







初识HTTP
HTTP为超文本传输协议,其作用是把超文本数据从网络传输到本地浏览器。
HTTP请求过程
在网址栏输入一个url,按下回车便可观察到对应的页面内容。这个过程是浏览器先向网站所在服务器发送一个请求,网站服务器接收到请求后对其进行处理和分析,然后返回对应的响应,接着传回浏览器。浏览器再对响应里所含的源代码进行解析,最后呈现出来。
开发者界面
在网页中鼠标右击,选择“检查”(或者按下快捷键F12),即可打开浏览器开发者界面,此时切换到Network面板,刷新界面,面板下会出现很多条目,每一条条目就代表一次发送请求和接受响应的过程。
4. 爬虫的基本原理
(1)爬虫概述
获取网页
获取网页源代码
提取信息
分析网页源代码,从中提取我们想要的数据。最通用的方法是正则表达式。
保存数据
将获得的数据保存方便后续使用,存储数据的方式多种多样,可以简单保存为TXT文本或者JSON文本,也可以保存到数据库。
自动化程序
爬虫代替人完成上述操作。
(2)能爬怎样的数据
常规网页,网页对应HTML源代码
网页返回的JSON字符串(API接口大多采用这样的形式)
网页中包含的二进制数据(图片、视频和音频等)
CSS、JavaScript和配置文件等
(3)JavaScript渲染的页面
渲染过程
在浏览器中打开打开页面时,首先加载这个HTML内容,接着里浏览器会发现其中引入了一个app.js文件,便去请求这个文件,获取文件后,执行其中的JavaScript代码,JavaScript会改变HTML中的节点,向其中添加内容,最后得到完整的页面。
爬取思路
一,分析源代码后台Ajax接口
二,使用库函数来模拟JavaScript渲染
电影信息爬取案例
我们要爬取的是一个电影信息网,打开页面如下图
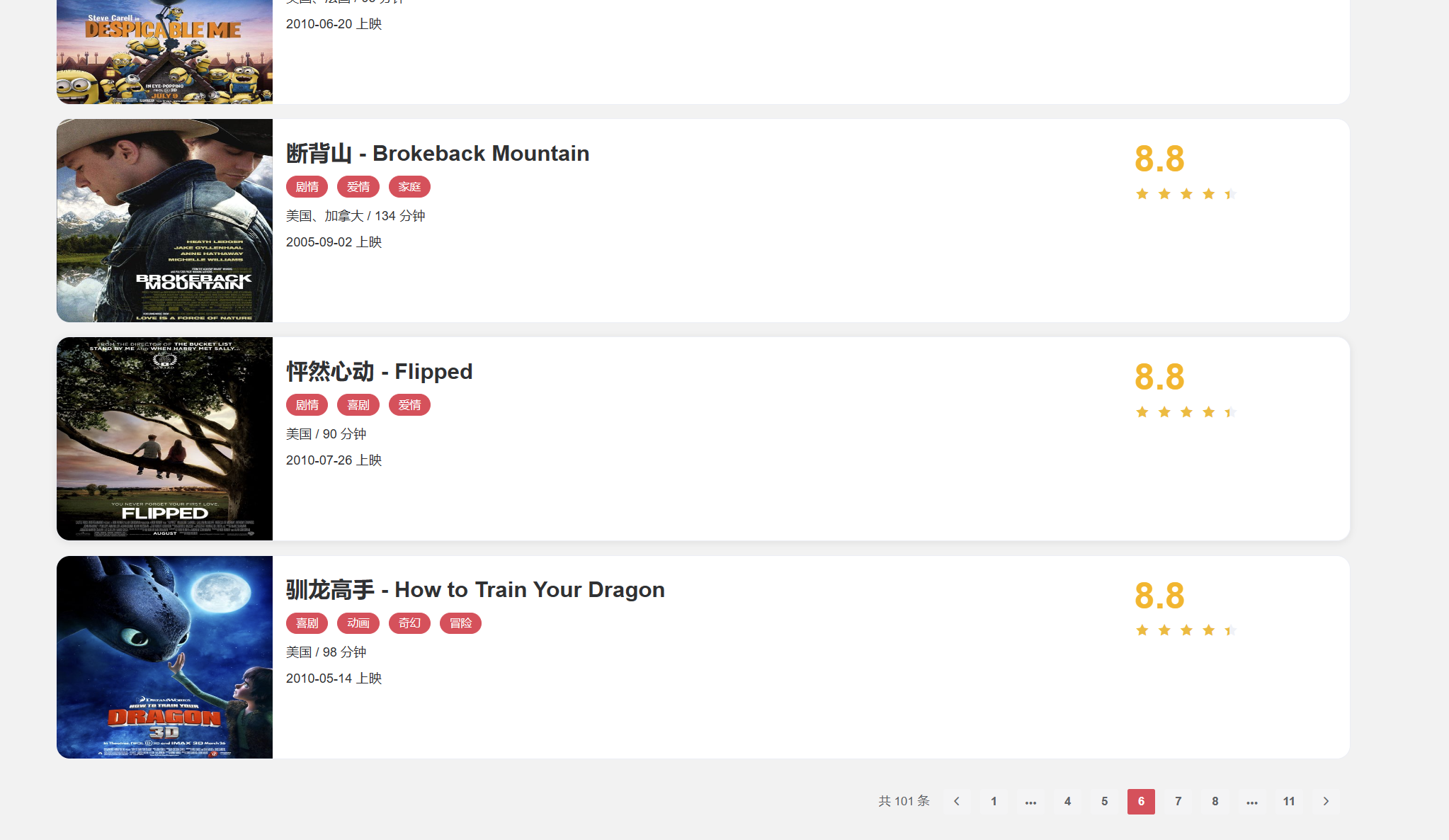
点击电影便会出现电影详情页,点击页码会出现另一页电影。

