







文章目录
今天是字符串专题的第二天
151.反转字符串里的单词
建议:这道题目基本把 刚刚做过的字符串操作 都覆盖了,不过就算知道解题思路,本题代码并不容易写,要多练一练。
题目链接:代码随想录 (programmercarl.com)
思路
一开始会想到使用split库函数对字符串进行分割,获得单词,然后定义一个新的字符串,把分隔后的番茨倒序相加,获得结果。但是这么做就失去了训练的意义,增加一点难度:如果不使用辅助空间,即空间复杂度要求为O(1),该如何解决
不能使用辅助空间,那么我们只能在原字符串上下功夫了。如果将整个字符串都反转过来,那么各个单词本身也是倒序的,但是单词之间的相对位置变换过来了,所以我们只需要将单词再反转,让单词的顺序正过来,就能获得单词反转后的字符串了
本题的难点在于如何移除多余的空格。题目说明:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。比如s = " hello world ",输出的结果应该是"world hello"。移除多余的空格,需要做到 首尾都不能有空格,单词之间只能有一个空格
参照day1的一道题目 27.移除数组中的元素 ,这道题目中使用快慢指针法移除指定的数组元素,没有用到额外的辅助空间。对于本题,我们可以指定要删除的数组元素为空格' ',利用 快慢指针法 移除多余的空格。但是,本题与 27.移除数组中的元素 有不同之处:我们不能把所有的空格都删除,单词之间需要保留一个空格,首尾都不能有空格。这就像后羿射日,十个太阳里面还要保留一个太阳。这需要我们在 快慢指针法 中加入一些判断
整体思路
- 移除多余空格
- 将整个字符串反转
- 将每个单词反转
举个例子,源字符串为:"the sky is blue "
- 移除多余空格 : “the sky is blue”
- 字符串反转:“eulb si yks eht”
- 单词反转:“blue is sky the”
这样我们就完成了翻转字符串里的单词
接下来详细介绍各步骤的实现思路
移除多余空格
可以参照 27.移除数组中的元素中使用的 快慢指针法。复习一下,我们定义了两个指针:slow和fast,slow指针负责收集满足条件的元素,构成新数组;fast指针负责遍历原数组中的所有元素,探测哪些元素满足条件:
- 如果元素a != val(要删除的元素值),则元素a赋值给nums[slow],然后同时移动fast和slow指针
- 如果元素a == val,则只移动fast指针,继续向后探测。slow指针保持不动
这样,我们获得了一个不含元素val的新数组,这个数组的大小是slow(循环过程中,slow始终指向新数组最后一个元素的下一个位置)
上面分析了本题与 27.移除数组中的元素 的不同:我们不能把所有的空格都删除,单词之间需要保留一个空格,首尾都不能有空格。因此我们需要增加一个bool变量判断当前s[fast]遇到的空格是否为 单词之间的第一个空格。设这个变量名为addSpace
-
初始,
addSpace = false,因为字符串的首个单词前不能有空格 -
遍历过程中
-
若
s[fast] != ' ',则说明进入了一个单词中,设置addSpace:addSpace = true,等待这个单词遍历结束后,在新字符串中添加该单词后的第一个空格(s[slow]负责收集新字符串的字符,构造出新字符串) -
若
a[fast] == ' ' && addSpace == true,这表示当前s[fast]遇到的是单词之后的第一个空格,我们要保留这个空格,需要赋给s[slow]一个空格,即s[slow] = ‘ ’,然后设置addSpace:addSpace = false,忽略后面的所有空格
-
-
遍历结束,上述过程能保证单词与单词之间只有一个空格,字符串的首个单词前没有空格,但如果源字符串的末尾有空格,那么遍历后的字符串的末尾单词后也保留了一个空格。所以我们要对末尾单独进行处理,如果末尾多了空格,也只能多一个空格。因此,如果末尾是空格,我们只需要减小 新字符串的大小,设置新字符串的大小为slow-1,即
s.resize(slow-1);如果末尾不是空格,我们只需要设置新字符串的大小为slow,即s.resize(slow)
经过上述步骤,我们获得了去除了所有额外的空格,接下来对整个字符串进行反转
反转整个字符串
参照day8中的字符串反转题目,我们使用双指针法实现字符串的反转。由于后面还需要对单词进行反转,所以我们要定义一个范围反转函数:reverseString(string &s, int start, int end),反转 s[start]到s[end] 范围内的所有字符
反转各个单词
这也是本题难处理的一个部分。遍历字符串s。当s[i] == ' '时,说明当前遍历完了一个单词,则i-1就是这个单词的末尾位置。遍历过程中,提前用变量start记录这个单词的起始位置。调用函数reverseString(string &s, int start, int end),反转s[start]到s[i-1]范围内的所有字符。最后更新start,start = i + 1,用start记录下一个将要遍历的单词的起始位置
注意边界情况:比较特殊的是s中的最后一个单词,它后面没有空格,需要单独处理。当i超出s.size()-1时,即i == s.size()成立时,此时遍历完了最后一个单词。还是调用reverseString函数,反转s[start]到s[i-1]范围内的所有字符,然后结束遍历
代码实现
class Solution {
public:
// 首先删除所有多余的空格
void removeExtraSpace(string &s)
{
bool addSpace = false;
int slow = 0;
for(int fast = 0; fast < s.size(); fast++)
{
if(s[fast] != ' ')
{
s[slow++] = s[fast];
addSpace = true;
continue;
}
if(addSpace)
{
s[slow++] = ' ';
addSpace = false;
}
}
// 处理结尾空格,上述过程可能导致最后一个元素s[slow-1]是空格(slow指向最后一个元素的下一个位置)
if(s[slow-1] == ' ')
{
s.resize(slow-1);
}else
{
s.resize(slow);
}
}
void reverseString(string &s, int start, int end)
{
int left = start, right = end;
while(right > left)
{
swap(s[left], s[right]);
left++;
right--;
}
}
string reverseWords(string s) {
// 首先去除多余的空格
removeExtraSpace(s);
// 然后反转整个字符串
reverseString(s, 0, s.size()-1);
// 最后对每个单词进行反转
// 当s[i]==' '时,说明遍历完了一个单词,start记录这个单词的起始,而i-1就是这个单词的结尾
// 比较特殊的是s中的最后一个单词,它后面没有空格,需要单独处理
int start = 0; // 第一个单词起始位置是0
for(int i=0; i<=s.size(); ++i)
{
if(i == s.size() || s[i] == ' ')
{
reverseString(s, start, i - 1); // 反转刚遍历完的单词
start = i + 1; // start记录下一个将要遍历的单词的起始位置
}
}
return s;
}
};
总结
本题难度不小,涉及到了 字符串的反转 和 字符串中指定元素的删除(相当于erase函数),而且细节比较多,尤其是对字符串首尾边界的处理 。要好好体会 快慢指针法 在本题中的应用
卡码网:55.右旋转字符串
建议:可以看看前一道题目的解题思路,会有启发的
题目链接:55. 右旋字符串(第八期模拟笔试) (kamacoder.com)
题目说明
字符串的右旋转操作是把字符串尾部的若干个字符转移到字符串的前面。给定一个字符串 s 和一个正整数 k,请编写一个函数,将字符串中的后面 k 个字符移到字符串的前面,实现字符串的右旋转操作
例如,对于输入字符串 “abcdefg” 和整数 2,函数应该将其转换为 “fgabcde”。
输入:输入共包含两行,第一行为一个正整数 k,代表右旋转的位数。第二行为字符串 s,代表需要旋转的字符串。
输出:输出共一行,为进行了右旋转操作后的字符串。
思路
我们不申请额外的空间,只能在本串上操作,这很像上一道题目。思路还是全局反转+局部反转
首先反转整个字符串,reverse(s.begin(), s.end())
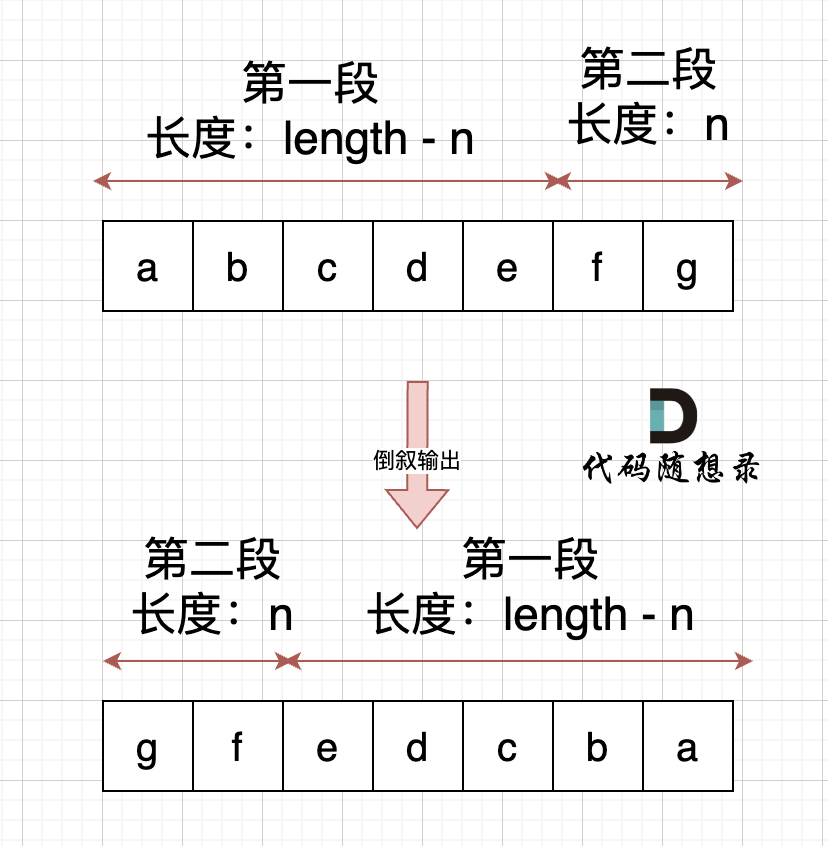
我们把字符串划分为两个部分,前n个字符是一个子串,后面length-n个字符是另一个子串。分别对这两个子串进行局部反转:
reverse(s.begin(), s.begin() + n)
reverse(s.begin()+n, s.end())
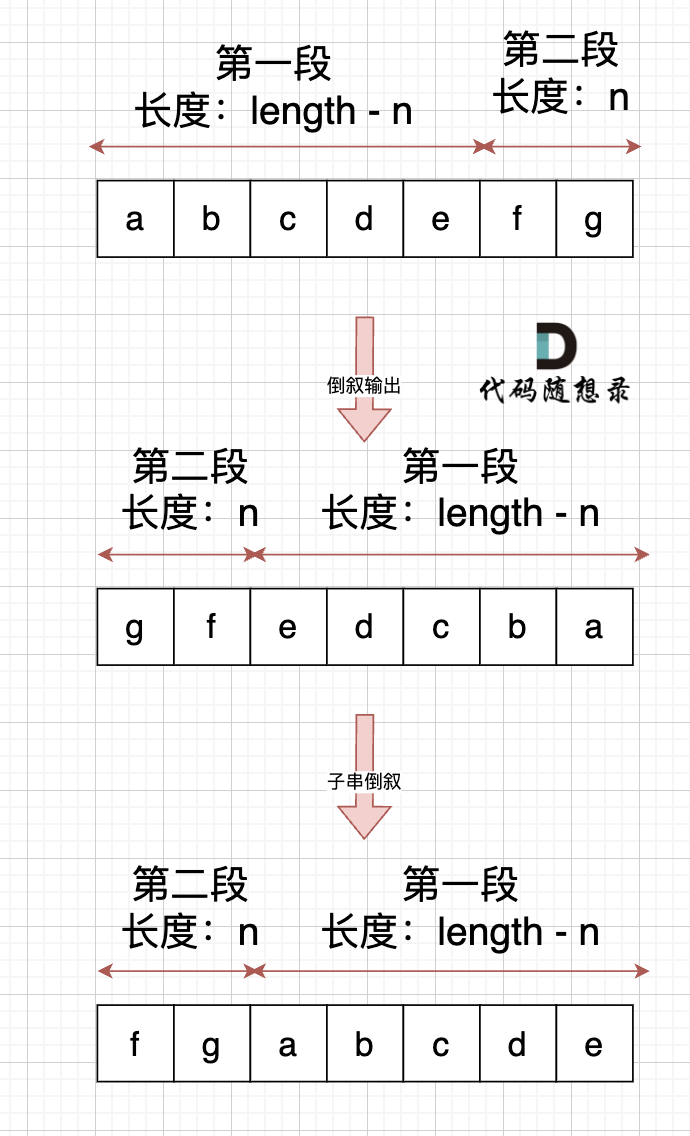
也可以先局部反转,再进行整体反转。整体反转变换了子串的相对位置,局部反转变换子串本身的内容
代码实现
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{
int n;
string s;
cin >> n;
cin >> s;
// 首先对整个字符串进行反转
reverse(s.begin(), s.end());
// 然后分别对 前k个字符 和 第k个~s.size()-1个字符反转
reverse(s.begin(), s.begin() + n);
reverse(s.begin() + n, s.end());
cout << s << endl;
return 0;
}
使用库函数reverse,不要忘记导入algorithm库
KMP算法
KMP算法用来匹配字符串,它的思想是:当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容(文本串的某个子串 和 模式串不匹配,一定是从某一位开始才不一样的,前面都匹配上了),利用这些信息避免从头再做匹配
KMP是一个非常精致且巧妙的算法,这个视频讲的很不错:https://www.youtube.com/watch?v=GTJr8OvyEVQ,接下来用视频中的例子讲解KMP算法的大体思路

