







资源来自:doit教育
1 大数据概述
1.1 简介
随着互联网的不断发展,世界上产生的数据正在以指数级增长,已经增长到了TB,PB甚至EB级别,比如百度搜索多易教育,就能搜索到近亿的词条,如果服务器使用常规手段进行数据的搜索,那么如此庞大的数据量会消耗大量的时间,给用户带来不好的使用体验。在这样的需求背景下,大数据应运而生。
大数据,指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据主要解决海量数据的采集,存储和分析运算。我们要学的hadoop生态,主要解决,海量数据的存储和海量数据的分析计算问题。
计算机描述数据大小的单位如下:
按顺序给出数据存储单位: bit、Byte.KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB。
1Byte = 8bit
lK=1024Byte
1MB=1024K
1G=1024M
1T= 1024G
1P= 1024T
- 海量数据的存储
- 海量数据的处理运算
1.2 大数据特征
一、Volume:容量
大 数据的采集,计算,存储量都非常的庞大。
二、Variety:种类
多 种类和来源多样化。种类有:结构化、半结构化和非结构化数据等,常见的来源有:网络日志、音频、视频、图片等等。
三、Value:价值
值 数据价值密度相对较低,犹如浪里淘金,百炼成钢般才能获取到大量信息中的部分有价值的信息
四、Velocity:速度
快 数据增长速度快,处理速度也快,获取数据的速度也要快。

五、Veracity:真实性
信 数据的准确性和可信赖度,即数据的质量。
六、复杂性(Complexity):数据量巨大,来源多渠道。
1.3 大数据应用场景
-
猜你喜欢
比如你在逛B站或者抖音等短视频软件时,给你推荐的视频都是你浏览过或者搜索过相关的视频(所以不要再问这个视频为什么出现在你的首页了)
-
广告推荐
当你打开购物网站,买了一个两万块钱的电脑,这时网站可能会给你推荐一个键盘,一个鼠标等等,都是根据你的行为数据进行推算得出的。
-
线下销售
如果你听过啤酒和纸尿布的故事,一定会对这个应用感到豁然开朗,美国的沃尔玛超市通过对购物数据的收集和分析得出,当一个男人去购买纸尿布时,通常会买几罐啤酒,所以将纸尿布和啤酒放在一起售卖使得两者的销售额都上升了。这不就是收集了你的购物信息,进行数据分析后再做出对应的决策吗?
-
物流
根据订单信息确定仓库位置,能够最快的给客户送货。
-
金融
如今金融和大数据结合也是一个很热门的方向,通过多维度分析用户特征,帮助金融机构推荐优质客户,防范欺诈风险。
1.4 hadoop介绍
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
Hadoop软件库是一个框架,该框架允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。库本身不是设计用来依靠硬件来提供高可用性,而是旨在检测和处理应用程序层的故障,因此可以在计算机集群的顶部提供高可用性的服务,而每台计算机都容易出现故障。
它解決了两大问题:大数据存储、大数据分析。也就是 Hadoop 的两大核心:HDFS 和 MapReduce。
1.4.1 hadoop起源
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
Hadoop的成长过程
Lucene–>Nutch—>Hadoop
总结起来,Hadoop起源于Google的三大论文
GFS:Google的分布式文件系统Google File System
MapReduce:Google的MapReduce开源分布式并行计算框架
BigTable:一个大型的分布式数据库
演变关系
GFS—->HDFS
Google MapReduce—->Hadoop MapReduce
BigTable—->HBase
1.4.2 hadoop的优点
- 扩容能力(Scalable):Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计个节点(机器)中。
- 成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
- 高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
- 可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
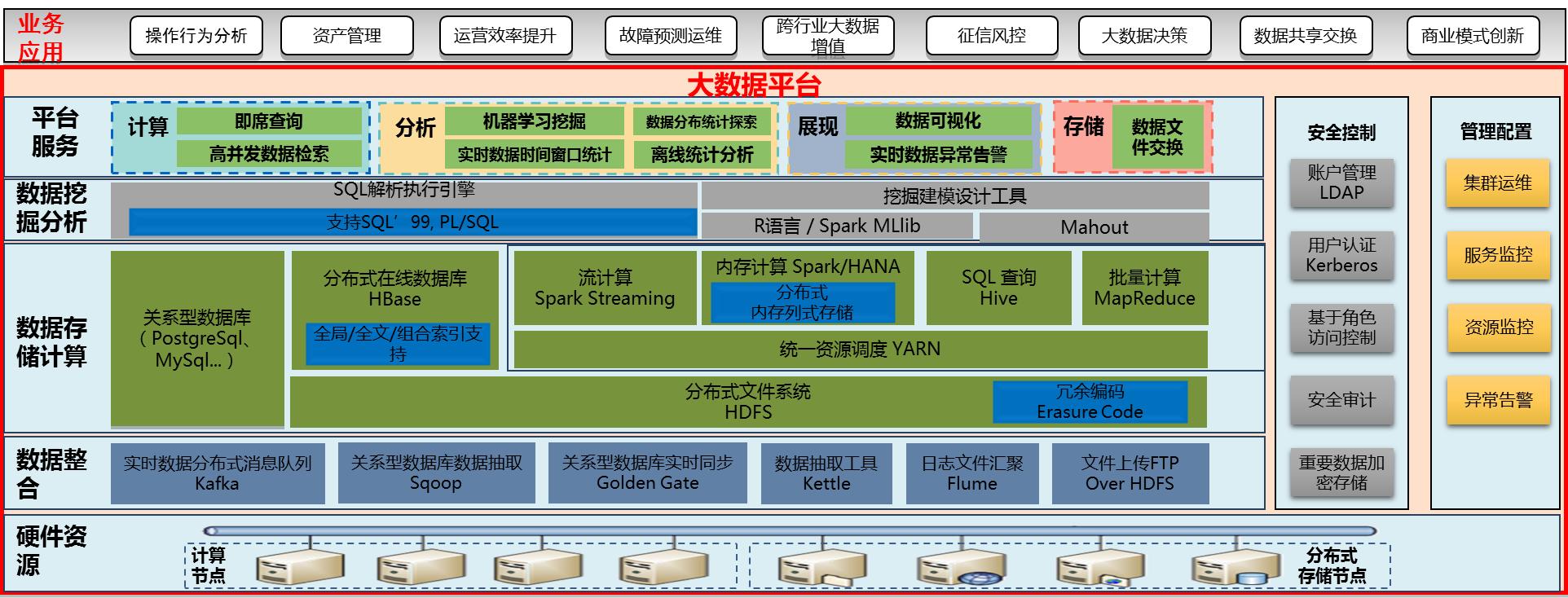
1.4.3 hadoop组件
在Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大,在Hadoop2.x时代,增加了Yan。Yarn只负责资源的调度,MapReduce只负责运算。
-
HDFS 分布式文件系统 海量数据的存储
-
MapReduce 海量数据的分析计算
-
Yarn 资源调度
-
