







By Mejias
背景:
应团队的PMP的要求,为自己的Team开发了一个内部网站信息抓取的工具(整体代码展示见文章末尾,可能稍微有点长)。上上周周写完测试后推给了大家,没有什么问题。今天Team的一个小伙伴突然告诉我报错,显示是Chrome Driver与Chrome版本不对,搜索Chrome://version,才发现是Chrome自动升级了。这样原来版本的Chrome driver就不支持了,导致程序报错。
在Chrome Driver官网here重新搜索了版本匹配的Chrome Driver并下载安装好之后,再次运行程序,发现前面都运行的很好直到后面首尾部分报错如下:

报错显示的是下面这里出了问题:
def control_in_shadow(driver,js):
shadow = driver.execute_script(js)
return shadow #返回的对象在这里
js = 'return document.querySelector("#ra-shadow-root").shadowRoot'
shadow= control_in_shadow(driver,js)
shadow.find_element(By.ID,'ra-asin-list-count-input').clear()
shadow.find_element(By.ID,'ra-asin-list-count-input').send_keys('1000')
shadow.find_element(By.ID,'ra-asin-list-load-btn').click()上面的代码访问下列Shadow Doml里的元素。
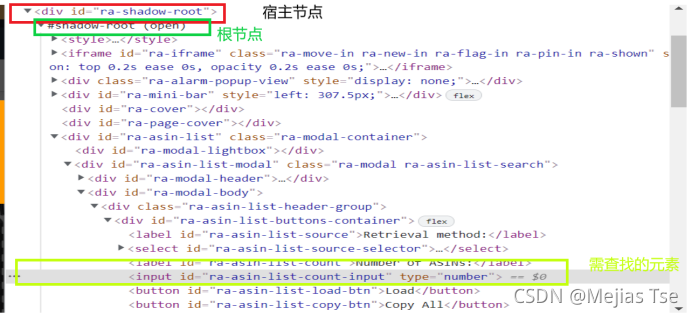
采用的方法就是常说的三步法:
定位到Shadow Dom的Host节点 =》 使用.shadowRoot属性定位到根节点 =》
直接通过页面Element的方法访问Shadow Dom内部的元素。这种方法在未更新chrome driver 的版本之前一直用的很好的。
但是在更新了Chrome版本和chrome driver版本之后就会报错了。原来的方法在新的chrome driver并不适用。于是在收到小伙伴的反馈后,就需要测试代码问题以及修改和Refine了。
测试&发现问题:
首先根据上面的报错可以定位到是下面的代码出了问题。
def control_in_shadow(driver,js):
shadow = driver.execute_script(js)
return shadow #返回的对象在这里
js = 'return document.querySelector("#ra-shadow-root&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