上面是文本串,下面是模式串。我们要在文本串中找到一个和模式串相同的子串
上面指针text指向x时,下面指针pattern指向c,子串和模式串在这一位不相同,匹配失败了。按照一般的思路,我们会将text向前移动到子串(abcdabx)的第二个字符b处,pattern移动到模式串的第一个字符a处,继续进行比较。但是KMP保留了这次匹配过程中的部分匹配信息,虽然这个子串和模式串没有匹配成功,但是 子串和模式串 部分匹配上了一个串:abcdab。我们该怎么利用这个信息进行下一个匹配过程呢?
首先定义一些基本概念
基本概念
-
前缀
字符串的前缀是指不包含最后一个字符的所有以第一个字符(索引为0)开头的连续子串,以abcdab为例,它的前缀有a、ab、abc、abcd、abcda
-
后缀
字符串的后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串,以abcdab为例,它的后缀有bcdab、cdab、dab、ab、b
-
公共前后缀
公共前后缀:一个字符串的 所有前缀连续子串 和 所有后缀连续子串 中相等的子串,以abcdab为例,它的公共前后缀为ab
-
最长公共前后缀
最长公共前后缀:所有公共前后缀 的 长度最长的 那个子串,在abcdab中,最长公共前后缀是ab
我们可以利用 当前的部分匹配 和 部分匹配串的最长公共前后缀 决定指针pattern应该移到哪个位置进行下一次匹配

