







SQLServer笔记
SQLServer
基础知识
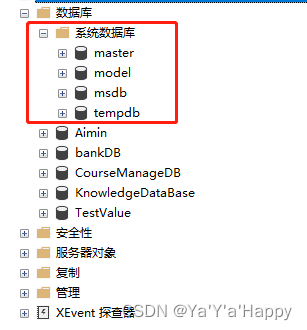
-
master:系统数据库,数据库的数据库,用来储存数据库信息和管理数据库
-
model:数据库的模板
-
msdb:数据库的代理
-
tempdb:临时数据库,临时的数据产生会存在这里
在执行某一段SQL语句时,可以手动选择对应的数据库去执行
基于脚本创建数据库
先判断是否存在这个数据库,如果存在就删除,避免重复创建
这个方法仅限于测试时使用,在项目部署前需要删除这行代码,避免数据库及数据
- drop database删除数据库,该方法一般不可撤销
if exists(select*from sysdatabases where name='TestDB')
drop database TestDB
go
- 数据文件初始大小:建议创建的时候根据情况选择合适的大小,如果太小会很容易不够用,太大会影响访问速度,虽然可以通过数据文件增长量来进行自动扩容,但是不要指望自动扩容来扩增文件内存大小。
create database TestDB
on primary
(
--数据库文件的逻辑名(数据库管理系统用的,名称必须是唯一的,不可以重复)
name='TestDB_data',
--数据库的物理文件名(绝对路径)
filename='D:\SqlDB\TestDB_data.mdf',--主数据文件
--数据文件初始大小
size=20MB,--实际开发中,要根据需要设置合理的大小
--数据文件增长量(当数据文件储存空间不够用时,会以增长量的大小去自动调整大小,但是建议不要指望这个增长)
filegrowth=5MB
)
,
(
name='TestDB_data1',--次要数据文件名
filename='D:\SqlDB\TestDB_data1.ndf',--次要数据文件
--(可以根据项目需求扩展多个或者一个,可以放在不同的磁盘内)
size=20MB,
filegrowth=5MB
)
log on
(
name='TestDB_log',--日志数据文件名
filename='D:\SqlDB\TestDB_log.log',--日志数据文件
--(可以根据项目需求扩展多个或者一个,可以放在不同的磁盘内)
size=10MB,
filegrowth=1MB
)
go
--点击“执行”完成创建
- 当需要删除数据库时,需要线勾选“关闭现有连接”避免其他正在连接使用数据库引发的冲突
基于脚本创建数据表
创建表
-
关键字 primary key主键约束
-
一般设置数据表的主键时必须的,以便于后期的索引
--指向要操作的数据库
use TestDB
go
if exists(select*from sysobjects where name='TestMarstData')--判断数据表Teacher是否已经存在
drop table TestMarstData
go
create table TestMarstData --关键字create(创建)
(
TestMarstId int primary key,--列的规范:列名称 数据类型 各种约束
TestMarstName varchar(20)not null
)
go
-
关键字unique:为避免内容重复,可使用unique来设定唯一约束,例如ID,物料号码
-
关键字default:当不确定内容时可以使用关键字default添加默认约束,当未写入数据时,将会以默认值进行写入
-
关键字identity:标识列:自动增长列
-
使用场合:如果你需要设计一个字段是自动增长的字段,那你就可以直接使用。
如果你的数据表的列,没有能够唯一区分的列,这时候,我们可以使用自动增长列(本质是没有什么特殊意义) 仅仅是为了区别而已。同时,也会再给当前列设置主键约束。 主键:不仅唯一,重要的影响数据的索引。 -
identity(标识种子,增长量)
-
注意问题:使用普通的delete删除数据后,标识列不会自动补全的。
比如:100005 100006(被删除) 1000007
-
-
关键字:references外键约束。当添加一行数据时,他会参考关联的外键里的值,格式为:内键约束属性名称 数据类型 references 外键数据表名称(关联外键属性名称) 为了后期代码的编写一般建议内键和外键名称相同
if exists(select*from sysobjects where name='TestValue')--判断数据表Teacher是否已经存在
drop table TestValue
go
create table TestValue --关键字create(创建)
(
TestValueId int identity(10000,1)primary key,--标识列/自动增长列
TestValueName varchar(20)not null,
TestValuePar char(3)check(TestValuePar='OK'or TestValuePar='NOK'), --check检查约束,如果添加了条件外的其他数据是无法添加进去的
DataTestValue datetime not null,
--numeric(6,0) 一共6位数,小数点0位
--TestValueIdNo numeric(6,0)check (len(TestValueIdNo)=6)unique,--unique唯一约束
TestValueIdNo char(6)check (len(TestValueIdNo)=6)unique,--unique唯一约束
TeatValueNumber int check(TeatValueNumber>0 and TeatValueNumber<32767),
TeatValuePos nvarchar(50)default('没有测试数据'),--default是默认约束
TestMarstId int references TestMarstData(TestMarstId)--外键约束,要求:列的数据类型和长度和主键对应的字段必须一致
)
go
在创建的时候切记要计算好所需字符的长度,不然后期插入的数据超过定义的长度会报错。
如下所示,在使用SQLServer语句插入的时候发现报错,后来检查发现是创建的时候没有计算好字符长度,这样在创建的时候并不会报错,但是在使用的时候会报错
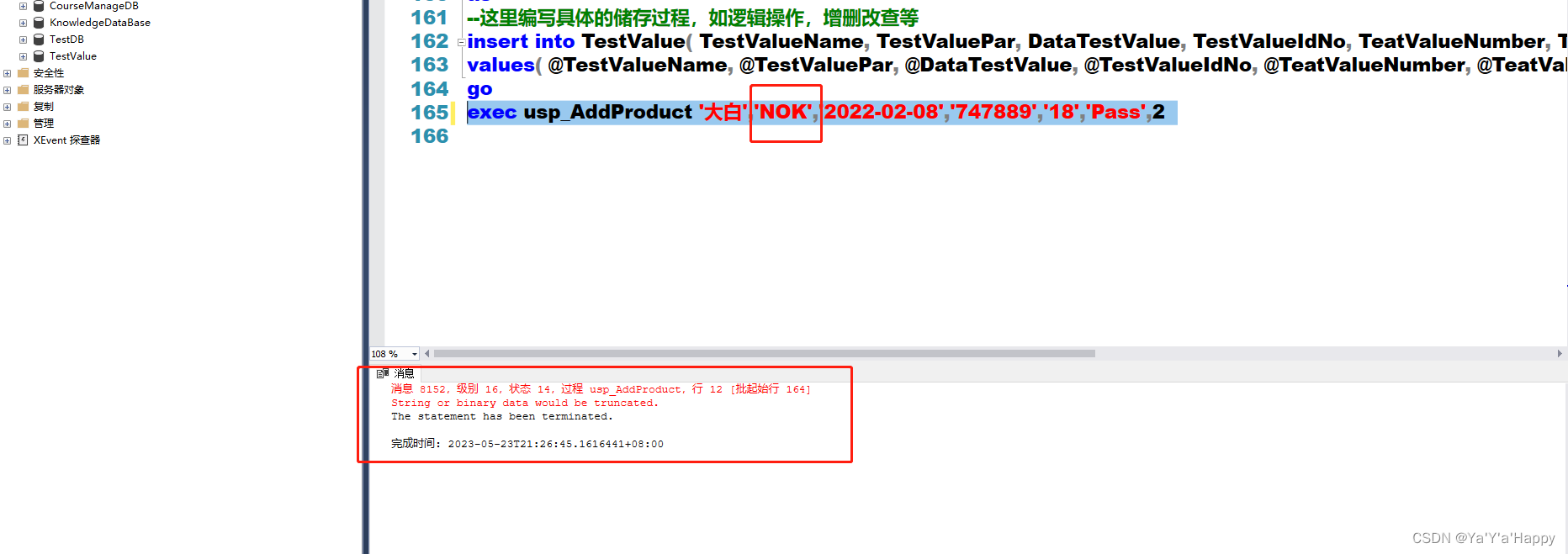
可以看出,由于创建的时候长度不适当没所以在使用的时候会报错。
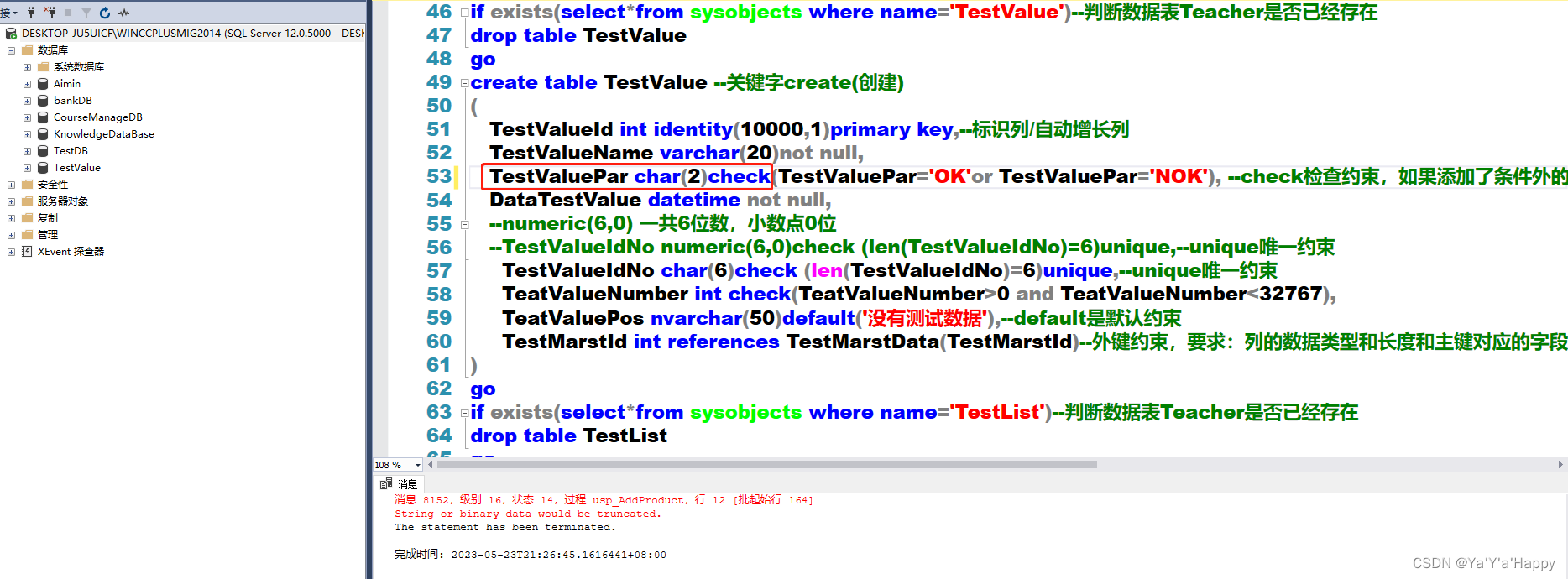
- 关键字 getdate:内置函数,用来获取当前时间
if exists(select*from sysobjects where name='TestList')--判断数据表Teacher是否已经存在
drop table TestList
go
create table TestList
(
Id int identity(1,1)primary key,
TestValueId int references TestValue(TestValueId),
UpdateTime datetime default(getdate())--内置函数获取当前时间
)
go

关于约束
1、为什么要使用约束?也就是约束是保证数据有效性,和正确性的最后一个屏障。(应用程序验证也是保证数据合法性)
2、约束类型:
-
主键约束–>要求唯一、并且不能为null,数据存储默认会参考主键约束。用来保证数据唯一的最好方法。
-
标识列–》自定维护的,也是唯一的。标识列一般都会和主键挂钩,当我们不能够选出一个字段作为主键的时候,可以使用。
注意不能为标识列显示的插入值。
常见错误:当 IDENTITY_INSERT 设置为 OFF 时,不能为表 ‘Students’ 中的标识列插入显式值。
以上两者都是为了保证实体(数据)唯一能够区分的。保证某一行的。
-
检查约束Check:保证某一列的字段值,在我们希望的范围内。
-
默认约束default:就是给某一个字段提供一个默认的数据。
-
