






大家好,我是袋鼠帝 昨天分享了一篇关于Gemini的文章 Google发布新版Gemini2.5 Pro 袋鼠帝,公众号:袋鼠帝AI客栈
Google这把超神了,AI编程的天叒被捅破了【新增Bug级功能】
由于看到Google最新的模型性能这么强劲(体验下来确实强) 在那篇文章里面表达了一些对国内大模型恨铁不成钢的看法。 直到我看见这两条评论,我才意识到,我分析得不够全面。


添加图片注释,不超过 140 字(可选)
AI领域,我们与国外大模型厂商的竞争,并不仅仅在于模型的性能(虽然性能是很重要)
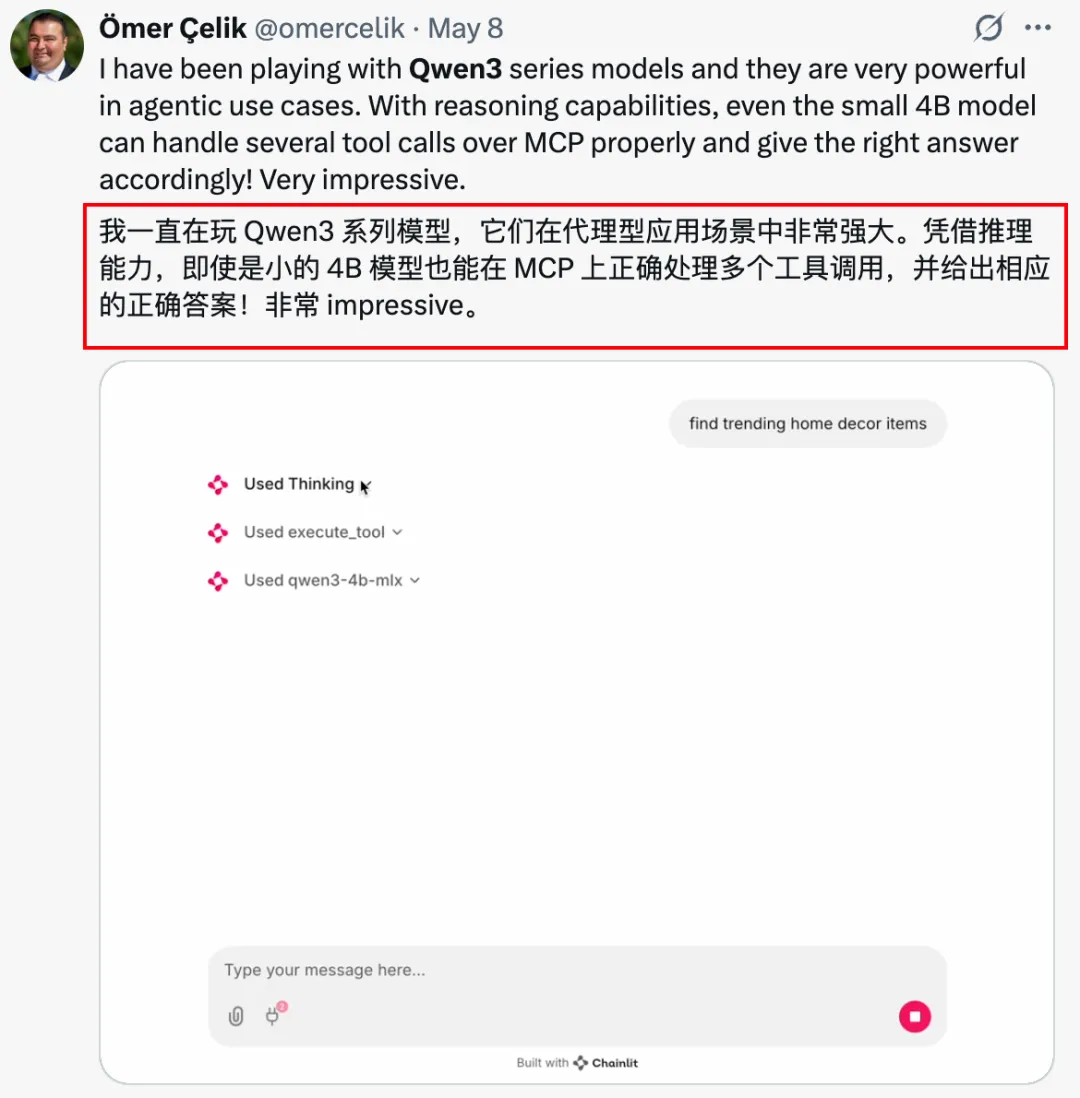
于是我在本地安装了Qwen3的小尺寸模型,测试完我直接震惊了,仅仅8B参数量的模型,有时候效果甚至直追那些闭源收费的大模型。
比如这个好玩的动画特效 你敢信是一个8B参数量模型跑出来的?
而且只经过两轮提问,之前那些8B模型连个简单网页都跑不出来,而且还一推bug,需要反复提问修改。。。
动画特效
好的标题可以获得更多的推荐及关注者
其他挺棒的Case写在最后了,包含提示词,需要可自取
这还是没有经过进一步微调的原生Qwen3
经过查阅各种资料、信息后,我惊奇的发现
阿里的Qwen(千问)其实早就在海外杀疯了...
特别是这次刚发布不久的Qwen3
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
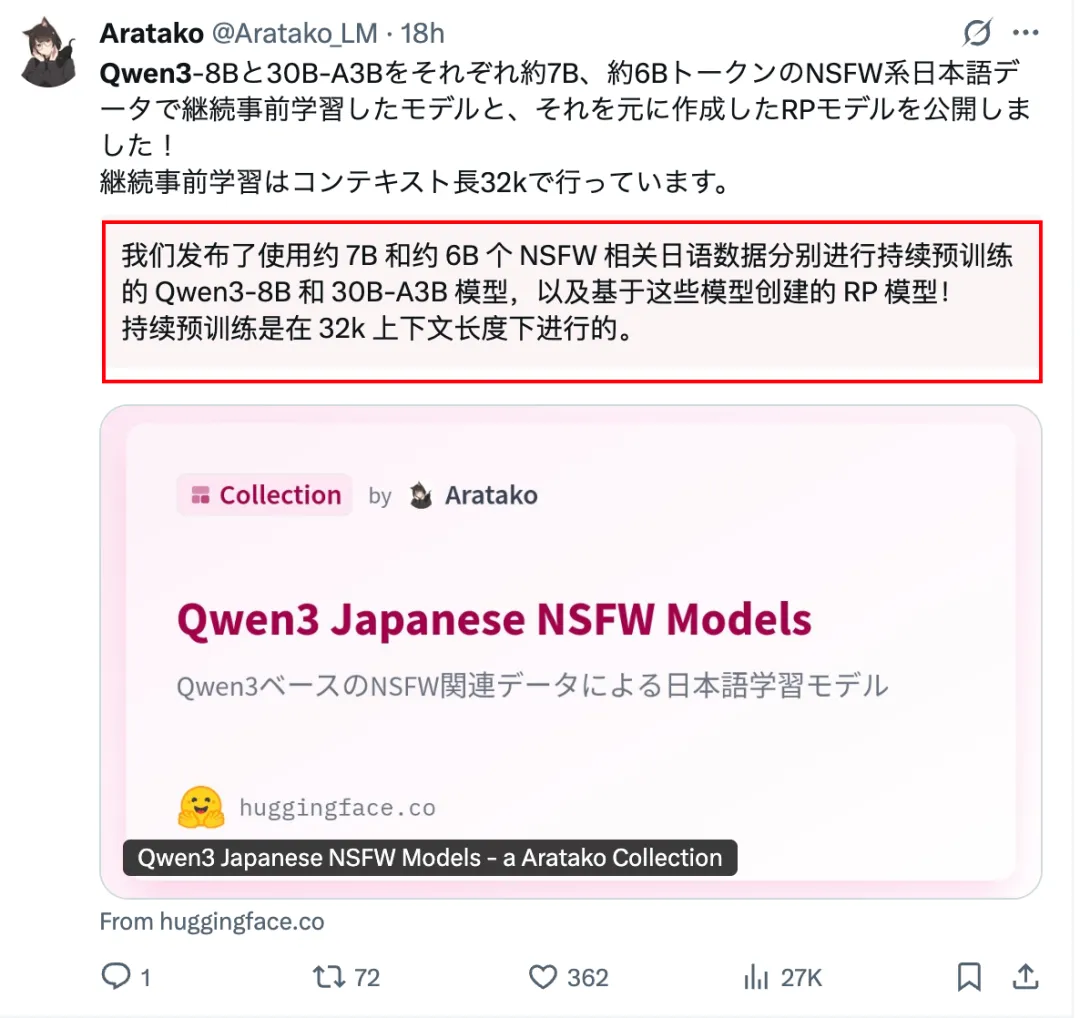
而且海外那帮人,已经基于Qwen开源模型训练出一堆垂类模型,做得风生水起...