- 部分匹配串的最长公共前后缀:部分匹配串为abcdab,它的最长公共前后缀是ab,这意味着abcdab有一个前缀ab对应后缀ab
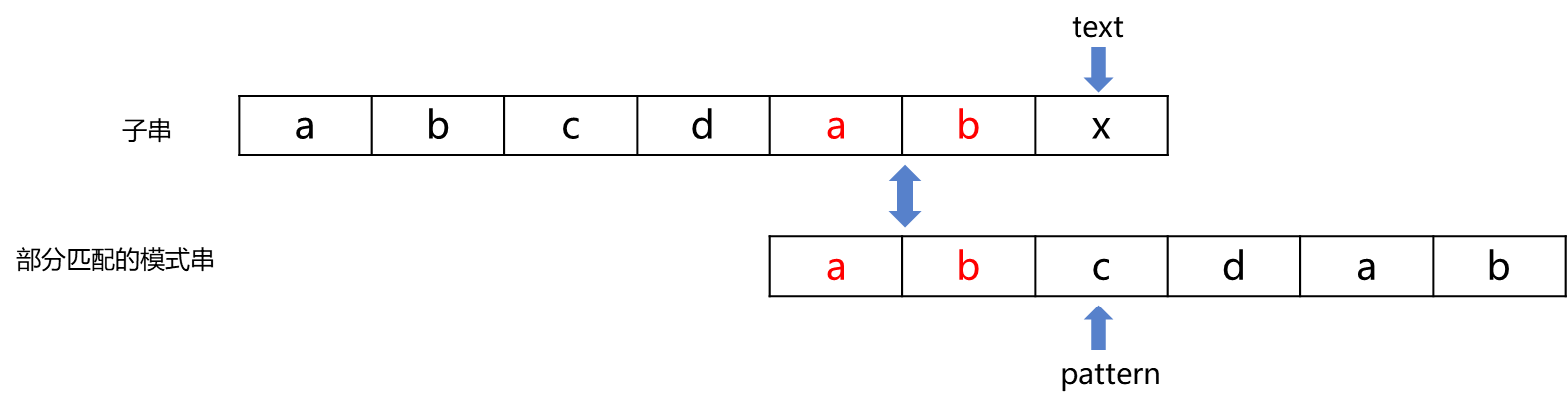
- 当前的部分匹配:子串为abcdabx,部分匹配串为abcdab,指针text指向子符x。abcdab 的后缀ab 匹配上了 子串abcdabx中高亮的ab。由于abcda的最长公共前后缀是ab,所以abcdab中有一个前缀ab对应后缀ab,因此abcdab的前缀ab 匹配上了 子串abcdabx中高亮的ab,这就是我们利用 当前的部分匹配 和 部分匹配串的最长公共前后缀 分析出来的结果:abcdab的前缀ab 匹配上了 子串abcdabx中高亮的ab
- 根据上述分析,我们只需要将pattern回退到abcdab的第三个位置处,令pattern指向字符c,而text指针不动,依然指向字符x,然后开始进行下一次匹配
如图所示:
由部分匹配可知,部分匹配串的abcdab后缀ab 匹配上了 子串abcdabx中的ab

由部分匹配串的最长公共前后缀为ab可知,部分匹配串abcdab有一个前缀ab 与 后缀ab相对应

因此,部分匹配串abcdab的前缀ab 匹配上了 子串的abcdabx的ab,pattern移动到第三个字符c的位置处,继续匹配
KMP的整个过程是这样的:匹配->匹配失败,pattern回退到模式串的某个位置,text不动->匹配->···->匹配->匹配成功 或 text到达文本串的末尾,结束匹配
可以看到指针text始终在向后移动,不会回退,因此KMP算法匹配的时间复杂度是O(n),n是文本串的长度
大体的思路已经说完了,那么该如何实现KMP算法呢?部分匹配串可能是模式串的任何子串,我们如何为各个部分匹配串找到的最长前后缀呢?这就需要用到部分匹配表了
部分匹配表next
对于字符串str,从 第一个字符开始的每个子串 的 最后一个字符 与 该子串的最长公共前后缀的长度 的对应关系表格。这个表我们以 int[] next 数组方式进行存储。实际上,next[i]存放的是 部分匹配串str[0] ~ str[i]的最长公共前后缀的长度
假设当前模式串为aabaabaaa,求这个模式串的next数组:
创建两个指针i、j:
-
初始:j指向str[0],i指向str[1],next[0] = 0

-
指针i从前向后 遍历模式串,比较str[i]与str[j],填充next数组,有三种情况:
-
若str[i] == str[j],则
next[i] = j + 1,然后i、j同时向后移动一位比如j = 0,i = 1时,str[i] == str[j](都是字符a),则next[i] = j + 1,即next[1] = 0 + 1 = 1,然后i、j向后移动一位,j = 1,i = 2。对于字符串aa而言,它的最长公共前后缀是a,长度为1,因此next[1] = 1是正确的。实际上,i每遍历到一个字符str[i]时,都在计算字符串
str[0]~str[i]的最长公共前缀的长度,然后把长度值填到next[i]中。j指向的是这个字符串的 最长相同前缀 的最后一个字符,i指向 最长相同后缀 的最后一个字符,所以要比较i、j指向的字符是否相同,如果str[i] == str[j],则说明 最长相同前缀 的长度为j+1,因此next[i] = j + 1
-
若str[i] != str[j],有以下两种情况:
-
j != 0,即j没有指向第一个字符,则j跳跃到下标为next[j-1]的字符上,即j = next[j-1],然后再比较str[i] == str[j]比如j = 1,i = 2时,str[i]为b,str[j]为a,因此str[i] != str[j],则
j = next[j-1],即j = next[0],j回退到下标为0的字符处,j指向第一个字符,然后再比较str[i] == str[j]
-
j == 0,即j指向第一个字符,且str[i] != str[j],说明此时没有公共前后缀,则停止回退j,next[i] = 0,然后i向后移动一位,j不动接着上面的例子,此时j = 0,i = 2,且str[i]为b,str[j]为a,str[i] != str[j],则next[i] = 0,即next[2] = 0,然后i向后移动一位,i=3

-
-
我们介绍了遍历过程中的三种可能情况,也同时举例完成了这个next数组的前3位。接下来继续遍历,填充完数组next:
-
i == 3
此时j=0,str[i] == str[j](都为字符a),因此next[i] = j + 1,即next[3] = 0 + 1,然后i、j同时向后移动一位
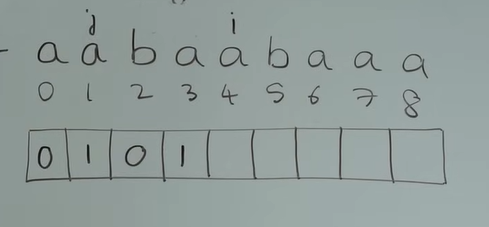
-
i == 4
此时j==1,str[i] == str[j](都为字符a),因此next[i] = j + 1,即next[4] = 1 + 1,然后i、j同时向后移动一位

