






Hive学习笔记3
本博客仅作学习记录所用,基于尚硅谷和黑马程序员做的笔记…
Hive学习笔记1
Hive学习笔记2
压缩和存储
Hadoop 压缩配置
- 压缩的优点
- 减小文件存储所占空间
- 加快文件传输效率,从而提高系统的处理速度
- 降低IO读写的次数
- 压缩的缺点
- 使用数据时需要先对文件解压,加重CPU负荷,压缩算法越复杂,解压时间越长
MR 支持的压缩编码

为了支持多种压缩/解压缩算法,Hadoop 引入了编码/解码器,如下表所示:


压缩性能的比较:

http://google.github.io/snappy/
On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250
MB/sec or more and decompresses at about 500 MB/sec or more.
(在64位模式下的core i7处理器单核上,Snappy的压缩率约为250MB/秒或更多,解压速度大约为500 MB/秒或更多。)
压缩参数配置
要在 Hadoop 中启用压缩,可以配置如下参数(mapred-site.xml 文件中):

开启 Map 输出阶段压缩(MR 引擎)
开启 map 输出阶段压缩可以减少 job 中 map 和 Reduce task 间数据传输量。具体配置如下:
- 案例实操:
- (1)开启 hive 中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
- (2)开启 mapreduce 中 map 输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
- (3)设置 mapreduce 中 map 输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
- (4)执行查询语句
hive (default)> select count(ename) name from emp;
hadoop103:8088查看历史任务日志:
- 没开启 Map 输出阶段压缩 的日志

- 开启 Map 输出阶段压缩 的日志

返回顶部
开启 Reduce 输出阶段压缩
当 Hive 将 输 出 写 入 到 表 中 时 , 输出内容同样可以进行压缩。属性hive.exec.compress.output控制着这个功能。用户可能需要保持默认设置文件中的默认值false,这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为 true,来开启输出结果压缩功能。
- 案例实操:
- (1)开启 hive 最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
- (2)开启 mapreduce 最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
- (3)设置 mapreduce 最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
- (4)设置 mapreduce 最终数据输出压缩为块压缩
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
- (5)测试一下输出结果是否是压缩文件
hive (default)> insert overwrite local directory
'/opt/module/data/distribute-result' select * from emp distribute by
deptno sort by empno desc;

文件存储格式
Hive 支持的存储数据的格式主要有:TEXTFILE(默认) 、SEQUENCEFILE、ORC、PARQUET。
列式存储和行式存储

如图所示左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
- 行式存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。 - 列式存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE 和 SEQUENCEFILE 的存储格式都是基于行式存储的;ORC 和 PARQUET 是基于列式存储的。
TextFile 格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合 Gzip、Bzip2 使用,
但使用 Gzip 这种方式,hive 不会对数据进行切分,从而无法对数据进行并行操作。
Orc 格式
Orc (Optimized Row Columnar)是 Hive 0.11 版里引入的新的存储格式。
如下图所示可以看到每个 Orc 文件由 1 个或多个 stripe 组成,每个 stripe 一般为 HDFS的块大小,每一个 stripe 包含多条记录,这些记录按照列进行独立存储,对应到 Parquet中的 row group 的概念。每个 Stripe 里有三部分组成,分别是 Index Data,Row Data,Stripe Footer:

Index Data:一个轻量级的 index,默认是每隔 1W 行做一个索引。Index data包含每列的最大和最小值以及每列所在的行位置。行索引里面提供了偏移量,它可以跳到正确的压缩块位置。
有了相对频繁的行索引使用,使得在stripe中快速读取的过程中可以跳过很多行,尽管这个stripe的大小很大。在默认情况下,可以跳过10000行。
(row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个 Stream 来存储。
stream:一个stream表示文件中一段有效的数据,包括索引和数据两类。索引stream保存每一个row group的位置和统计信息,数据stream包括多种类型的数据,具体需要哪几种是由该列类型和编码方式决定。Stripe Footer:存的是各个 Stream 的类型,长度等信息。
每个文件有一个 File Footer,这里面存的是每个 Stripe 的行数,每个 Column 的数据类型,以及列级别的一些聚合的结果,比如:count, min, max, and sum 等;
每个文件的尾部是一个 PostScript,这里面记录了整个文件的压缩类型以及FileFooter 的长度信息等。
在读取文件时,会 seek 到文件尾部读 PostScript,从里面解析到File Footer 长度,再读 FileFooter,从里面解析到各个 Stripe 信息,再读各个 Stripe,即从后往前读。
使用ORC文件格式时,用户可以使用HDFS的每一个block存储ORC文件的一个stripe。对于一个ORC文件来说,stripe的大小一般需要设置得比HDFS的block小,如果不这样的话,一个stripe就会分别在HDFS的多个block上,当读取这种数据时就会发生远程读数据的行为。如果设置stripe的只保存在一个block上的话,如果当前block上的剩余空间不足以存储下一个strpie,ORC的writer接下来会将数据打散保存在block剩余的空间上,直到这个block存满为止。这样,下一个stripe又会从下一个block开始存储。
Parquet 格式
Parquet 文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此 Parquet 格式文件是自解析的。
行组(Row Group):每一个行组包含一定的行数,在一个 HDFS 文件中至少存储一个行组,类似于 orc 的 stripe 的概念。列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储 Parquet 数据的时候会按照 Block 大小设置行组的大小,由于一般情况下每一个 Mapper 任务处理数据的最小单位是一个 Block,这样可以把每一个行组由一个 Mapper 任务处理,增大任务执行并行度。Parquet 文件的格式。

上图展示了一个 Parquet 文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的 Magic Code,用于校验它是否是一个 Parquet 文件,Footer length 记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的 Schema 信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在 Parquet 中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前 Parquet 中还不支持索引页。
主流文件存储格式对比实验
从存储文件的压缩比和查询速度两个角度对比。
- 存储文件的压缩比测试:
- 测试数据(一部分数据)
[hyj@hadoop102 datas]$ vim log.data
2017-08-10 13:00:00 http://www.taobao.com/17/?tracker_u=1624169&type=1 B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1 http://hao.360.cn/ 1.196.34.243 NULL -1
2017-08-10 13:00:00 http://www.taobao.com/item/962967_14?ref=1_1_52_search.ctg_1 T82C9WBFB1N8EW14YF2E2GY8AC9K5M5P http://www.yihaodian.com/ctg/s2/c24566-%E5%B1%B1%E6%A5%82%E5%88%B6%E5%93%81?ref=pms_15_78_258 222.78.246.228 134939954 156
2017-08-10 13:00:00 http://www.taobao.com/1/?tracker_u=1013304189&uid=2687512&type=3 W17C89RU8DZ6NMN7JD2ZCBDMX1CQVZ1W http://www.yihaodian.com/1/?tracker_u=1013304189&uid=2687512&type=3 118.205.0.18 NULL -20
2017-08-10 13:00:00 http://m.taobao.com/getCategoryByRootCategoryId_1_5146 f55598cafba346eb217ff3fbd0de2930 http://m.yihaodian.com/getCategoryByRootCategoryId_1_5135 10.4.6.53 NULL -1000
2017-08-10 13:00:00 http://m.taobao.com/getCategoryByRootCategoryId_1_24728 f55598cafba346eb217ff3fbd0de2930 http://m.yihaodian.com/getCategoryByRootCategoryId_1_5146 10.4.4.109 NULL -1000
2017-08-10 13:00:00 http://union.taobao.com/link_make/viewPicInfo.do?imgSize=660x70&truckerU=101542127 4PBTT18JEEJHM91DNGKNUSZTA29W8WP3 http://www.jintoutiao.com/yule.html 125.38.159.84 NULL -30
2017-08-10 13:00:00 http://www.taobao.com/item/9680587_1?smt_b=C0B0A09BECBF110A470F00C 615MMAA5RFVRRMHJVP5VCHTQGEGDW988 211.167.237.134 NULL -20
2017-08-10 13:00:00 http://union.taobao.com/link_make/viewPicInfo.do?imgSize=660x70&truckerU=101542127 QCU8A6VCNX28YGGJVQAABG4BJ6F8QT1B http://jintoutiao.com/yule.html 117.22.144.64 NULL 327
2017-08-10 13:00:00 http://www.taobao.com/ctg/s2/c8325-%E7%99%BE%E6%B4%81%E5%B8%83-%E9%92%A2%E4%B8%9D%E7%90%83/ ZYVF5W5WDFGAQP1S45RTFR7SPVM8GY5Q http://www.yihaodian.com/item/user/continueShopping.do?lc=\u6c34\u4e0a\u7528\u5177&csps=1984887_3_1_950411&pageType=B 61.128.247.131 5305018 -40
2017-08-10 13:00:00 http://m.taobao.com/getProductDetail_1_1001417 A90A3460D49D437E96BC3B4DC138B628 http://m.yihaodian.com/searchProduct_1_银杏洗面奶_2 222.128.241.1 NULL -20
2017-08-10 13:00:00 http://search.taobao.com/s2/c0-0/k%25E6%25B4%2597%25E5%258F%2591%25E6%25B0%25B4/ WGSMFJD42BQEYB57EUHPUHHZMZHJTGX2 http://www.yihaodian.com/3/?type=3&tracker_u=1013241403 60.30.93.90 NULL -30
2017-08-10 13:00:00 http://m.taobao.com/ RJSDGJVTMNBHXE9HX53ZTZTV11NCYTED 58.39.59.80 NULL -10
- TextFile
(1)创建表,存储数据格式为 TEXTFILE
create table log_text (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as textfile;
(2)向表中加载数据
load data local inpath '/opt/module/hive-3.1.2/datas/log.data' into table log_text ;
(3)查看表中数据大小
dfs -du -h /user/hive/warehouse/log_text;
18.1 M 54.4 M /user/hive/warehouse/log_text/log.data
或

