







hello!我是小J,每天一个小知识,一起学python,让技术无限发散。
模型类——增删改查
1. 演示工具shell的使用
- hell 工具 ,django中的manage的启动文件提供的,帮助我们提前配置好了当前项目的运行环境(比如数据库连接)用来测试python的语句
使用python manage.py shell 打开shell
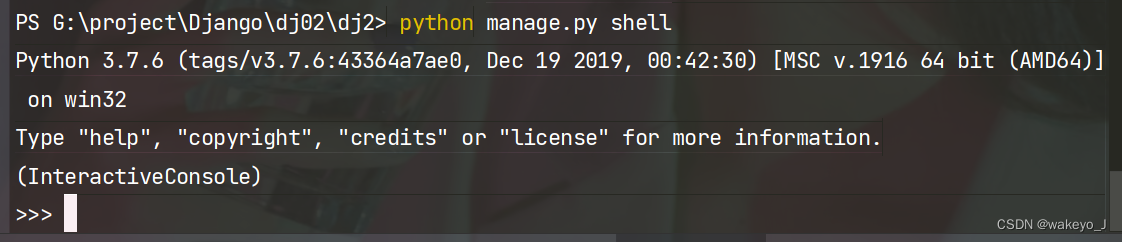
在数据库中插入要查询的数据
insert into bookinfo(name, pub_date, readcount,commentcount, is_delete) values
('射雕英雄传', '1980-5-1', 12, 34, 0),
('天龙八部', '1986-7-24', 36, 40, 0),
('笑傲江湖', '1995-12-24', 20, 80, 0),
('雪山飞狐', '1987-11-11', 58, 24, 0);
insert into peopleinfo(name, gender, book_id, description, is_delete) values
('郭靖', 1, 1, '降龙十八掌', 0),
('黄蓉', 0, 1, '打狗棍法', 0),
('黄药师', 1, 1, '弹指神通', 0),
('欧阳锋', 1, 1, '蛤蟆功', 0),
('梅超风', 0, 1, '九阴白骨爪', 0),
('乔峰', 1, 2, '降龙十八掌', 0),
('段誉', 1, 2, '六脉神剑', 0),
('虚竹', 1, 2, '天山六阳掌', 0),
('王语嫣', 0, 2, '神仙姐姐', 0),
('令狐冲', 1, 3, '独孤九剑', 0),
('任盈盈', 0, 3, '弹琴', 0),
('岳不群', 1, 3, '华山剑法', 0),
('东方不败', 0, 3, '葵花宝典', 0),
('胡斐', 1, 4, '胡家刀法', 0),
('苗若兰', 0, 4, '黄衣', 0),
('程灵素', 0, 4, '医术', 0),
('袁紫衣', 0, 4, '六合拳', 0);
在shell中导入两个模型类
>>> from books.models import BookInfo,PeopleInfo
>>>
2. 添加数据
模型类添加数据有两种方式:
1.先创建一个实例化对象
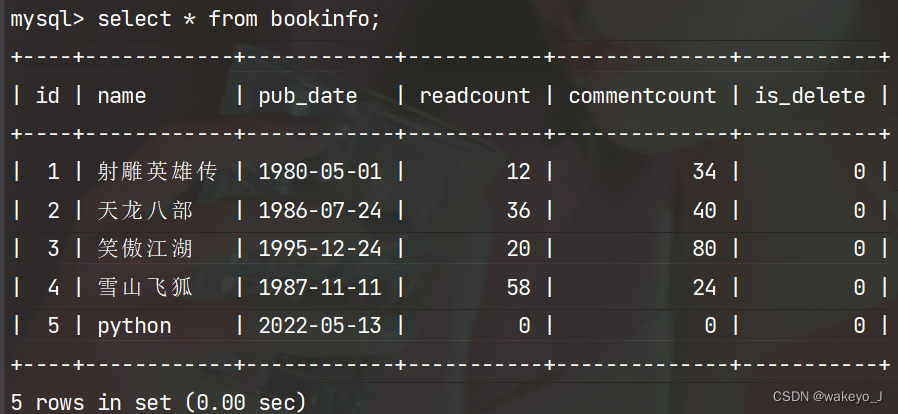
>>> book = BookInfo(name='python',pub_date='2022-5-13')
再使用save()保存数据
>>> book.save()
结果:
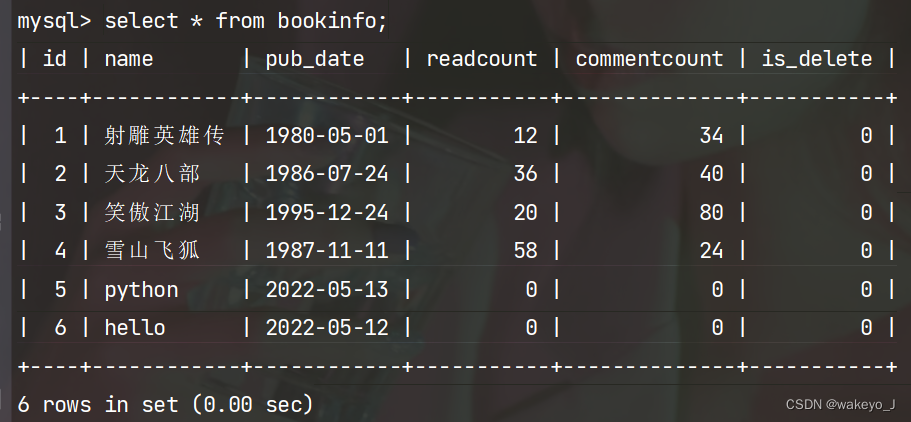
2.objects管理器对象使用create()进行添加数据
>>> BookInfo.objects.create(name='hello',pub_date='2022-5-12')
<BookInfo: hello>
结果:
3. 查询数据
3.1 基础条件查询
- 查询表中一条数据
查询语法:模型类.objects.get(字段=值)得到一个行对象
>>> BookInfo.objects.get(id=1)
