







 本文详细介绍了自顶向下的语法分析方法,包括最左推导和最右推导,以及不确定和确定的分析策略。重点讨论了LL(1)分析方法,解释了回溯的判别条件和左递归文法的消除。同时,提到了预测分析表的构造以及非递归预测分析法的工作原理。
本文详细介绍了自顶向下的语法分析方法,包括最左推导和最右推导,以及不确定和确定的分析策略。重点讨论了LL(1)分析方法,解释了回溯的判别条件和左递归文法的消除。同时,提到了预测分析表的构造以及非递归预测分析法的工作原理。
目录
自顶向下的语法分析
4.1 语法分析器的功能
1.功能:以词法分析器生成的单词符号序列作为输入,在分析过程中验证这个单词符号序列是否是该程序设计语言的文法的一个句子。
2.语法分析方法的种类:自顶向下和自底向上。
3.自顶向下的语法分析
1)定义:从顶部(树根)建立语法分析树,构造一个最左推导,面对当前输入的单词符号和当前被替换的非终结符,选择这个非终结符的某个产生式规则进行替换(替换哪个非终结符以及用该非终结符的哪个产生式进行替换)。
2)分类:递归下降的预测分析法(递归下降预测法)、非递归的预测分析法(非递归预测法)(LL(1)分析法)。
3)说明:若文法是二义的,则递归下降法和非递归预测法通常均可回溯。
4.1.1 最左推导
在最左推导中,总是选择每个句型的最左非终结符进行替换

4.1.2 最右推导
在最右推导中,总是选择每个句型的最右非终结符进行替换

自底向上采用最左规约,最右推导
自顶向下采用最左推导,最右规约
最左推导和最右推导具有唯一性
4.2 不确定的自顶向下的分析方法
- 基本思想:对给定的单词符号串w,从文法的开始符号出发,试图构造一个最左推导,或自顶向下的为w建立一棵语法分析树。若成功的为w构造一个相应的推到序列或一棵语法分析树,则w为相应文法的合法句子,否则w不是文法句子。
- 本质:穷举试探,反复使用不同规则,寻求匹配输入串的过程。
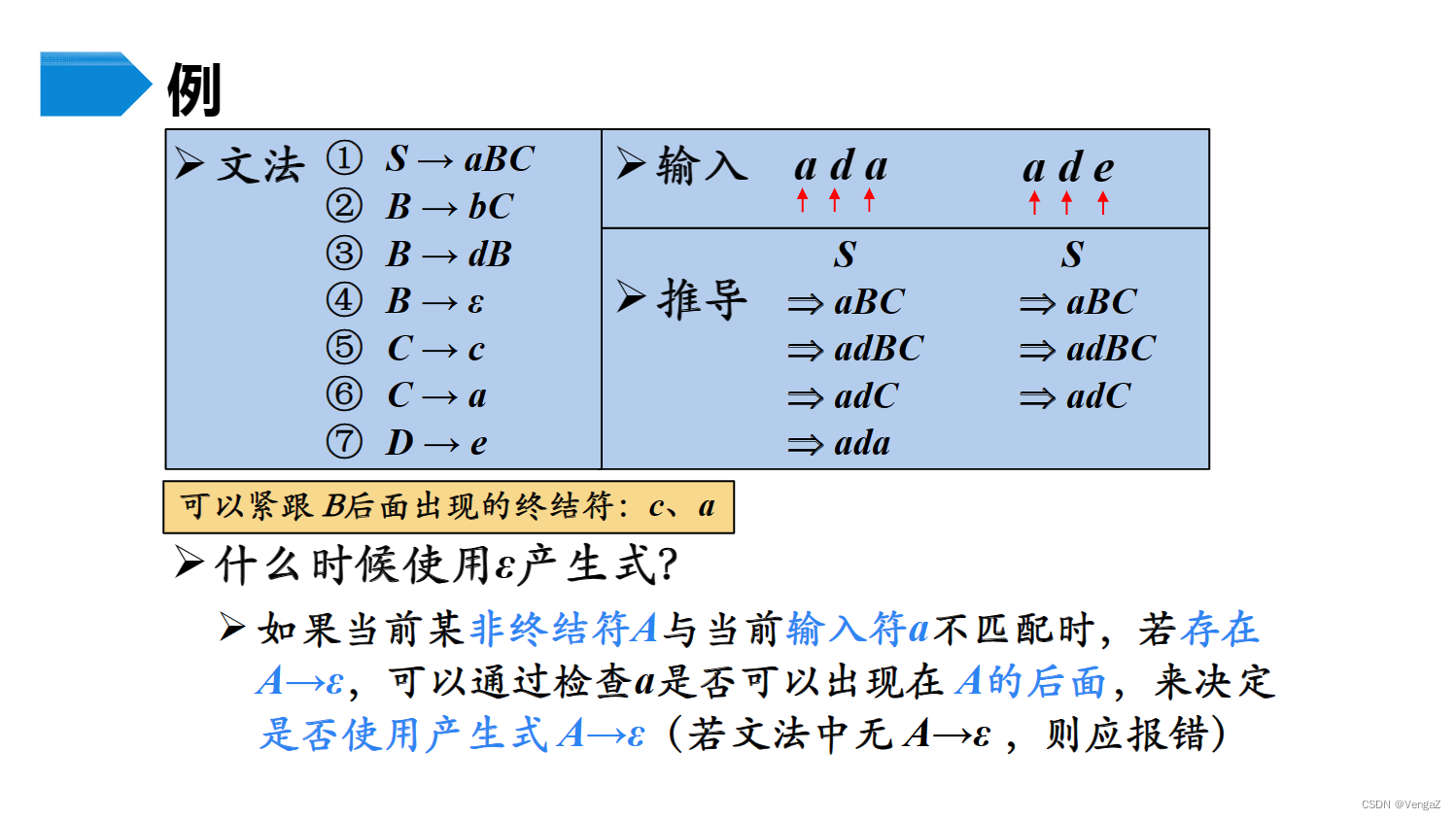
- 具体过程:在每一步推导中,面对替换的非终结符A和从左到右读输入串读到的单词符号a,若A的产生式规则(除了A→ε)A→α1|α2|…αn中,只有αi(1≤i≤n)能推导出的第一个终结符号是a,则可选择A→αi构造最左推导。若A的产生式规则(除了A→ε)中,推导的首个符号集合不含a,则选择A→ε进行推导。其中,a称为向前看符号。
- 特点:效率低,回溯代价高,实际过程通常不用。
4.3 预测分析(确定的自顶向下的分析方法)
- 预测分析不需要回溯,是递归下降分析技术的一个特例
4.4 LL(1)分析方法(如何判断没懂)
4.4.0 文法转换
-
问题:
-
同一非终结符的多个候选是存在共同前缀,导致回溯现象