-
i == 5
此时j==2,str[i] == str[j](都为字符b),因此next[i] = j + 1,即next[5] = 2 + 1,然后i、j同时向后移动一位

-
i == 6
此时j==3,str[i] == str[j](都为字符a),因此next[i] = j + 1,即next[6] = 3 + 1,然后i、j同时向后移动一位

-
i == 7
此时j==4,str[i] == str[j](都为字符a),因此next[i] = j + 1,即next[7] = 4 + 1,然后i、j同时向后移动一位

-
i == 8(重点)
此时j==5,str[i] != str[j](i指向字符a,j指向字符b),则j要回退到下标为next[j-1]的位置上,即next[4] == 2的位置上,j = 2

此时j==2,str[i] != str[j](i指向字符a,j指向字符b),则j要回退到下标为next[j-1]的位置上,即next[1] == 1的位置上,j = 1

此时j==1,str[i] == str[j](都是字符a),则next[i] = j + 1,即next[8] = 1 + 1。由于i指向了最后一个字符,遍历结束,next数组也被填完了
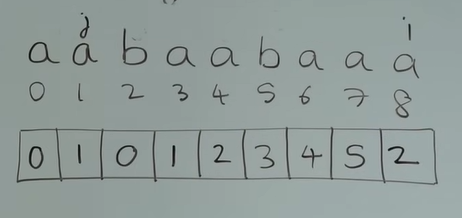
可以看到,这个方法的时间复杂度是O(m),m是匹配串的长度,空间复杂度也是O(m)
j = next[j-1]的解释
启发:文本串中匹配模式串
前面我们分析了i、j的本质:对于当前的字符串str[0]~str[i],j指向这个字符串 最长相同前缀 的最后一个字符,i指向这个字符串 最长相同后缀 的最后一个字符,这里的 最长相同前/后缀 就是 字符串str[0]~str[i]的最长公共前后缀中的前/后缀。当str[i] != str[j] 并且 j != 0时,需要将j回退,寻找新的最长公共前后缀。根据上面对i、j本质的分析,寻找新的最长公共前后缀 等价于 将j回退到某个位置,使str[m]~str[i](m为j-1)与str[0]~str[j]重合。你会发现这个过程并不陌生,在文本串text中寻找模式串pattern时 我们遇到过类似的过程。设文本串指针为i,模式串指针为j,当text[i] != pattern[j]时,需要利用部分匹配信息 和 部分匹配串的最长公共前后缀将j回退,而i不动,直至text[i] == pattern[j]或者text[i] != pattern[j] && j == 0(模式串的第一个元素 和 text[i]也不同)时,才将i向后移动一位。这个过程中,我们在比较pattern[0]~pattern[j]与text[m]~text[i](m为j-1)是否重合。
举个例子:文本串为aabaaa,模式串为aabaab,如图所示:
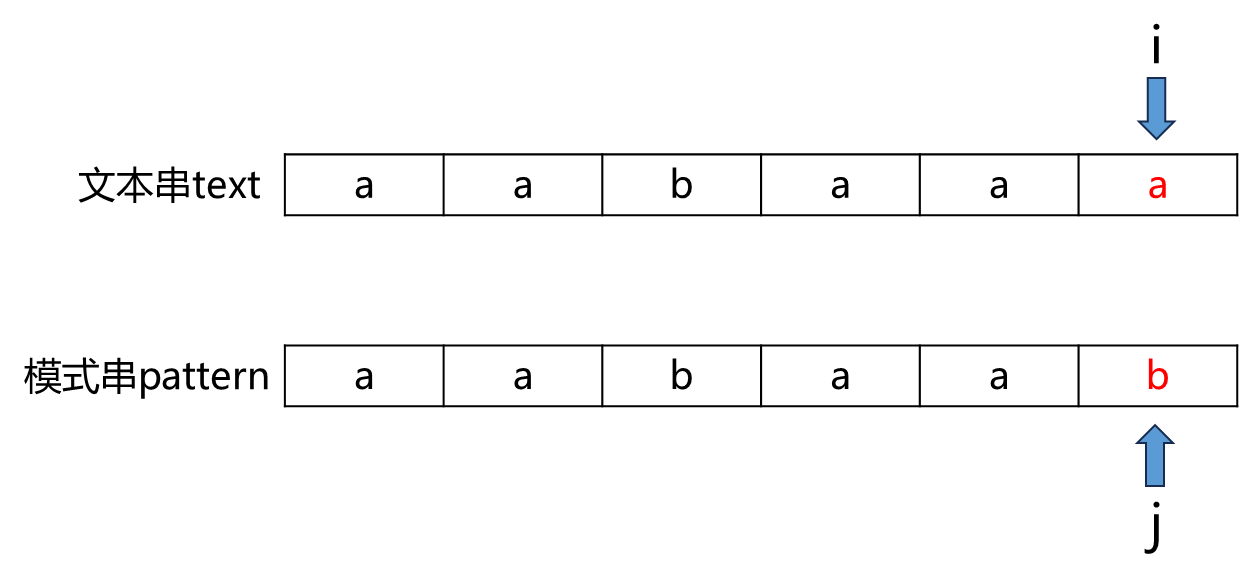
部分匹配串为aabaa,最长公共前后缀是aa:

根据部分匹配信息,文本串aabaaa中高亮的aa 匹配上了 部分匹配串aabaa的后缀aa
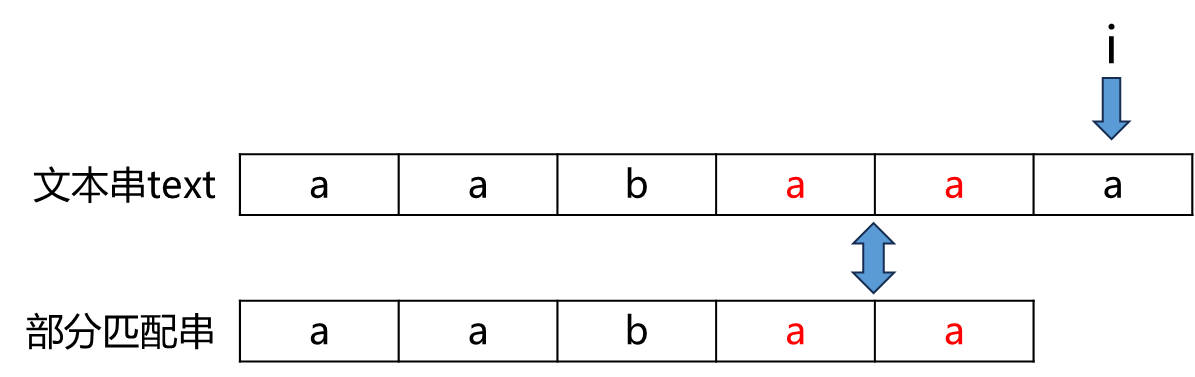
因此,文本串aabaaa中高亮的aa 匹配上了 部分匹配串aabaa的前缀aa。因此我们将模式串上的指针j移到前缀aa之后,继续比较text[i] 与pattern[j]。实际上,这就是在比较pattern[0]~pattern[j]与text[m]~text[i](m为j-1)是否重合。由于pattern[0]~pattern[j-1] 与 text[m]~text[i-1](m为j-1)必然匹配上了(由前面的分析可知),所以我们只需要比较text[i] 与pattern[j]:
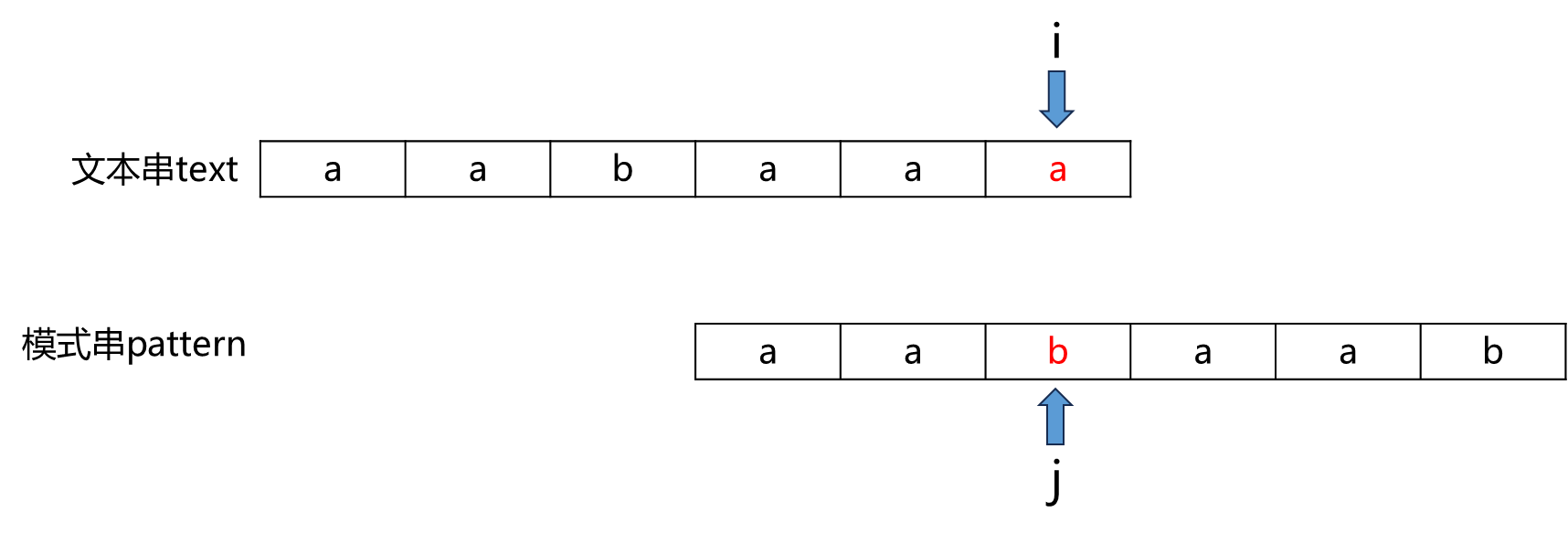
发现text[i] != pattern[j],因此j还要回退。本次部分匹配串是aa,最长公共前后缀是a,因此我们将j移动到 部分匹配串aa前缀a的后一位(原理同上):
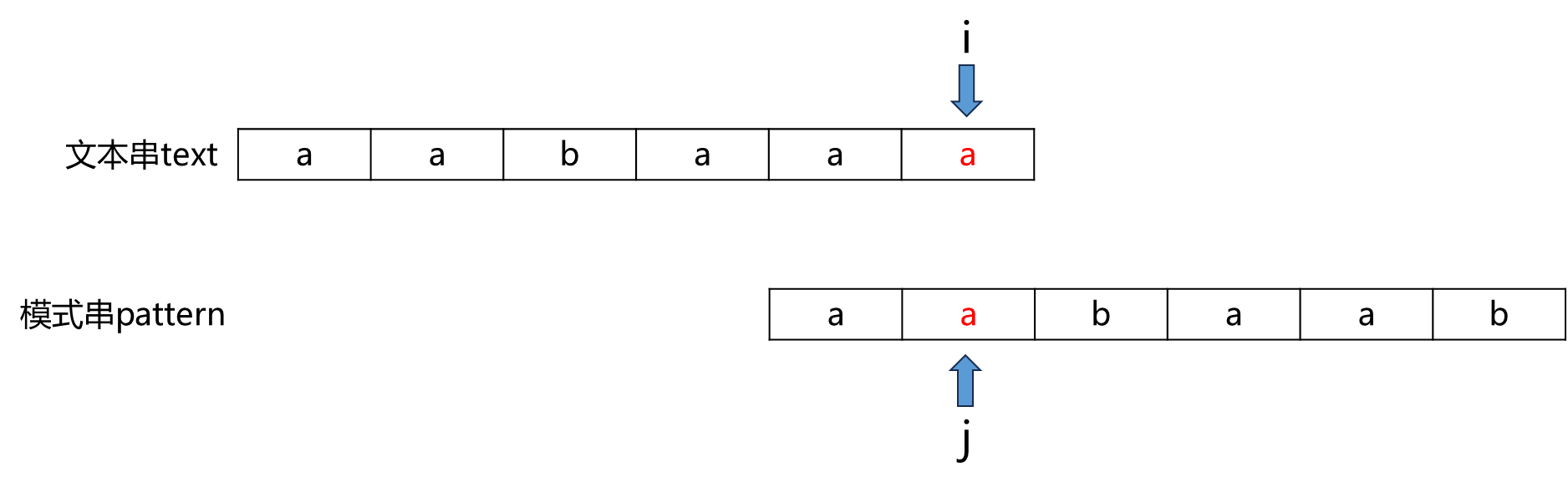
此时text[i] == pattern[j],也就是说pattern[0]~pattern[j]与text[m]~text[i](m为j-1)重合。
问题的转化
回到next数组的构造问题上。当str[j] != str[i]时,我们需要将j回退到某个位置,使str[0]~str[j] 与 str[m]~str[i](m为j-1)重合。这个问题等价于 利用部分匹配信息 和 部分匹配串的最长公共前后缀将j回退,而i不动,比较pattern[0]~pattern[j]与text[m]~text[i](m为j-1)是否重合。因此,我们将str[0]~str[j]作为模式串,将str[m]~str[i](m为j-1)作为文本串,按照上面例子中描述的过程对j回退,即可找到 字符串str[0]~str[i]的 最长公共前后缀
j = next[j-1]的含义
明白这个转化后,我们讨论一下j = next[j-1]的含义。这涉及到后面要讲的 利用部分匹配表实现KMP算法 的过程,不过这并不难,所以可以放在这里讲。举个例子:

当i == 7时,str[i] == str[j](都是字符a),此时的最长公共前后缀是aabaa,然后i、j同时向后移动一位:

当i == 8时,str[i] != str[j](i指向a,而j指向b)。我们需要将j跳转到部分匹配串的前缀的后一位,而由i==7时,str[0]~str[i]的最长公共前后缀为aabaa可知,此时str[0]~str[j] 与 str[m]~str[i](m为j-1)的 部分匹配串 就是aabaa。部分匹配串 aabaa的 最长前后缀 是aa,j需要回退到aabaa前缀aa的下一位,而next[j-1]本质上是aabaa的 最长前后缀 的长度,因此j跳到下标为next[j-1]的位置上,即j = 2,然后再比较str[j]与str[i]。

