






bp简介
github
原文:https://github.com/amace-lzo/top-algorithm-set/wiki/bpnn_BPNeuralNetwork
BP神经网络(Back Propagation Neural Network)是一种基于BP算法的人工神经网络,其使用BP算法进行权值与阈值的调整。在20世纪80年代,几位不同的学者分别开发出了用于训练多层感知机的反向传播算法,David Rumelhart和James McClelland提出的反向传播算法是最具影响力的。其包含BP的两大主要过程,即工作信号的正向传播与误差信号的反向传播,分别负责了神经网络中输出的计算与权值和阈值更新。工作信号的正向传播是通过计算得到BP神经网络的实际输出,误差信号的反向传播是由后往前逐层修正权值与阈值,为了使实际输出更接近期望输出。
(1)工作信号正向传播。输入信号从输入层进入,通过突触进入隐含层神经元,经传递函数运算后,传递到输出层,并且在输出层计算出输出信号传出。当工作信号正向传播时,权值与阈值固定不变,神经网络中每层的状态只与前一层的净输出、权值和阈值有关。若正向传播在输出层获得到期望的输出,则学习结束,并保留当前的权值与阈值;若正向传播在输出层得不到期望的输出,则在误差信号的反向传播中修正权值与阈值。
(2)误差信号反向传播。在工作信号正向传播后若得不到期望的输出,则通过计算误差信号进行反向传播,通过计算BP神经网络的实际输出与期望输出之间的差值作为误差信号,并且由神经网络的输出层,逐层向输入层传播。在此过程中,每向前传播一层,就对该层的权值与阈值进行修改,由此一直向前传播直至输入层,该过程是为了使神经网络的结果与期望的结果更相近。
当进行一次正向传播和反向传播后,若误差仍不能达到要求,则该过程继续下去,直至误差满足精度,或者满足迭代次数等其他设置的结束条件。
面向matlab工具箱的神经网络理论与应用(第三版)
第66页

训练代码:(代码+解释)
初始化
public BPModel trainBP(BPParameter bpParameter, Matrix inputAndOutput) throws Exception {
ActivationFunction activationFunction = bpParameter.getActivationFunction();
int inputCount = bpParameter.getInputLayerNeuronCount();
