是读的话,就不用global
a += 1
print("第二次:", a)
# add() #第一次: 1000000
# add2() #第二次: 2000000
if __name__ == '__main__':
first = Thread(target = add)
second = Thread(target = add2)
first.start()
second.start()
输出结果

由于存在资源竞争,每次输出的结果都可能不同
(6)线程同步
线程同步有两种实现方式。
①join()
a = 0
b = 1000000
#循环一次就给全局变量a+1
def add():
for i in range(b):
global a #如果在函数内部直接修改全局变量(如 a += 1),必须先用 global 声明该变量为全局变量。如果只是读的话,就不用global
a += 1
print("第一次:",a)
def add2():
for i in range(b):
global a # 如果在函数内部直接修改全局变量(如 a += 1),必须先用 global 声明该变量为全局变量。如果只是读的话,就不用global
a += 1
print("第二次:", a)
if __name__ == '__main__':
first = Thread(target = add)
second = Thread(target = add2)
first.start()
first.join() #等待第一个子线程执行结束完成以后,代码再继续往下执行,开始执行第二个子线程
second.start()
②互斥锁
对共享数据进行锁定,保证多个线程访问共享数据不会出现数据错误问题:保证同一时刻只能有一个线程去操作。
acquire() 加锁,release() 解锁,这两个方法必须要成对出现,否则容易形成死锁。死锁即一直等待对方释放锁的情景,会造成应用程序停止响应,不再处理其他任务。
a = 0
b = 1000000
# 1、创建互斥锁
lock = Lock()
def add():
lock.acquire() #加锁
for i in range(b):
global a
a += 1
print("第一次:",a)
lock.release() #解锁
def add2():
lock.acquire() # 加锁
for i in range(b):
global a
a += 1
print("第二次:", a)
lock.release() # 解锁
if __name__ == '__main__':
first = Thread(target = add)
second = Thread(target = add2)
first.start()
second.start()
输出结果

注意:互斥锁是多个线程一起去抢,抢到锁的线程先执行。
总结:
1、互斥锁作用:保证同一时刻只有一个线程去操作共享数据,保证共享数据不会出现错误问题
2、上锁和释放锁必须成对出现,否则容易造成死锁现象
3、互斥锁的缺点:会影响代码的执行效率
12、进程
(1)进程
①含义
进程是操作系统进行资源分配和调度的基本单位,是操作系统结构的基础;
一个正在运行的程序或者软件就是一个进程,程序跑起来就成了进程。
注意:进程里面可以创建多个线程,多进程也可以完成多任务。
②进程的状态
1、就绪状态:运行的条件都已经满足,正在等待cpu执行
2、执行状态:cpu正在执行其功能
3、等待(阻塞)状态:等待某些条件满足,如一个程序sleep了,此时就是等待状态
举例
# print("我是zct") #程序执行,处于执行状态
# sex = input("输入性别:") #光标闪动,等待用户输入,处于等待状态
# print(sex) #执行状态
# time.sleep(1) #延迟1秒,等待(阻塞)状态
(2)进程的语法结构
multiprocessing模块提供了Process类代表进程对象
①Process 类参数
1、target:执行的目标任务名,即子进程要执行的任务
2、args:以元组的形式传参
3、kwargs:以字典的形式传参
②方法
1、start():开启子进程
2、is alive():判断子进程是否还活着,存活就返回True,死亡就返回False
3、join():主进程等待子进程执行结束
③属性
1、name :当前进程的别名,默认Process-N
2、pid:当前进程的进程编号
def sing():
# os.getpid():获取当前进程编号
# os.getppid():获取当前父进程编号
print(f"sing子进程编号:{os.getpid()},父进程pid:{os.getppid()}") #父进程的pid就是py文件主进程的pid
print("唱歌")
def dance():
print(f"dance子进程编号:{os.getpid()},父进程pid:{os.getppid()}")
print("跳舞")
if __name__ == '__main__':
# 创建子进程
# 修改子进程名第一种方式
p1 = Process(target = sing,name = "子进程一")
p2 = Process(target = dance,name = "子进程二")
# 开启
p1.start()
p2.start()
# 修改子进程名第二种方式
p1.name = "子进程1"
p2.name = "子进程2"
# 访问name属性
print("p1:",p1.name)
print("p2:",p2.name)
# 查看子进程的进程编号
print("p1.pid:",p1.pid)
print("p2.pid:",p2.pid)
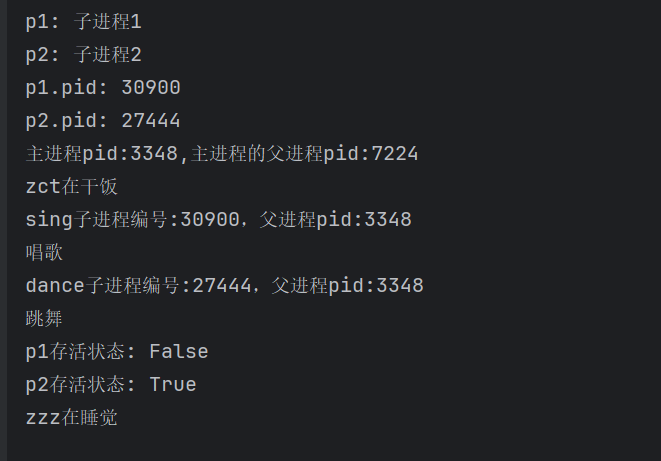
print(f"主进程pid:{os.getpid()},主进程的父进程pid:{os.getppid()}")
# cmd命令提示符窗口输入tasklist就可以查看电脑里面进程的命令
# Ctrl + F 查找
# pycharm64软件进程编号就是主进程的父进程编号
def eat(name):
print(f"{name}在干饭")
def sleep(name):
print(f"{name}在睡觉")
if __name__ == '__main__':
p1 = Process(target = eat,args = ("zct",)) #元组只有一个元素时,必须要加逗号
p2 = Process(target= sleep, args=("zzz",))
p1.start()
p1.join() #主进程处于等待状态,等待p1执行完毕,p1是运行状态
p2.start()
print("p1存活状态:",p1.is_alive()) #False,此时p1已执行完,p2开始启动了
print("p2存活状态:",p2.is_alive()) #True
输出结果
注意:写在主进程中判断存活状态的时候需要加入join阻塞一下。
④进程间不共享全局变量
li = []
def wdata():
for i in range(5):
li.append(i)
time.sleep(0.2)
print("写入的数据是:",li)
def rdata():
print("读取的数据是:",li)
# 1、防止别人导入文件的时候执行了main里面的方法
# 2、防止windows系统递归创建子进程
if __name__ == '__main__':
p1 = Process(target = wdata)
p2 = Process(target = rdata)
p1.start()
p1.join()
p2.start()
输出结果