外键约束foreign key :主要是表直接的关联约束。比如我们在外键表中插入数据的时候,外键的值(比如TestValue表中的TestValueId)会自动的和关联的主键表(StudentClass)中的对应主键ClassId做检查,也就是说你在外键表中插入的外键数据必须在主键表中存在。否则就会出错。
插入数据
- 自动增长列primary key类型的列名不需要手动添加,会根据顺序自动添加
- “ * ”符号代表所有通配符,一般在测试的时候使用,在实际开发中是不使用的
insert into TestMarstData(TestMarstId,TestMarstName)values(1,'老虎'),(2,'大象');
select *from TestMarstData
- 由于TestValue表中的TestMarstId和TestMarstData表中的TestMarstId内外键关系,所以如果TestMarstData表中没有对应的外键,则TestValue表将会插入失败
insert into TestValue(TestValueName,TestValuePar,DataTestValue,TestValueIdNo,TeatValueNumber,TeatValuePos,TestMarstId)
values('大耳朵','OK','2022-02-02','654327','10',default,2);
- 由于TestList表中UpdateTime使用了getdate所以他在写入的时候会自动获取时间
insert into TestList(TestValueId)values(10000);
select*from TestList
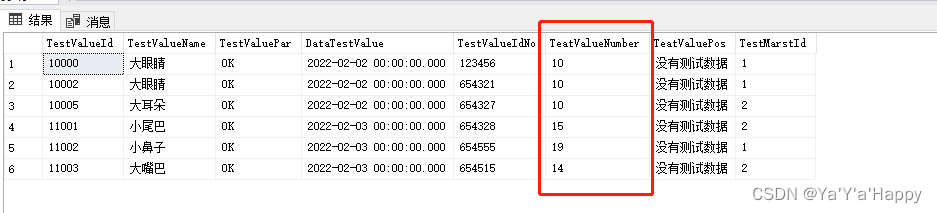
- 下图中的自动增长标识列10000,后面直接是10002,并没有出现10001,是因为当插入数据出现错误时,自动增长标识列也会产生,但是因为数据出错,所以并不会有数据插入进数据库,一直到插入正确的数据时,他会略过所有的出错标识列依次往下排序

基础查询操作
1.基本查询
- 查询表内内容为null的列名
- TestValue表内TeatValuePos列为空的数据
select *from TestValue where TeatValuePos is null;
- 查询列表中的前3条数据
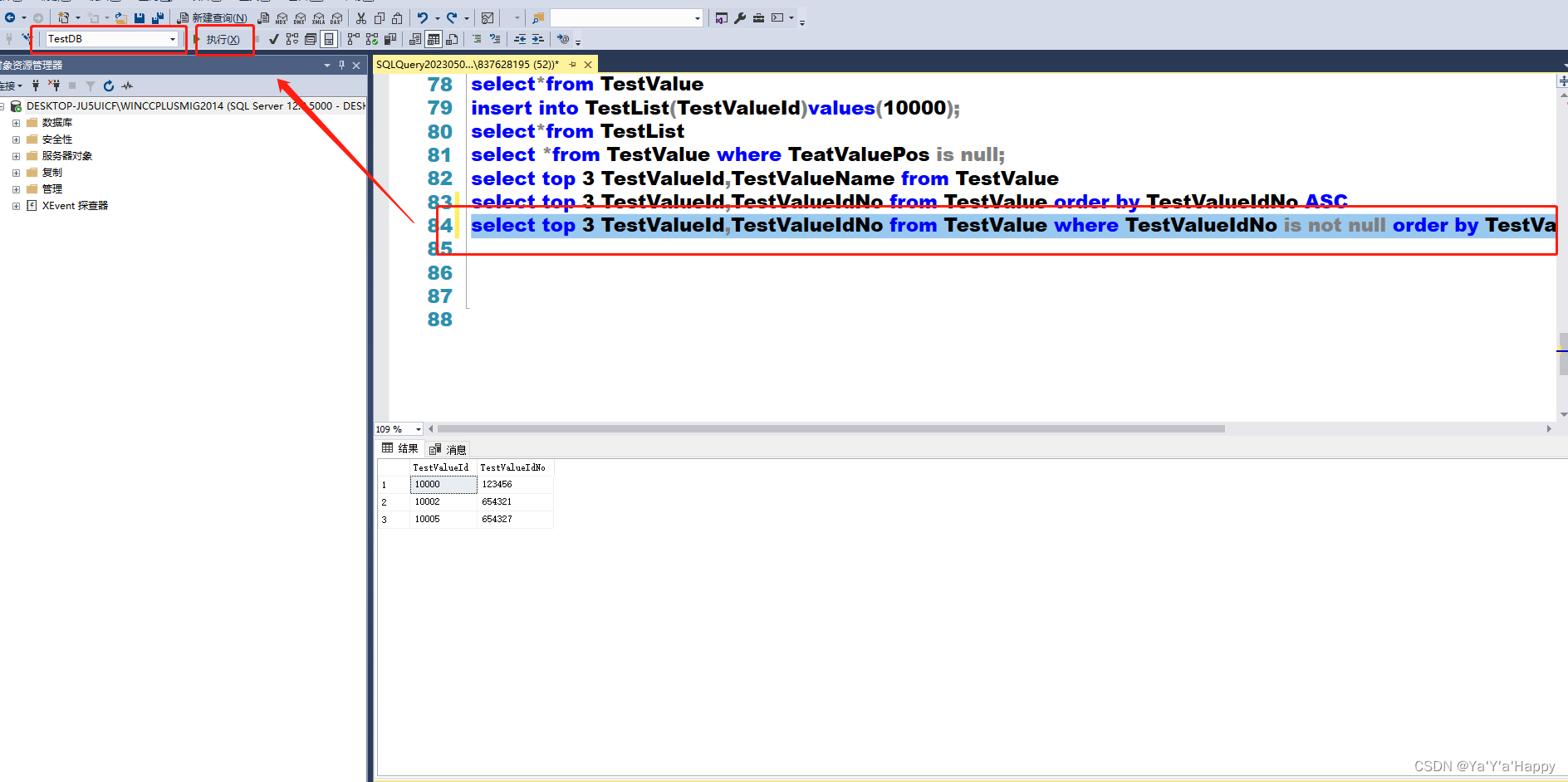
select top 3 TestValueId,TestValueName from TestValue
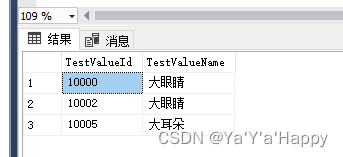
- 查找列表中的前3条数据,按升序排列,但是使用这种方法会优先排列内容为Null的列,即null内容也会参与排序
select top 3 TestValueId,TestValueIdNo from TestValue order by TestValueIdNo ASC
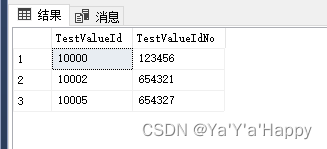
- 查找列表中的前3条数据,按升序排列,除去空的内容
select top 3 TestValueId,TestValueIdNo from TestValue where TestValueIdNo is not null order by TestValueIdNo ASC
- 查询列表中的前20%条数据,按升序排列
- 关键字percent,百分比
select top 20 percent TestValueId,TestValueIdNo from TestValue order by TestValueIdNo ASC
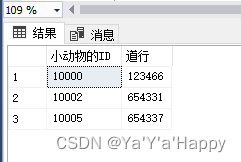
- 利用列表中的数据进行数学运算并查询
select 小动物的ID=TestValueId,道行=(TestValueIdNo+TeatValueNumber)from TestValue
2.内外联接查询
- 连接查询需求,当我们查询的结果在不同的表中时,我们通常需要将两个或者多个表关联起来查询
- 在建立链接查询前需要确认表之间的内外链接关系,如果没有建立内外连接将不能进行联表查询。
- 在查询时,需要查询的对应列都有内容或数据,否则有任意一个表的内容缺失都不会查询到。
- 关键字inner join 建立内连接
select TestMarstData.TestMarstId,TestMarstName,道行=(TestValueIdNo+TeatValueNumber)from TestValue
inner join TestMarstData on TestMarstData.TestMarstId=TestValue.TestMarstId
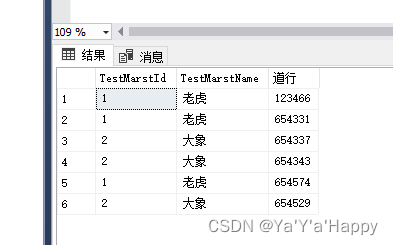
- 使用左外键查询
- 关键字 left join 左外键查询,即优先保证左边的数据表TestValue的完整性,这样当左边的列有9条耳右边的数据有8条,会优先显示9条数据,右边列如果没有数据会用null来自动填补
select TestMarstData.TestMarstId,TestMarstName,道行=(TestValueIdNo+TeatValueNumber)from TestValue
left join TestMarstData on TestMarstData.TestMarstId=TestValue.TestMarstId

- 右键查询,这种方式用的比较少,因为可以直接用内键查询inner join代替
- 关键字right join右键查询
select TestMarstData.TestMarstId,TestMarstName,道行=(TestValueIdNo+TeatValueNumber)from TestValue
right join TestMarstData on TestMarstData.TestMarstId=TestValue.TestMarstId
- 模糊查询(关键字查询)
- 通配符 “ %”
- 当查询关键字,例如 “%老虎”,那么将以"老虎"的前面可以匹配任意内容,即后面含有“老虎”的内容都会被找出来,如果是“老虎%”那么“老虎”后面有匹配任意的内容,都会被找出来,如果是“%老虎%”,则“老虎”的前面都可以有内容,包含“老虎”的内容都会被找出来
select TestValueName,TestValuePar,DataTestValue from TestValue where DataTestValue like '%2022%'
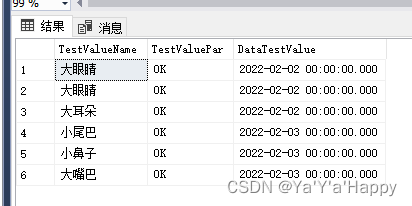
- 模糊查询(关键字查询)
- 关键字 “between” ,这个方法可用于查询一定时间,数量等区间的数量
- 下面查询某个时间段的区间
select TestValueName,TestValuePar,DataTestValue from TestValue where DataTestValue between '2022-02-02 00:00:00.000'and '2022-02-03 00:00:00.000'
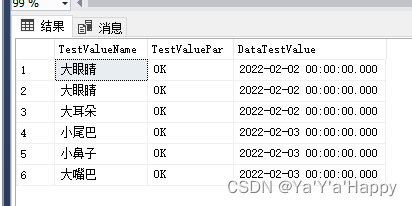
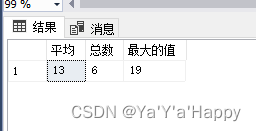
- 统计函数 avg ,count,max
- 关键字 “avg” 统计平均值函数
- 关键字 “ count” 统计总数量函数
- 关键字 "max"统计最大值函数
- 关键字 “Min” 统计最小值函数
- 使用关键字从数据表 “TestValue”里进行查询
”count(*)“里的 “ * ” 号可以使用 数字 “ 1” 代替,即”count(1)“ 得到的结果是一样的
select avg(TeatValueNumber)as 平均,总数=count(*),最大的值=max(TeatValueNumber)
from TestValue
关于视图
1.创建视图
在没有视图之前,我们都是写各种各样的SQL语句,优点:非常灵活。后面我们进行应用程序开发的时候,通过C#发送过来的SQL语句
到达数据库的时候,会执行什么过程呢?