int hiddenCount = bpParameter.getHiddenLayerNeuronCount();
int outputCount = bpParameter.getOutputLayerNeuronCount();
double normalizationMin = bpParameter.getNormalizationMin();
double normalizationMax = bpParameter.getNormalizationMax();
double step = bpParameter.getStep();
double momentumFactor = bpParameter.getMomentumFactor();
double precision = bpParameter.getPrecision();
int maxTimes = bpParameter.getMaxTimes();
if(inputAndOutput.getMatrixColCount() != inputCount + outputCount){
throw new Exception("神经元个数不符,请修改");
}
- 我们去看一下BPParameter 类,如图:设定了一些默认值
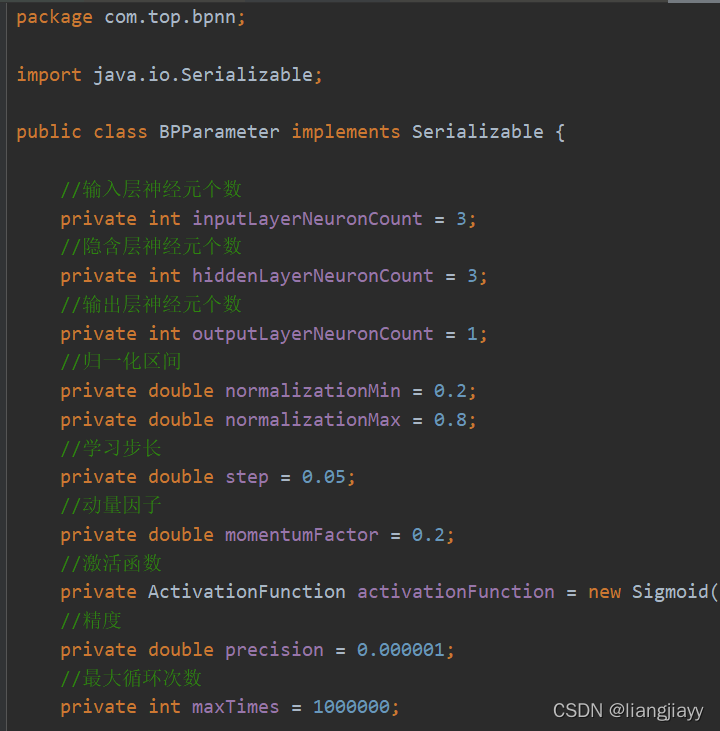
激活函数
-
默认的激活函数是:sigmoid,而且提供的也只有sigmoid
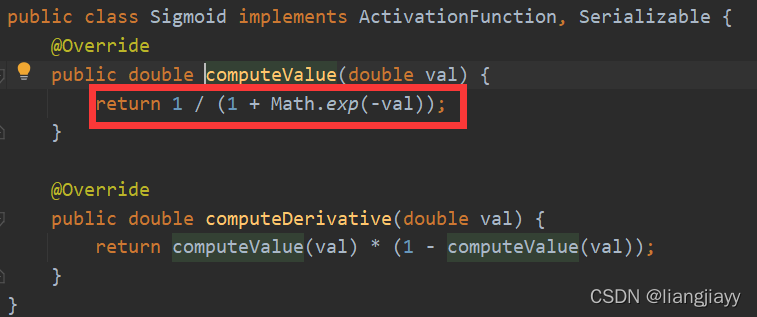
sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。Sigmoid函数由下列公式定义
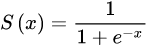
其对x的导数可以用自身表示:
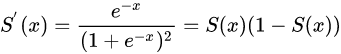
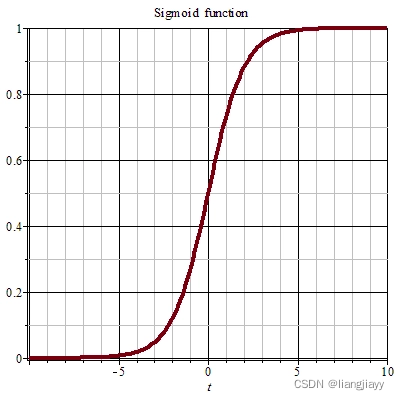
Sigmoid函数的图形如S曲线
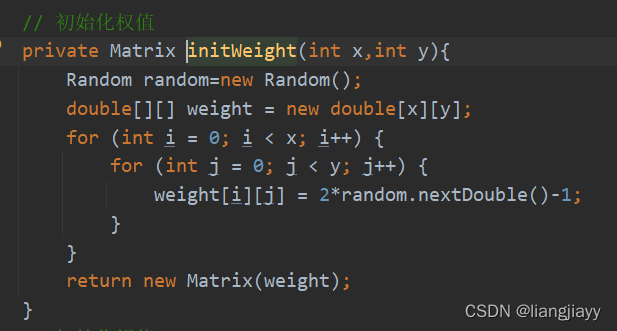
初始化权值
- 包含隐藏层权值w1和输出层权值w2
// 初始化权值
Matrix weightIJ = initWeight(inputCount, hiddenCount);
Matrix weightJP = initWeight(hiddenCount, outputCount);
- 方法是生成-1~1之间的随机数
