









 协程是一种轻量级的并发执行体,它在一个线程内创建,允许多个协程共享资源并主动切换执行。相比线程,协程的切换开销小且无需系统调用,适合处理高并发和IO密集型任务。在IO多路复用场景中,通过协程可以减少线程数量,降低内存开销,提高性能。当协程因IO阻塞时,可以快速切换到其他协程继续执行,避免线程切换的额外成本。
协程是一种轻量级的并发执行体,它在一个线程内创建,允许多个协程共享资源并主动切换执行。相比线程,协程的切换开销小且无需系统调用,适合处理高并发和IO密集型任务。在IO多路复用场景中,通过协程可以减少线程数量,降低内存开销,提高性能。当协程因IO阻塞时,可以快速切换到其他协程继续执行,避免线程切换的额外成本。
协程是什么?具体优势以及使用场景
个人博客地址:sillybaka的博客
此博客参考了许多优质博客(其实很多都说不清楚),最主要是参考了b站up:幼麟实验室 的协程系列视频,总结了关于协程的介绍以及优势、具体的使用场景等
视频链接如下:
协程介绍
协程是线程中的特殊执行体(也可以说是特殊函数),一个线程可以创建多个协程,线程在创建协程的时候会为它分配用户栈空间,多个协程共享所属线程的资源
一个线程同时只能执行一个协程,协程在执行的过程中可以主动让出cpu资源,主动切换,从而让线程调度其他协程继续执行。
但如果中间暂停了,在恢复协程的时候,要如何恢复现场呢?
所以协程也需要上下文资源,比如说标识符、在栈中的存放地址、执行现场(下一条要执行的指令、寄存器值等),在进行协程切换的时候就需要保存它的上下文,便于下次执行时恢复现场
协程的优势
-
协程对于OS来说是透明的,所以说协程的调度就会交由我们程序员进行处理,调度更加灵活
在程序中则会表现为 一个协程就是一个特殊函数,在函数执行体中可以主动发起切换,由我们程序员来自定义切换的时机,同时这样也能够避免诸如时间片切换这种算法的开销 -
协程是存放在用户空间的,所以同一线程下的协程切换不需要进行系统调用,同时也因为协程占有的资源比线程少(因为只占用线程的用户栈的一部分),所以协程切换的开销远远小于线程切换,同时是在用户态下进行切换,没有状态切换的开销
-
在高并发场景下,往往需要创建许多线程来确保高并发的执行,但缺点就在于往往有很多线程是没有在执行的,因为实际上能并发的数量并没有这么多,所以会造成内存开销极大、同时频繁的进行线程切换也会导致执行效率下降
而
引入协程,就能够以少量的线程资源,实现高并发的效果
具体场景 —— IO多路复用场景
Reactor模型很好的对IO多路复用进行了诠释
所以以下我就采用Reactor模型图进行参考
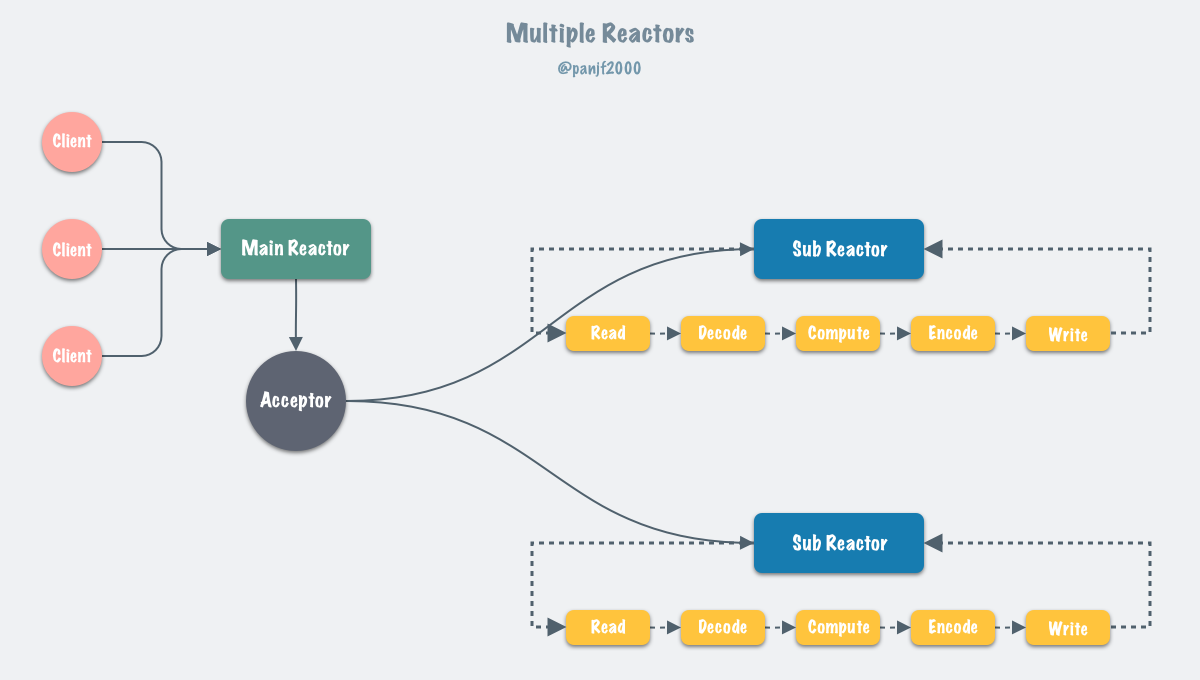
在一般的IO多路复用实现中,都会是由一个线程或是线程组(MainReactor)来监听并建立多个客户端连接(Socket)
然后MainReactor再将这些Socket交给 子线程组(SubReactor)对这些Socket进行事件循环(比如说读事件、写事件、写回事件等)
在子线程组中,一个线程只负责同时处理一个Socket的事件,所以当事件阻塞,比如说读事件在等待数据时,就需要进行线程切换,切换到另一个线程去处理另一个Socket的事件 在这里 线程和Socket是一对一的关系
但这时候弊端就展现出来了
在IO密集型的场景下,子线程池中的线程经常会因为IO而阻塞,所以我们就需要创建更多的线程,从而保证CPU的利用率,这也就导致了内存开销过高,同时因为经常阻塞,所以就要频繁地进行线程切换,线程切换的开销也会很高
那么思考一下,如果我们在这个场景下引入协程呢?结果会不会变得不太一样?
在引入了协程之后,那么我们接下来的模型就变成了
一个线程获取了多个Socket,分配给它的每一个协程,而每一个协程负责一个Socket的事件处理,但每个线程同时只能处理一个协程,即一个Socket
在这里 线程和协程是一对多关系,协程和Socket是一对一关系,
我们再考虑一下刚才的IO密集型场景
我们可以创建充足利用CPU资源的线程数(我们可以将它当做是CPU密集型来设置,因为IO阻塞的开销可以交给协程来解决)而考虑IO阻塞的部分就为每个线程创建多个协程。
在协程足够的情况下,当一个协程因为IO而阻塞后,那就可以进行协程切换,线程将cpu分配给另一个协程继续执行,也就是说 切换的时候就只需要进行协程切换;(当一个线程的协程数不够时则又会发生线程切换)
在这里,我们可以知道,我们无需创建过多的线程,只需要为每个线程创建足够的协程,就可以保证高并发的效果,这样内存上的开销就会小很多
同时,因为只需要进行频繁的协程切换,而线程切换较少,所以在切换这一方面的开销也可以小很多,在性能上也会更高一些。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