读取一直是空的,是因为进程不共享全局变量。
(3)进程间的通信
from queue import Queue或者from multiprocessing import Process,Queue导入Queue模块
q.put():放入数据
q.get():取出数据
q.empty():判断队列是否为空
q.qsize():返回当前队列包含的消息参数
q.full():判断队列是否满了
# 初始化一个队列队形
q = Queue(3) #最多可以接收三条消息,没写或者是负值就代表没有上限,直到内存的尽头
q.put("爱你到老")
q.put("你在做梦")
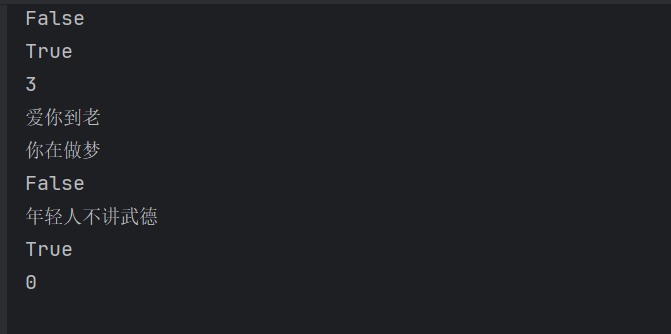
print(q.full())
q.put("年轻人不讲武德")
print(q.full())
# q.put("陪你度过余生")
print(q.qsize())
print(q.get()) #获取队列的一条消息,然后将其从队列中移除
print(q.get())
print(q.empty())
print(q.get())
print(q.empty())
print(q.qsize())
输出结果
进程操作队列
li = ['张三','李四','王麻子','赵六']
def wdata(q1):
for i in range(5):
print(f"{i}已经被放入")
q1.put(i)
time.sleep(0.2)
print("写入的数据是:",li)
def rdata(q2):
while True:
#判断是否为空,队列为空就退出循环
if q2.empty():
break
else:
print("取出数据:",q2.get())
print("读取的数据是:",li)
if __name__ == '__main__':
# 创建队列对象
q = Queue()
p1 = Process(target = wdata,args = (q,))
p2 = Process(target = rdata,args = (q,))
p1.start()
p1.join() #等待队列中的数据放入完成
p2.start()
输出结果