初始化阈值
- 包括隐藏层阈值b1和输出层阈值b2
// 初始化阈值
Matrix b1 = initThreshold(hiddenCount);
Matrix b2 = initThreshold(outputCount);
- 神经网络是模仿大脑的神经元,当外界刺激达到一定的阀值时,神经元才会受刺激,影响下一个神经元
- 方法也是-1~1之间的随机数

动量项
// 动量项
Matrix deltaWeightIJ0 = new Matrix(inputCount, hiddenCount);
Matrix deltaWeightJP0 = new Matrix(hiddenCount, outputCount);
Matrix deltaB10 = new Matrix(1, hiddenCount);
Matrix deltaB20 = new Matrix(1, outputCount);
- 动量项反应了以前积累的调整经验,对于t时刻的调整起阻尼作用。当误差曲面出现骤然起伏时,可以减小振荡趋势,提高收敛速度。
- 动量项奖励一致的梯度,惩罚不一致的梯度,类似于对梯度作了归一化,也可以认为是利用了某种形式的高阶信息。因此即使梯度的某些分量很小,对带动量的GD variants影响也不会很大。
- 通俗的讲,就是修改权值和阈值的变化量,使其和上一次的变化量有关。
通过上面的BP算法的分析,接下来就更便于理解下面要讨论的动量BP算法了。动量BP算法本质上就是在BP算法的基础上引入了动量因子 n(0~1),引入次因子的优点为使其可以采用较大的学习率,而不会造成学习过程的发散,因为当修正过量时,该算法总是可以使修正量减少,以保持修正方向向着收敛的方向进行。另一方面,动量BP算法总是加速同一梯度方向的修正量。以下则使MOBP的数学模型:
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/a483780e4bac631f7ed1a250b316eae5.png)
- 其中,▲x(k+1):第k+1次的权值、阈值改变量;▲x(k+1):第k次的权值、阈值变化量;α:学习速率;E:误差函数;x:权值/阈值
该算法是以前一次的修正结果来影响本次修正量,当前一次的修正量过大时,第二项的符号将与前一次修正量的符号相反(左边小于右边),从而减少本次的修正量,起到减小振荡的作用,反之亦然。可以看出,动量BP算法总是力图使在同一梯度方向上的修正量增加。动量因子 [公式] 越大,同一梯度方向上的动量也越大。
截取输入矩阵和输出矩阵