<BookInfo: 射雕英雄传>
>>> BookInfo.objects.get(pk=5)
<BookInfo: python>
>>>
- 查询表的所有数据
语法:模型类.objects.all()得到一个查询集
>>> BookInfo.objects.all()
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo
: 雪山飞狐>, <BookInfo: python>, <BookInfo: hello>]>
>>>
- count()查询结果数量
>>> BookInfo.objects.count()
6
3.2 过滤查询
实现MySQL中的where功能:
- filter 过滤出多个结果
- exclude 排除掉符合条件剩下的结果
- get 过滤单一结果
语法:模型类.objects.filter(筛选条件) 或者 查询集.filter(筛选条件)
过滤条件的表达语法如下:
属性名__比较运算符=值
属性名和比较运算符间使用两个下划线,所以属性名不能包括多个下划线
①精准查询
查询id=1的图书,exact表示相等
>>> BookInfo.objects.filter(id__exact=1)
<QuerySet [<BookInfo: 射雕英雄传>]>
>>> BookInfo.objects.filter(id=1)
<QuerySet [<BookInfo: 射雕英雄传>]>
>>> BookInfo.objects.get(id=1)
<BookInfo: 射雕英雄传>
>>> BookInfo.objects.filter(id=1)[0]
<BookInfo: 射雕英雄传>
# BookInfo.objects.get(id=1) 相当于 BookInfo.objects.filter(id=1)[0]
②模糊查询
- contains:是否包含(如果要包含%无需转义,直接写即可)
查询书名含“传”的图书
>>> BookInfo.objects.filter(name__contains='传')
<QuerySet [<BookInfo: 射雕英雄传>]>
>>>
- startswith、endswith:以指定值开头或结尾
查询书名以“天”开头和以’部’结尾的图书
>>> BookInfo.objects.filter(name__startswith='天')
<QuerySet [<BookInfo: 天龙八部>]>
>>> BookInfo.objects.filter(name__endswith='传')
<QuerySet [<BookInfo: 射雕英雄传>]>
>>>
以上运算符都区分大小写,在这些运算符前加上i表示不区分大小写,如iexact、icontains、istartswith、iendswith
3.3 空查询
- isnull:是否为null
查询书名为空的图书
>>> BookInfo.objects.filter(name__isnull=True)
<QuerySet []>
>>>
3.4 范围查询
- in:是否包含在范围内
查询编号为1或3或6的图书
>>> BookInfo.objects.filter(id__in=[1,3,6])
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 笑傲江湖>, <BookInfo: hello>]>
