







MySQL面试常见知识点
1、 MySQL常用的存储引擎有什么?它们有什么区别?
- InnoDB
InnoDB是MySQL的默认存储引擎,支持事务、行锁和外键等操作。
- MyISAM
MyISAM是MySQL5.1版本前的默认存储引擎,MyISAM的并发性比较差,不支持事务和外键等操 作,默认的锁的粒度为表级锁。
InnoDB
MyISAM
外键
支持
不支持
事务
支持
不支持
锁
支持表锁和行锁
支持表锁
可恢复性
根据事务日志进行恢复
无事务日志
表结构
数据和索引是集中存储的,.ibd 和.frm
数据和索引是分开存储的,数据 .MYD ,索 引 .MYI
查询性 能
一般情况相比于MyISAM较好
一般情况相比于InnoDB较差
索引
聚簇索引
非聚簇索引
2、 数据库的三大范式
- 第一范式:确保每列保持原子性,数据表中的所有字段值都是不可分解的原子值。
- 第二范式:确保表中的每列都和主键相关
- 第三范式:确保每列都和主键列直接相关而不是间接相关
3、 MySQL的数据类型有哪些
-
整数
TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT分别占用8、16、24、32、64位存储空间。值 得注意的是,INT(10)中的10只是表示显示字符的个数,并无实际意义。一般和UNSIGNED ZEROFILL配合使用才有实际意义,例如,数据类型INT(3),属性为UNSIGNED ZEROFILL,如果插 入的数据为3的话,实际存储的数据为003。
-
浮点数
FLOAT、DOUBLE及DECIMAL为浮点数类型,DECIMAL是利用字符串进行处理的,能存储精确的 小数。相比于FLOAT和DOUBLE,DECIMAL的效率更低些。FLOAT、DOUBLE及DECIMAL都可以 指定列宽,例如FLOAT(5,2)表示一共5位,两位存储小数部分,三位存储整数部分。
-
字符串
字符串常用的主要有CHAR和VARCHAR,VARCHAR主要用于存储可变长字符串,相比于定长的 CHAR更节省空间。CHAR是定长的,根据定义的字符串长度分配空间。
应用场景:对于经常变更的数据使用CHAR更好,CHAR不容易产生碎片。对于非常短的列也是使用 CHAR更好些,CHAR相比于VARCHAR在效率上更高些。一般避免使用TEXT/BLOB等类型,因为查 询时会使用临时表,造成严重的性能开销。
-
日期
比较常用的有year、time、date、datetime、timestamp等,datetime保存从1000年到9999年的 时间,精度位秒,使用8字节的存储空间,与时区无关。
timestamp和UNIX的时间戳相同,保存从 1970年1月1日午夜到2038年的时间,精度到秒,使用四个字节的存储空间,并且与时区相关。
应用场景:尽量使用timestamp,相比于datetime它有着更高的空间效率。
4、 索引
什么是索引
索引是一种用于快速查询和检索数据的数据结构 ,常见的索引结构有: B 树, B+树和 Hash。
索引的作用就相当于目录的作用。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
索引的优缺点?
优点:
- 大大加快数据检索的速度。
- 将随机I/O变成顺序I/O(因为B+树的叶子节点是连接在一起的)
- 加速表与表之间的连接
缺点:
-
从空间角度考虑,建立索引需要占用物理空间
-
从时间角度 考虑,创建和维护索引都需要花费时间,例如对数据进行增删改的时候都需要维护 索引
索引的数据结构?
