






论文阅读笔记:BurstSketch: Finding Bursts in Data Streams
这篇文章是杨仝老师课题组发表在2021SIGMOD的检测burst流量的一篇文章,相对于flow size, cardinality, heavy hitter而言,burst属于一种相对较新的应用场景。所谓burst是指一条流在一个固定窗口的出现数量呈现先突然增加后突然减少的状况,本文提出了一种BurstSketch的结构,采用两种技术:Running Track和Snapshotting。数据结构与一些流大小测量的结构比较相似,增加了一个时间窗口的概念,因为本文定义的burst要先经过流数量的一个突然增加,然后突然减少,所以涉及到多个不同的时间窗口。以前也有两篇相关的工作:CM-PBE和TopicSketch。他们对burst的定义要么是流大小的突然增加或者是突然减少,并没有考虑两者同时存在的情况。
Abstract
Burst是数据流中的一种常见模式,其特征是到达率(arrival rate)突然增加,然后突然下降。Burst detection已经引起了研究界的广泛关注。在本文中,我们提出了一种新的sketch,即BurstSketch,以准确地实时检测butst。BurstSketch首先使用Running Track技术高效地选择潜在bursts项目,然后使用snapshotting技术对潜在burst项目进行监控并捕捉burst模式的关键特征。实验结果表明,我们的sketch的召回率(recall rate) 比strawman方案高1.75倍。
1. 背景和动机
定义:
Burst: 是数据流中的一种常见模式,其特点是到达率突然增加,然后突然下降。
The arrival rate of an itme: 是指该项目在固定时间窗口内出现的次数。
a sudden increase: 在两个相邻的时间窗口,项目e在第二个时间窗口的到达率不小于在第一个时间窗口到达率的k倍。
a sudden decrease: 项目e在第二个时间窗口的到达率不多于第一个时间窗口到达率的1/k。
burst threshold: 一个burst项目的到达率因该超过a burst threshold。
the width of a burst: burst所持续的时间窗口数量。
sudden-increase window: 如果一个burst的宽度是 j-i windows,那么window w i + 1 w_{i+1} wi+1 是sudden-increase window。
sudden-decrease window: 如果一个burst的宽度是 j-i windows,那么window w j + 1 w_{j+1} wj+1 是sudden-decrease window。
a high-speed item: 一个时间序列数据流𝑆被分成多个大小相等的时间窗口𝑤1,𝑤2,𝑤3…高速项目是指在一个时间窗口内出现频率超过预定义阈值的项目
bursts inside bursts: 定义类似于括号匹配,左括号对应突然增加,右括号对应突然减少。
fastest item: 一个项目的到达率是最快的。
实时burst检测挑战性:
实时突发检测具有挑战性,因为我们需要在保持准确性的同时赶上高速(例如每秒1.5M个项目)的数据流。为了实现高速,在处理项时只访问CPU缓存是理想的,这要求数据结构足够小,可以保存在缓存中。
本文设计目标:利用有限的内存实时准确地检测bursts。
两篇相关工作:第一篇检测burst事件的是CM-PBE,其中burst定义是项目的突然增加。第二篇是TopicSketch。在这两篇中,burst的定义只能检测到突然的增加,而不能检测到突然的减少
我们提出方案:BurstSketch,有3个特性:memory efficient, accurate, fast。