>>>
3.5 比较查询
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于
查询编号小于4的图书
>>> BookInfo.objects.filter(id__lte=4)
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo
: 雪山飞狐>]>
不等于的运算符,使用exclude()过滤器
查询编号不等于4的图书
>>> BookInfo.objects.exclude(id__exact=4)
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo
: python>, <BookInfo: hello>]>
>>>
>>> BookInfo.objects.exclude(id=4)
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo
: python>, <BookInfo: hello>]>
3.6 日期查询
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算
查询1980年发表的图书
>>>BookInfo.objects.filter(pub_date__year=1980)
<QuerySet [<BookInfo: 射雕英雄传>]>
查询2000年1月1日后发表的图书
>>> BookInfo.objects.filter(pub_date__gt='2000-1-1')
<QuerySet [<BookInfo: python>, <BookInfo: hello>]>
3.7 F对象和Q对象
对象的比较属性超过两个通常使用F和Q对象
① F对象的语法格式
BookInfo.objects.filter(字段名__运算符=F('字段名'))
查询阅读量大于评论量的图书和阅读量大于2倍评论量的图书
>>> from django.db.models import F
>>> BookInfo.objects.filter(readcount__gt=F('commentcount'))
<QuerySet [<BookInfo: 雪山飞狐>]>
>>> BookInfo.objects.filter(readcount__gt=F('commentcount')*2)
<QuerySet [<BookInfo: 雪山飞狐>]>
②Q对象,多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字
查询阅读量大于30,并且编号小于5的图书
>>> BookInfo.objects.filter(readcount__gt=30,id__lt=5)
<QuerySet [<BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
>>> BookInfo.objects.filter(readcount__gt=30).filter(id__lt=5)
<QuerySet [<BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