- ORC
(1)创建表,存储数据格式为 ORC
create table log_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="NONE"); -- 设置 orc 存储不使用压缩
(2)向表中加载数据(不能使用load命令)
insert into table log_orc select * from log_text;
(3)查看表中数据大小
dfs -du -h /user/hive/warehouse/log_orc;
7.7 M 23.1 M /user/hive/warehouse/log_orc/000000_0
- Parquet
(1)创建表,存储数据格式为 parquet
create table log_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet;
(2)向表中加载数据(不能使用load命令)
insert into table log_parquet select * from log_text;
(3)查看表中数据大小
dfs -du -h /user/hive/warehouse/log_parquet;
13.1 M 39.3 M /user/hive/warehouse/log_parquet/000000_0
- 存储文件的对比总结:
ORC > Parquet > textFile
- 存储文件的查询速度测试:
- TextFile
insert overwrite local directory
'/opt/module/data/log_text' select substring(url,1,4) from log_text;

- ORC
insert overwrite local directory
'/opt/module/data/log_orc' select substring(url,1,4) from log_orc;

- Parquet
insert overwrite local directory
'/opt/module/data/log_parquet' select substring(url,1,4) from log_parquet;

存储文件的查询速度总结:查询速度相近。
存储和压缩结合
测试存储和压缩
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
ORC 存储方式的压缩:

注意:所有关于 ORCFile 的参数都是在 HQL 语句的 TBLPROPERTIES 字段里面出现
- 创建一个 ZLIB 压缩的 ORC 存储方式
- (1)建表语句
create table log_orc_zlib(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="ZLIB");
- (2)插入数据
insert into log_orc_zlib select * from log_text;
- (3)查看表中数据大小
dfs -du -h /user/hive/warehouse/log_orc_zlib/;
2.8 M 8.3 M /user/hive/warehouse/log_orc_zlib/000000_0
- 创建一个 SNAPPY 压缩的 ORC 存储方式
- (1)建表语句
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="SNAPPY");
- (2)插入数据
insert into log_orc_snappy select * from log_text;
- (3)查看表中数据大小
dfs -du -h /user/hive/warehouse/log_orc_snappy/;
3.7 M 11.2 M /user/hive/warehouse/log_orc_snappy/000000_0
ZLIB 比 Snappy 压缩的还小。原因是 ZLIB 采用的是 deflate 压缩算法。比 snappy 压缩的压缩率高。
- 创建一个 SNAPPY 压缩的 parquet 存储方式
- (1)建表语句
create table log_parquet_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet
tblproperties("parquet.compression"="SNAPPY");
- (2)插入数据
insert into log_parquet_snappy select * from log_text;
- (3)查看表中数据大小
dfs -du -h /user/hive/warehouse/log_parquet_snappy;
6.4 M 19.2 M /user/hive/warehouse/log_parquet_snappy/000000_0
- 存储方式和压缩总结
在实际的项目开发当中,hive 表的数据存储格式一般选择:orc 或 parquet。压缩方式一般选择 snappy,lzo。
企业级调优
执行计划(Explain)
- 基本语法
EXPLAIN [FORMATTED|EXTENDED|DEPENDENCY|AUTHORIZATION|] query
- FORMATTED:formatted对执行计划进行格式化,
返回JSON格式的执行计划 - EXTENDED:extended提供一些额外的信息,比如文件的路径信息,
返回更加详细的执行计划 - DEPENDENCY:dependency以JSON格式
返回查询所依赖的表和分区的列表 - AUTHORIZATION:authorization
列出需要被授权的条目,包括输入与输出
- 组成
解析后的执行计划一般由三个部分构成,分别是:
- The Abstract Syntax Tree for the query
抽象语法树:Hive使用Antlr解析生成器,可以自动地将HQL生成为抽象语法树 - The dependencies between the different stages of the plan
Stage依赖关系:会列出运行查询所有的依赖以及stage的数量 - The description of each of the stages
Stage内容:包含了非常重要的信息,比如运行时的operator和sort orders等具体的信息
- 示例1:过滤
explain select count(*) as cnt from tb_emp where deptno = '10';


- 示例2:分组排序
explain
select
deptno,count(*) as cnt
from tb_emp where salary > 2000
group by deptno order by cnt desc;


