







开发应用程序时,最糟糕的事莫过于程序因UI线程阻塞而挂起了,在iOS系统中,阻塞过久可能会使应用程序终止执行,所幸苹果公司以全新的方式设计了多线程,并且当前多线程的核心就是“块”与“大中枢派发”,“块”是一种可在C、C++及OC代码中使用的“词法闭包”,GCD是一种与块有关的技术,它提供了对线程的抽象,而这种抽象则基于“派发队列”。
块与GCD都是当前OC编程的基石,因此,必须理解其工作原理及功能。
第37条:理解“块”这一概念
块可以实现闭包,并且其是作为“扩展”而加入GCD编译器中的。
1.块的基础知识:
块与函数类似,只不过是直接定义在另一个函数里的,和定义它的那个函数共享同一个范围内的东西。块用“^”符号来表示,后边跟着一对花括号,括号里面是块的实现代码。例如:
^{
//代码
}
块其实就是个值,而且自有其相关类型。与int、float或OC对象一样,也可以把块赋值给变量,然后像使用其他变量那样使用它。**块类型的语法与函数指针近似。**块的结构语法如下:
return_type (^block_name)(parameters)
例如:
int (^addBlock)(int a, int b) = ^(int a, int b){
return a + b;
};
如果使用的话就是:
int add = addBlock(2, 5);
这个类似于函数中套一个函数的感觉,然后你可以在该函数中调用这个block,并且它还能捕获在它声明的范围内的所有变量。
默认情况下,为块所捕获的变量,是不可以在块里修改的,不过,声明变量时可以加上_block修饰符,这样就可以在块内修改了。
例如:
_block NSIntger count = 0;
//下面是一个块
那么这个count值就可以在块中改变了,这也是“内联块”的用法。
如果块所捕获的变量是对象类型,那么就会自动保留它。系统在释放这个块的时候,也会将其一并释放。这就引出了一个于块有关的重要问题。块本身可视为对象。并且块本身也和其他对象一样,有引用计数。
如果将块定义在OC类的实例方法中,那么除了可以访问类的所有实例变量之外,还可以使用self变量。块总能修改实例变量,所以在声明时无需加_block。不过,如果通过读取或写入操作捕获了实例变量,那么也会自动把self变量一并捕获了,因为实例变量是与self所指代的实例关联在一起的。也就是说,只要你在块中调用到了属性值,那么这个块就会捕获这个类本身也就是self。
然而一定要记住:self也是个对象,因而块在捕获它时也会将其保留。如果self所指代的那个对象同时也保留了块,那么这种情况通常就会导致“保留环”。
2.块的内部结构:
块本身也是对象,在存放块对象的内存区域中,首个变量是指向Class对象的指针,该指针叫做isa。其余内存里含有块对象正常运转所需的各种信息。块对象的内存布局:
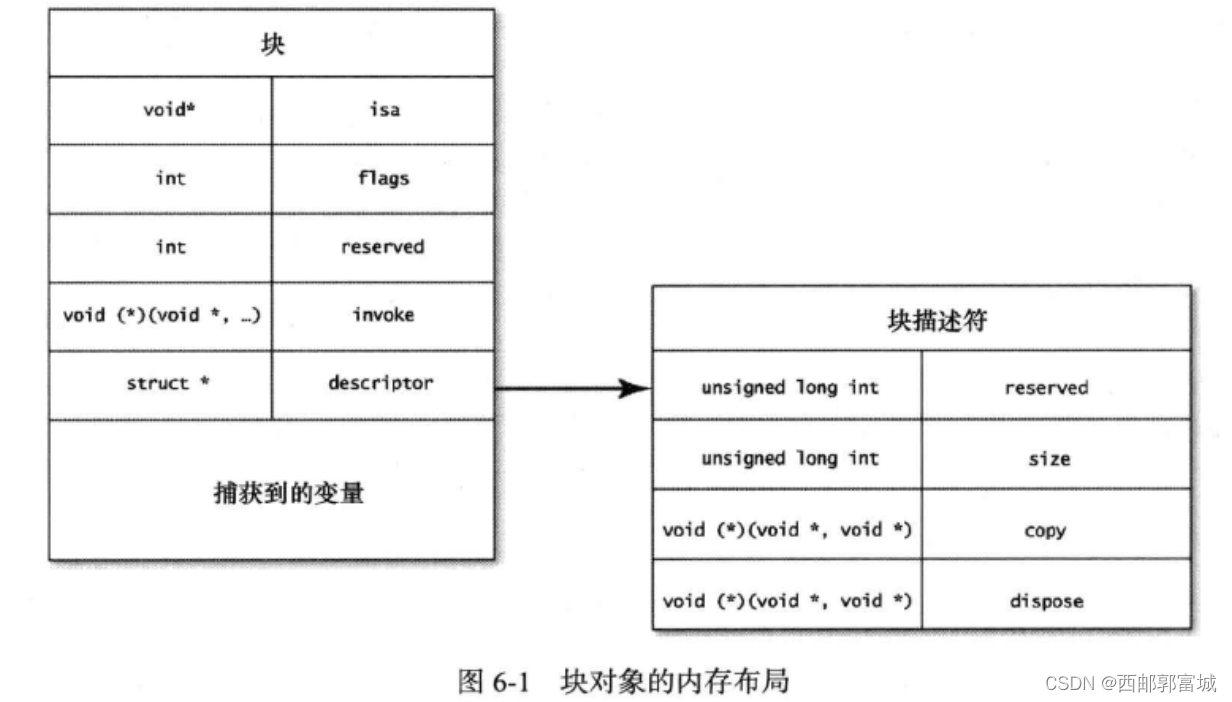
在内存布局中,最重要的就是invoke变量,这是个函数指针,指向块的实现代码。函数原型至少需要接受一个void*型的参数,此参数代表块。
descriptor变量是指向结构体的指针,每个块里都包含此结构体,其中声明里块对象的总体大小,还声明里copy与dispose这两个辅助函数所对应的函数指针。
块还会把它所捕获的所有变量都拷贝一份。这些拷贝放在descriptor变量的后面,捕获了多少个变量,就要占据多少内存空间。请注意,拷贝的并不是对象本身,而是指向这些对象的指针变量。invoke函数为何需要把块对象作为参数传进来呢? 原因就在于,执行块时,要从内存中把这些捕获到的变量读出来。
3.全局块、栈块及堆块:
定义块的时候,其所占的内存区域是分配在栈中的。这就是说,块只在定义它的那个范围内有效。像下面这种代码就可能有危险:

定义在if及else语句中的两个块都分配在栈内存中。编译器会给每个块分配好栈内存,然而等离开了相应的范围后,编译器有可能把分配给块的内存覆写掉。于是,这两个块只能保证在对应的if或else语句范围内有效。这样写出来的代码时而正确,时而错误。若编译器未覆写待执行的块,则程序照常运行,若覆写,则程序崩溃。通俗的说就是,因为你在if条件内定义的块,if执行完了之后可能就会把你的块回收了,然后你再在if条件之外使用就出错了。
为了解决这个问题,我们可以给块对象发送copy消息以拷贝之。这样的话,就可以把块从栈复制到堆了。并且拷贝后的块,可以在定义它的那个范围之外使用。

如果你使用的是手动管理引用计数,那么就记得用外块之后还需将其释放。
除了“栈块”和“堆块”之外,还有一类块叫做“全局块”。这种块不会捕捉任何状态(比如外围的变量),运行时也无须有状态来参与。块所使用的整个内存区域,在编译期已经完全确定了,因此,全局块可以声明在全局内存里,而不需要在每次用到的时候于栈中创建。另外,全局块的拷贝操作是个空操作,因为全局块绝不可能为系统所回收。这种块实际上相当于单例。下面就是个全局块:
void (^block)() = ^{
NSLog(@"This is a block");
};
4.要点:
- 块是C、C++、OC中的词法闭包。
- 块可接受参数,也可返回值。
- 块可以分配在栈上或堆上,也可以是全局的。分配在栈上的块可拷贝到堆里,这样的话,就和标准的OC对象一样,具备引用计数了。
第38条:为常用的块类型创建typedef
每个块都具备其“固有类型”,因而可将其赋给适当类型的变量。这个类型由块所接受的参数及其返回值组成。
因为之前我们使用或者书写块的时候代码都十分的复杂,所以我们为了简化代码就用到了typedef,就像这样:
typedef int (^EOCSomeBlock)(BOOL flag, int value);
这样就实现了对一个块的重命名,现在想要定义这个块就可以直接使用EOCSomeBlock来定义,这个就相当于一个新的数据类型一样,它接受两个参数,返回一个int型的数据。
例如:
EOCSomeBlock block = ^(BOOL flag, int value) {
//代码
};
这次代码就读起来顺畅多了:与定义其他变量时一样,变量类型在左边,变量名在右边。
当然其用处不止这点,当一个函数在接受参数的时候,其参数很多,我们就可以使用这种方法将方法签名中的参数类型写成一个词,那样就读起来顺口多了。
例如:

就可以写成:

这样写看上去简洁明了,易于理解,并且在我们想要更改其接收参数时也更加的方便,不易出错,我们只需要改变其typedef中的定义的参数就好了,若是有些地方的参数没调整过来它就会对其进行警告,我们就可以清楚的知道了。
并且,若是有好几个方法的接收参数都一样,你也不能用一个替代了,你也得给每个方法都定义一个接收参数的别名,因为若是你都用同一个的话,修改了一个就等于说是将其都修改了,这样会对别的方法造成影响。
要点:
- 以typedef重新定义块类型,可令块变量用起来更加简单。
- 定义新类型时应遵从现有的命名习惯,勿使其名称与别的类型相冲突。
- 不妨为同一个块签名定义多个类型别名。如果要重构的代码使用了块类型的某个别名,那么只需要修改相应typedef中的块签名即可,无须改动其他typedef。
第39条:用handler块降低代码分散程度
为用户界面编码时,一种常用的范式就是“异步执行任务”。这种范式的好处在于:处理用户界面的显示及触摸操作所用的线程,不会因为要执行I/O或网络通信这类耗时的任务而阻塞。这个线程通常称为主线程。
某些情况下,如果应用程序在一定时间内无响应,那么就会自动终止。iOS系统上的应用程序就是如此,“系统监控器”在发现某个应用程序的主线程已经阻塞了一段时间之后,就会令其终止。
通常我们想在某任务执行完了之后再通知相关代码进行后续的任务就会用到各种传值,但是我们上面说了块的各种用法,在此我们就可以用到,我们将一个方法的方法签名改为一个块,那么我们是不是就可以通过这个块来达到我们想要的效果,就像这样:
这种方法和委托协议很像,但是可以以内联形式定义completion handler,以此方式来使用“网络数据获取器”,可令代码比原先易懂很多。
与使用委托模式的代码相比,用块写出来的代码显然更为整洁。但是委托模式又个缺点:如果类要分别使用多个获取器下载不同数据,那么就得在delegate回调方法里根据传入的获取器参数来切换,就像这样:

改用块来写的好处是:无须保存获取器,也无须在回调方法里切换。每个completion handler的业务逻辑,都是和相关的获取器对象一起来定义的:
并且使用这种写法还可以处理很多错误情况,这又分为两种办法。可以分别用两个处理程序来处理操作失败的情况和操作成功的情况。也可以把处理失败情况所需的代码,与处理正常情况所用的代码,都封装到同一个completion handler块里。例如:

这种API设计风格很好,由于成功和失败的情况要分别处理,所以调用此API的代码也就会按照逻辑,把对应成功和失败情况的代码分开来写,这将令代码更易读懂。而且,若有需要,还可以把处理失败情况或成功情况所用的代码省略。
而另一种是这样的:

这种方式需要在块代码中检测传入的error变量,而且要把逻辑代码都放在一处。这种写法的缺点是:由于全部逻辑都写在一起,所以会令块变得比较长,且比较复杂。然而只用一个块的写法也有好处,那就是更为灵活。
把成功情况和失败情况放在同一个块中还有一个优点:调用API的代码可能会在处理成功响应的过程中发现错误。
有时需要在相关事件点执行回调操作,这种情况也可以使用handler块。就比如说是下载应用的进度条。我们为其添加一个观察者,并且在其值发生改变的时候我们调用其中的块。
此处传入的NSOperationQueue参数就表示触发通知时用来执行块代码的那个队列。这是个“队列操作”,而非“底层GCD队列”,不过两者语义也相同。
要点:
- 在创建对象时,可以使用内联的handler块将相关的业务逻辑一并声明。
- 在有多个实例需要监控时,如果采用委托模式,那么经常需要根据传入的对象来切换,而若改用handler块来实现,则可以直接将块与相关对象放在一起。
- 设计API时如果用到了handler块,那么可以增加一个参数,使用调用者可以通过此参数来决定应该把块安排在哪个队列上执行。
第40条:用块引用其所属对象时不要出现保留环
使用块时,若不仔细思量,则很容易出现“保留环”。比如说下面的这段代码:

还有另一个类去引用他:

这两段代码看上去没什么问题,但是其中有个保留环,其情况是这样: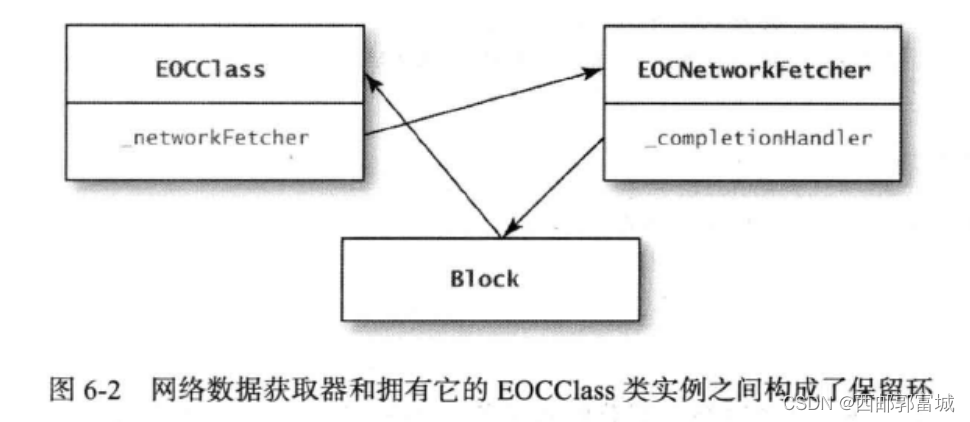
在EOCClass类中,那个start方法块中引用了_fetchedData实例变量也就相当于这个块引用了这个类本身,因为想要获取到这个实例变量就的获取到这个类。
想要破解这个保留环其实也很简单,就让其中一处断裂就好了:
这种是三方的保留而造成的保留环,当然也有两方的保留而造成的保留环,如果completion handler块所引用的对象最终又引用了这个块本身,那么就会出现保留环。所以我们在书写这类代码的时候,一定要好好注意,或许你看不出来,但是它确实存在。
要点:
- 如果块所捕获的对象直接或间接的保留了块本身,那么就得当心保留环问题。
- 一定要找个适当的时机解除保留环,而不能把责任推给API的调用者。
第41条:多用派发队列 ,少用同步锁
在OC中,如果有多个线程要执行同一份代码,那么有时就会出现问题。这种情况下,通常要使用锁来实现某种同步机制。在GCD出现之前,有两种方法,第一种是采用内置的“同步块”。

这种写法会根据给定的对象,自动创建一个锁,并等待块中的代码执行完毕。执行到这段代码结尾处,锁就释放了。然而,滥用@synchronized(self)则会降低代码效率,因为公用一个锁的那些同步块,都必须按顺序执行。若是在self对象上频繁加锁,那么程序可能要等另一段与此无关的代码执行完毕,才能继续执行当前代码,这样做其实并没有必要。
另一个方法是直接使用NSLock对象:

也可以使用NSRecursiveLock这种“递归锁”,线程能过多次持有该锁,而不会出现死锁现象。
这两种方法都很好,不过也有其缺陷。比方说,在极端情况下,同步块会导致死锁,另外,其效率也不见得很高,而如果直接使用锁对象的话,一旦遇到死锁,就会非常麻烦。
代替方案就是使用GCD,它能以更加简单、更高效的形式为代码加锁。

因为刚才说了,滥用@synchronized(self)会很危险,因为所有同步块都会彼此抢夺同一个锁。所以我们出现了一种简单而高效的办法来代替同步块或锁对象,那就是“串行同步队列”。用法如下:

此模式的思路是:把设置操作与获取操作都安排在序列化的队列里执行,这样的话,所有针对属性的访问操作就都同步了。但是这么写有个坏处:如果你测一下程序性能,那么可能会发现这种写法比原来的慢,因为执行异步派发时,需要拷贝块。若拷贝块所用的时间明显超过执行块所花的时间,则这种做法将比原来更慢。
多个获取方法可以并发执行,而获取方法与设置方法之间不能并发执行,利用这个特点,我们可以写出更快的代码来。这次我们使用并发队列。

像现在这样写代码,还无法正确实现同步。所有读取操作与写入操作都会在同一个队列上执行,不过由于是并发队列,所以读取与写入操作可以随时执行。而我们恰恰不想让这些操作随意执行。此问题用一个简单的GCD功能即可解决,他就是栅栏。下列函数可以向队列中派发块,将其作为栅栏使用:
在队列中,栅栏块必须单独执行,不能与其他块并行。这只对并发队列有意义,因为串行队列的块总是按顺序来执行的。并发队列如果接下来要处理的块是个栅栏块,那么就一直要等到当前所有并发块都执行完完毕,才会单独执行这个栅栏块。待栅栏块执行过后,再按正常方式继续向下处理。
因为获取和写入方法不能同步进行,所以上述的方法可以这样来写:

对获取方法使用并发队列,而对写入方法使用栅栏块。其用图来说明就是这样: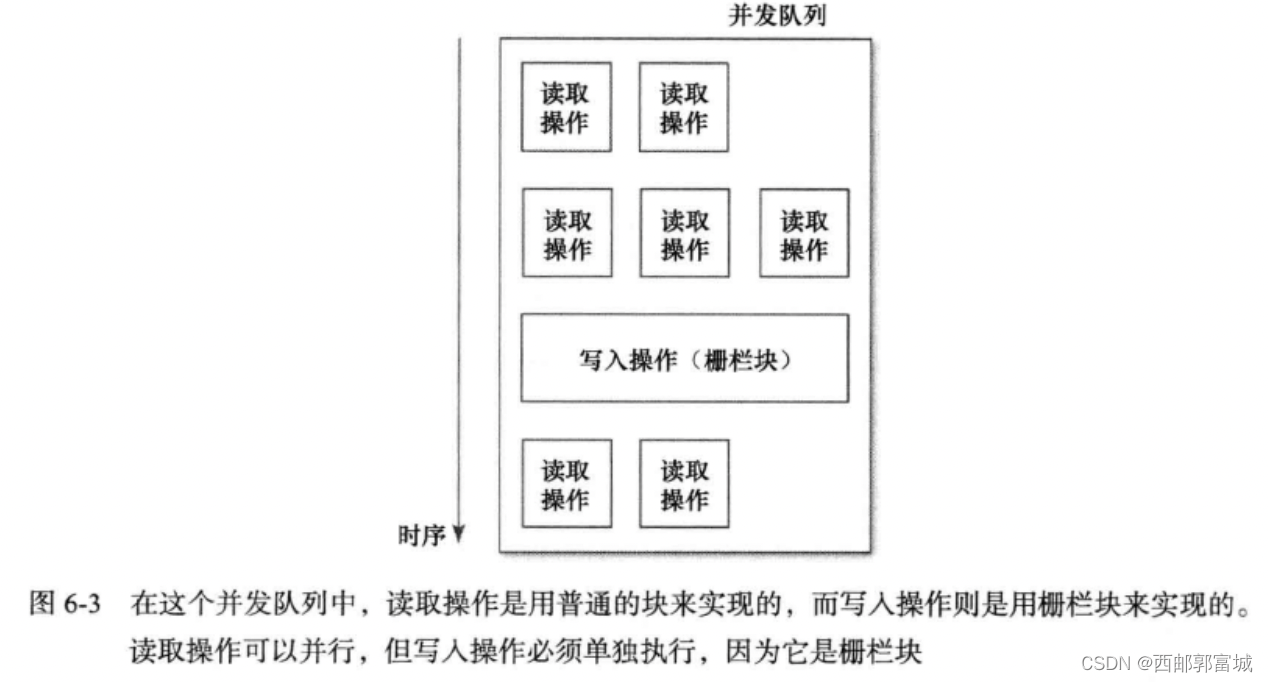
这样写来一定比之前的串行队列要快。注意:设置函数也可以改用同步的栅栏块来实现,那样做可能会更高效,其原因刚才也说明了。
要点:
- 派发队列可用来表述同步语义,这种做法要比使用@synchronized块或NSLock对象更简单。
- 将同步与异步派发结合起来,可以实现与普通加锁机制一样的同步行为,而这么做却不会阻塞执行异步派发的线程。
- 使用同步队列及栅栏块,可以令同步行为更加高效。
第42条:多用GCD,少用performSelector系列方法
OC是一门非常动态的语言,NSObject定义了几个方法,令开发者可以随意调用任何方法。这几个方法可以推迟执行方法调用,也可以指定运行方法所用的线程。但是现在还是少用的好。
其中最简单的是“performSelector:”。该方法签名如下,它接受一个参数,就是要执行的那个选择子:
- (id)performSelector:(SEL)selector;
该方法与直接调用选择子等效。所以下面两行代码的执行效果相同:

这种方式看上去很鸡肋,但是若选择子是在运行期决定的,那么就能体现出这种方式的强大之处了。这就相当于在动态绑定之上再次使用动态绑定,就像下面这样:

这种方式极为灵活,还可以用来简化代码。还有一种用法,就是先把选择子保存起来,等某个事件发生之后再调用。不管哪种用法,编译器都不知道要执行的选择子是什么,这必须到了运行期才能确定。然而,使用此特性的代价是,如果在ARC下编译代码,那么编译器会发出如下警示信息:
因为编译器不知道要调用的选择子是什么,也就不了解其方法签名及返回值,甚至连有没有返回值都不知道,就不知道使用ARC分配多少空间。鉴于此,ARC采取了比较谨慎的做法,就是不添加释放操作。就是因为这个而导致的内存泄漏,因为方法在返回对象时可能已经将其保留了。所以我们通常不建议使用这个方法来访问程序中的方法。