// 截取输入矩阵和输出矩阵
Matrix input = inputAndOutput.subMatrix(0,inputAndOutput.getMatrixRowCount(),0,inputCount);
Matrix output = inputAndOutput.subMatrix(0,inputAndOutput.getMatrixRowCount(),inputCount,outputCount);
- 把输入数据分成两部分,一部分是权值,一部分是目标值
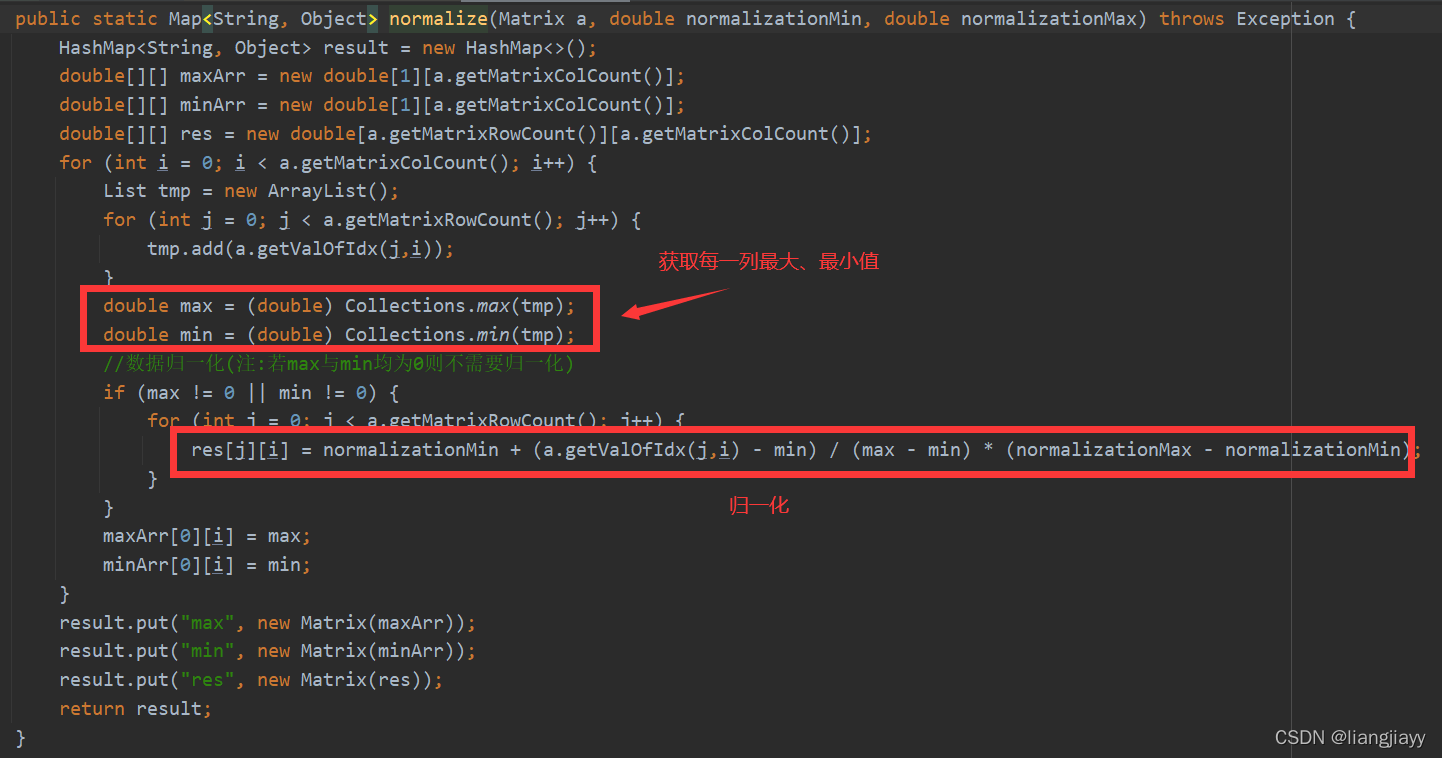
归一化
// 归一化
Map<String,Object> inputAfterNormalize = MatrixUtil.normalize(input, normalizationMin, normalizationMax);
input = (Matrix) inputAfterNormalize.get("res");
Map<String,Object> outputAfterNormalize = MatrixUtil.normalize(output, normalizationMin, normalizationMax);
output = (Matrix) outputAfterNormalize.get("res");
工作信号正向传播:以f2(f1(x1 * w1 + b1)*w2+ b2))为例
- f1(x)、f2(x)是激活函数;w1,b1隐含层的权值、阈值;w2,b2输出层的权值、阈值;x1:输入矢量
int times = 1;
double E = 0;//误差
while (times < maxTimes) {
/*-----------------正向传播---------------------*/
// 隐含层输入
Matrix jIn = input.multiple(weightIJ);
// 扩充阈值
Matrix b1Copy = b1.extend(2,jIn.getMatrixRowCount());
// 加上阈值
jIn = jIn.plus(b1Copy);
// 隐含层输出
Matrix jOut = computeValue(jIn,activationFunction);
// 输出层输入
Matrix pIn = jOut.multiple(weightJP);
// 扩充阈值
Matrix b2Copy = b2.extend(2, pIn.getMatrixRowCount());