Commons (辅助工具)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EHfwRbNi-1626077526283)(https://gitee.com/dun-chengliang/cloudimages/raw/master/img/20210708230020.png)]
- hadoop 组件 hdfs mapreduce yarn commons
- 优点 廉价 易扩容 高效 可靠
- 大数据 应用到各行各业
2 HDFS概述
2.1 HDFS背景及定义
分布式文件系统利用集群中的多台机器存储海量数据
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS 只是分布式文件管理系统中的一种。
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务 器有各自的角色。 HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变
思考: 分布式文件系统设计的核心要点??
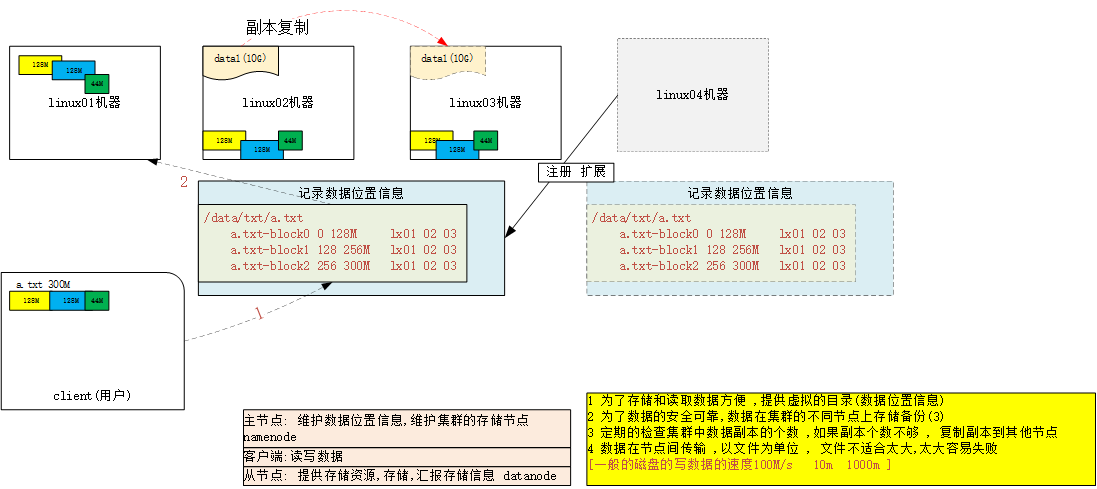
1 架构上, 主从架构,一主多从
2 主节点维护和管理整个集群
3 从节点向主节点注册 , 方便扩容
4 客户端向主节点请求读写
5 存储数据 ,分配存储节点, 主节点记录数据存储位置信息(元数据)
6 读区数据, 主节点维护虚拟目录 ,获取数据位置信息 , 获取数据
7 为了维护数据可靠性 ,数据在集群中存储3个副本
8 集群维护副本的个数 , 数据块的移动
9 数据在集群中切块存储 [物理切块 128M]
2.2 HDFS 优缺点
2.2.1 优点:
-
高容错性
数据自动保存多个副本。它通过增加副本的形式,提高容错性。某一个副本丢失以后,它可以自动恢复。
-
适合处理大数据
数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据;
文件规模:能够处理百万规模以上的文件数量,数量相当之大。
-
可构建在廉价机器上,通过多副本机制,提高可靠性。
-
易扩容
2.2.2 缺点:
-
不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
-
无法高效的对大量小文件进行存储。
存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和 块信息。这样是不可取的,因为NameNode的内存总是有限的;
小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
-
不支持并发写入、文件随机修改。IO
一个文件只能有一个写,不允许多个线程同时写;
仅支持数据append(追加),不支持文件的随机修改。
IO
可以随机读取数据 skip
不能随机修改数据
不能并发写
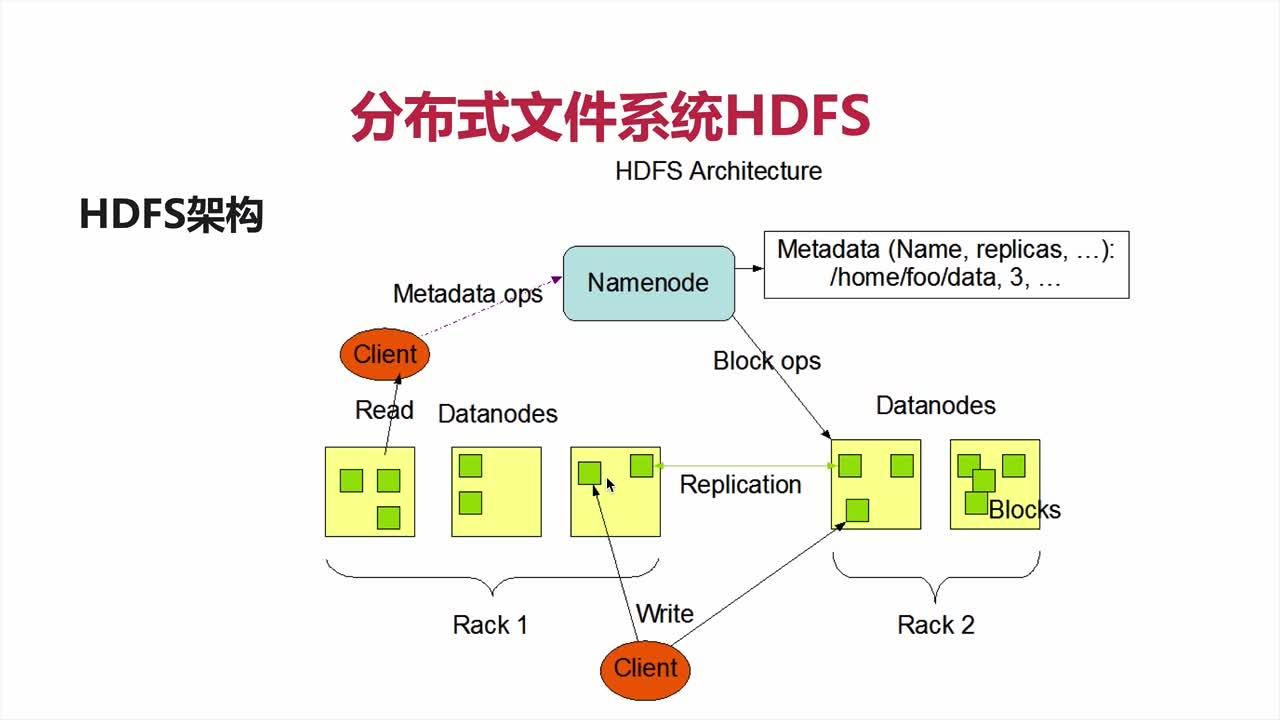
2.3 HDFS组成结构
-
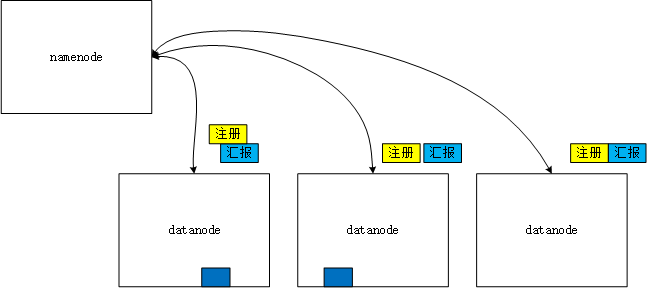
NameNode(nn):就是Master,它 是一个主管、管理者。
(1)管理HDFS的名称空间,HDFS分布式文件系统的位置
(2)配置副本策略;
(3)管理数据块(Block)映射信息 元数据;
(4)处理客户端读写请求。
(5) 接受datanode的注册和汇报 , 维护集群
-
DataNode:就是Slave(workers)。NameNode 下达命令,DataNode执行实际的操作。
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
(3) 汇报自己的节点的存储信息
(4) 执行副本复制任务
-
Client:就是客户端。
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如NameNode格式化;
(5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作;
-
Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不 能马上替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode ;
(2)在紧急情况下,可辅助恢复NameNode。
1.4 HDFS文件块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数 ( dfs.blocksize)来规定,默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。
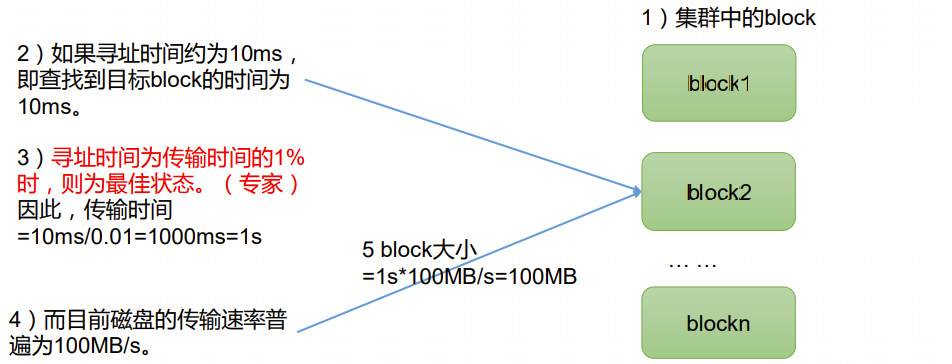
所以,Block块不能太大也不能太小,原因如下:
(1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