数据库接收到各种应用程序发送的SQL语句的时候,通常的流程是这样的:
【1】语法检查–>【2】优化(根据你的查询条件内容,和索引情况等,综合优化一下)–>【3】编译–>【4】执行
我们想,常见的查询,尤其是组合查询,能不能把查询固化到数据库服务器端,然后客户端使用的时候,只是调用一下呢?
当然可以,这个就是存储过程和视图。
视图其实就是一个查询,本身没有数据,就是把我们要查询的SQL语句,经过优化后经过编译存储到数据库服务器端。
视图我们本身也可以把它看成一个“没有数据的表”。
2.视图的创建与使用
- 视图的命名规范:建议以 “view_”开头
- 使用 “create view”进行床创建
- as 和 go 之间写查询语句
create view
go
----------这里写查询语句
as
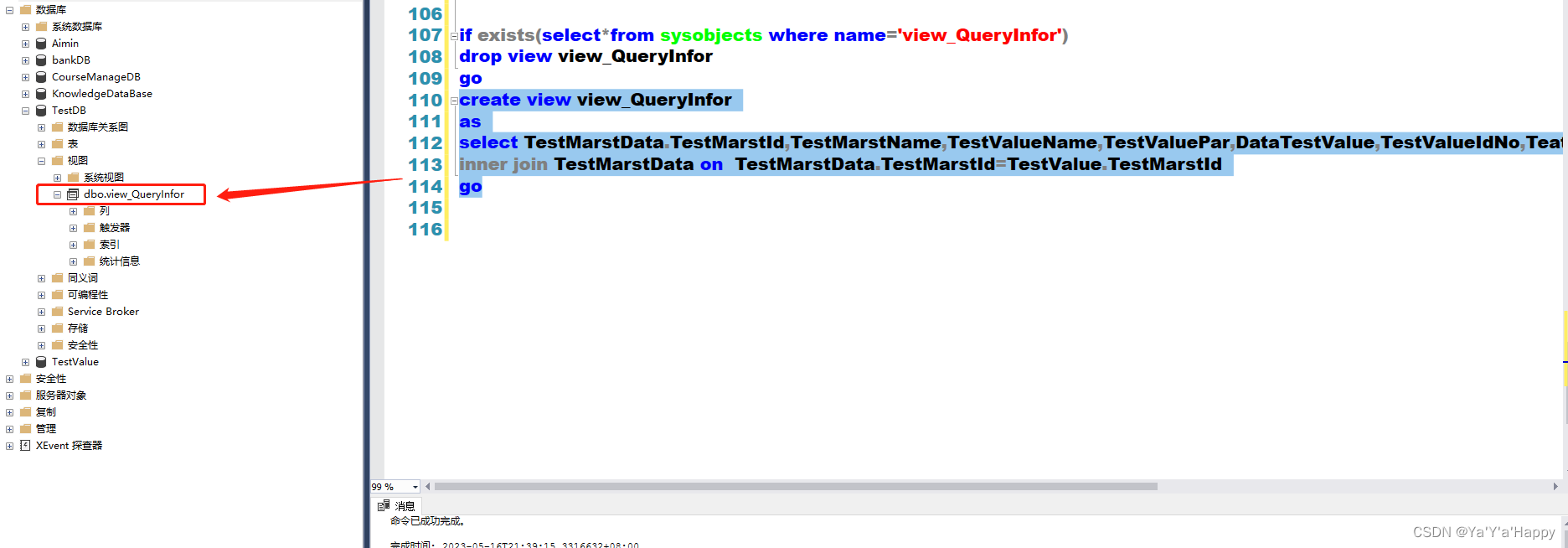
- 以下是创建视图的模板
if exists(select*from sysobjects where name='view_QueryInfor')
drop view view_QueryInfor
go
create view view_QueryInfor
as
select TestMarstData.TestMarstId,TestMarstName,TestValueName,TestValuePar,DataTestValue,TestValueIdNo,TeatValueNumber,TeatValuePos from TestValue
inner join TestMarstData on TestMarstData.TestMarstId=TestValue.TestMarstId
go
2.使用视图
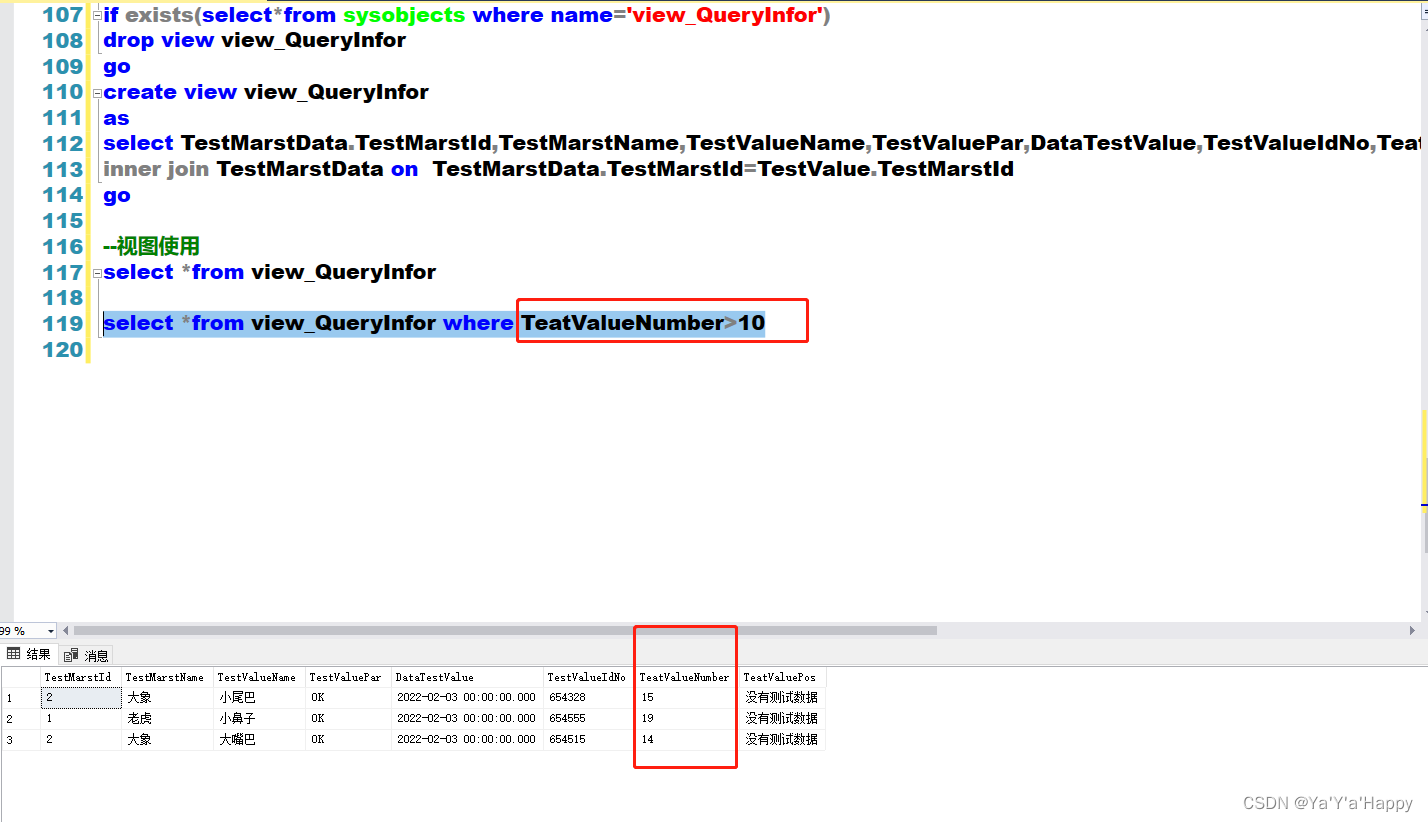
- 创建完成后可以直接进行使用,可以当作一张表去查询
select *from view_QueryInfor

* 也可以配合添加逻辑使用
```sql
select *from view_QueryInfor where TeatValueNumber>10