- 详细解释
explain select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
Explain |
--------------------------------------------------------------------------------------------------+
STAGE DEPENDENCIES: |
Stage-1 is a root stage |
Stage-0 depends on stages: Stage-1
|
#stage -1是根阶段,stage -0在stage -1完成后执行(stage -0依赖于stage -1)
|
STAGE PLANS: |
Stage: Stage-1 |
Map Reduce |
Map Operator Tree: #Map操作 |
TableScan #表扫描 |
alias: emp #alias:表名称
#Statistics:表统计信息,包含表中数据条数,数据大小等 |
Statistics: Num rows: 1 Data size: 6610 Basic stats: COMPLETE Column stats: NONE |
Select Operator #选取操作
#expressions:需要的字段名称及字段类型
expressions: sal (type: double), deptno (type: int)
#输出的列名称
outputColumnNames: sal, deptno |
Statistics: Num rows: 1 Data size: 6610 Basic stats: COMPLETE Column stats: NONE |
Group By Operator #分组聚合操作 |
aggregations: avg(sal) #aggregations显示聚合函数信息 |
keys: deptno (type: int) #分组的字段 |
mode: hash #mode:聚合模式,hash表示随机聚合,partial局部聚合,final最终聚合
#聚合之后输出列名
outputColumnNames: _col0, _col1
#表统计信息(预估),包含分组聚合之后的数据条数,数据大小等
Statistics: Num rows: 1 Data size: 6610 Basic stats: COMPLETE Column stats: NONE |
Reduce Output Operator #输出到reduce操作 (Map操作将数据输出到reduce,并没有开始做reduce) |
# 在Map阶段和Reduce阶段输出的都是键值对的形式
# key expressions:Map阶段输出的键(key)所用的数据列
key expressions: _col0 (type: int) # |
sort order: + #分区排序,sort order值为空不排序;值为+升序排序;值为-降序排序;值为±排序的列为两列,第一列为升序,第二列为降序 |
#Map阶段输出到Reduce阶段的分区列
Map-reduce partition columns: _col0 (type: int) |
Statistics: Num rows: 1 Data size: 6610 Basic stats: COMPLETE Column stats: NONE|
#value expressions:Map阶段输出的值(value)所用的数据列
value expressions: _col1 (type: struct<count:bigint,sum:double,input:double>) |
Execution mode: vectorized #向量化模式,每次处理数据时会将1024行数据组成一个batch进行处理,而不是一行一行进行处理,显著提高执行速度 |
Reduce Operator Tree: #Reduce操作 |
Group By Operator #分组聚合操作 |
aggregations: avg(VALUE._col0) |
keys: KEY._col0 (type: int) |
mode: mergepartial #mergepartial合并多个Map的输出 若是complete完全模式,则表示Map端没有进行聚合 |
outputColumnNames: _col0, _col1 #聚合之后输出列名 |
Statistics: Num rows: 1 Data size: 6610 Basic stats: COMPLETE Column stats: NONE |
Filter Operator #过滤操作
#predicate:过滤条件
predicate: (_col1 > 2000.0D) (type: boolean) |
Statistics: Num rows: 1 Data size: 6610 Basic stats: COMPLETE Column stats: NONE |
File Output Operator #文件输出操作(Reduce端的输出,输出为一个临时文件) |
compressed: false #是否压缩 |
Statistics: Num rows: 1 Data size: 6610 Basic stats: COMPLETE Column stats: NONE |
table: #表的信息,包含输入输出文件格式,序列化方式 |
input format: org.apache.hadoop.mapred.SequenceFileInputFormat |
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat |
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
|
Stage: Stage-0 |
Fetch Operator #客户端获取数据操作 |
limit: -1 #-1表示不限制条数,其它值为限制的条数 |
Processor Tree: |
ListSink |
|
默认设置了hive.map.aggr=true(提高聚合的性能,这个设置会触发在map阶段做部分聚合),
所以会在mapper端先group by一次,最后再把结果merge(合并)起来,为了减少reducer处理的数据量。
如果把hive.mao.aggr=false,那将group by放到reducer才做。
Group By任务转化为MR任务的流程如下:
Map:生成键值对,以GROUP BY条件中的列作为Key,以聚集函数的结果作为Value
Shuffle:根据Key的值进行 Hash,按照Hash值将键值对发送至不同的Reducer中
Reduce:根据SELECT子句的列以及聚集函数进行Reduce
参考链接:Hive执行计划分析之group by执行计划分析
--A:
explain select e.*,d.* from emp e,dept d where e.deptno =d.deptno;
--B:
explain select * from emp e cross join dept d on e.deptno =d.deptno;
explain select * from emp e cross join dept d where e.deptno =d.deptno;
--可以发现这3条查询语句的执行计划是一样的
Explain |
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
STAGE DEPENDENCIES: |
Stage-4 is a root stage |
Stage-3 depends on stages: Stage-4 |
Stage-0 depends on stages: Stage-3 |
#stage -4是根阶段,stage -3在stage -4完成后执行,stage -0在stage -3完成后执行。
|
STAGE PLANS: |
Stage: Stage-4 |
#本地化的MapReduce:因为测试表的数据量非常小,所以Hive最终选择将数据拉取到本地直接操作,而不是去执行一个完整的分布式MapReduce
Map Reduce Local Work |
Alias -> Map Local Tables: |
$hdt$_1:d |
Fetch Operator |
limit: -1 |
Alias -> Map Local Operator Tree: |
$hdt$_1:d |
TableScan #表扫描 |
alias: d # alias:别名
#Statistics:表统计信息(预估),包含表中数据条数,数据大小等 |
Statistics: Num rows: 1 Data size: 730 Basic stats: COMPLETE Column stats: NONE
Filter Operator #过滤操作(join时null值不能关联,,在取数据时直接过滤掉了) |
#predicate过滤条件
predicate: deptno is not null (type: boolean) |
Statistics: Num rows: 1 Data size: 730 Basic stats: COMPLETE Column stats: NONE |
Select Operator #选取操作
#expressions:需要的字段名称及字段类型
expressions: deptno (type: int), dname (type: string), loc (type: int)
#输出的列名称
outputColumnNames: _col0, _col1, _col2 |
Statistics: Num rows: 1 Data size: 730 Basic stats: COMPLETE Column stats: NONE |
#将小表sink制作成hashmap,在下一个stage的map任务中 Map Join Operator进行连接。
HashTable Sink Operator |
keys: |
0 _col7 (type: int) |
1 _col0 (type: int) |
|
Stage: Stage-3 |
Map Reduce |
Map Operator Tree: |
TableScan |
alias: e |
Statistics: Num rows: 1 Data size: 6610 Basic stats: COMPLETE Column stats: NONE |
Filter Operator #过滤操作
#predicate过滤条件
predicate: deptno is not null (type: boolean) |
Statistics: Num rows: 1 Data size: 6610 Basic stats: COMPLETE Column stats: NONE |
Select Operator |
expressions: empno (type: int), ename (type: string), job (type: string), mgr (type: int), hiredate (type: string), sal (type: double), comm (type: double), deptno (type: int)|
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7 |
Statistics: Num rows: 1 Data size: 6610 Basic stats: COMPLETE Column stats: NONE |
Map Join Operator |
condition map: # condition map:join方式 |
Inner Join 0 to 1 |
keys: # keys: join的条件字段 |
0 _col7 (type: int) #第一张表输出的数据集 |
1 _col0 (type: int) #第二张表输出的数据集
#join完成之后输出的字段
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10 |
Statistics: Num rows: 1 Data size: 7271 Basic stats: COMPLETE Column stats: NONE |
File Output Operator #文件输出操作 |
compressed: false #是否压缩 |
Statistics: Num rows: 1 Data size: 7271 Basic stats: COMPLETE Column stats: NONE |
table: #表的信息,包含输入输出文件格式,序列化方式 |
input format: org.apache.hadoop.mapred.SequenceFileInputFormat |
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat |
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
Execution mode: vectorized |
Local Work: |
Map Reduce Local Work |
|
Stage: Stage-0 |
Fetch Operator #客户端获取数据操作 |
limit: -1 #-1表示不限制条数,其它值为限制的条数 |
Processor Tree: |
ListSink |
|
分布式缓存就是:Hadoop为MapReduce框架提供的一种分布式缓存机制,它会将需要缓存的文件分发到各个执行任务的子节点的机器中,各个节点可以自行读取本地文件系统上的数据进行处理。
首先启动一个本地的MR Local Task,会去读小表(根据表的元数据中的统计信息确定),
将小表的数据读入之后生成一个HashTable文件,
将该文件存入hadoop的分布式缓存中;然后启动一个Map任务,
将另外一个表的数据读入之后和上一步存入到入hadoop的分布式缓存中的HashTable文件进行join操作,查出数据。
第二张表一边map一边和缓存做join,不需要shuffle不需要reduce。
这种join是没有shuffle(shuffle:将相同的deptno分到一个reduce上去)进行网络传输的,是性能比较高的join方法。
参考链接:hive的JOIN和SQL执行计划解读
返回顶部
Fetch 抓取
- Fetch 抓取是指,
Hive 中对某些情况的查询可以不必使用 MapReduce 计算。例如:SELECT*FROM employees;在这种情况下,Hive 可以简单地读取 employee 对应的存储目录下的文件,然后输出查询结果到控制台。 - 在 hive-default.xml.template 文件中
hive.fetch.task.conversion默认是 more,老版本 hive默认是minimal,该属性修改为 more 以后,在全局查找、字段查找、limit 查找等都不走mapreduce。
none: disable hive.fetch.task.conversionminimal: SELECT STAR(*), 字段查找,FILTER on partition columns, LIMIT onlymore: SELECT*,字段查找, FILTER, LIMIT only (support TABLESAMPLE and virtual columns虚拟字段)
- 案例实操:
(1)把 hive.fetch.task.conversion 设置成 none,然后执行查询语句,都会执行 mapreduce程序。
set hive.fetch.task.conversion;
set hive.fetch.task.conversion=none;
select * from emp;
select ename from emp;
select ename from emp limit 3;
(2)把 hive.fetch.task.conversion 设置成 minimal,然后执行查询语句,如下查询方式都不会执行 mapreduce 程序。
set hive.fetch.task.conversion=minimal;
select * from emp;
select ename from emp;
select ename from emp limit 3;
select * from dept_partition where day='20200402'; --基于分区字段过滤
(2)把 hive.fetch.task.conversion 设置成 more,然后执行查询语句,如下查询方式都不会执行 mapreduce 程序。
set hive.fetch.task.conversion=more;
select * from emp;
select ename from emp;
select ename from emp limit 3;
select ename from emp where sal>2000;
select * from dept_partition where day='20200402'; --基于分区字段过滤,分区字段是虚拟字段
本地模式
- 使用Hive的过程中,有一些数据量不大的表也会转换为MapReduce处理,提交到集群时,需要申请资源,等待资源分配,启动JVM进程,再运行Task,一系列的过程比较繁琐,本身数据量并不大,提交到YARN运行返回会导致性能较差的问题。
- Hive为了解决这个问题,延用了MapReduce中的设计,提供本地计算模式,允许程序不提交给YARN,直接在本地运行,以便于提高小数据量程序的性能。
- 大多数的 Hadoop Job 是需要 Hadoop 提供的完整的可扩展性来处理大数据集的。不过,有时 Hive 的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际 job 的执行时间要多的多。对于大多数这种情况,
Hive 可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
用户可以通过设置 hive.exec.mode.local.auto 的值为 true,来让 Hive 在适当的时候自动启动这个优化。
--开启本地模式
set hive.exec.mode.local.auto=true; //开启本地 mr
//设置 local mr 的最大输入数据量,当输入数据量小于这个值时采用 local mr 的方式,默认为 134217728,即 128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//设置 local mr 的最大输入文件个数,当输入文件个数小于这个值时采用 local mr 的方式,默认为 4
set hive.exec.mode.local.auto.input.files.max=10;
- 案例实操:
- (1)关闭本地模式(默认是关闭的),并执行查询语句
select count(*) from emp group by deptno;

- (2)开启本地模式,并执行查询语句
set hive.exec.mode.local.auto=true;
select count(*) from emp group by deptno;