(2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开 始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘传输速率。
3 HDFS实操
3.1 安装
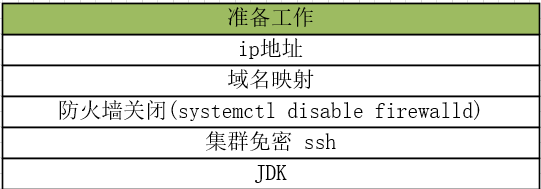
3.1.1 基础环境搭建

3.1.2 上传解压
3.1.3 hadoop目录介绍
drwxr-xr-x. 2 zss 1001 183 Aug 2 2018 bin 系统一些基本操作的命令
drwxr-xr-x. 3 zss 1001 20 Aug 2 2018 etc 配置文件的目录
drwxr-xr-x. 2 zss 1001 106 Aug 2 2018 include
drwxr-xr-x. 3 zss 1001 20 Aug 2 2018 lib
drwxr-xr-x. 4 zss 1001 288 Aug 2 2018 libexec
-rw-r--r--. 1 zss 1001 147144 Jul 28 2018 LICENSE.txt
-rw-r--r--. 1 zss 1001 21867 Jul 28 2018 NOTICE.txt
-rw-r--r--. 1 zss 1001 1366 Jul 28 2018 README.txt
drwxr-xr-x. 3 zss 1001 4096 Aug 2 2018 sbin 集群角色启停有关
drwxr-xr-x. 4 zss 1001 31 Aug 2 2018 share 帮助文档和jar包
3.1.4 修改配置文件
# 1 JAVA_HOME的位置 hadoop-env.sh
export JAVA_HOME=/opt/apps/jdk1.8.0_141
# 2 namenode机器的位置 vi etc/hadoop/hdfs-site.xml
<!-- 集群的namenode的位置 datanode能通过这个地址注册-->
<property>
<name>dfs.namenode.rpc-address</name>
<value>linux01:8020</value>
</property>
<!-- namenode存储元数据的位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hdpdata/name</value>
</property>
<!-- datanode存储数据的位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hdpdata/data</value>
</property>
<!-- secondary namenode机器的位置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>linux02:50090</value>
</property>
3.1.5 分发
scp -r hadoop-3.1.1 linux02:$PWD
scp -r hadoop-3.1.1 linux03:$PWD
3.1.6 初始化namenode
注意:只在namenode角色的节点上初始化
bin/hadoop namenode -format
3.1.7 单节点启动
- 先启动namenode – 在linux01
[root@linux01 sbin]# ./hadoop-daemon.sh start namenode
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
[root@linux01 sbin]# jps
2706 Jps
2638 NameNode
--------------------------------------------------------------------------------------------
访问: http://linux01:9870 9870 http协议的web页面的UI
- 先启动datanode
[root@linux02 sbin]# ./hadoop-daemon.sh start datanode
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
WARNING: /opt/apps/hadoop-3.1.1/logs does not exist. Creating.
[root@linux02 sbin]# jps
2418 DataNode
2450 Jps

演示HDFS集群动态扩容
思考 : 如果克隆linux01 --> linux04
1) ip
2) 域名映射 + 192.168.133.6 linux04
3) 主机名
4) 免密 配置
5) 删除hdpdata 每个datanode都有一个唯一的标识
3.1.8 一键启动/停止
- 在linux01上配置workers节点
vi workers
linux01
linux02
linux03
- 启动脚本/停止脚本中添加如下配置
