









MySQL 高级/进阶 SQL 语句
环境准备
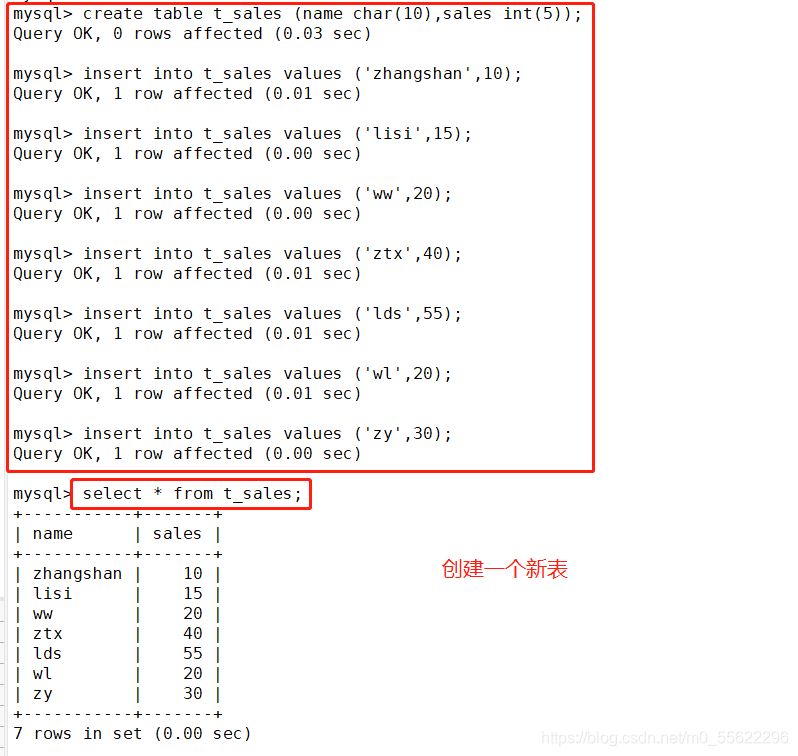
一.算排名
----算排名----表格自我连结(Self Join), 然后将结果依序列出,算出每一行之前(包含那一行本身)有多少行数
SELECT A1.Name, A1.Sales, COUNT (A2.Sales) Rank FROM Total_Sales A1.Total_Sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales=A2.Sales AND A1.Name = A2. Name)
GROUP BY A1.Name,Al.Sales ORDER BY A1.Sales DESC;
#统计Sales栏位的值是比自己本身的值小的以及Sales栏位和Name栏位都相同的数量,比如zhangsan为6+1=7
A1.score为75时,A2.score可为75、80、90、95、96 则 count(A2.score)为5
A1.score为80时,A2.score可为80、90、95、96 则 count(A2.score)为4
A1.score为90时,A2.score可为90、95、96 则 count(A2.score)为3
A1.score为95时,A2.score可为95、96 则 count(A2.score)为2
A1.score为96时,A2.score可为96 则 count(A2.score)为1
二.算中位数
SELECT Sales Middle FROM (SELECT A1.Name,A1.Sales,COUNT(A2.Sales) Rank FROM Total_Sales A1, Total_Sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales = A2.Sales AND A1.Name >= A2.Name)
GROUP BY A1.Name, A1.Sales ORDER BY Al.Sales DESC) A3