表的优化
小表大表 Join(MapJOIN)
-
将 key 相对分散,并且数据量小的表放在 join 的左边,可以使用 map join 让小的维度表先进内存。在 map 端完成 join。
-
实际测试发现:新版的 hive 已经对小表 JOIN 大表和大表 JOIN 小表进行了优化。小表放在左边和右边已经没有区别。
-
案例实操
- 需求介绍
测试大表 JOIN 小表和小表 JOIN 大表的效率 - 开启 MapJoin 参数设置
- (1)设置自动选择 Mapjoin
set hive.auto.convert.join = true; --默认为 true
- (2)大表小表的阈值设置(默认 25M 以下认为是小表)
set hive.mapjoin.smalltable.filesize = 25000000;
- MapJoin 工作机制

- 数据准备(一部分数据)
[hyj@hadoop102 datas]$ vim smalltable #10万条小表数据(12.4MB)
95048 20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http:456456www.123qiyi.com456
95096 20111230000005 66c5bb7774e31d0a22278249b26bc83a 凡人修仙传 3 1 http:456456www.123booksky.org456BookDetail.aspx?BookID=1050804&Level=1
95144 20111230000007 b97920521c78de70ac38e3713f524b50 本本联盟 1 1 http:456456www.123bblianmeng.com456
95192 20111230000008 6961d0c97fe93701fc9c0d861d096cd9 华南师范大学图书馆 1 1 http:456456lib.scnu.edu.cn456
95192 20111230000008 f2f5a21c764aebde1e8afcc2871e086f 在线代理 2 1 http:456456proxyie.cn456
95144 20111230000009 96994a0480e7e1edcaef67b20d8816b7 伟大导演 1 1 http:456456movie.douban.com456review4561128960456
95096 20111230000009 698956eb07815439fe5f46e9a4503997 youku 1 1 http:456456www.123youku.com456
95144 20111230000009 599cd26984f72ee68b2b6ebefccf6aed 安徽合肥365房产网 1 1 http:456456hf.house365.com456
95192 20111230000010 f577230df7b6c532837cd16ab731f874 哈萨克网址大全 1 1 http:456456www.123kz321.com456
95192 20111230000010 285f88780dd0659f5fc8acc7cc4949f2 IQ数码 1 1 http:456456www.123iqshuma.com456
[hyj@hadoop102 datas]$ vim bigtable #100万条大表数据(123MB)
0 20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http:456456www.qiyi.com456
0 20111230000005 66c5bb7774e31d0a22278249b26bc83a 凡人修仙传 3 1 http:456456www.booksky.org456BookDetail.aspx?BookID=1050804&Level=1
0 20111230000007 b97920521c78de70ac38e3713f524b50 本本联盟 1 1 http:456456www.bblianmeng.com456
0 20111230000008 6961d0c97fe93701fc9c0d861d096cd9 华南师范大学图书馆 1 1 http:456456lib.scnu.edu.cn456
0 20111230000009 599cd26984f72ee68b2b6ebefccf6aed 安徽合肥365房产网 1 1 http:456456hf.house365.com456
0 20111230000010 f577230df7b6c532837cd16ab731f874 哈萨克网址大全 1 1 http:456456www.kz321.com456
1 20111230000010 285f88780dd0659f5fc8acc7cc4949f2 IQ数码 1 1 http:456456www.iqshuma.com456
1 20111230000011 58e7d0caec23bcb4daa7bbcc4d37f008 张国立的电视剧 2 1 http:456456tv.sogou.com456vertical4562xc3t6wbuk24jnphzlj35zy.html?p=40230600
1 20111230000011 a3b83dc38b2bbc35660dffcab4ed9da8 吹暖花开嘎嘎吧 1 1 http:456456www.7183.info456
1 20111230000011 b89952902d7821db37e8999776b32427 怎么骂一个人不带脏字 1 1 http:456456wenwen.soso.com456z456q131927207.htm
1 20111230000011 7c54c43f3a8a0af0951c26d94a57d6c8 百度一下 你就知道 1 1 http:456456www.baidu.com456
2 20111230000012 1d374b57fbbc81aa0cc38e6f4efb88ec qq老头像 1 1 http:456456tui.qihoo.com45628302631456article_2893190.html
[hyj@hadoop102 datas]$ vim nullid #
\N 20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http:2879www.123qiyi.com/
\N 20111230000005 66c5bb7774e31d0a22278249b26bc83a 凡人修仙传 3 1 http:2879www.123booksky.org/BookDetail.aspx?BookID=1050804&Level=1
\N 20111230000007 b97920521c78de70ac38e3713f524b50 本本联盟 1 1 http:2879www.123bblianmeng.com/
\N 20111230000008 6961d0c97fe93701fc9c0d861d096cd9 华南师范大学图书馆 1 1 http:2879lib.scnu.edu.cn/
\N 20111230000008 f2f5a21c764aebde1e8afcc2871e086f 在线代理 2 1 http:2879proxyie.cn/
\N 20111230000009 96994a0480e7e1edcaef67b20d8816b7 伟大导演 1 1 http:2879movie.douban.com/review/1128960/
\N 20111230000009 698956eb07815439fe5f46e9a4503997 youku 1 1 http:2879www.123youku.com/
\N 20111230000009 599cd26984f72ee68b2b6ebefccf6aed 安徽合肥365房产网 1 1 http:2879hf.house365.com/
\N 20111230000010 f577230df7b6c532837cd16ab731f874 哈萨克网址大全 1 1 http:2879www.123kz321.com/
\N 20111230000010 285f88780dd0659f5fc8acc7cc4949f2 IQ数码 1 1 http:2879www.123iqshuma.com/
\N 20111230000010 f4ba3f337efb1cc469fcd0b34feff9fb 推荐待机时间长的手机 1 1 http:2879mobile.zol.com.cn/148/1487938.html
\N 20111230000010 3d1acc7235374d531de1ca885df5e711 满江红 1 1 http:2879baike.baidu.com/view/6500.htm
\N 20111230000010 dbce4101683913365648eba6a85b6273 光标下载 1 1 http:2879zhidao.baidu.com/question/38626533
- 创建大表、小表和 JOIN 后表的语句
//创建大表
create table bigtable(id bigint, t bigint, uid string, keyword string,
url_rank int, click_num int, click_url string) row format delimited
fields terminated by '\t';
// 创建小表
create table smalltable(id bigint, t bigint, uid string, keyword string,
url_rank int, click_num int, click_url string) row format delimited
fields terminated by '\t';
// 创建 join 后的表
create table jointable(id bigint, t bigint, uid string, keyword string,
url_rank int, click_num int, click_url string) row format delimited
fields terminated by '\t';
- 分别向大表和小表中导入数据
load data local inpath '/opt/module/data/bigtable' into table bigtable;
load data local inpath '/opt/module/data/smalltable' into table smalltable;
- 小表 JOIN 大表语句
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from smalltable s
join bigtable b
on b.id = s.id;
- 大表 JOIN 小表语句
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable b
join smalltable s
on s.id = b.id;
大表 Join 大表
空 KEY 过滤
有时 join 超时是因为某些 key 对应的数据太多,而相同 key 对应的数据都会发送到相同的 reducer 上,从而导致内存不够。此时我们应该仔细分析这些异常的 key,很多情况下,这些 key 对应的数据是异常数据,我们需要在 SQL 语句中进行过滤。例如 key 对应的字段为空,操作如下:
- 案例实操
- 配置历史服务器
(1)配置 mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
(2)启动历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver
(3)查看 jobhistory
http://hadoop102:19888/jobhistory
- 创建原始数据空 id 表
-- 创建空 id 表
create table nullidtable(id bigint, t bigint, uid string, keyword string,
url_rank int, click_num int, click_url string) row format delimited
fields terminated by '\t';
- 加载空 id 数据到nullidtable表中
load data local inpath '/opt/module/hive-3.1.2/datas/nullid' into table nullidtable;
- 测试不过滤空 id
insert overwrite table jointable
select n.* from
nullidtable n left join bigtable o on n.id = o.id;
Time taken: 72.529 seconds
- 测试过滤空 id
insert overwrite table jointable
select n.* from
(select * from nullidtable where id is not null) n left join bigtable o on n.id = o.id;
Time taken: 47.679 seconds
返回顶部
空 key 转换
有时虽然某个 key 为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join 的结果中,此时我们可以表 a 中 key 为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的 reducer 上。例如:
- 案例实操:
- 不随机分布空 null 值:
(1)设置 reduce 个数为5
set mapreduce.job.reduces = 5;
(2)JOIN 两张表
insert overwrite table jointable
select n.* from nullidtable n left join bigtable b on n.id = b.id;
结果:如下图所示,可以看出来,出现了数据倾斜,某些 reducer 的资源消耗远大于其他 reducer。