-
左递归文法会使递归下降分析器陷入无限循环
4.4.1 回溯的判别条件与LL(1)文法
- First集:设G[Z]=(VN,VT,P,Z),α∈(VN∪VT),符号串α的首符号集合的定义为:
First(α)={a|α ⇒ a…且a∈VT}
若α ⇒* ε,则规定ε∈First(α)。 - Follow集:设G[Z]=(VN,VT,P,Z),A∈VN,非终结符号A的后继符号集合的定义为:
Follow(A)={a|Z ⇒* …Aa…且a∈VT}
若Z ⇒* …A,则规定#∈First(A)。#为结束符。 - 回溯的判断:对一个上下文无关文法G[Z]=(VN,VT,P,Z),对某个产生式规则A→α1|α2|…αn,若存在a∈VT,使得a∈First(αi)∩First(αj)(1≤i,j≤n且i≠j)或a∈First(αi)∩Follow(A)(1≤i≤n,A ⇒* ε)或αi ⇒* ε且αj ⇒* ε(1≤i,j≤n且i≠j),则对应于文法G的自顶向下分析需要回溯。
- LL(1)文法定义
1)文法不含左递归。
2)对某个非终结符A,若其对应的产生式规则为A→α1|α2|…αn,则First(αi)∩First(αj)=Ø(1≤i,j≤n且i≠j)。
3)对文法中的每个非终结符A,若A ⇒* ε,则First(αi)∩Follow(A)=Ø(1≤i≤n)。

4.4.2 左递归文法的改造(重点:消除左递归,算法)
-
左递归缺点:容易产生死循环
-
消除直接左递归
若某个文法中非终结符A的产生式规则是直接左递归规则:A→Aα|β,其中α,β∈(VN∪VT)*。若β不以A打头,则将A的产生式规则改写为:A→βA’,A’→αA’|ε。A’是新增加的非中介符号。

推广:若A的全部产生式规则为:A→Aα1| Aα2|…|Aαm|β1|β2|…|βn,其中βi(1≤i≤n)不以A开头,且αi(1≤i≤m)不等于ε,则A的产生式规则改写为:A→β1A’|β2A’|…|βnA’, A’→α1A’|α2A’|…αmA’|ε。


eg:设有文法G[Z]:
E→E+T|E-T|T
T→TF|T/F|F
F→(E)|i
消除非终结符E,T的直接左递归后,文法G[Z’]改写为:
E→TE’
E’→+TE’|-TE’|ε
T→FT’
T’→FT’|/FT’|ε
F→(E)|i
- 消除间接左递归
1)对文法G的非终结符号按任一种顺序排列成A1,A2,…,An。
2)依次对各非终结符号对应的产生式进行左递归的消除:
for(j=1;j<=n;j++)
for(k=1;k<=j-1;k++){
i)把每个形如Aj→Akα的规则改写为Aj→δ1α|δ2α|…|δmα。其中Ak→δ1|δ2|…|δm是关于当前Ak的产生式规则;
ii)消除关于产生式规则Aj的直接左递归;
}
3)进一步化简消除左递归之后的新文法,删去多余的产生式规则。
eg:设有文法G[S]:
S→Sa|Tbc|Td
T→Se|gh
将非终结符号排成顺序为S,T
消除产生式S左递归:
S→(Tbc|Td)S1
S1→aS1|ε
对T→Se|gh,将S代入展开得:
T→T(bc|d)S1e|gh
消除产生式T左递归:
T→ghT1
T1→(bc|d)S1eT1|ε

-
回溯的消除
1)提取左因子。
若有A→αβ1|αβ2|…|αβ1|γ,其中γ不是以α开头的候选式,则A的产生式规则可替换为A→αA‘|γ,A’→β1|β2|…|βn。A’是一个新的非终结符号。


2)消除左递归。
S_文法

后继符号集(FOLLOW)



可选集(SELECT)

产生式右部第一个非终结符的FIRST集的终结符(第一个是非终结符);或者是第一个终结符本身(第一个是终结符的情况);或者是空的话,则是产生式左部的FOLLOW集
相同左部SELECT集互不相交
预测分析表
q_文法(较S文法功能更加强大)

串首终结符集(FIRST)


a都是非终结符,并且每个都能推出空


如果Y1能推导出空,则将Y2的First集加入X的first集中(相当于y1是空,串首是y2…)
若yi都能推出空,则将空加入x的first集
如下:

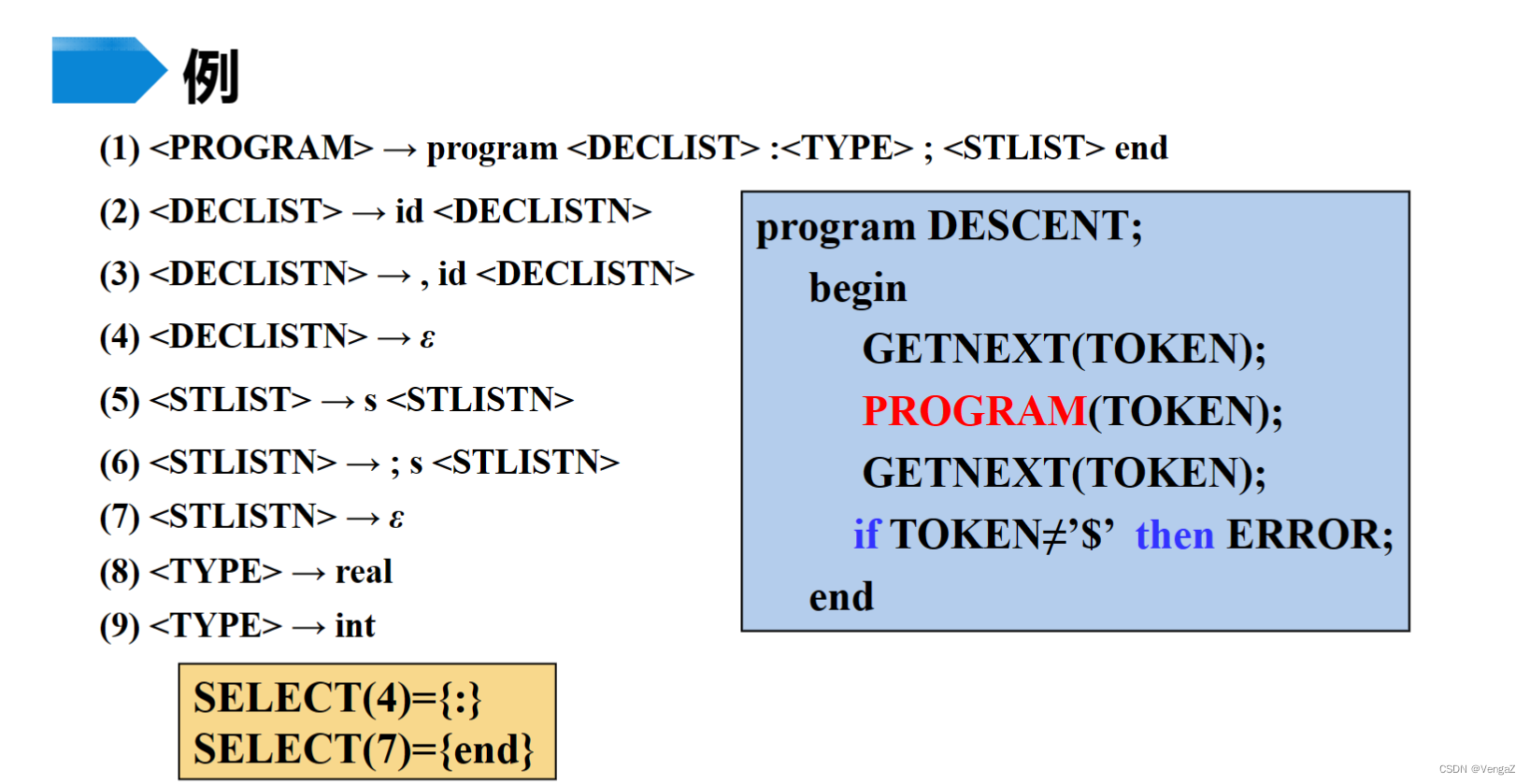
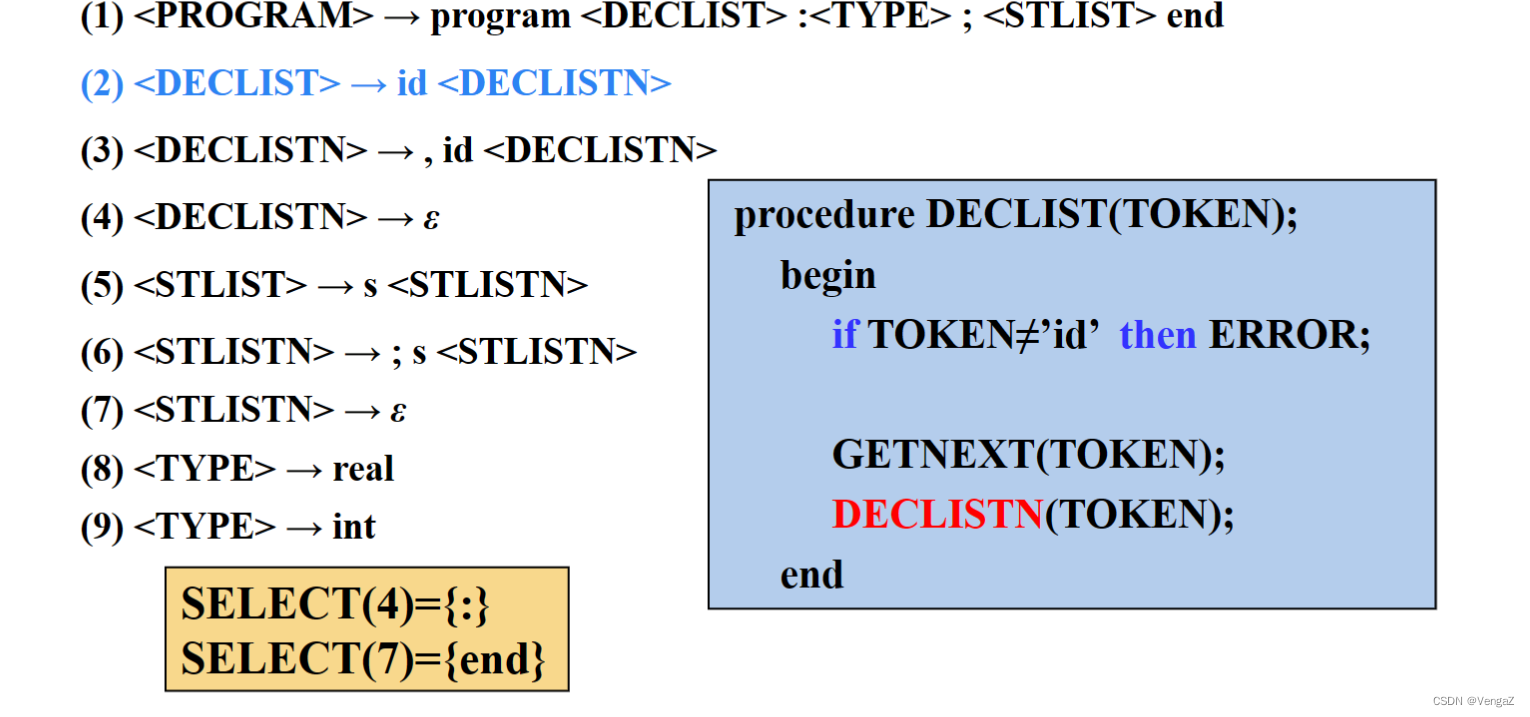
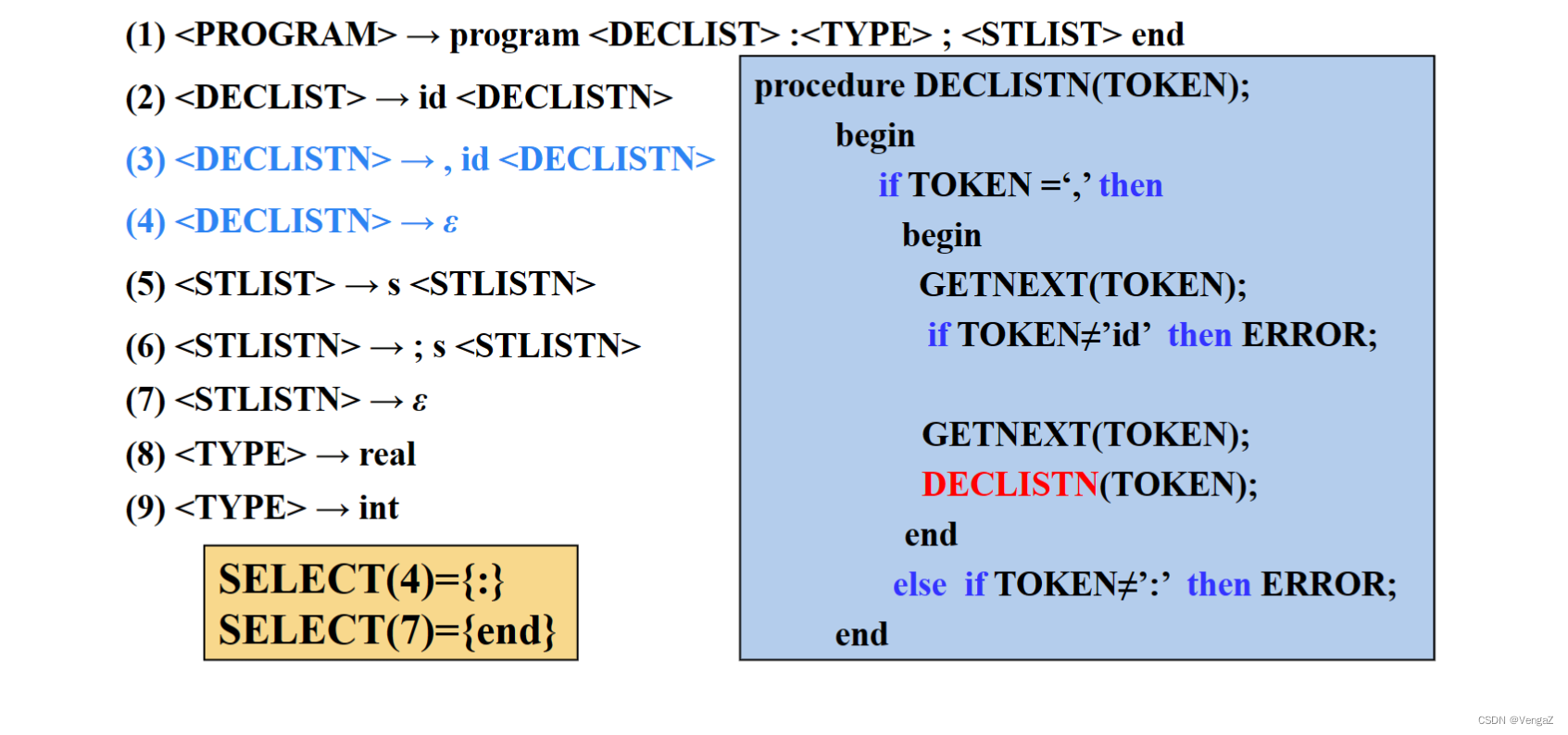
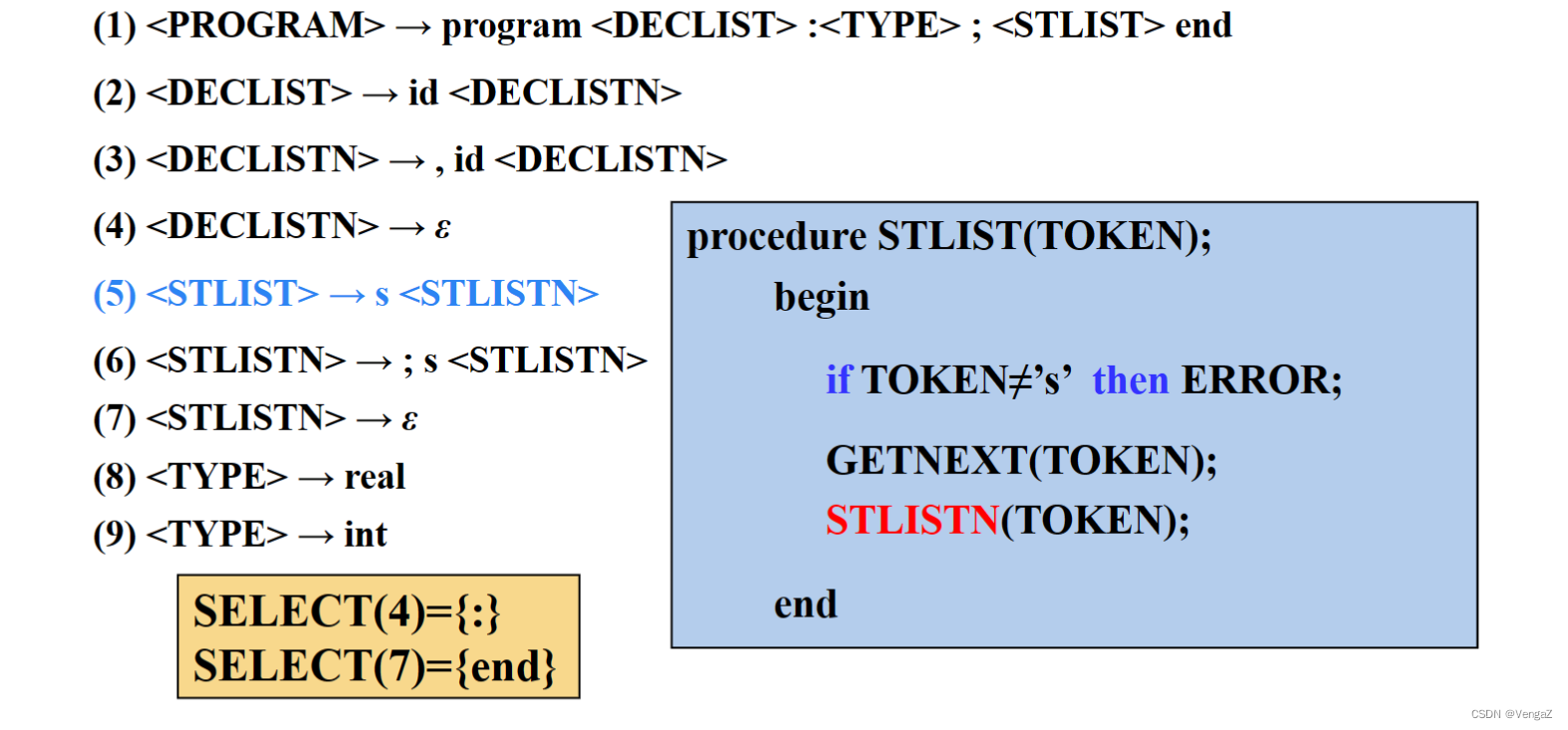
4.5 构造递归下降分析程序
- 定义:由一组递归函数或过程组成,每个函数或过程对应文法的一个非终结符的程序,称为递归下降分析器。
- 基本思路:
1)当遇到终结符a时,编写语句:if(当前读来的输入符号==’a’) 读入下一个输入符号;
2)当遇到非终结符A时,则编写语句调用A()。
3)当遇到A→ε产生式规则时,则编写语句:if(当前读来的输入符号∉Follow(A)) error();
4)当某个非终结符有多个候选产生式规则时,分两种情况处理:
i)if(当前读来的输入符号∈First(αi)) 按照规则A→αi进行推导;
ii)if(当前读来的输入符号∈Follow(A)且αi ⇒* ε) 按照规则A→αi进行推导;