更🐂🍺的是,我发现Qwen已经成为海外多国的AI开发基础了
下面都会一一介绍,说不定有合适的落地场景应用可参考哦~
1.Qwen,开源第一
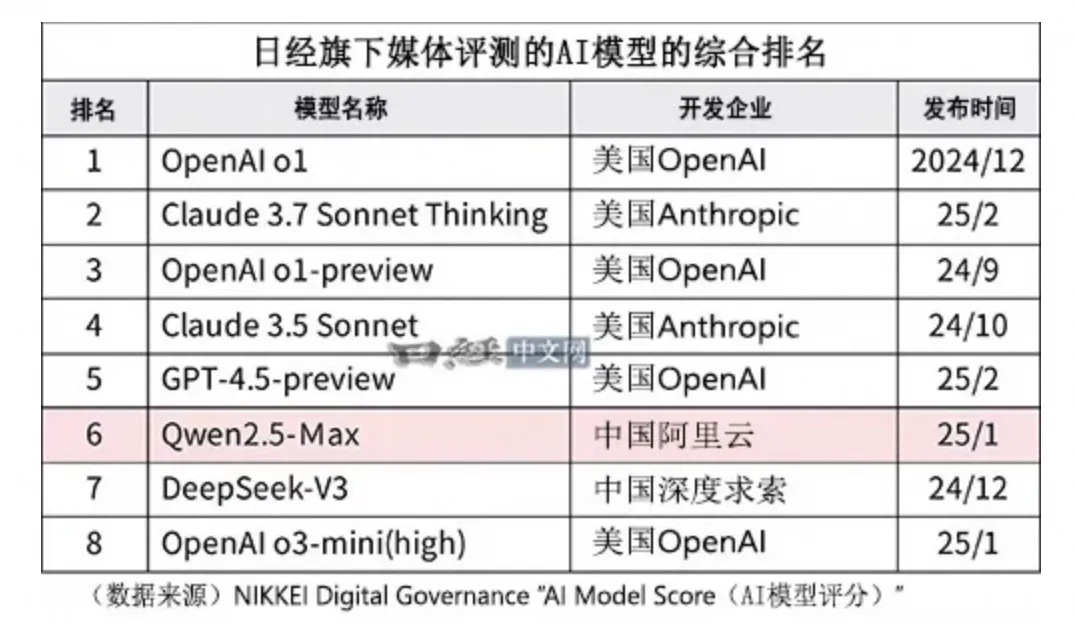
先来看一个数据吧 国际权威媒体-日本经济新闻(NIKKEI)在4月份公开了一份AI模型评分榜。
添加图片注释,不超过 140 字(可选)
Qwen力压众多闭源模型,在全球113个模型中排名第6,并且是排名第一的开源大模型。
2年时间,阿里通义已经开源了200多个模型,全球下载量超2亿次,衍生模型数超10万个,已完全超越美国的Llama,登顶全球第一开源模型!
Qwen Chat:https://chat.qwenlm.ai
通义APP:https://www.tongyi.com/
Hugging Face:https://huggingface.co/spaces/Qwen/Qwen3-Demo
ModelScope:https://www.modelscope.cn/studios/Qwen/qwen3-chat-demo
GitHub:https://github.com/QwenLM/Qwen3
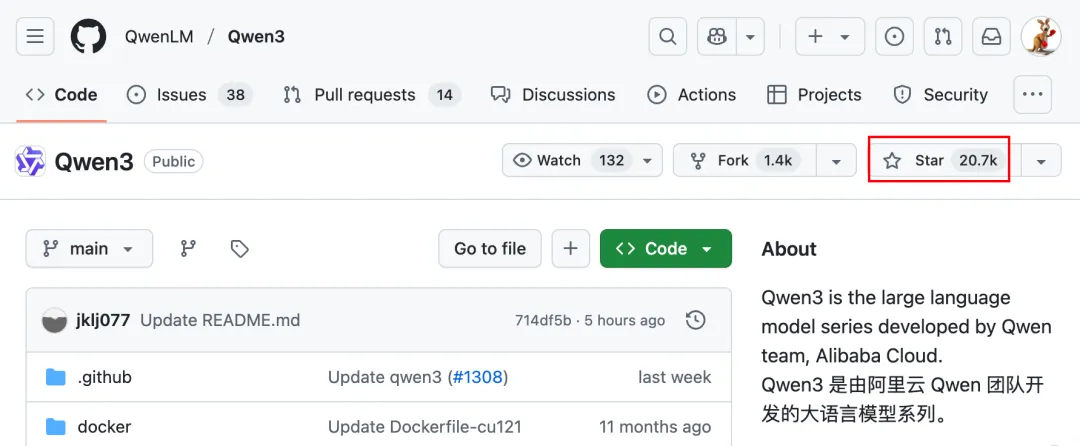
而且,Qwen3才刚刚开源一周,就在Github斩获了20K Star
添加图片注释,不超过 140 字(可选)
2.为什么Qwen能成为多国AI开发基础
看到这里,可能有人会问,感觉DeepSeek更火,但为什么没有成为多国AI开发的基础呢?
DeepSeek的部署成本还是太高了,注定没法普及。
旗舰版千问3模型的总参数235B激活22B,大致需要4张H20或同等性能的GPU。对比来看,满血版DeepSeek-R1总参数671B激活37B,1台8卡H20(100w左右)可跑但比较吃紧,一般推荐16卡H20,总价约200万左右。 因此,从部署成本看,千问3是满血版R1的25%~35%,模型部署成本直降六/七成,大大降低了顶尖模型的部署应用门槛。
而Qwen不仅性能强劲,还全面(全尺寸、全模态)
全模态:包含文本生成模型、视觉理解/生成模型、语音理解/生成模型、文生图/视频模型
全尺寸:参数量覆盖0.5B、0.6、1.5B、3B、4B、7B、14B、30B、32B、72B、110B、235B
非常适合用来做二次训练、微调 手机端侧应用推荐4B模型;
电脑或者汽车端侧应用推荐8B模型;14B 模型适合作落地应用,普通开发者有几张卡也都能玩转起来;32B应该是开发者和企业最喜欢的模型尺寸,企业可大规模部署商用
同时,对于那些技术相对落后的国家和地区,无疑是福音。
完全开源的Qwen为他们提供了便利,极大降低了AI开发门槛。
当然,即便是对于技术强劲的日本等发达国家来说,他们也没有比Qwen更好的选择了。
真的很离谱,我感觉Qwen已经快占领日本企业了
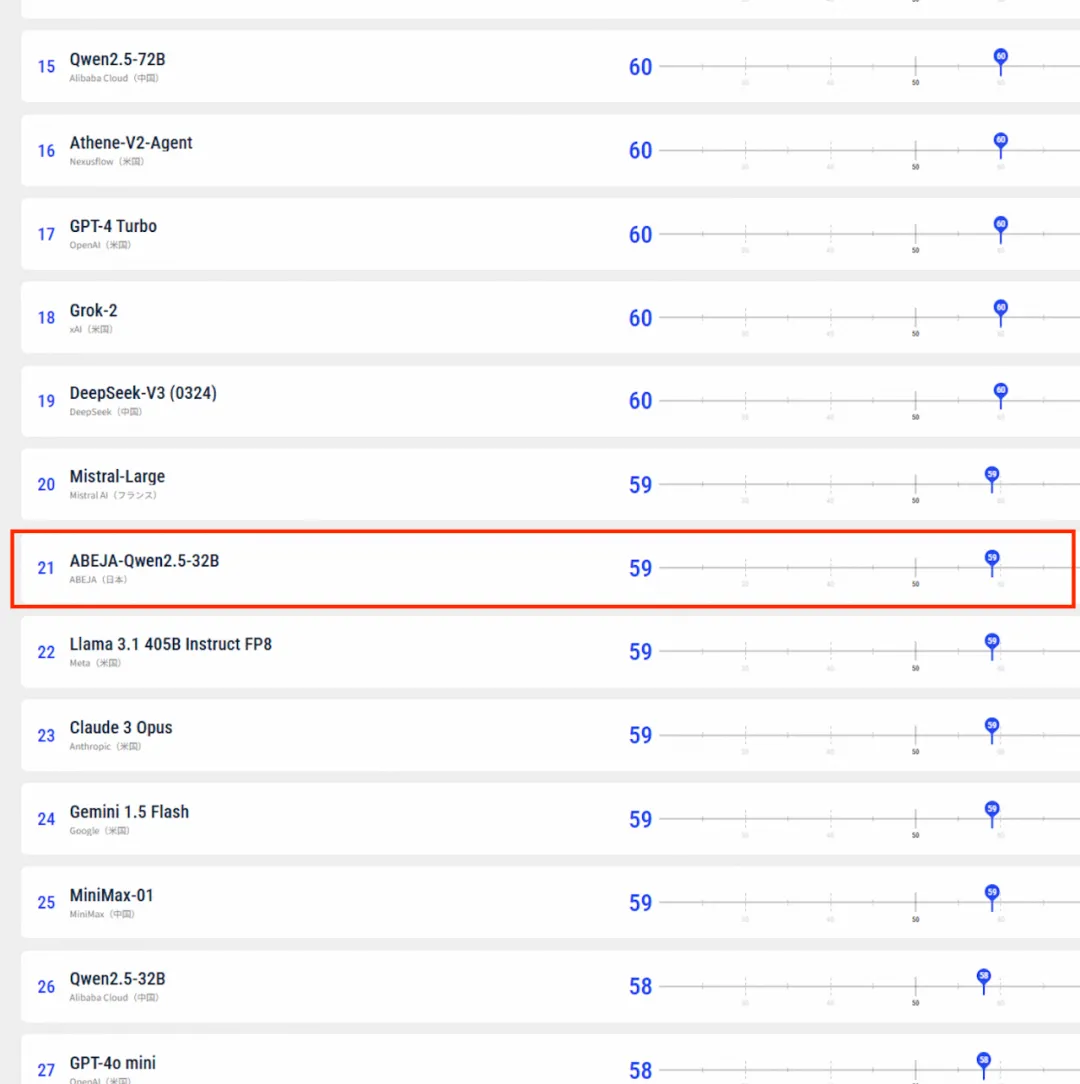
包括ABEJA在内的大量日本新兴企业都在基于Qwen做AI开发 ABEJA株式会社是日本著名科技公司,专注于深度学习和人工智能技术的开发与应用,提供包括数据分析、图像识别、自然语言处理等服务。感觉可以类比国内阿里。
比如参评日本企业中得分最高的模型:ABEJA-Qwen2.5-32B也是基于千问开发的...
