






1.DDL建表语句结构
- 只有这几个划红线的必须选,画圈的二选一,其他都可以默认设置,也可以修改Hive对这些属性的默认配置
- 建表语法一定要按这个顺序,不可颠倒

删除表就跟SQL标准一样,DROP TABLE xxx,不过要注意是否是内部表导致数据文件也被删除
2.数据类型
2.1原生数据类型
用的比较多的是:int、double、String、timestamp、date
2.2复杂数据类型
用的比较多的是:array、map
2.3数据类型特征
- 大小写不敏感
- 复杂数据类型使用通常需要和分隔符指定语法配合使用
- 数据类型转换:如果数据类型不一致,Hive会尝试隐式转换(不一定成功,隐式转换的方向是保证精度不丢失)
2.3.1显示转换
CAST函数:
- CAST(‘100’ as INT)把这个字符串100,转为int。能成功,返回100
- CAST(‘AB’ as INT)这样就会转化失败,返回null
2.3.2隐式转换
可以从int转double,void转boolean,总之不能让精度丢失
3.查看表的属性
3.1desc formatted指令
describe formatted 库.表
或
desc formatted 库.表
3.2包含的内容
通过观察结构可以看出Hive的describe指令是通过如下图的方式进行区分的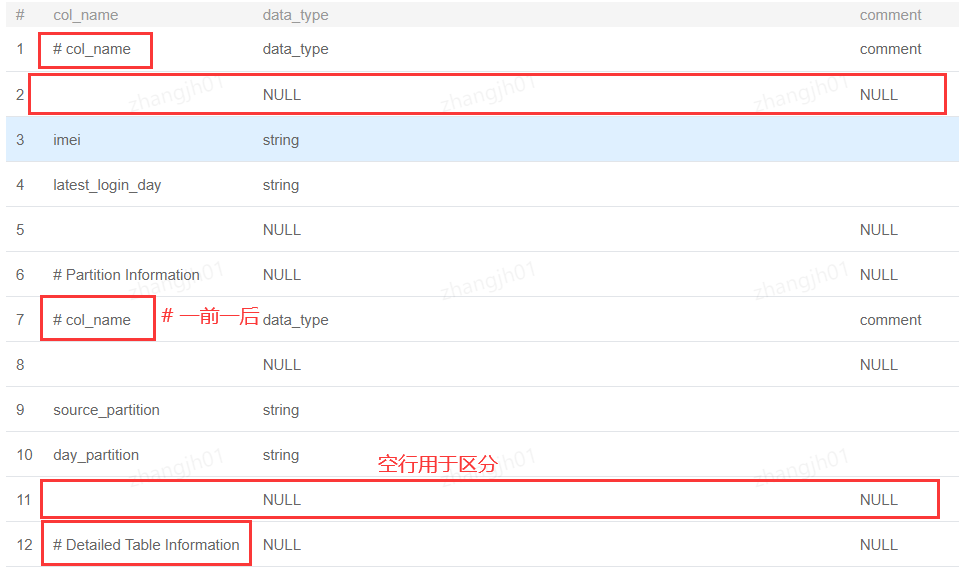
其中包含了所有的表信息,包括但不限于:列、分区分桶、owner、创建及更新时间、location
其中比较重要的几个是:
Table Type: 内部表or外部表SerDe Library: SerDe方式InputFormat和OutputFormat:通常与SerDe一致,不一致可能出现序列化、反序列化的错误location:存储在HDFS上的路径
3.3内部表、外部表
内部表:Internal Table、也叫托管表Managed Table,删除内部表会导致HDFS上对应文件也被删除
外部表:建表时指定EXTERNAL,实际生产中可以配合 指定location达到更安全的效果
3.4SerDe(见下方)
4.SerDe类
SerDe分别对应
- Serializer序列化:对象 转 字节码
- Deserializer反序列化:字节码 转 对象
对象 指:表中的行
- 序列化与反序列化必须一致,否则可能解析错误,因此DDL时直接在后面加
STORED AS xxxx,此时的InputFormat和OutputFormat则都与SerDe一致
4.1常用SerDe
一般来说最常用的就是ORC和默认的LazySimpleSerDe
4.1.1LazySimpleSerDe处理文本文档
这个SerDe类主要是用于处理text文本文件,我们可以通过如下ddl案例看出,我们可以在文本文档中通过符号来界定元素