// 加上阈值
pIn = pIn.plus(b2Copy);
// 输出层输出
Matrix pOut = computeValue(pIn,activationFunction);
// 计算误差
Matrix e = output.subtract(pOut);
E = computeE(e);//误差
// 判断是否符合精度
if (Math.abs(E) <= precision) {
System.out.println("满足精度");
break;
}
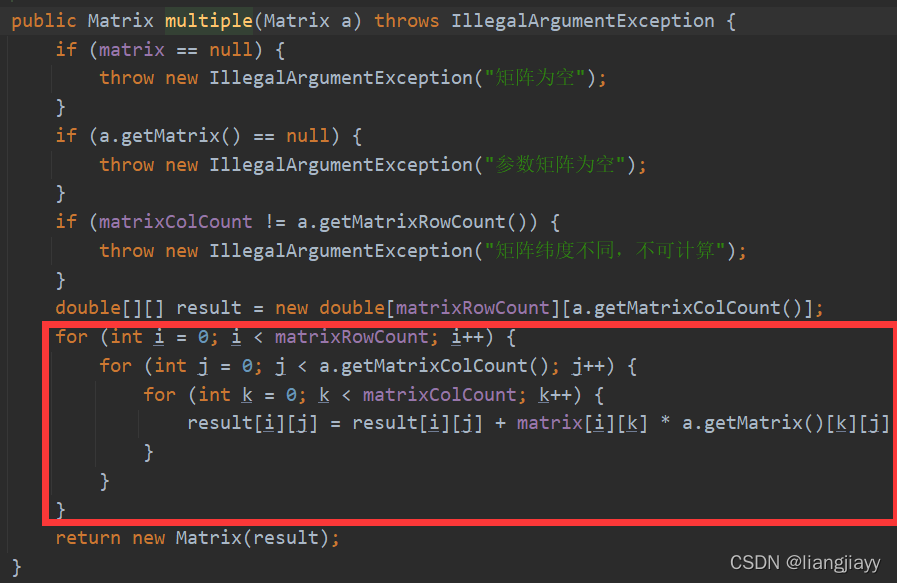
隐含层输入
相当于x1 * w1
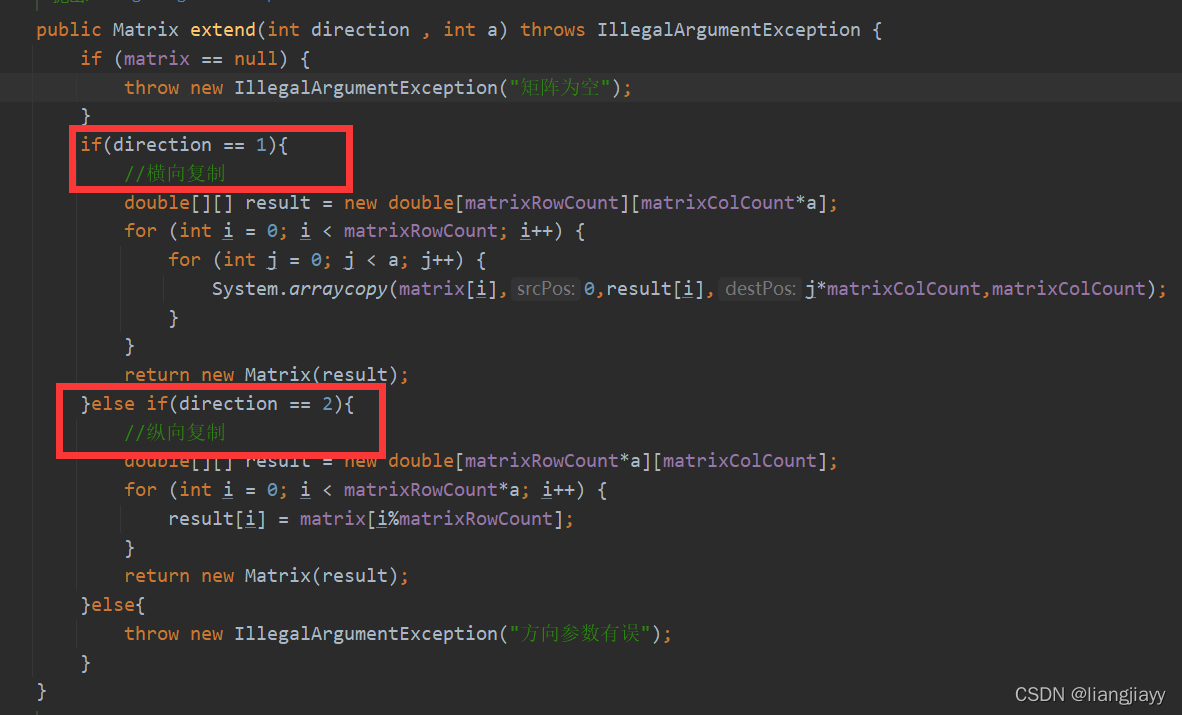
扩充阈值
相当于把单行的b扩充为n行(n:输入数据的个数)的b,用于构造b1
加上阈值
相当于内层的x1 * w1 + b1
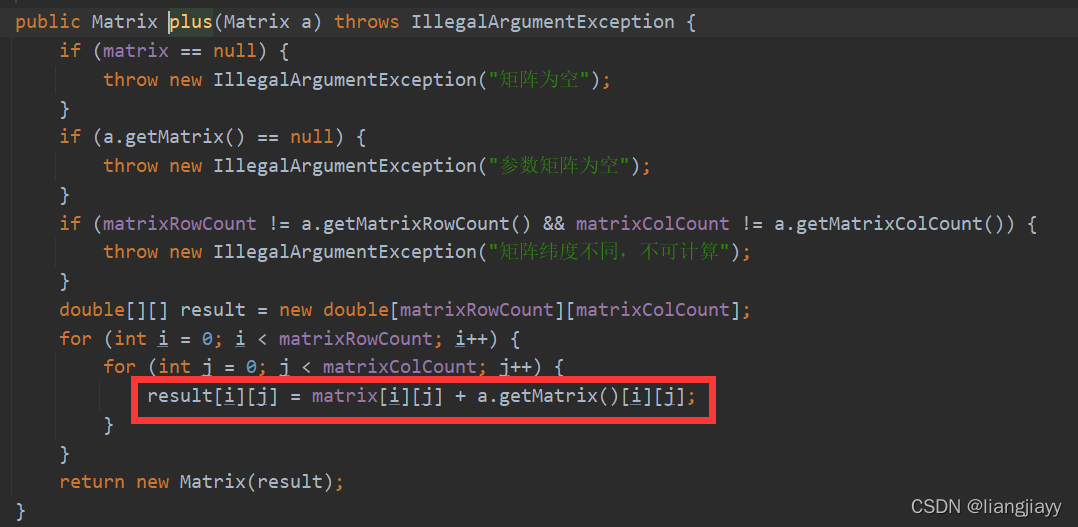
隐含层输出
- 上一步的值代入激活函数计算结果,相当于内层的
f1(x1 * w1 + b1)
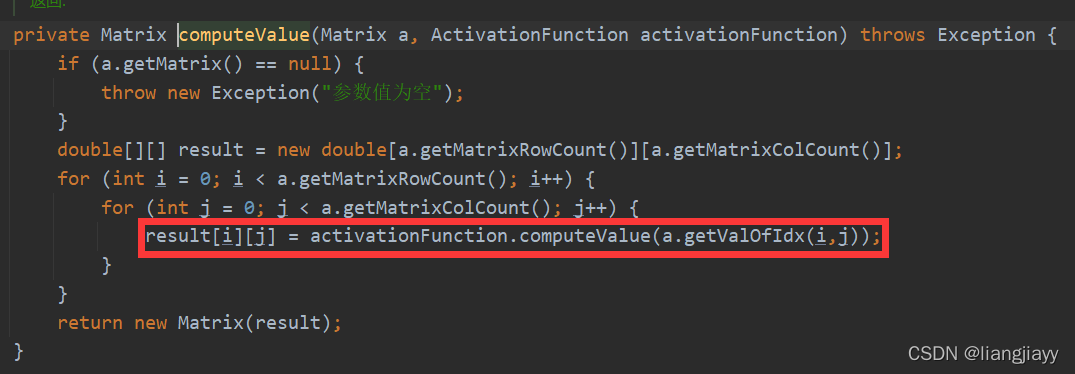
- Logistic函数的计算:
输出层输入
- 同隐含层输入,外层的
X2 * W2
扩充阈值
- 同上一个扩充阀域,可得出 b2
加上阈值
- 外层的
X2 * W2+ b2,其中x2 = x1 * w1+ b1
输出层输出
- 上一步的值通过激活函数计算结果,相当于外层的
f2(X2 * W2 + b2)
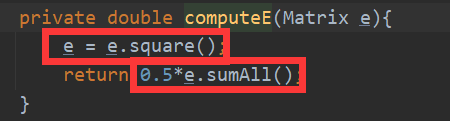
计算误差
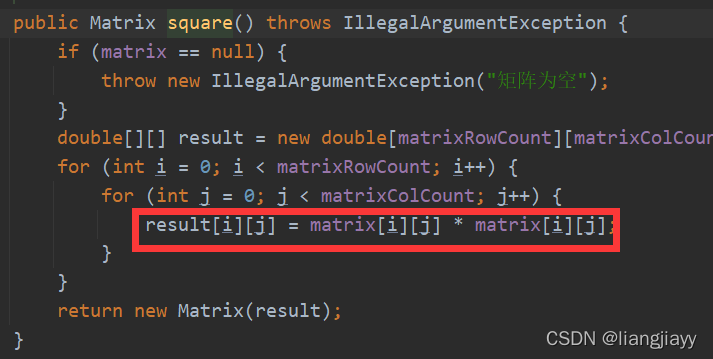
公式:1/2 * ( t-a )^2
代码:
- t-a
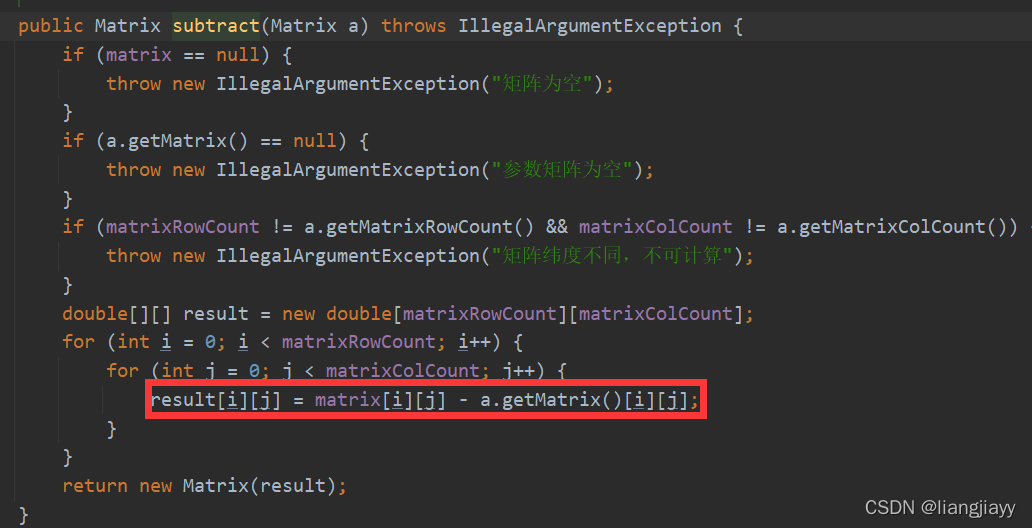
- 1/2 * ( t-a )^2
判断是否符合精度
- 是否比给定精度小

误差信号反向传播
/*-----------------反向传播---------------------*/
// J与P之间权值修正量
Matrix deltaWeightJP = e.multiple(step);
deltaWeightJP = deltaWeightJP.pointMultiple(computeDerivative(pIn,activationFunction));
