







好了,我考完了,我花了40min走出考场,不是因为都会,而是因为不会的是一点不会哇
更正一下,gpt那里考的相当变态,考了few shot learning,填空题就更变态了(谁去给老师说让他把难度调高点的,绝望)
我以为LAS占20分,结果tactron24分,永远猜不透老师的心思.jpg
期末卷子大概构成:分数不太准确
填空18分:考了一堆细节,成对语音包括什么?我怎么知道。两种不同的语言模型训练方式,懵逼
选择题20分:差不多正常,不过也有很难的,问gpt是自回归还是自监督,听都没听过.jpg
名词解释10分:token以及他的走狗们;seq2seq
大题 24分:gpt的few shot learning;还有两个大题,不记得了
综合题24分:RNN-based LM 要会画结构图
目录
复习步骤
1.看老师ppt(大学老师的ppt就类似于考纲)
2.找到一个非常好的学长的笔记,希望我以后也能写出这么好的笔记,学长的笔记没有Introduction和chatgpt,我在后面博客里会补上
(31条消息) 【NLP】自然语言处理学习笔记(一)语音识别_token 自然语言处理_zstar-_的博客-CSDN博客(31条消息) 【NLP】自然语言处理学习笔记(三)语音合成_nlp 语音合成_zstar-_的博客-CSDN博客(31条消息) 【NLP】自然语言处理学习笔记(二)语音转换_nlp语音转文字_zstar-_的博客-CSDN博客
3.根据我看过笔记和ppt形成的理解去自己制作思维导图,期间不要翻任何参考资料~
4.熟读成诵思维导图,思维导图是我自己思维浓缩的精华以及我记忆的提示词
补充笔记u1 introduction
一、什么是自然语言处理?自然语言处理对人类有什么好处?
自然语言处理是指让机器能够理解、处理和生成人类语言的技术。它涵盖了语音识别、文本分析、自动翻译、情感分析、文本生成等多个子领域。
作为一门跨学科的研究领域,自然语言处理结合了计算机科学、语言学、心理学等多个学科。它的目标是让计算机能够像人类一样理解和使用语言,实现人机交互的最终目的。
二、自然语言处理的应用领域
目前,自然语言处理已经在很多领域得到了广泛应用。下面介绍几个比较典型的应用领域。
1. 语音识别
语音识别是自然语言处理中的一个重要分支,它的目的是将人类语音转换成计算机可理解的文本。语音识别技术已经得到了广泛应用,例如语音助手、智能家居等领域。
现在的语音识别技术已经非常成熟,准确率也得到了大幅提升。例如,苹果的Siri、谷歌的Google Assistant等语音助手已经成为人们生活中不可或缺的一部分。
2. 文本分类
文本分类是指将文本按照不同的类别进行分类。例如,将一篇新闻按照政治、经济、娱乐等类别进行分类。文本分类技术在新闻聚合、情报分析、舆情监测等领域得到了广泛应用。
文本分类技术通常采用机器学习算法,例如朴素贝叶斯、支持向量机等。这些算法可以对文本进行自动分类,并不断优化分类效果。
3. 情感分析
情感分析是指对文本进行情感判断,判断文本是积极的、消极的还是中性的。情感分析技术在社交媒体监测、品牌管理等领域得到了广泛应用。
情感分析技术通常采用机器学习算法,例如支持向量机、神经网络等。这些算法可以对文本进行情感判断,并不断优化情感判断效果。
4. 文本生成
文本生成是指让计算机能够自动生成符合语法和语义规则的文本。文本生成技术在智能客服、智能写作等领域得到了广泛应用。
