







第一张 绪论
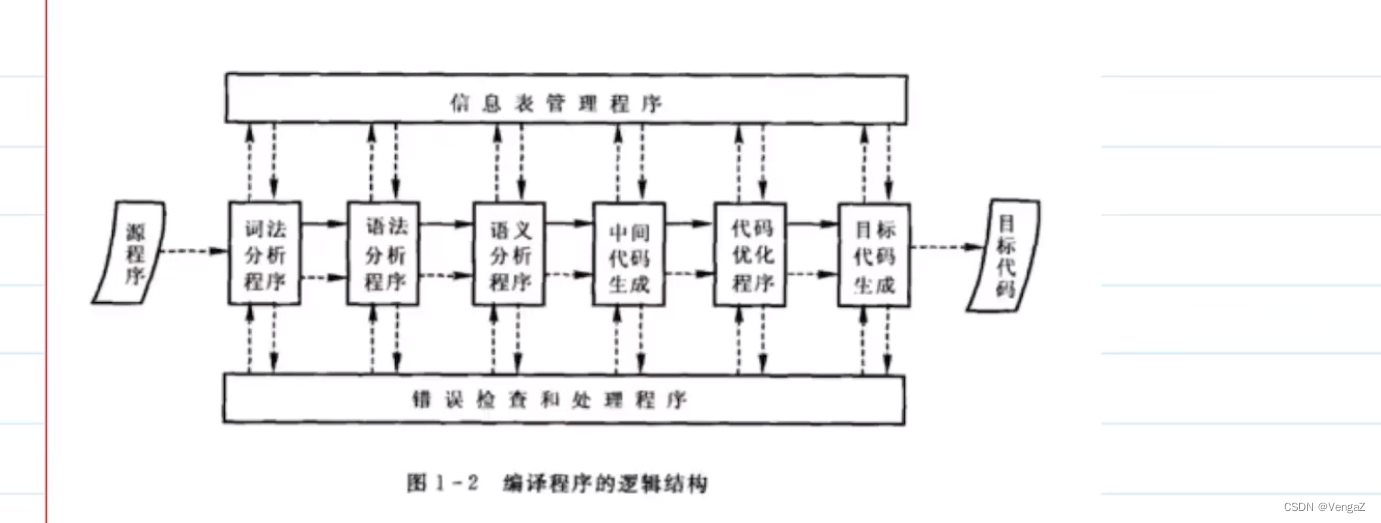
编译原理由哪些部分组成(八个部分)
词法分析、语法分析、语义分析三个程序
中间代码生成、代码优化程序、目标代码生成程序
信息表管理程序、错误检查和处理程序

第二章 前后文无关文法和语言
1. 符号串的计算



2. 设计文法



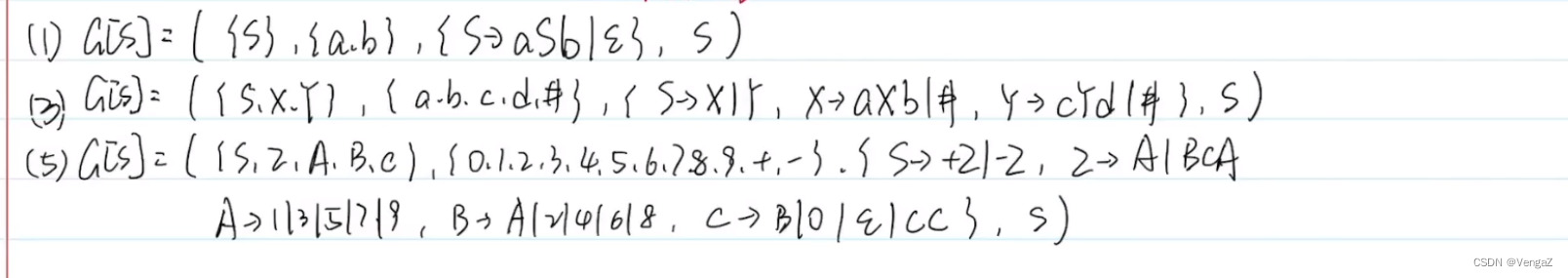
3. 最左最右

自底向上(LR)采用最左规约,最右推导
自顶向下(LL)采用最左推导,最右规约
最左推导和最右推导具有唯一性
最右推导是规范推导,最左规约是规范规约
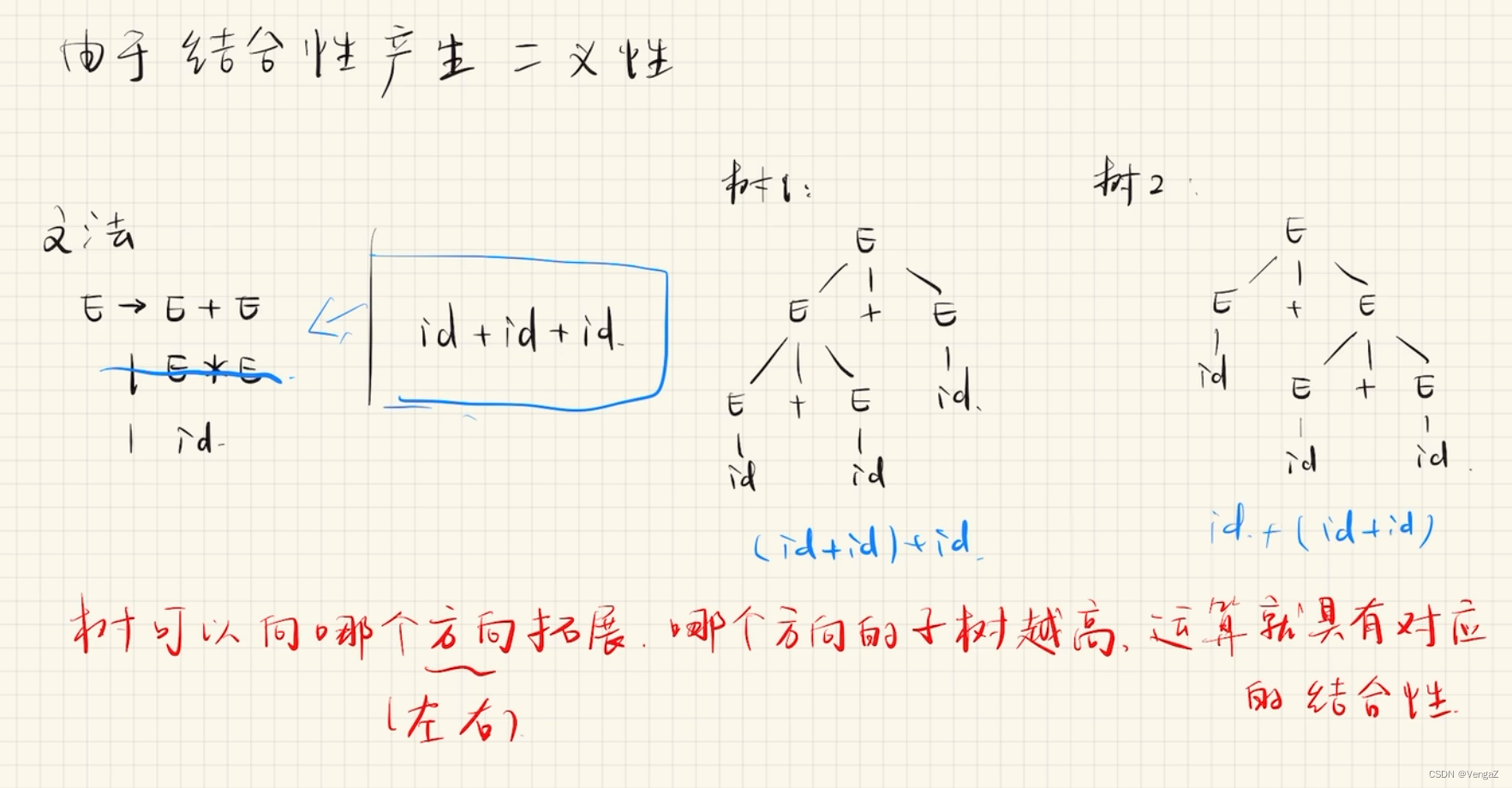
推导、语法树的例子

4. 二义性文法

5. 短语和句柄

短语、直接短语、句柄(第二章)
- 直接短语一定是一个产生式的右部,但是产生式的右部不一定是当前句型的直接短语
- 高人,民生,活水则都不是当前句型的直接短语,但是是其他句型的产生式右部
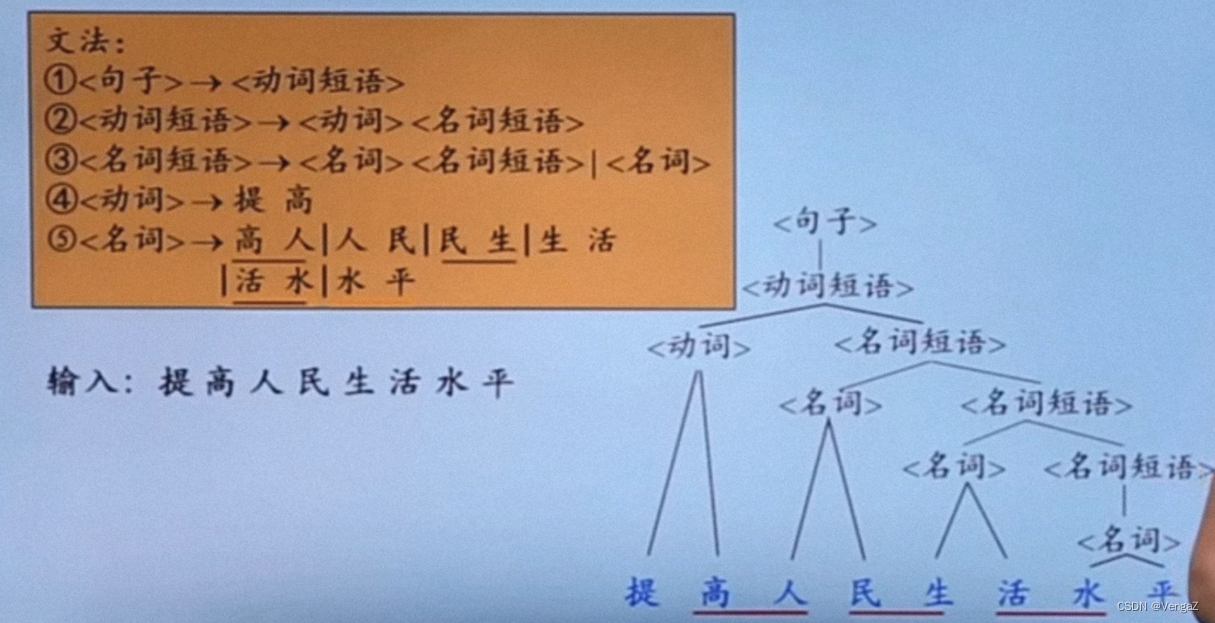

