




 本文介绍了Disruptor框架中如何解决伪共享问题以提高性能,包括通过填充字段来避免不必要的缓存同步。此外,文章详细讲解了如何实现消费者线程的优雅停止,包括外部通知机制和确保所有事件被消费完的shutdown方法。最后,讨论了将消费者序列集合由ArrayList优化为数组以提升性能。
本文介绍了Disruptor框架中如何解决伪共享问题以提高性能,包括通过填充字段来避免不必要的缓存同步。此外,文章详细讲解了如何实现消费者线程的优雅停止,包括外部通知机制和确保所有事件被消费完的shutdown方法。最后,讨论了将消费者序列集合由ArrayList优化为数组以提升性能。
🚀 优质资源分享 🚀
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| 💛Python量化交易实战💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
MyDisruptor V6版本介绍
在v5版本的MyDisruptor实现DSL风格的API后。按照计划,v6版本的MyDisruptor作为最后一个版本,需要对MyDisruptor进行最终的一些细节优化。
v6版本一共做了三处优化:
- 解决伪共享问题
- 支持消费者线程优雅停止
- 生产者序列器中维护消费者序列集合的数据结构由ArrayList优化为数组Array类型(减少ArrayList在get操作时额外的rangeCheck检查)
由于该文属于系列博客的一部分,需要先对之前的博客内容有所了解才能更好地理解本篇博客
- v1版本博客:从零开始实现lmax-Disruptor队列(一)RingBuffer与单生产者、单消费者工作原理解析
- v2版本博客:从零开始实现lmax-Disruptor队列(二)多消费者、消费者组间消费依赖原理解析
- v3版本博客:从零开始实现lmax-Disruptor队列(三)多线程消费者WorkerPool原理解析
- v4版本博客:从零开始实现lmax-Disruptor队列(四)多线程生产者MultiProducerSequencer原理解析
- v5版本博客:从零开始实现lmax-Disruptor队列(五)Disruptor DSL风格API原理解析
伪共享问题(FalseSharing)原理详解
在第一篇博客中我们就已经介绍过伪共享问题了,这里复制原博客内容如下:
现代的CPU都是多核的,每个核心都拥有独立的高速缓存。高速缓存由固定大小的缓存行组成(通常为32个字节或64个字节)。CPU以缓存行作为最小单位读写,且一个缓存行通常会被多个变量占据(例如32位的引用指针占4字节,64位的引用指针占8个字节)。
这样的设计导致了一个问题:即使缓存行上的变量是无关联的(比如不属于同一个对象),但只要缓存行上的某一个共享变量发生了变化,则整个缓存行都会进行缓存一致性的同步。
而CPU间缓存一致性的同步是有一定性能损耗的,能避免则尽量避免。这就是所谓的“伪共享”问题。
disruptor通过对队列中一些关键变量进行了缓存行的填充,避免其因为不相干的变量读写而无谓的刷新缓存,解决了伪共享的问题。
举例展示伪共享问题对性能的影响
- 假设存在一个Point对象,其中有两个volatile修饰的long类型字段,x和y。
有两个线程并发的访问一个Point对象,但其中一个线程1只读写x字段,而另一个线程2只读写y字段。
存在伪共享问题的demo
public class Point {
public volatile int x;
public volatile int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
}
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class FalseSharingDemo {
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 2, 60L, TimeUnit.SECONDS, new SynchronousQueue<>());
CountDownLatch countDownLatch = new CountDownLatch(2);
Point point = new Point(1,2);
long start = System.currentTimeMillis();
executor.execute(()->{
// 线程1 x自增1亿次
for(int i=0; i<100000000; i++){
point.x++;
}
countDownLatch.countDown();
});
executor.execute(()->{
// 线程2 y自增1亿次
for(int i=0; i<100000000; i++){
point.y++;
}
countDownLatch.countDown();
});
countDownLatch.await();
long end = System.currentTimeMillis();
System.out.println("testNormal 耗时=" + (end-start));
executor.shutdown();
}
}
- 两个线程各自独立访问两个不同的数据,但x和y是一个对象的两个相邻属性因此在内存中是连续分布的,大概率读写时会被放到同一个高速缓存行中,
由于volatile变量修饰的原因,线程1对x线程的修改会对当前缓存行进行触发高速缓存间同步进行强一致地写,使得线程2中x、y字段所在CPU的高速缓存行失效,被迫重新读取主存中最新的数据。