13、协程
(1)协程
协程,单线程下的开发,又称为微线程。线程和进程的操作是由程序触发系统接口,最后的执行者是系统,协程的操作则是程序员。
①简单实现协程
import time
def task1():
while True:
yield '哈哈哈'
time.sleep(1)
def task2():
while True:
yield '嘿嘿嘿'
time.sleep(1)
if __name__ == '__main__':
t1 = task1()
t2 = task2()
while True:
print(next(t1))
print(next(t2))
②应用场景
1、如果一个线程里面由I/O操作比较多的时候,就用协程
常见的I/O操作:文件操作、网络请求、
2、适合高并发处理
(2)greenlet
greenlet是一个由C语言实现的协程模块,通过设置switch()来实现任意函数之间的切换。需要安装第三方模块。
注意:greenlet属于手动切换,当遇到I/O操作,程序会阻塞,而不能进行自动切换 通过greenlet实现任务的切换。
from greenlet import greenlet
def sing():
print("在唱歌")
print("唱完歌了")
def dance():
print("在跳舞")
print("跳完舞了")
# sing()
# dance()
if __name__ == '__main__':
#创建协程对象 greenlet(任务名)
g1 = greenlet(sing)
g2 = greenlet(dance)
g1.switch() #切换到g1中去运行
g2.switch()
输出结果

(3)greenlet
①遇到I/O操作时,会进行自动切换,属于主动式切换。
gevent.spawn(函数名) :创建协程对象
gevent.sleep(): 耗时操作
gevent.join(): 阻塞,等待某个协程执行结束
gevent.joinall(): 等待所有协程对象都执行结束再退出,参数是一个协程对象列表
②gevent自带耗时操作
def sing():
print("在唱歌")
gevent.sleep(2)
# time.sleep(1)
print("唱完歌了")
def dance():
print("在跳舞")
gevent.sleep(3)
print("跳完舞了")
if __name__ == '__main__':
# 1、创建协程对象
g1 = gevent.spawn(sing)
g2 = gevent.spawn(dance)
# 2、阻塞:等待协程执行结束
g1.join() #等待g1对象执行结束
g2.join()

在输出结果中,”跳完舞了”会比“唱完歌了”晚一秒输出。
③joinall()
等待所有协程对象都执行结束再退出。
def sing(name):
for i in range(3):
gevent.sleep(1)
print(f"{name}在唱歌,被送走的第{i}次")
if __name__ == '__main__':
gevent.joinall([
gevent.spawn(sing,'zct'),
gevent.spawn(sing,'xz')
])
输出结果