- 随机分布空 null 值
(1)设置reduce 个数为5
set mapreduce.job.reduces = 5;
(2)JOIN 两张表
insert overwrite table jointable
select n.* from nullidtable n full join bigtable o on
nvl(n.id,rand()) = o.id;
结果:如下图所示,可以看出来,消除了数据倾斜,负载均衡 reducer 的资源消耗

返回顶部
Map Join
- 应用场景
适合于小表join大表或者小表Join小表 - Hive中默认自动开启了Map Join
hive.auto.convert.join=true
- Hive中判断哪张表是小表及限制
LEFT OUTER JOIN的左表必须是大表
RIGHT OUTER JOIN的右表必须是大表
INNER JOIN左表或右表均可以作为大表
FULL OUTER JOIN不能使用MAPJOIN
MAPJOIN支持小表为子查询
使用MAPJOIN时需要引用小表或是子查询时,需要引用别名
在MAPJOIN中,可以使用不等值连接或者使用OR连接多个条件
在MAPJOIN中最多支持指定6张小表,否则报语法错误 - Hive中小表的大小限制
-- 2.0版本之前的控制属性
hive.mapjoin.smalltable.filesize=25M
-- 2.0版本开始由以下参数控制
--Hive是否支持根据输入文件大小进行普通join到mapjoin的转换优化。如果开启此参数,并且n-1个表/分区的大小之和小于指定大小后,join直接转换为mapjoin。
set hive.auto.convert.join.noconditionaltask = true;
-- n-way join的n-1个表/分区的大小之和小于这个大小,join直接转换为mapjoin
set hive.auto.convert.join.noconditionaltask.size = 10000000;
Reduce Join

- 应用场景
适合于大表Join大表 - 原理
将两张表的数据在shuffle阶段利用shuffle的分组来将数据按照关联字段进行合并
必须经过shuffle,利用Shuffle过程中的分组来实现关联 - 使用
Hive会自动判断是否满足Map Join,如果不满足Map Join,则自动执行Reduce Join
Bucket Join and SMB(Sort Merge Bucket join)
- 应用场景
适合于大表Join大表(大表Join的优化方案Bucket Join) - 原理
将两张表按照相同的规则将数据划分,根据对应的规则的数据进行join,减少了比较次数,提高了性能

返回顶部
(1)创建第二张大表
create table bigtable2(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/hive-3.1.2/datas/bigtable' into table bigtable2;
测试大表直接 JOIN
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable s
join bigtable2 b
on b.id = s.id;
Time taken: 69.475 seconds
(2)创建分通表 1,桶的个数不要超过可用 CPU 的核数
create table bigtable_buck1(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/hive-3.1.2/datas/bigtable' into table bigtable_buck1;
(3)创建分通表 2,桶的个数不要超过可用 CPU 的核数
create table bigtable_buck2(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/hive-3.1.2/datas/bigtable' into table bigtable_buck2;
- Bucket Join
(1)语法:clustered by colName
(2)参数:
-- 开启分桶join
set hive.optimize.bucketmapjoin = true;
(3)要求:分桶字段 = Join字段 ,桶的个数相等或者成倍数
(4)测试
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable_buck1 s
join bigtable_buck2 b
on b.id = s.id;
- Sort Merge Bucket Join(SMB):基于有序的数据Join
(1)语法:clustered by colName sorted by (colName)
(2)参数
-- 开启分桶SMB join
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join=true; --Will the join be automatically converted to a sort-merge join, if the joined tables pass the criteria for sort-merge join.
(3)要求:分桶字段 = Join字段 = 排序字段 ,桶的个数相等或者成倍数
(4)测试
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable_buck1 s
join bigtable_buck2 b
on b.id = s.id;
Group By
默认情况下,Map 阶段同一 Key 数据分发给同一个 reduce,当一个 key 数据过大时就倾斜了.

并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端进行部分聚合,最后在 Reduce 端得出最终结果。
- 开启 Map 端聚合参数设置
- (1)是否在 Map 端进行聚合,默认为 True
set hive.map.aggr = true
- (2)在 Map 端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000
- (3)有数据倾斜的时候进行负载均衡(默认是 false)
set hive.groupby.skewindata = true
当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
select deptno from emp group by deptno;
优化以后
set hive.groupby.skewindata = true;
select deptno from emp group by deptno;
Count(Distinct) 去重统计
数据量小的时候无所谓,数据量大的情况下,由于 COUNT DISTINCT 操作需要用一个Reduce Task 来完成,这一个 Reduce 需要处理的数据量太大,就会导致整个 Job 很难完成,一般 COUNT DISTINCT 使用先 GROUP BY 再 COUNT 的方式替换,但是需要注意 group by 造成的数据倾斜问题.
- 案例实操
(1)设置 5 个 reduce 个数
set mapreduce.job.reduces = 5;
(2)执行去重 id 查询
select count(distinct id) from bigtable;
(3)采用 GROUP by 去重 id
select count(id) from (select id from bigtable group by id) a;
虽然会多用一个 Job 来完成,但在数据量大的情况下,这个绝对是值得的。
笛卡尔积
尽量避免笛卡尔积,join 的时候不加 on 条件,或者无效的 on 条件,Hive 只能使用 1 个reducer 来完成笛卡尔积。
行列过滤
列处理:在 SELECT 中,只拿需要的列,如果有分区,尽量使用分区过滤,少用 SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在 Where 后面,那么就会先全表关联,之后再过滤,比如:
案例实操:
- 测试先关联两张表,再用 where 条件过滤
select o.id from bigtable b join bigtable o on o.id = b.id where o.id <= 10;
Time taken: 22.953 seconds, Fetched: 1081 row(s)
- 通过子查询后,再关联表
select b.id from bigtable b join (select id from bigtable where id <= 10) o on b.id = o.id;
Time taken: 21.575 seconds, Fetched: 1081 row(s)
返回顶部