但实际上线程1读写x和线程2读写y是完全不相关的,线程1与线程2在实际业务中并不需要共享同一片内存空间,因此强一致的高速缓存行同步完全是画蛇添足,只会降低性能。
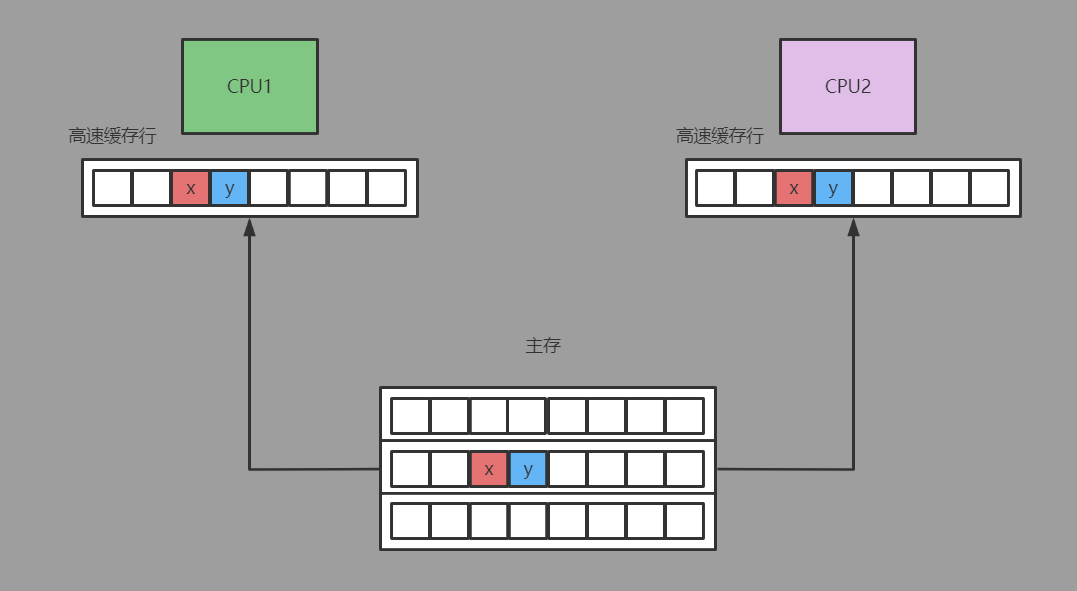
- 需要注意的是,伪共享问题绝大多数情况下是出现在不同对象之间的,例如线程1会访问对象A中的volatile变量aaa,而线程2会访问另一个对象B中的volatile变量bbb。
但恰好对象A的aaa属性和对象B的bbb属性被加载到同一个缓存行中,这便是实际上最常见的伪共享场景。
因此上述同一个Point对象中x、y两个属性互相干扰的例子其实并不是很恰当,只是为了方便演示效果才拿同一个对象里的不同字段的伪共享场景举例。 - 解决伪共享问题的方法是做缓存行的填充,简单来说就是通过在需要避免伪共享的volatile字段集合前后填充无用的padding字段,让编译器在编排变量地址时保证其不会被其它线程在访问不相关的变量时所影响。
无论怎样分配变量地内存地址,被填充字段包裹的volatile变量都不会被其它无关的变量访问而被迫进行强一致地高速缓存同步。

通过填充无用字段解决伪共享问题demo
public class PointNoFalseSharing {
private long lp1, lp2, lp3, lp4, lp5, lp6, lp7;
public volatile long x;
private long rp1, rp2, rp3, rp4, rp5, rp6, rp7;
public volatile long y;
public PointNoFalseSharing(int x, int y) {
this.x = x;
this.y = y;
}
}
public class NoFalseSharingDemo {
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 2, 60L, TimeUnit.SECONDS, new SynchronousQueue<>());
CountDownLatch countDownLatch = new CountDownLatch(2);
PointNoFalseSharing point = new PointNoFalseSharing(1,2);
long start = System.currentTimeMillis();
executor.execute(()->{
// 线程1 x自增1亿次
for(int i=0; i<100000000; i++){
point.x++;
}
countDownLatch.countDown();
});
executor.execute(()->{
// 线程2 y自增1亿次
for(int i=0; i<100000000; i++){
point.y++;
}
countDownLatch.countDown();
});
countDownLatch.await();
long end = System.currentTimeMillis();
System.out.println("testNoFalseSharing 耗时=" + (end-start));
executor.shutdown();
}
}
- 感兴趣的读者可以把上述存在伪共享问题和解决了伪共享问题的demo分别执行下看看。
在我的机器上,两个线程在对x、y分别自增1亿次的场景下,存在伪共享问题的示例代码FalseSharingDemo比解决了伪共享问题示例代码NoFalseSharingDemo要慢3到5倍。
disruptor中伪共享问题的解决方式
- disruptor中对三个关键组件的全部或部分属性进行了缓存行的填充,分别是Sequence、RingBuffer和SingleProducerSequencer。
这三个组件有两大特征:只会被单个线程写、会被大量其它线程频繁的读,令它们避免出现伪共享问题在高并发场景下对性能有很大提升。 - MySingleProducerSequencer中很多属性,但只有nextValue和cachedConsumerSequenceValue被填充字段包裹起来,其主要原因是只有这两个字段会被生产者频繁的读写。
MySequence解决伪共享实现
/**
* 序列号对象(仿Disruptor.Sequence)
*
* 由于需要被生产者、消费者线程同时访问,因此内部是一个volatile修饰的long值
* */
public class MySequence {
/**
* 解决伪共享 左半部分填充
* */
private long lp1, lp2, lp3, lp4, lp5, lp6, lp7;
/**
* 序列起始值默认为-1,保证下一个序列恰好是0(即第一个合法的序列号)
* */
private volatile long value = -1;
/**
* 解决伪共享 右半部分填充
* */
private long rp1, rp2, rp3, rp4, rp5, rp6, rp7;
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
static {
try {
UNSAF 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5095
5095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