并且这种方法还有许多延伸的方法,就像下面这些,但是还是不建议使用,因为其弊大于利,有很大的局限性。

比如上述的这两个其最多才能传递两个参数,那么你想传递更多的参数怎么办,并且由于其是id类型的参数,所以就只能传递对象,若是接收的是整数或者浮点数那还得转换又很麻烦。与之类似的还有很多但是都不建议使用因为他们都有局限性而且我们还可以找到更好的方法来替代。
就比如,延后执行可以用dispatch_after来实现,在另一个线程上执行任务则可通过dispatch_sync及dispatch_async来实现。
要点:
- performSelector系列方法在内存管理方面容易有疏失。它无法确定将要执行的选择子具体是什么,因而ARC编译器也就无法插入适当的内存管理方法。
- performSelector系列方法所能处理的选择子太过局限了,选择子的返回值类型及发送给方法的参数个数都受到限制。
- 如果想把任务放在另一个线程上执行,那么最好不要用performSelector系列方法,而是应该把任务封装到块里,然后调用大中枢派发机制的相关方法来实现。
第43条:掌握GCD及操作队列的使用时机
在执行后台任务时,GCD并不一定是最佳的方式。还有一种技术叫做NSOperationQueue,它虽然与GCD不同,但是却与之相关,开发者可以把操作以NSOperation子类的形式放在队列中,而这些操作也能够并发执行。
这两者的诸多差别中,首先要注意:GCD是纯C的API,而操作队列则是OC的对象。在GCD中,任务用块来表示,而块是个轻量级的数据结构。与之相反,“操作”则是个更为重量级的OC对象。
使用NSOperation及NSOperationQueue的好处如下:


NSOperation对象也有“线程优先级”,这决定了运行此操作的线程处在何种优先级上。用GCD也可以实现此功能,而采用操作队列更简单,只需要设置一个属性。
总之,还是应该尽可能选用高层的API,只在确有必要时才求助于底层。但是还得因情况而议。
要点:
- 在解决多线程与任务管理问题时,派发队列并非唯一方案。
- 操作队列提供了一套高层的OC API,能实现纯GCD所具备的绝大部份功能,而且还能完成一些更为复杂的操作,那些操作若改用GCD来实现,则需另外编写代码。
第44条:通过Dispatch Group机制,根据系统资源状况来执行任务
dispatch group是GCD的一项特性,能够把任务分组。调用者可以等待这组任务执行完毕,也可以在提供回调函数之后继续往下执行,这组任务完成时,调用者会得到通知。其中最重要的用法,就是把将要并发执行的多个任务合为一组,于是调用者就可以知道这些任务何时才能全部执行完毕。
下面这个函数可以创建dispatch group:
dispatch_group_tdispatch_group_create();
想把任务编组,有两种方法。第一种是下面这个函数:
void dispatch_group_async(dispatch_group_t group, dispatch_queue_t queue, dispatch_block_t block);
他是普通dispatch_async函数的变体,比原来多一个参数,用于表示带执行块所归属的组。还有中办法能够指定任务所属的dispatch group,那就是使用下面这一对函数:
void dispatch_group_enter(dispatch_group_t group);
void dispatch_group_leave(dispatch_group_t group);
前者能够使分组里正要执行的任务数递增,而后者则使之递减。由此可知,调用了dispatch_group_enter以后,必须有与之对应的dispatch_group_leave才行。这和引用计数相似。而在使用dispatch group时,如果调用enter之后,没有相应的leave操作,那么这一组任务就永远执行不完。
下面这个函数可用于等待dispatch group执行完毕:
long dispatch_group_wait(dispatch_group_t group, dispatch_time_t timeout);
此函数接受两个参数,一个是要等待的group,另一个是代表等待时间的timeout值。timeout参数表示函数在等待dispatch group执行完毕时,应该阻塞多久。如果执行dispatch group所需的时间小于timeout,则返回0,否则返回非0。此参数也可以取常量dispatch_time_forever,这表示函数会一直等着dispatch group执行完,而不会超时。
除了使用上面那个函数等待dispatch group执行完毕之外,也可以换个方法,使用下列函数:
void dispatch_group_notify(dispatch_group_t group, dispatch_queue_t queue, dispatch_block_t block);
与wait函数略有不同的是:开发者可以向此函数传入块,等dispatch group执行完毕之后,块会在特定的线程上执行。并且notify回调时所选用的队列,完全应该根据具体情况来定。
为什么要“根据系统资源状况来执行任务”呢?
为了执行队列中的块,GCD会在适当的时机自动创建新线程或复用旧线程。如果使用并发队列,那么其中有可能会有多个线程,这也意味着多个块可以并发执行。在并发队列中,执行任务所用的并发线程数量,取决于各种因素,而GCD主要是根据系统资源状况来判定这些因素的。
我们想要遍历collection,并在其每个元素上执行任务,而这也可以用另一个GCD函数来实现:
void dispatch_apply(size_t iterations, dispatch_queue_t queue, void(^block)(size_t));
此函数会将块反复执行一定的次数,每次传给块的参数都会递增,从0开始,直至“iterations - 1”,其用法如下:

有一件事要注意:dispatch_apply所用的队列可以是并发队列。如果采用并发队列,那么系统就可以根据资源状况来并行执行这些块了,这与使用dispatch group的那段实例代码一样。
总之我们还是得灵活使用,不是学了一个就死用一种方法,我们要因情况而议,选择最好的办法。
要点:
- 一系列任务可归入一个dispatch group之中。开发者可以在这组任务执行完毕时获得通知。
- 通过dispatch group,可以在并发式派发队列里同时执行多项任务。此时GCD会根据系统资源状况来调度这些并发执行的任务。开发者若自己来实现此功能,则需编写大量代码。
第45条:使用dispatch_once来执行只需运行一次的线程安全代码
单例模式对我们来说都不陌生,常见的实现方式为:在类中编写名为sharedInstance的方法,该方法只会返回全类共用的单例实例,而不会在每次调用时都创建新的实例。

但是这样写还有有争议的,不过GCD引入了一项特征,能使单例实现起来更为容易:
void dispatch_once(dispatch_once_t *token, dispatch_block_t block);
此函数接受类型为dispatch_once_t的特殊函数,称为标记,此外还接受块参数。对于给定的标记来说,该函数抱枕相关的块必定会执行,且仅执行一次。首次调用该函数时,必然会执行块中的代码,最重要的一点在于,此操作完全是线程安全的。请注意,对于只需执行一次的块来说,每次调用函数时传入的标记都必须完全相同。因此,开发者通常将标记声明在static或global作用域里。
那么单例就可以这样写:

要点:
- 经常需要编写“只需执行一次的线程安全代码”。通过GCD所提供的dispatch_once函数,很容易就能实现此功能。
- 标记应该声明在static或global作用域中,这样的话,在把只需执行一次的块传给dispatch_once函数时,传进去的标记也是相同的。
第46条:不要使用dispatch_get_current_queue
使用GCD时,我们经常需要判断当前代码正在那个队列上执行, 我们会发现苹果给了我们这个函数:
dispatch_queue_t dispatch_get_current_queue();
此函数会返回当前正在执行代码的队列。但是我们最好还是不要使用,因为队列之间会形成一套层级体系,这意味着在某个队列中的块,会在其上级队列(“父队列”)里执行。层级里地位最高的那个队列总是“全局并发队列”。这样我们再进行检测的时候,他返回的其实并不是我们想要队列,而可能是其子队列,若对其进行条件的判断就有可能造成“死锁”。
要解决这个问题,最好的办法就是通过GCD所提供的功能来设定“队列特有数据”,此功能可以把任意数据以键值对的形式关联到队列里。最重要之处在于,假如根据指定键获取不到关联数据,那么系统就会沿着层级向上查找,知道找到数据或到达根队列为止。
void dispatch_queue_set_specific(dispatch_queue_t queue, const void *key, void *context, dispatch_function_t destructor);
此函数的首个参数表示待设置数据的队列,其后两个参数是键与值。键与值都是不透明的void指针。对于键来说,有个问题一定要注意:函数是按指针值来比较键的,而不是按照其内容。
函数最后一个参数是“析构函数”,对于给定的键来说,当队列所占内存为系所回收,或者有新的值与键相关联时,原有的值对象就会移除,而析构函数也会于此时运行。dispatch_function_t类型的定义如下:
typedef void (*dispatch_function_t)(void*);
要点:
- dispatch_get_current_queue函数的行为常常与开发者所预期的不同。此函数已经废弃。只应做调试只用。
- 由于派发队列是按层级来组织的,所以无法单用某个队列对象来描述“当前队列”这一概念。
- dispatch_get_current_queue函数用于解决不可重入的代码所引发的死锁,然而能用此函数解决的问题,通常也能改用“队列特定数据”来解决。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