设G[Z]是一个文法,假定αβδ是文法G的一个句型。
1)短语:若存在Z ⇒+ αAδ且A ⇒+ β,则称β是句型αβδ相对于非终结符A的短语。(即子树的边缘)
2)直接短语:若存在Z ⇒+ αAδ且A⇒β,则称β是句型αβδ相对于产生式规则A→β的直接短语。(高度为2的子树的边缘)
3)句柄:一个句型的最左直接短语称为该句型的句柄。
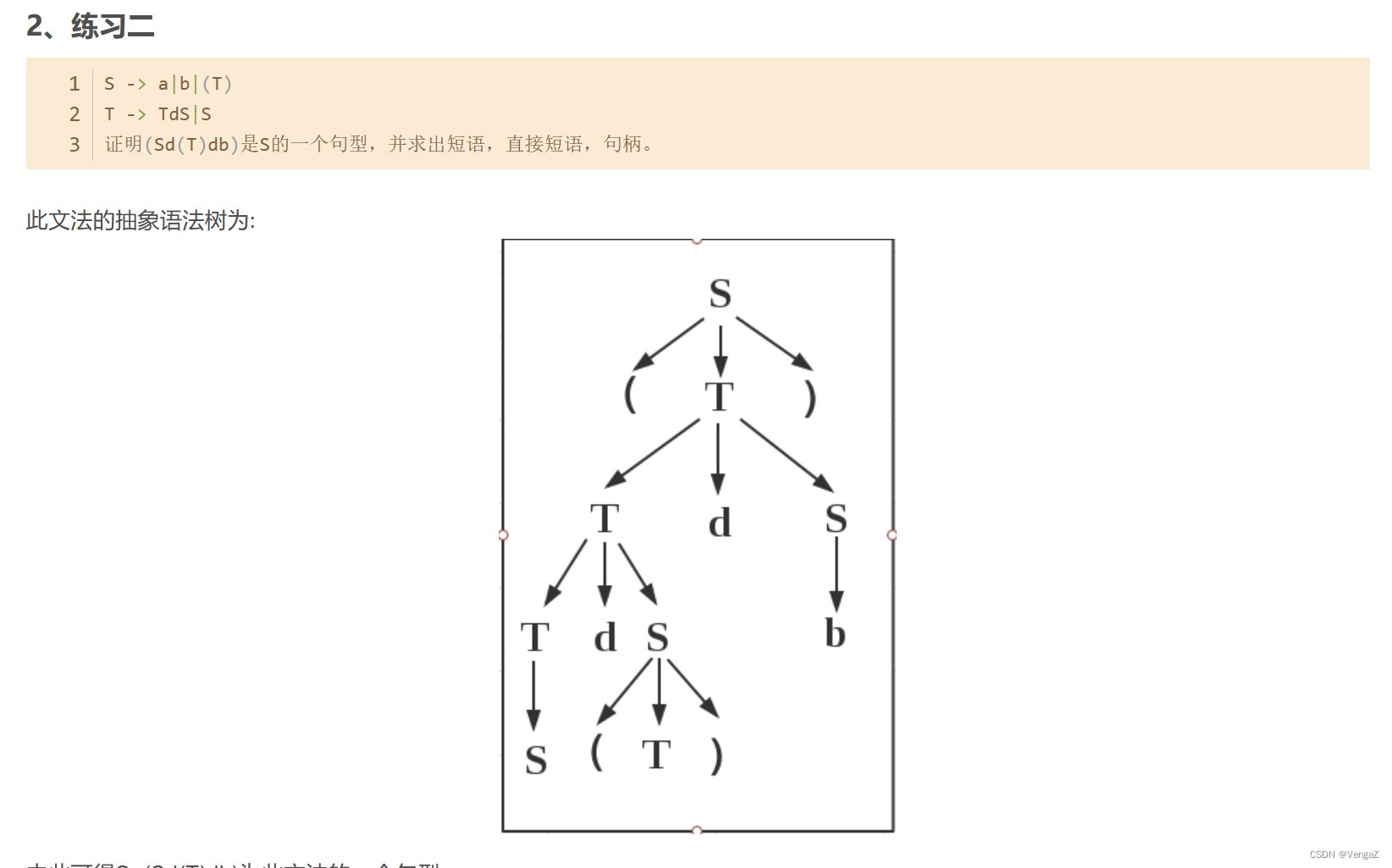
练习1
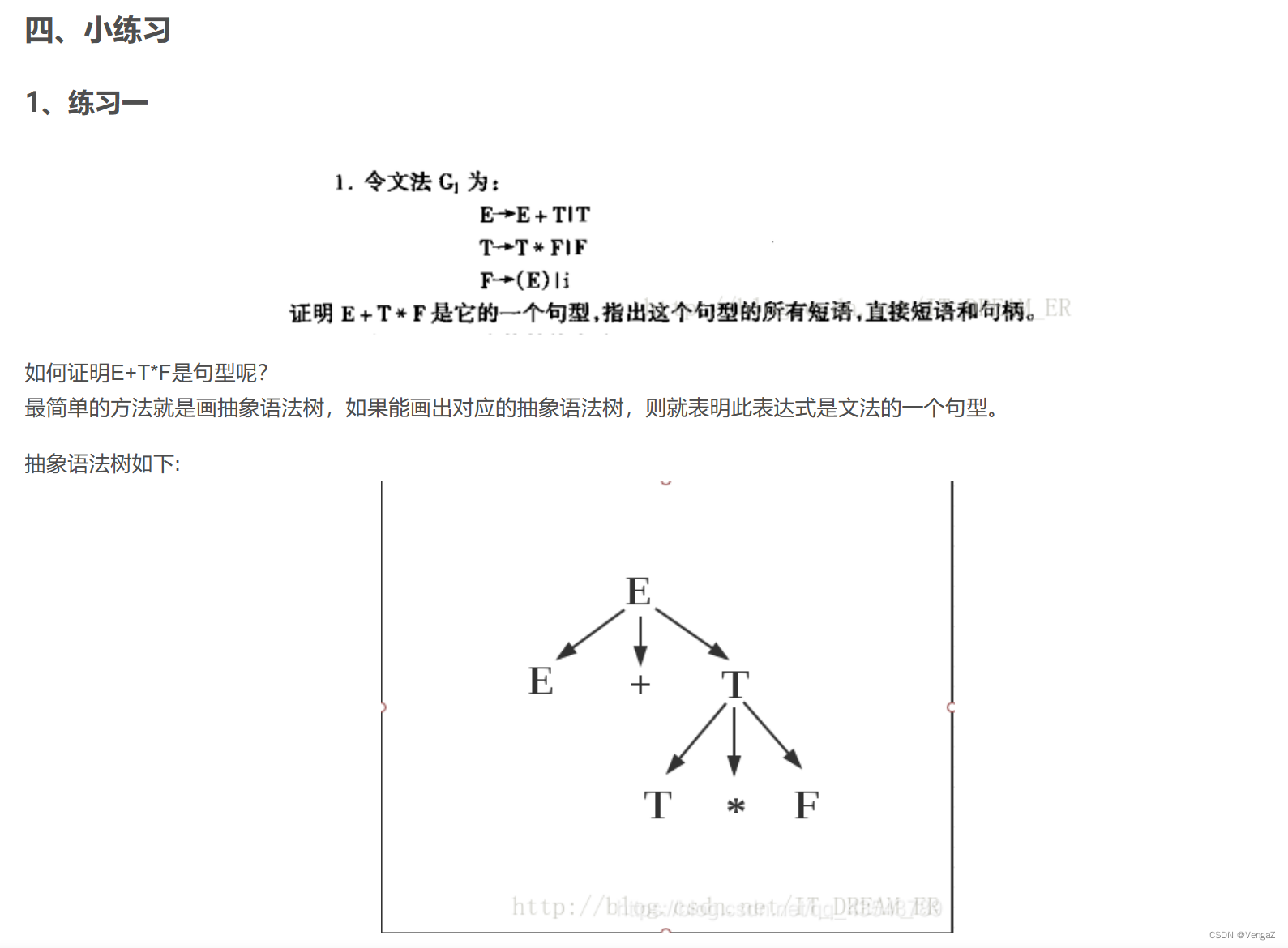

练习2

6. 化简文法

第三章 词法分析及词法分析程序
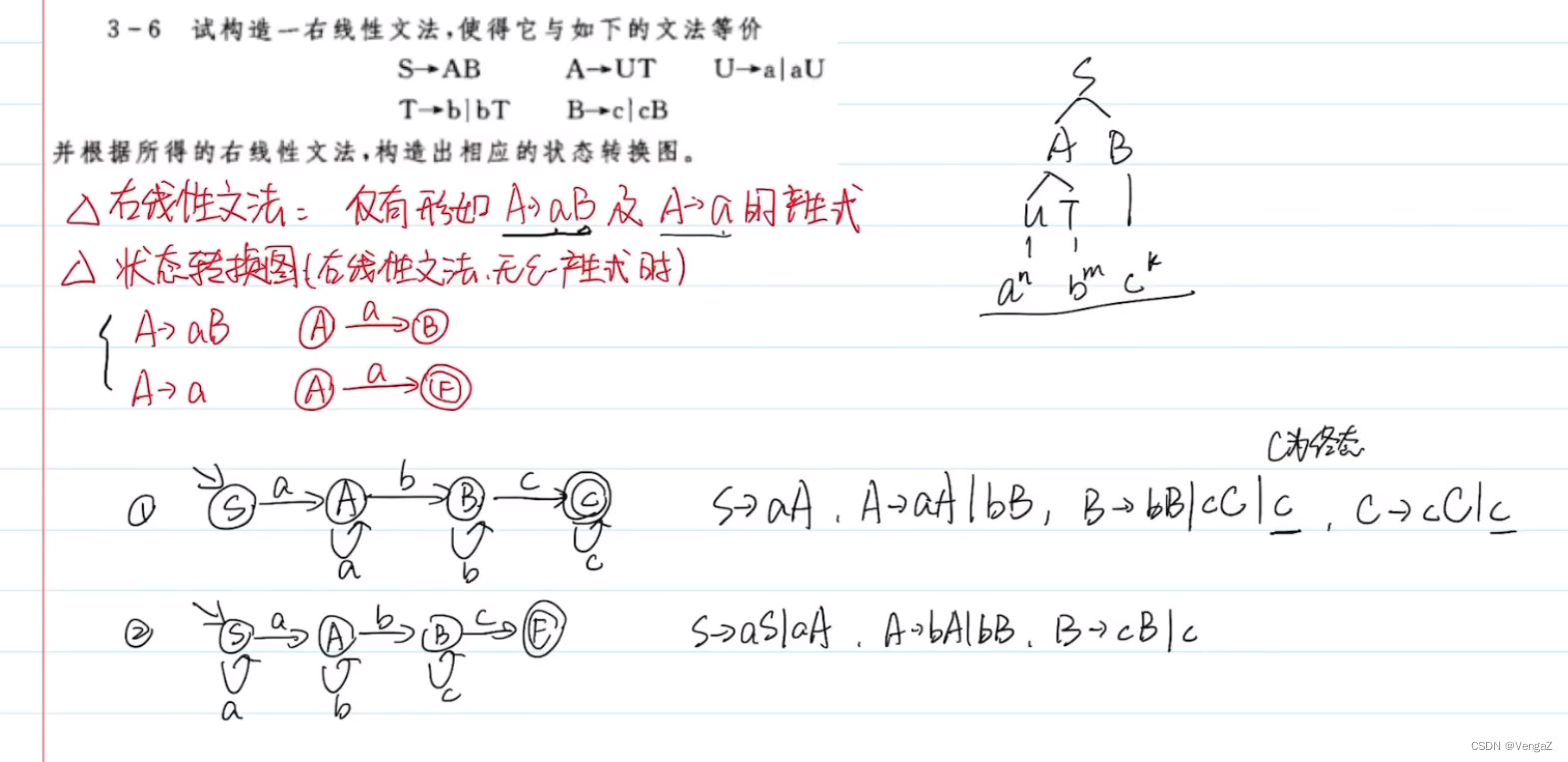
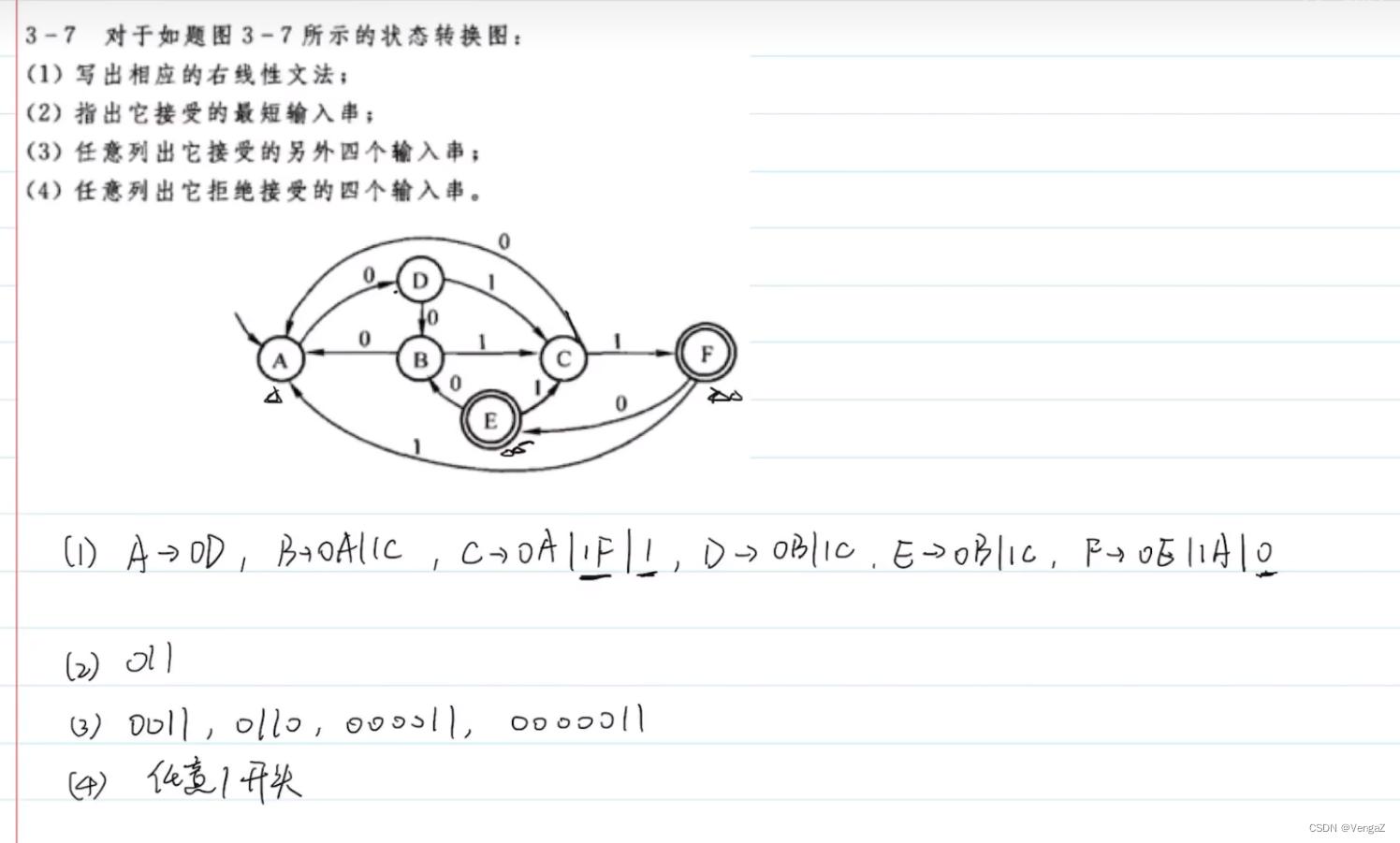
1. 右线性文法以及状态转换图
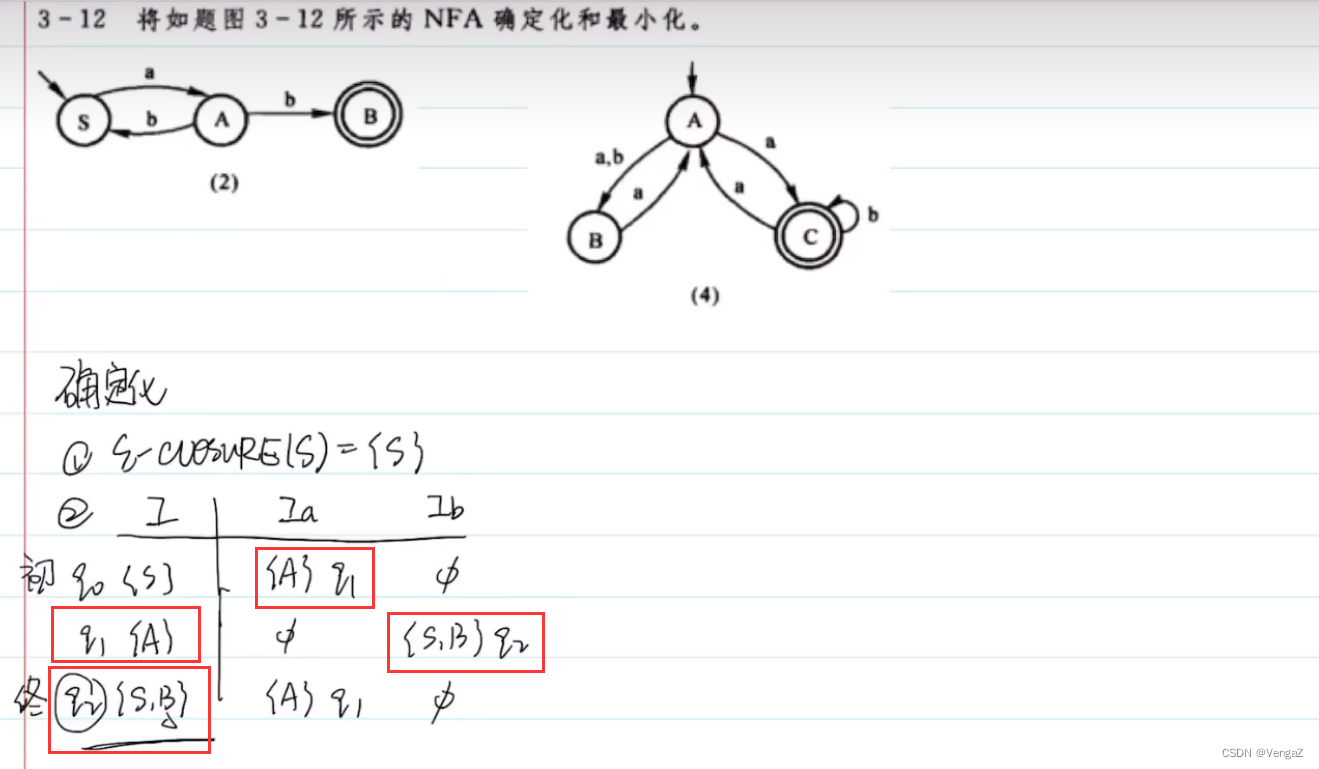
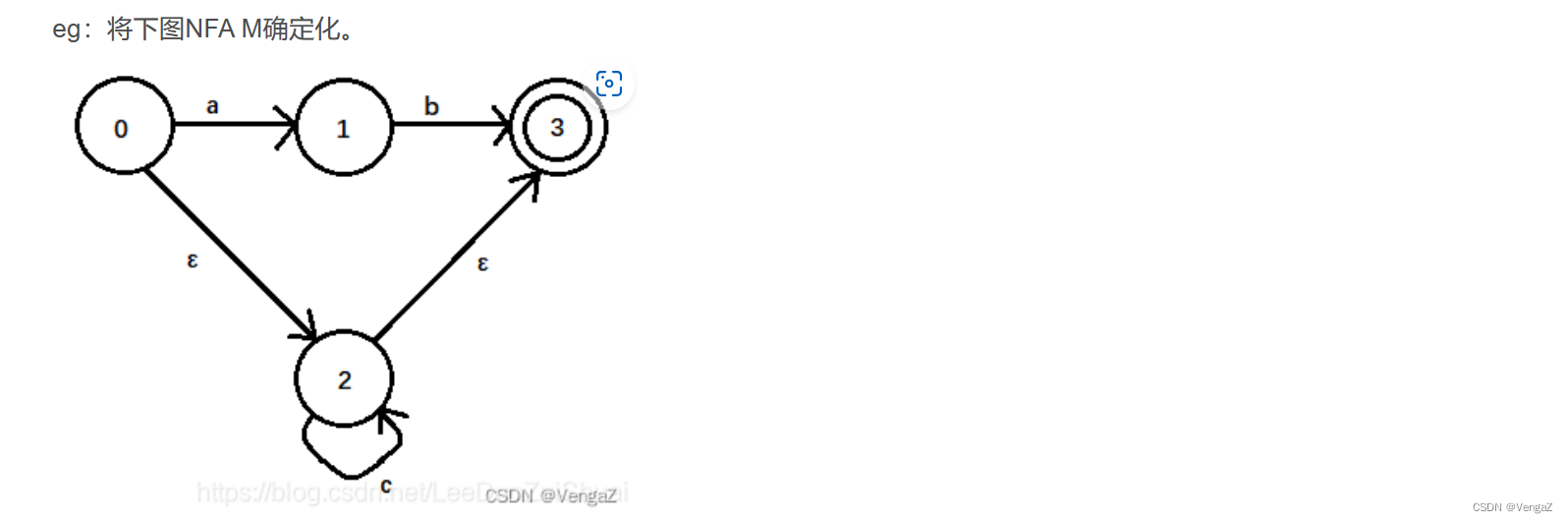
2. NFA的确定化和最小化
乱七八糟版


