






Node.JS实现网络爬虫
文章目录
目标
1、选取3-5个代表性的新闻网站(比如新浪新闻、网易新闻等,或者某个垂直领域权威性的网站比如经济领域的雪球财经、东方财富等,或者体育领域的腾讯体育、虎扑体育等等)建立爬虫,针对不同网站的新闻页面进行分析,爬取出编码、标题、作者、时间、关键词、摘要、内容、来源等结构化信息,存储在数据库中。
2、建立网站提供对爬取内容的分项全文搜索,给出所查关键词的时间热度分析。
一、爬虫的任务是什么?
1.读取种子页面
2.分析出种子页面里的所有新闻链接
3.爬取所有新闻链接的内容
4.分析新闻页面内容,解析出结构化数据
5.将结构化数据保存到本地文件
二、操作步骤
0.前言
var myRequest = require('request')
var myCheerio = require('cheerio')
var myURL = 'https://news.sina.com.cn/'
function request(url, callback) {//request module fetching url
var options = {
url: url, encoding: null, headers: null
}
myRequest(options, callback)
}
request(myURL, function (err, res, body) {
var html = body;
var $ = myCheerio.load(html, { decodeEntities: false });
console.log($.html());
//console.log("title: " + $('title').text());
//console.log("description: " + $('meta[name="description"]').eq(0).attr("content"));
})
运行这段基础代码的时候,会发现爬出了所贴网址的全部源代码