如果需要实现逻辑的查询,需要使用Q()对象结合|运算符
语法:
Q(属性名__运算符=值)

使用Q对象实现查询阅读量大于30,并且编号小于5的图书
>>> BookInfo.objects.filter(Q(readcount__gt=30)|Q(id__lt=5))
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo
: 雪山飞狐>]>
使用Q对象查询编号不等于2的图书
>>> BookInfo.objects.filter(~Q(id=2))
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 笑傲江湖>, <BookInfo: 雪山飞狐>, <BookInfo
: python>, <BookInfo: hello>]>
4. 修改数据
4.1 单一数据修改
- 查:通过get()获取单条数据值对象
- 改:对象.字段=新的值
- 存:对象.save()
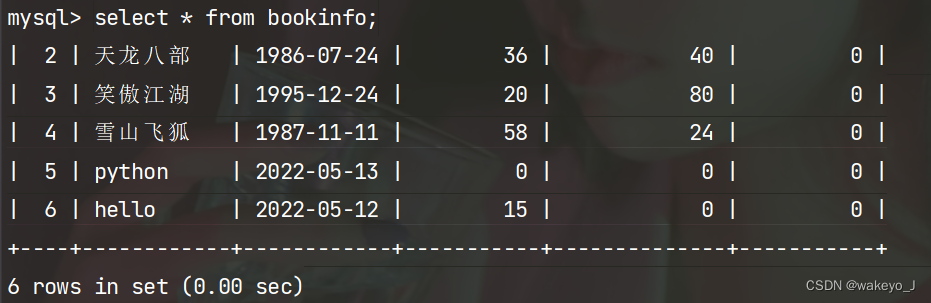
修改hello的阅读量为15
>>> book = BookInfo.objects.get(id=6)
>>> book
<BookInfo: hello>
>>> book.readcount = 15
>>> book.save()
结果:
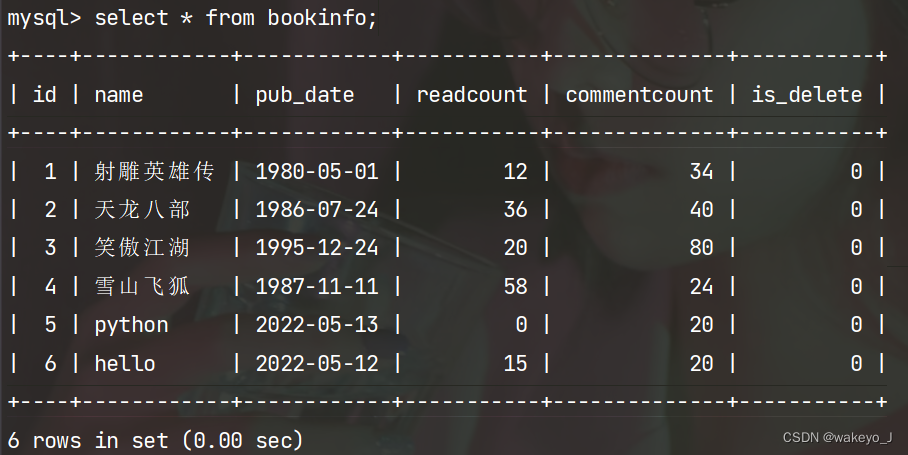
4.2 多条数据修改
- 通过查询语句查出数据
- 对象.update(字段 = 新的值)
>>> book = BookInfo.objects.filter(commentcount=0)
>>> book
<QuerySet [<BookInfo: python>, <BookInfo: hello>]>
>>> book.update(commentcount=20)
2
结果:
5. 删除数据
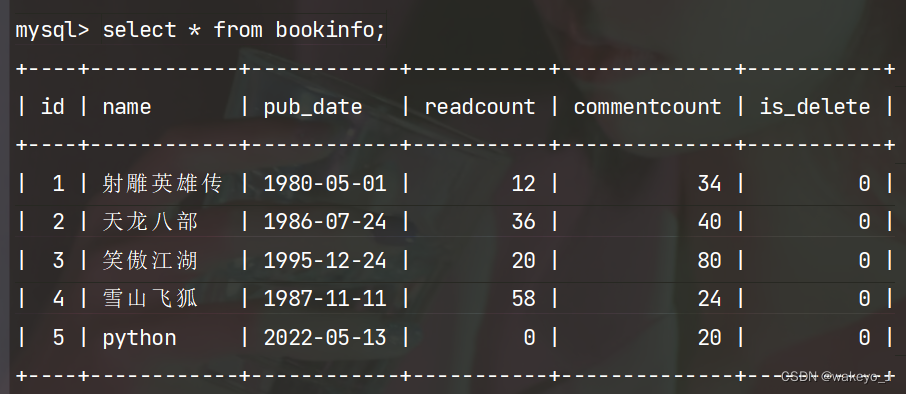
5.1 单一数据删除
- 查:通过get()获取数据
- 删:对象.delete()
删除hello的数据
>>> BookInfo.objects.filter(name='hello')
<QuerySet [<BookInfo: hello>]>
>>> BookInfo.objects.filter(name='hello').delete()
(1, {'books.BookInfo': 1})
结果:
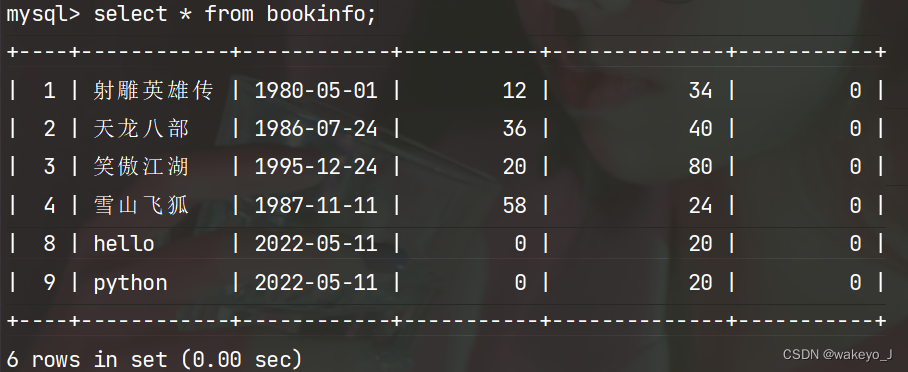
5.2 批量删除数据
- 查:通过filter获得数据
- 删:对象.delete()
>>> BookInfo.objects.filter(id__gt=4)
<QuerySet [<BookInfo: python>, <BookInfo: hello>]>
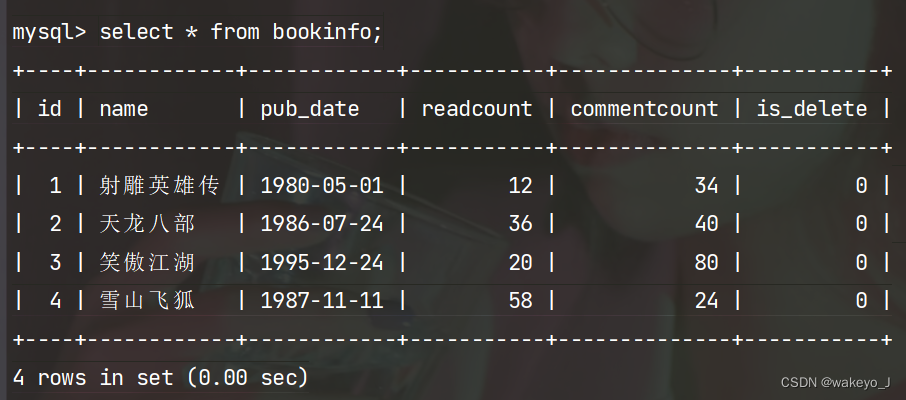
>>> BookInfo.objects.filter(id__gt=4).delete()
(2, {'books.BookInfo': 2})
删除前数据库:
删除后的数据库:
6. 聚合和排序函数
6.1 聚合函数
6.1.1 整表聚合