添加图片注释,不超过 140 字(可选)
3.Qwen在海外落地的应用场景
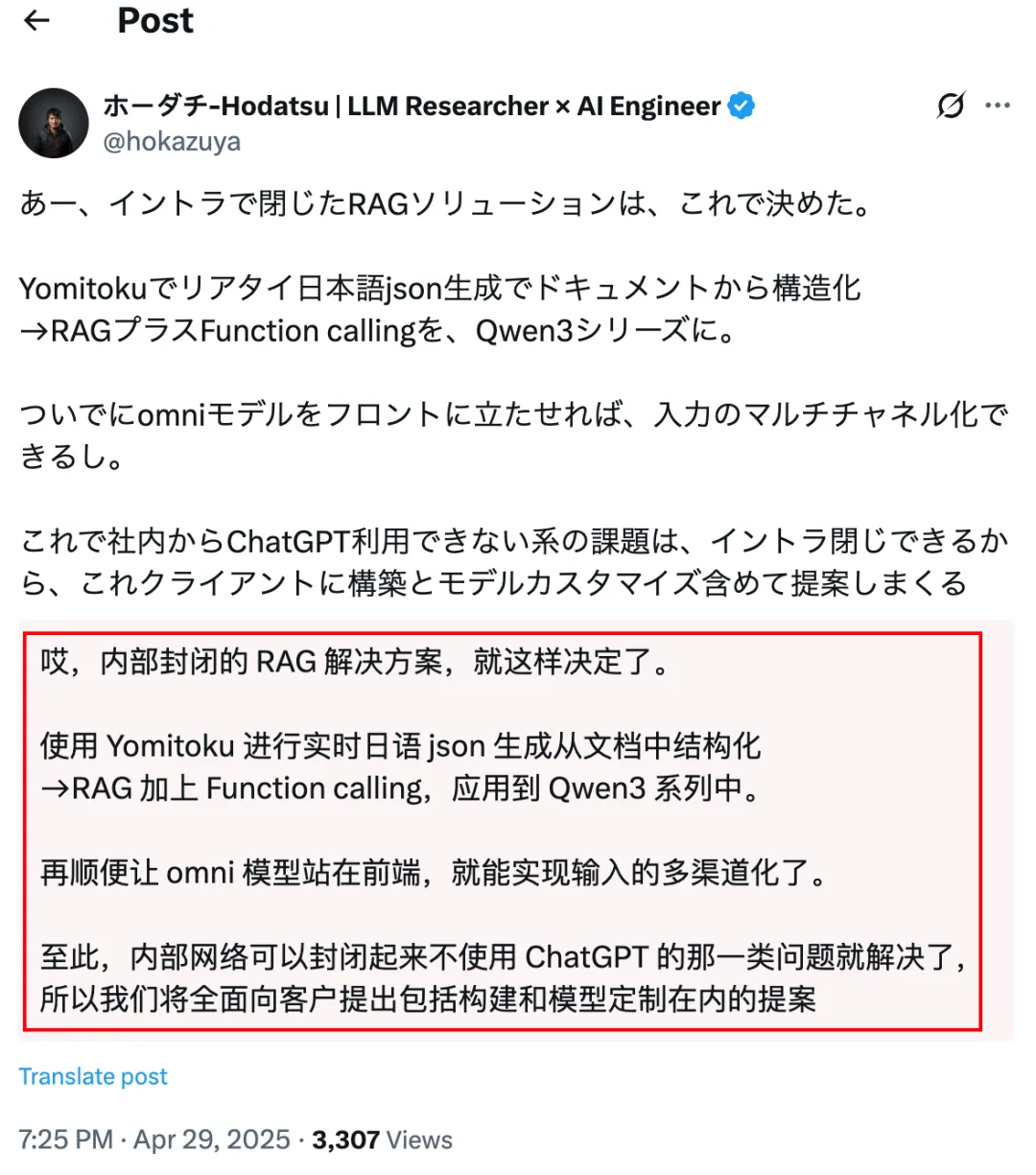
这位日本KOL 在X上拥有17.6K粉丝
他用本地部署的Qwen3解决了他的客户所在公司不允许使用ChatGPT这类远程大模型的难题。
添加图片注释,不超过 140 字(可选)
整个流程大概是:用 "Yomitoku" 工具从文档中实时生成结构化的日语JSON数据,将处理好的数据存入RAG系统(知识库)Qwen作为核心的问答模型,同时也具有function call的工具调用能力。
确实,不仅是日本,在国内也有很多公司不允许调用外部大模型

添加图片注释,不超过 140 字(可选)
所以全链路私有化的需求很大,是个机会:不管是你给别人做,还是自己用。
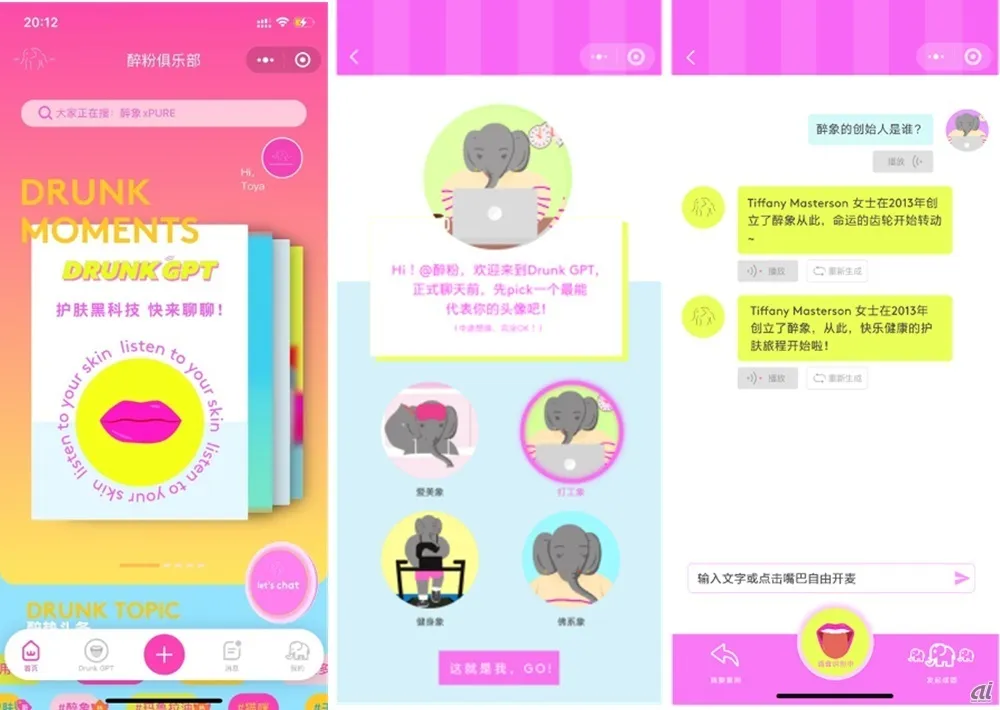
接下来我们再看一个企业内部使用Qwen的案例 2024年8月,资生堂旗下的护肤品牌 DRUNK ELEPHANT 使用阿里云的 Qwen 大型语言模型 (LLM) 开发了一款名为 DRUNKGPT 的聊天机器人,为消费者回答对护肤问题的询问 原文链接:https://japan.zdnet.com/article/35222907/
添加图片注释,不超过 140 字(可选)
它用Qwen基于该品牌的知识数据库进行训练,利用阿里云的监督微调(SFT)和检索增强生成(RAG)进行了优化。 中国消费者可以通过文字或语音与该聊天机器人互动,语音功能也是由阿里云的自动语音识别(ASR)和文本转语音(TTS)技术实现。
从这个案例中,值得借鉴的是RAG+SFT(微调)
如果你的RAG知识库,问答效果怎么都达不到要求,那么可以试试在本地用Qwen这类小模型来微调(主要是算力成本不高)。
