









文章目录
一.Map和Set
1.1主要的数据结构

Set:其实就是披着Set外衣的Map
也是Collection接口的子接口,一次保存一个元素,和List集合最大的区别在于List集合保存的元素不能重复。
Set:使用Set集合来进行去重处理
只要是Collection的子类都能使用for-each进行遍历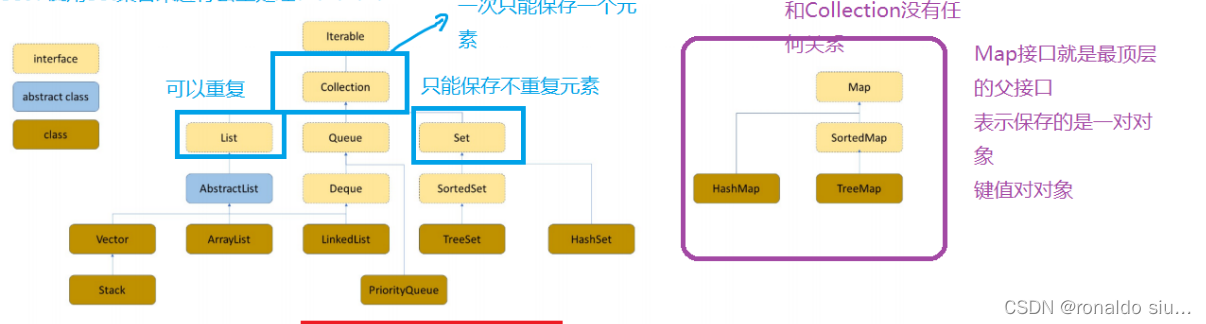
1.2Set集合的基础使用
Set集合元素不重复,使用Set集合去重处理
添加一个元素,若该元素不存在,则添加成功,返回true,若该元素已经存在了,添加失败,返回false
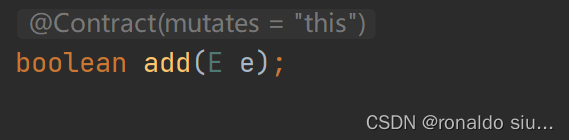
判断一个元素o是否在当前set中存在
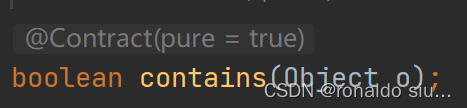
在set集合中删除指定的元素o,若该元素不存在,删除失败,返回false,否则删除该元素,返回true

没有提供修改方法,若需要修改元素,只能先把要修改的元素删除,再添加新元素
遍历集合使用for-each循环即可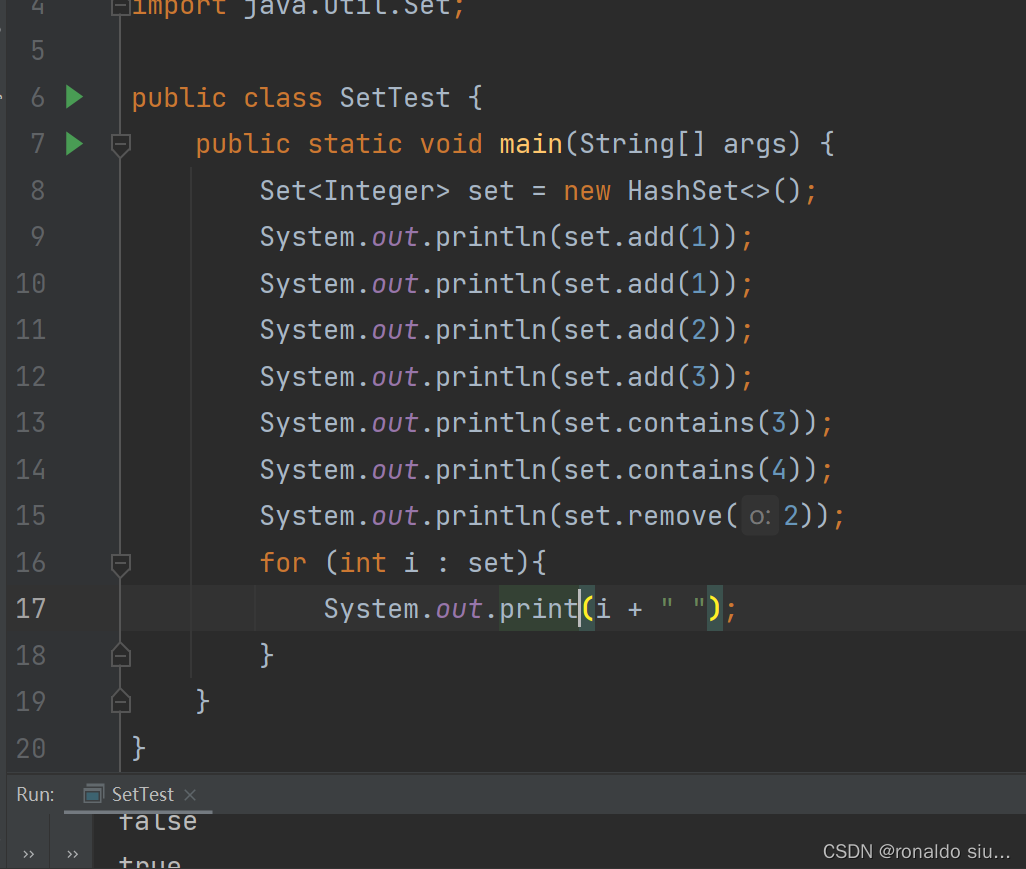