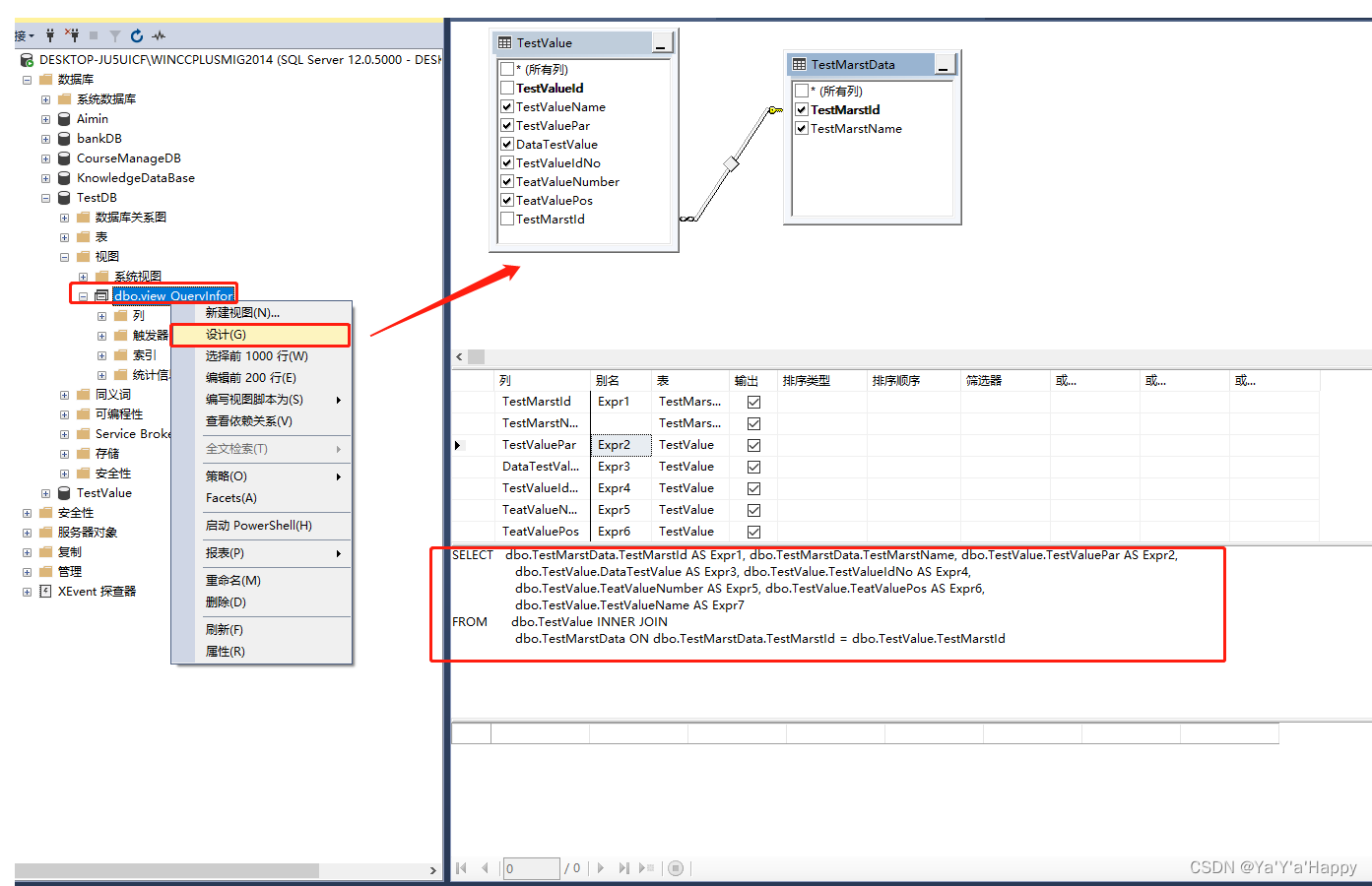
SQLserver提供了更快捷的修改已经创建好的试图表方法
可以用一下方式对已有的试图表格进行修改,修改后会自动生成代码
当数据比较多时,也可以直接使用新建的方式进行手动创建视图表,勾选需要查询的内容,它会自动生成对应的代码,创建完成后,点击“保存”即可生成视图
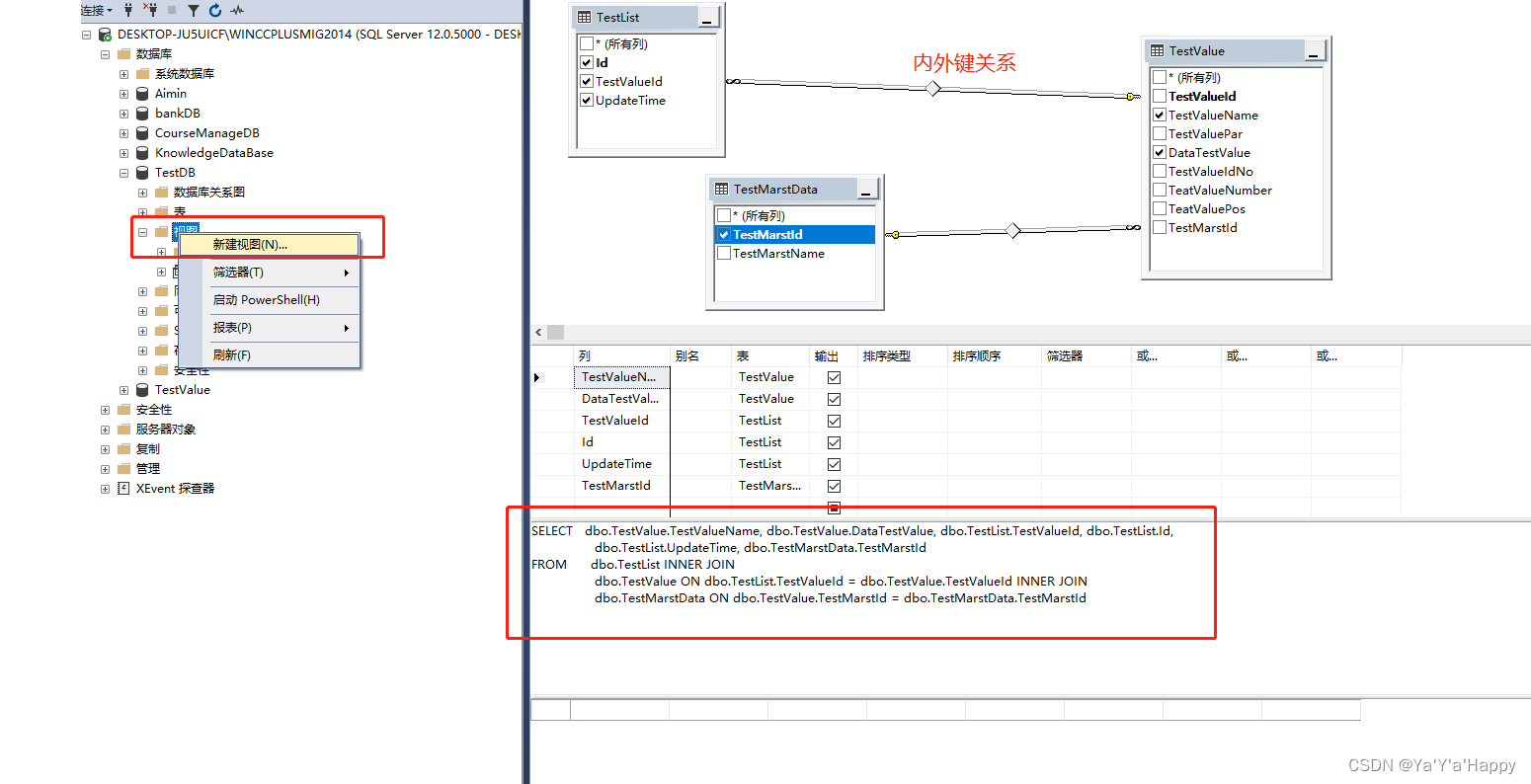
- 还可以使用视图进行复杂的逻辑显示
if exists(select*from sysobjects where name='view_QueryInfor2')
drop view view_QueryInfor2
go
create view view_QueryInfor2
as
select TestMarstData.TestMarstId,TestMarstName,TestValueName,TestValuePar,DataTestValue,TestValueIdNo,TeatValueNumber,TeatValuePos,
--类似于C#中的 switch case语法
测试结果=case
when TeatValueNumber>15 then '多'
when TeatValueNumber<12 then '少'
when TeatValueNumber=0 then '缺少'
else '正常'
end
from TestValue
inner join TestMarstData on TestMarstData.TestMarstId=TestValue.TestMarstId
go
--视图的使用
select *from view_QueryInfor2

3. 视图和普通的SQL语句查询比较
【1】视图本身就是一个提前写好的查询。但是这个查询保存到数据库服务器端。应用程序通过调用可以直接执行。
【2】普通的SQL语句查询。它在应用程序端。要执行,需要通过程序把SQL语句发送到数据库服务器端。
【3】后期的查询维护不同。如果我们要通过应用程序发送SQL语句,你必须要修改程序。但是如果我们使用视图呢?