4.6 非递归的预测分析法

4.6.1 预测分析程序的工作原理
- 预测分析器的组成:一张预测分析表M(LL(1)分析表)、一个栈、一个预测分析控制程序、一个输入缓冲区、一个输出流。
下推自动机(PDA)
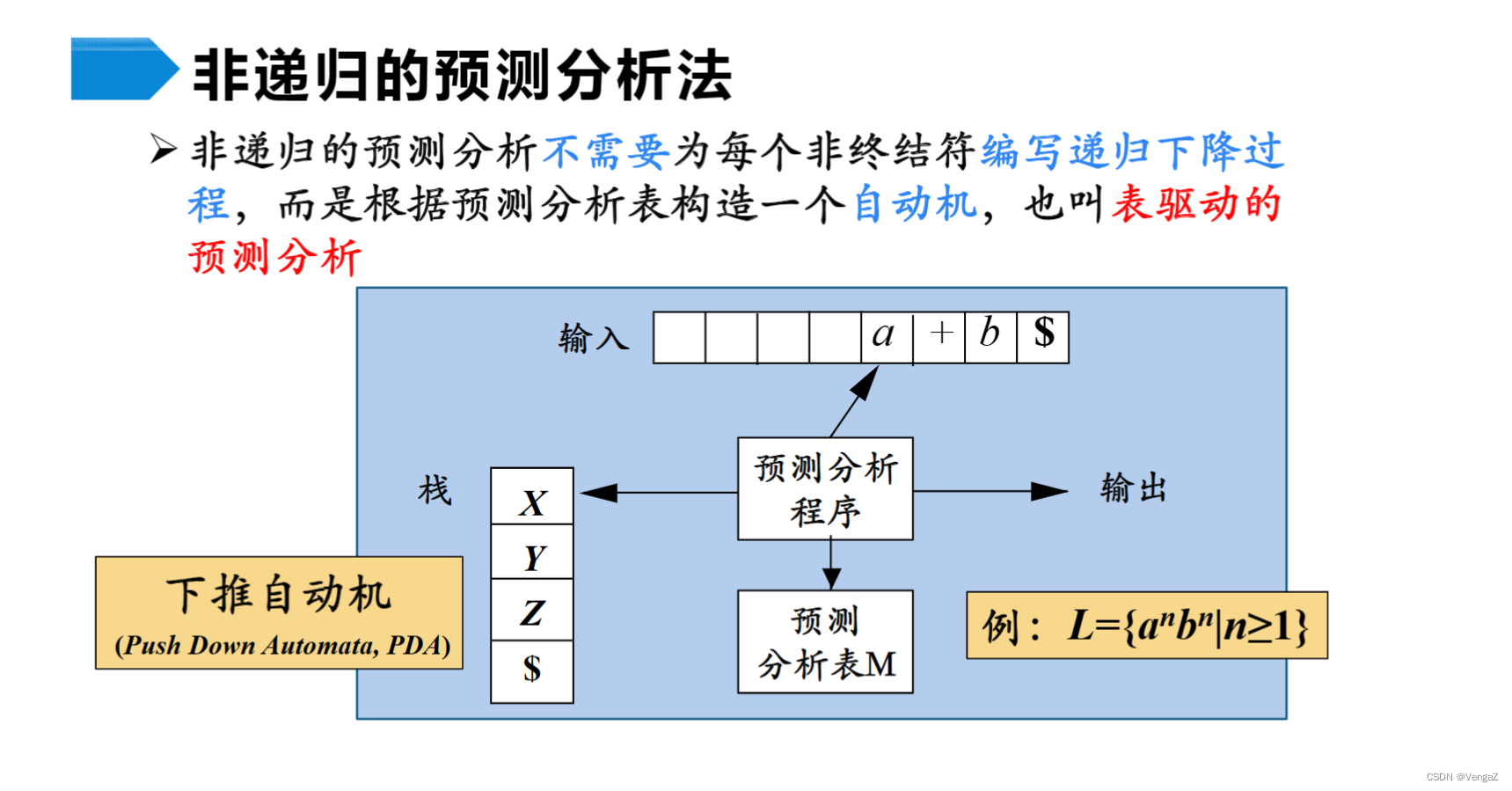