1.3Map集合的基础使用
HashMap:基于哈希表实现
TreeMap:基于RBTree(红黑树-二分平衡搜索树)实现
Map接口=》一对键值对元素 key=value
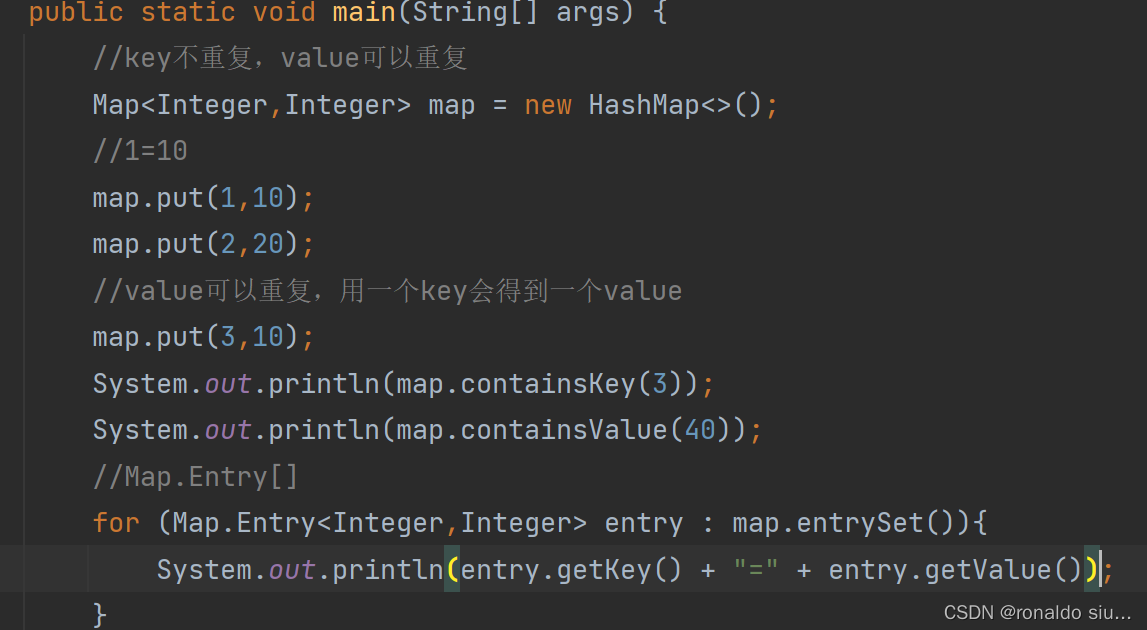
根据相应的k值取出相应的value值

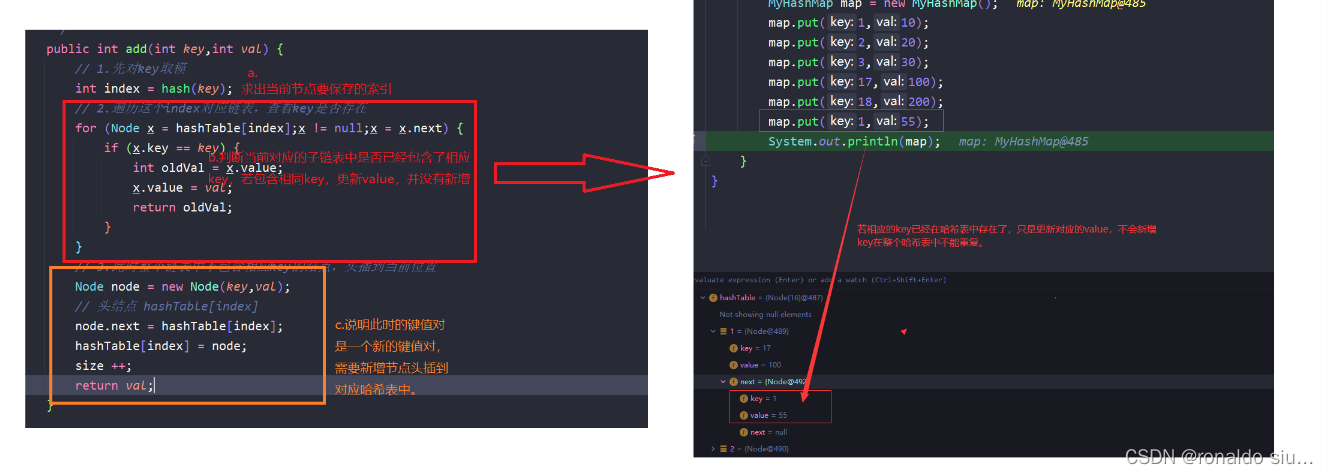
添加一个新的键值对=》若k不存在,就新增一个Map.Entry对象,保存到Map中,若k已经存在,修改原来的value值为新的value值,返回修改前的value值。
新增&修改

删除指定k值的这一对键值对,返回删除的value值

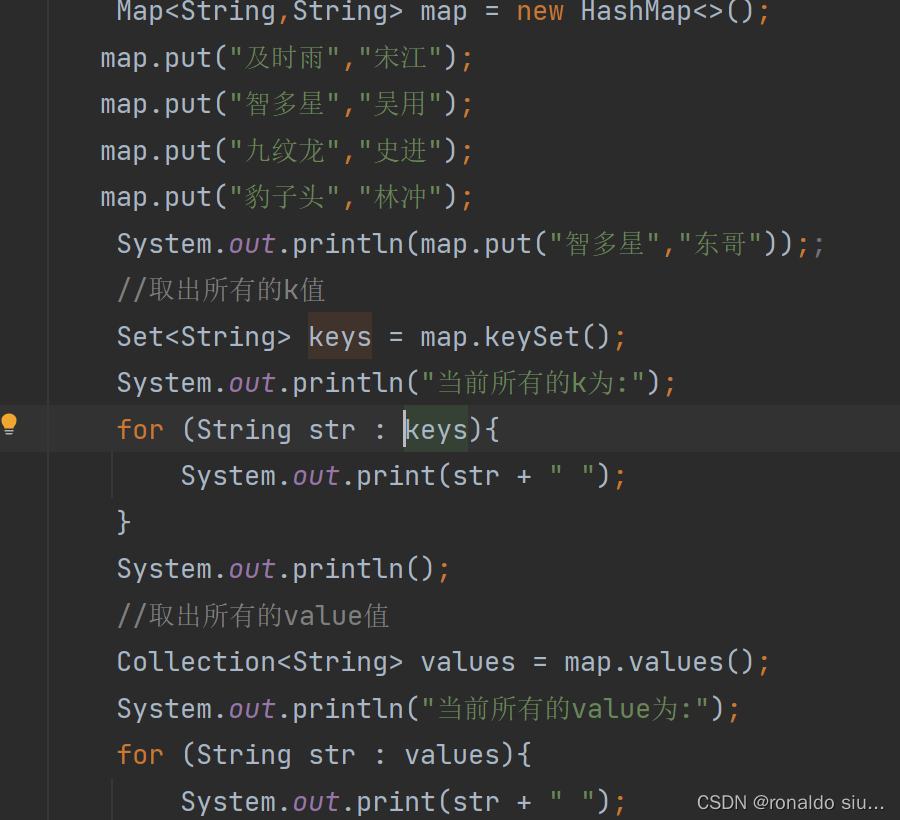
返回当前Map接口中所有的k值集合=》返回值是一个Set
key不能重复=》Set接口中就保存不重复的元素

返回当前Map接口中所有的value值集合,返回值是一个Collection接口
Value可以重复

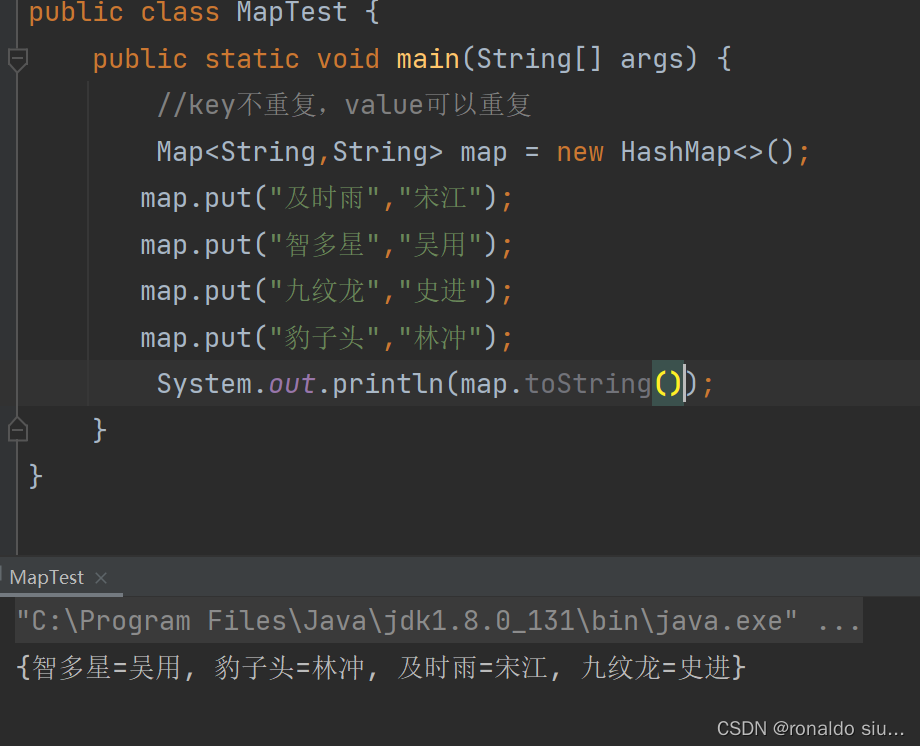
在Map接口元素添加的循序和保存的循序没有必然联系