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
3.1.9 系统环境变量配置
export JAVA_HOME=/opt/apps/jdk1.8.0_141
export HADOOP_HOME=/opt/apps/hadoop-3.1.1
export PATH=$PATH:$JAVA_HOME:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
source /etc/profile
sbin/start-dfs.sh
sbin/stop-dfs.sh
3.2 Shell客户端
所执行的客户端命令在 bin目录下
hadoop fs 一般不使用
hdfs dfs 命令操作
hdfs dfs -ls / 查看本地文件系统 [默认操作的是本地文件系统]
hdfs dfs -ls hdfs://linux01:8020/ 查看分布式文件系统/内容
hdfs dfs -mkdir -p hdfs://linux01:8020/aa/bb/cc 在分布式文件系统中创建文件夹 层级
hdfs dfs -put ./x.txt hdfs://linux01:8020/aa/ 上传本地文件到布式文件系统
页面查看hdfs文件系统
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4pu2ilA2-1626077526296)(img/image-20210620160351166.png)]
3.2.1 修改默认的文件系统
vi core-site.xml 不需要重新启动集群
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux01:8020</value>
</property>
默认配置文件参数:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
3.2.2 shell CMD
hadoop fs 和 hdfs dfs开启分布式文件系统的shell客户端
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] 修改权限
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]] 查看磁盘大小
[-du [-s] [-h] [-v] [-x] <path> ...] 文件/文件夹
[-expunge]
[-find <path> ... <expression> ...] 查找
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] 下载
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]] 列表
[-mkdir [-p] <path> ...] 创建文件夹
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>] 移动 / 重命名
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>] 上传
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...] 删除
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>] 最后几行内容
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
hdfs dfs -CMD -args
3.2.2.1 上传
hdfs dfs -put 本地路径 /HDFS路径
hdfs dfs -put x.txt /a.txt 上传+修改名称
3.2.2.2 下载
hdfs dfs -get /HDFS系统 /本地路径
3.2.2.3 创建文件夹
hdfs dfs -mkdir -p 创建层级文件夹
hdfs dfs -mkdir /x /y /z 同时创建多个文件夹
3.2.2.4 移动/重命名
hdfs dfs -mv /x /a/
hdfs dfs -mv /y /yy
3.2.2.5 删除
[root@linux01 /]# hdfs dfs -rm /a.txt 文件
Deleted /a.txt
[root@linux01 /]# hdfs dfs -rm -r /a 文件夹 -r递归
Deleted /a
hdfs dfs -rm -r hdfs://linux01:8020/* 必须
3.2.2.6 查看列表
hdfs dfs -ls
3.2.2.7 系统存储资源
[root@linux01 /]# hdfs dfs -df -h
Filesystem Size Used Available Use%
hdfs://linux01:8020 51.0 G 75.8 K 44.4 G 0%
3.2.2.8 文件夹大小
hdfs dfs -du -h /jdk1.8.0_141