合理设置 Map 及 Reduce 数
- 通常情况下,作业会通过 input 的目录产生一个或者多个 map 任务。
主要的决定因素有:input 的文件总个数,input 的文件大小,集群设置的文件块大小。 - 是不是 map 数越多越好?
答案是否定的。如果一个任务有很多小文件(远远小于块大小 128m),则每个小文件也会被当做一个块,用一个 map 任务来完成,而一个 map 任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的 map 数是受限的。 - 是不是保证每个 map 处理接近 128m 的文件块,就高枕无忧了?
答案也是不一定。比如有一个 127m 的文件,正常会用一个 map 去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果 map 处理的逻辑比较复杂,用一个 map任务去做,肯定也比较耗时。
针对上面的问题 2 和 3,我们需要采取两种方式来解决:即减少 map 数和增加 map 数;
复杂文件增加 Map 数
当 input 的文件都很大,任务逻辑复杂,map 执行非常慢的时候,可以考虑增加 Map 数,来使得每个 map 处理的数据量减少,从而提高任务的执行效率。增加 map 的方法为:根据
computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M 公式,
调整 maxSize 最大值。让 maxSize 最大值低于 blocksize 就可以增加 map 的个数。
案例实操:
- 执行查询
hive (default)> select count(*) from emp;
Hadoop job information for Stage-1: number of mappers: 1; number of
reducers: 1
- 设置最大切片值为 100 个字节
hive (default)> set mapreduce.input.fileinputformat.split.maxsize=100;
hive (default)> select count(*) from emp;
Hadoop job information for Stage-1: number of mappers: 6; number of
reducers: 1
小文件进行合并
- 在 map 执行前合并小文件,减少 map 数:CombineHiveInputFormat 具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat 没有对小文件合并功能。
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
- 在 Map-Reduce 的任务结束时合并小文件的设置:
- 在 map-only 任务结束时合并小文件,默认 true
-- 如果hive的程序,只有maptask,将MapTask产生的所有小文件进行合并
set hive.merge.mapfiles = true;
- 在 map-reduce 任务结束时合并小文件,默认 false
-- 如果hive的程序,有Map和ReduceTask,将ReduceTask产生的所有小文件进行合并
set hive.merge.mapredfiles = true;
- 合并文件的大小,默认 256M
-- 每一个合并的文件的大小
set hive.merge.size.per.task = 268435456;
- 当输出文件的平均大小小于该值时,启动一个独立的 map-reduce 任务进行文件 merge
--平均每个文件的大小,如果小于这个值就会进行合并
set hive.merge.smallfiles.avgsize = 16777216;
合理设置 Reduce 数
- 调整 reduce 个数方法一
- (1)每个 Reduce 处理的数据量默认是 256MB
hive.exec.reducers.bytes.per.reducer=256000000
- (2)每个任务最大的 reduce 数,默认为 1009
hive.exec.reducers.max=1009
- (3)计算 reducer 数的公式
N=min(参数 2,总输入数据量/参数 1)
- 调整 reduce 个数方法二
在 hadoop 的 mapred-default.xml 文件中修改
设置每个 job 的 Reduce 个数
set mapreduce.job.reduces = 15;
- reduce 个数并不是越多越好
(1)过多的启动和初始化 reduce 也会消耗时间和资源;
(2)另外,有多少个 reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
在设置 reduce 个数的时候也需要考虑这两个原则:处理大数据量利用合适的 reduce 数;使单个 reduce 任务处理数据量大小要合适;
并行执行
Hive 会将一个查询转化成一个或者多个阶段。这样的阶段可以是 MapReduce 阶段、抽样阶段、合并阶段、limit 阶段。或者 Hive 执行过程中可能需要的其他阶段。默认情况下,Hive 一次只会执行一个阶段。不过,某个特定的 job 可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个 job 的执行时间缩短。不过,如果有更多的阶段可以并行执行,那么 job 可能就越快完成。
通过设置参数 hive.exec.parallel 值为 true,就可以开启并行执行。不过,在共享集群中,需要注意下,如果 job 中并行阶段增多,那么集群利用率就会增加。
set hive.exec.parallel=true; //打开任务并行执行
set hive.exec.parallel.thread.number=16; //同一个 sql 允许最大并行度,默认为8。
--线程数越多,程序运行速度越快,但同样更消耗CPU资源
当然,得是在系统资源比较空闲的时候才有优势,否则,没资源,并行也起不来。
返回顶部
严格模式
Hive 可以通过设置防止一些危险操作:
- 分区表不使用分区过滤
将hive.strict.checks.no.partition.filter设置为 true 时,对于分区表,除非 where 语句中含有分区字段过滤条件来限制范围,否则不允许执行。换句话说,就是用户不允许扫描所有分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表。 - 使用 order by 没有 limit 过滤
将hive.strict.checks.orderby.no.limit设置为 true 时,对于使用了 order by 语句的查询,要求必须使用 limit 语句。因为 order by 为了执行排序过程会将所有的结果数据分发到同一个Reducer 中进行处理,强制要求用户增加这个 LIMIT 语句可以防止 Reducer 额外执行很长一段时间(开启了 limit 可以在数据进入到 reduce 之前就减少一部分数据)。 - 笛卡尔积
将hive.strict.checks.cartesian.product设置为 true 时,会限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在 执行 JOIN 查询的时候不使用 ON 语句而是使用 where 语句,这样关系数据库的执行优化器就可以高效地将 WHERE 语句转化成那个 ON 语句。不幸的是,Hive 并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。
Hive On Tez
Hive引擎的支持
- Hive作为数据仓库工具,底层的计算由分布式计算框架实现,目前Hive支持三种计算引擎,分别是MapReduce、Tez、Spark。Hive中默认的计算引擎是MapReduce,由
hive.execution.engine参数属性控制。 - Hive从2.x版本开始就提示未来的版本中将不再支持底层使用MapReduce,推荐使用Tez或者Spark引擎来代替MapReduce计算。如果依旧要使用MapReduce,需要使用Hive的1.x版本。
Tez的介绍
- Hive底层默认的的计算引擎为MapReduce,由于MapReduce的编程模型不够灵活,性能相对较差等问题,在实际使用Hive的过程中,我们建议将Hive的底层计算引擎更改为Tez或者Spark引擎。
- Tez是Apache社区中的一种
支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。最终Tez也会将程序提交给YARN来实现运行。 - 用 Hive 直接编写 MR 程序,假设有四个有依赖关系的 MR 作业,下图中,绿色是 Reduce Task,云状表示写屏蔽,需要将中间结果持久化写到 HDFS。Tez 可以将多个有依赖的作业转换为一个作业,这样只需写一次 HDFS,且中间节点较少,从而大大提升作业的计算性能。