这也是我最近想要尝试的方案:RAG+微调的本地大模型双管齐下,看看AI客服的问答效果可以再提升多少。
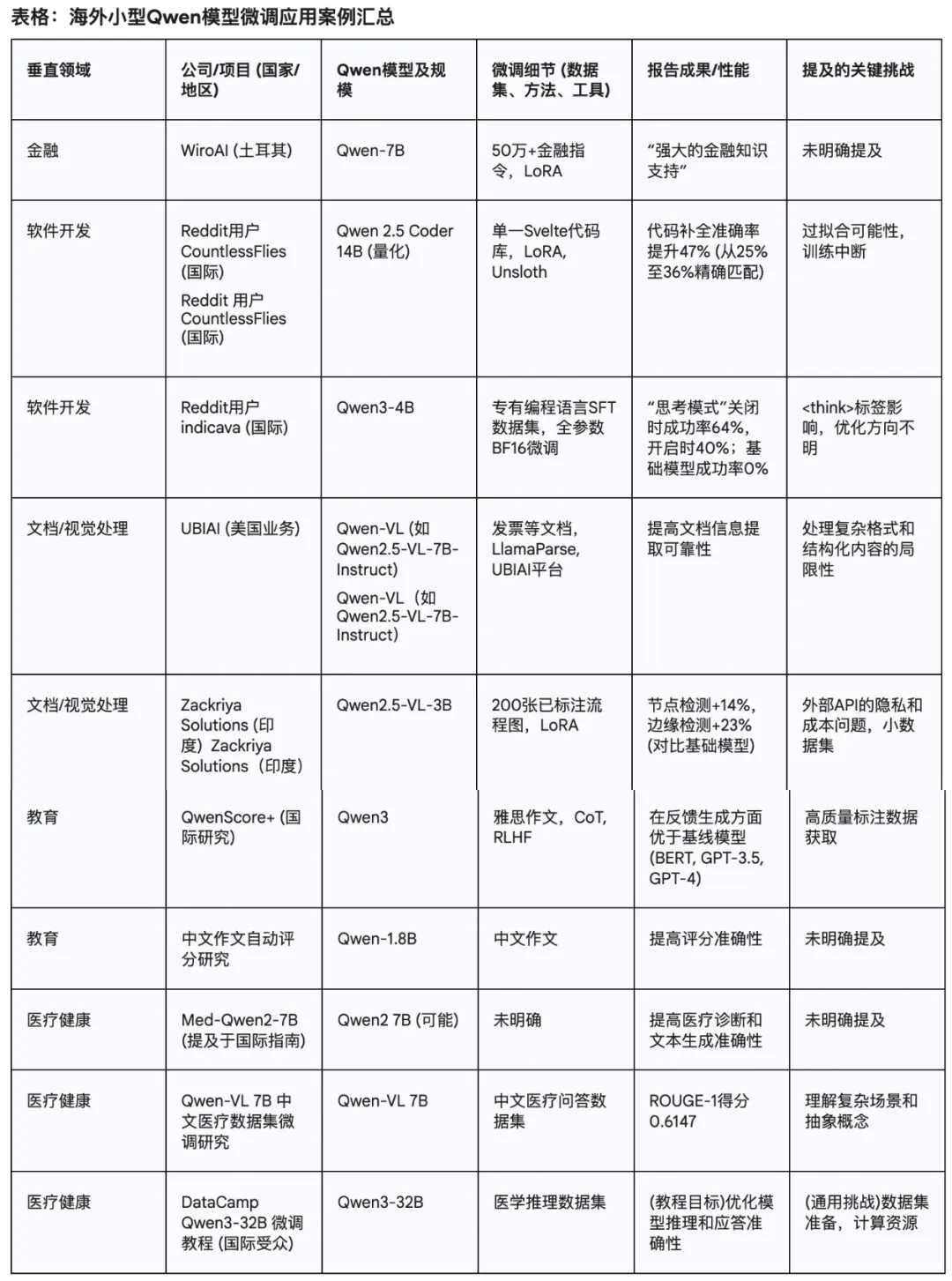
下面是我搜索整理出来的Qwen小模型在海外的其他应用场景(可以参考参考)
添加图片注释,不超过 140 字(可选)
小模型虽然在性能上无法跟大参数量的模型相比,但Qwen3的每款模型均斩获同尺寸开源模型SOTA(最佳性能) 最难得的一点是可以以超低的成本去进行进一步的训练、微调,打造适配需求和业务的垂类大模型,关键可以毫无压力的本地部署,内网使用,安全私密,不怕信息泄露。
当我看到下面这些X上的媒体、博主争相报道Qwen3的画面 我勒个豆,感觉似成相识,这不咱们这边蹲OpenAI的既视感吗
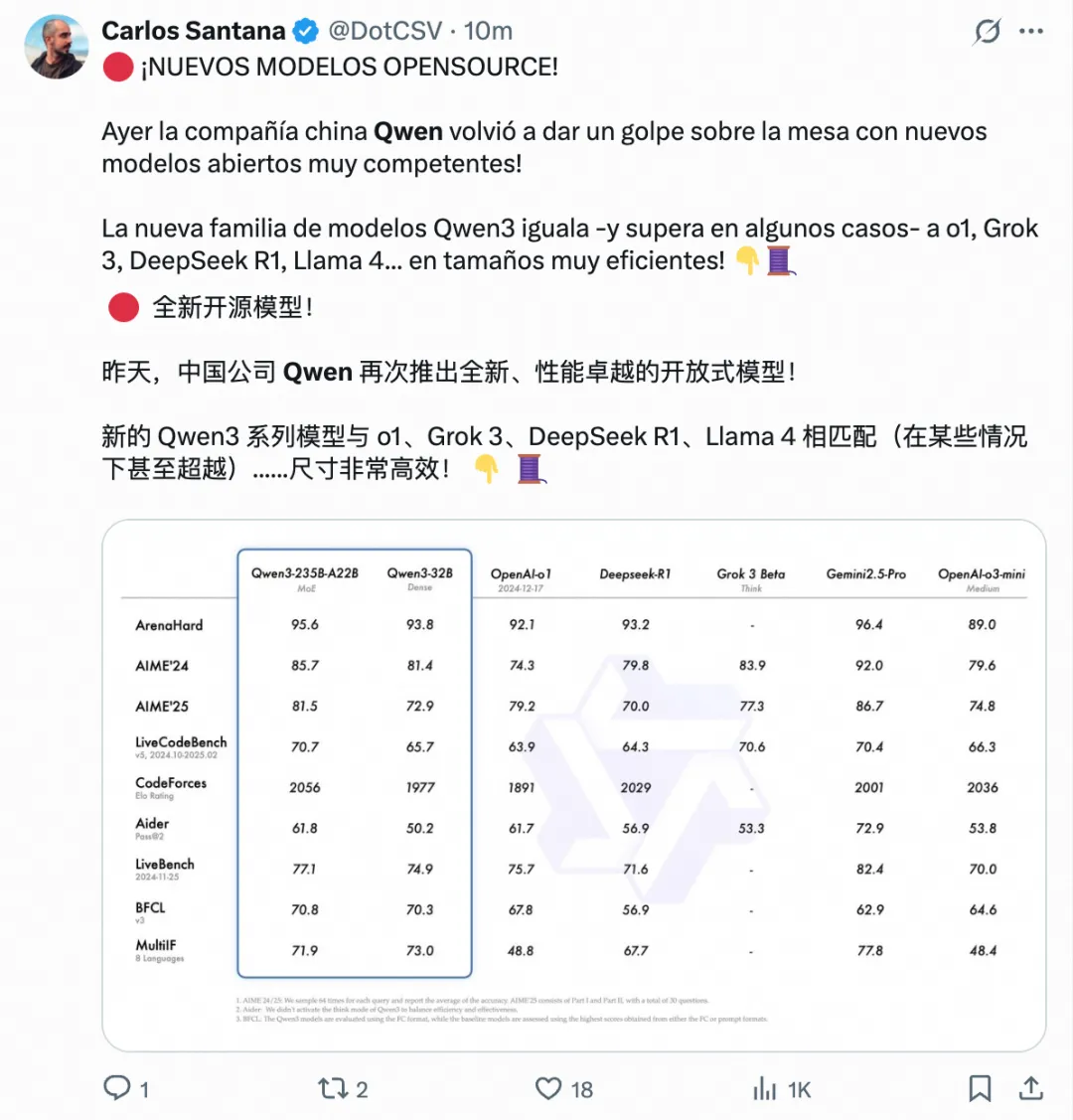
添加图片注释,不超过 140 字(可选)
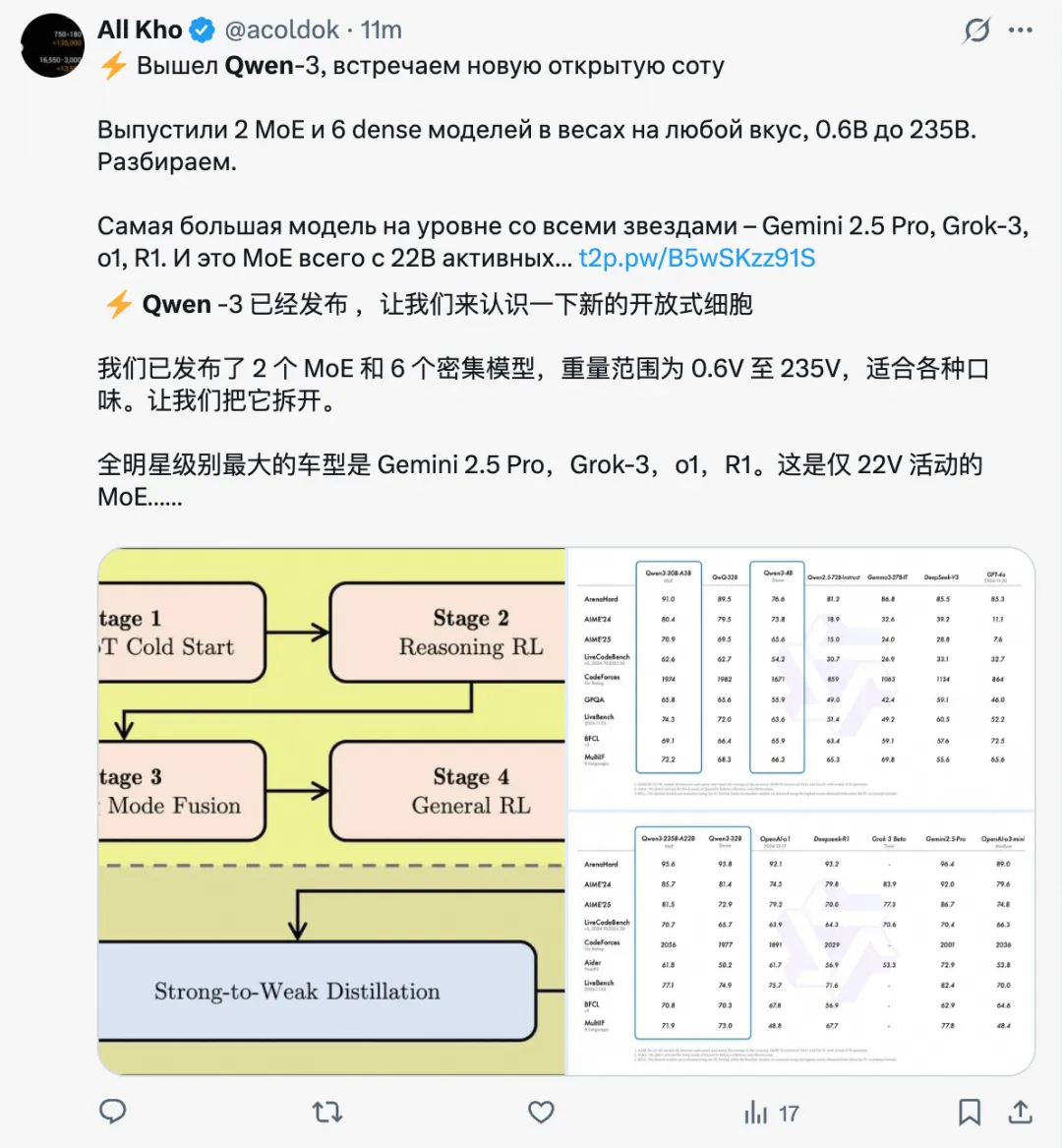
添加图片注释,不超过 140 字(可选)
在墙外人的眼中,它好像真是香饽饽。
4.Qwen3小模型使用技巧
既然Qwen3在海外这么受欢迎,我就打算在本地测试一下 真的是不测不知道,一测吓一跳了 强烈建议用这个开源软件(Aingdesk)来下载开源模型,速度贼拉快(无需魔法上网),可以参考我之前分享的这篇 袋鼠帝,公众号:袋鼠帝AI客栈
私有知识库+本地300种模型一键部署,私密性拉满!这个国产开源工具太绝了 这下载速度就问你服不服
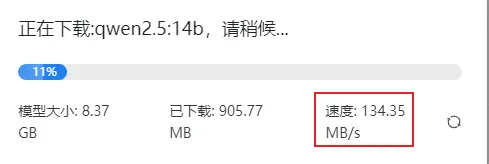
添加图片注释,不超过 140 字(可选)
但是如果你要Qwen帮你写点前端网页的话
可以用Aingdesk快速下载模型之后换成Cherry Studio
