






本文能解决的疑惑:
- idea在debug时偷偷调用toString方法,在HashMap追源码时产生的疑惑
- HashMap的entrySet()和keySet()方法真的创建了一个存满数据的set对象吗?
- 内部类:EntrySet类没有构造器,那它是怎么初始化的呢?
- 为什么集合框架中一定要利用好迭代器iterator()来获取入口?
- entrySet().size()获取的值是该set的实际大小吗?
- …
entrySet()和keySet()详解
- entrySet()和keySet()方法都是返回一个set对象,并且在debug时也能看到set的值和size;但是源码中并没有利用构造器对其初始化。
- 在此文中以entrySet()举例,来阐述entrySet和keySet的生命周期
测试代码示例,并提出问题
HashMap hs = new HashMap();
hs.put("啊啊", "2");
hs.put("2", "2");
hs.put("3", "2");
hs.put("4", "2");
hs.put("5", "2");
hs.put("6", "2");
hs.put("7", "2");
hs.put("8", "2");
hs.put("9", "2");
Set entrySet = hs.entrySet();//1.获取entrySet对象
System.out.println(entrySet );//2.结果:正确输出了上面put的内容
Object[] objects = entrySet .toArray();
System.out.println(objects[3]);//3.结果:正确打印了5=2
Iterator iterator = entrySet .iterator();//4.获取迭代器
while (iterator.hasNext()){//5.迭代器遍历
Map.Entry next = (Map.Entry) iterator.next();
next.getKey();
next.getValue();
}
- 如果在idea中使用debug对
Set entrySet = hs.entrySet()打断点,你会发现即便是没有运行到第二步,debug信息栏中已然出现了该set全部的内容。 - 跟着debug一直step into进行分析,发现并没有任何一个方法对entrySet对象进行过赋值,那么hashMap对象中的内容是如何进入到entrySet中的呢?
1 debug分析
new EntrySet()
- 没有找到构造函数

- AbstractSet中只有一个空参且空函数体的方法

第一个结论:entrySet是空对象
entrySet只是new出来了,但它是一个没有内容的空对象。
2第二个问题:entrySet对象调用方法时为何有值?
既然 Set entrySet = hs.entrySet()出来的entrySet 对象是个空对象,那为何System.out.println(entrySet );
Object[] objects = entrySet .toArray();
Iterator iterator = entrySet .iterator()
对entrySet对象进行调用方法的时候却能正确的执行呢?
2 源码分析
toString方法
System.out.println(entrySet ); 显然调用的是toString方法;
- 在2.5中的源码可知entrySet对象继承于
AbstractSet类,间接实现了AbstractCollection接口 - 重写的toString()方法调用了
this.iterator()即EntrySet类的iterator()方法进行输出

iterator方法
-
我们发现HashMap中的内部类EntrySet中重写了iterator()方法,实际调用的是EntryIterator对象
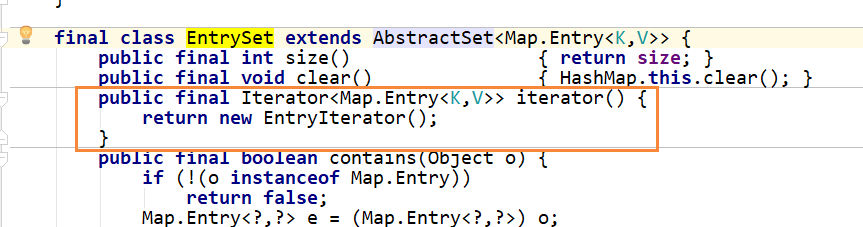
-
EntryIterator类继承于HashIterator类 :nextNode方法是HashIterator中的方法