每次都把新生成的状态写在下边

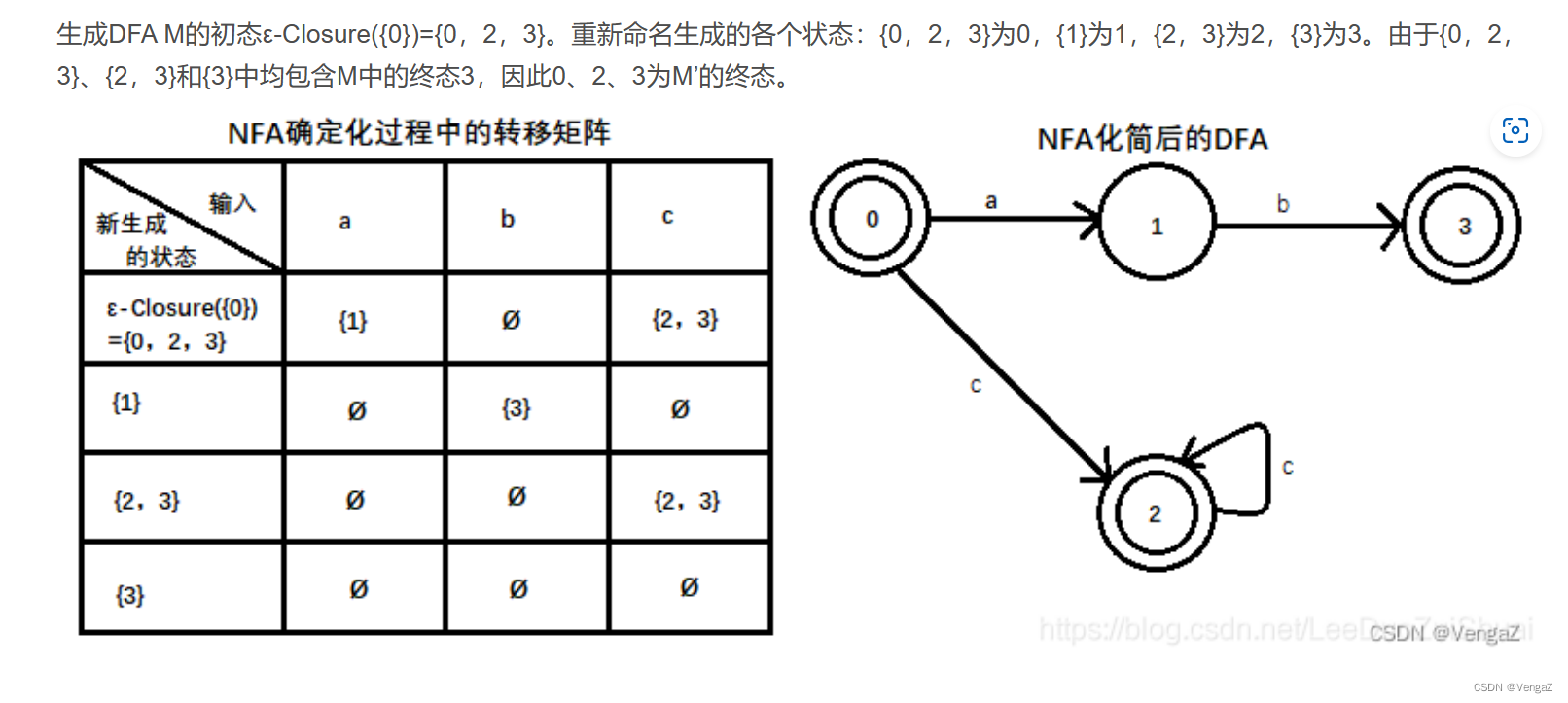
生成DFA M的初态ε-Closure
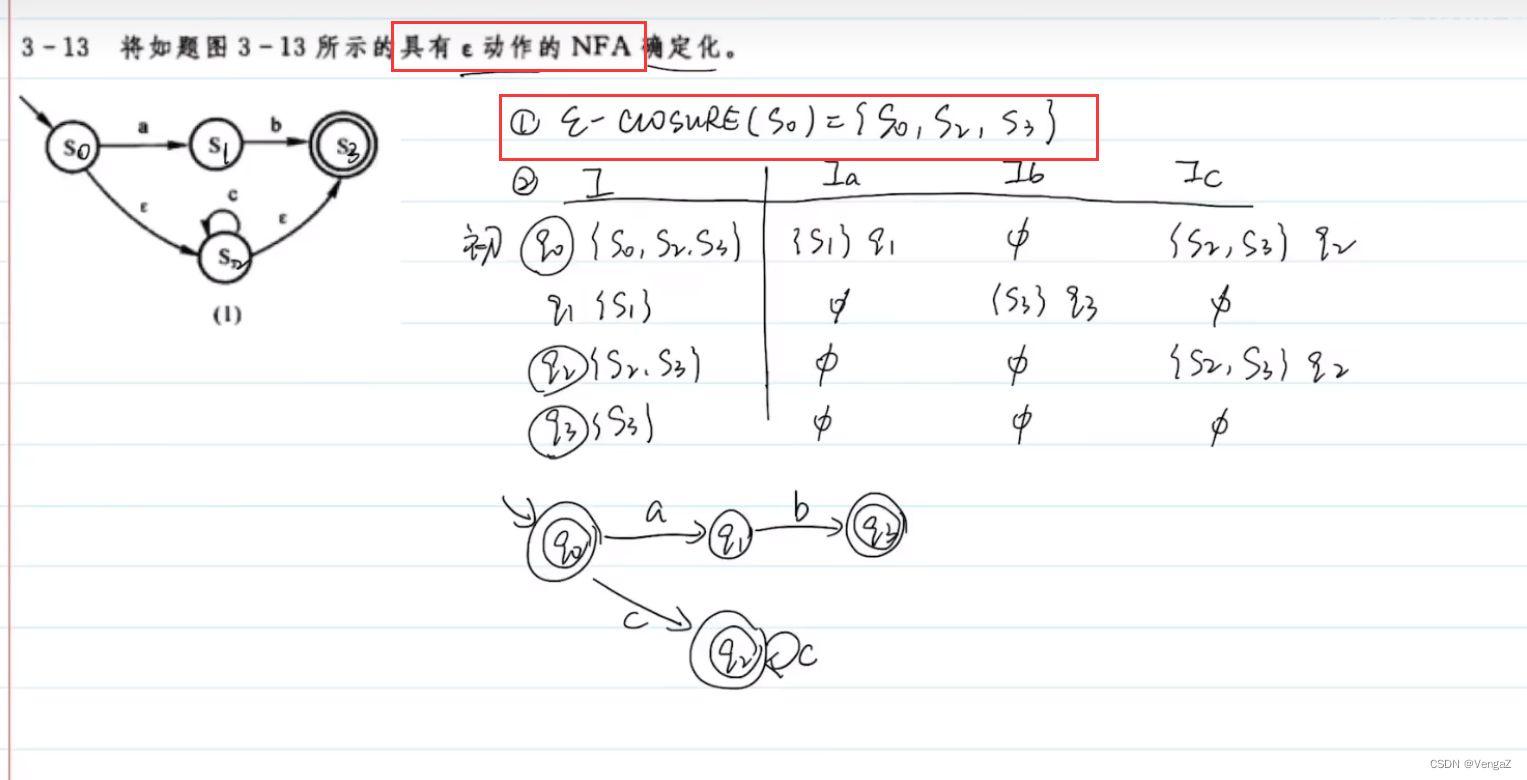
确定化:子集构造法
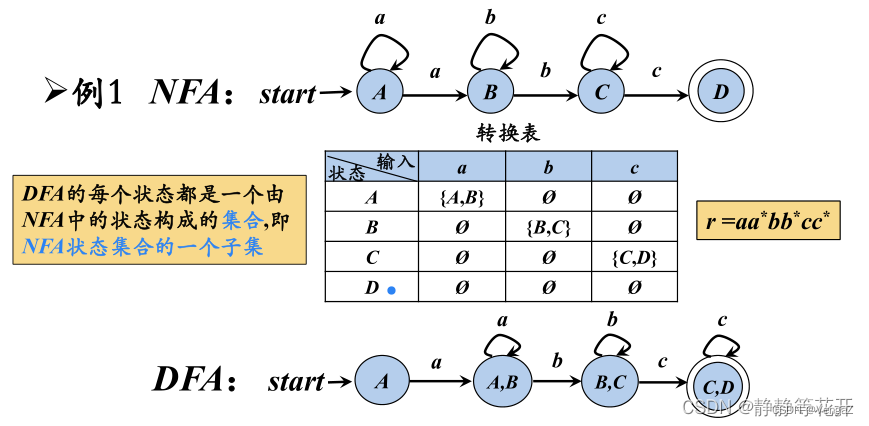
先确定开始状态,再查看转换表该状态分别经过a、b所能到达的状态。能通过a到达的状态集合统归为一个新的状态。类似的对新状态包含的状态分别对a、b进行考察,通过a到达的状态集合再归为一个新状态。b边同理。
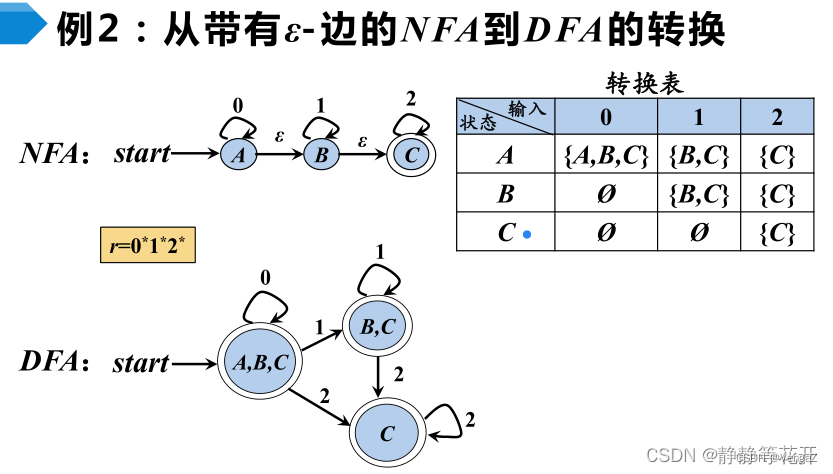
【每进入一个(新)状态,都需要观察这个新状态通过每一种边能到达的状态,新状态通过某一边(比如a边)所能到达的状态成为一个集合,这个集合又成为一个(新)状态;以此类推】
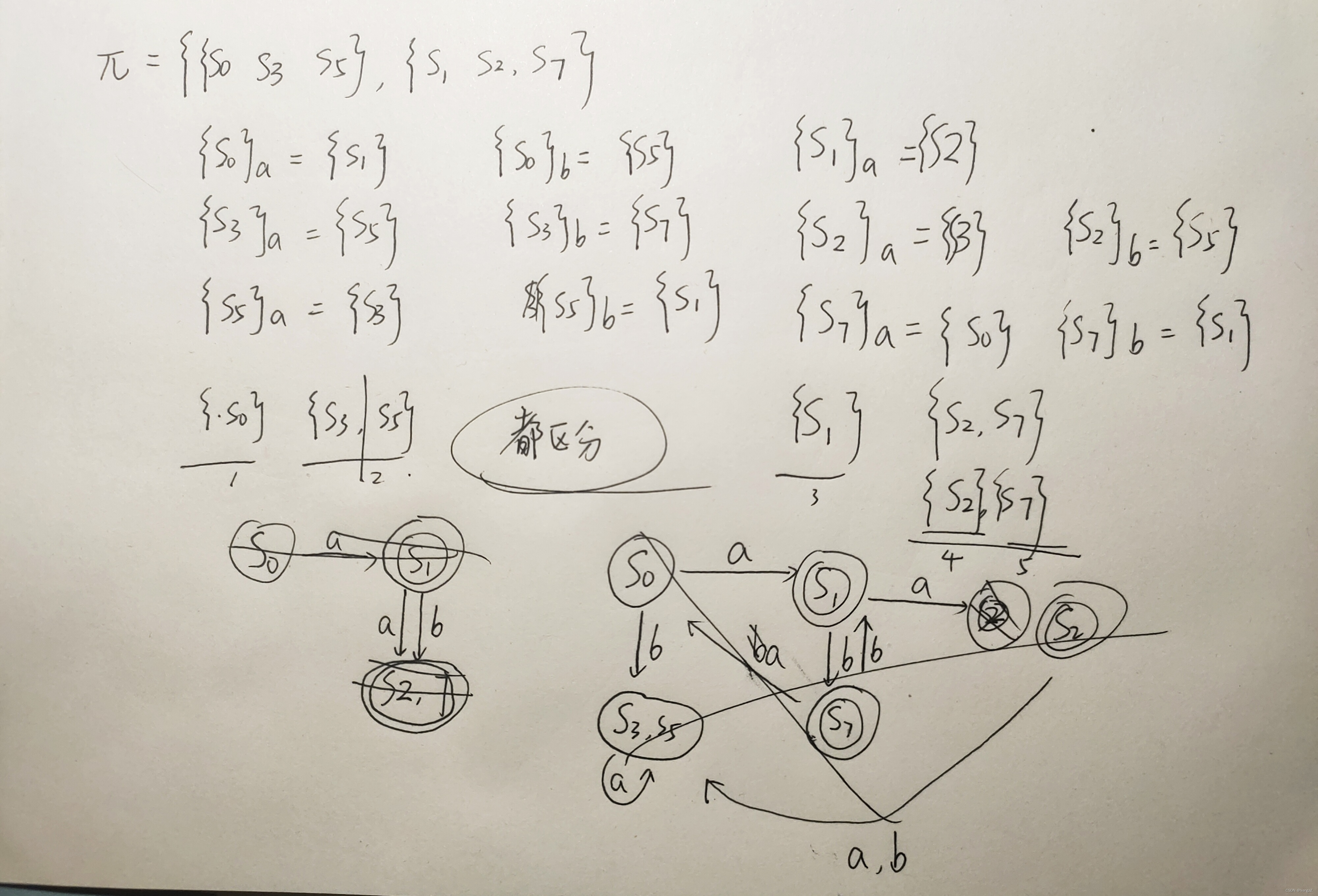
最小化:化简DFA
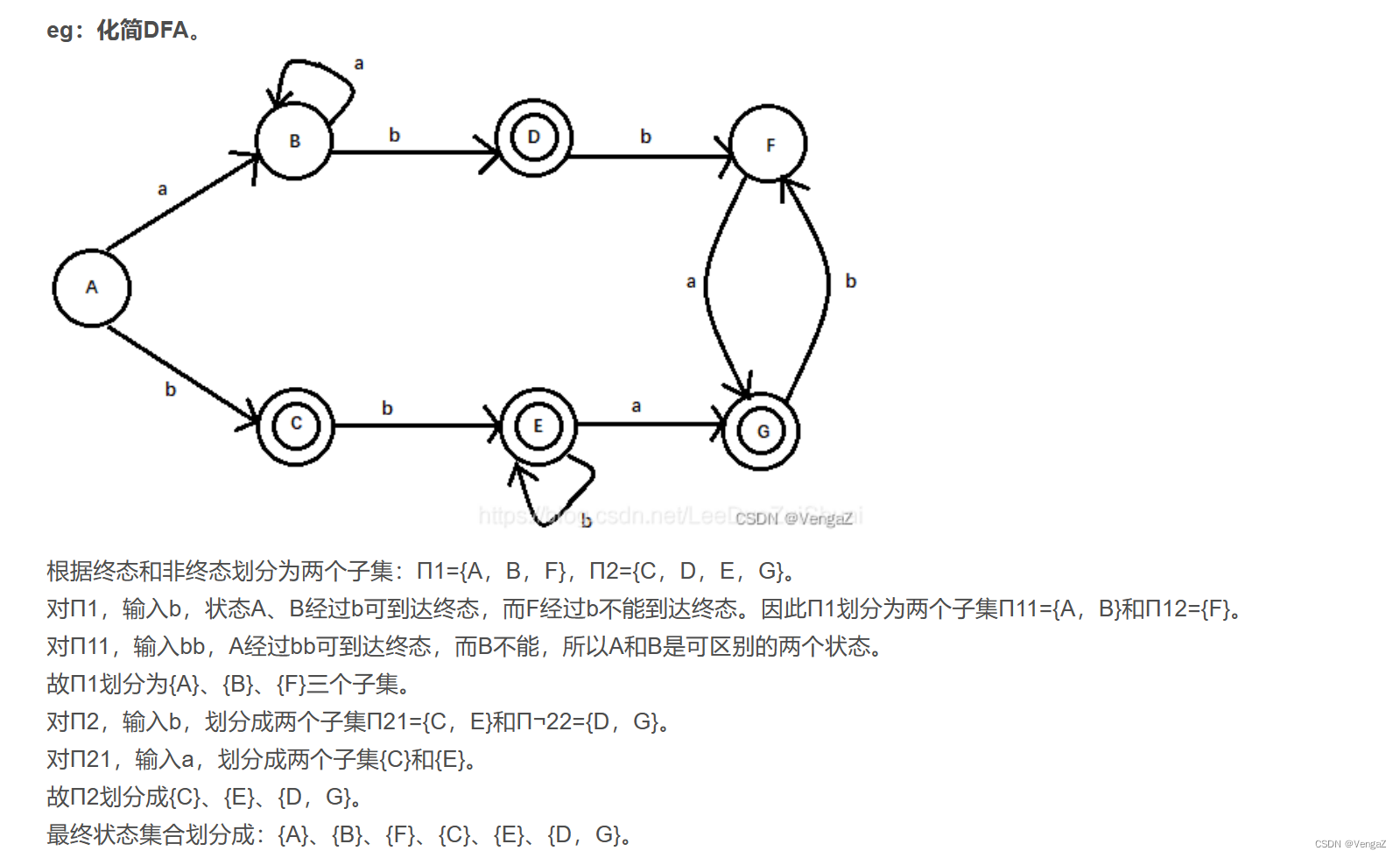
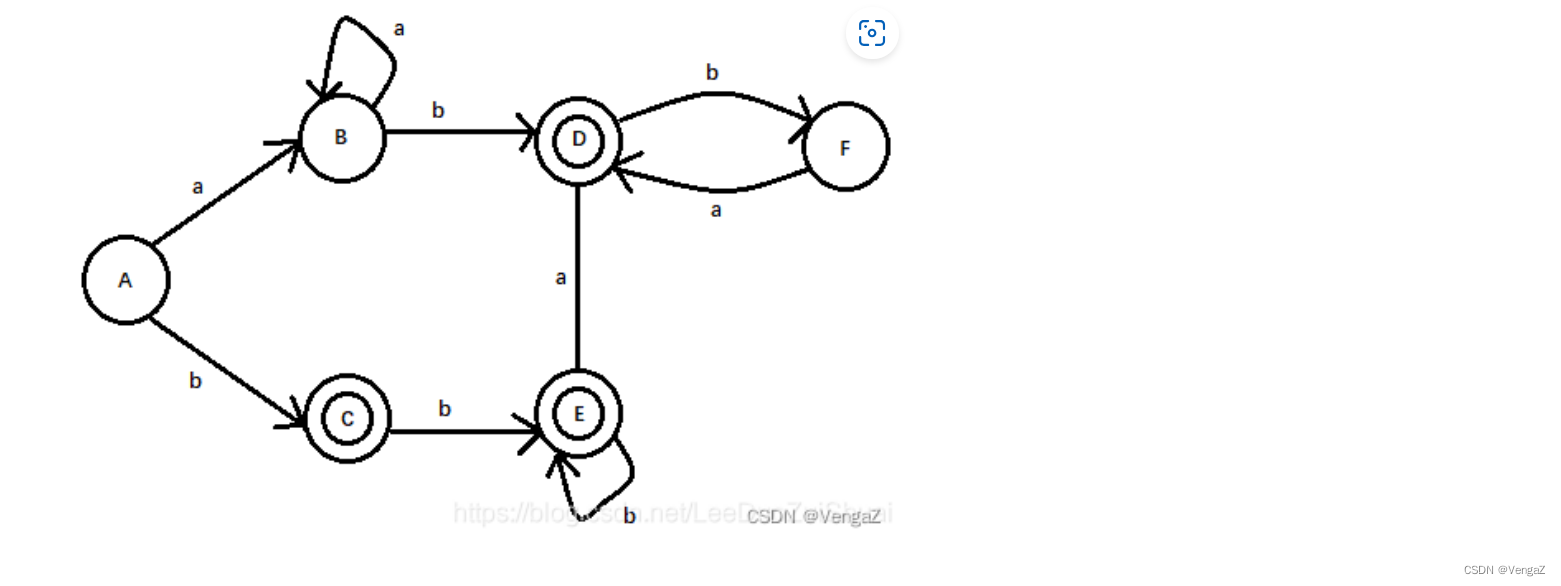
特殊的一个化简
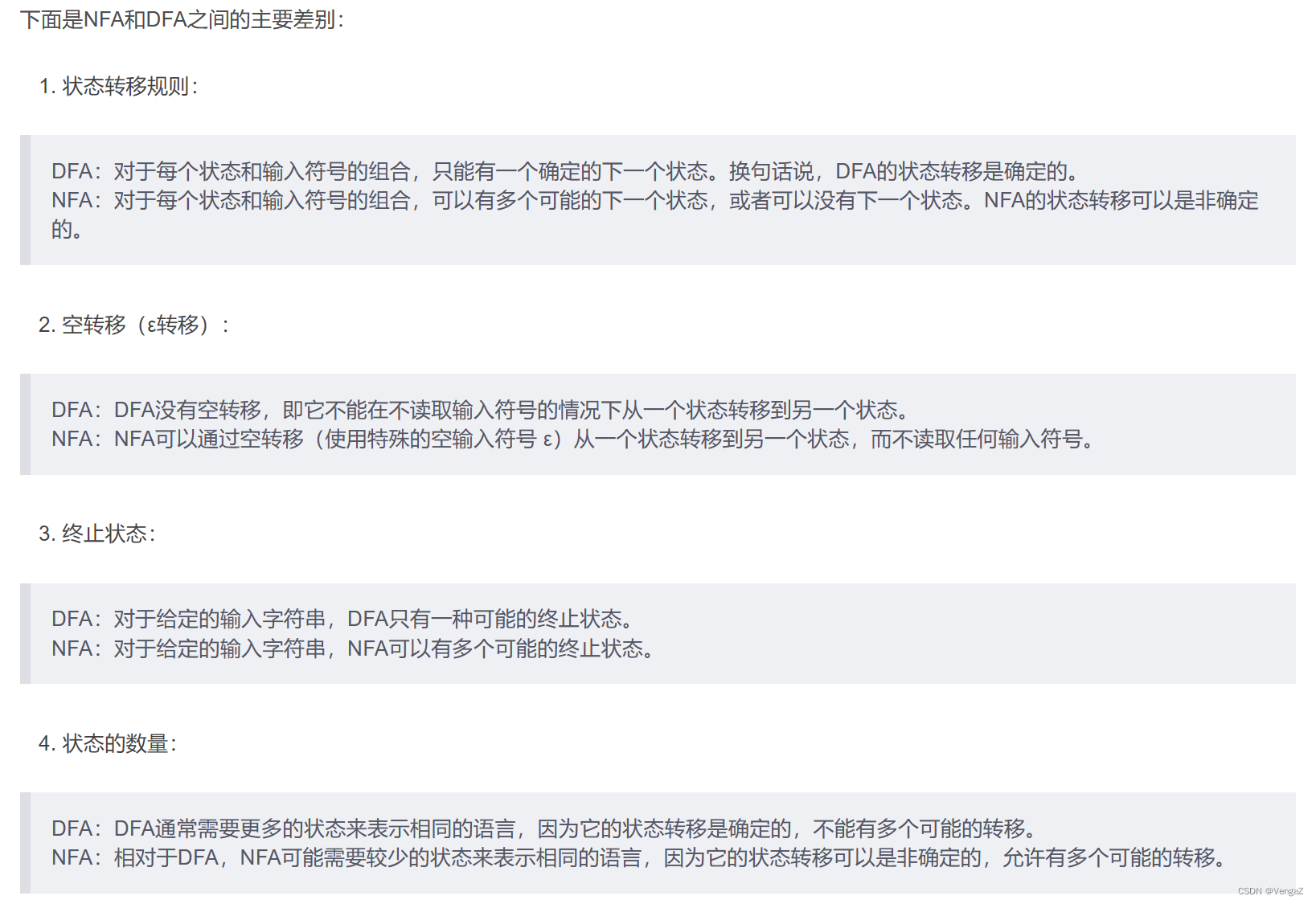
NFA跟DFA的主要差别
词法错误检测
如果当前状态与当前输入符号在转换表对应项中的信息为空,而当前状态又不是终止状态 ,则 调用错误处理程序。