WHERE A3.Rank = (SELECT (COUNT(*)+1) DIV 2 FROM Total_Sales) ;
#每个派生表必须有自己的别名,所以别名A3必须要有
#DIV是在MySQL中算出商的方式

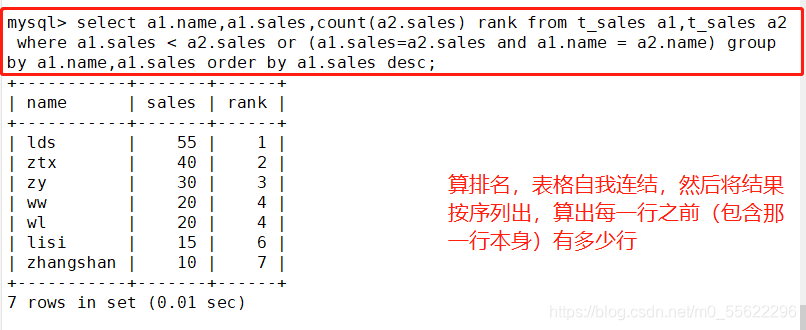
三.算累积总计
----算累积总计----表格自我连结(Self Join),然后将结果依序列出,算出每一-行之前(包含那一行本身)的总合
SELECT A1.Name, A1.Sales,SUM(A2.Sales) Sum_Total FROM Total_Sales A1,Total_Sales A2
WHERE A1.Sales < A2.Sales OR (Al.Sales=A2.Sales AND A1.Name = A2.Name)
GROUP BY A1.Name, A1.Sales ORDER BY A1.sales DESC;
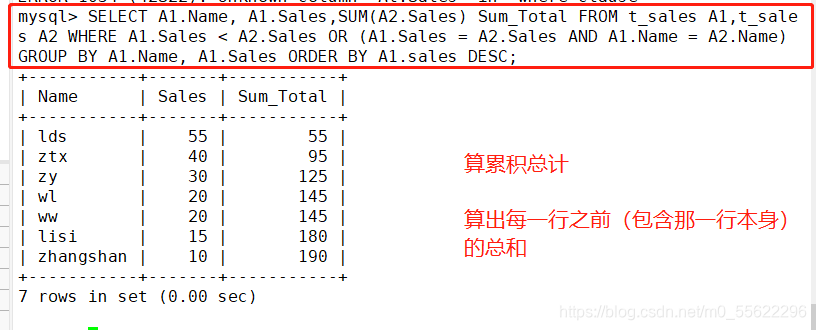
四.算总和百分比
算总合百分比
SELECT A1.Name, A1.Sales, A1.Sales/(SELECT SUM (Sales) FROM t_sales) Per_Total
FROM t_sales A1, t_sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales=A2.Sales AND A1.Name = A2.Name)
GROUP BY A1.Name,A1.Sales ORDER BY A1.Sales DESC;
#SELECT SUM(Sales) FROM Total_ sales 这一.段子查询是用来算出总合
#总合算出后,我们就能够将每- -行一- -除以总合来求出每- - 行的总合百分比
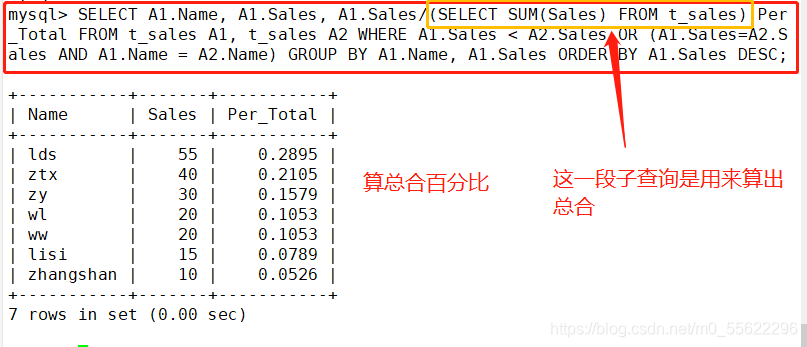
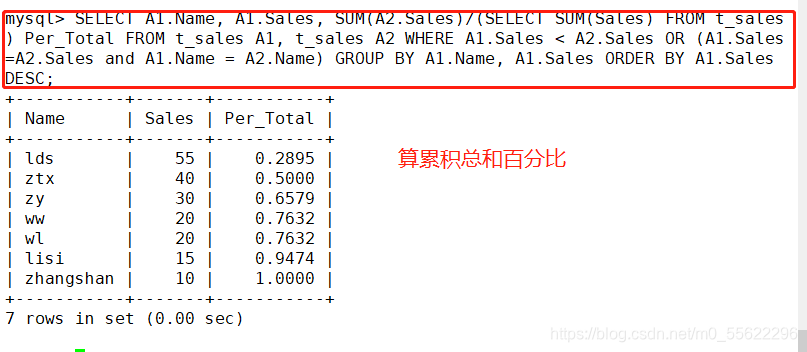
五.算累积总和百分比
算累积总合百分比
SELECT A1.Name, A1.Sales, SUM(A2.Sales)/(SELECT SUM(Sales) FROM t_sales) Per_Total