数据结构:由两部分组成,Stage1和Stage2,用到两个技术Running Track和Snapshotting。对于每个传入的项目,我们首先检查它是否是阶段1中的潜在burst item,如果是,则将其发送到阶段2。在阶段1和阶段2中使用的技术分别被称为Running Track和Snapshotting。
技术一:Running Track: 用于选择潜在的突发项目(burst item)。它需要过滤掉不经常出现的项目(infrequent items)以及以稳定的速度到达的项目。Running Track的工作原理如下:我们使用许多tracks,每个项目将通过散列函数映射到d个tracks(类似于一个bucket)。对于每个track,我们只观察最频繁的项目。如果它足够频繁,我们认为它是一个潜在的突发项目(potential burst item)。为了在每个track中找到最快的项目(fastest item),有几种可选策略:frequent[8],probabilistic decay[9],probabilistic replacement[10]。我们选择frequent方法,因为它是最简单和最快的,与其他方法相比,它具有相对的准确性。在我们的策略中,高速项目不太可能在每个track中被过滤掉,因为只要它在至少一个track中成为最频繁的项目,它就会被选中。
技术二:Snapshotting:Snapshotting用于从潜在的突发(potential burst)中检测突发(bursts)。Snapshotting的基本原理是,burst只能用到达率的突然增加和突然减少来描述。因此,我们不需要在每个时间窗口中记录项目的频率。在Snapshotting中,我们只对突然增加和突然减少拍摄两个快照(snapshots),以便我们确认是否为burst。Snapshotting检测突发使用𝑂(1)内存。
2. BurstSketch算法设计
基本原理:BurstSketch包括两个阶段。为了避免记录不必要的信息,第一阶段检查传入的项目是否是潜在的突发项目(potential burst item)。我们只会把潜在项目送到第二阶段进行burst检测。为了检测burst,Stage 2并不记录每个项目𝐿+ 2个时间窗口的频率,而是只记录潜在突发项目相邻的2个时间窗口的频率,以检测是否存在突然增加或突然减少,并使用时间戳对其进行快照(snapshot)。总之,与稻草人解决方案(strawman solution)相比,我们的BurstSketch过滤掉了更多不必要的信息。
数据结构:第一层使用Running Track过滤低到达率项目,第二级别使用Snapshotting去找burst模式。
C
p
r
e
C_{pre}
Cpre 记录以前以前时间窗口项目频率,
C
c
u
r
C_{cur}
Ccur 记录现在时间窗口项目频率。timestamp记录最近一次突然增加发生的时间窗口。如果时间戳等于0,意味着没有突然增加发生。
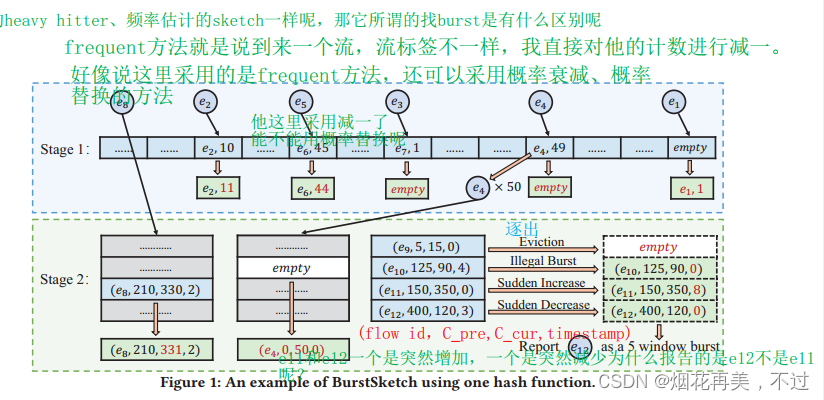
涉及到3个操作:插入、检测和清理政策。

检测:阶段2使用Snapshotting捕捉每个项目的突然增加和突然减少,并在每个时间窗口结束时报告bursts。对于项目𝑒,假设burst的最大宽度为𝐿。首先,我们检测是否有突然增加或突然减少:我们检查𝑒在最近两个时间窗口的频率。如果 e . C c u r e . C p r e ≥ 2 \frac{e.C_{cur}}{e.C_{pre}} \geq 2 e.Cpree.Ccur≥2 时,突然增加发生。然后我们将当前时间窗口更新为𝑡。特别地,如果𝑒已经插入到当前时间窗口的第二阶段(这意味着我们不知道 e . C p r e e.C_{pre} e.Cpre ),我们把 e . C p r e e.C_{pre} e.Cpre 视为0。如果 e . C c u r e . C p r e ≤ 1 2 \frac{e.C_{cur}}{e.C_{pre}} \leq \frac{1}{2} e.Cpree.Ccur≤21 ,一个突然减少发生。然后我们检查是否有突然的增加,以及𝑡与当前时间窗口之间的差异是否不超过𝐿。如果是这样,则BurstSketch报告一个burst,其中𝑡为其突然增加窗口,当前时间窗口为其突然减少窗口,然后我们清理 e . t e.t e.t 到0。否则,没有burst被报告,𝑡保持不变。