deltaWeightJP = deltaWeightJP.transpose().multiple(jOut);
deltaWeightJP = deltaWeightJP.transpose();
// P层神经元阈值修正量
Matrix deltaThresholdP = e.multiple(step);
deltaThresholdP = deltaThresholdP.transpose().multiple(computeDerivative(pIn, activationFunction));
// I与J之间的权值修正量
Matrix deltaO = e.pointMultiple(computeDerivative(pIn,activationFunction));
Matrix tmp = weightJP.multiple(deltaO.transpose()).transpose();
Matrix deltaWeightIJ = tmp.pointMultiple(computeDerivative(jIn, activationFunction));
deltaWeightIJ = input.transpose().multiple(deltaWeightIJ);
deltaWeightIJ = deltaWeightIJ.multiple(step);
// J层神经元阈值修正量
Matrix deltaThresholdJ = tmp.transpose().multiple(computeDerivative(jIn, activationFunction));
deltaThresholdJ = deltaThresholdJ.multiple(-step);
if (times == 1) {
// 更新权值与阈值
weightIJ = weightIJ.plus(deltaWeightIJ);
weightJP = weightJP.plus(deltaWeightJP);
b1 = b1.plus(deltaThresholdJ);
b2 = b2.plus(deltaThresholdP);
}else{
// 加动量项
weightIJ = weightIJ.plus(deltaWeightIJ).plus(deltaWeightIJ0.multiple(momentumFactor));
weightJP = weightJP.plus(deltaWeightJP).plus(deltaWeightJP0.multiple(momentumFactor));