-
跟进nextNode方法,框体内容是指针的变化的判断细节,不是本论题的重点

由此可知:
这个EntrySet类重写的iterator()方法可以使得指针正确得指向下一个节点…
toArray方法
- 测试代码中也正确输出了toArray()的结果,同样的,这个方法也是重写在其父类
AbstractCollection中的 - 同理,其底层实现还是调用了iterator(),利用HashIterator类中的nextNode()方法对指针进行下移
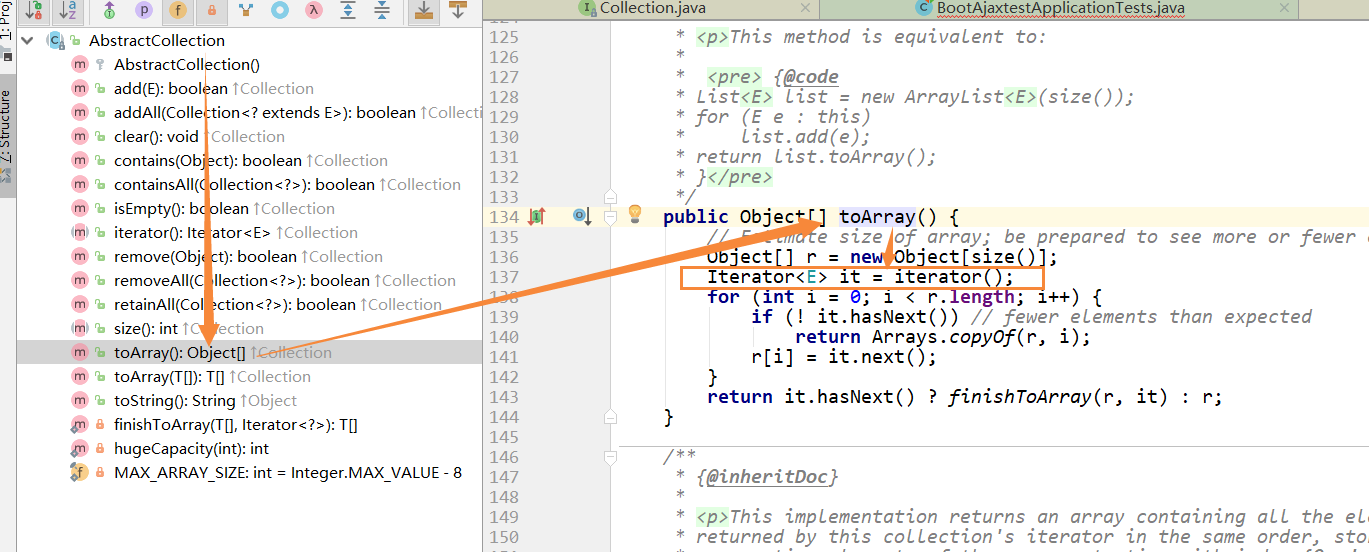
size、clear方法
这两个方法很简单,就是直接用的当前HashMap对象的属性和方法

hashMap.entrySet().size()的大小并不是真正这个entrySet对象的大小,而是调用了size属性的fake size
3小总结
- entrySet()和keySet()都是懒汉式,调用方法,new对象的时候并没有对其进行赋值,并且其size()方法也是一个虚假的size
- 而是在使用hashMap.entrySet().toString()、hashMap.entrySet(). toArray() 等方法的时候才
调用iterator()来获取迭代器 - EntrySet类和KeySet类也都没有构造器能进行初始化
- 不得不说HashMap的设计十分精巧,entrySet()表面上获取了一个set对象,实际上这个set对象是空的,几乎所有的方法都是先直接获取迭代器入口,节约内存的同时性能大幅提升
补充:putVal()方法和entrySet()无关
在翻阅资料的时候看到很多人说是putVal()方法中调用了resize()来维护了entrySet(),在看完源码之后才会发现这种说法是没有根据的。
resize()放是扩容的方法,代码中也没有出现任何的跟EntrySet相关的逻辑
补充:new HashSet();
根据以上的思路就可以知道,集合中Set底层为什么调用的是Map,你看源码中new HashSet()也是new了一个HashMap,两者逻辑可以完全复用
4关于idea在debug时的问题
- DEA在debug时,当debug到某个对象时,会调用对象的toString()方法,用来在debug界面显示对象信息。
- IDEA调用toString()方法时,即使在toString()方法中设置了断点,该断点也不会被触发,也就是说,开发者多数情况下不会知道toString()方法被调用了。
- 多数情况下调用一下toString()方法没有什么问题,但是也有例外,
比如重写了toString()方法的类,随意的调用toString()方法会导致未知的问题。本案例就是因为重写toString()方法而产生了问题















 6875
6875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