当j == 2时,str[j] !- str[i](i指向a,而j指向b),我们要再次回退j,首先就是要确定当前str[0]~str[j] 与 str[m]~str[i](m为j-1)的 部分匹配串 是什么。实际上,部分匹配串就是str[0]~str[j-1]。在上一次回退时,我们保证了str[0]~str[j-1] 与 str[m]~str[i-1](m为j-1)是重合的,而回退后str[j] != str[i],因此部分匹配串就是str[0]~str[j-1] 。接下来,我们需要回退到部分匹配串str[0]~str[j-1]的 最长相等前缀 的后一位,与上一次回退相同,这个位置是next[j-1]处,因此j = next[j-1]。这就是j = next[j-1]的意义,关键是明白每次str[j] != str[i]时,部分匹配串就是str[0]~str[j-1]。
我们将j回退到next[j-1]处,即j = 1:

此时str[j] == str[i](都是字符a),我们获得了最长公共前后缀aa,长度为j+1,因此next[i] = j + 1,即next[8] = 1 + 1。我们找到了str[j] != str[i]时,字符串str[0]~str[i]的 最长前后缀。至此,我讲完了构造next数组时的三种情况处理方法 以及这么处理的原理。要明白原理,为什么 比 是什么 更重要
用部分匹配表next实现KMP算法
复习一下在文本串中匹配模式串的思路:
KMP的整个过程是这样的:设模式串pattern上指针为j,文本串text上指针为i。匹配->匹配失败,指针j回退到模式串的某个位置,i不动->匹配->···->匹配->匹配成功 或 i到达文本串的末尾,结束匹配
KMP算法的关键是匹配失败时,即pattern[j] != text[i]时,该如何回退j,进行下一轮匹配。我们利用 当前的部分匹配 和 部分匹配串的最长公共前后缀 决定指针j应该移到哪个位置进行下一次匹配。
有了next数组为我们了部分匹配串的 最长公共前后缀 信息:next[j]存放了 每个子字符串(pattern[0]~pattern[j])的 最长公共前后缀 的长度。next数组存储了部分匹配串的 最长公共前后缀 长度,但是部分匹配信息是什么呢?我们该怎么获得当前的部分匹配串?
其实很简单,pattern[j] != text[i],这次比较失败了,但是上次比较是成功的,即pattern[j-1] == text[i],因此部分匹配串就是pattern[0] ~ pattern[j-1]
我们要将j回退到 部分匹配串的 最长相等前缀 的后一位,这就是下标为next[j-1]的位置处。因此,j = next[j-1],i不动,直至pattern[j] == text[i] 或者 pattern[j] != text[i] && j == 0时才将i移动一位
举例说明:
文本串:abxabcabcaby
模式串:abcaby
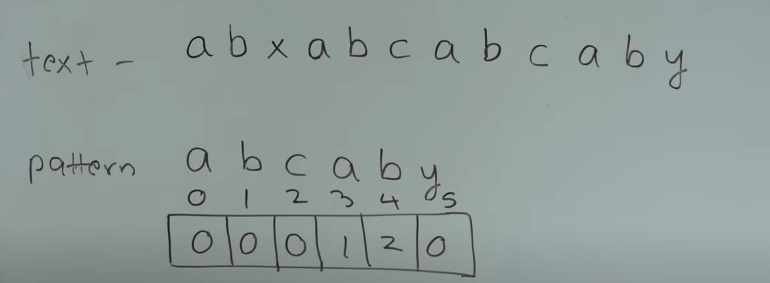
首先构建模式串的next数组,设文本串的指针是i,模式串的指针是j
-
i == 2时,text[i] != pattern[j],需要将j回退
根据上述的分析,
j = next[j-1],则j = 0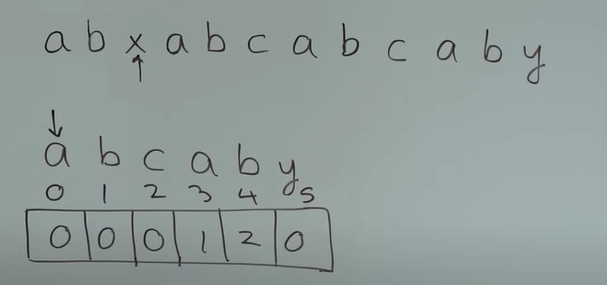
j指向第一个元素a,而此时text[i] != pattern[j](i指向字符x,j指向字符a),而j此时为0,满足pattern[j] != text[i] && j == 0的情况,因此i向后移动一位,j保持不动 -
i == 3~7时,text[i] == pattern[j]始终成立,i、j同时向后移动 -
i == 8时,text[i] != pattern[j](i指向字符c,j指向字符y),需要将j回退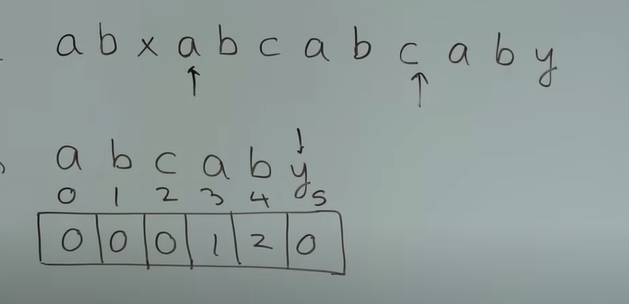
j = next[j-1],则j = 2,j指向第三个字符c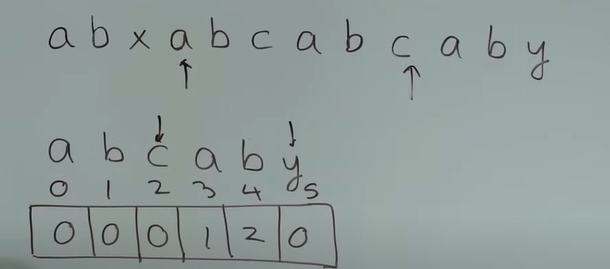
继续比较
text[i]与pattern[j],text[i] == pattern[j],则i、j同时向后移动一位 -
i == 9~11时,text[i] == pattern[j],且j == 5,则文本串text中的一个子串 匹配上了 模式串,算法结束
算法的时间复杂度是O(m+n),m是模式串的长度,n是文本串的长度。构建数组时间复杂度是O(m),使用KMP算法进行查找的时间复杂度是O(n)的,因此整个算法的时间复杂度是O(m+n)的。空间复杂度是O(m),用了一个长度为m的next数组
代码实现
#include <iostream>
using namespace std;
#include <vector>
// 构造next数组
vector<int> Next(string pattern)
{
vector<int> next;
next.push_back(0); //next容器的首位必定为0
for (int i = 1, j = 0; i < pattern.size(); i++)
{
while (j > 0 && pattern[j] != pattern[i])
{
j = next[j - 1];
}
if (pattern[i] == pattern[j])
{
j++;
}