可以适当的直接在数据库服务器上修改。
-
视图本身的特点:本身不保存任何数据,只是保存到服务器端的一段编译好的SQL语句而已,并且已经优化好和编译好。
-
关于使用建议:我们在学习阶段,必须会使用脚本写视图。如果是正式开发阶段,我们可以适当的使用可视化方式创建视图。
创建完毕后,把SQL语句优化好,再复制到你要创建的视图中。这个仅仅是为了省时间。必要的时候可以使用。
-
视图还有一个非常重要的功能:比如我们在项目中会根据不同的角色,做不同的数据查询,这时候,我们在必要的时候完全可以
针对不同的用户角色,设计不同的视图,保证数据的安全。
关于存储过程
1.创建存储过程
- 概念:存储过程就是编写到数据库服务器端的SQL语句,存储过程的内容不仅仅是可以实现查询,也可以实现CRUD同时操作。
使用选择:如果仅仅是查询,建议你使用视图。尤其是针对不同的角色需要调用不同的视图。这时候视图是非常方便的。
-
分类:系统存储过程(请大家自己学习一下,知道即可,可以随时查询)–>系统给我们提前定义好的,我们可以直接使用。
用户自定义存储过程(我们主要用的)
-
好处:
【1】执行效率高。已经编译好,并保存到服务器端。只需要调用,必要的时候传递参数即可。
减轻客户端的压力。
【2】安全型好。客户端调用,只需要发送指令即可。数据安全有保障。
【3】维护方便。如果后续有改动,可以直接在服务器端修改即可,而客户端程序不用修改。
- 调用:
【1】在数据库服务器端,写脚本调用。
【2】在应用程序中调用。
- 创建用户储存过程名称定义规范建议以 “usp_”开头,代表用户储存过程
- 储存过程里的输入参数以 “@”符号开头作为标示
可使用拖拽对应列的方式到代码中进行快速的代码添加
--创建存储过程
if exists(select*from sysobjects where name='usp_AddProduct')
drop procedure usp_AddProduct
go
create procedure usp_AddProduct
@TestValueId varchar(50),
@TestValueName varchar (50),
@TestValuePar varchar(50),
@DataTestValue datetime,
@TestValueIdNo varchar(50),
@TeatValueNumber varchar(50),
@TeatValuePos varchar(50),
@TestMarstId int
as
go
为了更快捷的添加变量,可以选择拖拽的方式,然后再加上 @符号
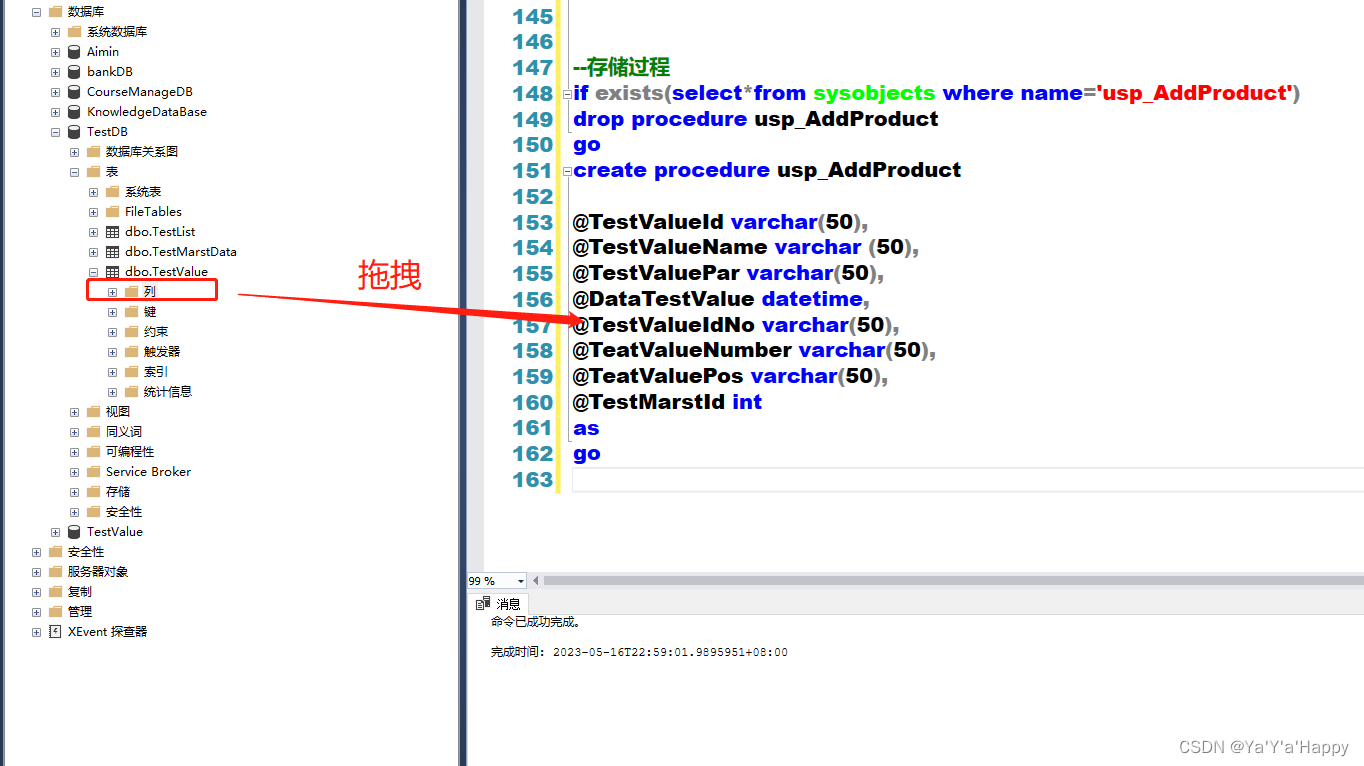
- 创建完成就,点击生成即可看到创建好的储存过程

3.使用储存过程
exec usp_AddProduct '大白','OK','2022-02-08','747888','18','Pass',2
如图所示,插入成功

3.1 关于手动插入自动增长列
- 由于自动增长列的特殊性,当手动去插入时会报错,“Cannot insert explicit value for identity column in table ‘TestValue’ when IDENTITY_INSERT is set to OFF.”(翻译:当identity_insert设置为OFF时,无法在表“TestValue”中为标识列插入显式值。)如下