- Apache Tez未来将替换MapReduce做为默认的Hive执行引擎。Hive3未来的版本将不再支持MapReduce。Tez通过有向无环图(DAG)和数据传输原语的表达式,在Tez下执行Hive查询可以提高性能。整体的执行过程如下图所示:

- Hive编译查询。
- Tez执行查询。
- YARN为集群中的应用程序分配资源,并为YARN队列中的Hive作业启用授权。
- Hive根据表类型更新HDFS或Hive仓库中的数据。
- Hive通过JDBC连接返回查询结果。
- 安装 Tez 引擎(了解)
- 将 tez 安装包上传到集群,并解压 tar 包
[hyj@hadoop102 module]$ mkdir tez
[hyj@hadoop102 module]$ tar -zxvf /opt/software/tez-0.10.1-SNAPSHOT-minimal.tar.gz -C ./tez/
- 上传 tez 依赖到 HDFS
[hyj@hadoop102 software]$ hadoop fs -mkdir /tez
[hyj@hadoop102 software]$ hadoop fs -put ./tez-0.10.1-SNAPSHOT.tar.gz /tez
- 配置Hadoop关联Tez
新建 tez-site.xml
[hyj@hadoop102 software]$ vim $HADOOP_HOME/etc/hadoop/tez-site.xml
添加如下内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.10.1-SNAPSHOT.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.am.resource.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.4</value>
</property>
<property>
<name>tez.task.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.task.resource.cpu.vcores</name>
<value>1</value>
</property>
</configuration>
将tez-site.xml分发给其它Hadoop节点
- 配置环境变量
[hyj@hadoop102 software]$ cd /opt/module/hadoop-3.1.3/etc/hadoop/shellprofile.d/
[hyj@hadoop102 shellprofile.d]$ ls
example.sh
[hyj@hadoop102 shellprofile.d]$ vim tez.sh
添加如下内容:
hadoop_add_profile tez
function _tez_hadoop_classpath
{
hadoop_add_classpath "$HADOOP_HOME/etc/hadoop" after
hadoop_add_classpath "/opt/module/tez/*" after
hadoop_add_classpath "/opt/module/tez/lib/*" after
}
- 修改 Hive 的计算引擎
[hyj@hadoop102 module]$ vim $HIVE_HOME/conf/hive-site.xml
添加如下内容:
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>1024</value>
</property>
- 解决日志 Jar 包冲突
[hyj@hadoop102 module]$ rm -fr /opt/module/tez/lib/slf4j-log4j12-1.7.10.jar
ORC文件索引
在使用ORC文件时,为了加快读取ORC文件中的数据内容,ORC提供了两种索引机制:Row Group Index 和 Bloom Filter Index可以帮助提高查询ORC文件的性能,当用户写入数据时,可以指定构建索引,当用户查询数据时,可以根据索引提前对数据进行过滤,避免不必要的数据扫描。
- Row Group Index
一个ORC文件包含一个或多个stripes(groups of row data),每个stripe中包含了每个column的min/max值的索引数据,当查询中有<,>,=的操作时,会根据min/max值,跳过扫描不包含的stripes。而其中为每个stripe建立的包含min/max值的索引,就称为Row Group Index行组索引,也叫min-max Index大小对比索引,或者Storage Index。
在建立ORC格式表时,指定表参数orc.create.index=true之后,便会建立Row Group Index,需要注意的是,为了使Row Group Index有效利用,向表中加载数据时,必须对需要使用索引的字段进行排序,否则,min/max会失去意义。另外,这种索引主要用于数值型字段的范围查询过滤优化上。
- 开启索引配置
set hive.optimize.index.filter=true;
永久生效,请配置在hive-site.xml中
- 创建表,并指定构建索引
create table smalltable_orc_index
stored as orc tblproperties("orc.create.index"="true")
as select * from smalltable
distribute by id
sort by id;
- 当进行范围或者等值查询(<,>,=)时就可以基于构建的索引进行查询
select count(*) from smalltable_orc_index where id > 95100;
- Bloom Filter Index
建表时候,通过表参数”orc.bloom.filter.columns”=”columnName……”来指定为哪些字段建立BloomFilter索引,这样,在生成数据的时候,会在每个stripe中,为该字段建立BloomFilter的数据结构,当查询条件中包含对该字段的=号过滤时候,先从BloomFilter中获取以下是否包含该值,如果不包含,则跳过该stripe。
- 创建表,并指定构建索引
create table smalltable_orc_bloom
stored as orc tblproperties("orc.create.index"="true","orc.bloom.filter.columns"="id,url_rank")
as select * from smalltable
distribute by id
sort by id;
- id的范围过滤可以走row group index,url_rank的过滤可以走bloom filter index
select
count(*)
from smalltable_orc_bloom
where id > 95100
and url_rank = '3' ;
ORC矢量化查询
Hive的默认查询执行引擎一次处理一行,而矢量化查询执行是一种Hive针对ORC文件操作的特性,目的是按照每批1024行读取数据,并且一次性对整个记录整合(而不是对单条记录)应用操作,提升了像过滤, 联合, 聚合等等操作的性能。
注意:要使用矢量化查询执行,就必须以ORC格式存储数据。
- 配置
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
JVM重用
- JVM正常指代一个Java进程,Hadoop默认使用派生的JVM来执行map-reducer,如果一个MapReduce程序中有100个Map,10个Reduce,
Hadoop默认会为每个Task启动一个JVM来运行,那么就会启动100个JVM来运行MapTask,在JVM启动时内存开销大,尤其是Job大数据量情况,如果单个Task数据量比较小,也会申请JVM资源,这就导致了资源紧张及浪费的情况。 - 为了解决上述问题,MapReduce中提供了JVM重用机制来解决,JVM重用可以使得JVM实例在同一个job中重新使用N次,当一个Task运行结束以后,JVM不会进行释放,而是继续供下一个Task运行,直到运行了N个Task以后,就会释放,N的值可以在Hadoop的mapred-site.xml文件中进行配置,通常在10-20之间。
- 配置
-- Hadoop3之前的配置,在mapred-site.xml中添加以下参数
-- Hadoop3中已不再支持该选项
mapreduce.job.jvm.numtasks=10
多重模式
如果你碰到一堆 SQL,并且这一堆 SQL 的模式还一样。都是从同一个表进行扫描,做不同的逻辑。有可优化的地方:如果有 n 条 SQL,每个 SQL 执行都会扫描一次这张表。
insert .... select id,name,sex, age from student where age > 17;
insert .... select id,name,sex, age from student where age > 18;
insert .... select id,name,sex, age from student where age > 19;
隐藏了一个问题:这种类型的 SQL 有多少个,那么最终。这张表就被全表扫描了多少次
insert into t_ptn partition(city=A). select id,name,sex, age from student
where city= A;
insert into t_ptn partition(city=B). select id,name,sex, age from student
where city= B;
insert into t_ptn partition(city=c). select id,name,sex, age from student
where city= c;
修改为:
from student
insert into t_ptn partition(city=A) select id,name,sex, age where city= A
insert into t_ptn partition(city=B) select id,name,sex, age where city= B
如果一个 HQL 底层要执行 10 个 Job,那么能优化成 8 个一般来说,肯定能有所提高,多重插入就是一个非常实用的技能。一次读取,多次插入,有些场景是从一张表读取数据后,要多次利用。
in/exists 语句
在 Hive 的早期版本中,in/exists 语法是不被支持的,但是从 hive-0.8x 以后就开始支持这个语法。但是不推荐使用这个语法。虽然经过测验,Hive-2.3.6 也支持 in/exists 操作,但还是推荐使用 Hive 的一个高效替代方案:left semi join
比如说:-- in / exists 实现
select a.id, a.name from a where a.id in (select b.id from b);
select a.id, a.name from a where exists (select id from b where a.id = b.id);
可以使用 join 来改写:
select a.id, a.name from a join b on a.id = b.id;
应该转换成:
– left semi join 实现
select a.id, a.name from a left semi join b on a.id = b.id;
CBO优化器引擎
- 在使用MySQL或者Hive等工具时,我们经常会遇到一个问题,默认的优化器在底层解析一些聚合统计类的处理的时候,底层解析的方案有时候不是最佳的方案。
- 例如:当前有一张表【共1000条数据】,id构建了索引,id =100值有900条,我们现在的需求是查询所有id = 100的数据,所以SQL语句为:select * from table where id = 100;
由于id这一列构建了索引,索引默认的优化器引擎RBO,会选择先从索引中查询id = 100的值所在的位置,再根据索引记录位置去读取对应的数据,但是这并不是最佳的执行方案。有id=100的值有900条,占了总数据的90%,这时候是没有必要检索索引以后再检索数据的,可以直接检索数据返回,这样的效率会更高,更节省资源,这种方式就是CBO优化器引擎会选择的方案。 - 使用Hive时,Hive中也支持RBO与CBO这两种引擎,默认使用的是RBO优化器引擎。
- RBO
rule basic optimise:基于规则的优化器
根据设定好的规则来对程序进行优化 - CBO
cost basic optimise:基于代价的优化器
根据不同场景所需要付出的代价来合适选择优化的方案
对数据的分布的信息【数值出现的次数,条数,分布】来综合判断用哪种处理的方案是最佳方案
很明显CBO引擎更加智能,所以在使用Hive时,我们可以配置底层的优化器引擎为CBO引擎。
- 配置
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
set hive.stats.fetch.partition.stats=true;
- 要求
要想使用CBO引擎,必须构建数据的元数据【表行数、列的信息、分区的信息……】
提前获取这些信息,CBO才能基于代价选择合适的处理计划
所以CBO引擎一般搭配analyze分析优化器一起使用
Analyze分析优化器
- 功能
用于提前运行一个MapReduce程序将表或者分区的信息构建一些元数据【表的信息、分区信息、列的信息】,搭配CBO引擎一起使用 - 语法
-- 构建分区信息元数据
ANALYZE TABLE tablename
[PARTITION(partcol1[=val1], partcol2[=val2], ...)]
COMPUTE STATISTICS [noscan];
-- 构建列的元数据
ANALYZE TABLE tablename
[PARTITION(partcol1[=val1], partcol2[=val2], ...)]
COMPUTE STATISTICS FOR COLUMNS ( columns name1, columns name2...) [noscan];
-- 查看元数据
DESC FORMATTED [tablename] [columnname];
- 举例
- 构建表中分区数据的元数据信息
ANALYZE TABLE tb_login_part PARTITION(logindate) COMPUTE STATISTICS;
- 构建表中列的数据的元数据信息
ANALYZE TABLE tb_login_part COMPUTE STATISTICS FOR COLUMNS userid;
- 查看构建的列的元数据
desc formatted tb_login_part userid;

谓词下推(PPD)
基本思想
谓词下推 Predicate Pushdown(PPD)的思想简单点说就是在不影响最终结果的情况下,尽量将过滤条件提前执行。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,降低了Reduce端的数据负载,节约了集群的资源,也提升了任务的性能。
基本规则
- 开启参数
-- 默认自动开启谓词下推
hive.optimize.ppd=true;
- 不同Join场景下的Where谓词下推测试
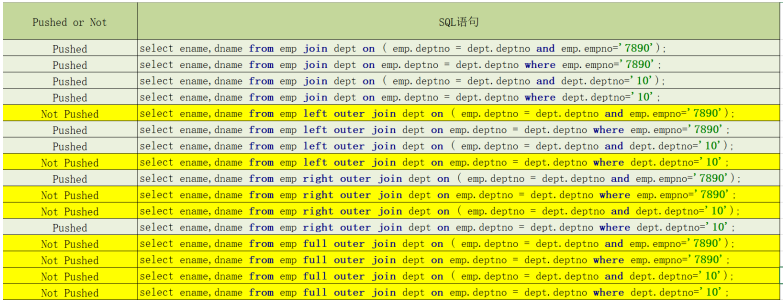
- 试验结论