FROM t_sales A1, t_sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales-A2.Sales and A1.Name = A2.Name)
GROUP BY A1.Name, A1.Sales ORDER BY A1.Sales DESC;
#用累积总计SUM(a2.Sales) 除以总合来求出每一行的累积总合百分比
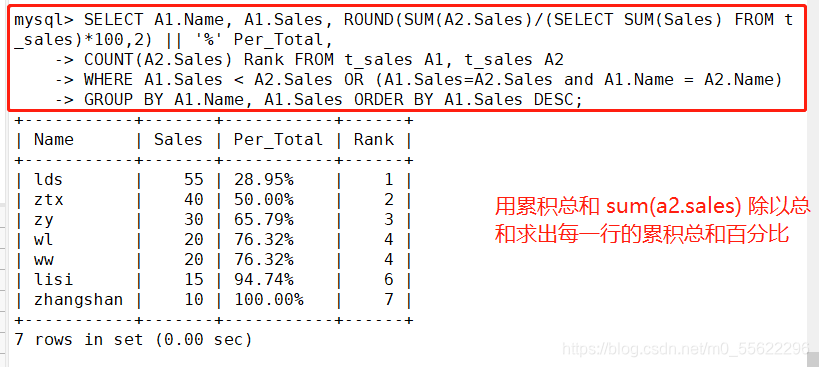
SELECT A1.Name, A1.Sales, ROUND(SUM(A2.Sales)/(SELECT SUM(Sales) FROM t_sales)*100,2) || '%' Per_Total,
COUNT(A2.Sales) Rank FROM t_sales A1, t_sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales=A2.Sales and A1.Name = A2.Name)
GROUP BY A1.Name, A1.Sales ORDER BY A1.Sales DESC;
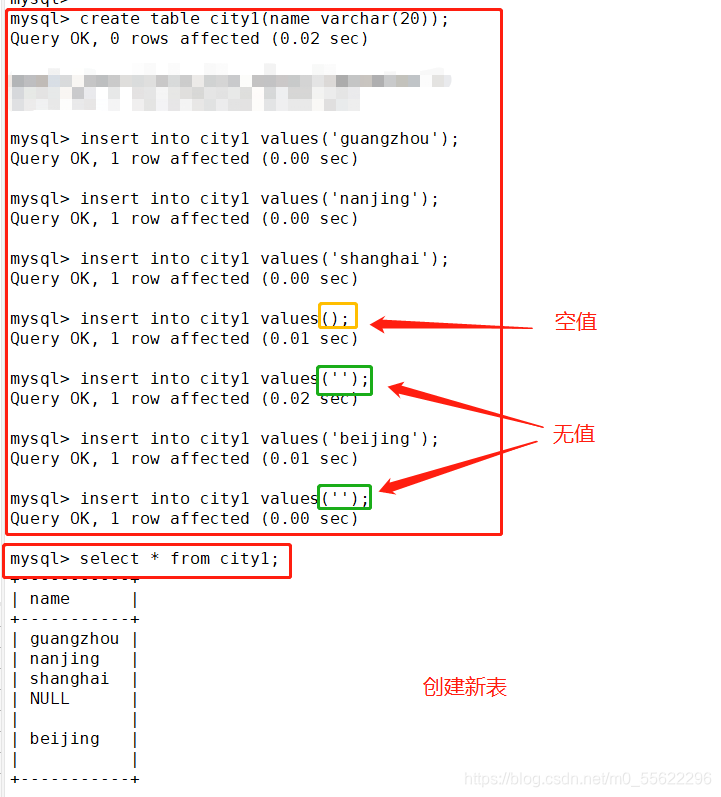
六.空值(null)和 无值(‘ ’)的区别
空值(NULL)和无值(‘’)的区别
1.无值的长度为0,不占用空间的;而NULL 值的长度是NULL,是占用空间的。
2.IS NULL或者IS NOT NULL,是用来判断字段是不是为NULL或者不是NULL,不能查出是不是无值的。
3.无值的判断使用=' '或者<>' '来处理。<>代表不等于。{}
4.在通过count()指定字段统计有多少行数时,如果遇到NULL 值会自动忽略掉,遇到无值会加入到记录中进行计算。
select length(site) from SITE;
select * from SITE where site is NULL;
select * from SITE where site is not NULL;
