







一.神经网络
1.神经网络的定义:
大量(结构简单的,功能相近的)神经元节点按一定体系架构连接成的网状结构
2.神经网络的作用:
(1)分类
(2)模式识别
(3)连续值的预测
(4)建立输入与输出的映射关系
3.神经元:
(1)神经元的模型
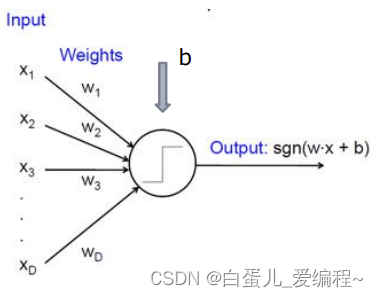
(2)神经元的作用:
每个神经元都是一个结构相似的独立单元,他接受前一层传来的数据,并将这些数据的加权和输入非线性作用函数中,最后将非线性作用函数的输出结果传递给后一层。
(3)神经元输入与输出的关系:
![]()
上式中,非线性函数f,称为激活函数。
(4)激活函数:
最开始有两个常用的激活函数,如下图:

(5)对于“层”的通俗理解:
1.“层”实现了输入空间到输出空间的线性或非线性变换
2.假设输入是碳原子和氧原子,输出三个变量
3.通过改变权重的值,可以获得若干个不同物质 -------提取不同特征
4.节点数决定了想要获得多少种不同的新物质 --------提取特征的个数


(6)人工神经网络:
神经网络是由大量神经元节点按一定体系架构连接成的网状结构,一般都有输入层,隐含层和输出层。
传统的浅层网络,一般有3-5层。
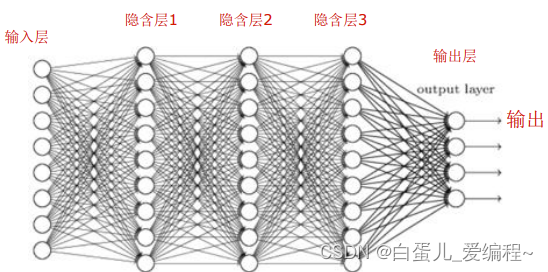
(7)前馈神经网络:
1.定义:是人工神经网络的一种,各神经元从输入层开始,接收前一级输入,并输出到下一级,直至输出层。整个神经中无反馈,可用一个有向无环图表示。
2.前馈神经网络采用一种单向多层结构。其中每一层包含若干个神经元,同一层的神经元之间没有互相连接,层间信息的传送只沿一个方向进行
3.其中第一层成为输入层,最后一层为输出层,中间为隐含层。隐含层可以是一层,也可以是多层。
二.误差反向传播算法
1.Delta学习规则
定义:是一种有监督学习算法,该算法根据神经元的实际输出与期望输出差别来调整连接权,其数学表示如下:
![]()
其中:

2.前馈神经网络的目标函数:

3.梯度下降:
为了让实际输出和我们的期望输出达到最大的相等,我们需要让前馈神经网络的目标函数达到最小,用的方法就是梯度下降。
下图是一个表示参数w与目标函数J(w)的关系图,红色的部分是表示J(w)有着比较高的取值,需要能够让J(w)的值尽量的低。也就是深蓝色的部分。w1,w2表示w向量的两个维度。

先确定一个初始点,将w按照梯度下降的方向进行调整,就会使得J(w)往更低的方向进行变化,如图所示,算法的结束将是在w下降到无法继续下降为止。

4.梯度下降示意

5.输出层权重的改变量
每次参数w在更新时,都需要计算输出层权重的改变量![]() ,下面我们来推导输出层权重改变量是怎么计算的。
,下面我们来推导输出层权重改变量是怎么计算的。