这里我爬的是新浪新闻,可以看到很多最近的电影消息~我想这大概就是爬虫的最最基础版本了,获取网页信息。
1.crawler1.js
(这里以中国新闻网为例 http://www.chinanews.com/)
**代码示例:** ·引入必须的模块, ·定义要访问的网站:
var fs = require('fs');
var myRequest = require('request')
var myCheerio = require('cheerio')
var myIconv = require('iconv-lite')
require('date-utils');
var source_name = "中国新闻网";
var myEncoding = "utf-8";
var seedURL = 'http://www.chinanews.com/';
·定义新闻页面里具体的元素的读取方式,
·定义哪些url可以作为新闻页面:
var seedURL_format = "$('a')";
var keywords_format = " $('meta[name=\"keywords\"]').eq(0).attr(\"content\")";
var title_format = "$('title').text()";
var date_format = "$('#pubtime_baidu').text()";
var author_format = "$('#editor_baidu').text()";
var content_format = "$('.left_zw').text()";
var desc_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
var source_format = "$('#source_baidu').text()";
var url_reg = /\/(\d{4})\/(\d{2})-(\d{2})\/(\d{7}).shtml/;
var regExp = /((\d{4}|\d{2})(\-|\/|\.)\d{1,2}\3\d{1,2})|(\d{4}年\d{1,2}月\d{1,2}日)/
·创造一个模仿浏览器的request:
//防止网站屏蔽我们的爬虫
var headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.65 Safari/537.36'
}
//request模块异步fetch url
function request(url, callback) {
var options = {
url: url,
encoding: null,
//proxy: 'http://x.x.x.x:8080',
headers: headers,
timeout: 10000 //
}
myRequest(options, callback)
}
·读取种子页面,
·解析出种子页面里所有的< a href >链接:
request(seedURL, function(err, res, body) { //读取种子页面
// try {
//用iconv转换编码
var html = myIconv.decode(body, myEncoding);
//console.log(html);
//准备用cheerio解析html
var $ = myCheerio.load(html, { decodeEntities: true });
// } catch (e) { console.log('读种子页面并转码出错:' + e) };
var seedurl_news;
try {
seedurl_news = eval(seedURL_format);
//console.log(seedurl_news);
} catch (e) { console.log('url列表所处的html块识别出错:' + e) };
·遍历种子页面里所有的< a href >链接
·规整化所有链接,如果符合新闻URL的正则表达式就爬取:
seedurl_news.each(function(i, e) { //遍历种子页面里所有的a链接
var myURL = "";
try {
//得到具体新闻url
var href = "";
href = $(e).attr("href");
if (typeof(href) == "undefined") { // 有些网页地址undefined
return true;
}
if (href.toLowerCase().indexOf('http://') >= 0 || href.toLowerCase().indexOf('https://') >= 0) myURL = href; //http://开头的或者https://开头
else if (href.startsWith('//')) myURL = 'http:' + href; 开头的
else myURL = seedURL.substr(0, seedURL.lastIndexOf('/') + 1) + href; //其他
} catch (e) { console.log('识别种子页面中的新闻链接出错:' + e) }
if (!url_reg.test(myURL)) return; //检验是否符合新闻url的正则表达式
//console.log(myURL);
newsGet(myURL); //读取新闻页面
·读取具体的新闻页面,构造一个空的fetch对象用于存储数据:
function newsGet(myURL) { //读取新闻页面
request(myURL, function(err, res, body) { //读取新闻页面
//try {
var html_news = myIconv.decode(body, myEncoding); //用iconv转换编码
//console.log(html_news);
//准备用cheerio解析html_news
var $ = myCheerio.load(html_news, { decodeEntities: true });
myhtml = html_news;
//} catch (e) { console.log('读新闻页面并转码出错:' + e);};
console.log("转码读取成功:" + myURL);
//动态执行format字符串,构建json对象准备写入文件或数据库
var fetch = {};
fetch.title = "";
fetch.content = "";
fetch.publish_date = (new Date()).toFormat("YYYY-MM-DD");
//fetch.html = myhtml;
fetch.url = myURL;
fetch.source_name = source_name;
fetch.source_encoding = myEncoding; //编码
fetch.crawltime = new Date();
·读取新闻页面中的元素并保存到fetch对象里:
if (keywords_format == "") fetch.keywords = source_name; // eval(keywords_format); //没有关键词就用sourcename
else fetch.keywords = eval(keywords_format);
if (title_format == "") fetch.title = ""
else fetch.title = eval(title_format); //标题
if (date_format != "") fetch.publish_date = eval(date_format); //刊登日期
console.log('date: ' + fetch.publish_date);
console.log(myURL);
fetch.publish_date = regExp.exec(fetch.publish_date)[0];
fetch.publish_date = fetch.publish_date.replace('年', '-')
fetch.publish_date = fetch.publish_date.replace('月', '-')
fetch.publish_date = fetch.publish_date.replace('日', '')
fetch.publish_date = new Date(fetch.publish_date).toFormat("YYYY-MM-DD");
if (author_format == "") fetch.author = source_name; //eval(author_format); //作者
else fetch.author = eval(author_format);
if (content_format == "") fetch.content = "";
else fetch.content = eval(content_format).replace("\r\n" + fetch.author, ""); //内容,是否要去掉作者信息自行决定
·将fetch对象保存在文件中:
if (source_format == "") fetch.source = fetch.source_name;
else fetch.source = eval(source_format).replace("\r\n", ""); //来源
if (desc_format == "") fetch.desc = fetch.title;
else fetch.desc = eval(desc_format).replace("\r\n", ""); //摘要
var filename = source_name + "_" + (new Date()).toFormat("YYYY-MM-DD") +
"_" + myURL.substr(myURL.lastIndexOf('/') + 1) + ".json";
存储json
fs.writeFileSync(filename, JSON.stringify(fetch));
});
运行结果:
用vscode运行 : node crawler1.js
结果:创建出多个新闻文件。


2.爬虫的任务扩展
2.1.数据库存储爬取的数据;
2.2.爬取新闻页面之前先查询数据库,是否该url已经爬取过了;
2.3.设置爬虫定时工作。
2.1 运用数据库(MySQL)
·进入mysql后可创建一个数据库crawl,然后再创建一个表fetches:
-create database crawl;
-use crawl;
-将下面fetches.sql拷贝到命令行里;
-show tables;
CREATE TABLE `fetches` (
`id_fetches` int(11) NOT NULL AUTO_INCREMENT,
`url` varchar(200) DEFAULT NULL,
`source_name` varchar(200) DEFAULT NULL,
`source_encoding` varchar(45) DEFAULT NULL,
`title` varchar(200) DEFAULT NULL,
`keywords` varchar(200) DEFAULT NULL,
`author` varchar(200) DEFAULT NULL,
`publish_date` date DEFAULT NULL,
`crawltime` datetime DEFAULT NULL,
`content` longtext,
`createtime` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id_fetches`),
UNIQUE KEY `id_fetches_UNIQUE` (`id_fetches`),
UNIQUE KEY `url_UNIQUE` (`url`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
show tables之后得到:

2.2 Node 调用MySQL
·npm install mysql
·创建 mysql.js
·在爬虫中引用
var mysql = require("mysql");
var pool = mysql.createPool({
host: '127.0.0.1',
user: 'root',
password: 'root',
database: 'crawl'
});
var query = function(sql, sqlparam, callback) {
pool.getConnection(function(err, conn) {
if (err) {
callback(err, null, null);
} else {
conn.query(sql, sqlparam, function(qerr, vals, fields) {
conn.release(); //释放连接
callback(qerr, vals, fields); //事件驱动回调
});
}
});
};
var query_noparam = function(sql, callback) {
pool.getConnection(function(err, conn) {
if (err) {
callback(err, null, null);
} else {
conn.query(sql, function(qerr, vals, fields) {
conn.release(); //释放连接
callback(qerr, vals, fields); //事件驱动回调
});
}
});
};
exports.query = query;
exports.query_noparam = query_noparam;
2.3 修改爬虫代码 crawler2.js
在crawler1.js的基础上修改:
var mysql = require('./mysql.js');
newsGet函数中修改:
// var filename = source_name + "_" + (new Date()).toFormat("YYYY-MM-DD") +
// "_" + myURL.substr(myURL.lastIndexOf('/') + 1) + ".json";
// 存储json
// fs.writeFileSync(filename, JSON.stringify(fetch));
var fetchAddSql = 'INSERT INTO fetches(url,source_name,source_encoding,title,' +
'keywords,author,publish_date,crawltime,content) VALUES(?,?,?,?,?,?,?,?,?)';
var fetchAddSql_Params = [fetch.url, fetch.source_name, fetch.source_encoding,
fetch.title, fetch.keywords, fetch.author, fetch.publish_date,
fetch.crawltime.toFormat("YYYY-MM-DD HH24:MI:SS"), fetch.content
];
//执行sql,数据库中fetch表里的url属性是unique的,不会把重复的url内容写入数据库
mysql.query(fetchAddSql, fetchAddSql_Params, function(qerr, vals, fields) {
if (qerr) {
console.log(qerr);
}
}); //mysql写入
运行结果:

2.4 爬虫定时工作 crawler2.1.js
·引入第三方包node-schedule
var schedule = require('node-schedule');
//!定时执行
var rule = new schedule.RecurrenceRule();
var times = [0, 12]; //每天2次自动执行
var times2 = 5; //定义在第几分钟执行
rule.hour = times;
rule.minute = times2;
//定时执行httpGet()函数
schedule.scheduleJob(rule, function() {
seedget();
});
3.爬虫的功能扩展
3.1.用mysql查询已爬取的数据;
3.2.用网页发送请求到后端查询;
3.3.用express构建网站访问mysql;
3.4.用表格显示查询结果;
3.5.可以尝试的其他扩展。
3.1 用mysql查询已爬取的数据
var mysql = require('./mysql.js');
var title = '新冠';
var select_Sql = "select title,author,publish_date from fetches where title like '%" + title + "%'";
mysql.query(select_Sql, function(qerr, vals, fields) {
console.log(vals);
});
运行结果:

这里也可以把“新冠”改为“专家”,但前提是要确认自己的数据库里存在以此开头的文件:

3.2 用网页发送请求到后端查询
·首先创建一个网页端(前端)【7.02.html】
<!DOCTYPE html>
<html>
<body>
<form action="http://127.0.0.1:8080/process_get" method="GET">
<br> 标题:<input type="text" name="title">
<input type="submit" value="Submit">
</form>
<script>
</script>
</body>
</html>

·再创建一个【7.02.js】作为后端
var http = require('http');
var fs = require('fs');
var url = require('url');
var mysql = require('./mysql.js');
http.createServer(function(request, response) {
var pathname = url.parse(request.url).pathname;
var params = url.parse(request.url, true).query;
fs.readFile(pathname.substr(1), function(err, data) {
response.writeHead(200, { 'Content-Type': 'text/html; charset=utf-8' });
if ((params.title === undefined) && (data !== undefined))
response.write(data.toString());
else {
response.write(JSON.stringify(params));
var select_Sql = "select title,author,publish_date from fetches where title like '%" +
params.title + "%'";
mysql.query(select_Sql, function(qerr, vals, fields) {
console.log(vals);
});
}
response.end();
});
}).listen(8080);
console.log('Server running at http://127.0.0.1:8080/');
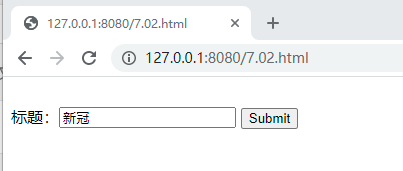
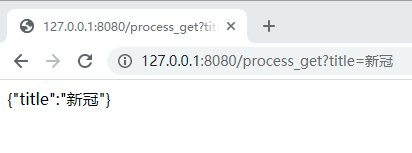
·Node运行 7.02.js 后访问 http://127.0.0.1:8080/7.02.html
·输入任意查询词点击submit
运行结果:

3.3 用express构建网站访问mysql
·同样先创建一个7.03.html作为前端
<!DOCTYPE html>
<html>
<body>
<form action="http://127.0.0.1:8080/process_get" method="GET">
<br> 标题:<input type="text" name="title">
<input type="submit" value="Submit">
</form>
<script>
</script>
</body>
</html>

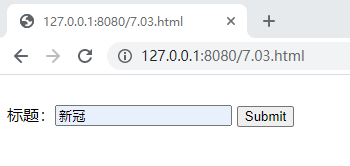
·Node运行 7.03.js 后访问 http://127.0.0.1:8080/7.03.html
·输入任意查询词点击submit
【7.03.js】
var express = require('express');
var mysql = require('./mysql.js')
var app = express();
//app.use(express.static('public'));
app.get('/7.03.html', function(req, res) {
res.sendFile(__dirname + "/" + "7.03.html");
})
app.get('/7.04.html', function(req, res) {
res.sendFile(__dirname + "/" + "7.04.html");
})
app.get('/process_get', function(req, res) {
res.writeHead(200, { 'Content-Type': 'text/html;charset=utf-8' }); //设置res编码为utf-8
//sql字符串和参数
var fetchSql = "select url,source_name,title,author,publish_date from fetches where title like '%" +
req.query.title + "%'";
mysql.query(fetchSql, function(err, result, fields) {
console.log(result);
res.end(JSON.stringify(result));
});
})
var server = app.listen(8080, function() {
console.log("访问地址为 http://127.0.0.1:8080/7.03.html")
})
运行结果:


3.4 用表格显示查询结果
·我们用express脚手架来创建一个网站框架
·express -e search_site
·然后生成出一个search_site的文件夹
·由于我们需要使用mysql,因此将mysql.js拷贝进这个文件夹
【mysql.js】
var mysql = require("mysql");
var pool = mysql.createPool({
host: '127.0.0.1',
user: 'root',
password: 'root',
database: 'crawl'
});
var query = function(sql, sqlparam, callback) {
pool.getConnection(function(err, conn) {
if (err) {
callback(err, null, null);
} else {
conn.query(sql, sqlparam, function(qerr, vals, fields) {
conn.release(); //释放连接
callback(qerr, vals, fields); //事件驱动回调
});
}
});
};
var query_noparam = function(sql, callback) {
pool.getConnection(function(err, conn) {
if (err) {
callback(err, null, null);
} else {
conn.query(sql, function(qerr, vals, fields) {
conn.release(); //释放连接
callback(qerr, vals, fields); //事件驱动回调
});
}
});
};
exports.query = query;
exports.query_noparam = query_noparam;
运行结果:


·mysql.js拷贝后还需要在search_site文件夹内cmd运行:
·npm install mysql -save
(-save表示将mysql包安装到该项目中,并且将依赖项保存进package.json里
·在search_site文件夹内cmd运行npm install
(将package.json中列举的依赖项全部安装,完成网站搭建)


·用vscode打开文件夹search_site
·打开search_site/routes/index.js准备修改:
var express = require('express');
var router = express.Router();
var mysql = require('../mysql.js');
/* GET home page. */
router.get('/', function(req, res, next) {
res.render('index', { title: 'Express' });
});
router.get('/process_get', function(request, response) {
//sql字符串和参数
var fetchSql = "select url,source_name,title,author,publish_date " +
"from fetches where title like '%" + request.query.title + "%'";
mysql.query(fetchSql, function(err, result, fields) {
response.writeHead(200, {
"Content-Type": "application/json"
});
response.write(JSON.stringify(result));
response.end();
});
});
module.exports = router;
·在search_site/public/下创建一个search.html
<!DOCTYPE html>
<html>
<header>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.js"></script>
</header>
<body>
<form>
<br> 标题:<input type="text" name="title_text">
<input class="form-submit" type="button" value="查询">
</form>
<div class="cardLayout" style="margin: 10px 0px">
<table width="100%" id="record2"></table>
</div>
<script>
$(document).ready(function() {
$("input:button").click(function() {
$.get('/process_get?title=' + $("input:text").val(), function(data) {
$("#record2").empty();
$("#record2").append('<tr class="cardLayout"><td>url</td><td>source_name</td>' +
'<td>title</td><td>author</td><td>publish_date</td></tr>');
for (let list of data) {
let table = '<tr class="cardLayout"><td>';
Object.values(list).forEach(element => {
table += (element + '</td><td>');
});
$("#record2").append(table + '</td></tr>');
}
});
});
});
</script>
</body>
</html>
·在search_site文件夹下cmd运行:node bin/www
·用chrome浏览器打开 http://127.0.0.1:3000/search.html