④monkey补丁
拥有在运行时替换的功能,即将用到的time.sleep()替换成gevent里面自己实现耗时操作的gevent.sleep()代码。
from gevent import monkey
monkey.patch_all()
def sing(name):
for i in range(3):
time.sleep(1)
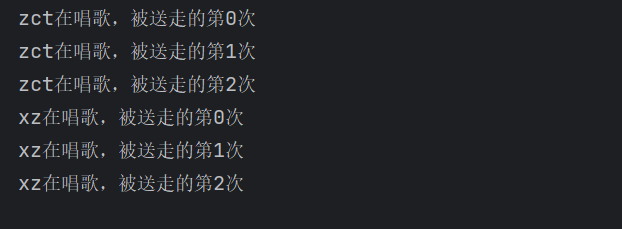
print(f"{name}在唱歌,被送走的第{i}次")
if __name__ == '__main__':
gevent.joinall([
gevent.spawn(sing,'zct'),
gevent.spawn(sing,'xz')
])
输出结果
注意:monkey.patch_all()必须放在被打补丁者的前面。
(4)进程、线程、协程总结
1、线程时CPU调度的基本单位,进程是资源分配的基本单位
2、进程、线程、协程对比
进程:切换需要的资源最大,效率最低
线程:切换需要的资源一般,效率一般
协程:切换需要的资源最小,效率高
3、多线程适合IO密集型操作(文件操作、爬虫),多进程适合CPU密集型操作(科学及计算、对视频进行高清解码、计算圆周率等)
4、进程、线程、协程都是可以完成多任务的,可以根据自己实际开发的需要选择使用。
14、正则基础
(1)正则表达式
需要导入re模块
特点:语法比较复杂,可读性较差。通用性较强,适用于多种编程语言。
步骤:
1、导入re模块
2、使用match方法进行匹配操作
re.match()能匹配出以xxx开头的字符串
如果起始位置没有匹配成功,返回None
3、如果上一步数据匹配成功,使用group()提取数据
import re
res = re.match("z","zct")
print(res.group())
(2)匹配单个字符
1 .匹配任意一个字符,除\n以外
2 [ ]匹配[ ]中列举的字符
3 \d匹配数字0-9
4 \D匹配非数字
5\s匹配空白,即空格和tab键
6 \S匹配非空白
7 \w匹配单词字符,即a-z,A-Z,0-9,_,汉字
8\W匹配非单词字符
(3)匹配多个字符
①*匹配前一个字符出现0次或者无限次,即可有可无
res = re.match(r'\w*','zct')
print(res.group()) #zct
②+匹配前一个字符出现1次或者无限次,即至少一次
res = re.match(r'\d+','12地主家的傻儿子')
print(res.group()) #12
③?匹配前一个字符出现1次或者0次
res = re.match(r'\d?','12地主家的傻儿子')
print(res.group()) #1
④{m}匹配前一个字符出现m次
res = re.match(r'\d{2}','123地主家的傻儿子')
print(res.group()) #12
⑤{m,n}匹配前一个字符出现从m次到n次
res = re.match(r'\d{1,3}','1234地主家的傻儿子')
print(res.group()) #123
(4)匹配开头和结尾
①^:表示以…开头;表示对…取反
res = re.match(r'^py','python')
print(res.group()) #py
注意:^在[]中表示不匹配
res = re.match('[^py]','thon') #[^py]表示匹配除了p、y之外的字符
print(res.group()) #t
②$:匹配字符串结尾
res = re.match(r'\w{6}$','python') #[^py]表示匹配除了p、y之外的字符
print(res.group()) #python
(5)匹配分组
①|匹配左右任意一个表达式 (常用)
res = re.match('abc|def','abc')
print(res.group()) #abc
②(ab)将括号中字符作为一个分组(常用)
res = re.match(r'\w*@(163|qq|126).com','123@163.com')
print(res.group()) #123@163.com
③\num 匹配分组num匹配到的字符串 (经常在匹配标签时被使用)
res = re.match(r'<(\w*)>\w*</\1>','<html>login</html>')
print(res.group()) #<html>login</html>
res = re.match(r'<(\w*)><(\w*)>.*</\2></\1>','<html><body>login</body></html>')
print(res.group()) #<html><body>login</body></html>
④ (?P=name) 引用别名为name分组匹配到的字符串
#(?P<name>)分组起别名
# res = re.match(r'<(?P<L1>\w*)><(?P<L2>\w*)>.*</(?P=L2)></(?P=L1)>','<html><body>login</body></html>')
# print(res.group())
匹配网址 例子:
li = ['www.baidu.com','www.python.org','http.jd.cn','www.py.en','www.abc.cn']
# res = re.match(r'www.\w*.(com|cn|org)','www.baidu.com')
# print(res.group())
for i in li:
res = re.match(r'www.\w*.(com|cn|org)',i)
if res:
print(res.group())
else:
print(f"{i}这个网址有错误")
输出结果