BurstSketch还可以应用于找high-speed items。
3. 实验结果
数据集: IP Trace Dataset、Web Page Dataset、 Network Dataset。
指标:Recall Rate (RR)、Precision Rate (PR)、F1 Score、Throughput
对比实验:在burst检测,比较了CM-PBE-1和TopicSketch。在找high-speed items,比较了HeavyGuardian和Space-Saving。
总结:高速数据流中的实时burst检测在许多应用中都很重要。本文提出了一种快速、高效、准确的实时突发检测算法——BurstSketch。实验结果表明,BurstSketch在实时突发检测(real-time burst detection)和寻找高速项目(finding high-speed items)时,可以在相当有限的内存使用量下达到较高的准确率。
4. 总结
本文的优点:
- burst的应用场景是比较新的,以前的相关工作较少,所以对burst检测的数据结构优化比较少,所以是一个可以深挖的方向。
- 提出了两种技术:Running Track和Snapshotting。BurstSketch首先使用Running Track技术高效地选择潜在突发项目,然后使用Snapshotting技术对潜在突发项目进行监控并捕捉突发模式的关键特征。
感觉可能存在的问题:
- 我觉得这个结构和很多heavy hitter检测的结构有些相似,两层结构,第一层插入超过阈值插到第二层,第二层也会发生剔除效应,只是增加了多个时间窗口,多了两个计数器分别记录上一次突然增加的时间窗口和现在的时间窗口。
- 数学分析会不会有些少呢,因为以前看的杨老师组其他论文的数学分析篇幅都不短。
本文的创新点:
首先是定义创新,定义新问题、新的应用场景。这篇文章和以前的burst检测文章的burst定义不一样,这篇文章的burst定义是数据流大小先突然增加再突然减少。
我觉得第二级别桶里面计数器的设置比较好,(flow_id, C_pre, C_cur, timestamp),这个是有效检测项目的在不同时间窗口先突然增加再突然减少的核心。
启发
第一,有能力的话也可以定义一些新定义、新问题和新场景,对经常使用的数据结构进行优化以适应新问题、新场景。burst检测方向可以多看看。
第二,加入时间窗口、时间戳,分析动态时间窗口的变化数据流的变化情况可以研究一下。或者滑动窗口机制。
第三,有关burst检测 和 滑动窗口流检测的相关方向我觉得可以看看。但滑动窗口的定义什么的感觉有点绕,以及实现可能有点不太好搞。
第四,过滤器 + bucket cell的数据结构可以再好好看看。
第五,看实验部分,要注重一下看数据量的规模有多大,是几兆。一分钟caida数据量大概是3600万个,那一秒钟就是60万个,即0.6M数据。1k=1000,1M=1000000(100万)。那一分钟caida数据集就是36M。因为数据量和存储空间是相关的,如果他采用大的数据量,那实验结果图内存使用也大些那是正常的,如果它采用的是小规模数据量,那实验结果内存使用也应该小一些。一般内存使用要在多少kb?
第六,实验部分,吞吐量大小的单位是Mips,即每秒多少兆,吞吐量含义即每秒能处理多少兆的数据。一般吞吐量在20M比较优秀。
它采用的是小规模数据量,那实验结果内存使用也应该小一些。一般内存使用要在多少kb?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