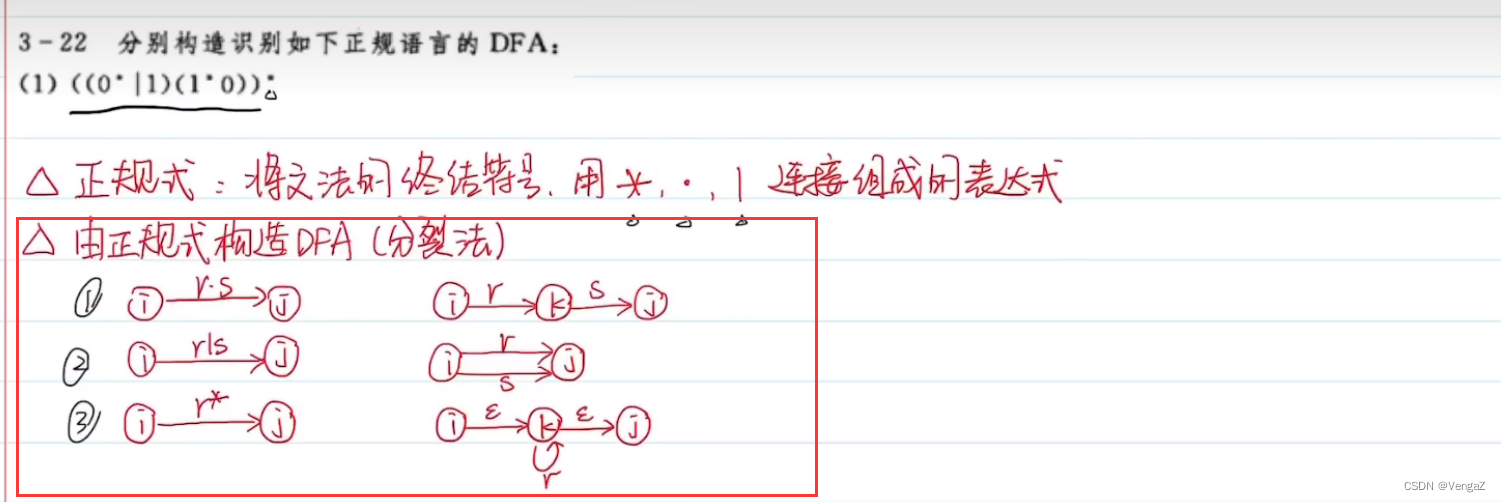
正规式构造NFA

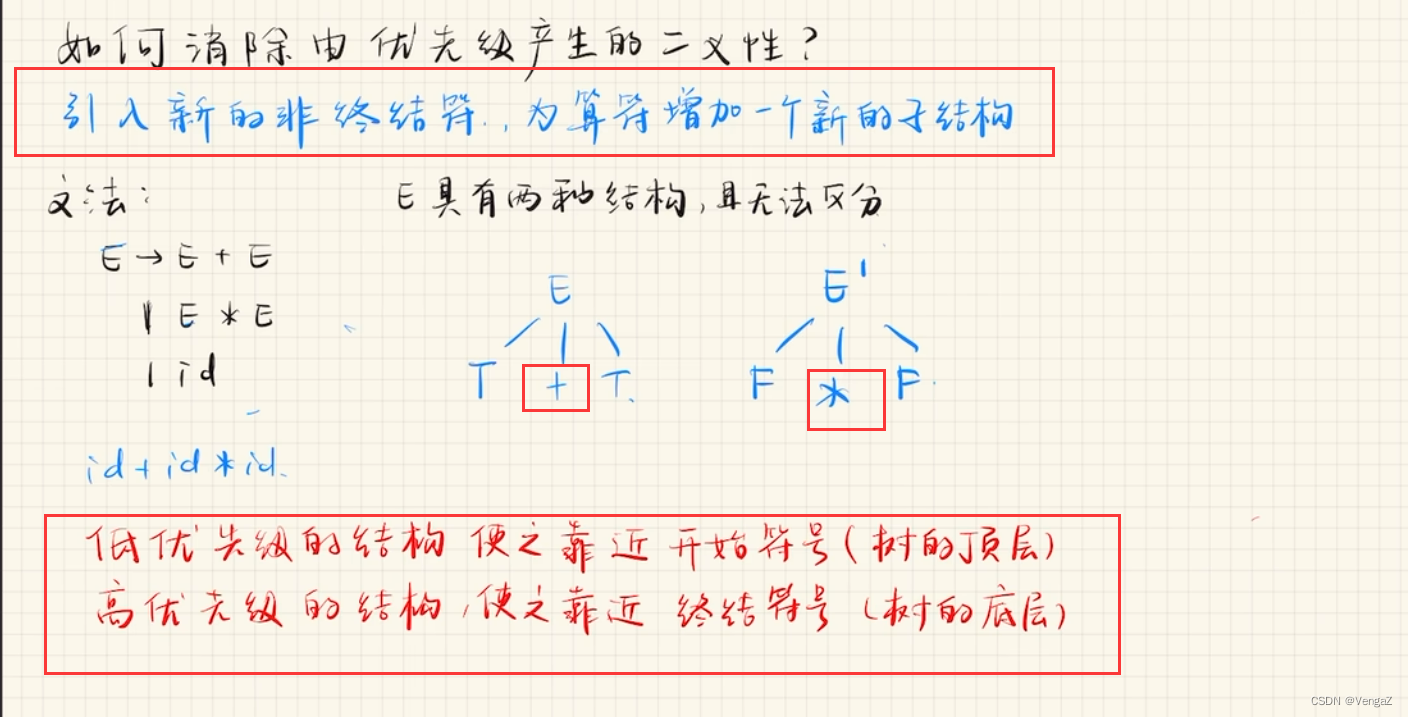
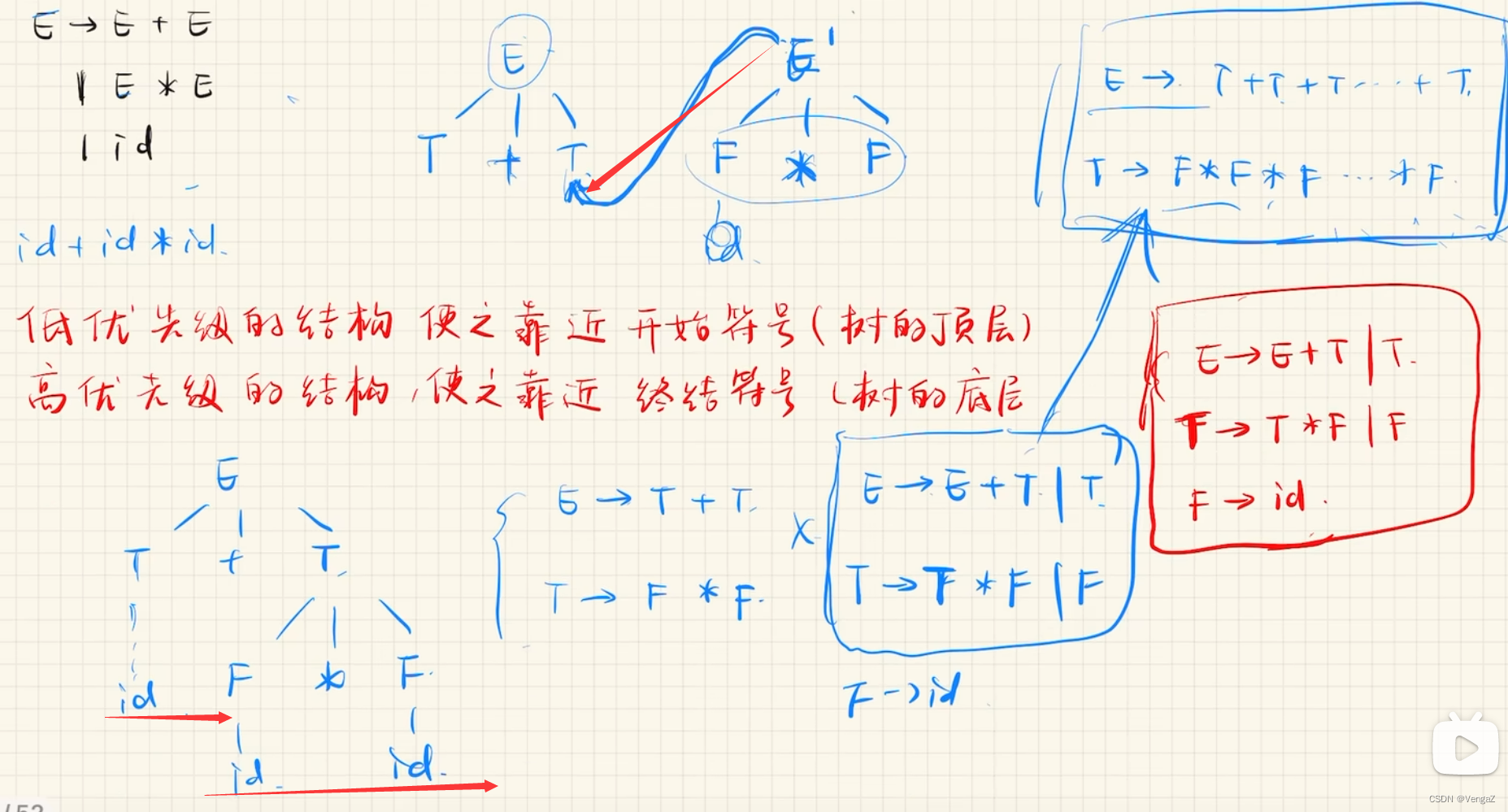
二义性消除