因为Cherry Studio支持直接预览生成的HTML代码(太省事儿了)
添加图片注释,不超过 140 字(可选)
我本地电脑用的Mac,配置是M2芯片+24G内存(Mac的M系列芯片GPU和CPU是共用一个内存的) 意味着我的GPU可使用内存就是24G 我几乎尝试了,所有理论上我能跑的Qwen3尺寸(如下图)
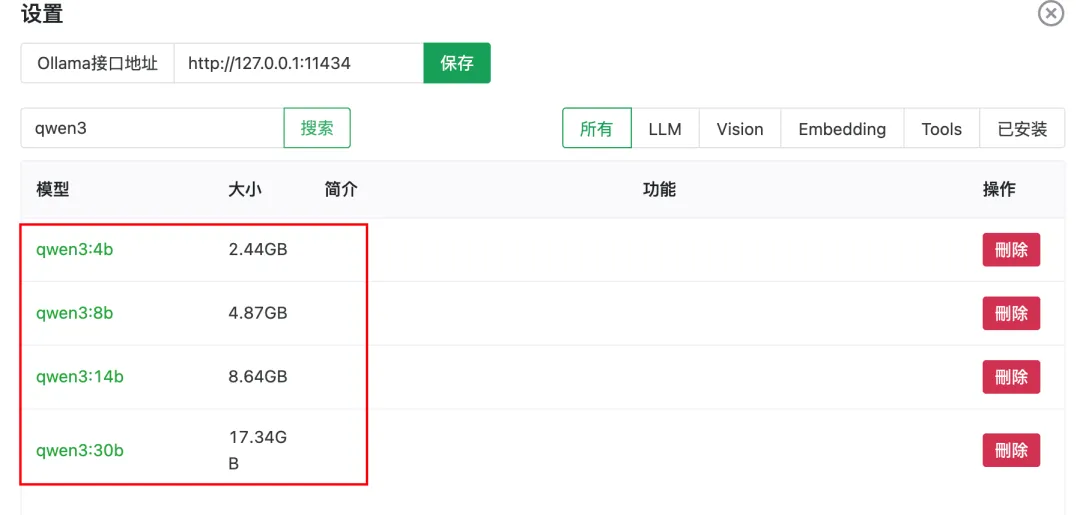
添加图片注释,不超过 140 字(可选)
本地大模型还是吃GPU的内存,教大家一个选择适合本机模型的方法:
模型所需GPU内存大小≈模型大小×1.2 所以理论上17G的qwen3:30B我的Mac是能跑的(17*1.2=20.4 < 24G)
但是实际体验下来30B的模型是能跑,但是贼慢 最后我选择了最合适的qwen3:8b,对于我的配置来说,这个尺寸的回复速度刚刚好。
接下来直接开测~
不得不说,小模型本地化部署的优势在断网下提现的淋漓尽致。
下面的Case都是我从昆明->杭州的飞机上跑的
一个仅有8B的模型,效果完全惊艳到我,比起以前用过的那些小模型提升太多了。
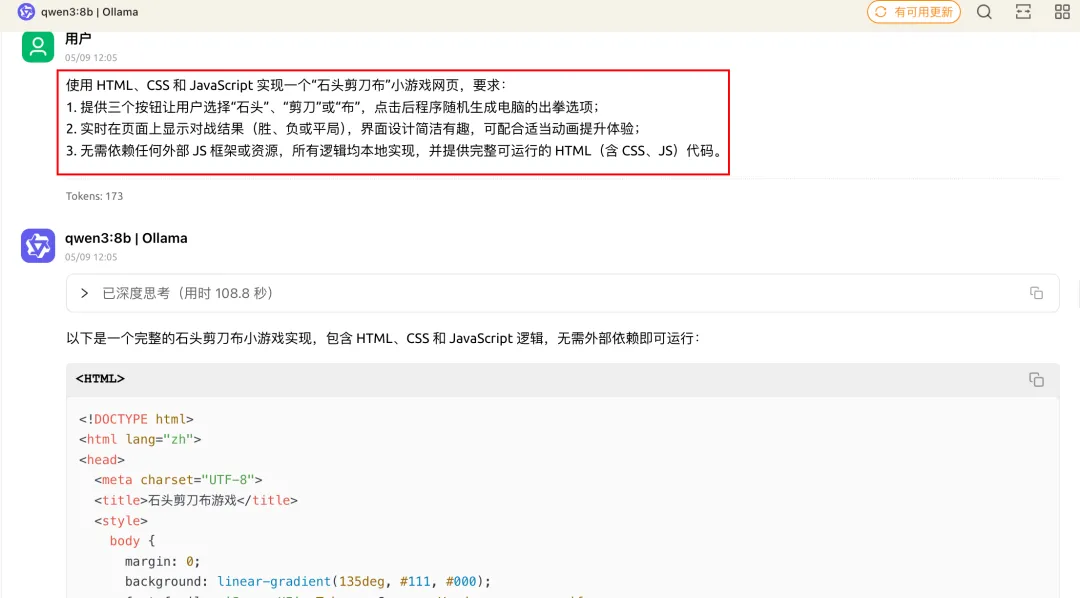
咱们先测试一下它的代码能力 让它生成一个石头剪刀布的小游戏
提示词: 使用 HTML、CSS 和 JavaScript 实现一个“石头剪刀布”小游戏网页,要求: 1. 提供三个按钮让用户选择“石头”、“剪刀”或“布”,点击后程序随机生成电脑的出拳选项; 2. 实时在页面上显示对战结果(胜、负或平局),界面设计简洁有趣,可配合适当动画提升体验; 3. 无需依赖任何外部 JS 框架或资源,所有逻辑均本地实现,并提供完整可运行的 HTML(含 CSS、JS)代码。
添加图片注释,不超过 140 字(可选)