3.2.2.9 修改权限
当需要在页面上删除文件 文件夹 修改权限
hdfs dfs -chmod -R 777 /jdk1.8.0_141
3.2.2.10 tail
hdfs dfs -tail -f /a.txt 监控
hdfs dfs -tail /a.txt 直接查看
3.3 maven简单使用
maven是一个项目管理工具
-
创建项目
-
管理项目jar包的依赖
-
打包 (测试,报告,打包,部署[生命周期])
-
统一开发环境
基本使用
1 加压 maven.zip文件
2 在指定的盼复下创建文件夹 d://my_maven/repository
3 将setiings.xml放在 d://my_maven/目录下
4 修改setiings.xml文件的第55行
<localRepository>D:\my_maven\repository</localRepository>
5 打开idea
setting->Build->maven
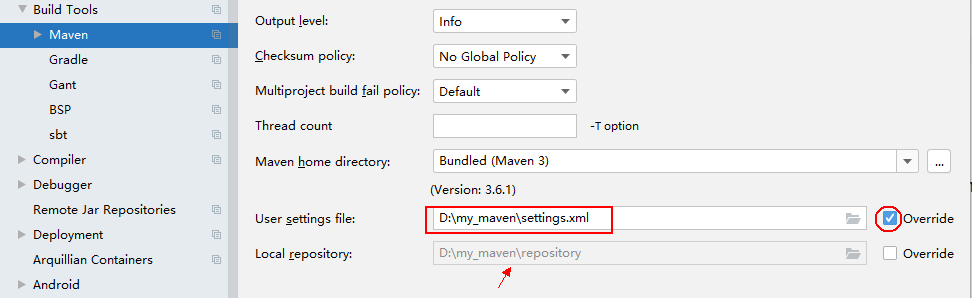
创建项目
注意GAV坐标
<!--当前项目的坐标 , 根据这个坐标定位唯一的一个程序-->
<groupId>com._51doit</groupId>
<artifactId>Doit24_Hadoop</artifactId>
<version>1.0</version>
3.4 Java-API
操作HDFS, 添加jar包 : 添加依赖
<!--添加项目的依赖-->
<dependencies>
<!--hadoop工具依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
<!--HDFS-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.1</version>
</dependency>
<!--MR-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.1</version>
</dependency>
<!--MR的工具-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.1.1</version>
</dependency>
<!--和磁盘交互-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.1.1</version>
</dependency>
<!--json解析-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
</dependencies>
3.4.1 HDFS入门-创建层级文件夹
/**
* Author: Hang.Z
* Date: 21/06/21
* Description:
* 使用java 操作远程的 HDFS 系统
*/
public class HdfsDemo1 {
public static void main(String[] args) throws Exception {
//1 获取操作HDFS的客户端 URI jdbc:mysql://linux01:3306/default hdfs://linux01:8020
// url:http://linux01:8080/day01/
URI uri = new URI("hdfs://linux01:8020");
Configuration conf = new Configuration();
/**
* FileSystem的构造器被保护 ,不能new ,调用静态方法
* 参数一 HDFS 系统的位置
* 参数二 配置对象(默认参数 副本个数3 物理切块128M) 自己设置参数
* 参数三 提供操作HDFS的用户名
*
*/
FileSystem fs = FileSystem.newInstance(uri, conf, "root");
//2 操作
/**
* 创建文件夹 , 在HDFS中使用Path代理原来的File
*/
// boolean b = fs.mkdirs(new Path("/day02"));
// 可以直接创建层级文件夹
boolean b = fs.mkdirs(new Path("/day01/hdp/hdfs"));
System.out.println(b);
//3 释放资源
fs.close();
}
}
3.4.2 工具类
/**
* Author: Hang.Z
* Date: 21/06/21
* Description:
*/
public class DoitUtil {
/**
* 获取分布式文件系统客户端对象 FileSystem
*/
public static FileSystem getFs() throws Exception {
Configuration conf = new Configuration();
URI uri = new URI("hdfs://linux01:8020");