使用aggregate()过滤器调用聚合函数。聚合函数包括:Avg平均,Count数量,Max最大,Min最小,Sum求和
语法:
模型类名.objects.aggregate(结果变量名 = 聚合函数('列'))
或
模型类名.objects.aggregate(聚合函数('列'))
查询阅读量最少的图书
>>> BookInfo.objects.aggregate(Min('readcount'))
{'readcount__min': 0}
>>> BookInfo.objects.aggregate(name = Min('readcount'))
{'name': 0}
>>> BookInfo.objects.aggregate(name = Max('readcount'))
{'name': 58}
>>> BookInfo.objects.aggregate(Max('readcount'))
{'readcount__max': 58}
6.1.2 分组聚合
返回值:
- 分组后,用 values 取值,则返回值是 QuerySet 数据类型里面为一个个字典;
- 分组后,用 values_list 取值,则返回值是 QuerySet 数据类型里面为一个个元组。
注意:
annotate 里面放聚合函数。
-
values 或者 values_list 放在 annotate 前面:values 或者 values_list 是声明以什么字段分组,annotate 执行分组。
-
values 或者 values_list 放在annotate后面: annotate 表示直接以当前表的pk执行分组,values 或者 values_list 表示查询哪些字段, 并且要将 annotate 里的聚合函数起别名,在 values 或者 values_list 里写其别名。
>>> BookInfo.objects.values('name').annotate(res=Sum('readcount'))
<QuerySet [{'name': '射雕英雄传', 'res': 12}, {'name': '天龙八部', 'res': 36}, {'name':
'笑傲江湖', 'res': 20}, {'name': '雪山飞狐', 'res': 58}, {'name': 'hello', 'res': 0}, {'
name': 'python', 'res': 20}]>
>>> BookInfo.objects.annotate(a=Count('readcount')).values('name','a')
<QuerySet [{'name': '射雕英雄传', 'a': 1}, {'name': '天龙八部', 'a': 1}, {'name': '笑傲
江湖', 'a': 1}, {'name': '雪山飞狐', 'a': 1}, {'name': 'hello', 'a': 1}, {'name': 'pytho
n', 'a': 1}]>
>>> BookInfo.objects.annotate(a=Min('readcount')).values('name','a')
<QuerySet [{'name': '射雕英雄传', 'a': 12}, {'name': '天龙八部', 'a': 36}, {'name': '笑