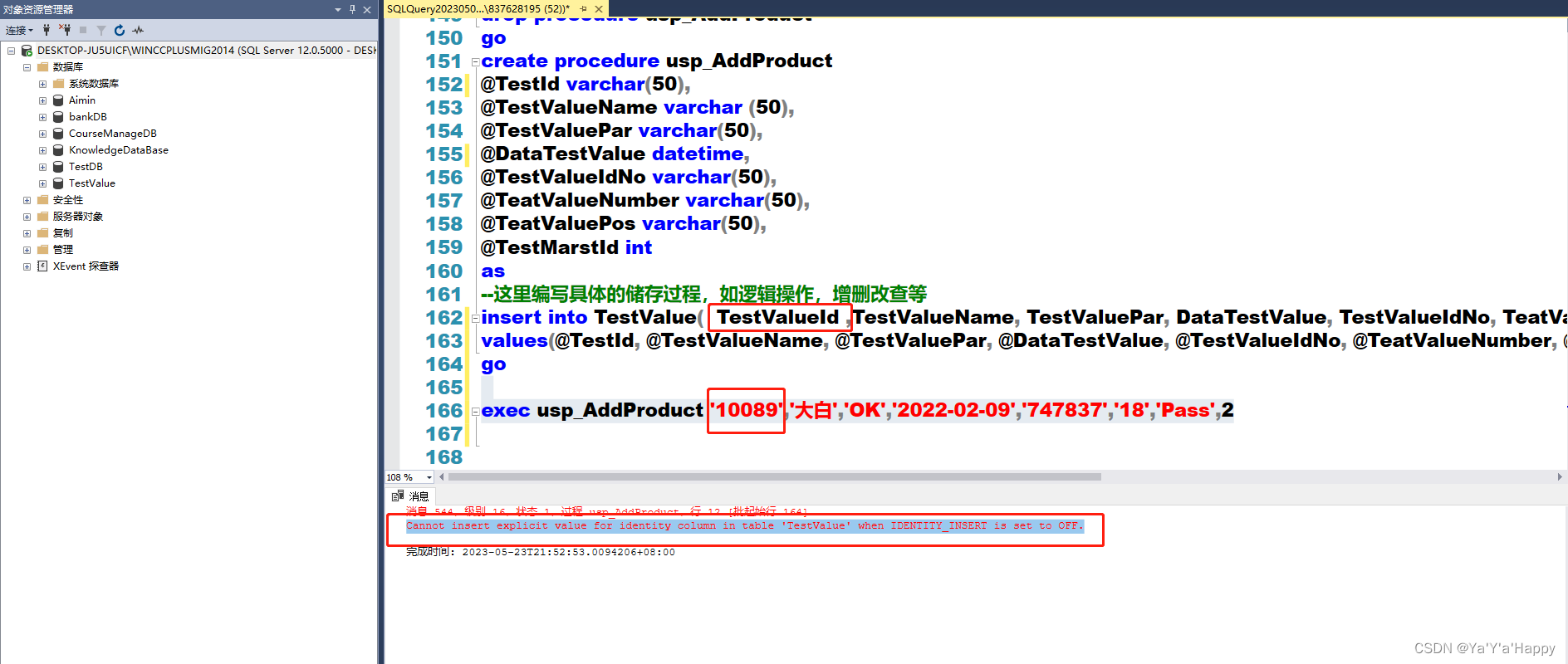
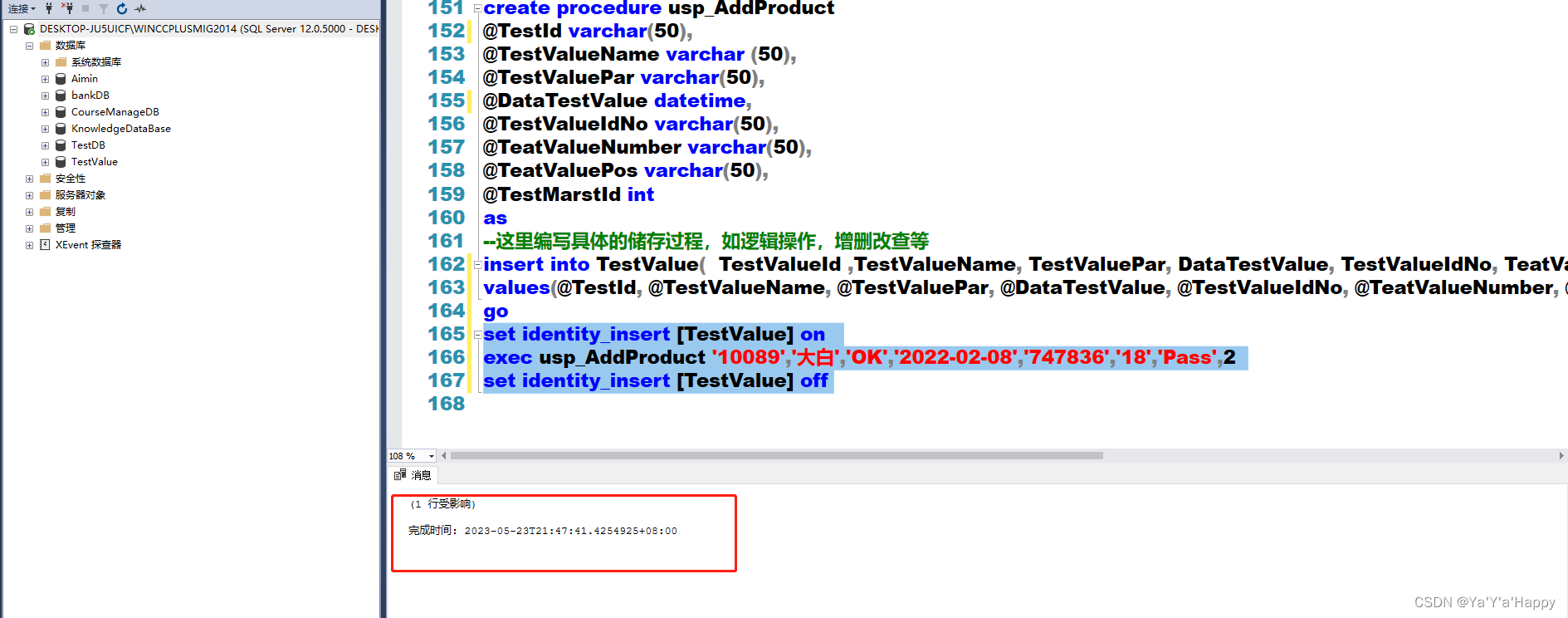
这时可手动打开要插入数据的表 identity insert 设置为on,插入完数据后再设置为off ,为了保证数据键的稳定性,尽量避免去手动插入自动增长列
--设置表 ‘TestValue’ 为 on
set identity_insert [TestValue] on
exec usp_AddProduct '10089','大白','OK','2022-02-08','747836','18','Pass',2
set identity_insert [TestValue] off
以下插入成功
4.创建及使用带有初始值的存储过程
当有些情况需要使用带有初始值的存储过程时可以按以下方式进创建
- 注意含有初始值的参数应该在定义时应该放在最后
--带默认值的存储过程
if exists(select*from sysobjects where name='usp_AddProduct2')
drop procedure usp_AddProduct2
go
create procedure usp_AddProduct2
@TestValueName varchar (50),
@TestValuePar varchar(50),
@DataTestValue datetime,
@TestValueIdNo varchar(50),
@TeatValueNumber varchar(50),
@TeatValuePos varchar(50)='16', --为了方便使用,有默认值的参数应该定义在最后
@TestMarstId int=2
as
--这里编写具体的储存过程,如逻辑操作,增删改查等
insert into TestValue(TestValueName, TestValuePar, DataTestValue, TestValueIdNo, TeatValueNumber, TeatValuePos, TestMarstId)
values(@TestValueName, @TestValuePar, @DataTestValue, @TestValueIdNo, @TeatValueNumber, @TeatValuePos, @TestMarstId)
go
- 使用带有初始值的存储过程
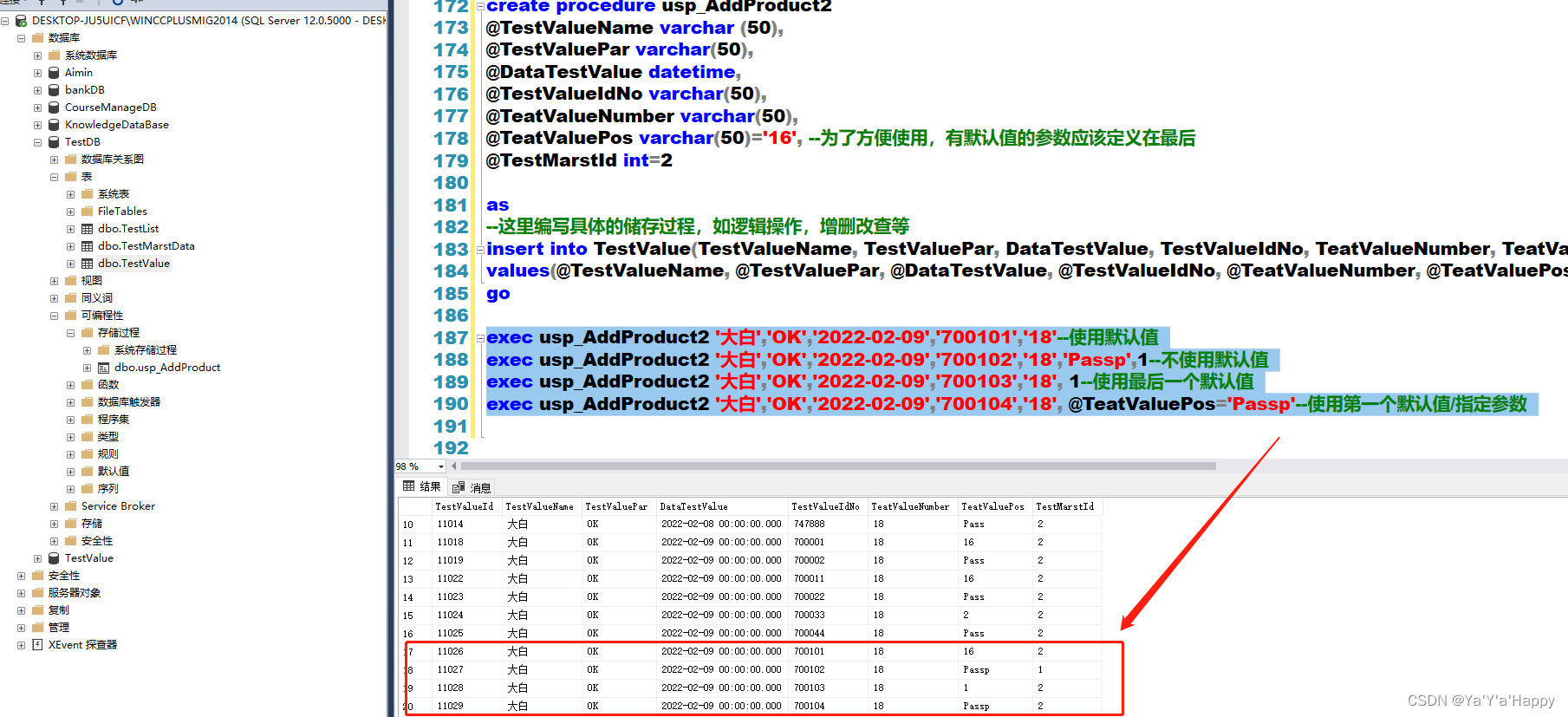
exec usp_AddProduct2 '大白','OK','2022-02-09','700101','18'--使用默认值
exec usp_AddProduct2 '大白','OK','2022-02-09','700102','18','Passp',1--不使用默认值
exec usp_AddProduct2 '大白','OK','2022-02-09','700103','18', 1--使用最后一个带有默认值的参数
exec usp_AddProduct2 '大白','OK','2022-02-09','700104','18', @TeatValuePos='Passp'--使用第一个默认值/指定某个带默认值的参数