String userName = "root" ;
FileSystem fs = FileSystem.newInstance(uri, conf, userName);
return fs ;
}
}
3.4.3 HDFS-API-上传
/**
* Author: Hang.Z
* Date: 21/06/21
* Description:
* 注意: HDFS集群是开启的
* 上传本地数据到集群上
*/
public class UpLoad {
public static void main(String[] args)throws Exception {
FileSystem fs = DoitUtil.getFs();
/**
* 参数一 本地路径
* 参数二 HDFS路径
*/
// fs.copyFromLocalFile(new Path("E:\\软件\\spark-3.0.0-bin-hadoop3.2.tgz"),new Path("/hdp.tgz"));
/**
* 参数一 是否删除上传的文件
* 参数二 如果HDFS存储这个文件 是否删除
* 参数三 本地路径 (可以是一个数组:同时上传多个文件)
* 参数四 HDFS路径
*
*/
fs.copyFromLocalFile(true , false,new Path("E:\\软件\\spark-3.0.0-bin-hadoop3.2.tgz"),new Path("/hdp2.tgz"));
fs.close();
}
}
3.4.4 HDFS-API-下载
注意:将HDFS的文件下载到本地的时候会在本地进行校验! 需要本地系统有hdp的环境
解压
配置
/**
* Author: Hang.Z
* Date: 21/06/21
* Description:
* 将HDFS上的文件下载到本地
*/
public class DownLoad {
public static void main(String[] args) throws Exception {
FileSystem fs = DoitUtil.getFs();
/**
* 参数一 HDFS的路径
* 参数二
* 将数据下载到本地 在本地生成一个校验文件 .hdp.tgz.crc [隐藏]
*/
// fs.copyToLocalFile(new Path("/hdp.tgz") , new Path("d://"));
/**
* 参数一 是否删除源文件
* 参数二 HDFS的路径
* 参数三 本地路径
* 参数四 是否在本地生成一个校验文件 默认fasle 生成
* true
*/
fs.copyToLocalFile(false ,
new Path("/hdp.tgz") ,
new Path("d://") ,
true);
fs.close();
}
}
3.4.5 HDFS-API-删除
public class DeleteDemo {
public static void main(String[] args)throws Exception {
FileSystem fs = DoitUtil.getFs();
// 判断文件文件夹存在
Path path = new Path("/hdp.tgz");
if(fs.exists(path)){
// 递归删除数据
boolean b = fs.delete(path, true);
if(b){
System.out.println("成功");
}
}else{
System.out.println("路径不存在");
}
fs.close();
}
}
3.4.6 HDFS-API-移动/重命名
public class MvDemo {
public static void main(String[] args)throws Exception {
FileSystem fs = DoitUtil.getFs();
// 判断文件文件夹存在
Path path1 = new Path("/a.tgz");
Path path2 = new Path("/day01/");
// 修改名称 移动
fs.rename(path1,path2) ;
fs.close();
}
}
3.4.6 HDFS-API-List
代码一
public class ListDemo1 {
public static void main(String[] args)throws Exception {
FileSystem fs = DoitUtil.getFs();
Path path = new Path("/");
// /下的所有的文件以及子文件夹下的文件
RemoteIterator<LocatedFileStatus> iterator = fs.listFiles(path, true);
// 遍历每个文件
while(iterator.hasNext()){
//具体的文件对象
LocatedFileStatus next = iterator.next();
Path p = next.getPath();
String name = p.getName();