2分钟左右,生成完毕 我本来没报多大希望,但是没想到一次就成功了!
而且效果还真不赖(起码功能是正常的),然后我就在飞机上跟它玩了好几分钟的石头剪刀布...

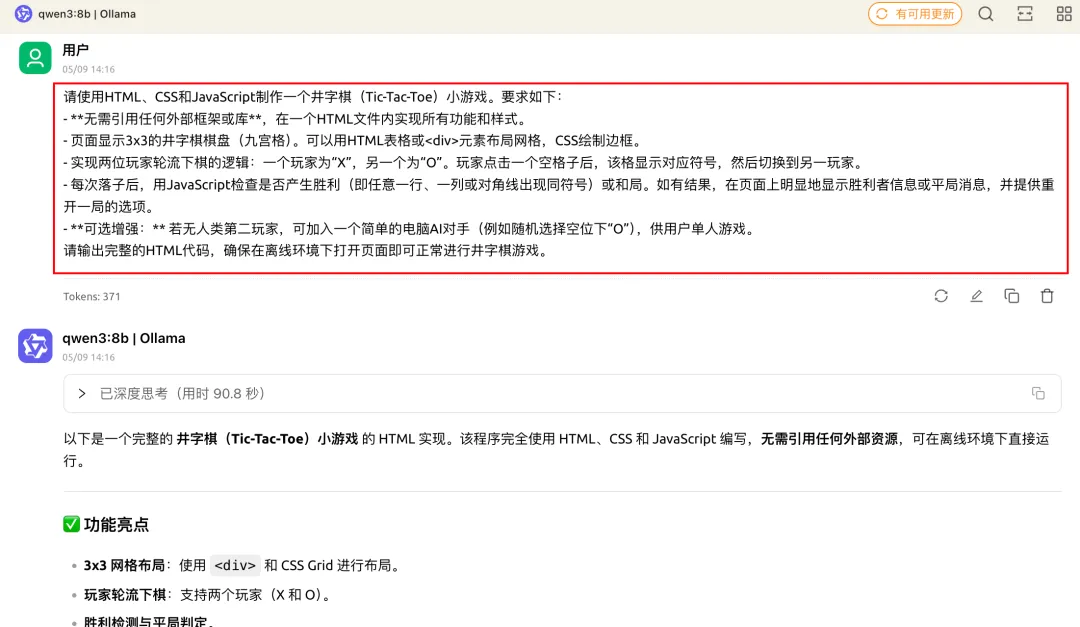
接着我怀疑它的一次性成功是偶然,以前用的8B模型也不是这样的呀。 所以就再来了一次代码测试(生成一个井字棋小游戏)
提示词: 请使用HTML、CSS和JavaScript制作一个井字棋(Tic-Tac-Toe)小游戏。要求如下: - **无需引用任何外部框架或库**,在一个HTML文件内实现所有功能和样式。 - 页面显示3x3的井字棋棋盘(九宫格)。可以用HTML表格或<div>元素布局网格,CSS绘制边框。 - 实现两位玩家轮流下棋的逻辑:一个玩家为“X”,另一个为“O”。玩家点击一个空格子后,该格显示对应符号,然后切换到另一玩家。 - 每次落子后,用JavaScript检查是否产生胜利(即任意一行、一列或对角线出现同符号)或和局。如有结果,在页面上明显地显示胜利者信息或平局消息,并提供重开一局的选项。 - **可选增强:** 若无人类第二玩家,可加入一个简单的电脑AI对手(例如随机选择空位下“O”),供用户单人游戏。 请输出完整的HTML代码,确保在离线环境下打开页面即可正常进行井字棋游戏。
添加图片注释,不超过 140 字(可选)
这次它生成的比上次还快 而且还是一次成功,确实有点东西啊
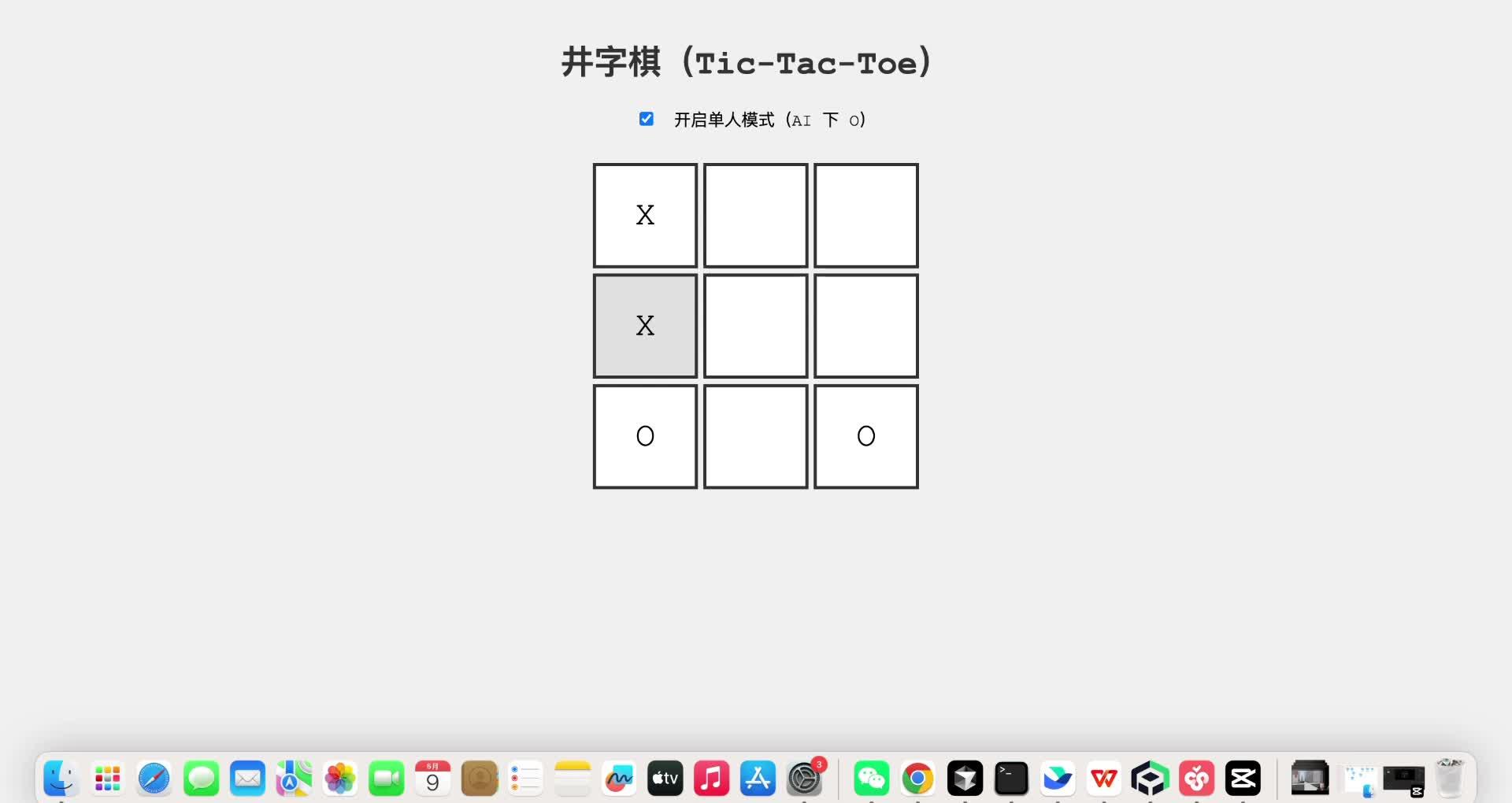
在飞机上,我又被这玩意儿硬控了5分钟,虽然跟AI写的程序下棋其实挺无聊的,但是自己做的小游戏呀,就跟吃自己做的饭一样香~
说实话,跑本地模型,电脑掉电是真快(跑一个任务,掉4%左右的电)
而且我抱着它,感觉大腿越来越烫了,热量散我身上了...