1.4关于Map接口常见子类的添加问题
1.在Map接口中,元素的添加的循序和保存的循序没有必然联系
不想List,添加顺序和保存顺序一致,先添加1,1这个元素一定保存在2之前,逻辑连续
在HashMap中保存的元素顺序由hash函数来决定
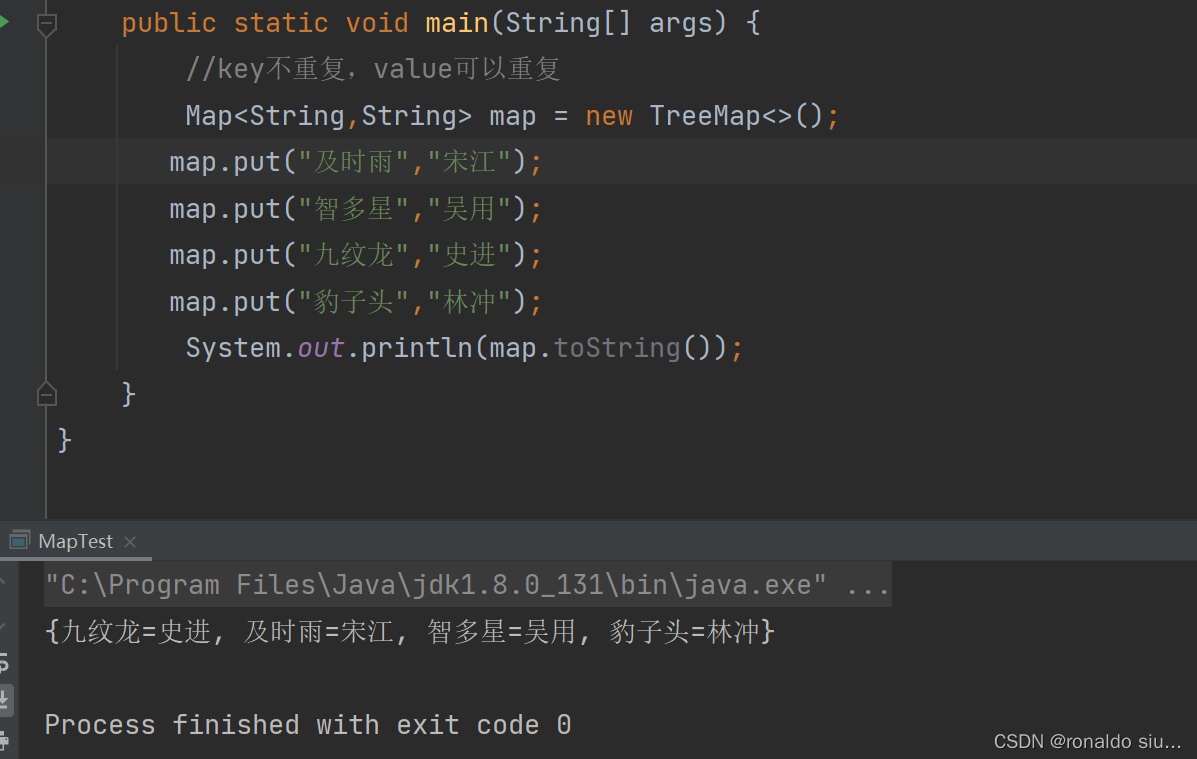
由TreeMap中的compareTo方法决定,要能使用TreeMap保存元素,该类必须要么实现comparable接口,要么传入一个比较器。
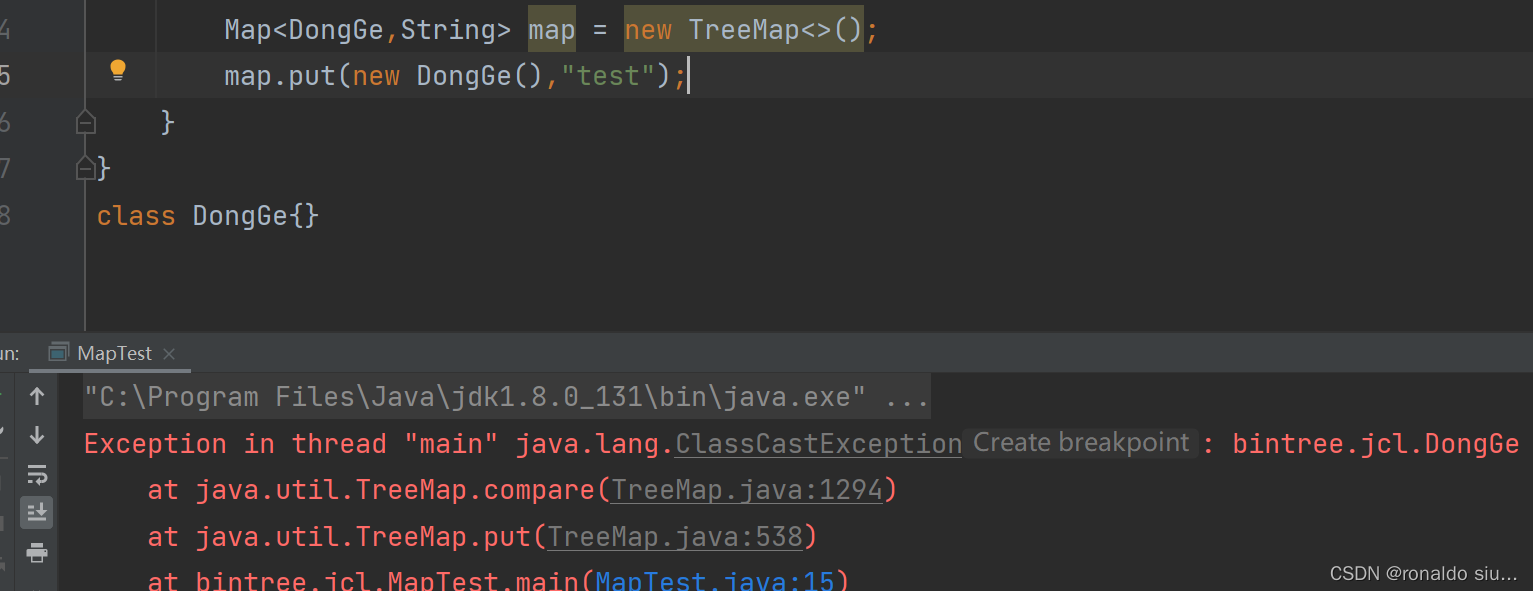
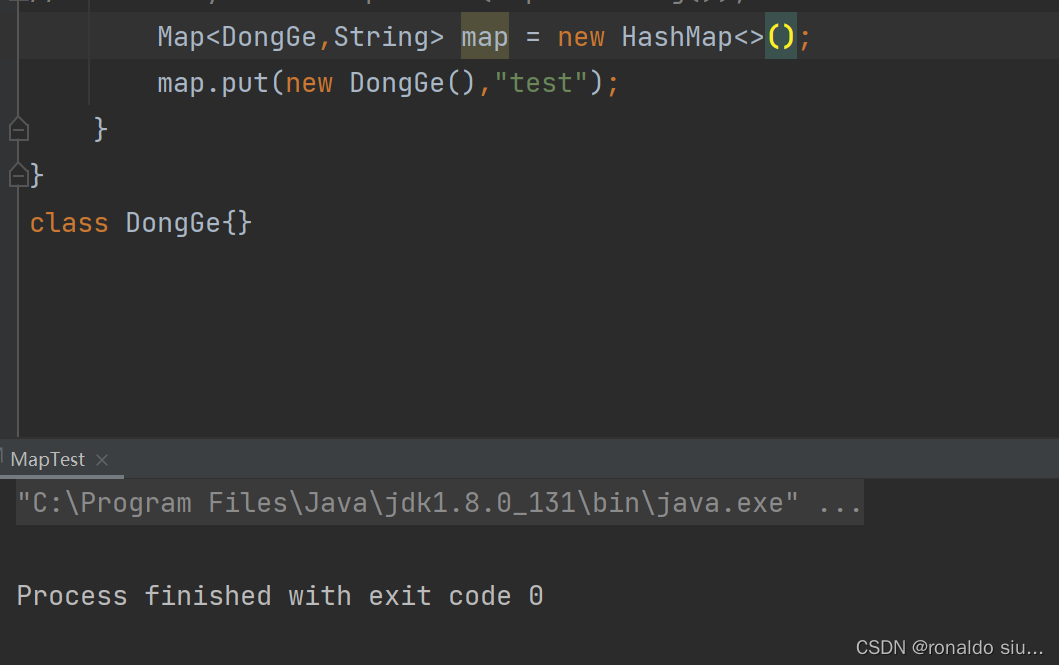
1.5关于保存null值的说明
HashMap的key和value都能为null
若key值为null,有且只有一个
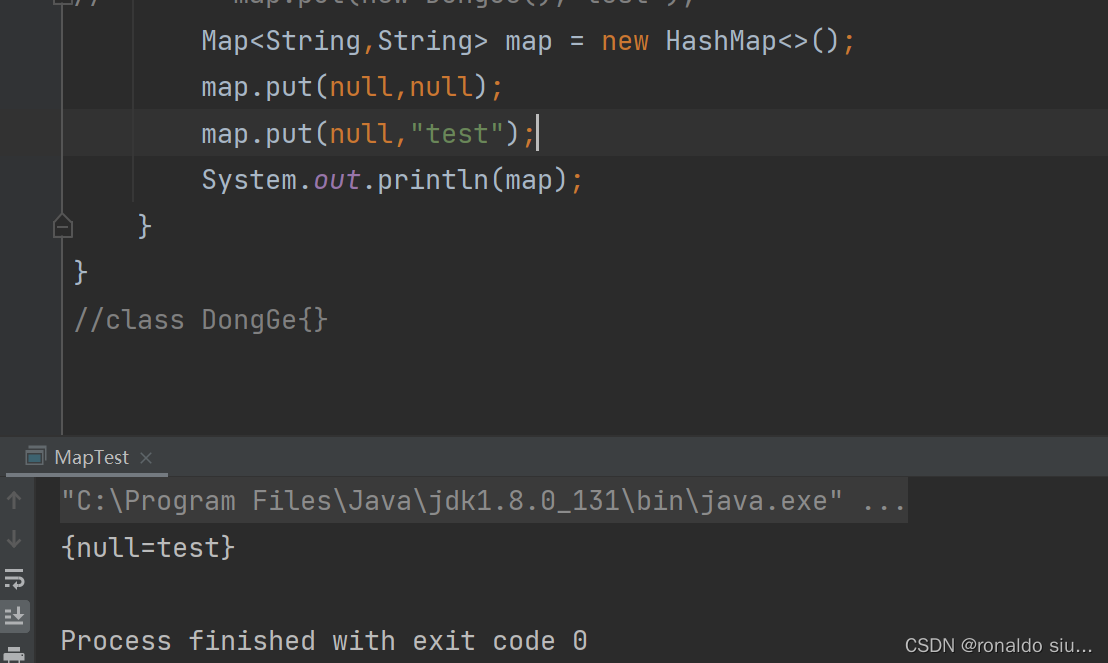
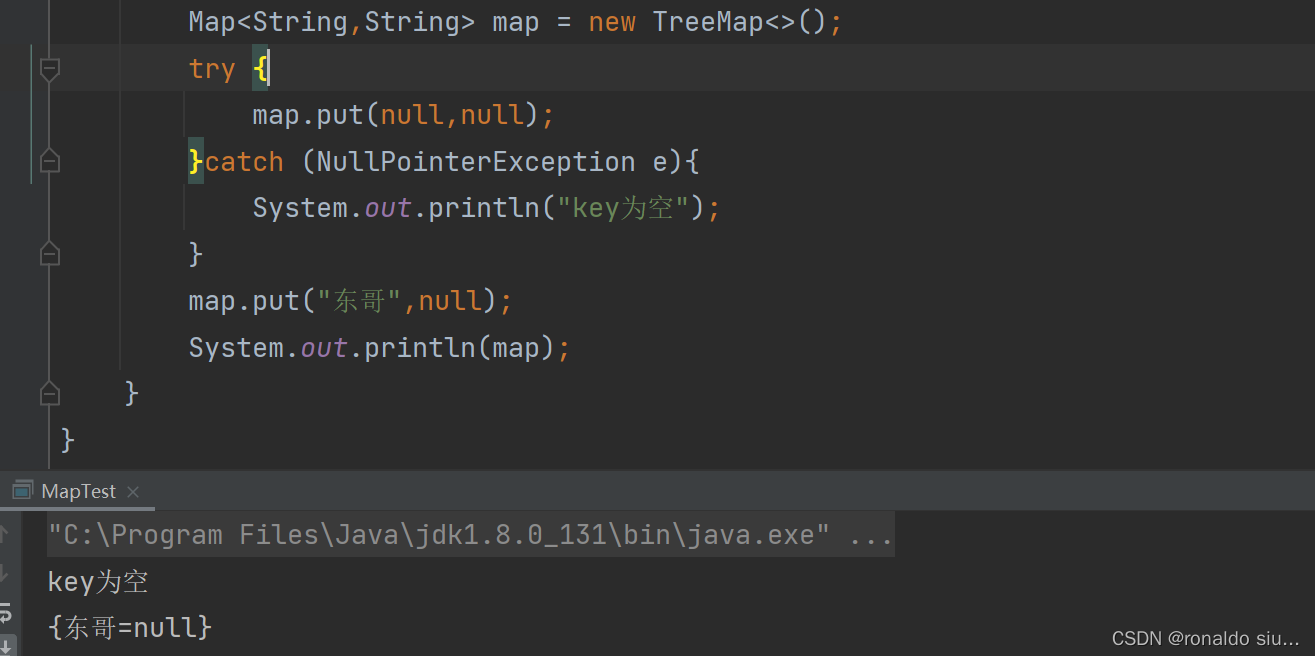
TreeMap中key不能为null
value可以为null
二.哈希函数
2.1什么是哈希函数
‘a’=>0
‘b’=>1