傲江湖', 'a': 20}, {'name': '雪山飞狐', 'a': 58}, {'name': 'hello', 'a': 0}, {'name': 'p
ython', 'a': 20}]>
6.2 排序函数
使用order_by对结果进行排序,默认是升序
# 默认升序
>>> BookInfo.objects.all().order_by('commentcount')
<QuerySet [<BookInfo: python>, <BookInfo: hello>, <BookInfo: 雪山飞狐>, <BookInfo: 射雕
英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>]>
# 降序
>>> BookInfo.objects.all().order_by('-commentcount')
<QuerySet [<BookInfo: 笑傲江湖>, <BookInfo: 天龙八部>, <BookInfo: 射雕英雄传>, <BookInfo
: 雪山飞狐>, <BookInfo: hello>, <BookInfo: python>]>
7. 关联查询
7.1 一对多查询
一到多的访问语法
一对应的模型类对象.多对应的模型类名小写_set
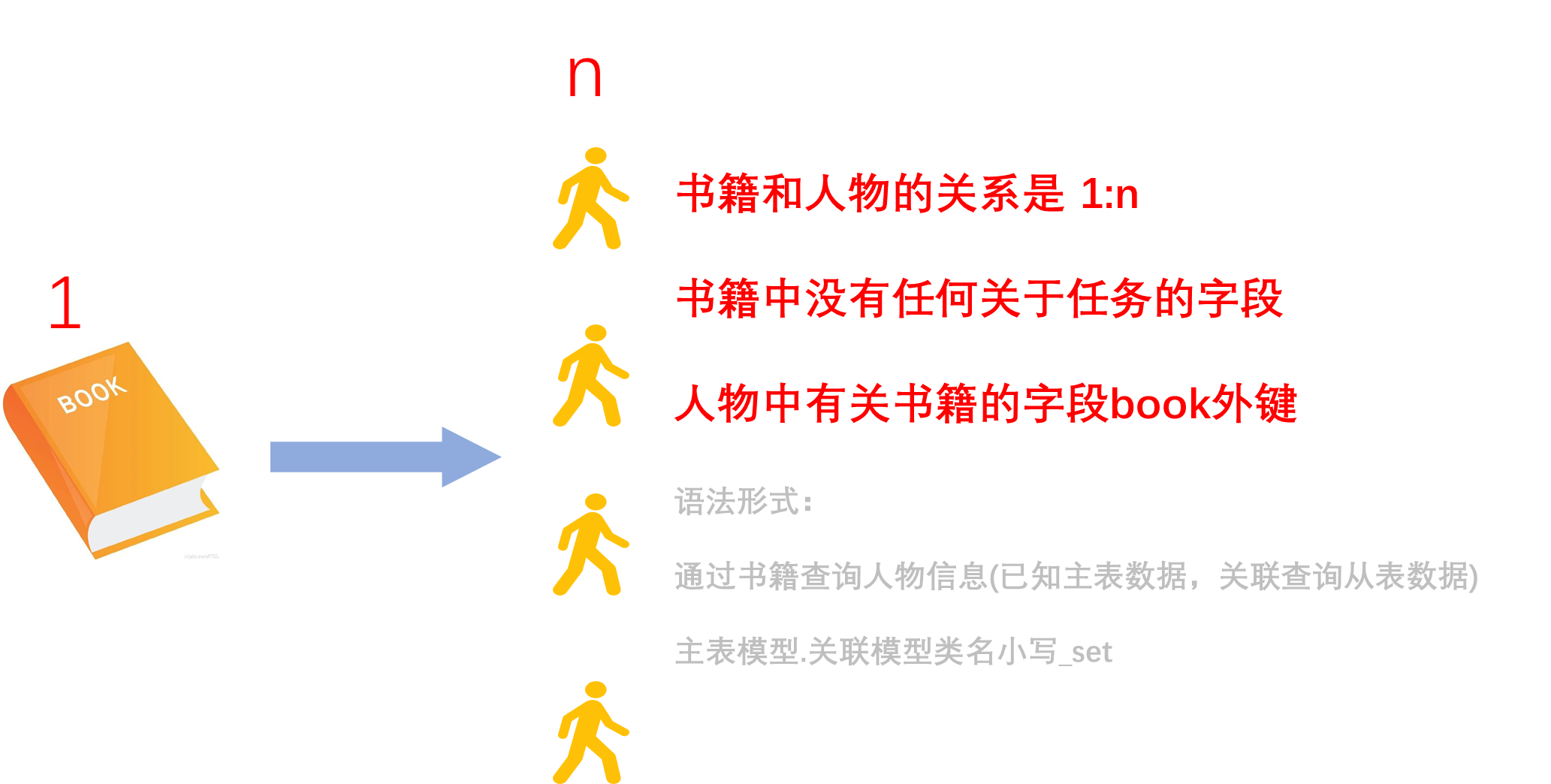
# 查询书籍为1的所有人物信息
>>> BookInfo.objects.get(id__exact=1).peopleinfo_set.all()
<QuerySet [<PeopleInfo: 郭靖>, <PeopleInfo: 黄蓉>, <PeopleInfo: 黄药师>, <PeopleInfo: 欧
阳锋>, <PeopleInfo: 梅超风>]>
7.2 多对一查询
多到一的访问语法
多对应的模型类对象.多对应的模型类中的关系类属性名

# 查询人物为2的书籍信息
>>> PeopleInfo.objects.get(id=2).book
<BookInfo: 射雕英雄传>
>>> PeopleInfo.objects.get(id=2).book_id
1
>>> PeopleInfo.objects.get(id=2).description
'打狗棍法'
7.3 关联过滤查询
①由多模型类条件查询一模型类数据
语法:
关联模型类名小写__属性名__条件运算符=值
注意:如果没有"__运算符"部分,表示等于
# 查询图书,要求图书人物为"郭靖"
>>> BookInfo.objects.filter(peopleinfo__name='郭靖')
<QuerySet [<BookInfo: 射雕英雄传>]>
>>> BookInfo.objects.filter(peopleinfo__gender__gt=0)
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 射雕英雄传>, <BookInfo: 射雕英雄传>, <Book
Info: 天龙八部>, <BookInfo: 天龙八部>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <Book
Info: 笑傲江湖>, <BookInfo: 雪山飞狐>]>
②由一模型类条件查询多模型类数据
语法:
一模型类关联属性名__一模型类属性名__条件运算符=值