6.隐藏层权重改变量
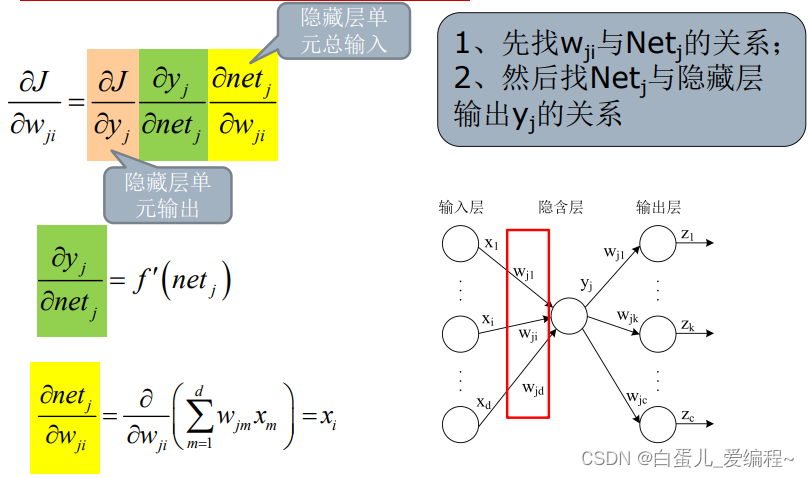

7.误差传播的迭代公式
比较重要的点:(1)残差是重要参数,后面还会提到
(2)从输出层反推向一层层的隐含层知道输入层,每次迭代规律都是一样的,都是用倒数的链式法则推导而出


总结:输出层和隐藏层的误差传播公式可统一为:
(1)权重增量=-1*学习步长*目标函数对权重的偏导数
(2)目标函数对权重的偏导数=-1*残差*当前层的输入
(3)残差=当前层激励函数的导数*上层反传来的误差
(4)上层反传来的误差=上层残差的加权和
8.简单的BP算例
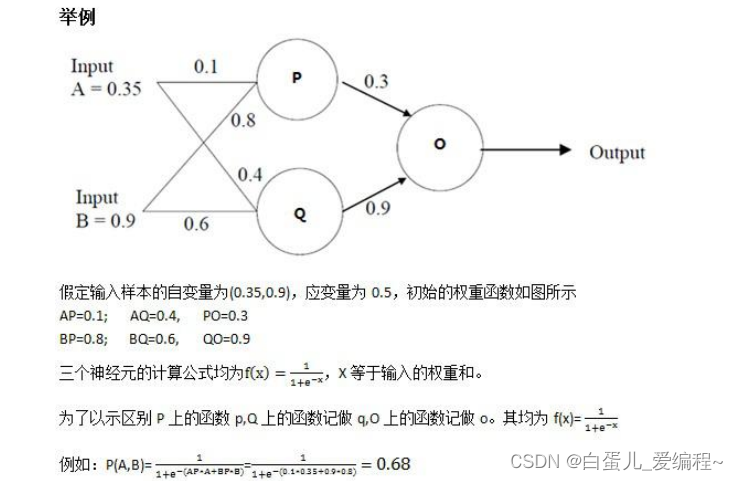


以上是我们举得简单的例子,然而在实际的训练之中我们的样本非常之多,于是就有了我们常说的优化器,不同的优化器利用不同的方法来进行梯度下降。
9.梯度下降的不同方法
(1)批量梯度下降
每迭代一步,都要用到训练集所有的数据,他得到的是一个全局最优解,但是如果m也就是数据集很大,那么迭代速度会非常的差。
(2)随机梯度下降(SGD)
通过每个样本迭代更新一次,若样本量很大,那么可能只用其中部分的样本,就已经迭代到最优解了,但是,SGD并不是每次迭代都向着整体最优方向
(3)mini-batch Graddient Descent
在批量梯度下降和随机梯度下降两种方法中取折中,每次从所有训练集中取一个子集(mini-batch)用于计算梯度
广义条件下,SGD指的就是MBGD

10.特征对学习的影响
一般而言,机器学习中特征越多,给出的信息越多,识别准确性会得到提升。但特征多,计算复杂度增加,探索的空间就大,训练数据在全体特征向量中就会显得稀疏,影响相似性判断。更重要的时,若有对分类无益的特征,反而可能干扰学习效果。
结论:特征不一定越多越好,获得好的特征是识别成功的关键。需要有多少特征,需要学习问题本身来决定。
11.深度学习的特征
深度学习,是一种基于无监督特征学习和特征层次结构的学习模型,其实是对神经网络模型的拓展。















 5171
5171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