long len = next.getLen();
short replication = next.getReplication();
long blockSize = next.getBlockSize();
long accessTime = next.getAccessTime();
System.out.println(p+"--"+name);
}
fs.close();
}
}
代码二
public class ListDemo2 {
public static void main(String[] args)throws Exception {
FileSystem fs = DoitUtil.getFs();
Path path = new Path("/");
// /下的所有的文件以及子文件夹下的文件
RemoteIterator<LocatedFileStatus> iterator = fs.listFiles(path, true);
// 遍历每个文件
while(iterator.hasNext()){
//具体的文件对象
LocatedFileStatus file = iterator.next();
// 获取文件的元数据信息 数据在HDFS上存储的信息
// a.tgz 214M 2物理切块 128M 3副本 机器
String name = file.getPath().getName();
if("a.tgz".equals(name)){
// 获取文件的元数据信息 数据在HDFS上存储的信息
// 文件物理切块的信息
BlockLocation[] bls = file.getBlockLocations();
// 遍历数据块
for (BlockLocation dataBlock : bls) { // 2 物理切块
String[] hosts = dataBlock.getHosts();
// 将数组转成List集合 方便查看内容
List<String> list = Arrays.asList(hosts);
System.out.println(hosts.length); // 3
// 数据块所在的位置
System.out.println(list);
}
}
}
fs.close();
}
}
代码三
public class ListDemo3 {
public static void main(String[] args)throws Exception {
FileSystem fs = DoitUtil.getFs();
Path path = new Path("/");
// 遍历文件夹和文件夹
FileStatus[] fileStatuses = fs.listStatus(path);
for (FileStatus fileStatus : fileStatuses) {
boolean b = fileStatus.isFile();
if(!b){
Path path1 = fileStatus.getPath();
System.out.println(path1);
}
}
fs.close();
}
}
3.4.6 HDFS-API-读取文件内容
在HDFS中存储的数据就是以文件为单位 , HDFS 的应用场景适合一次存储多次读取!!
/**
* Author: Hang.Z
* Date: 21/06/21
* Description:
* 获取输入流加载数据
* seek skip可以随机读数据
*/
public class ReadData {
public static void main(String[] args) throws Exception {
FileSystem fs = DoitUtil.getFs();
Path path = new Path("/a.txt");
FSDataInputStream inputStream = fs.open(path);
//aige
/**
* skip
* seek 一样 跳过指定长度的数据 开始读取数据
* 并且读取的数据可以记录长度 #### ##### #####
* 随机读取
*/
inputStream.skip(1*1024*1024);
int read = inputStream.read();
System.out.println(read);
// 释放连接资源 IO
inputStream.close();
fs.close();
}
}
/**
* Author: Hang.Z
* Date: 21/06/21
* Description:
* 获取输入流加载数据
* 可以使用装饰者模式将获取的输入流进行包装 获取行数据
*/
public class ReadData2 {
public static void main(String[] args) throws Exception {
FileSystem fs = DoitUtil.getFs();
Path path = new Path("/a.txt");