索引的数据结构主要有B+树和哈希表,对应的索引分别为B+树索引和哈希索引。InnoDB引擎的索引类 型有B+树索引和哈希索引,默认的索引类型为B+树索引。
-
B+树索引
熟悉数据结构的同学都知道,B+树、平衡二叉树、红黑树都是经典的数据结构。在B+树中,所有 的记录节点都是按照键值大小的顺序放在叶子节点上,如下图。
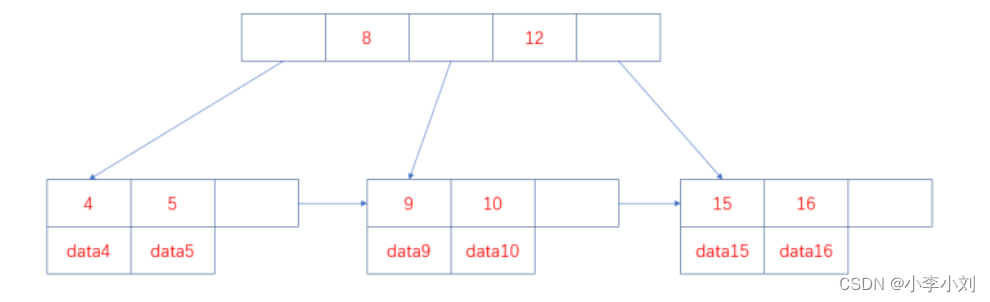
从上图可以看出 ,因为B+树具有有序性,并且所有的数据都存放在叶子节点,所以查找的效率非 常高,并且支持排序和范围查找。
B+树的索引又可以分为主索引和辅助索引。其中主索引为聚簇索引,辅助索引为非聚簇索引。聚簇 索引是以主键作为B+ 树索引的键值所构成的B+树索引,聚簇索引的叶子节点存储着完整的数据记 录;非聚簇索引是以非主键的列作为B+树索引的键值所构成的B+树索引,非聚簇索引的叶子节点 存储着主键值。所以使用非聚簇索引进行查询时,会先找到主键值,然后到根据聚簇索引找到主键 对应的数据域。上图中叶子节点存储的是数据记录,为聚簇索引的结构图,非聚簇索引的结构图如 下:
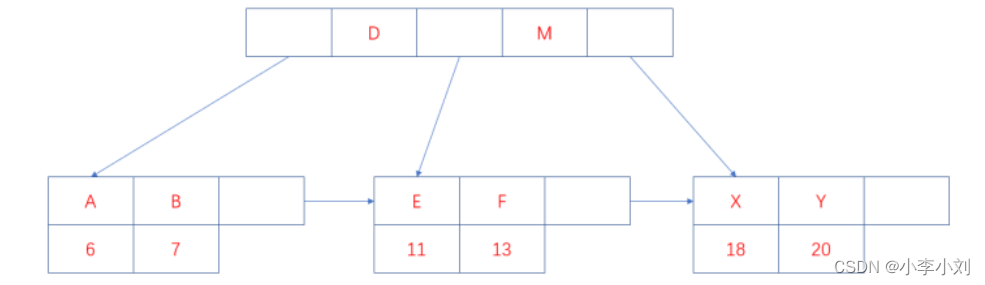
上图中的字母为数据的非主键的列值,假设要查询该列值为B的信息,则需先找到主键7,在到聚簇 索引中查询主键7所对应的数据域。
-
哈希索引
哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
为何能够通过 key 快速取出 value呢? 原因在于 哈希算法(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
hash = hashfunc(key)
index = hash % array_size
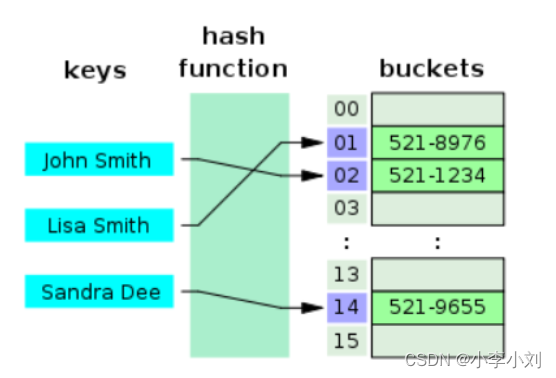
但是!哈希算法有个 Hash 冲突 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 链地址法。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 HashMap 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后HashMap为了减少链表过长的时候搜索时间过长引入了红黑树。
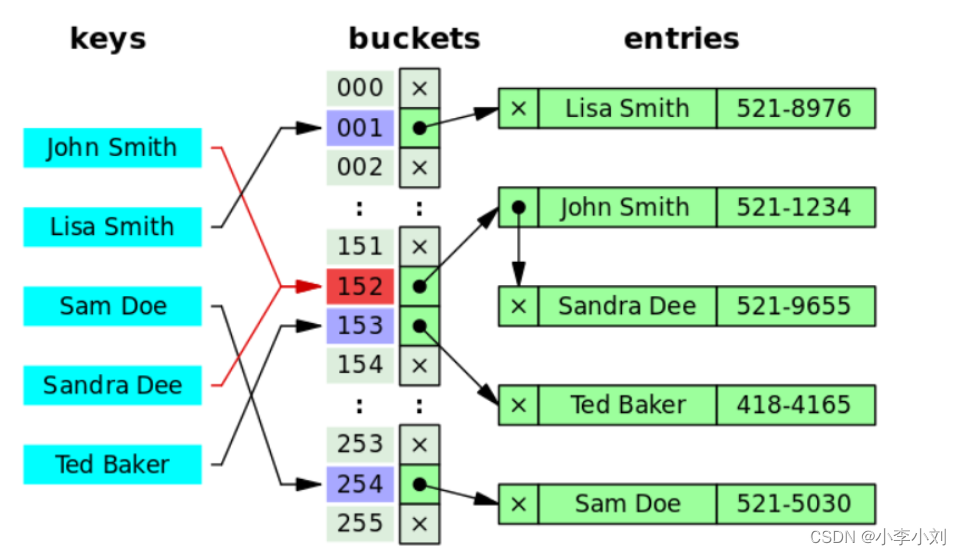
为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
既然哈希表这么快,为什么MySQL 没有使用其作为索引的数据结构呢?