3.5 可以尝试的其他扩展
1.对查询结果进行分页显示;
2.对查询结果按某个字段进行排序;
3.对多个查询结果进行复合查询;
4.其他功能和性能的提升。
三、重点内容
1、基础知识
(缓慢学习中==)
1.在Node.js中,fs全称为filesystem,指的是fs模块,提供本地文件的读写能力;
2.require:全局性加载模块的方法;
request:用于http请求;
cheerio:用于提取request返回的html中需要的信息;
icnov-lite:实现编码转换(icnov.decode);
date-utils:包含与时间相关的处理;
3.“创造一个模仿浏览器的request” 中防止网页屏蔽爬虫的方式:将自己伪装为浏览网站的用户,使用user-agent,代表用什么【设备】来请求访问;
4.拿到网页的html代码之后,用iconv转换编码,console.log(html)检验,之后就开始用cheerio解析html;
5.entities:网页实体(组成部分);
6.try{}catch()的作用是处理报错:try住、执行、出错的话就被catch,打印错误信息出来,+e(exception)代表出现例外(这里是字符串相加代表直接相连);
7.each函数(i,e):遍历,i是下标(index),e是元素(element);
8.正则表达式(标准格式):以http://或者https://开头的网址;
9.eval函数:接收一个参数s,如果s不是字符串,则直接返回s。否则执行s语句。如果s语句执行结果是一个值,则返回此值,否则返回undefined;
10.构造空的fetch对象用于存储数据:除了title和content,其他都用自己的url信息填写;
11.fetches.sql中,定义了id_fetches(编号)、url(地址)等等,其中编号是int类型,url是varchar字符型;
12.PRIMARY KEY 主键,这里是通过id_fetches来判断爬没爬过相同的内容;
13.UNIQUE KEY 联合键,用来查询的,这里是查询id_fetches和url;
14.var query = function(sql, sqlparam, callback){};的作用是查询,sql代表查询语句,sqlparam代表查询参数,callback代表查询完的通知结果);
15.conn.query(sql, sqlparam,…)的作用是连接(connection)、传入,记得release;
16.除了14.中提到的带参查询语句,还有一种无参查询:var query = function(sql, callback){};
17.之后在2.3中修改,将爬取的内容从存入文件的形式改为插入数据库,newsGet函数中修改,fetch一条数据包括fetches(url,source_name,…),然后用fetchesAddSql_Params={fetch.url,fetch_source_name,…)将与上面一一对应的参数传入;
18.定时执行,定义rule,每天在times规定的0点和12点、times2规定的5分钟后,执行一次爬虫查询,并且用seedget()自己定义的来定时执行;
19.var select_Sql = “select title,author,publish_date from fetches where title like '%” + title + “%’” ,固定的格式,把存入mysql的信息再次拿出来;
20.在mysql中运行 select url, title, author from fetches limit 10; 就可以打印出url、title、author三个内容,如果还想查看其它的就继续在from前面增加列名:

2、课外拓展
(我们继续用上述代码爬取的信息,这里注意我们的mysql数据库里的表最开始的命名为fetches)
(1.对查询结果进行分页显示;
查询第1条到第10条的数据:select * from table limit 0,10;
查询第一页的数据:select * from table limit (1-1)*10,10;
所以分页sql的格式是:select * from table limit (start-1)*limit,limit;
(其中start是页码,limit是每页显示的条数。)
(2.对查询结果按某个字段进行排序;
mysql> select url,title,author,publish_date from fetches order by author ;