FSDataInputStream inputStream = fs.open(path);
// 需要一行一行的加载内存
/**
* 装饰者模式 静态代理(装饰者模式)
* AA(A(a))
*/
BufferedReader br = new BufferedReader(new InputStreamReader(inputStream));
String line = null;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
inputStream.close();
br.close();
fs.close();
}
}
3.4.6 HDFS-API-写数据
HDFS中的文件不支持并发写,不建议写操作! 不支持随机写,不能修改数据内容 ,非要写,追加写
/**
* Author: Hang.Z
* Date: 21/06/21
* Description:
* hdfs 中写数据 追加写 不能随机改
*/
public class WriteData01 {
public static void main(String[] args) throws Exception {
FileSystem fs = DoitUtil.getFs();
FSDataOutputStream fout = fs.create(new Path("/a.txt"));
fout.writeUTF("hello benge1"+"\n");
fout.writeUTF("hello benge2"+"\n");
fout.writeUTF("hello benge3"+"\n");
fout.close();
fs.close();
}
}
/**
* Author: Hang.Z
* Date: 21/06/21
* Description:
* hdfs 中写数据 追加写 不能随机改
*/
public class WriteData02 {
public static void main(String[] args) throws Exception {
FileSystem fs = DoitUtil.getFs();
FSDataOutputStream fout = fs.append(new Path("/a.txt"));
fout.writeUTF("hello benge4"+"\n");
fout.writeUTF("hello benge5"+"\n");
fout.writeUTF("hello benge6"+"\n");
fout.close();
fs.close();
}
}
4 原理加强
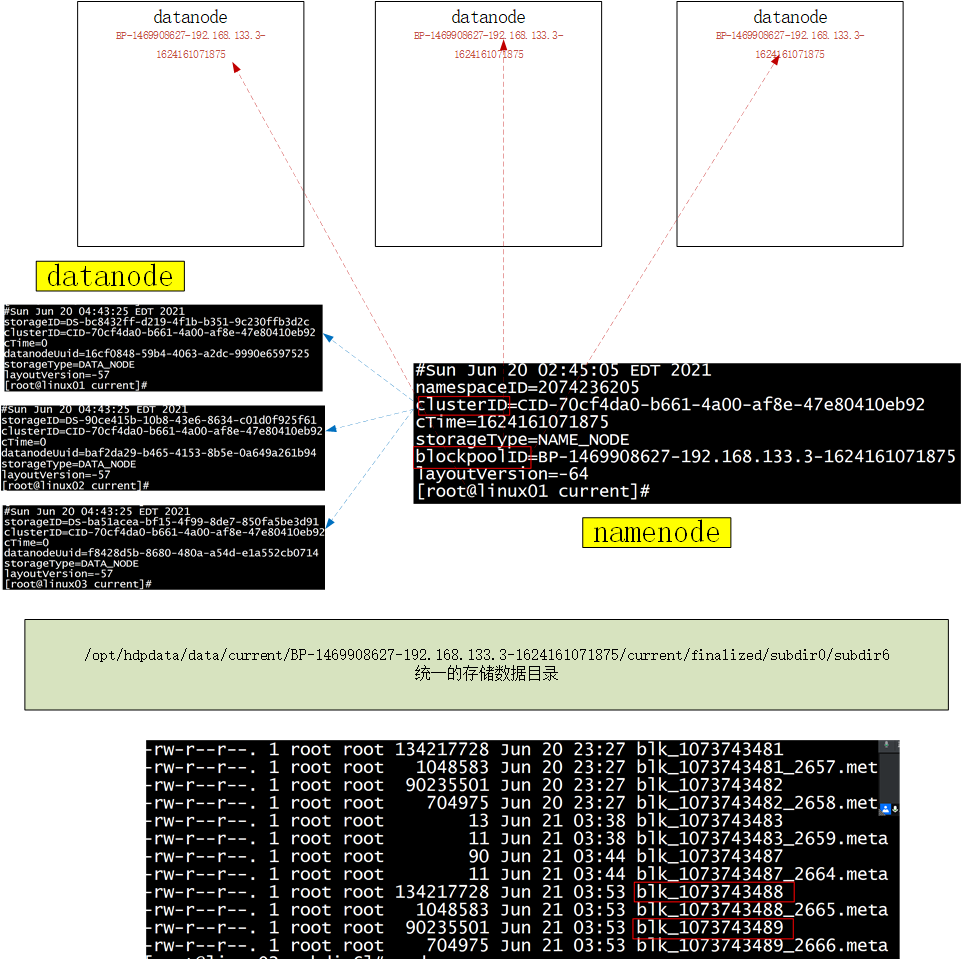
4.1 数据存储位置
在HDFS集群上
-
文件切块存储在不同的机器上(物理块128M)
-
每个物理块在存储副本 3个
-
DataNode节点负责存储数据 数据的位置 /opt/hdpdata/data
-
a.txt 300M block0 << block1 << block2 完整的文件

214M 切成2块 3个副本
4.2 上传数据流程
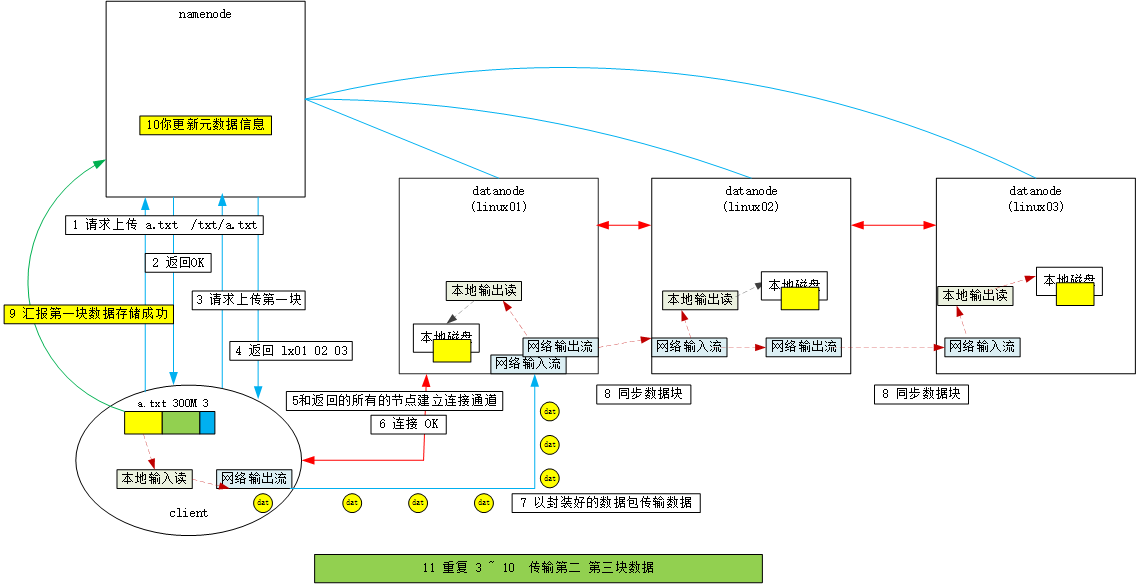
1 客户端请求NN上传文件
2 NN校验 返回OK
3 客户端请求上传第一块数据
4 NN 返回对应的副本个数的主机名
5 客户端和返回的多台节点连接 , 创建连接通道 ,成功以后
6 开始传输第一块数据 ,[机架/带宽]
7 本地流读第一块 , 封装成数据包 ,交给DistributeOutputStream传输数据
8 DN 接受数据 存储在本地的指定目录中
9 同时通道间的数据传输
10 返回OK 更新元数据
11 重复3 ~ 10
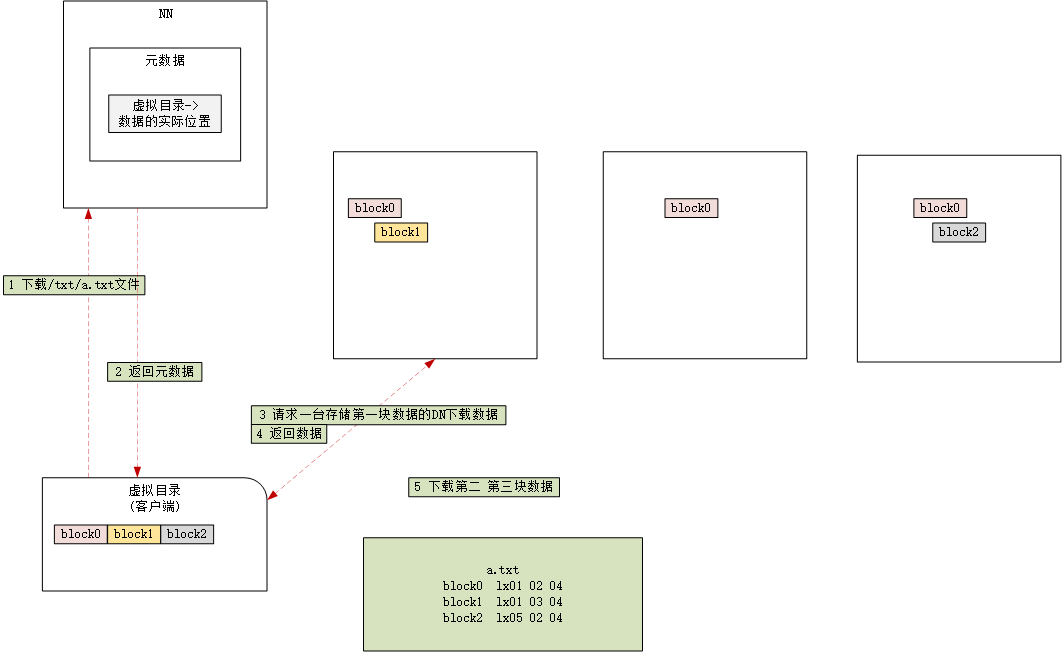
4.3 下载数据
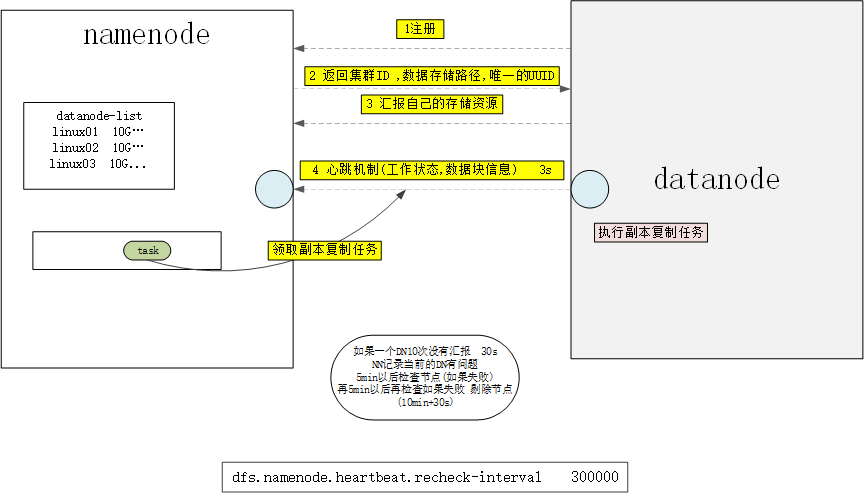
4.4 NN和DN之间的通信
4.5 checkpoint机制
namenode: 记录元数据信息
内存对象中 FsImage / 目录树Tree
元数据只存内存中不安全 , 容易丢失
FsImage à 序列化(10101)到磁盘,如果内存数据丢失,可以反序列化回来数据
FsImage 什么时候进行序列化 , 如果1min序列化一次 , 在这一分钟之内更新的元数据,只在内存中! 宕机 , 这一分钟之内的元数据丢失!
更新一条序列化一次:保证数据不丢失 ,但是FsImage 很大, 会有大量的数据和磁盘交互,占用IO
/opt/hdpdata/name/文件夹下
HDFS分布式文件系统 , 存储海量数据 , 为文件为单位
注意:
HDFS 不能无限扩容<NN内存有限> , HDFS中尽量不要存储小文件,记录元数据
HDFS 中为文件内容适合一次存储多次读取的场景
HDFS 中的文件内容不能随机修改, 不能并发写
HDFS可以追加写操作















 741
741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