文本生成技术通常采用基于神经网络的生成模型,例如循环神经网络、变分自编码器等。这些模型可以学习文本的生成规律,并自动生成符合要求的文本。
三、自然语言处理面临的挑战
虽然自然语言处理技术已经得到了广泛应用,但它仍然面临一些挑战。下面介绍几个比较典型的挑战。
1. 语言
语言的多样性是自然语言处理面临的一个重要挑战。不同的语言有着不同的语法、词汇、表达方式等,因此需要针对不同语言的特点进行处理。
例如,中文和英文的语法结构差别很大,中文的词语之间没有空格,而英文的词语之间通常用空格隔开。因此,对于中文和英文的处理需要采用不同的方法和技术。
2. 多义词和歧义
自然语言中存在大量的多义词和歧义,这给自然语言处理带来了很大的挑战。同一个词在不同的语境下可能有不同的含义,因此需要通过上下文来确定词语的具体含义。
例如,单词“bank”既可以表示银行,也可以表示河岸。在一个句子中,如果没有上下文信息,计算机很难确定“bank”的具体含义。
3. 数据量和质量
自然语言处理技术需要大量的数据作为训练和测试集,同时需要保证数据的质量。数据量不足可能导致模型过拟合或欠拟合,数据质量不高可能导致模型效果不佳。
同时,自然语言处理技术需要处理的数据种类繁多,包括文本、音频、视频等。这些数据的形式和特点不同,需要针对不同数据种类采用不同的处理方法和技术。
补充笔记 u6 chatgpt
chatgpt的组成
1.transformer
基于自注意力机制的神经网络,能有效处理长文本
2.pre-trained
经过海量数据预训练来的
3.RLHF
基于人类反馈的强化学习
4.prompt
微调技术(通过提示词不断为gpt补全信息)
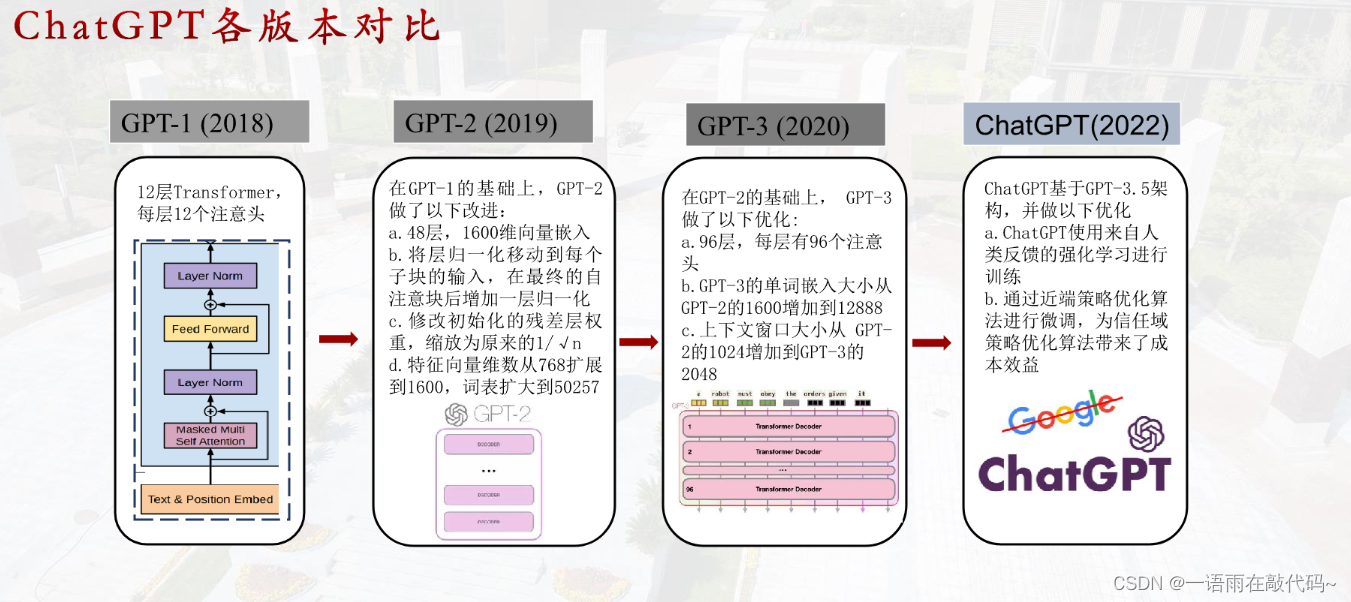
chatgpt的不同版本区别
GPT1:正常的语言模型transformer的解码器部分
GPT2:zero shot,输入改成了 Input+task,提示词出现
GPT3:few shot,参数量更大
Chatgpt:基于instructgpt,更侧重于学习对话。
chatgpt论述chatgpt(我也是太闲了)
GPT是由OpenAI开发的一系列自然语言处理模型,目前已经发布了多个版本。以下是几个版本之间的主要区别:
1. GPT-1:发布于2018年,包含1.5亿个参数,用于生成自然语言文本。它可以完成文本生成、文本分类、文本摘要等任务。
2. GPT-2:发布于2019年,包含1.5亿到1.5亿个参数,是GPT-1的改进版。它可以生成更长、更连贯、更自然的文本,但由于其强大的生成能力,OpenAI决定不公开发布其完整模型,只提供了一些小型模型供研究使用。
3. GPT-3:发布于2020年,包含1.75万亿个参数,是目前最大的自然语言处理模型。它可以完成更多的任务,如问答、翻译、文本摘要、语言推理等。GPT-3的生成能力非常强大,可以生成高质量的文章、诗歌、对话等。
总的来说,GPT系列模型的主要区别在于参数数量和生成能力的提升。随着模型的不断升级,GPT系列模型的性能和应用范围也在不断扩展。
chatgpt和其他模型的比较
Chatgpt:连贯
Bert:在自然语言处理的任务上很专业,关注上下文的理解,但是没有很好的生成效果
Transformer-XL:长文本有优势(相对位置编码)
T5:端到端的文本生成