爬取目标
1.爬取每一页的电影列表,以及顺着列表去爬取每个电影的详情页
2.用正则表达式提取每部电影各种信息
3.将爬取内容保存为表格
分析过程
分析,我们需要获得电影的详情信息,只要获得电影详情页的URL,爬虫爬取详情页,提取信息即可,要获得电影详情页就得从分页列表中获取,所以还得获取每一页列表页的URL。
首先分析每个列表页的URL,在点击页码时,便能获取到不同页码的列表页,所以url信息隐藏在页码节点附近,在站点根页面中,打开开发者工具,观察HTML代码。如下图:

观察规律URL里的数字与页码相对应,将站点根URL与提取的URL结合便构成了列表页完整的URL。URL构造代码如下:
index_url = f'{BASE_URL}/page/{page}' #构造分页的URL在站点根页面中,打开开发者工具,观察HTML代码。选择一部电影的元素,观察节点,可以得到其对应详情页的URL(/detail/1),点开详情页观察其完整URL(站点根URL加上文详情页的URL)如下图:

只要将每一页的十个URL信息爬取出来,并与站点根URL结合便可获得所有电影详情页的URL,构造URL使用urljion函数,代码如下:
detail_url = urljoin(BASE_URL,item)上述分析已经介绍如何获取列表页和详情页的URL,接下来上代码。代码与图片一起食用更美味哦!!
案例代码实现
导入库,初始化参数
import requests
import logging #输出信息
import re
from urllib.parse import urljoin #做URL的拼接
from openpyxl import Workbook
logging.basicConfig(level =logging .INFO ,
format= '%(asctime)s-%(levelname)s:%(message)s')
BASE_URL = 'https://ssr1.scrape.center' #站点根URL,
TOTAL_PAGE = 10 #爬取的总页数定义爬取页面的方法,我们需要爬取的是列表页,以及电影详情页。参数是URL地址
def scrape_page(url):
logging.info('scraping %s......',url) #显示正在爬取什么网址
try:
response = requests.get(url)
if response.status_code == 200:
return response .text
logging .error('get invalid status code %s while scraping %s', response.status_code, url)
except requests .RequestException :
logging.error('error occurred while scraping %s', url, exc_info=True)爬取页面的方法定义完成,定义爬取列表页函数
def scrape_index(page):
index_url = f'{BASE_URL}/page/{page}' #构造分页的URL
return scrape_page(index_url) #调用页面信息爬取的函数,返回页面信息定义解析列表页函数,获取详情页的URL
def parse_index(html):
pattern = re.compile('<a.*?href="(.*?)".*?class="name">')
items = re.findall(pattern, html)
if not items:
return []
for item in items:
detail_url = urljoin(BASE_URL,item)
# logging.info('get detail url %s ', detail_url)
yield detail_url详情页URL已经获取,需要解析详情页获取需要的信息
# 1.分析爬取页面结构

# 2.定义详情页爬取函数
def scrape_detail(url):
return scrape_page(url)# 3.定义解析详情页界面函数(对照图中的HTML代码写正则表达式)
def parse_detail(html):
cover_pattern = re.compile(
'class="item.*?<img.*?src="(.*?)".*?class="cover">', re.S)
name_pattern = re.compile('<h2.*?>(.*?)</h2>')
categories_pattern = re.compile(
'<button.*?category.*?<span>(.*?)</span>.*?</button>', re.S)
published_at_pattern = re.compile('(\d{4}-\d{2}-\d{2})\s?上映')
drama_pattern = re.compile('<div.*?drama.*?>.*?<p.*?>(.*?)</p>', re.S)
score_pattern = re.compile('<p.*?score.*?>(.*?)</p>', re.S)
cover = re.search(cover_pattern, html).group(
1).strip() if re.search(cover_pattern, html) else None
name = re.search(name_pattern, html).group(
1).strip() if re.search(name_pattern, html) else None
categories = re.findall(categories_pattern, html) if re.findall(
categories_pattern, html) else []
categories = ' '.join(categories)
published_at = re.search(published_at_pattern, html).group(
1) if re.search(published_at_pattern, html) else None
drama = re.search(drama_pattern, html).group(
1).strip() if re.search(drama_pattern, html) else None
score = float(re.search(score_pattern, html).group(1).strip()
) if re.search(score_pattern, html) else None
return {
'cover': cover,
'name': name,
'categories': categories,
'published_at': published_at,
'drama': drama,
'score': score
}定义数据存储函数
#定义数据存储函数
def save(inputData,outPutFile):
Lable = ['A', 'B', 'C', 'D', 'E', 'F', 'H']
wb = Workbook()
sheet = wb.active
sheet.title = "Sheet1"
item_0 = inputData[0]
i = 0
for key in item_0.keys():
sheet[Lable[i] + str(1)].value = key
i = i + 1
j = 1
for item in inputData:
k = 0
for key in item:
sheet[Lable[k] + str(j + 1)].value = item[key]
k = k + 1
j = j + 1
wb.save(outPutFile)
print('数据写入完毕!')定义数据获取函数
def data():
df = []
for page in range(1,TOTAL_PAGE ):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
detail_urls = list(detail_urls )
logging.info('detail urls %s',detail_urls)
for i in range(len(detail_urls)):
detail_url = detail_urls[i]
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info('get detail data %s', data)
df.append(data)
return df主函数
if __name__ == '__main__':
df = data()
save(df,'data.xlsx')结果:

















 7888
7888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