select * from SITE where site ='';
select * from SITE where site <> '';

七.正则表达式
匹配模式 描述 实例
^ 匹配文本的开始字符 ‘^bd’ 匹配以 bd 开头的字符串
$ 匹配文本的结束字符 ‘qn$’ 匹配以 qn 结尾的字符串
. 匹配任何单个字符 ‘s.t’ 匹配任何 s 和 t 之间有一个字符的字符串
* 匹配零个或多个在它前面的字符 ‘fo*t’ 匹配 t 前面有任意个 o
+ 匹配前面的字符 1 次或多次 ‘hom+’ 匹配以 ho 开头,后面至少一个m 的字符串
字符串 匹配包含指定的字符串 ‘clo’ 匹配含有 clo 的字符串
p1|p2 匹配 p1 或 p2 ‘bg|fg’ 匹配 bg 或者 fg
[...] 匹配字符集合中的任意一个字符 ‘[abc]’ 匹配 a 或者 b 或者 c
[^...] 匹配不在括号中的任何字符 ‘[^ab]’ 匹配不包含 a 或者 b 的字符串
{n} 匹配前面的字符串 n 次 ‘g{2}’ 匹配含有 2 个 g 的字符串
{n,m} 匹配前面的字符串至少 n 次,至多m 次 ‘f{1,3}’ 匹配 f 最少 1 次,最多 3 次
语法: SELECT "栏位" FROM "表名" WHERE "栏位" REGEXP {模式} ;
SELECT * FROM Store_Info WHERE Store_Name REGEXP 'os' ;
SELECT * FROM Store_Info WHERE Store_Name REGEXP '^[A-G]' ;
SELECT * FROM Store_Info WHERE Store_Name REGEXP 'Ho|Bo' ;

八.存储过程
存储过程是一组为了完成特定功能的SQL语句集合
存储过程在使用过程中是将常用或者复杂的工作预先使用sQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。存储过程在执行,上比传统SQL速度更快、执行效率更高
存储过程的优点:
1.执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
