






通过爬取百度翻译页面

想获得框中信息

通过测试发现此框会发生动态改变
于是猜测应该是通过Ajax完成数据的上传
于是打开抓包工具
点击Network
打开XHR....
通过分析sug包发现这就是我想要的
并且发现通过改变url后缀kw
可以改变页面内容 参数即kw:word
既可以通过键入单词 获得想要翻译的内容
即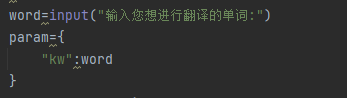
通过分析content-type可以发现这是一个json类字典
即需引入json库

想将获取的翻译内容保存到文件
推荐使用with...as 创建完成后保存关闭释放内存 避免内存积压使cpu占用过多
避免翻译的内容以ascii的形式存在 故需用到ensure_ascii
并通过json.dump进行数据存储

虽然到这里已经完了 但是打开文件查看单词的翻译未免有些繁琐
且
含有一些不必要的信息
故应用到正则表达式 引入re库
由于使用with...as关闭了文件 无法读取
故需要再次打开文件 但此时json数据需要以utf-8-sig的形式进行解码
再使用json.load进行读取 (内容本就是json字符串 解码也改变不了其存入的本质)
如何删去不必要的信息并输入到运行程序框中实现即运行即获得翻译结果呢
如下
由于从网站中获取的响应信息含有""
故无法进行正则表达式的提取 会报如下错
JSONDecodeError: Expecting value: line 1 column 1
所以这里需要使用re.sub(要被替换的,要替换成的,匹配的字符串,替换次数) 进行字符的替换
但json.load()提取出来的非字符串
避免出现expected string or bytes-like object
故需要通过str()
进行强类型转换
才可顺利使用re.sub()
替换完成后可进行正常的提取
通过分析翻译内容可得到此pattern
![]()
从而提取所有符合条件的子串并打印

以下是效果图

若有错误敬请斧正^_^















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