1)输入缓冲区:存放待分析的输入符号串,其后以符号#/$作为结束符。
2)栈:存放替换当前非终结符的某个产生式规则的右部符号串,栈底的符号为#。
3)预测分析表:一张二维表,行为非终结符号,列为终结符号,其元素形式为M[S,a],表中元素M[S,a]存放一条产生式规则或相应的出错处理程序的入口地址(分析出错时)。其中,M[S,a]表示当前栈顶S面对当前向前看符号a应采取的动作。
- 预测分析器的工作原理:#和文法开始符号进栈,从输入缓冲区读进输入符号a,弹出栈顶元素给X:
1)若X=a=’#’,则分析器工作结束,分析成功。
2)若X=a≠‘#’,则分析器把X从栈顶弹出,让输入指针指向下一个输入符号。
3)若X是一个非终结符号,则查阅预测分析表M。若在M[X,a]中存放着关于X的一个产生式规则,则先把X弹出,再把产生式规则右部符号串按逆序一一压入栈中。若M[X,a]={X→ε},则预测分析器把在栈顶的X弹出。若M[X,a]=error,则调用出错处理程序。
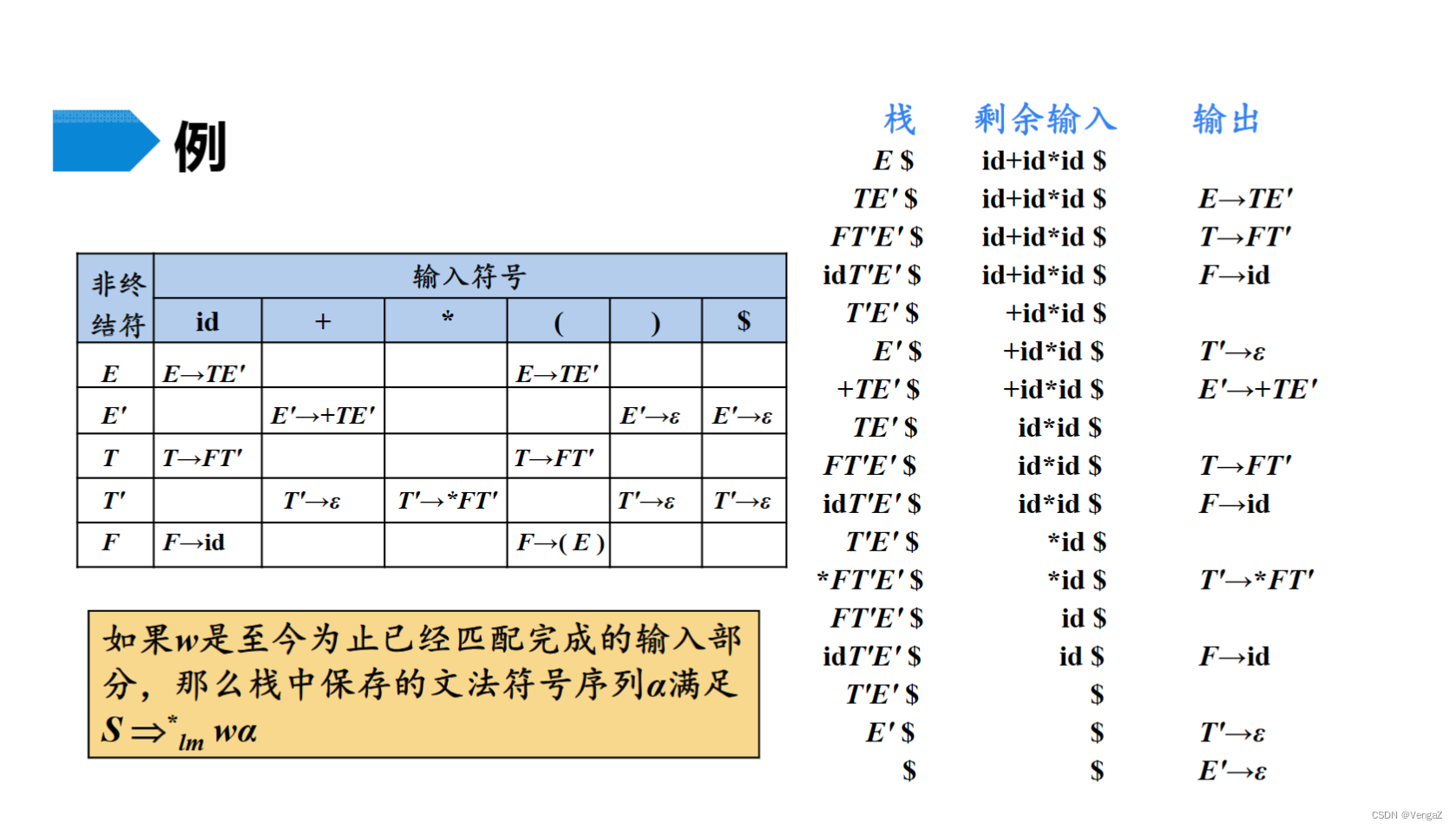

递归的预测分析法与非递归的预测分析法的比较
- 递归的预测分析法是根据产生式右部编写程序,所以直观性较好;
- 递归的预测分析法是根据产生式右部编写程序,所以不好自动生成,非递归的预测分析法是根据自动机生成,所以较易自动生成
4.6.2 构造预测分析表
1.构造方法
1)计算文法G的每个非终结符的First集和Follow集。
对每一个文法符号X∈(VT∪VN),如下计算First(X)里可以有ε:
i)若X∈VT,则First(X)={X}。(x是终结符,first集里只有他本身)
ii)若X∈VN,且有产生式规则X→a…,a∈VT,则a∈First(X)。
iii)若X∈VN,且有产生式规则X→ε,则ε∈First(X)。
iv)若有产生式规则X→X1X2…Xn,对于任意的j(1≤j≤n),当X1X2…Xj-1都是非终结符,且X1X2…Xj-1 ⇒ ε(即X1X2…Xj-1→ ε)时,则将First(Xj)中的非ε元素加到First(X)中。特别地,若X1X2…Xn ⇒ ε,则ε∈First(X)**。
v)反复执行i)到iv),直到First集不再变化为止。