2.SQL语句加上控制语句的集合,灵活性高
3.在服务器端存储,客户端调用时,降低网络负载
4.可多次重复被调用,可随时修改,不影响客户端调用
5.可完成所有的数据库操作,也可控制数据库的信息访问权限
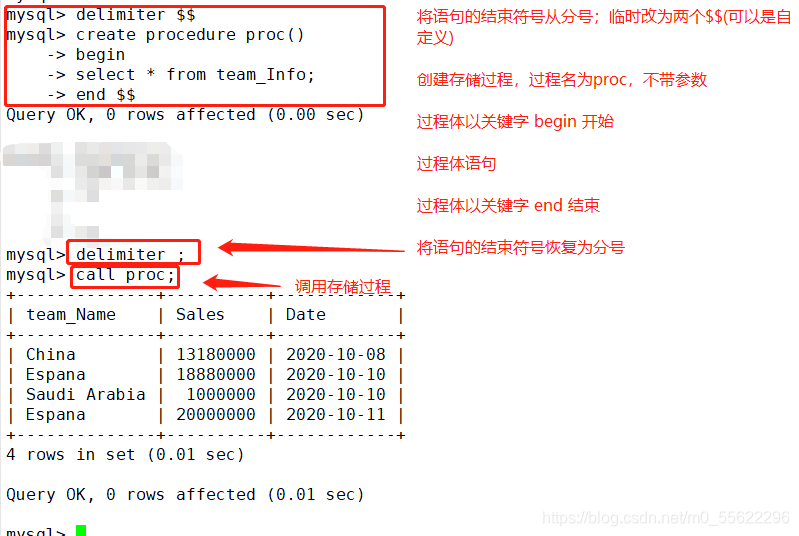
##创建存储过程##
DELIMITER $$ #将语句的结束符号从分号;临时改为两个$$(可以是自定义)
CREATE PROCEDURE Proc() #创建存储过程,过程名为Proc,不带参数
-> BEGIN #过程体以关键字BEGIN 开始
-> select * from Store Info; #过程体语句
-> END $$ #过程体以关键字END结束
DELIMITER ; #将语句的结束符号恢复为分号
##调用存储过程##
CALL Proc;
##查看存储过程#
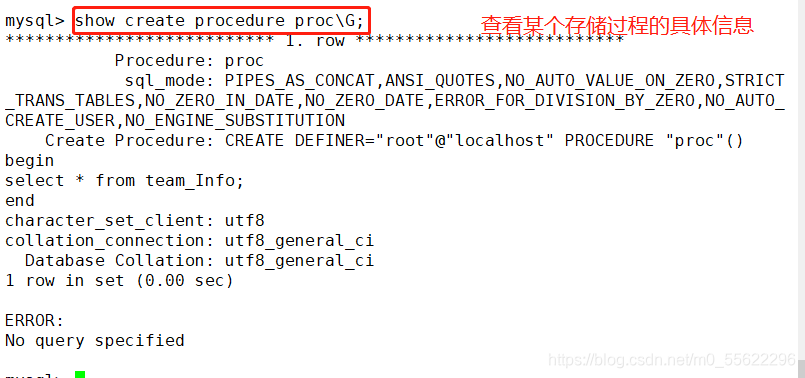
SHOW CREATE PROCEDURE [数据库.] 存储过程名; #查看某个存储过程的具体信息
SHOW CREATE PROCEDURE Proc;
SHOW PROCEDURE STATUS [LIKE '%Proc%'] \G
##存储过程的参数##
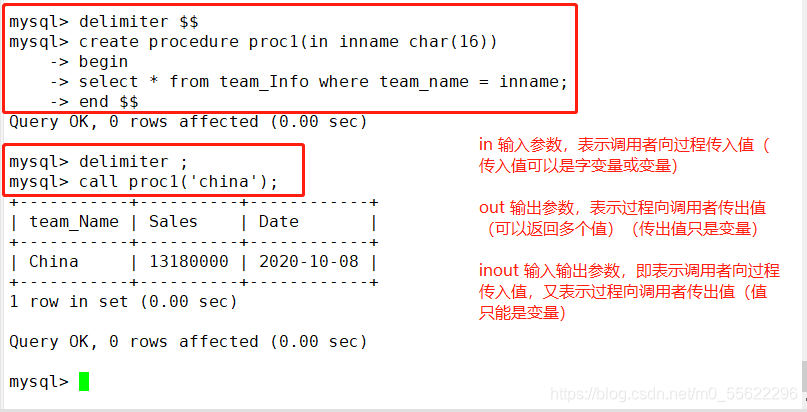
IN输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
OUT输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
INOUT输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
DELIMITER $$
CREATE PROCEDURE Proc1 (IN inname CHAR(16) )
-> BEGIN
-> SELECT * FROM Store_Info WHERE Store_Name = inname;
-> END $$
DELIMITER ;
CALL Proc1 ( 'Boston');