ELMO:双向LSTM,对上下文的信息把握更好
transformer(重点)
Transformer是一种基于自注意力机制的神经网络架构,主要由以下几个部分组成:
1. 输入嵌入层(Input Embedding Layer):将输入的离散化序列转换为连续的向量表示,通常使用词嵌入(Word Embedding)技术。
2. 编码器(Encoder):由多个编码器层组成,每个编码器层都包含一个多头自注意力机制(Multi-Head Self-Attention)和一个前馈神经网络(Feed-Forward Neural Network)。
3. 解码器(Decoder):由多个解码器层组成,每个解码器层都包含一个多头自注意力机制、一个多头注意力机制(Multi-Head Attention)和一个前馈神经网络。
4. 位置编码(Positional Encoding):为了保留序列中的位置信息,Transformer在输入嵌入层和编码器/解码器中都使用了位置编码。
5. 残差连接(Residual Connection)和层归一化(Layer Normalization):为了避免梯度消失和梯度爆炸,Transformer使用了残差连接和层归一化技术。
6. 掩码(Masking):在解码器中,为了避免模型在预测时使用未来的信息,需要使用掩码技术。
总体来说,Transformer的主要架构是由输入嵌入层、编码器、解码器、位置编码、残差连接、层归一化、掩码等多个组件构成的。
自注意力机制
自注意力机制(Self-Attention Mechanism)是一种用于自然语言处理和计算机视觉等领域的机器学习技术。它可以帮助模型在处理序列数据时更好地理解序列中不同位置之间的关系,从而提高模型的性能。
自注意力机制的核心思想是将输入序列中的每个元素都看作是查询(query)、键(key)和值(value)三个向量,然后通过计算它们之间的相似度来确定每个元素对其他元素的重要性权重,最终将所有元素的值加权求和得到输出。这个过程可以用矩阵运算来实现,通常使用多头注意力机制来增强模型的表达能力。
自注意力机制已经被广泛应用于自然语言处理领域,如机器翻译、文本分类、问答系统等任务中,取得了很好的效果。同时,它也被应用于计算机视觉领域,如图像生成、目标检测等任务中。
多头自注意力机制(Multi-Head Self-Attention Mechanism)是一种用于自然语言处理和机器翻译等任务的深度学习模型。它是基于注意力机制(Attention Mechanism)的改进,通过引入多个注意力头(Attention Head)来提高模型的表现力和泛化能力。
在多头自注意力机制中,输入序列首先通过多个不同的线性变换得到多个不同的查询(Query)、键(Key)和值(Value)向量。然后,每个注意力头都会对这些向量进行注意力计算,得到一个加权和向量。最后,这些加权和向量会被拼接在一起,并通过另一个线性变换得到最终的输出向量。
通过引入多个注意力头,多头自注意力机制可以捕捉不同的语义信息,并将它们整合在一起,从而提高模型的表现力和泛化能力。同时,多头自注意力机制还可以并行计算,从而加快模型的训练和推理速度。















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