next.push_back(j);
}
return next;
}
int main()
{
string pattern = "ABABC", text = "ABABA ABABCABAA CAADB ABABCAADKDABC";
vector<int>next = Next(pattern);
for (int i = 0, j = 0; i < text.size(); i++)
{
while (j > 0 && text[i] != pattern[j])
{
j = next[j - 1];
}
if (text[i] == pattern[j])
{
j++;
}
if (j == pattern.size())
{
cout << "Found pattern at " << i - j << " position" << endl;
j = next[j - 1];
}
}
return 0;
}
KMP算法到这里就讲完了,关键是理解j是如何回退的,这样就能理解j = next[j-1]的含义了,构建next表实现KMP算法搜索 是一个很巧妙的过程,也需要好好体会
接下来看一些KMP算法的题目
28.实现 strStr()
这道题目就是写一遍KMP算法代码,可以尝试自己写一遍KMP算法的代码,更深刻地理解KMP算法过程
题目链接:28. 找出字符串中第一个匹配项的下标 - 力扣(LeetCode)
思路
思路很简单,就是使用KMP算法解题。题目只需要找到第一个匹配项的下标,因此不需要将text字符串全部遍历一遍
class Solution {
public:
vector<int> Next(string &pattern)
{
int i, j;
vector<int> next;
next.push_back(0);
for(j=0, i=1; i < pattern.size(); ++i)
{
while(j > 0 && pattern[i] != pattern[j])
{
j = next[j-1];
}
if(pattern[i] == pattern[j])
{
j++;
}
next.push_back(j);
}
return next;
}
int strStr(string haystack, string needle) {
// 构建next数组
vector<int> next = Next(needle);
// 使用next数组实现KMP搜索
int i, j;
for(i=0, j=0; i < haystack.size(); ++i)
{
while(j > 0 && haystack[i] != needle[j])
{
j = next[j-1];
}
if(haystack[i] == needle[j])
{
j++;
}
// 只需要找到第一个匹配项的下标,所以不需要将haystack遍历完
if(j == needle.size())
{
return i-j+1;
}
}
return -1;
}
};
459.重复的子字符串
本题算是KMP算法的一个应用,不过 对KMP了解不够熟练的话,理解本题就难很多
题目链接:459. 重复的子字符串 - 力扣(LeetCode)
移动匹配
利用find函数 和 具有重复子串的字符串的性质。
当一个字符串s:abcabc,内部由重复的子串组成,那么这个字符串的结构一定是这样的:
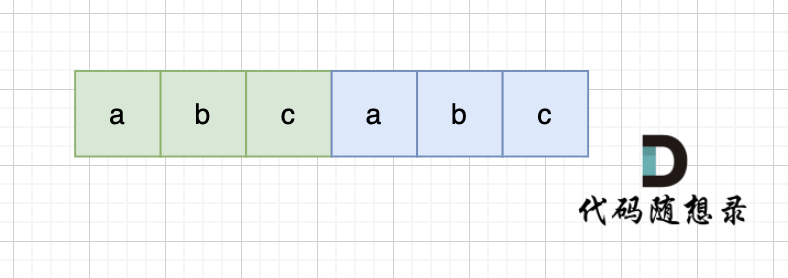
这个字符串能分成两半,每一半是s1:abc,s = s1 + s1
那么s + s就等于(s1 + s1) + (s1 + s1),也就是s1 + (s1 + s1) + s1,前一个s的后半子串 和 后一个s的前半子串 能构成一个s,这就是s的性质,我们使用find函数,在s + s中查找这个子串
注意:要删除s + s的首字符和尾字符,避免在s + s中搜索出原来的s,我们要搜索的是中间拼接出来的s
复习:std::string::find函数
在C++中,std::string类的find函数用于在一个字符串中查找子字符串或字符的第一次出现位置。该函数有多种重载形式,可以查找字符串、字符或字符数组
以下是std::string::find函数的一些常见用法:
-
查找子字符串:
size_t find(const std::string& str, size_t pos = 0) const; -
查找字符:
size_t find(char c, size_t pos = 0) const; -
查找字符数组:
size_t find(const char* s, size_t pos = 0) const;
find函数返回值是size_t类型。如果找到指定的子字符串或字符,函数返回其在字符串中的起始位置索引。如果未找到,则返回特殊值std::string::npos
代码实现
class Solution {
public:
bool repeatedSubstringPattern(string s) {
string t = s + s;
// 对 s + s 掐头去尾
t.erase(t.begin());
t.erase(t.end() - 1);
// 搜索 s + s 中间是否会出现s
if(t.find(s) != std::string::npos)
{
return true;
}
return false;
}
};