‘c’=>2
…=>唯一转为一个数字
将数据类型obj=》整型 哈希函数
数组中,若知道数组的索引,访问速度为o(1)
哈希表中需要一种方法将任意的数据类型转为数组的索引,这样的一种方法称之为哈希函数。
char=>int可以转换
int=>int(取模,摸一个素数)
String=>int字符串的内部就是字符数组,因此还是按照字符转为int的方式MD5
其他数据类型=》int任意类型都有toString=》String=》int
2.2哈希函数查找
哈希表的高效查找的秘诀就在于数组的随机访问能力,在数组中,若知道索引,可以在O(1)时间复杂度获取到该元素。
用空间换取时间
要在[9,5,2,7,3,6,8]中查找元素是否存在?
就建立一个长度为10的boolean数组,遍历原数组,若该元素在原数组中存在,boolean对应的位置置为true。
boolean[] hash = new boolean[10];
hash[9] = true;
hash[5] = true;
…知道扫描完整个集合。
查询元素3是否在原集合存在,判断hash[3] == true=>O(1)
任意的数字映射为数组的索引
数字值为多少,对应boolean数组的索引为多少~~
此时我们开辟的新哈希数组的大小是按照原数组的最大数值+1,若此时原数组中的数字跨度非常之大,包含负数,现在的这种方式就不再适用
[9,10001,-2,800,55,3000000],没发创造一个一一对应的索引。
若数字本身的值较大,就需要让原数字和下标建立一个映射关系(hash),让跨度较大的一组数据转为跨度很小的一组数据。高效利用有效空间。
哈希函数=将任意的数据类型key=>索引
字符c f© = ‘c’-‘a’=>作为索引
一个班的学号[1…30]=>直接将学号数值作为索引值
身份证号18位=》将大整数=》小整数
一般来说我们将任意的正整数映射为小区间数字的最常用做法“取模”
[10,20,30,40,50]=>[0,1,2,3,4]对原数组进行%4
分布严重不平衡,冲突严重
10%4=2
20%4=0
30%4=2
40%4=0
50%4=2
2.3哈希冲突
哈希冲突:不同的key值经过hash函数的计算得到了相同的值。
在理论上,数学中任意函数法(x),两个不相同的x都一定有可能会映射到相同的y

模一个素数!数论
模一个素数7
分布平均,哈希冲突较少
10%7=3
20%7=6
30%7=2
40%7=5
50%7=1