这次真的,让我亲身感受到了,什么叫算力消耗
那有没有办法减少掉电速度呢?
有,让它不要思考就行了
Qwen3是国内首个混合推理模型,可以在一个模型中,无缝切换推理模式和非推理模式。 官方给出的数据显示,它如果不思考,可节约600%的算力!那相应的电耗也就少了。
看完下面这个Case,你应该就会明白,它是如何无缝切换的了
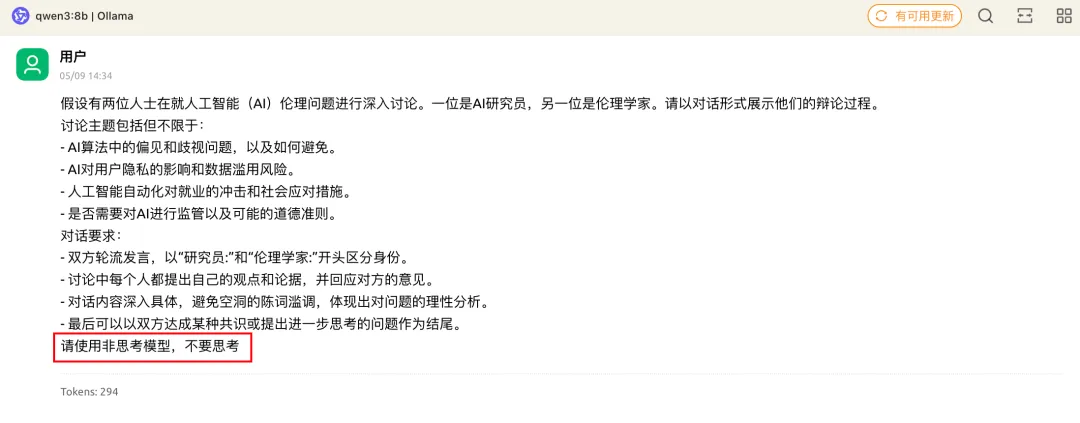
可以看到我在最后加上了一句话:"请使用非推理模式,不要思考"
在下图右边的回复中,它确实非常听话,没有思考 而是直接给出了一段“左右互搏”的回答,最后还自己跟自己达成一致了😂
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
同时也反应出Qwen3的角色扮演能力还是相当不错的。
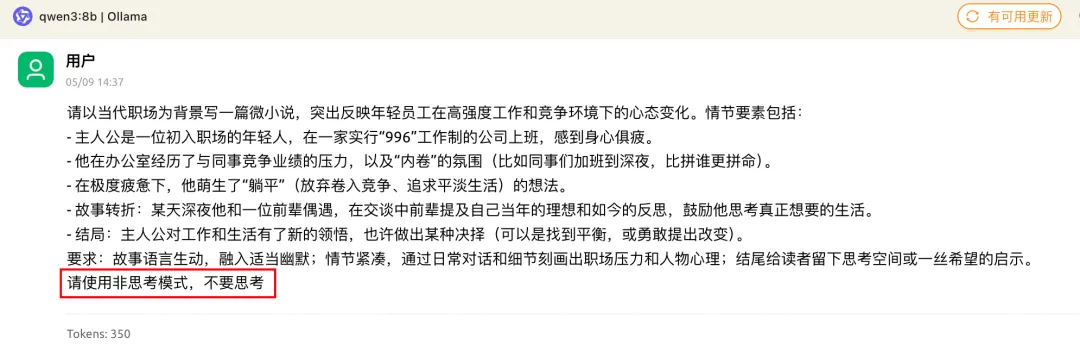
再来看看它的写作能力 下面这个Case,我同样让它不要思考,直接回答。
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
坐在飞机上,我逐字读完了Qwen3:8b写的这篇微小说,看到最后的一瞬间,居然起了一层鸡皮疙瘩。
这特么写得不就是当年的我吗?
跟我以前某段时间的心里活动一毛一样。 所以,我在23年底测底辞职,走上了AI自媒体这条不归路,当起了数字游民。虽然现在也很忙,但是我很开心能够做自己喜欢的事情,做自己时间的主人。
也许今天的我,也快要成为能够帮助别人“躺平“的前辈了吧。
最后,我测试了生成个人简历网页的Case(同样让它不要思考) 这个推理和非推理无缝切换的体验真挺丝滑的,我最烦之前的推理模型在一些非常简单的问题上都要吭哧吭哧推理半天...