这种解法并不够好,find函数的时间复杂度为O(m*n),接下来用KMP算法解决这道题
KMP算法
Q:为什么会使用KMP呢?KMP是在一个串中查找是否出现过另一个串,那么寻找重复子串怎么也涉及到KMP算法了呢?
A:我们细致分析以下这个串abababab:
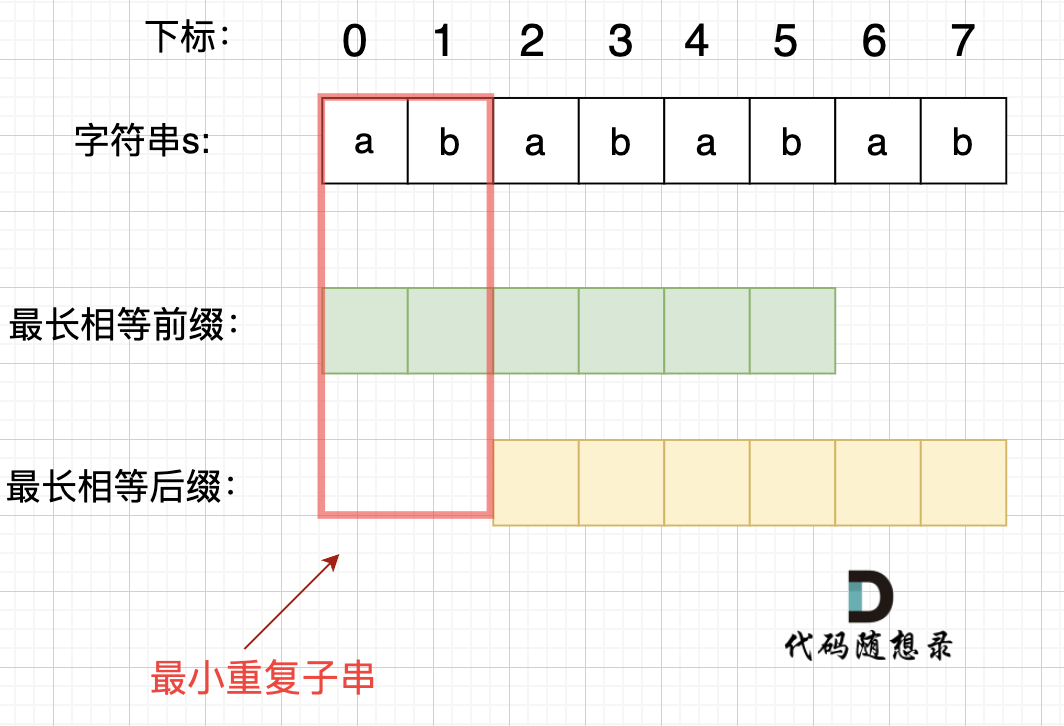
这个串的最小重复子串是ab,恰好是最长相等前后缀不包含的子串。这是巧合吗?并不是,我们分析一下 最长公共前后缀 带来的相等关系:
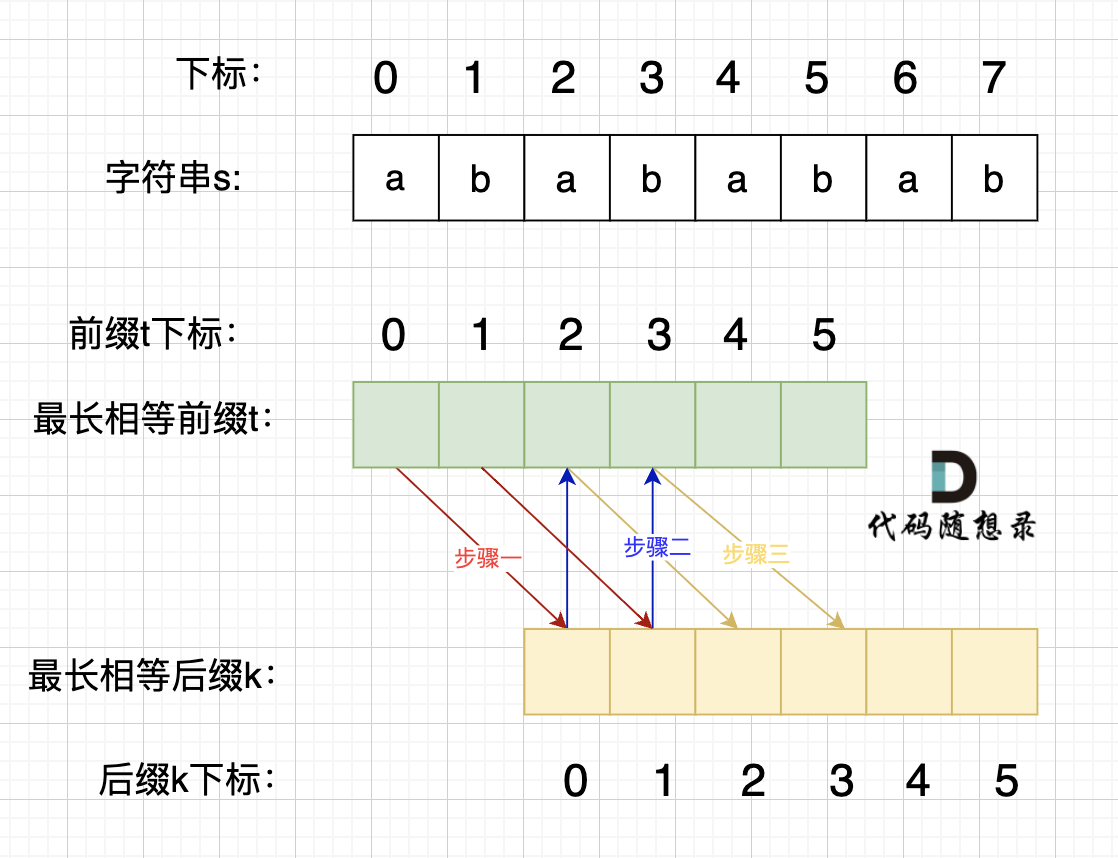
-
步骤一:前缀为
t,后缀为k,这是相等的前缀和后缀,因此t[0]与k[0]相同,t[1]与k[1]相同,而在s中,k[0]就是s[2],k[1]就是s[3],t[0]就是s[0],t[1]就是s[1]。因此,s[0]与s[2]相同,s[1]与s[3]相同,即s[0]s[1]与s[2]s[3]相同 -
步骤二:因为在同一个字符串位置,所以
t[2]与k[0]相同,t[3]与k[1]相同 -
步骤三:因为这是相等的前缀和后缀,
t[2]与k[2]相同,t[3]与k[3]相同,所以,结合步骤二得到的相等关系,k[0]与k[2],k[1]与k[3]相同,对应到s中,s[2]与s[4]相同,s[3]与s[5]相同,即s[2]s[3]与s[4]s[5]相同 -
步骤四:循环往复
所以字符串s中,s[0]s[1]与s[2]s[3]相同,s[2]s[3]与s[4]s[5]相同,s[4]s[5]与s[6]s[7]相同。
正是因为 最长相等前后缀的规则,当一个字符串由重复子串组成的,最长相等前后缀不包含的子串就是最小重复子串。这就涉及到KMP算法中构建next数组的部分,使用next数组,我们能很容易地获得字符串s的最长公共前后缀
判定方法
那么该如何用程序检测 最长相等前后缀不包含的子串 是否为最小重复子串呢?这里用一段数学推导说明:
假设字符串s使用多个重复子串构成,这个子串的长度是x,则s的长度为n*x
字符串s的最长相同前后缀一定不包含s本身,因此,最长相同前后缀长度为m*x,则前后缀不包含的子串 长度为(n-m)x,且n - m = 1(这个子串就是最小重复子串,长度为x)
设len = s.size(),而s的 最长公共前后缀 的长度为next[len-1],前后缀不包含的子串 长度为len-next[len-1]。由上述推导,如果s是由重复子串组成的,则len % (len-next[len-1])为0,s可以由 多个前后缀不包含的子串组成,这说明了这个子串就是最小重复子串
代码实现:
class Solution {
public:
vector<int> Next(string &s)
{
int i, j;
vector<int> next;
next.push_back(0);
for(j=0, i=1; i<s.size(); ++i)
{
while(j > 0 && s[i] != s[j])
{
j = next[j-1];
}
if(s[i] == s[j])
{
j++;
}
next.push_back(j);
}
return next;
}
bool repeatedSubstringPattern(string s) {
int length = s.size();
if(length == 0)
{
return false;
}
// 构建next数组
vector<int> next = Next(s);
// 找到最长公共前后缀的长度
if(next[length - 1] != 0 && length % (length - next[length - 1]) == 0)
{
return true;
}
return false;
}
};
- 时间复杂度: O(n)
- 空间复杂度: O(n)
字符串总结
双指针回顾
双指针法不隶属于某一个特定的数据结构,在数组、字符串、链表中都有使用到,使用双指针法能避免了多层for循环,把时间复杂度降低一个数量级。快慢指针法,左右双指针都是很经典的双指针方法。目前学习过程中,我感觉双指针法很灵活,它没有什么通用的使用场景,两个指针的含义和移动方法在不同场景中也不相同,所以碰到一道使用双指针的题目,还是需要记下来它的思路和使用场景,为后续题目提供参照和启发
Carl写的很好,具体的题目可以在我的博客中找到解答
总结
这是对今天题目的总结。今天的题目都很有挑战性,第一题 151.反转字符串里的单词 使用双指针法 和 整体反转+局部反转的方法,难点在于如何移除多余的空格。day1的一道题目 27.移除数组中的元素 提供了启发:我们可以使用双指针法移除多余的空格,但是要注意,单词之间要保留一个空格,而不是全部删除
第二题卡码网:55.右旋转字符串也涉及到了反转字符串,解题方法是 整体反转+局部反转,比较简单
第三、四题使用到KMP算法的思想。KMP是一个很精致且巧妙的算法,核心思想是利用已有的部分匹配信息 和 部分匹配串的最长前后缀,进行下一轮匹配,从而避免暴力搜索中的重复匹配。理解KMP算法,关键是理解j = next[j-1]的含义,这是很多文章没有讲清楚的部分,需要好好体会
不知不觉竟然写了两万多字了😜字符串专题就结束了,接下来准备下一个专题:栈与队列















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