此时这个数组内的元素被一一映射到不同的小数字
2.4哈希函数设计
哈希函数的设计:哈希冲突在数学领域理论上一定存在
哈希函数最核心的原则:尽可能在空间和时间上求平衡,利用最少的空间获取一个较为平均的数字分布。
模的数字就是开辟的空间大小
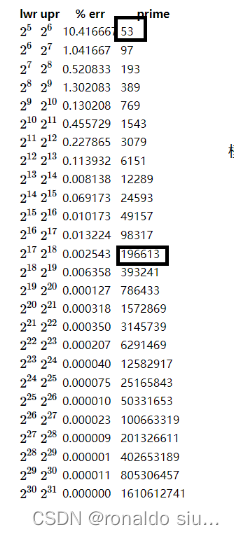
对于一般场景下的哈希函数的设计:
一般来说不用咱自己写,用现成的即可。
MD5,MD4,MD3
SHA1,SHA256
MD5一般用在字符串计算hash值
MD5的特点:
1.定长,无论输入的数据有多长,得到的MD5值固定
2.分散,如果输入的数据稍有偏差,得到的MD5值相差很大(冲突概率非常低,工程领域忽略不计)
3.不可逆,根据字符串计算一个MD5很容易,想通过得到的MD5还原字符串到底是啥,非常之难(基本不可能)
4.根据相同的数据计算的MD5值是稳定的,不会发生变化,稳定性是所有哈希函数都要满足的特点

MD5用途非常广泛:
1.作为hash运算
2.用于加密
3.对比文件内容(内容稍有修改,得到的MD5值天差万别)文件上传下载
我给铭哥发送大小为2G的文件,原文件算MD5值
铭哥在收到后咋知道这个文件内容是否有变化,传输是否成功?