(6)高级用法
①search()
扫描整个字符串并返回第一个成功匹配的对象,如果匹配失败,就返回None。
# res = re.match('th','python') #报错
res = re.search('th','python')
print(res.group()) #th
②findall()
从头到尾匹配,找到所有匹配成功的数据,返回一个列表。
res = re.findall('th','python')
print(res,type(res)) #['th'] <class 'list'>
总结:
1、match()从头开始匹配,匹配成功返回match对象,通过group()进行提取,匹配失败就返回None,只匹配一次
2、search()从头到尾匹配,匹配成功返回第一个成功匹配的对象,通过group()进行提取,匹配失败返回None,只匹配一次
3、findall()从头到尾匹配,匹配成功返回一个列表,匹配所有匹配成功的数据,不需要通过group()进行提取
③sub()
re.sub(pattern,rep1,string,count)
pattern 正则表达式(代表需要被替换的,也就是字符串里面的旧内容)
rep1 新内容
string 字符串
count 指定替换的次数
res = re.sub(r'\d','2','这是这个月的第30天',count=1)
print(res) #这是这个月的第20天
④split
split(pattern,string,maxsplit)
pattern 正则表达式
string 字符串
maxsplit 指定最大分割次数
res = re.split(',','hello,python,haha,hehe') #没有设置次数就默认全部分割
print(res) #['hello', 'python', 'haha', 'hehe']
(7)贪婪与非贪婪
# 1、贪婪匹配(默认):在满足匹配时,匹配尽可能长的字符串
res = re.match('em*','emmmmmm...')
print(res.group()) #emmmmmm
# 2、非贪婪匹配:在满足匹配时,匹配尽可能短的字符串,使用?来表示非贪婪匹配
res = re.match('em*?','emmmmmm...')
print(res.group()) #e
(8)原生字符串
r取消转译。
正则表达式中,匹配字符串中的字符\需要\\,加入原生字符串,\代表\
res = re.match(r'\\\\',r'\\\game')
print(res.group()) #\\
15、模块
(1)os模块
import os
作用:用于和操作系统交互
1、os.name ,指示正在使用的工作平台(返回操作系统类型)
2、os.getenv(环境变量名称) ,读取环境变量
3、os.path.split() ,把目录名和文件名分离,以元组的形式接收,第一个元素是目录路径,第二个元素是文件名
4、os.path.dirname ,显示split分割的第一个元素,即目录
5、os.path.basename ,显示split分割的第二个元素,即文件名
6、os.path.exists() ,判断路径(文件或目录)是否存在,存在的话就返回True,不存在就返回False
7、os.path.isfile() ,判断是否存在文件
8、os.path.isdir() ,判断目录是否存在
9、os.path.abspath() ,获取当前路径下的绝对路径
10、os.path.isabs() ,判断是否是绝对路径
(2)sys模块
导入sys模块:import sys
作用:负责程序跟python解释器交互
1、sys.getdefaultencoding() ,获取系统默认编码格式
2、sys.path ,获取环境变量的路径,跟解释器相关
3、sys.platform ,获取操作系统平台名称
4、sys.version ,获取python解释器的版本信息
(3)time模块
导入time模块: import time
三种时间表示:
1、时间戳(timestamp)
2、格式化的时间字符串(format time)
3、时间元组(strut_time)
1、time.sleep(),延时操作,以秒为单位
2、time.time() ,获取到当前的时间戳:以秒计算,从1970年1月1日 00:00:00开始到现在的时间差
3、time.localtime(),将一个时间戳转换为当前时区的struct_time,九个元素
4、time.asctime(), 获取系统当前时间,把struct_time换成固定的字符串表达式
5、time.ctime() ,获取系统当前时间,把时间戳换成固定的字符串表达式
6、time.strftime(格式化字符串,struct time) ,将struct_time转换成时间字符串
7、time.strptime(时间字符串,格式化字符串),将时间字符串转换成struct_time
(4)logging模块
①导入logging模块:import logging
logging模块作用:用于记录日志信息
②日志的作用
1、程序调试
2、了解软件程序运行情况是否正常
3、软件程序运行故障分析与问题定位
③级别排序(从高到低)
CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTEST
logging.debug("我是debug")
logging.info("我是info")
logging.warning("我是warning")
logging.error("我是error")
logging.critical("我是critical")

logging默认的level就是warning,也就是说Logging只会显示级别大于等于warning的日志信息,如上图结果所示。
④logging.basicConfig() 配置root logger的参数
1、filename:指定日志文件的文件名,所有会显示的日志都会存放到这个文件中去
2、filemode:文件的打开方式,默认是a,追加模式
3、level:指定日志显示级别,默认是警告信息warning
4、format:指定日志信息的输出格式
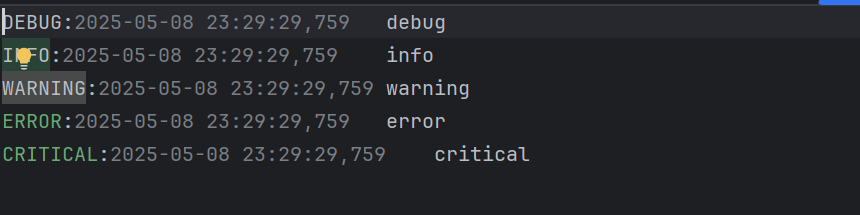
logging.basicConfig(filename = 'log.log',filemode = 'w',level = logging.NOTSET,format = '%(levelname)s:%(asctime)s\t%(message)s')
logging.debug("debug")
logging.info("info")
logging.warning("warning")
logging.error("error")
logging.critical("critical")
log.log文件中
(5)random模块
导入random模块:import random
作用:用于生成各种分布的伪随机数生成器,可以根据不同的实数分布来随机生成值
1、random.random() 产生大于0且小于1之间的小数
2、random.uniform() 产生指定范围的随机小数
3、random.randint() 产生指定范围的随机整数,包括开头和结尾
4、random.randrange(start,stop,[step]) 产生start,stop范围内的随机整数,包含开头,不包含结尾
print(random.random())
print(random.uniform(1,3))
print(random.randint(1,3))
print(random.randrange(2,7,2))

















 6409
6409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