b1 = b1.plus(deltaThresholdJ).plus(deltaB10.multiple(momentumFactor));
b2 = b2.plus(deltaThresholdP).plus(deltaB20.multiple(momentumFactor));
}
deltaWeightIJ0 = deltaWeightIJ;
deltaWeightJP0 = deltaWeightJP;
deltaB10 = deltaThresholdJ;
deltaB20 = deltaThresholdP;
times++;
}
以下计算变化量都是根据偏导计算,公式在下图中(公式太难敲了,略)
- J与P之间权值修正量
计算△w2=dE/dw2 - P层神经元阈值修正量
计算△b2=dE/db2 - I与J之间的权值修正量
- 计算
△w1=dE/dw1 - J层神经元阈值修正量
计算△b1=dE/db1

BP神经网络的输出
// BP神经网络的输出
BPModel result = new BPModel();
result.setInputMax((Matrix) inputAfterNormalize.get("max"));
result.setInputMin((Matrix) inputAfterNormalize.get("min"));
result.setOutputMax((Matrix) outputAfterNormalize.get("max"));
result.setOutputMin((Matrix) outputAfterNormalize.get("min"));
result.setWeightIJ(weightIJ);
result.setWeightJP(weightJP);
result.setB1(b1);
result.setB2(b2);
result.setError(E);
result.setTimes(times);
result.setBpParameter(bpParameter);
System.out.println("循环次数:" + times + ",误差:" + E);
return result;
}
- 保存了权值及目标值的最大值、最小值,w1,w2,b1,b2,误差,训练次数,bp的参数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