铭哥在收到之后,再把收到的文件计算一个MD5值
原MD5==新MD5=》传输成功
就用的MD5
2.5哈希函数解决
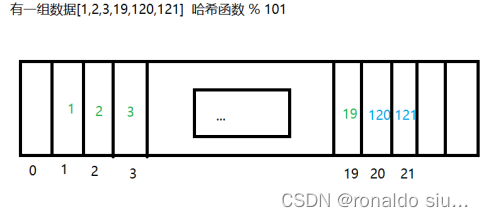
闭散列:当发生冲突时,找到冲突位置的旁边是否存在空闲位置,直到找到第一个空闲位置放入元素,好存难查更难删,工程中很少使用此方案。
当放入元素1时,1%101=1
当放入元素2时,2%101=2
当放入元素3时。3%101=3
当放入元素19时,19%101=19
当放入元素120时,120%101=19而19这个位置已经保存了元素,则继续向后寻找(一个个寻找|再哈希,二次哈希),发现20是一个位置为空,则将120放入20这个位置
当放入元素121时,121%101 = 20,向后寻找找到第一个空闲位置21放入元素
查找:
要查找120时,先120%101=19,发现19这个位置存放的不是120,则继续向后找,知道找到120位置,若一直向后遍历,走完整个数组还没找到,则这个元素不存在。
221%101=19,19这个位置没有此元素,走完整个数组都没找到221,221不存在。
若整个哈希表冲突非常严重,此时查找一个元素从O(1)=>O(n)
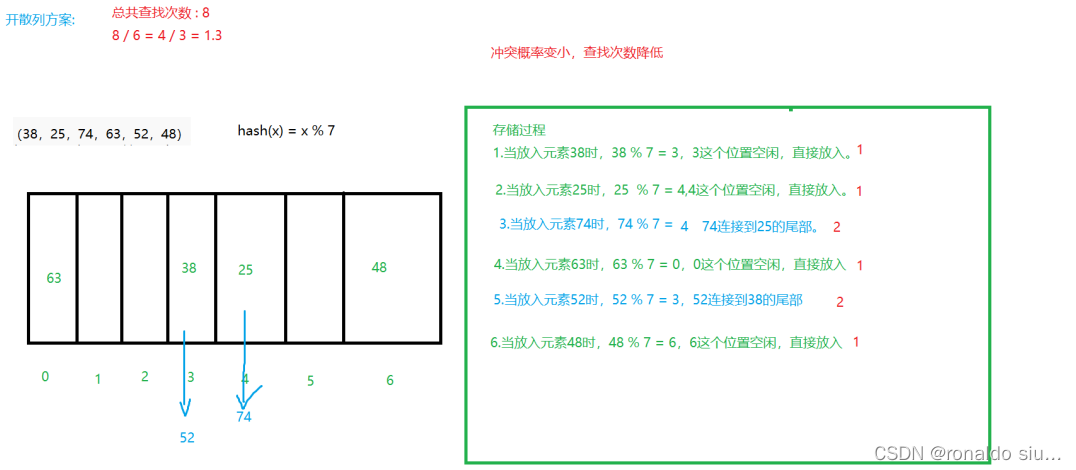
开散列:
若出现哈希冲突,就让这个位置变为链表;
开散列方式下的哈希表:数组+链表
当存入120时,120%10119就将120这个元素连到19的后面(此时和19构成链表)
当存入121时,121%10120
查找任意元素就是取模后若冲突,遍历链表。
最坏情况下,开散列方案遍历小链表
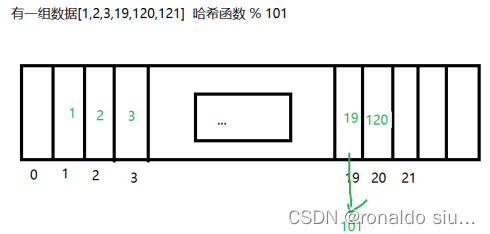
相较于闭散列方案查找次数会大大降低,元素的存储删除和查找,链表的对应操作,相较于闭散列来说,会容易很多
若当前哈希表中某个位置,图中19这个位置冲突非常严重,恰好每个元素取模后都是19,某个数组对应的链表的长度过长导致查找效率降低。
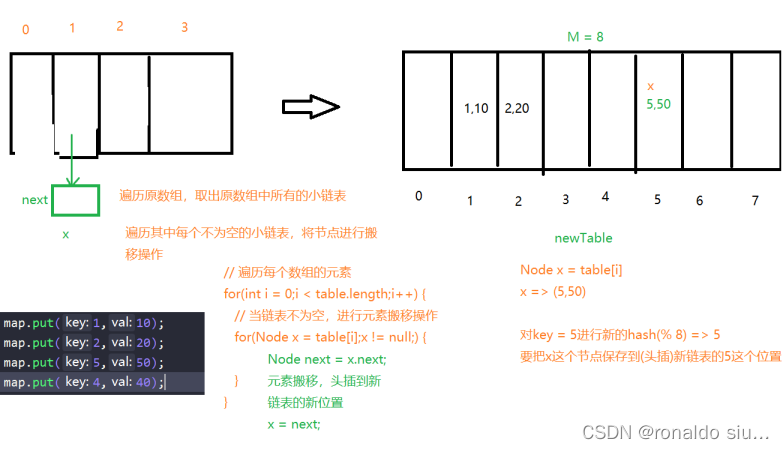