而你除了换模型外 没有任何办法。
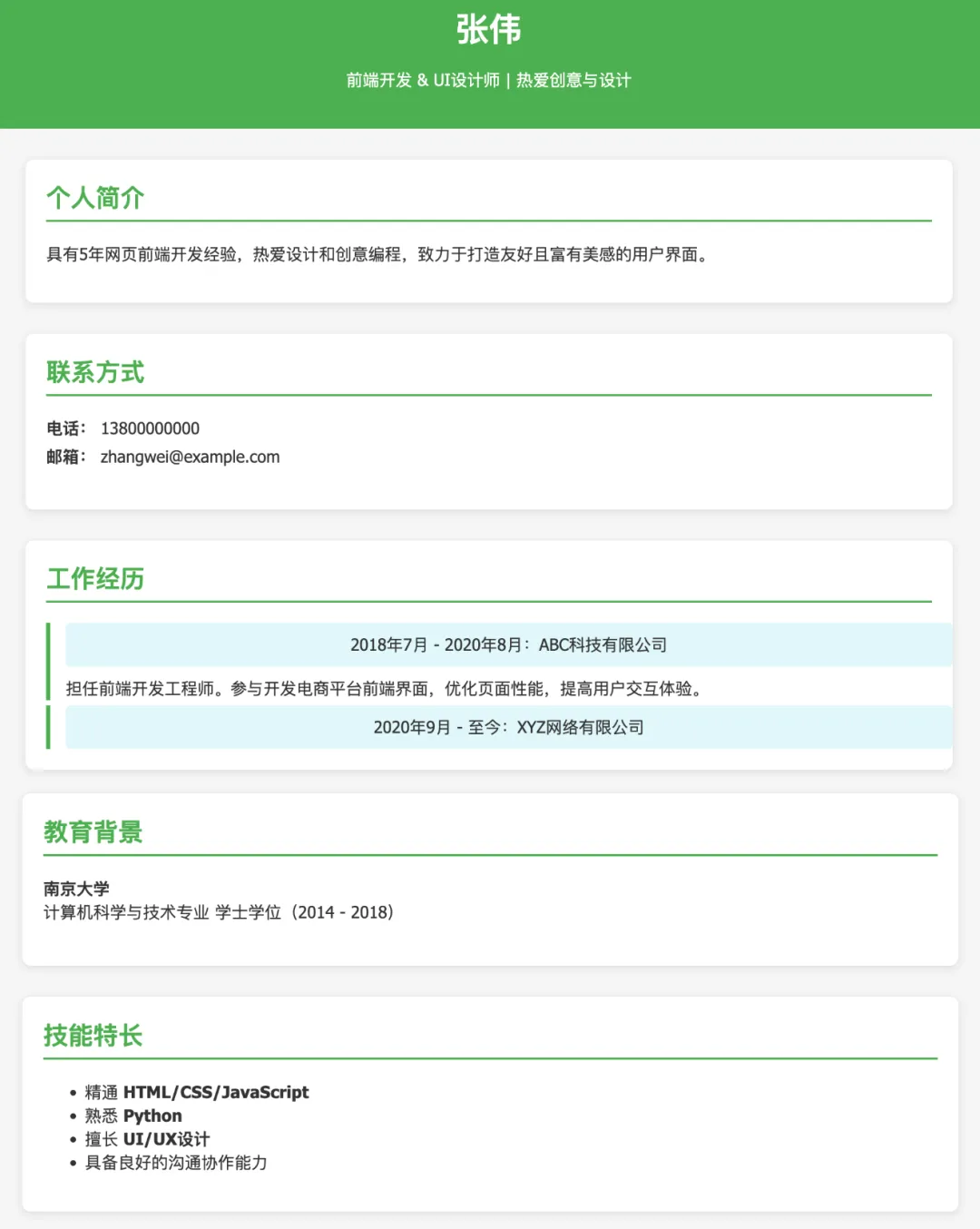
生成的页面还算不错,比较简约,简历确实也不需要太花哨
最后一个Case,我测了@沃垠AI 用Qwen3-235B跑出来的一个动画特效,虽然也是一个有点无聊的功能,但我一直玩了好久。
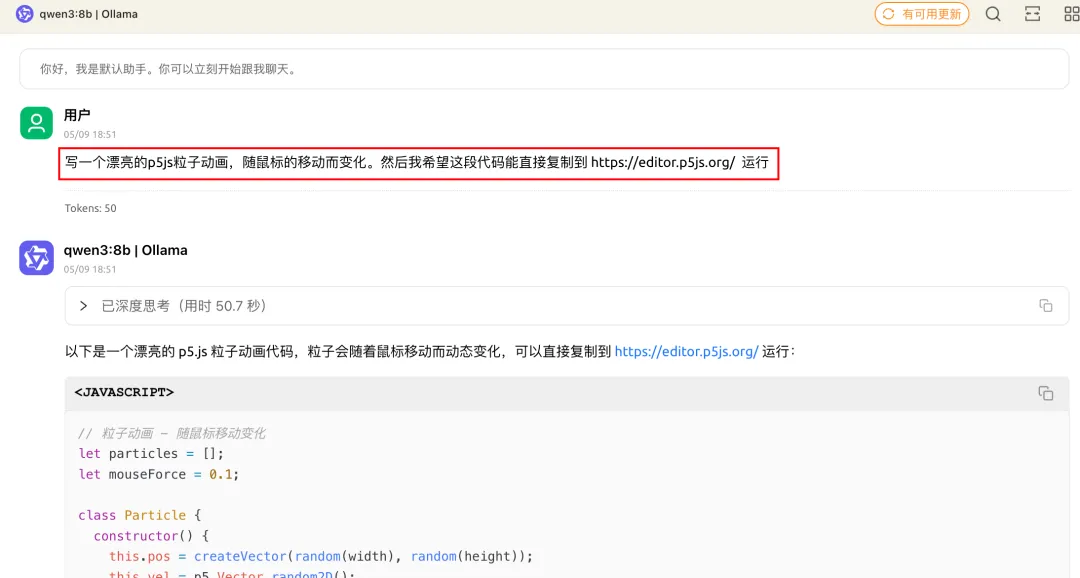
添加图片注释,不超过 140 字(可选)
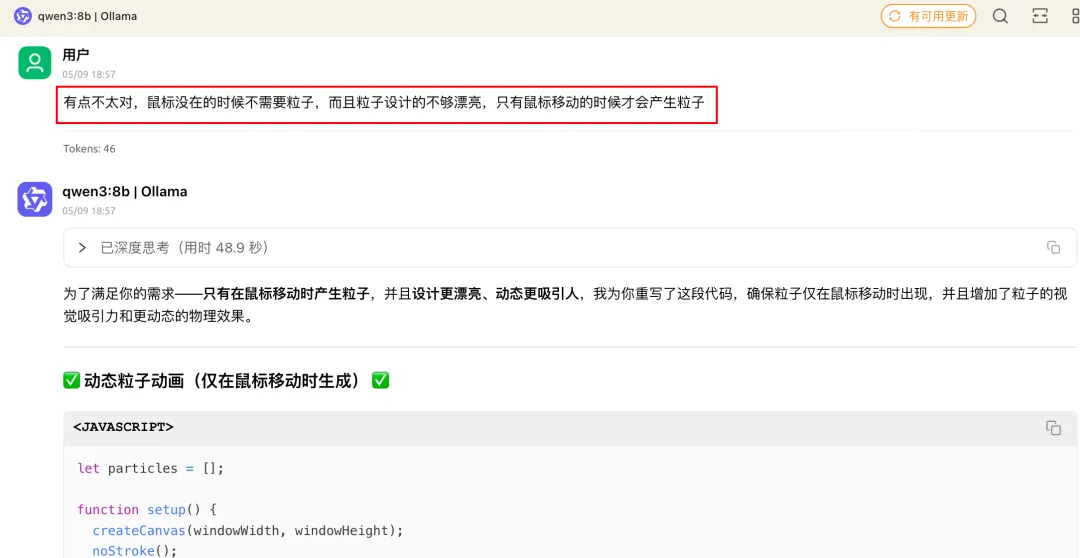
这个特效,我是万万没想到,只通过两轮提问就搞定了
动画特效
当然,这个效果比起Qwen3-235B跑出来的还是差了一些,但这是Qwen3:8B跑出来的哎,而且还可以继续让它优化。
测到这里,我的电脑也快关机了。
我想说,Qwen3不仅在海外杀疯了,今天也在我本地电脑里面杀疯了。
发挥太稳定了,而且指令遵循度超高,非常听话。
一个8B参数量的模型能做到这样,完全超乎我的想象。
在飞机上每跑完一个Case 内心都是:卧槽,卧槽
这确实跟我以前使用过的8B模型大不一样,可以说是质变了。
「最后」
看来阿里Qwen卷的方向是对的。
在小模型这块,Qwen3是目前无敌的存在,非常适合用来做小而美的垂类大模型。
直接让国外十万Qwen衍生模型把 Create in China 写进 README
Qwen3满血版的算力门槛砍到DeepSeek六分之一
小尺寸版,个人电脑就能跑
不只性能不错,还有普惠
Qwen,确实NB
你想用Qwen的小尺寸模型做什么呢?欢迎评论区分享~
能看到这里的都是凤毛麟角的存在!
如果觉得不错,随手点个赞、在看、转发三连吧~
如果想第一时间收到推送,也可以给我个星标⭐
谢谢你耐心看完我的文章~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