1.Hash 冲突问题 :我们上面也提到过Hash 冲突了,不过对于数据库来说这还不算最大的缺点。
2.Hash 索引不支持顺序和范围查询(Hash 索引不支持顺序和范围查询是它最大的缺点: 假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。
Hash索引和B+树的区别?
因为两者数据结构上的差异导致它们的使用场景也不同,哈希索引一般多用于精确的等值查找,B+索引 则多用于除了精确的等值查找外的其他查找。在大多数情况下,会选择使用B+树索引。
-
哈希索引不支持排序,因为哈希表是无序的。
-
哈希索引不支持范围查找。
-
哈希索引不支持模糊查询及多列索引的最左前缀匹配。
-
因为哈希表中会存在哈希冲突,所以哈希索引的性能是不稳定的,而B+树索引的性能是相对稳定 的,每次查询都是从根节点到叶子节点
索引的种类有哪些?
- 主键索引:数据列不允许重复,不能为NULL,一个表只能有一个主键索引
- 组合索引:由多个列值组成的索引。
- 唯一索引:数据列不允许重复,可以为NULL,索引列的值必须唯一的,如果是组合索引,则列值 的组合必须唯一。
- 全文索引:对文本的内容进行搜索。
- 普通索引:基本的索引类型,可以为NULL
B树和B+树的区别?
B树和B+树最主要的区别主要有两点:
- B树中的内部节点和叶子节点均存放键和值,而B+树的内部节点只有键没有值,叶子节点存放所有 的键和值。
- B+树的叶子节点是通过相连在一起的,方便顺序检索。
两者的结构图如下。
请添加图片描述
数据库为什么使用B+树而不是B树?
- B树适用于随机检索,而B+树适用于随机检索和顺序检索
- B+树的空间利用率更高,因为B树每个节点要存储键和值,而B+树的内部节点只存储键,这样B+树 的一个节点就可以存储更多的索引,从而使树的高度变低,减少了I/O次数,使得数据检索速度更 快。
- B+树的叶子节点都是连接在一起的,所以范围查找,顺序查找更加方便
- B+树的性能更加稳定,因为在B+树中,每次查询都是从根节点到叶子节点,而在B树中,要查询的 值可能不在叶子节点,在内部节点就已经找到。
那在什么情况适合使用B树呢,因为B树的内部节点也可以存储值,所以可以把一些频繁访问的值放在距 离根节点比较近的地方,这样就可以提高查询效率。综上所述,B+树的性能更加适合作为数据库的索引 。
什么是聚簇索引,什么是非聚簇索引?
聚簇索引和非聚簇索引最主要的区别是数据和索引是否分开存储。
- 聚簇索引:将数据和索引放到一起存储,索引结构的叶子节点保留了数据行。
- 非聚簇索引:将数据进和索引分开存储,索引叶子节点存储的是指向数据行的地址 。
在InnoDB存储引擎中,默认的索引为B+树索引,**利用主键创建的索引为主索引,也是聚簇索引,在主 索引之上创建的索引为辅助索引,也是非聚簇索引。**为什么说辅助索引是在主索引之上创建的呢,因为 辅助索引中的叶子节点存储的是主键。
在MyISAM存储引擎中,默认的索引也是B+树索引,但主索引和辅助索引都是非聚簇索引,也就是说索 引结构的叶子节点存储的都是一个指向数据行的地址。并且使用辅助索引检索无需访问主键的索引。
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