4.1.2ORC列式存储
列存储,列式存储比起传统的行式存储更适合批量OLAP查询
当我们建表时使用:
CREATE TABLE IF NOT EXISTS xxxx(
xxxx
)
STORED AS ORC;
那么就可以通过desc formatted xx表看到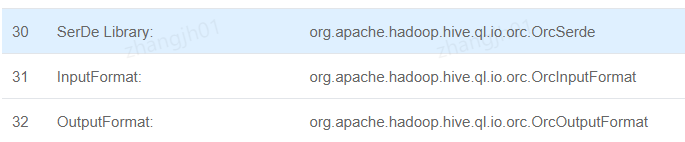
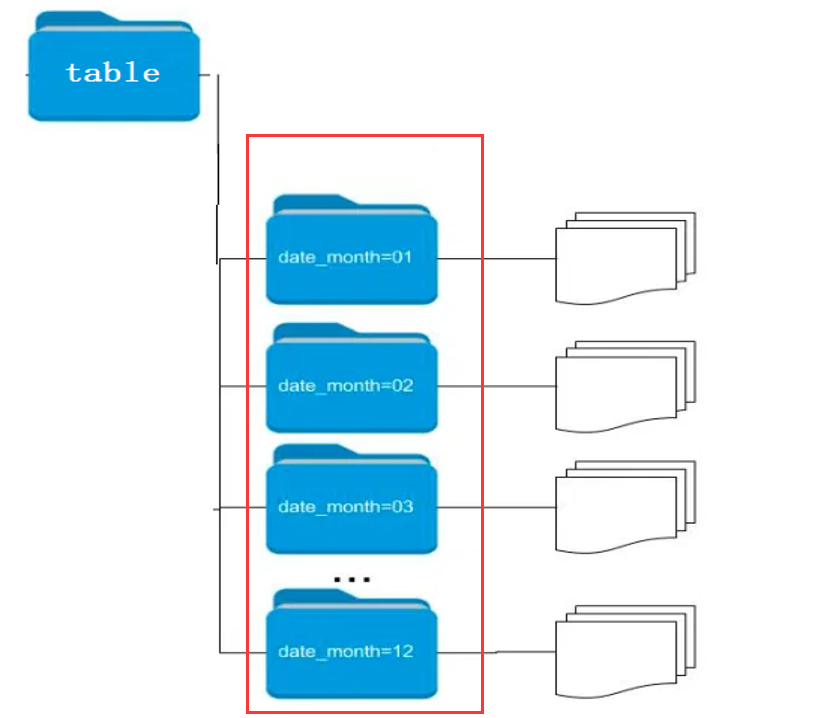
5.分区表
- 分区字段不能是表中已有字段(字段名必须区分开)
- SELECT时,分区字段也会显示在结果中(在最后的中列)

当我们对已经分区的表(如上方)加载数据时(加载数据可以通过insert、load两种方式),必须指定“数据加载到哪个分区”,否则无法加载数据
5.1静态分区
5.1.1 load方式
load data [local] inpath ‘路径’ into 表名 partition( partition1 = ‘分区值’, partition2 = ‘分区值’)
- 用load方式加载数据,一定是要把分区partition写死的,因为load无法动态获取数据的字段值
- []中的local参数用于区分是本地 or HDFS上的文件
5.2动态分区
- insert + select语句(也可以通过with建立内存表)
5.2.1允许动态分区加载
#是否开启动态分区功能
set hive.exec.dynamic.partition=true;
#指定动态分区模式,分为nonstick非严格模式和strict严格模式。
#strict严格模式要求至少有一个分区为静态分区。
set hive.exec.dynamic.partition.mode=nonstrict;
5.2.2操作示例
- 查询出来的字段数 必须多于 目标表
- 多出来的字段无关名字,直接按建表时的分区顺序来决定分区