对文法中的每一个A属于VN,如下计算Follow(A)里无ε:A→αB则把Follow(A)加到Follow(B)中
i)若A是文法的开始符号,则将‘#’加入到Follow(A)中。
ii)若A→αBβ是一条产生式规则,则把First(β)中的非ε元素加到Follow(B)中。
iii)若A→αB或A→αBβ是一条产生式规则,且β ⇒* ε,则把Follow(A)加到Follow(B)中。
iv)反复执行i)到iii),直到每个非终结符的Follow集不再发生变化为止。
2)对文法中的每个产生式规则A→α,若a∈First(α),则令M[A,a]=A→α。
3)若ε∈First(α),对任何b∈Follow(A),则令M[A,b]=A→α。
4)把预测分析表中无定义的空白元素标上出错标志error。
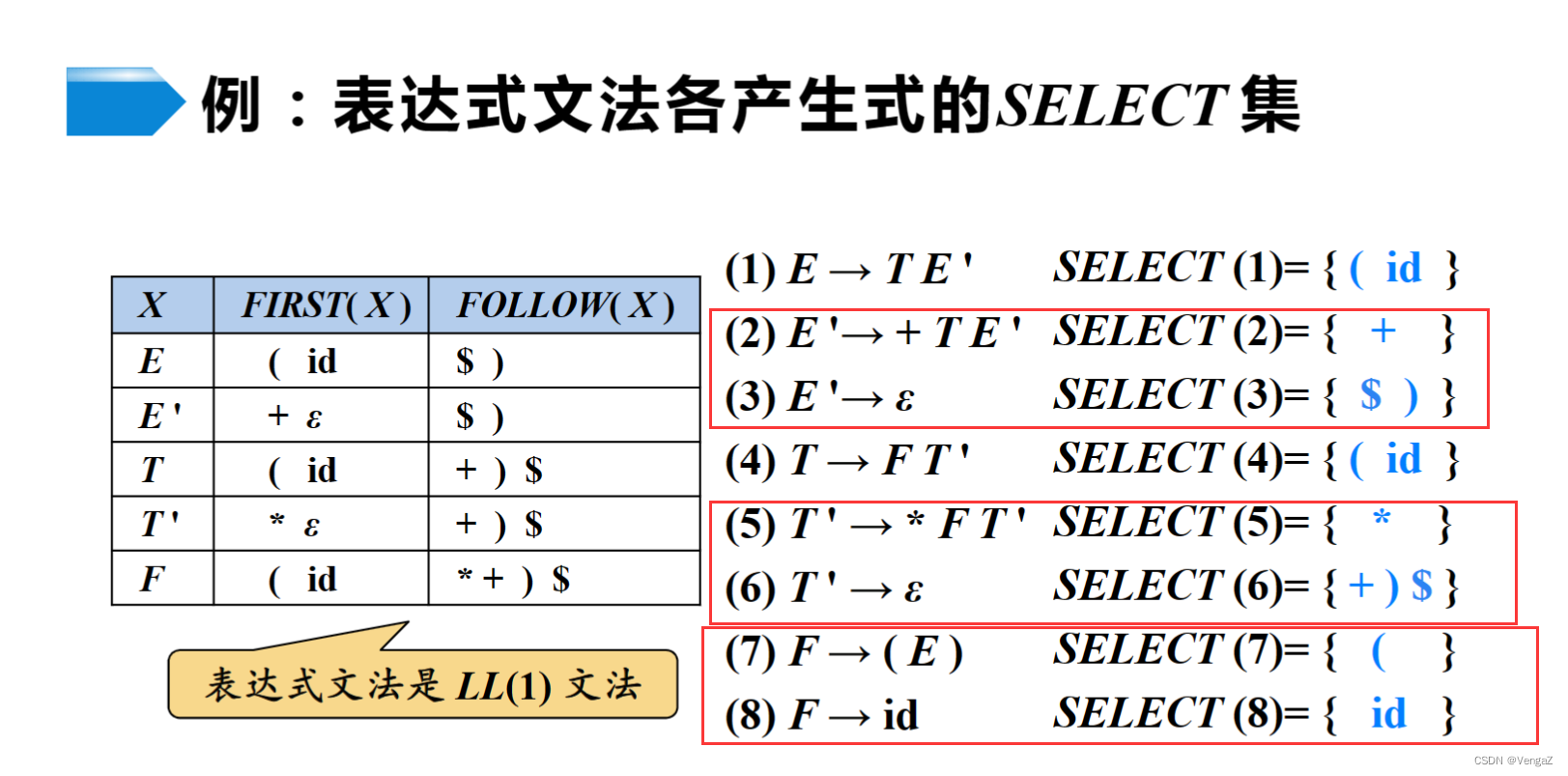
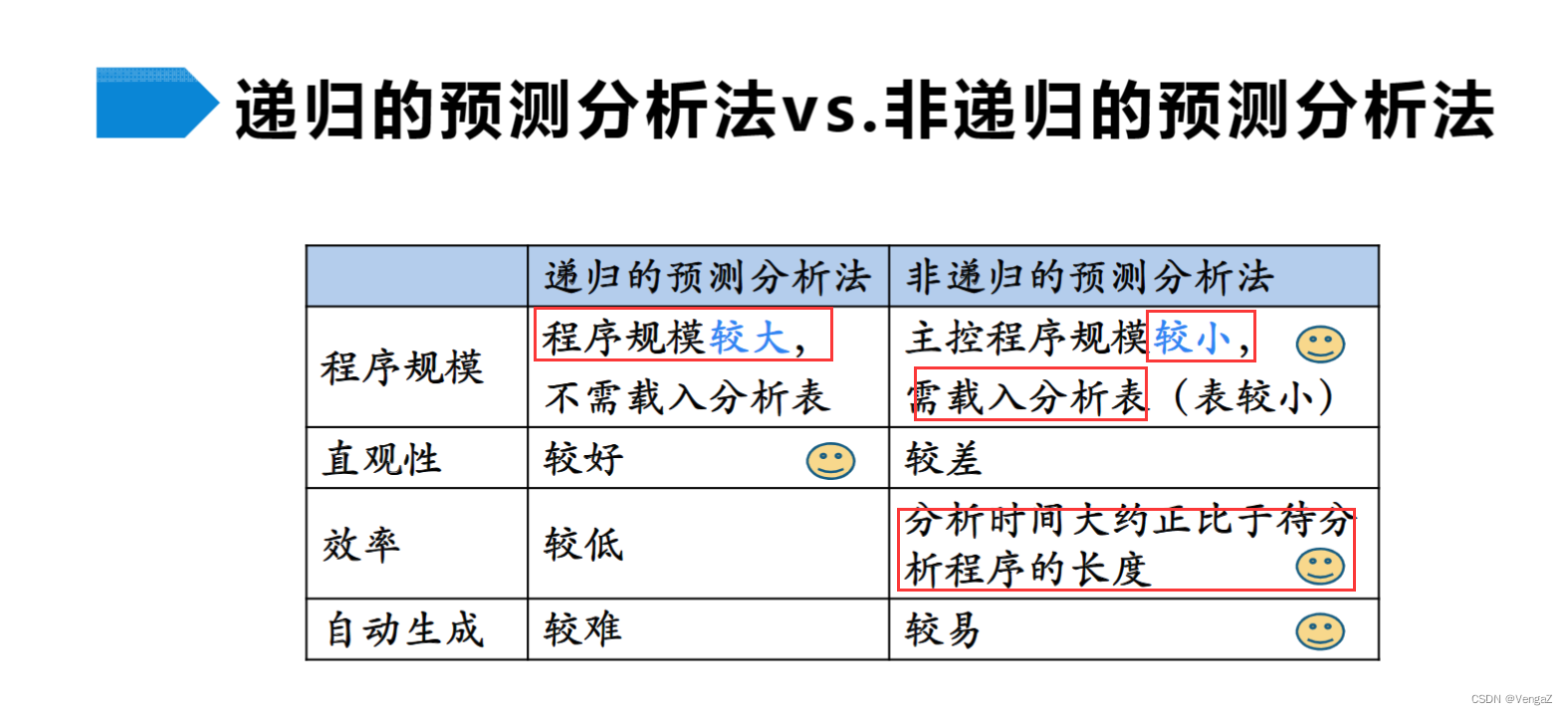
eg:设有文法G[E]:
E→TE1
E1→ATE1|ε
T→FT1
T1→MFT1|ε
F→(E)|i
A→+|-
M→*|/
试构造该文法得预测分析表M。
文法G的每个非终结符的First集和Follow集
| 产生式规则 | First集 | Follow集 |
|---|---|---|
| E→TE1 | First(E)={(,i} | Follow(E)={#,)} |
| E1→ATE1Iε | First(E1)={+,-,ε} | Follow(E1)={#,)} |
| T→FT1 | First(T)={(,i} | Follow(T)={+,-,),#} |
| T1→MFT1 Iε | First(T1)={*,/,ε} | Follow(T1)={+,-,),#} |
| F→(E)Ii | First(F)={(,i} | Follow(F)={+,-,*,/,),#} |
| - | First((E))={(},First(i)={i} | - |
| A→+I- | First(A)={+,-} | Follow(A)={(,i} |
| - | First(+)={+},First(-)={-} | - |
| M→*I/ | First(M)={*,/} | Follow(M)={(,i} |
| - | First()={},First(/)={/} | - |
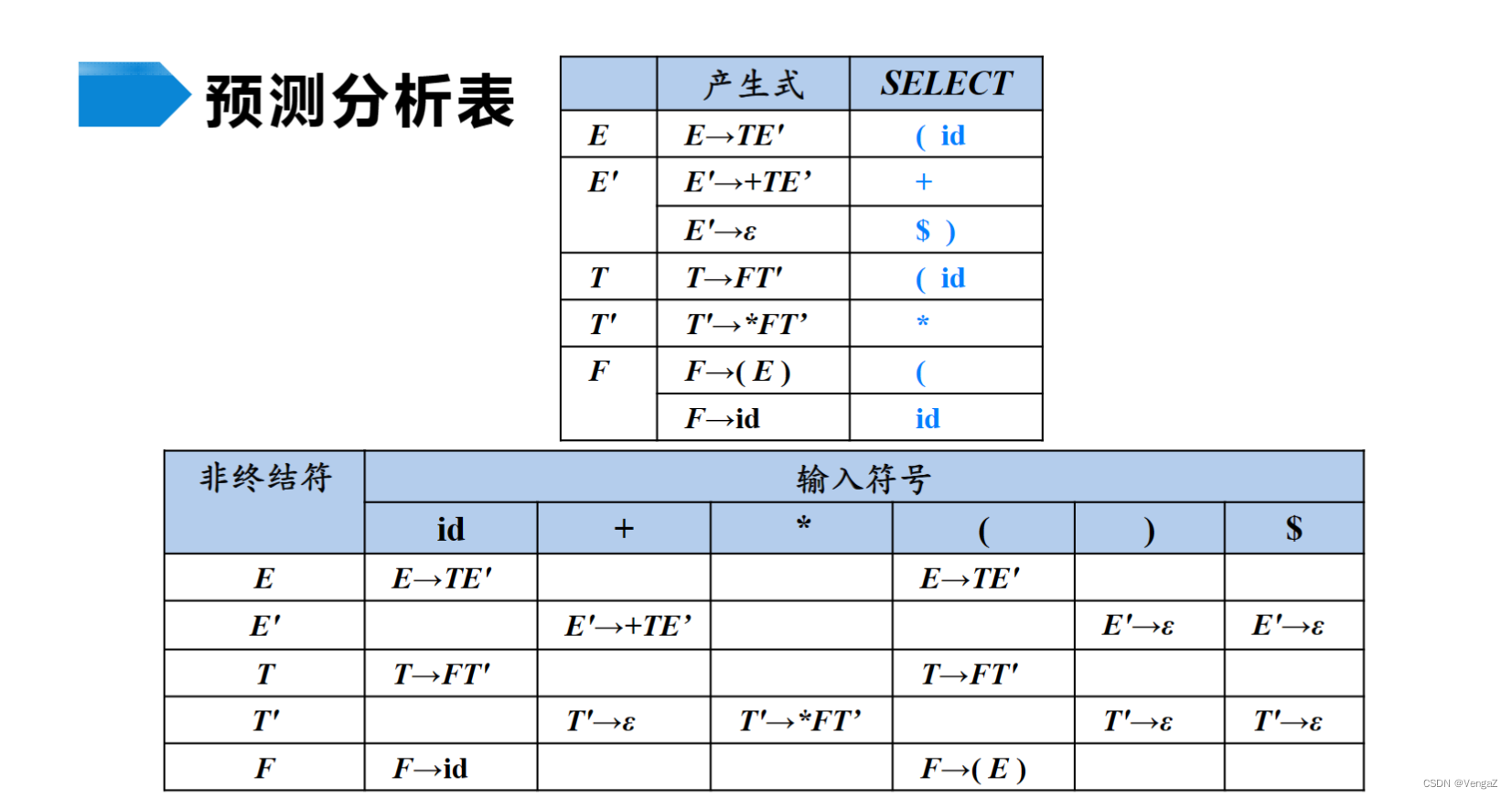
预测分析表