第四章 语法分析和语法分析程序

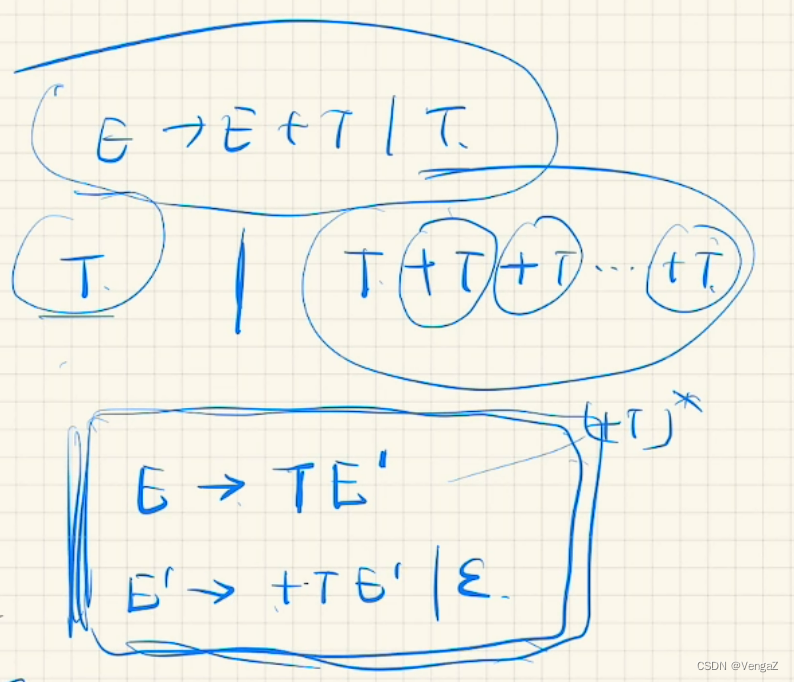
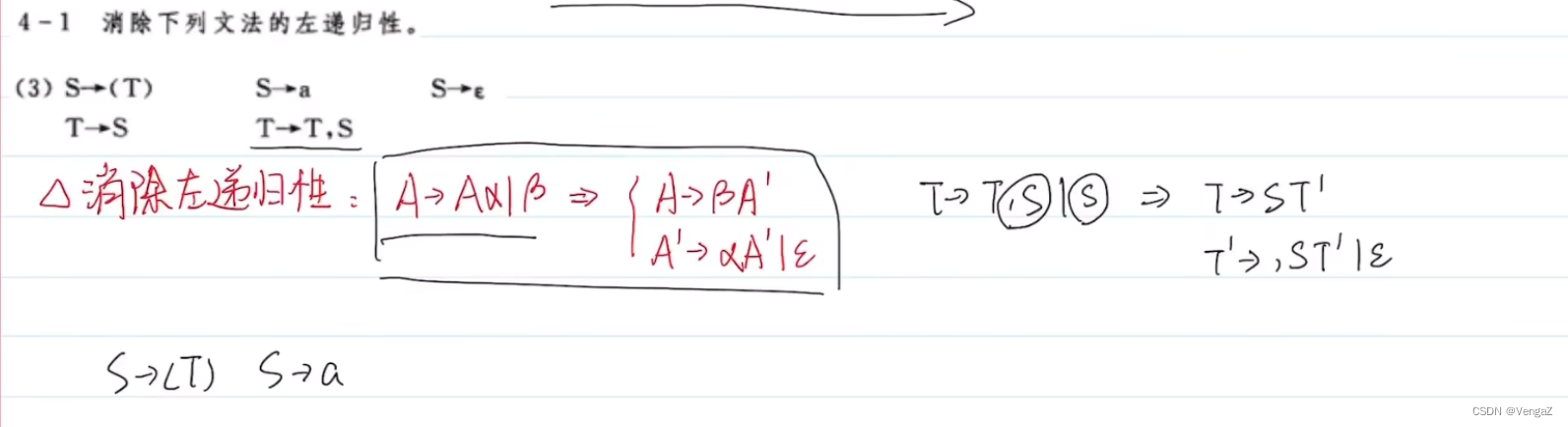
1. 消除左递归
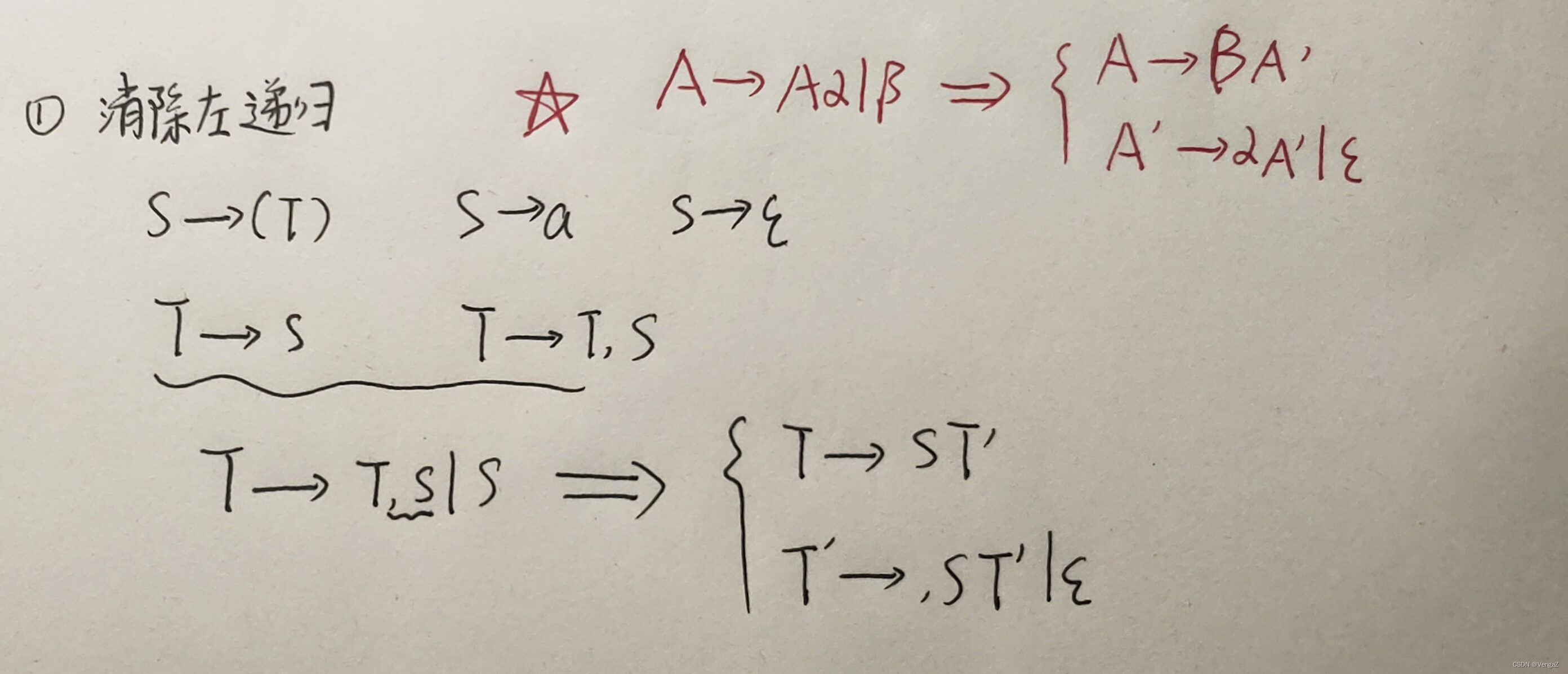
左递归文法的改造(重点:消除左递归,算法)
-
左递归缺点:容易产生死循环
-
消除直接左递归
若某个文法中非终结符A的产生式规则是直接左递归规则:A→Aα|β,其中α,β∈(VN∪VT)*。若β不以A打头,则将A的产生式规则改写为:A→βA’,A’→αA’|ε。A’是新增加的非中介符号。
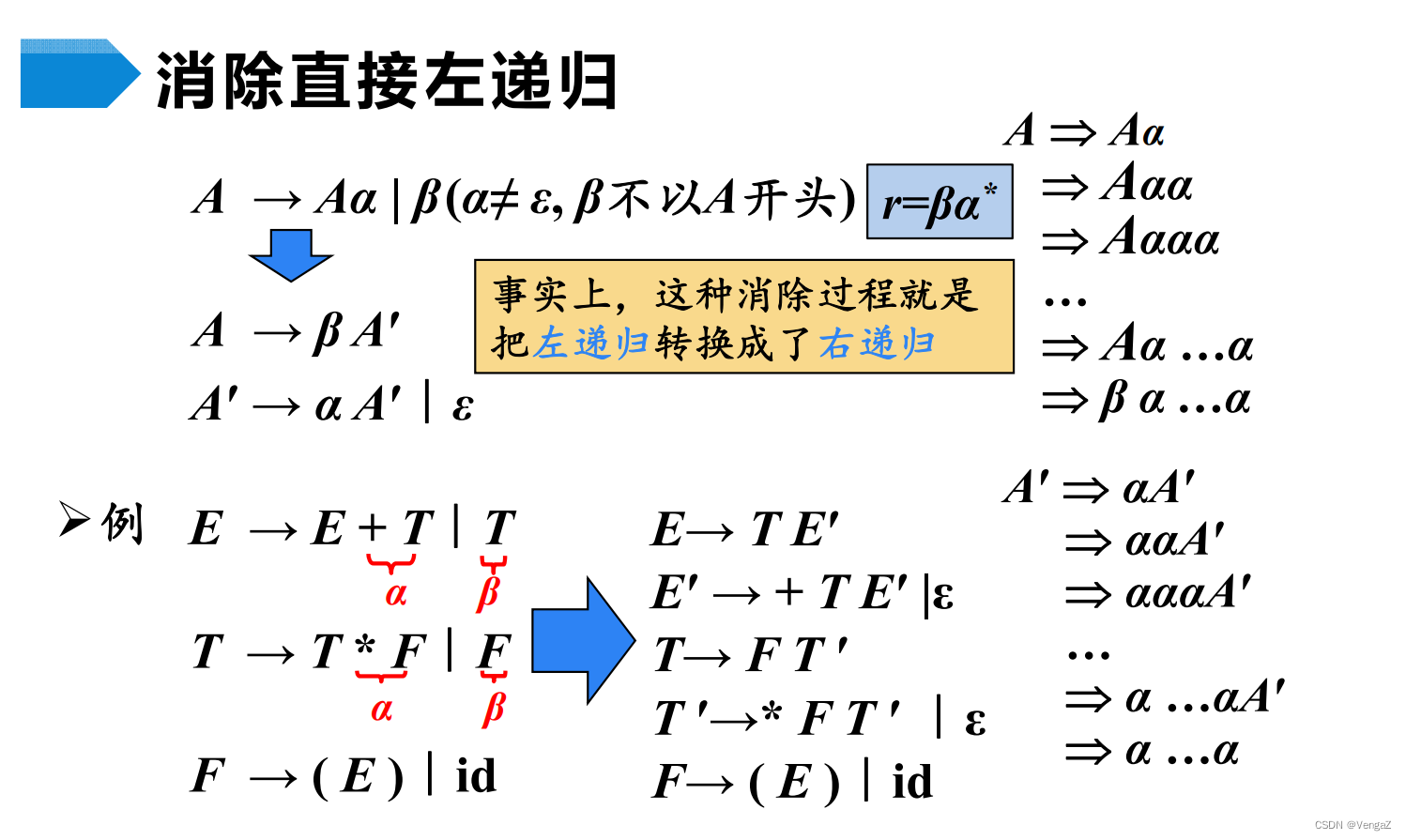
推广:若A的全部产生式规则为:A→Aα1| Aα2|…|Aαm|β1|β2|…|βn,其中βi(1≤i≤n)不以A开头,且αi(1≤i≤m)不等于ε,则A的产生式规则改写为:A→β1A’|β2A’|…|βnA’, A’→α1A’|α2A’|…αmA’|ε。
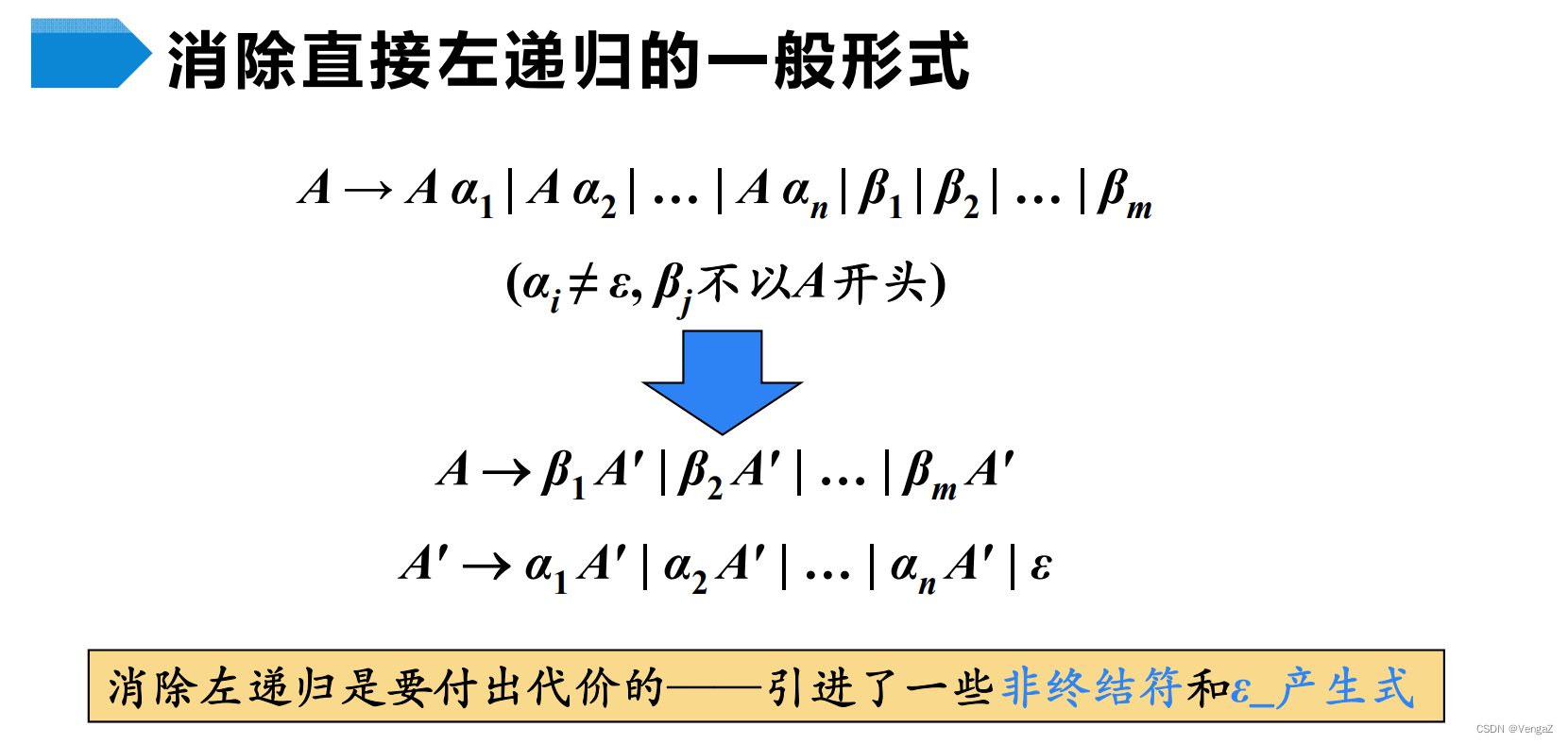

eg:设有文法G[Z]:
E→E+T|E-T|T
T→TF|T/F|F
F→(E)|i
消除非终结符E,T的直接左递归后,文法G[Z’]改写为:
E→TE’
E’→+TE’|-TE’|ε
T→FT’
T’→FT’|/FT’|ε
F→(E)|i
- 消除间接左递归
1)对文法G的非终结符号按任一种顺序排列成A1,A2,…,An。
2)依次对各非终结符号对应的产生式进行左递归的消除:
for(j=1;j<=n;j++)
for(k=1;k<=j-1;k++){