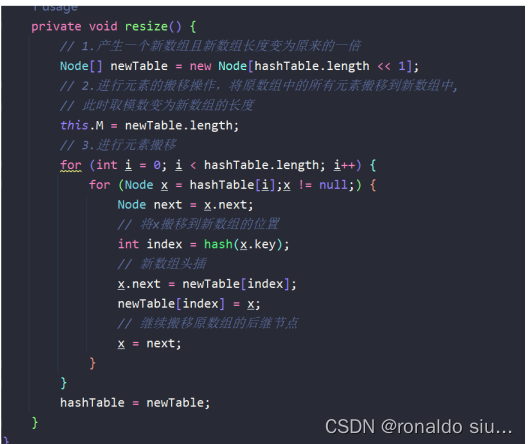
解决方案:1.针对整个数组进行扩容处理(现在数组长度101,扩容到202)就会由原先的%101=>%202,很多原来同一个链表上的元素就会均分到其他新的位置,降低哈希冲突。c++STL的Map
2.将这个冲突严重的链表再次变为新的哈希表/二分搜索树(将O(n)=>O(logn)),不会用整张哈希表进行处理,只处理冲突严重的链表,JDK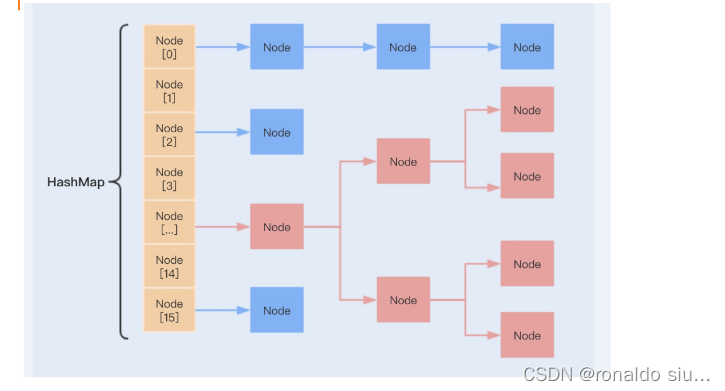

2.6基于开散列方式实现的哈希表
哈希表:数组+链表,哈希数组元素就是每个子链表的头节点
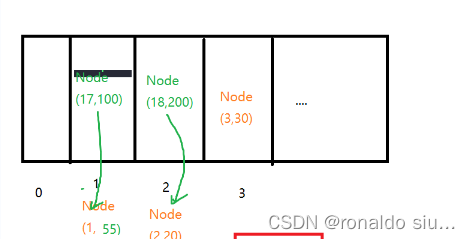
扩容:采用整表扩容的方式
什么时候需要对整个数组的扩容?冲突严重
哈希表最大的特点就是查询快
计算对应的hash,拿到索引,数组查询
我咋知道哈希表冲突严重?
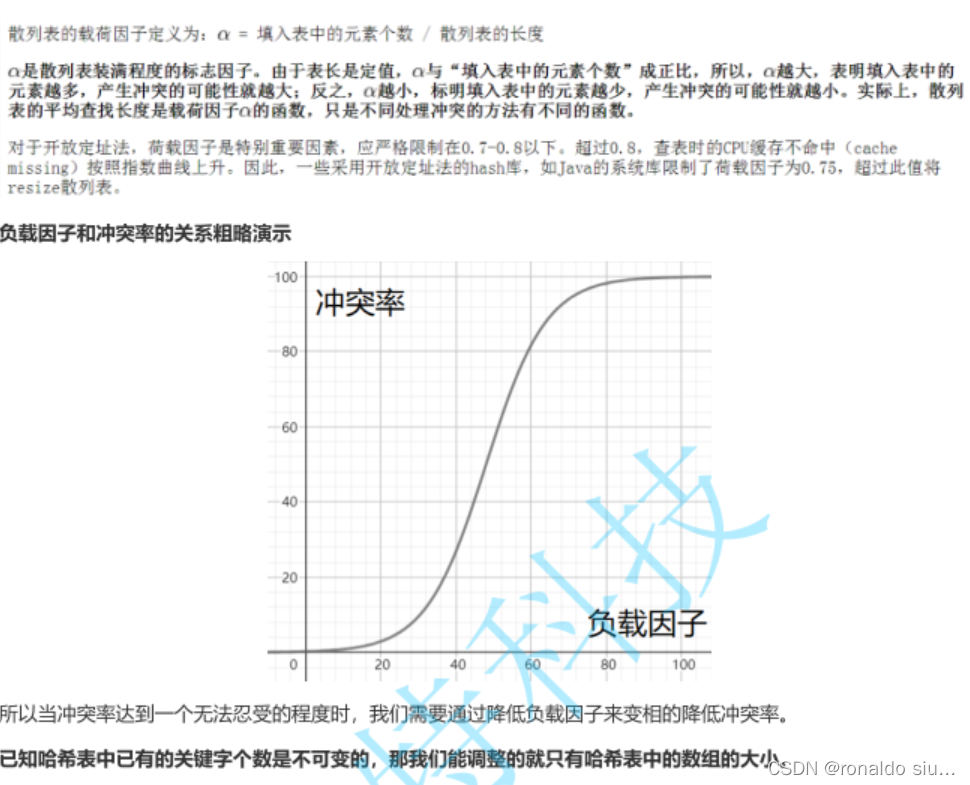
负载因子loadFactor=哈希表的有效元素个数/哈希表长度
这个值越大就说明冲突严重一些
这个值越小说明冲突越小,数组利用率越低
有效元素个数*loadFactor越大,此时哈希表中保存的元素较多
扩容与否就根据负载因子来决定,数组的长度 * 负载因子<=有效元素个数,就需要扩容
假设此时数组长度为16,负载因子=0.75(JDKHashMap的默认负载因子,最高效的查询)
160.75=12,当保存的元素个数>=12,就需要扩容,基本上不冲突,每个链表长度1左右,利用率低
假设此时数组长度=16,负载因子=10(阿里巴巴实验数据,空间利用率较高);
1610=160,保存的元素个数>=160(每个子链表平均长度为10)需要扩容,冲突较上面比较严重,每个链表平均都有10个节点
负载因子就是空间和时间取平衡
负载因子的取舍需要根据我们现实的需求去做实验















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