- 可选集

- 串首终结符集

预测分析法的实现步骤

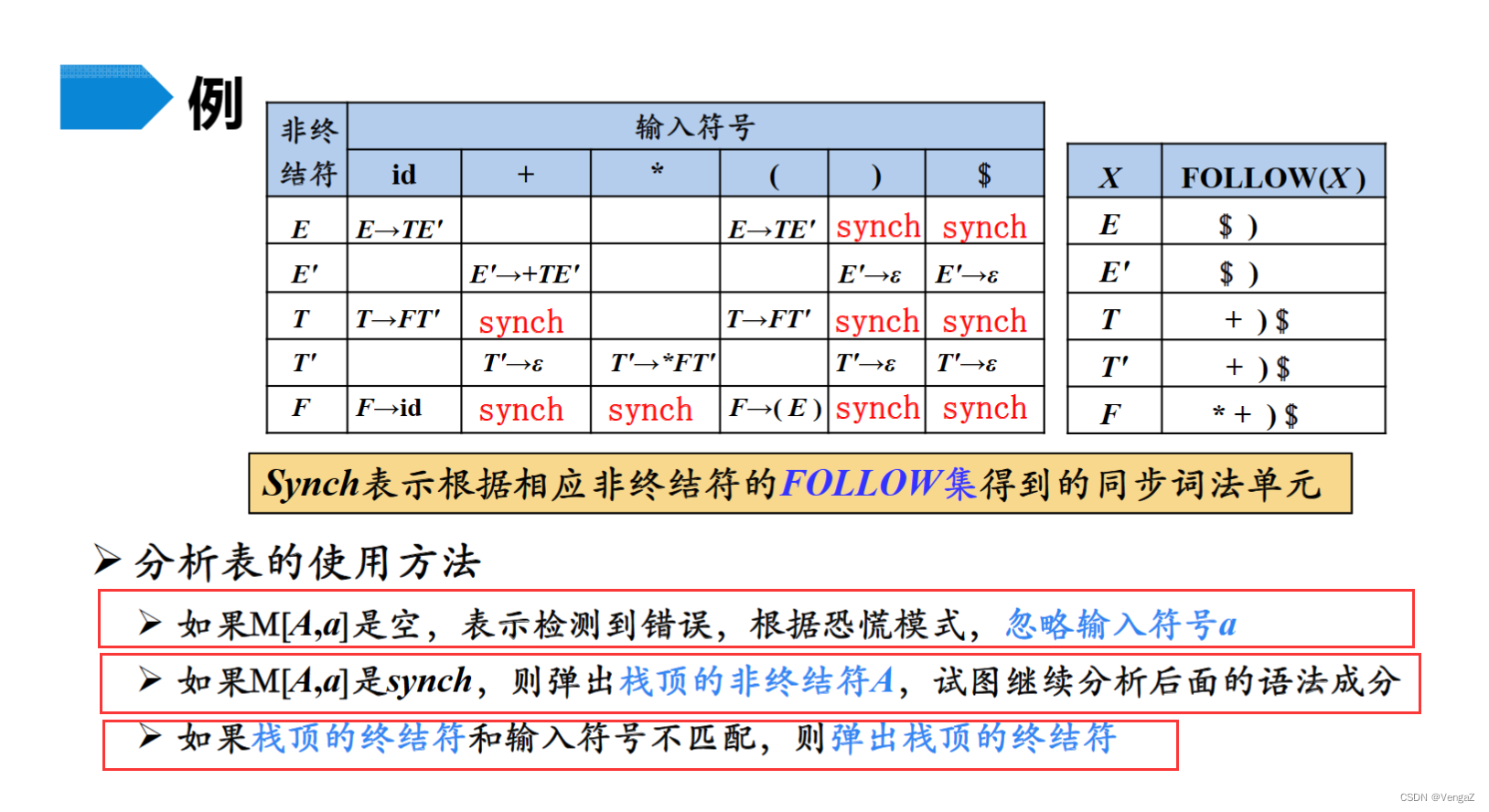
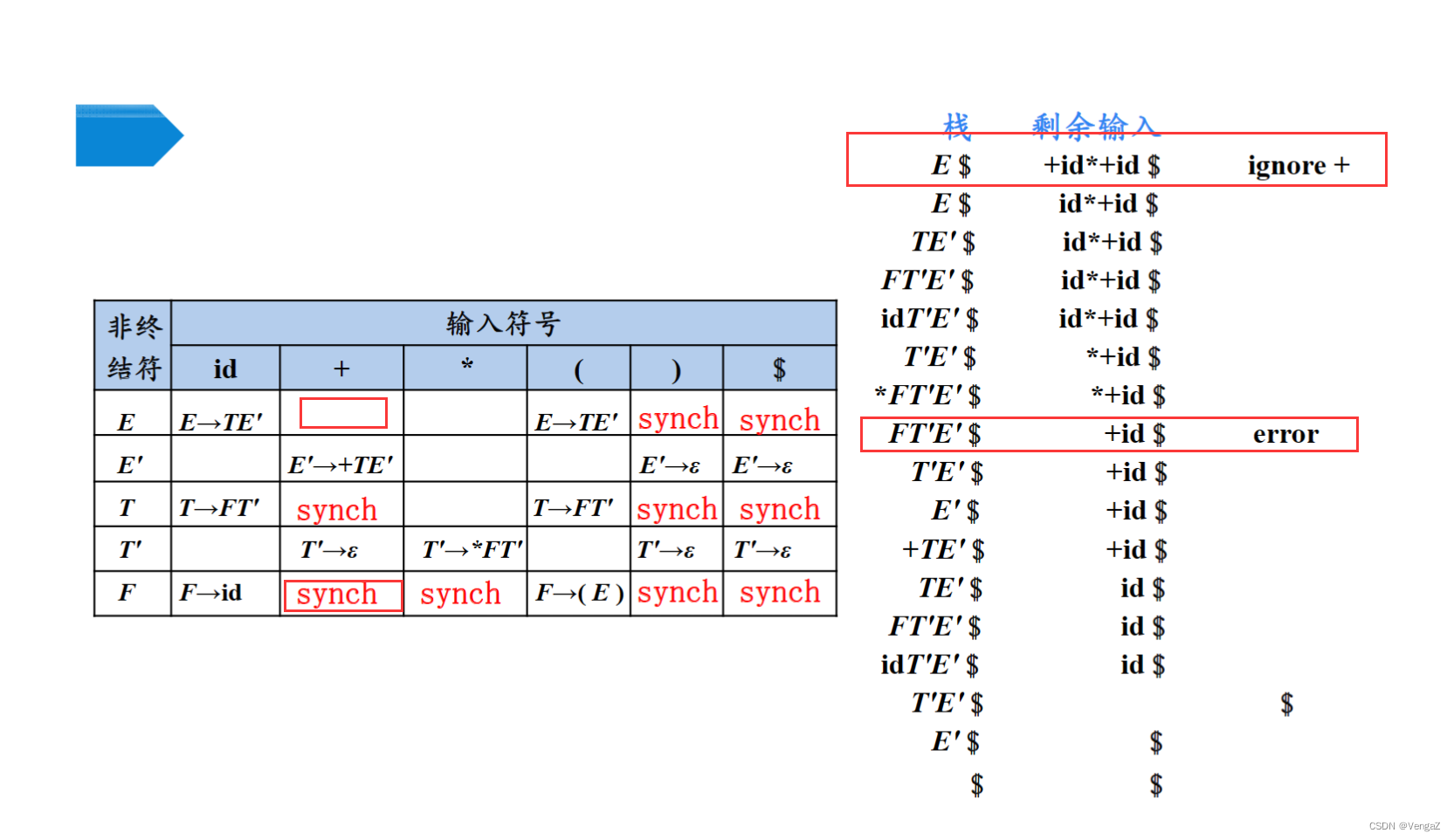
4.6.3预测分析的出错处理(同步符号集的选择)
-
出错情况
1)栈顶上的终结符号与下一个输入符号不匹配。
2)栈顶上是非终结符号A,下一个输入符号是a,但分析表M[A,a]为空。 -
解决思路:跳过输入串中的一些符号,直到遇到“同步符号“为止。
-
同步符号集的选择
1)把Follow(A)中的所有符号放入非终结符A的同步符号集。若跳读一些符号直到出现Follow(A)中的符号,把A从栈中弹出,这样就可能使分析继续下去。
2)对于非终结符A,只用Follow(A)作为它的同步符号集是不够的。
eg:若分号作为语句的结束符,则语句开头的关键字可能不在产生表达式的非终结符的Follow集中。一个赋值语句后少一个分号可能导致下一语句开头的关键字被跳过。
3)若把First(A)中的符号加入到非终结符A的同步符号集,则当First(A)中的一个符号在输入中出现时,可以根据A恢复语法分析。
4)若一个非终结符产生空串,则推导ε的产生式可以作为默认的情况,这样做可以推迟某些错误检查,但不能导致放弃一个错误。
5)若不能匹配栈顶的终结符号,一个简单的想法是弹出栈顶的这个终结符号,并发出一条信息,说明已经插入了这个终结符,继续进行语法分析。





















 1945
1945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