i)把每个形如Aj→Akα的规则改写为Aj→δ1α|δ2α|…|δmα。其中Ak→δ1|δ2|…|δm是关于当前Ak的产生式规则;
ii)消除关于产生式规则Aj的直接左递归;
}
3)进一步化简消除左递归之后的新文法,删去多余的产生式规则。
eg:设有文法G[S]:
S→Sa|Tbc|Td
T→Se|gh
将非终结符号排成顺序为S,T
消除产生式S左递归:
S→(Tbc|Td)S1
S1→aS1|ε
对T→Se|gh,将S代入展开得:
T→T(bc|d)S1e|gh
消除产生式T左递归:
T→ghT1
T1→(bc|d)S1eT1|ε

-
回溯的消除
1)提取左因子。
若有A→αβ1|αβ2|…|αβ1|γ,其中γ不是以α开头的候选式,则A的产生式规则可替换为A→αA‘|γ,A’→β1|β2|…|βn。A’是一个新的非终结符号。


2)消除左递归。
2. FIRST FOLLOW SELECT集



串首终结符集(FIRST)


a都是非终结符,并且每个都能推出空


如果Y1能推导出空,则将Y2的First集加入X的first集中(相当于y1是空,串首是y2…)
若yi都能推出空,则将空加入x的first集
如下:

后继符号集(FOLLOW)



可选集(SELECT)

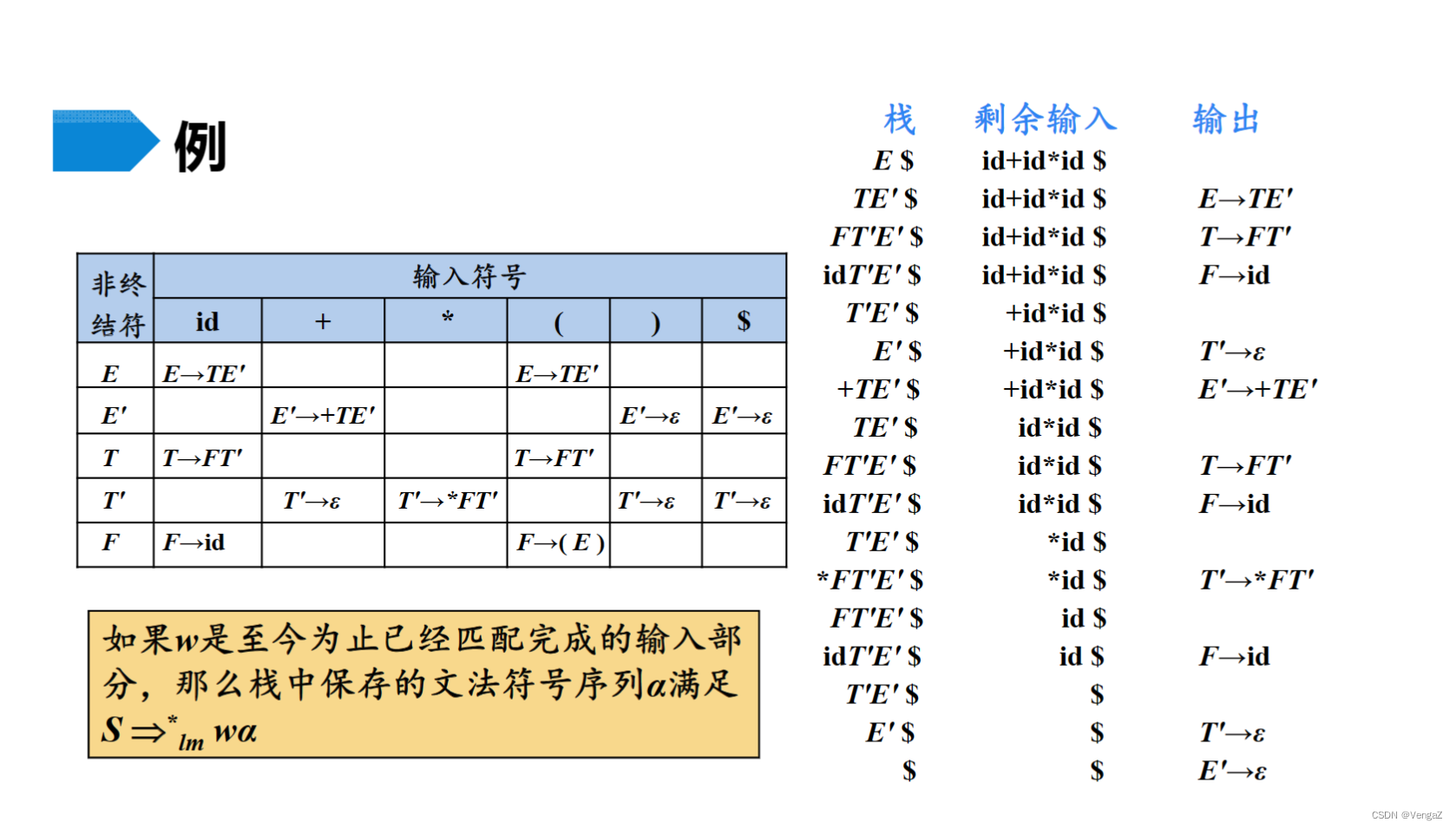
产生式右部第一个非终结符的FIRST集的终结符(第一个是非终结符);或者是第一个终结符本身(第一个是终结符的情况);或者是空的话,则是产生式左部的FOLLOW集
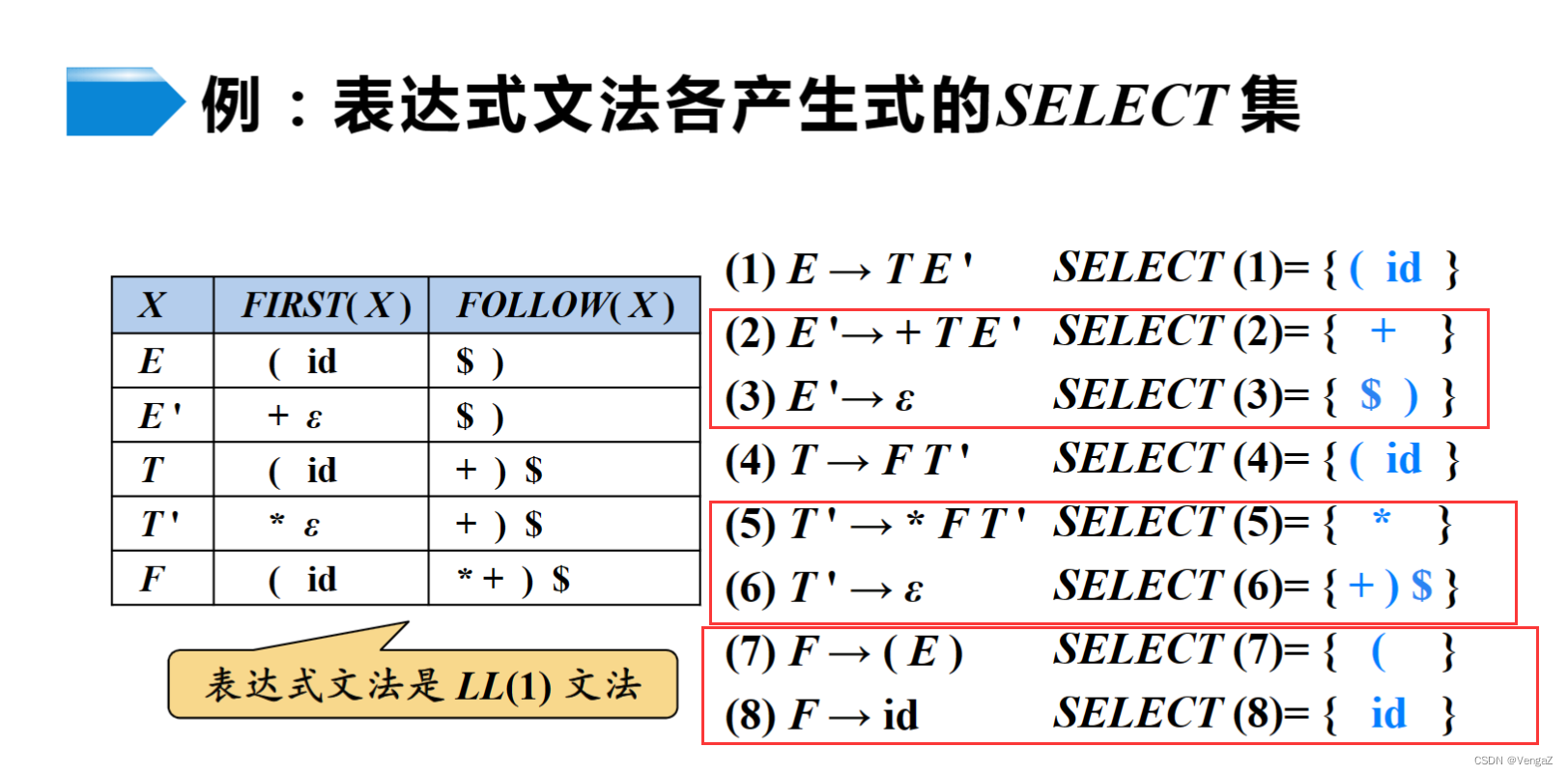
相同左部SELECT集互不相交
3. 判断LL(1)文法

