






目录
spark streaming和structured streaming的区别
介绍
spark streaming (spark 1.6 引入 使用批处理模拟流式计算) DStream (离散流)
structured streaming (结构化流 spark2.0引入)
Structured Streaming 基于 Spark SQl 引擎, 是一个具有弹性和容错的流式处理引擎. 使用 Structure Streaming 处理流式计算的方式和使用Spark SQL计算静态数据(表中的数据)的方式是一样的。
spark streaming和structured streaming的区别
1.简化编码
spark streaming是基于rdd算子操作的。
structured streaming是基于spark sql操作的,而Spark SQL又是基于rdd算子的,因此,rdd的一些聚合操作,状态操作都通过Spark SQL封装好了。我们只需要写sql语句,需要注意的是structured streaming中的数据是无界数据,也就全表数据,每次查询都是整条时间线上的数据,不像spark streaming中的数据需要分批次,每个批次的数据都是独立状态的,在某些聚合操作时,我们还需要进行有状态的操作。
2.structured streaming的核心思想
Structured Streaming 的核心思想是:把持续不断的流式数据当做一个不断追加的表。这使得新的流式处理模型同批处理模型非常相像. 我们可以表示我们的流式计算类似于作用在静态数据表上的标准批处理查询, spark 在一个无界表上以增量查询的方式来运行。
3.关于数据的时间
spark streaming 基于 processing time将数据落入window
structured streaming是基于event time将数据落入window
基于event time的好处:对于延迟数据可以落入他本该的统计窗口中
对于一些“过分”延迟的数据,就可以丢弃了,当然通过学习我们会发现,丢弃的不是数据,而是窗口

StructuredStreaming基本概念
1.输入表
把输入数据流当做输入表(Input Table). 到达流中的每个数据项(data item)类似于被追加到输入表中的一行。
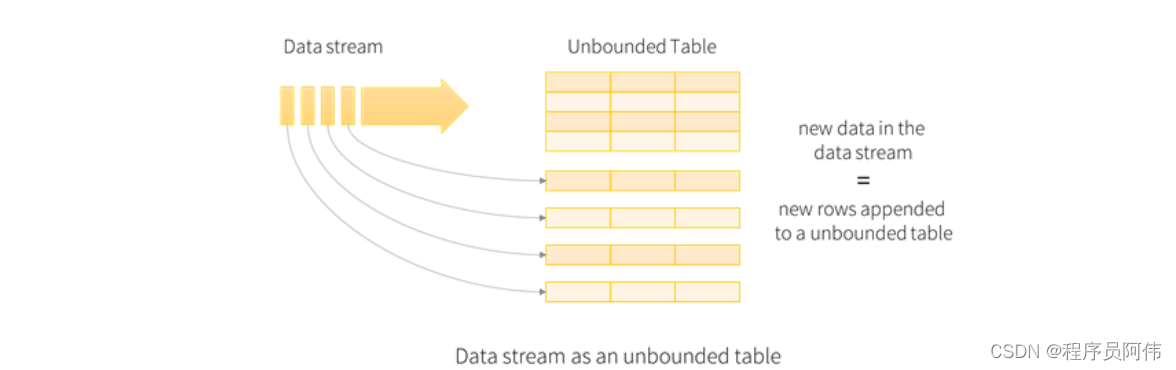
2.结果表
作用在输入表上的查询将会产生“结果表(Result Table)”. 每个触发间隔(trigger interval, 例如 1s), 新行被追加到输入表, 最终会更新结果表. 无论何时更新结果表, 我们都希望将更改的结果行写入到外部接收器(external sink)。

3.输出方式
输出(Output)定义为写到外部存储. 输出模式(outputMode)有 3 种:
-
Complete Mode 整个更新的结果表会被写入到外部存储. 存储连接器负责决定如何处理整个表的写出(类似于 spark streaming 中的有转态的转换)。
-
Append Mode 从上次触发结束开始算起, 仅仅把那些新追加到结果表中的行写到外部存储(类似于无状态的转换). 该模式仅适用于不会更改结果表中行的那些查询. (如果有聚合操作, 则必须添加 wartemark, 否则不支持此种模式)。
-
Update Mode 从上次触发结束开始算起, 仅仅在结果表中更新的行会写入到外部存储. 此模式从 2.1.1 可用. 注意, Update Mode 与 Complete Mode 的不同在于 Update Mode 仅仅输出改变的那些行. 如果查询不包括聚合操作, 则等同于 Append Mode。
使用案例
1.依赖导入
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>2.创建环境
// StructuredStreaming 支持使用SQL来处理实时流数据,数据抽象和Spark SQL一样,也是DataFrame和Dataset
// 所以这里创建StructuredStreaming执行环境就直接创建SparkSession即可
val spark: SparkSession =SparkSession.builder().master("local[*]").appName("Covid19_Data_Process").getOrCreate()
val sc:SparkContext = spark.sparkContext
sc.setLogLevel("WARN")3.连接Kafka
// 连接Kafka
val kafkaDF:DataFrame = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092")
.option("subscribe", "covid19") // 订阅主题
.load()4.取值
// 取出消息中的value,并转化成String类型
val jsonStrDS:Dataset[String] = kafkaDF.selectExpr("CAST(value AS STRING)").as[String]5.转化数据
StructuredStreaming中的数据最好是实体类型的数据,会自动将实体类的属性映射成列名
// 处理数据,将json格式的数据转换成实体类
val covidBeanDS:Dataset[CovidBean] = jsonStrDS.map( jsonStr => {
JsonUtils.jsonStrToBean(jsonStr,classOf[CovidBean])
})6.输出数据
statisticsDS.writeStream
.format("console") // 输出的目的
.outputMode("append") // 输出的模式,默认就是append
.option("truncate",false) // 表示列名过长不进行截断
.trigger(Trigger.ProcessingTime(0)) // 触发间隔,0表示尽可能快的执行
.start()
.awaitTermination()7.数据输出到外部存储
通常我们需要将计算的结果输出到其他存储位置,我们需要继承使用 ForeachWriter[Row]来自定义输出操作,这里就举个输出到mysql的例子。
abstract class BaseJdbcSink(sql:String) extends ForeachWriter[Row] {
// 开启连接
override def open(partitionId: Long, epochId: Long): Boolean = {
true
}
// 处理数据,将数据写入mysql
override def process(value: Row): Unit = {
realProcess(sql,value)
}
def realProcess(sql:String,value: Row)
// 关闭连接
override def close(errorOrNull: Throwable): Unit = {}
} val sink1 = new BaseJdbcSink(sql1) {
override def realProcess(sql: String, value: Row): Unit = {
println("正在将result1结果写入数据到mysql数据库")
var conn = JDBCUtils.getConnection
val params = ListBuffer[Any]()
params.append(value.getAs[String]("datetime"))
params.append(value.getAs[Long]("currentConfirmedCount"))
params.append(value.getAs[Long]("confirmedCount"))
params.append(value.getAs[Long]("suspectedCount"))
params.append(value.getAs[Long]("curedCount"))
params.append(value.getAs[Long]("deadCount"))
JDBCUtils.executeUpdate(conn, sql, params)
}
}
result1.writeStream
.foreach(sink1)
.outputMode("complete") // 输出的模式,默认就是append
.option("truncate",false) // 表示列名过长不进行截断
.trigger(Trigger.ProcessingTime(0)) // 触发间隔,0表示尽可能快的执行
.start()
.awaitTermination()















 1030
1030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