- Inner Join和Full outer Join,条件写在on后面,还是where后面,性能上面没有区别
- Left outer Join时 ,右侧的表写在on后面,左侧的表写在where后面,性能上有提高
- Right outer Join时,左侧的表写在on后面、右侧的表写在where后面,性能上有提高
- 如果SQL语句中出现不确定结果的函数,也无法实现下推
数据倾斜(重点)
绝大部分任务都很快完成,只有一个或者少数几个任务执行的很慢甚至最终执行失败,这样的现象为数据倾斜现象。- 一定要和数据过量导致的现象区分开,数据过量的表现为所有任务都执行的很慢,这个
时候只有提高执行资源才可以优化 HQL 的执行效率。 - 综合来看,导致数据倾斜的原因在于
按照 Key 分组以后,少量的任务负责绝大部分数据的计算,也就是说产生数据倾斜的 HQL 中一定存在分组操作,那么从 HQL 的角度,我们可以将数据倾斜分为单表携带了 GroupBy 字段的查询和两表(或者多表)Join 的查询。
单表数据倾斜优化
使用参数
当任务中存在 GroupBy 操作同时聚合函数为 count 或者 sum 可以设置参数来处理数据倾斜问题
--是否在 Map 端进行聚合,默认为 True
set hive.map.aggr = true; --通过减少Reduce的输入量,避免每个Task数据差异过大导致数据倾斜
--在 Map 端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000;
有数据倾斜的时候进行负载均衡(默认是 false),当选项设定为 true,生成的查询计划会有两个 MR Job。
set hive.groupby.skewindata = true;
自动构建随机分区并自动聚合
-- 开启随机分区,走两个MapReduce
hive.groupby.skewindata=true;
- 开启该参数以后,当前程序会自动通过两个MapReduce来运行
- 第一个MapReduce自动进行随机分布到reducer中,每个Reducer做部分聚合操作,输出结果
- 第二个MapReduce将上一步聚合的结果再按照业务(group by key)进行处理,保证相同的分布到一起,最终聚合得到结果
增加 Reduce 数量(多个 Key 同时导致数据倾斜)
- 调整 reduce 个数方法一
- (1)每个 Reduce 处理的数据量默认是 256MB
set hive.exec.reducers.bytes.per.reducer = 256000000
- (2)每个任务最大的 reduce 数,默认为 1009
set hive.exec.reducers.max = 1009
- (3)计算 reducer 数的公式
N=min(参数 2,总输入数据量/参数 1)(参数 2 指的是上面的 1009,参数 1 值得是 256M)
- 调整 reduce 个数方法二
在 hadoop 的 mapred-default.xml 文件中修改
设置每个 job 的 Reduce 个数
set mapreduce.job.reduces = 15;
Join 数据倾斜优化
实际业务需求中往往需要构建两张表的Join实现,如果两张表比较大,无法实现Map Join,只能走Reduce Join,那么当关联字段中某一种值过多的时候依旧会导致数据倾斜的问题,面对Join产生的数据倾斜,我们核心的思想是尽量避免Reduce Join的产生,优先使用Map Join来实现,但往往很多的Join场景不满足Map Join的需求,那么我们可以以下几种方案来解决Join产生的数据倾斜问题:
- 方案一:提前过滤,将大数据变成小数据,实现Map Join
实现两张表的Join时,我们要尽量考虑是否可以使用Map Join来实现Join过程。有些场景下看起来是大表Join大表,但是我们可以通过转换将大表Join大表变成大表Join小表,来实现Map Join。
例如:现在有两张表订单表A与用户表B,需要实现查询今天所有订单的用户信息,关联字段为userid。
A表:今天的订单,1000万条,字段:orderId,userId,produceId,price等
B表:用户信息表,100万条,字段:userid,username,age,phone等
需求:两张表关联得到今天每个订单的用户信息
实现1:直接关联,实现大表Join大表
select a.*,b.* from A join B on a.userid = b.userid;
由于两张表比较大,无法走Map Join,只能走Reduce Join,容易产生数据倾斜。
实现2:将下了订单的用户的数据过滤出来,再Join
select a.*,d.*
from (
select a.*,d.*
from (
-- 获取所有下订单的用户信息
select
b.*
from
-- 获取所有下订单的userid
( select distinct a.userid from A a ) c join B b on c.userid = b.userid ) d
join
A a on d.userid = a.userid;
- 100万个用户中,在今天下订单的人数可能只有一小部分,大量数据是不会Join成功的
- 可以提前将订单表中的userid去重,获取所有下订单的用户id
- 再使用所有下订单的用户id关联用户表,得到所有下订单的用户的信息
- 最后再使用下订单的用户信息关联订单表
通过多次Map Join来代替Reduce Join,性能更好也可以避免数据倾斜
- 方案二:使用Bucket Join
如果使用方案一来避免Reduce Join ,有些场景下依旧无法满足,例如过滤后的数据依旧是一张大表,那么最后的Join依旧是一个Reduce Join
这种场景下,我们可以将两张表的数据构建为桶表,实现Bucket Map Join,避免数据倾斜
使用参数
- Skew Join是Hive中一种专门为了避免数据倾斜而设计的特殊的Join过程,这种Join的原理是将Map Join和Reduce Join进行合并,如果某个值出现了数据倾斜,就会将产生数据倾斜的数据单独使用Map Join来实现,其他没有产生数据倾斜的数据由Reduce Join来实现,这样就避免了Reduce Join中产生数据倾斜的问题,最终将Map Join的结果和Reduce Join的结果进行Union合并。
在编写 Join 查询语句时,如果确定是由于 join 出现的数据倾斜,那么请做如下设置:
# join 的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.skewjoin.key=100000;
# 如果是 join 过程出现倾斜应该设置为 true
set hive.optimize.skewjoin=false;
如果开启了,在 Join 过程中 Hive 会将计数超过阈值 hive.skewjoin.key(默认 100000)的倾斜 key 对应的行临时写进文件中,然后再启动另一个 job 做 map join 生成结果。
通过hive.skewjoin.mapjoin.map.tasks 参数还可以控制第二个 job 的 mapper 数量,默认 10000。
set hive.skewjoin.mapjoin.map.tasks=10000;
MapJoin
详情看上面↑Bucket Join and SMB(Sort Merge Bucket join)
Hive On Spark
Executor 参数
以单台服务器 128G 内存,32 线程为例。
spark.executor.cores
- 该参数表示每个 Executor 可利用的 CPU 核心数。其值不宜设定过大,因为 Hive 的底层以 HDFS 存储,而 HDFS 有时对高并发写入处理不太好,容易造成 race condition。根据经验实践,设定在 3~6 之间比较合理。
- 我们使用的服务器单节点有 32 个 CPU 核心可供使用。考虑到系统基础服务和 HDFS等组件的余量,一般会将 YARN NodeManager 的
yarn.nodemanager.resource.cpu-vcores 参数设为 28,也就是 YARN 能够利用其中的 28 核,此时将 spark.executor.cores 设为 4 最合适,最多可以正好分配给 7 个 Executor 而不造成浪费。又假设 yarn.nodemanager.resource.cpuvcores 为 26,那么将 spark.executor.cores 设为 5 最合适,只会剩余 1 个核。 - 由于一个 Executor 需要一个 YARN Container 来运行,所以还需保证 spark.executor.cores的值不能大于单个 Container 能申请到的最大核心数,即 yarn.scheduler.maximum-allocation-vcores 的值。
spark.executor.memory/spark.yarn.executor.memoryOverhead
- 这两个参数分别表示
每个 Executor 可利用的堆内内存量和堆外内存量。堆内内存越大,Executor 就能缓存更多的数据,在做诸如 map join 之类的操作时就会更快,但同时也会使得GC 变得更麻烦。spark.yarn.executor.memoryOverhead 的默认值是 executorMemory * 0.10,最小值为 384M(每个 Executor) - Hive 官方提供了一个计算 Executor 总内存量的经验公式,如下:
yarn.nodemanager.resource.memory-mb*(spark.executor.cores/yarn.nodemanager.resource.cpu-vcores)
其实就是按核心数的比例分配。在计算出来的总内存量中,80%~85%划分给堆内内存,剩余的划分给堆外内存。 - 假设集群中单节点有 128G 物理内存,yarn.nodemanager.resource.memory-mb(即单个NodeManager 能够利用的主机内存量)设为 100G,那么每个 Executor 大概就是 100*(4/28)=约 14G。
再 按 8:2 比 例 划 分 的 话 , 最 终 spark.executor.memory 设 为 约 11.2G ,spark.yarn.executor.memoryOverhead 设为约 2.8G。 - 通过这些配置,每个主机一次可以运行多达 7 个 executor。每个 executor 最多可以运行4 个 task(每个核一个)。因此,每个 task 平均有 3.5 GB(14 / 4)内存。在 executor 中运行的所有 task 共享相同的堆空间。
set spark.executor.memory=11.2g;
set spark.yarn.executor.memoryOverhead=2.8g;
同理,这两个内存参数相加的总量也不能超过单个 Container 最多能申请到的内存量, 即 yarn.scheduler.maximum-allocation-mb 配置的值。
spark.executor.instances
该参数表示执行查询时一共启动多少个 Executor 实例,这取决于每个节点的资源分配情况以及集群的节点数。若我们一共有 10 台 32C/128G 的节点,并按照上述配置(即每个节点承载 7 个 Executor),那么理论上讲我们可以将 spark.executor.instances 设为 70,以使集群资源最大化利用。但是实际上一般都会适当设小一些(推荐是理论值的一半左右,比如 40),因为 Driver 也要占用资源,并且一个 YARN 集群往往还要承载除了 Hive on Spark 之外的其他业务。
spark.dynamicAllocation.enabled
上面所说的固定分配 Executor 数量的方式可能不太灵活,尤其是在 Hive 集群面向很多用户提供分析服务的情况下。所以更推荐将 spark.dynamicAllocation.enabled 参数设为 true,以启用 Executor 动态分配。
参数配置样例参考
set hive.execution.engine=spark;
set spark.executor.memory=11.2g;
set spark.yarn.executor.memoryOverhead=2.8g;
set spark.executor.cores=4;
set spark.executor.instances=40;
set spark.dynamicAllocation.enabled=true;
set spark.serializer=org.apache.spark.serializer.KryoSerializer;
Driver 参数
spark.driver.cores
该参数表示每个 Driver 可利用的 CPU 核心数。绝大多数情况下设为 1 都够用。
spark.driver.memory/spark.driver.memoryOverhead
这两个参数分别表示每个 Driver 可利用的堆内内存量和堆外内存量。根据资源富余程度和作业的大小,一般是将总量控制在 512MB~4GB 之间,并且沿用 Executor 内存的“二八分配方式”。例如,spark.driver.memory 可以设为约 819MB,spark.driver.memoryOverhead 设为约 205MB,加起来正好 1G。















 551
551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