select集相同左部,右部不相同
例1


例2
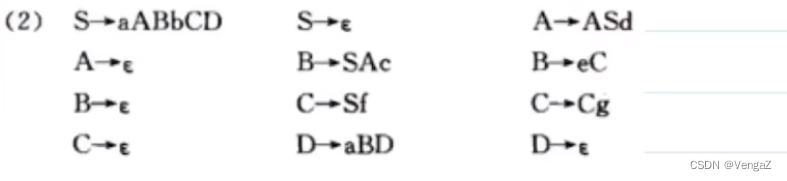

4. LR(0)分析
第一个项目的文法左部是,前一个产生式右边第一个非终结符

. 后边是是终结符号就是移进项目,非终结符号就是待约项目
不能有移进规约冲突以及规约规约冲突

增广文法

例子 LR(0)自动机
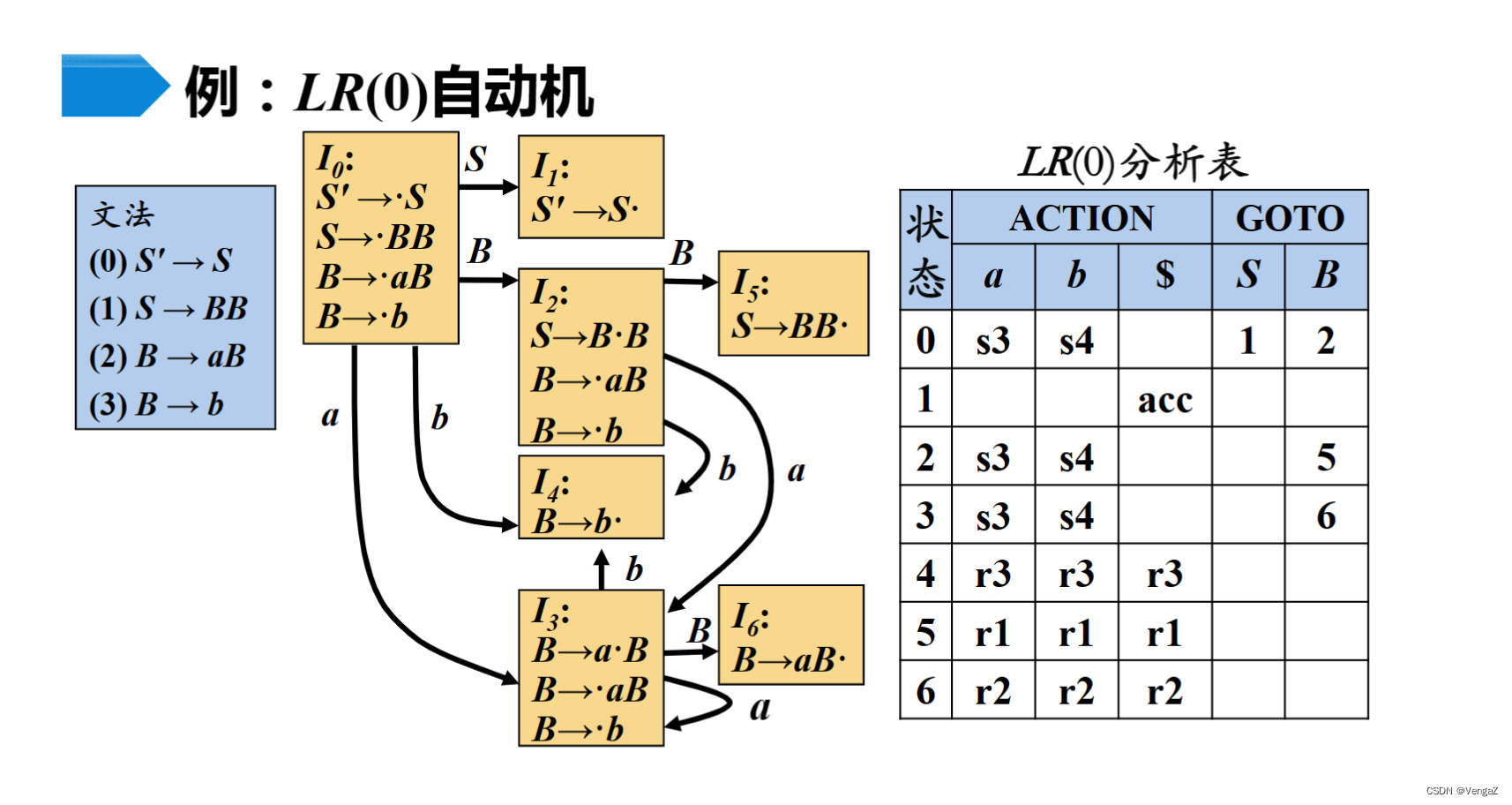
遇到终结符则式ACTION 非终结符则是GOTO
理解为遇到终结符需要移进,遇到非终结符是待约项目
然后因为每一个项目(一个方框)里,不同时存在两个规约项目,也不同时存在一个规约一个移进项目(有规约则是单独的一个项目,有移进的则无规约)
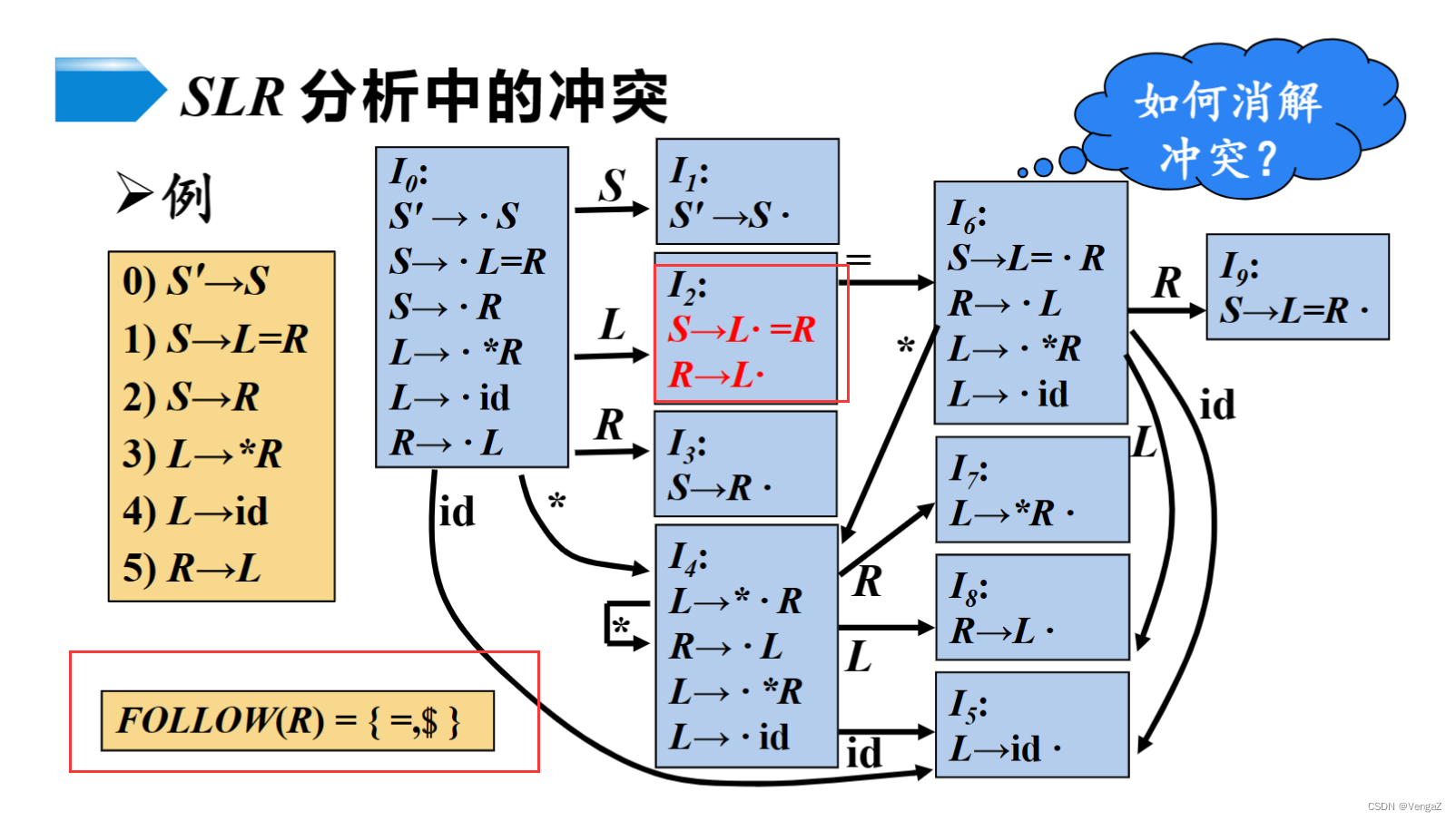
5. SLR(1)
SLR分析
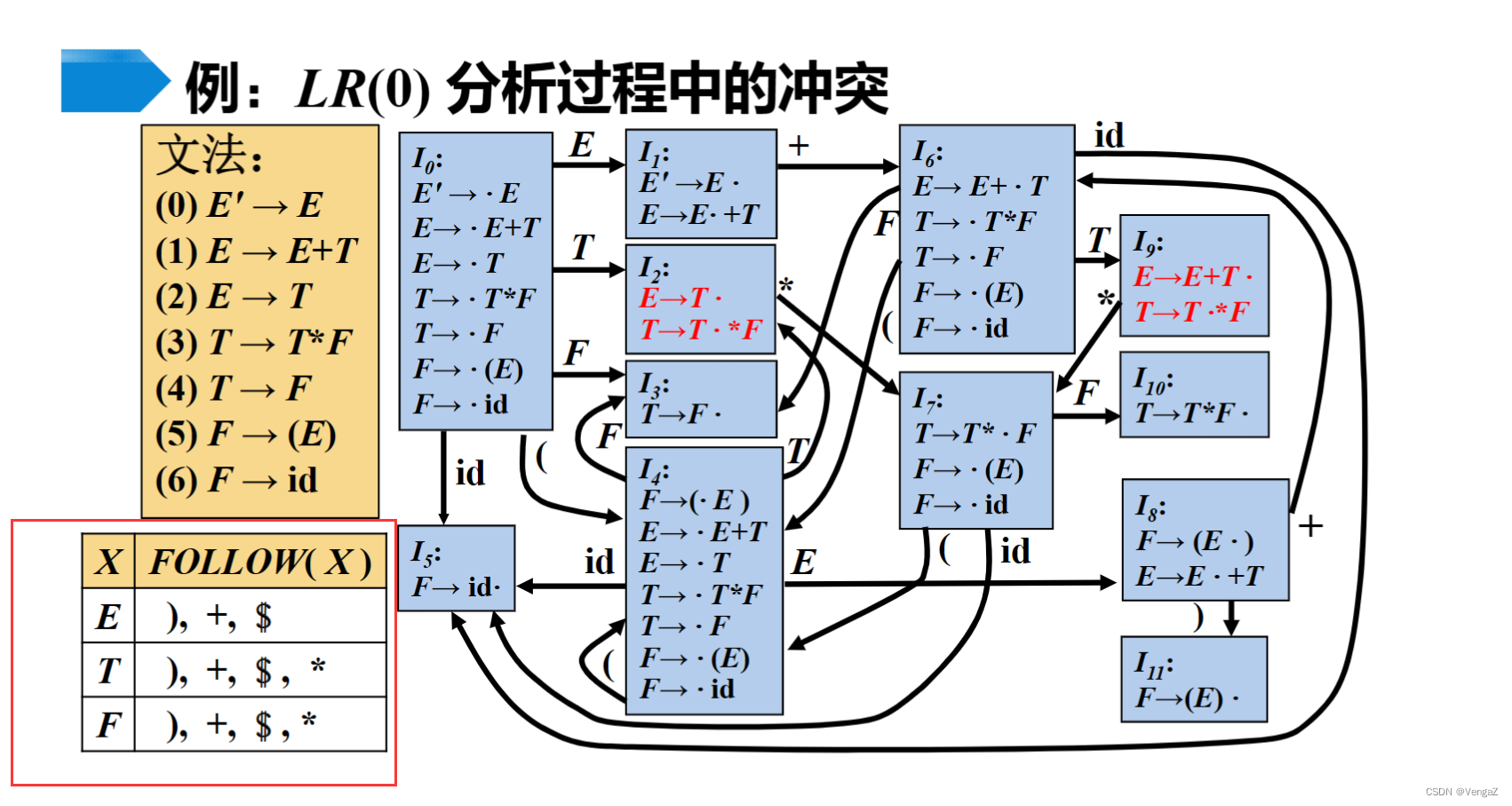
新增的LOLLOW集,说明就算规约了,E的FOLLW集也没有·*,所以就算规约了,也不能出现 * 故不能规约
借助FOLLOW集判定什么时候不能进行规约