5.3静动结合
这是我在工作中遇到的一个场景:
-
ios表、android表都是按day分区的,我们把其中的某两个字段加载到一个新表中
-
为了防止同一day的数据ios和android互相覆盖(基于业务特性原因,在5.3.1中详细说明),建表时额外对source进行分区
-
PARTITIONED BY ( source_partition STRING, day_partition STRING) -
加载数据时,source_partition要么选ios要么选android,那么就可以直接写死,而day_partition仍然动态分区
set hive.mapred.mode=nonstrict; --允许全分区字段动态,这里写strict也没事 set hive.exec.dynamic.partition=true; --动态插入分区表 WITH android as( --内存表中有两个字段 SELECT aaaaaa,day FROM .... ) --OVERWRITE覆盖原有文件,保证中途传的正常。 --按source和day分区 INSERT OVERWRITE TABLE xxx PARTITION(source_partition = 'android', day_partition) SELECT aaaaa, day , day FROM android --多查一遍day字段,会自动映射(因为只有一个动态分区了)
5.3.1 INSERT INTO和OVERWRITE
insert into:在原文件上追加写insert overwrite:先删除原文件,再新建文件
- 为了防止新表的数据出现重复(上一次传到一半宕机了,如果用insert into则会导致重复),因此不能用insert into
- 但是用insert overwrite 会导致同一day的ios和android数据互相覆盖,因此需要对source进行额外分区,防止覆盖数据
5.4分区的优点
当SELECT … WHERE 分区字段 = xxxx时,可以避免全表扫描
同时像5.3.1对于分区的用法也可以实现业务上的一些幂等操作
6.分桶表
这个用的没有分区表多,因为分区表已经能满足绝大部分场景了。
当且仅当每个分区的数据量都还是很大(十亿级别)、同时也能按逻辑再细划分(如:按省分区,按市分桶)
6.1与分区表的区别
- 分区不会把文件拆分,而分桶会
- 分区字段不能是列字段,而分桶字段必须是列字段
6.2分桶的原理
经典的hash取模算法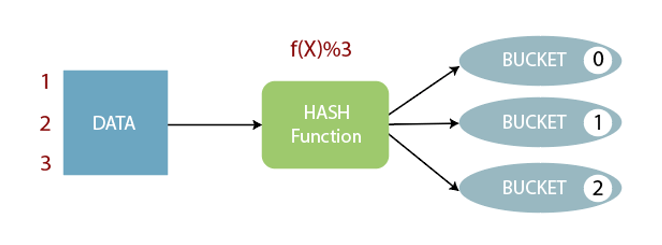
6.3分桶的优点
- 提升查询速度,避免全表扫描
- JOIN时提高MR效率,减少笛卡尔积数量(必须是针对JOIN ON的条件字段进行分桶)
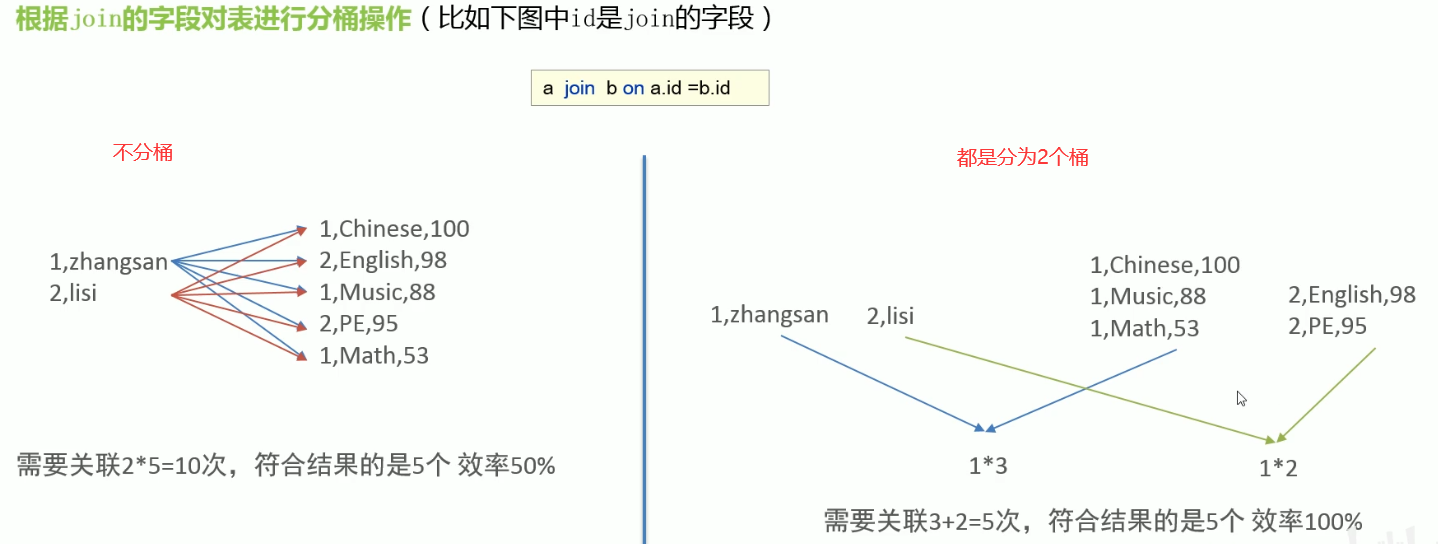
- 分桶表数据进行高效抽样


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