注意:如果没有"__运算符"部分,表示等于
# 查询书名为“天龙八部”的所有人物
>>> PeopleInfo.objects.filter(book__name='天龙八部')
<QuerySet [<PeopleInfo: 乔峰>, <PeopleInfo: 段誉>, <PeopleInfo: 虚竹>, <PeopleInfo: 王语
嫣>]>
# 查询图书阅读量大于30的所有人物
>>> PeopleInfo.objects.filter(book__readcount__gt=30)
<QuerySet [<PeopleInfo: 乔峰>, <PeopleInfo: 段誉>, <PeopleInfo: 虚竹>, <PeopleInfo: 王语
嫣>, <PeopleInfo: 胡斐>, <PeopleInfo: 苗若兰>, <PeopleInfo: 程灵素>, <PeopleInfo: 袁紫衣
>]
>>>
8. QuerySet(查询集)
Django的ORM中存在查询集的概念。查询集,也称查询结果集、QuerySet,表示从数据库中获取的对象集合。
当调用如下过滤器方法时,Django会返回查询集(而不是简单的列表):
- all():返回所有数据。
- filter():返回满足条件的数据。
- exclude():返回满足条件之外的数据。
- order_by():对结果进行排序。
对查询集可以再次调用过滤器进行过滤,也就意味着查询集可以含有零个、一个或多个过滤器。过滤器基于所给的参数限制查询的结果。如:
>>> BookInfo.objects.filter(commentcount__gt=30).order_by('pub_date')
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>]>
>>>
- exists():判断查询集中是否有数据,如果有则返回True,没有则返回False
9. 分页
from django.core.paginator import Paginator 导入分页类
>>> books = BookInfo.objects.all() 查询要分页的数据
>>> pageinator = Paginator(books,2) #创建分页实例 添加了分页的参数,分页的页数
<string>:1: UnorderedObjectListWarning: Pagination may yield inconsistent results with an unordered object_
list: <class 'books.models.BookInfo'> QuerySet.
>>> page_skus = pageinator.page(1) # 获取指定的页码数据
page_skus
<Page 1 of 2>
>>> total_page = pageinator.num_pages # 获取总页数
>>> total_page
2
结束语
本文属于作者原创,转载请注明出处,不足之处,希望大家能过给予宝贵的意见,如有侵权,请私信。每天一个小知识,一起学python,让技术无限发散

















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