##删除存储过程##
存储过程内容的修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。
DROP PROCEDURE IF EXISTS Proc; #仅当存在时删除,如果指定的过程不存在,则产生一- 个错误
##存储过程的控制语句##
create table t (id int (10));
insert into t values(10);
(1)条件语句if-then-else .... end if
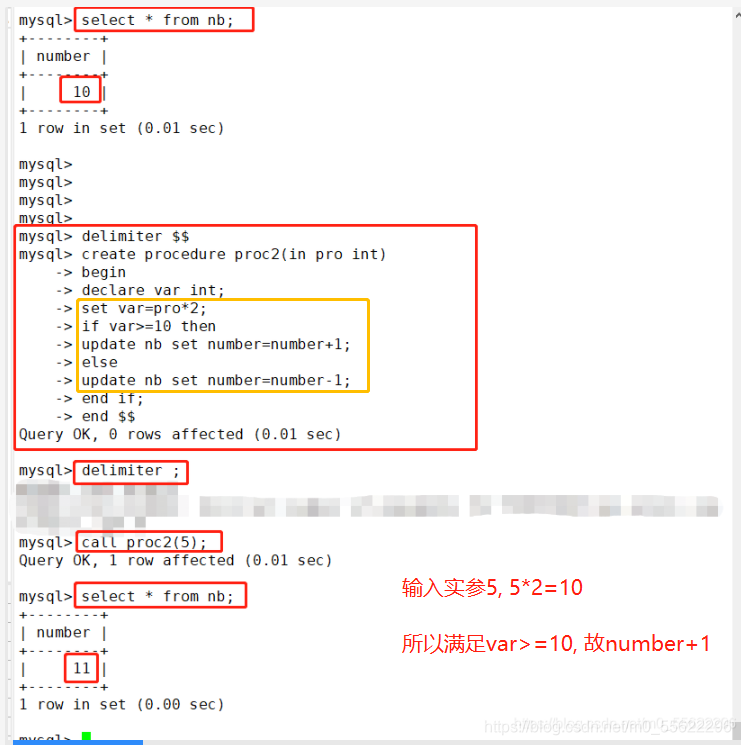
DELIMITER $$
CREATE PROCEDURE proc2(IN pro int)
-> begin
-> declare var int;
-> set var=pro*2;
-> if var>=10 then
-> update t set id=id+1 ;
-> else
-> update t set id=id-1;
-> end if;
-> end $$
DELIMITER ;
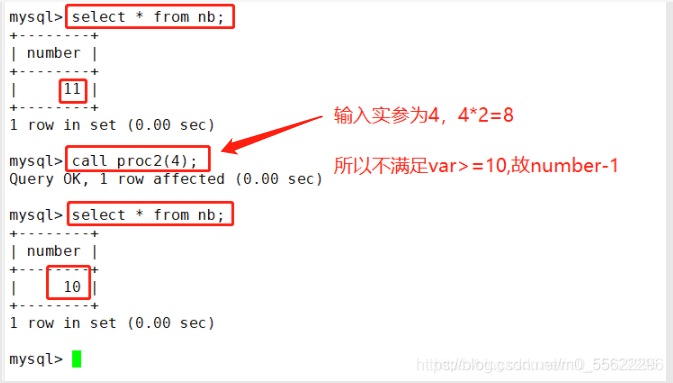
CALL Proc2(6);
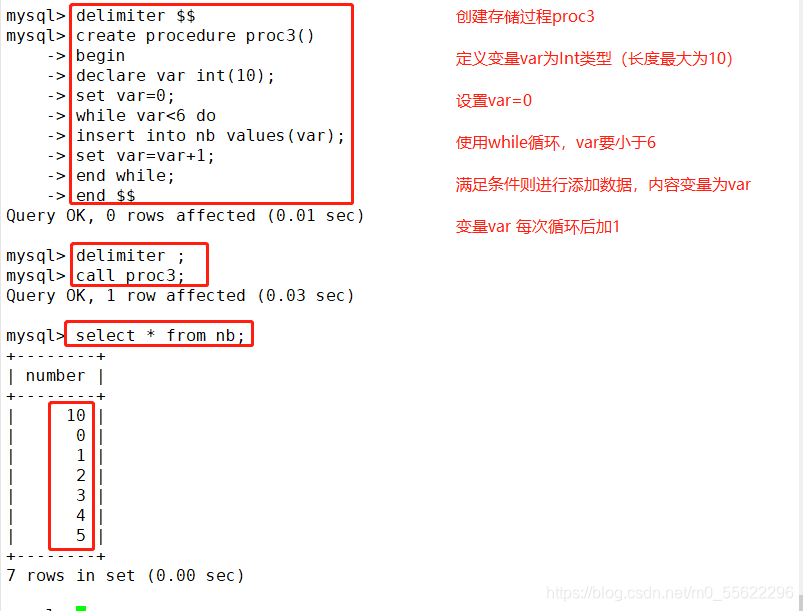
(2)循环语句while .... end while
DELIMITER $$
CREATE PROCEDURE proc3()
-> begin
-> declare var int (10);
-> set var=0;
-> while var<6 do |
-> insert into t values(var);
-> set var=var+1;
-> end while;
-> end $$
DELIMITER ;
CALL Proc3;
创建存储过程
查看存储过程
存储过程的参数
条件语句if
循环语句while















 2802
2802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