查询后效果如下
5.创建及使用带有输出参数的存储过程
在项目中有时会用到带有输出参数的存储过程,在调用时需要去定义输出参数来接收
- 以下是创建一个带有输出参数的存储过程
--带输出参数的存储过程
if exists(select*from sysobjects where name='usp_SelectProduct')
drop procedure usp_SelectProduct
go
create procedure usp_SelectProduct
@ProductCount int output--定义输出参数
as
--这里编写具体的储存过程,如逻辑操作,增删改查等
--可在这里声明需要使用的变量用于接收输出参数
select TestValueName, TestValuePar, DataTestValue, TestValueIdNo, TeatValueNumber, TeatValuePos, TestMarstId
from TestValue
select @ProductCount =count(*)from TestValue
go
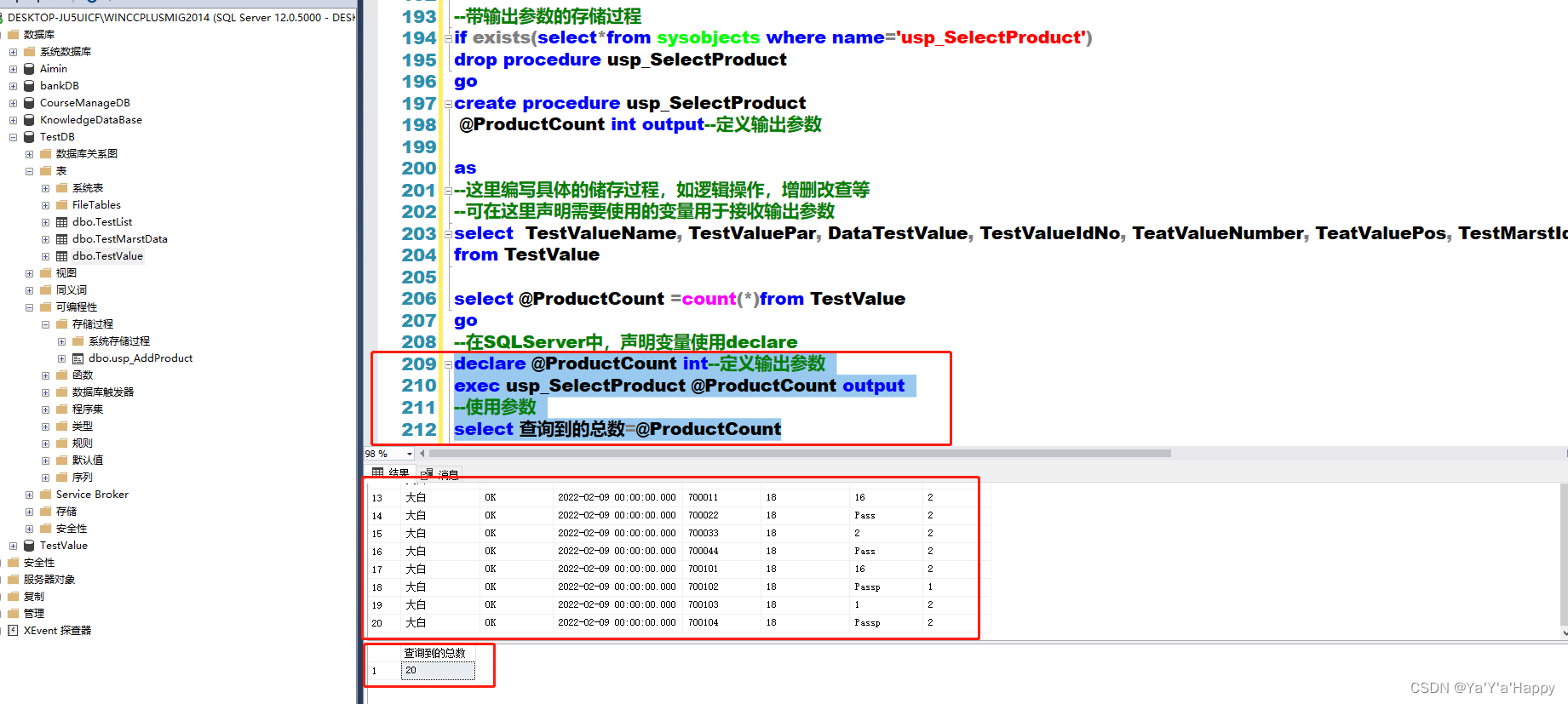
- 使用带有输出参数的存储过程
declare @ProductCount int--定义输出参数
exec usp_SelectProduct @ProductCount output--使用存储过程
--使用参数
select 查询到的总数=@ProductCount
关于事务
1.关于追加约束
在已经创建好的表后手动追加约束
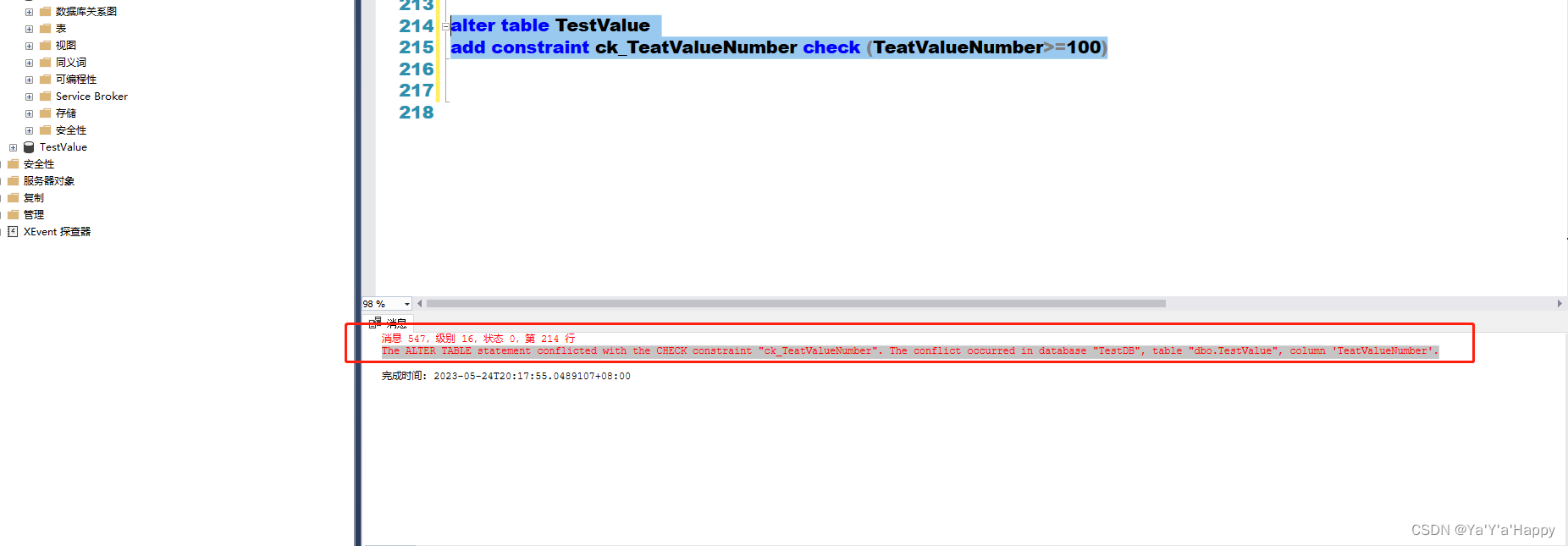
- 在追加约束时应检查对应的参数是否已经包含约束的内容,如果其内容已经属于约束的内容将会引发冲突并报错,如下所示
-由于表内的数据已经有不大于等于100的部分,所以此代码会引发冲突
alter table TestValue
add constraint ck_TeatValueNumber check (TeatValueNumber>=100)
- 报错:ALTER TABLE语句与CHECK约束“ck_TeatValueNumber”冲突。冲突发生在数据库“TestDB”、表“dbo.TestValue”、列“TeatValueNumber”中。
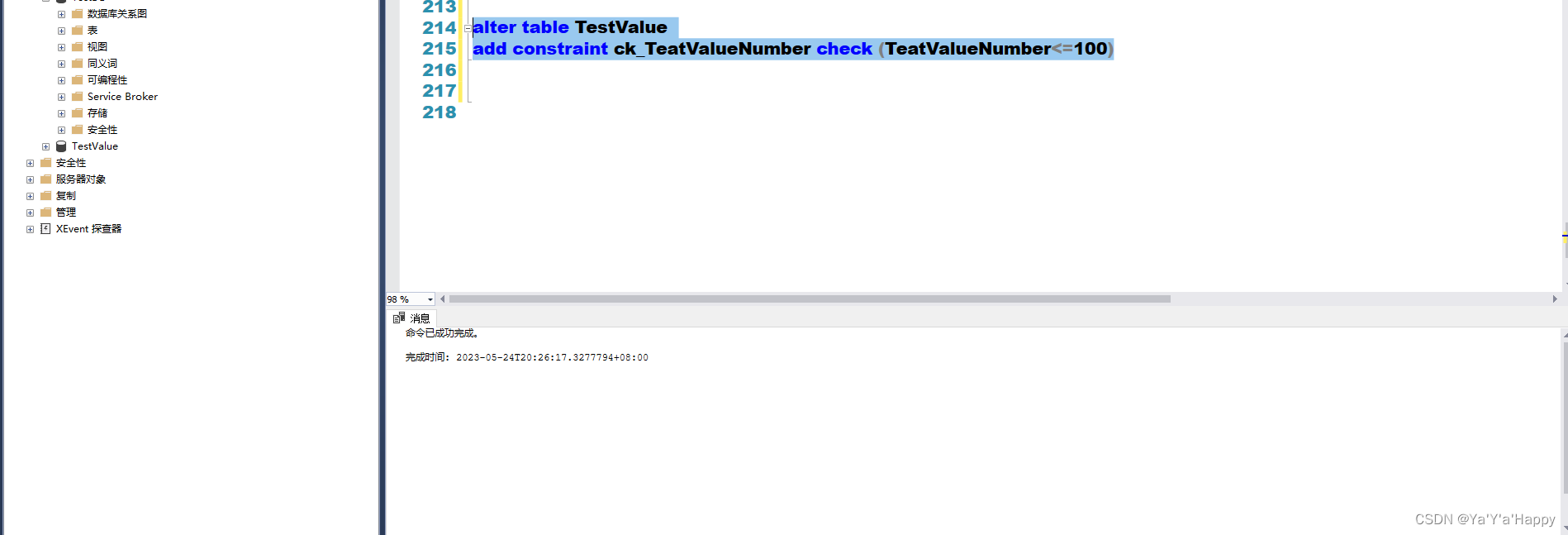
正确的做法是应先确认表内数据和约束没有冲突然后再添加约束
--以下是经过检查确认不会引发冲突的代码
alter table TestValue
add constraint ck_TeatValueNumber check (TeatValueNumber<=100)
2.为什么用事务?
如图所示,当使用存储过程进行两组同时插入的时候,会发现其中一组可以插入成功,一组插入失败。这种情况是我们不想要的。
通过刚才示例的观察,我们发现,当一个存储过程或多个SQL语句(指代insert、update、delete类型)依次执行时候,如果其中一条或几条发生错误,但是其他的还会继续执行,会造成数据的不一致,非常危险。常见的,比如银行,我们从一个账号
转钱到另一个账号,如果当我们转出的时候,系统发生了故障,但是没有转入,这样的话,银行的数据就出问题。
想解决这个问题,我们使用事务!