(可以看到查询结果是按照author的字典序排列的。)
(3.正则表达式的学习;
当我将中国新闻网换成新浪新闻的时候,发现mysql提取出来的还是原来的爬取信息,询问之后才得知是因为不同网站对应的正则表达式不同,因此我们不仅要更改上方代码里的网址信息,还要更改正则表达式那行代码。
推荐学习工具:https://regex101.com/
(1)限定符:
/used? 代表d可有可无(因此可以匹配use、used)
/ab*c 代表b可以出现0次或者多次(因此可以匹配ac,abc,abbbbbc)
/ab+c 代表b出现多次
/ab{2,6}c(b出现2至6次); ab{2,}c(b出现2至多次) ; ab{6}c(b出现6次)。
(2)或运算符:
/a (cat|dog) (先匹配a+空格,然后匹配cat或者dog)
/[a-zA-Z0-9]+ (匹配所有的大小写字母和数字)
/[^0-9]+ (匹配所有的非数字字符(包括换行符))
(3)元字符:
\d 数字字符 \D 非数字字符
\w 单词字符 \W非单词字符
\s 空白符 \S非空白字符
/. 任意字符但不包括换行符
^a (匹配行首的a)
a$ (匹配行尾的a)
(4)贪婪与懒惰匹配:
/<.+>
/<.+?>
(4.存储多个查询结果;
(1)尝试爬取其他网站,更改crawler2.js代码

【这些都是要改的!】
比如这里爬取“看看新闻”这个网站,就需要更改原来的代码的如下区域:
(因为源代码是class,所以要把#改为.)


爬取成功!
(2)那么如何把这些爬取信息存入数据库呢?
这里我一共建了五个表格:

爬取多个新闻网站
分别用fetches存储“中国新闻网”的爬取内容,
用round存取“看看新闻”的爬取内容,
用table存取”新浪新闻“的爬取内容,
用wangyi存取“网易新闻”的爬取内容,
用“ribao”存取“中国日报网”的爬取内容。
(注意这里table这个表名其实取的并不好,因为table是mysql自己包含的单词,会产生操作错误:
因此使用的时候要在两边加 ` !!)
更改相应fetch.sql的表格名称,用crawler2.js分别爬取网址。
看看新闻

新浪新闻
网易新闻

中国日报网

在尝试爬取中国日报网的时候,出现了问题,询问老师之后得知是因为这个网站不让我爬它(哎一古),于是只好换成爬取新华网了。
因此顺便把表名改一下吧。(ribao–>xinhua)

但是!!!在爬取新华网时我又遇到了新的问题!!!

这里的错因似乎是content_format没取出内容来,但最严重的问题是…

我这里显示了转码读取成功,按理来说应该可以在数据库查了呀。
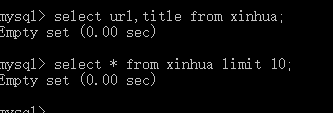
好家伙,数据库是空的。
无奈之下又去麻烦了老师,老师说是因为要加个判空的操作!

这里加上之后再次运行代码,就爬取成功了!
新华网


(这里我还以为没爬出来title、或者把url和title爬到一起去了,结果其实都分别爬出来了的(可以看见中间有杠杠隔开),虽然不知道为啥显示的时候塞在了一起orz)
那么这个时候就可以进行相应的前端查询操作了,和上面用fetches的步骤大同小异。

成功!★,°:.☆( ̄▽ ̄)/:.°★ 。
(5.热度词分析;
老师的要求是把搜索内容的时间热度分析体现在网页上,但我实在能力有限,只能先学习如何在mysql上把它体现出来。(就是这样我还懵了好一阵子不知道从何做起)询问朋友之后说是要用SQL模糊查询以天为单位的数据中包含关键词出现的次数。
学习了一番之后,尝试:

嗯嗯,这里倒是把关键词的出现数量排名表现出来了,但是怎么按照日期分类统计呢…
又好一顿尝试,这里展示一下我的惨痛 尝试过程:

!!!终于成功了(流下心酸的泪水 ):
(最最最后是我加工处理了一下的爬虫网页~)

总结
至此这次爬虫大作业就完成啦,总结一下就是了解html、js语言,学会去运用它们爬取网站信息,学会了用数据库存取和读取相应的关键词,学会了同时爬多个网址等等…
虽然大部分代码还是在老师给的基础上修改的,但遇到了很多问题的同时也收获了很多帮助(感谢亲爱的同学和老师不厌其烦的解答!!!),再一步步到最后的结果,真的受益匪浅。















 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