3.事务的特点
原子性:就是不可分割性,是一个整体。
一致性:也就是我们操作的数据,前后都保持高度的一致。
主要作用:就是保证数据在不同的操作中,或者这些操作全部成功,或者失败的时候全部取消。
- 在SQLServer中全局变量使用@@标识
常见的:@@Identity @@error 用来存储SQL操作最后一条语句的状态。
if exists(select*from sysobjects where name='usp_AddProduct02')
drop procedure usp_AddProduct02
go
create procedure usp_AddProduct02
@TestValueName varchar (50),
@TestValuePar varchar(50),
@DataTestValue datetime,
@TestValueIdNo varchar(50),
@TeatValueNumber varchar(50),
@TestMarstName varchar(50),
@TeatValuePos varchar(50)='16', --为了方便使用,有默认值的参数应该定义在最后
@TeatValuepp_Pos varchar(50)
as
declare @errorSun int --@errorSun这个变量用来记录错误变量的总数
set @errorSun=0 --给当前的变量赋一个初始值
begin transaction
begin
--这里编写具体的储存过程,如逻辑操作,增删改查等
insert into TestValue(TestValueName, TestValuePar, DataTestValue, TestValueIdNo, TeatValueNumber, TeatValuePos)
values(@TestValueName, @TestValuePar, @DataTestValue, @TestValueIdNo, @TeatValueNumber, @TeatValuePos)
--紧跟SQL语句后面用来捕获错误号码
set @errorSun=@errorSun+@@error
insert into TestValuePP(TeatValuepp_Pos)
values(@TeatValuepp_Pos);
set @errorSun=@errorSun+@@error --如果有查询语句,查询语句不用写
--测试(实际开发中,这个print不用写)
print @errorSun
--判断是否发生错误
if @errorSun>0
rollback transaction --回滚事务
else
commit transaction --提交事务
end
go
调用上面的代码,然后插入一行错误的SQLServer语句。
exec usp_AddProduct02 '老灰','OK','2022-02-20','900003','26','小白狼',@TeatValuepp_Pos='3'--使用默认值
可以看出,执行之后显示了一行受影响,并且显示了报错代码,但是这两条语句并没有被插入到数据库中
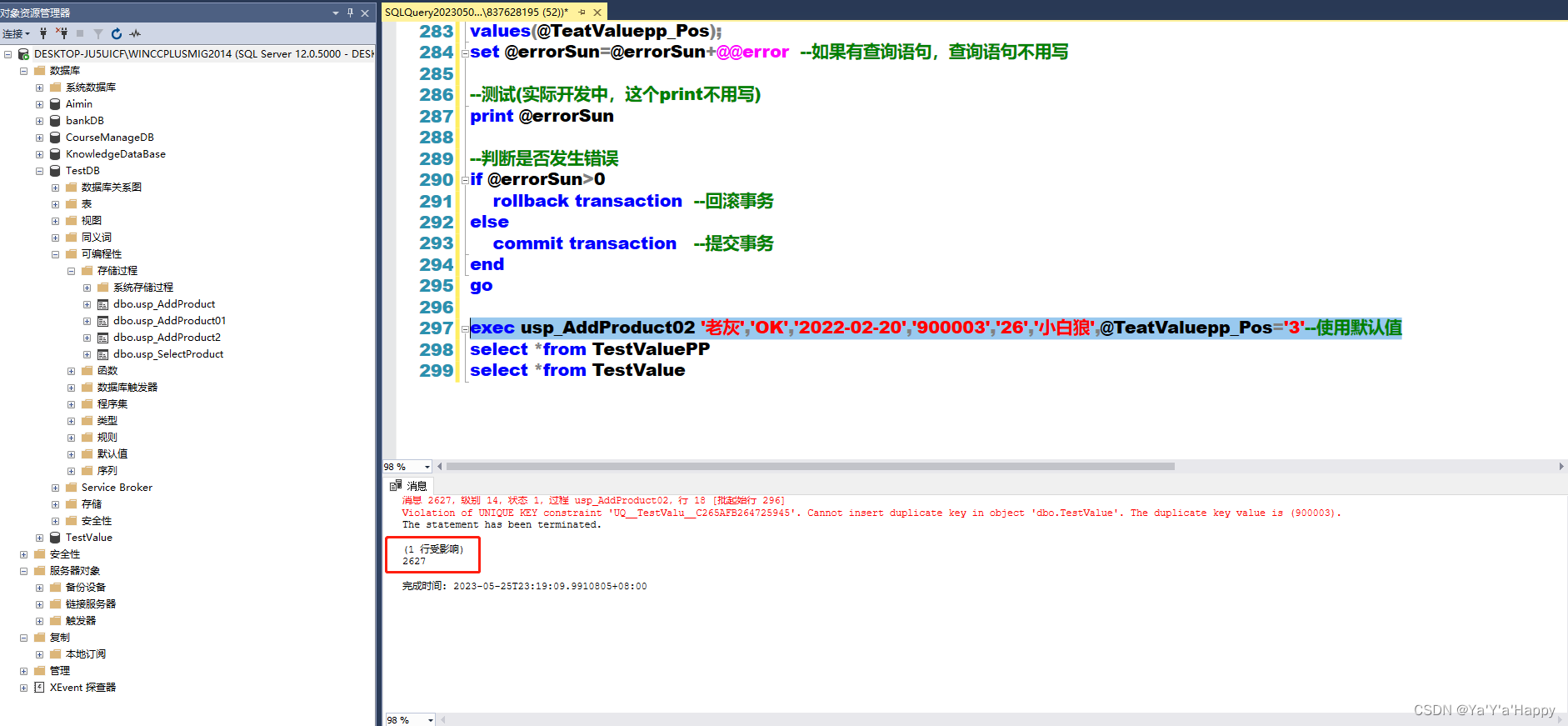
执行查询指令查看上面其中一条正确的插入指令是否有插入到数据库
select *from TestMarstData
select *from TestValue
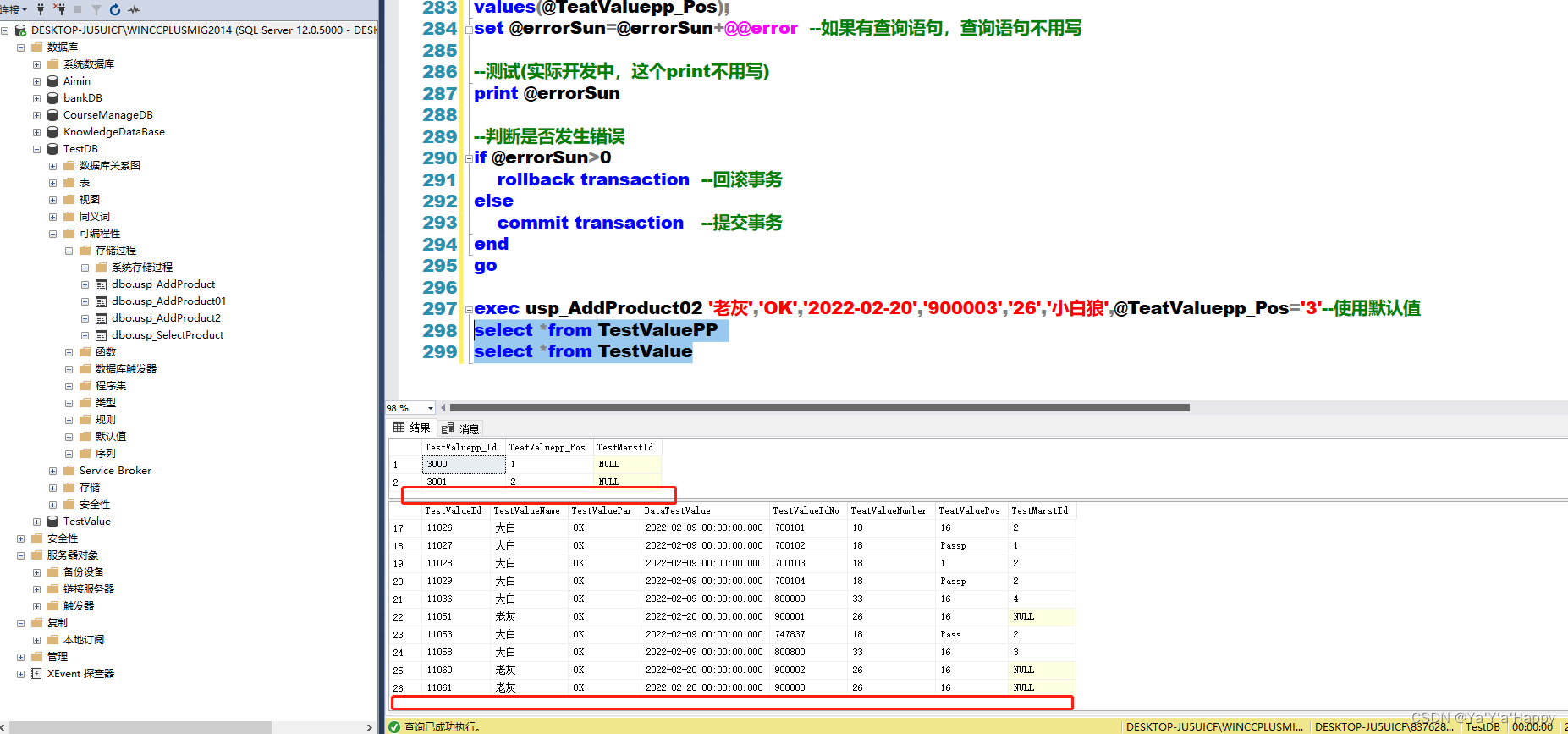
由上图可以看出代码并没有插入成功。
接下来再执行正确的SQLserver语句
exec usp_AddProduct02 '老灰','OK','2022-02-20','900003','26','小白狼',@TeatValuepp_Pos='3'--使用默认值

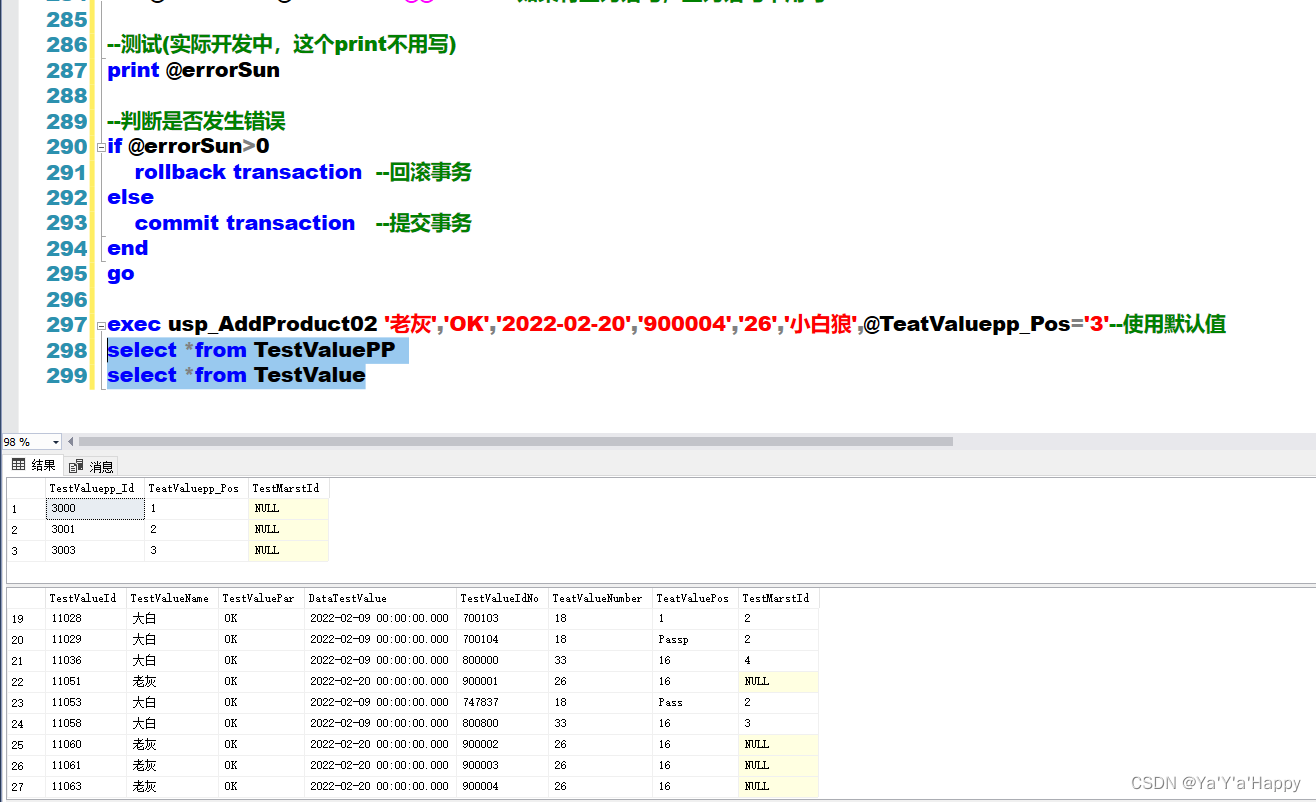 * 建议:如果你在开发中,使用存储过程,只要是两个或两个以上的insert、update或delete类型的SQL被执行,你就都可以
* 建议:如果你在开发中,使用存储过程,只要是两个或两个以上的insert、update或delete类型的SQL被执行,你就都可以
使用事务。















 2392
2392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