例子

根据状态2冲突的B和T,对比他们的FOLLOW集,写出对应的ACTION
SLR分析中的冲突
移入规约冲突
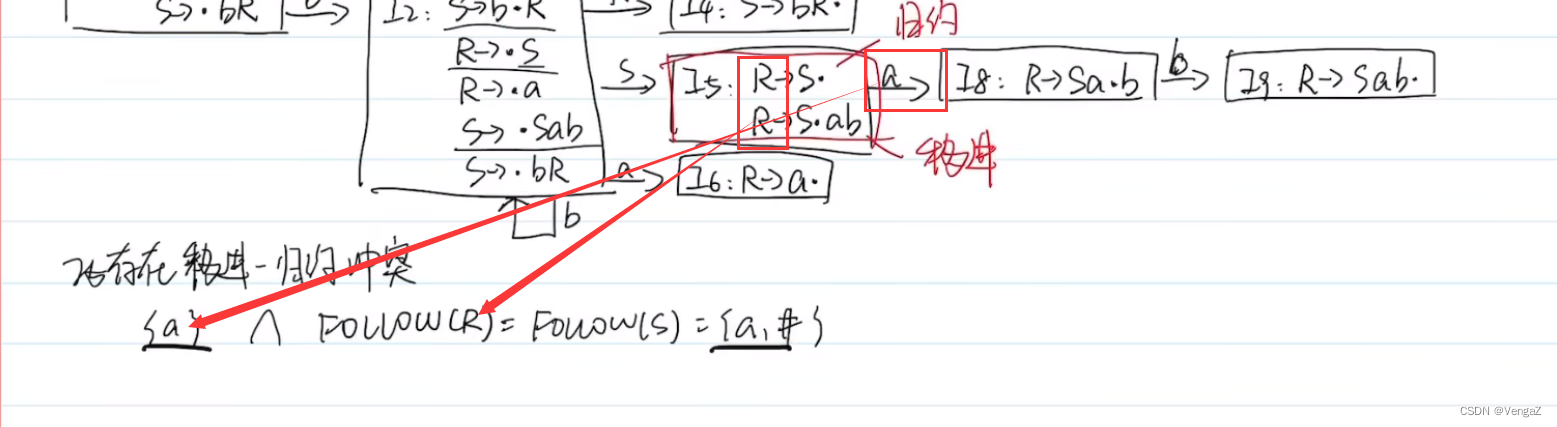
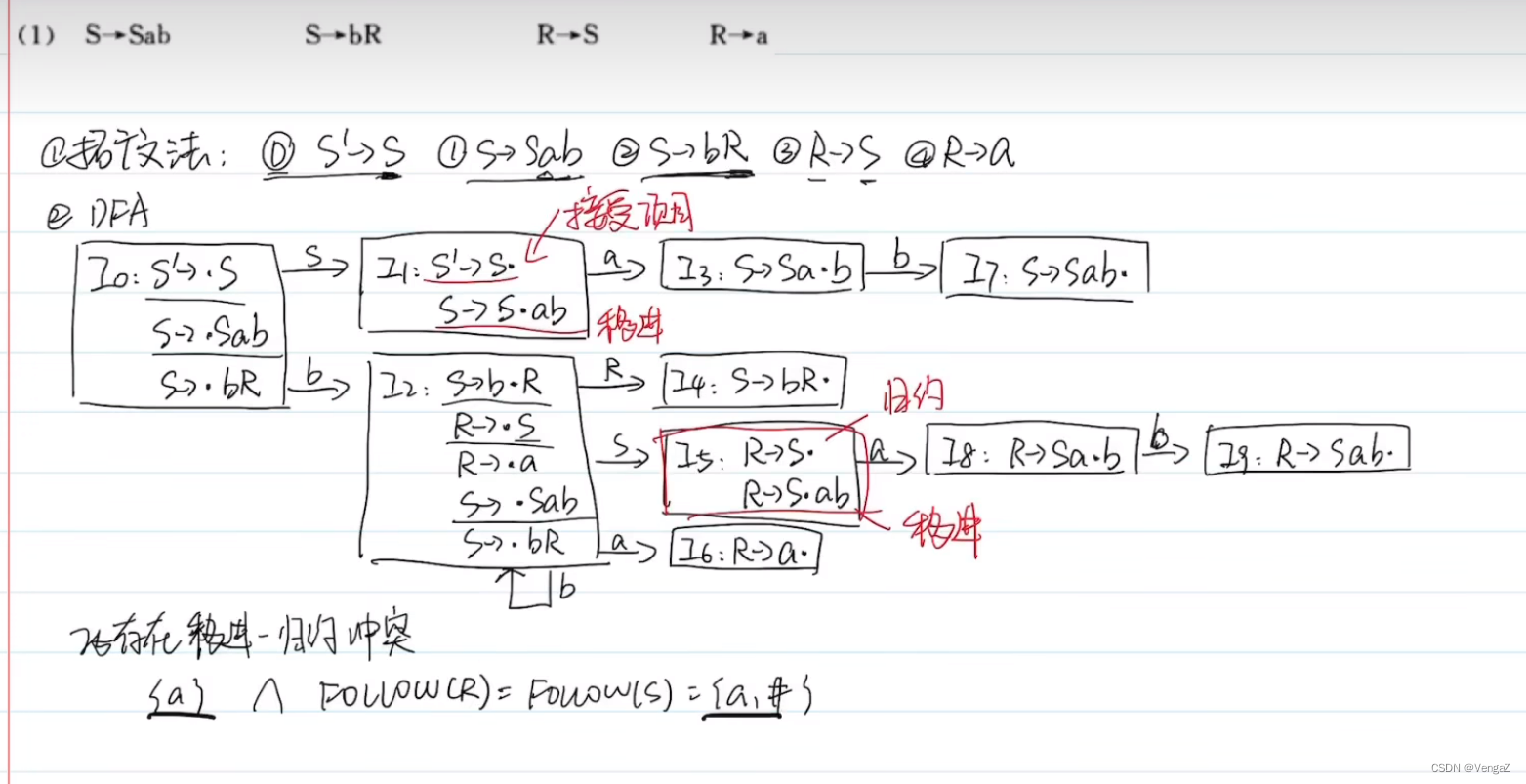

所以需要引入功能更加强大的分析法
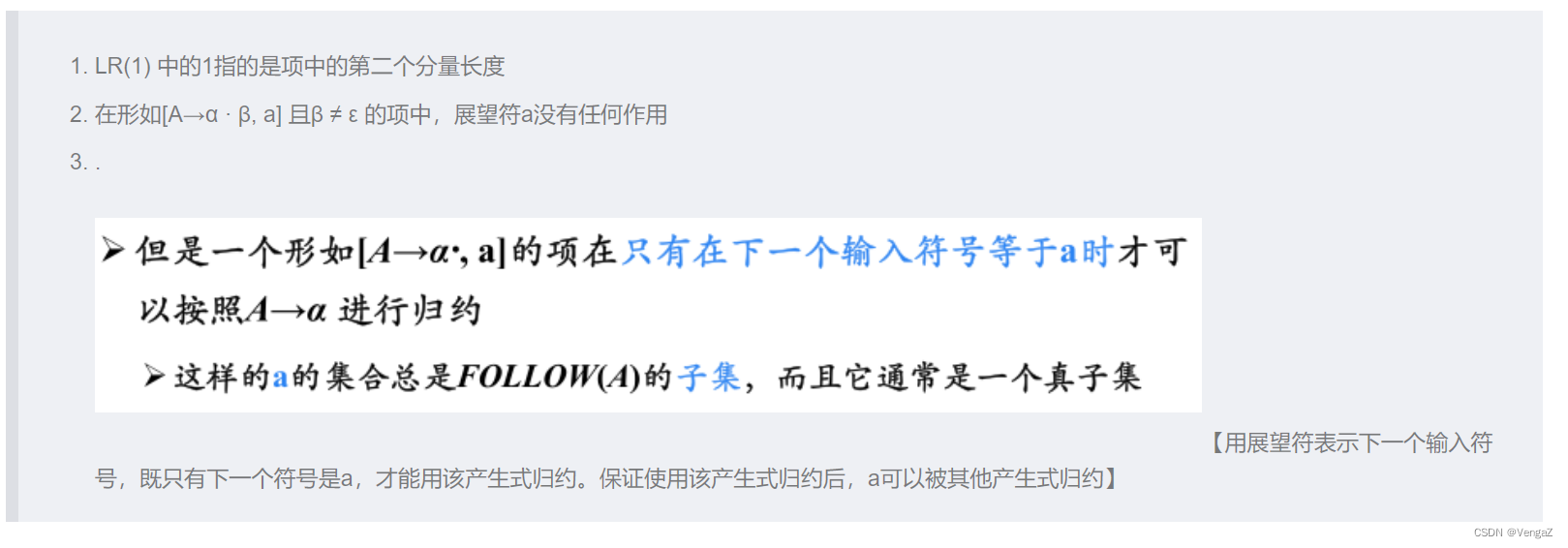
6. LR(1)分析
完整大题1

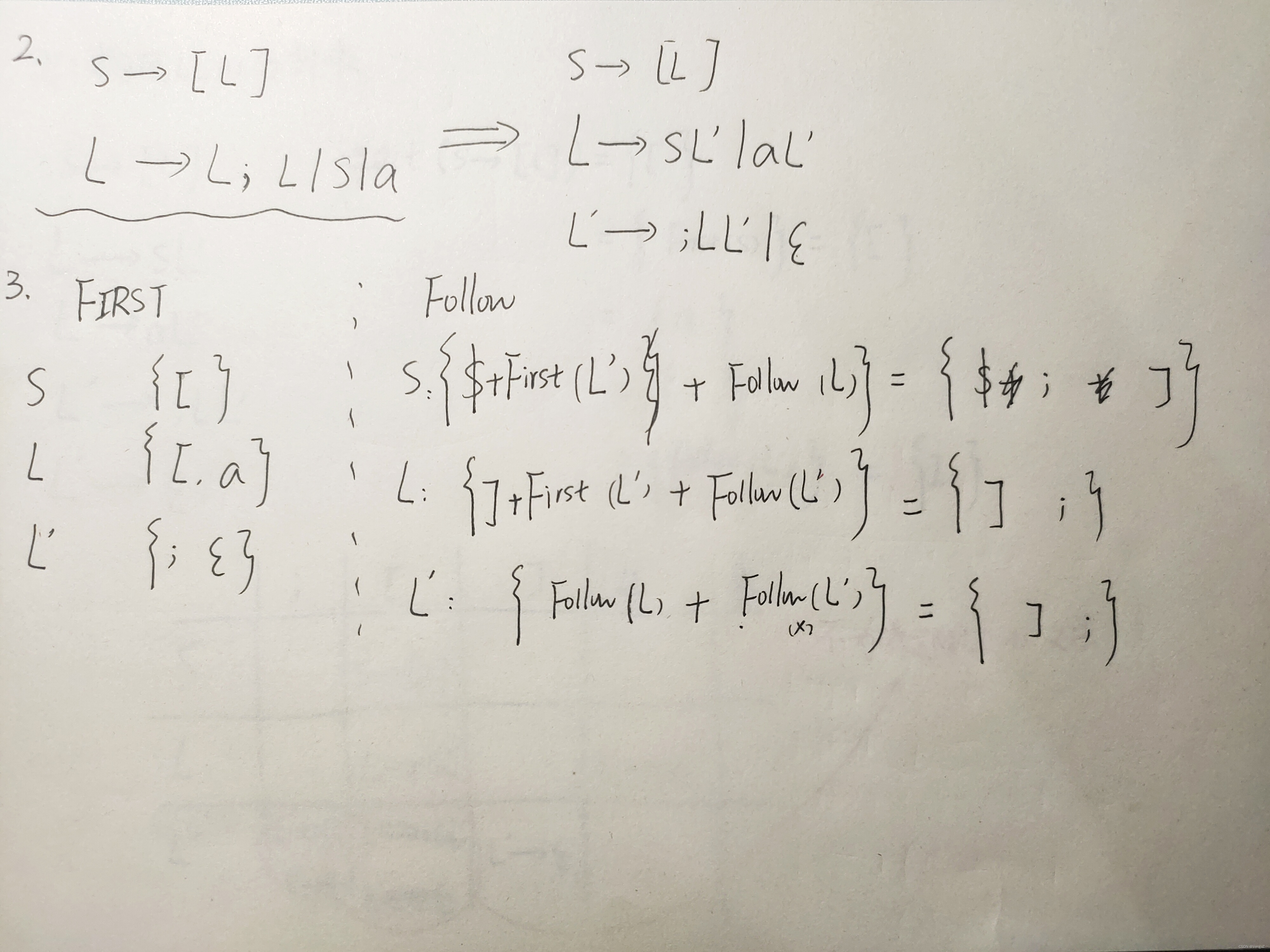


预测分析程序的工作原理
- 预测分析器的组成:一张预测分析表M(LL(1)分析表)、一个栈、一个预测分析控制程序、一个输入缓冲区、一个输出流。
下推自动机(PDA)
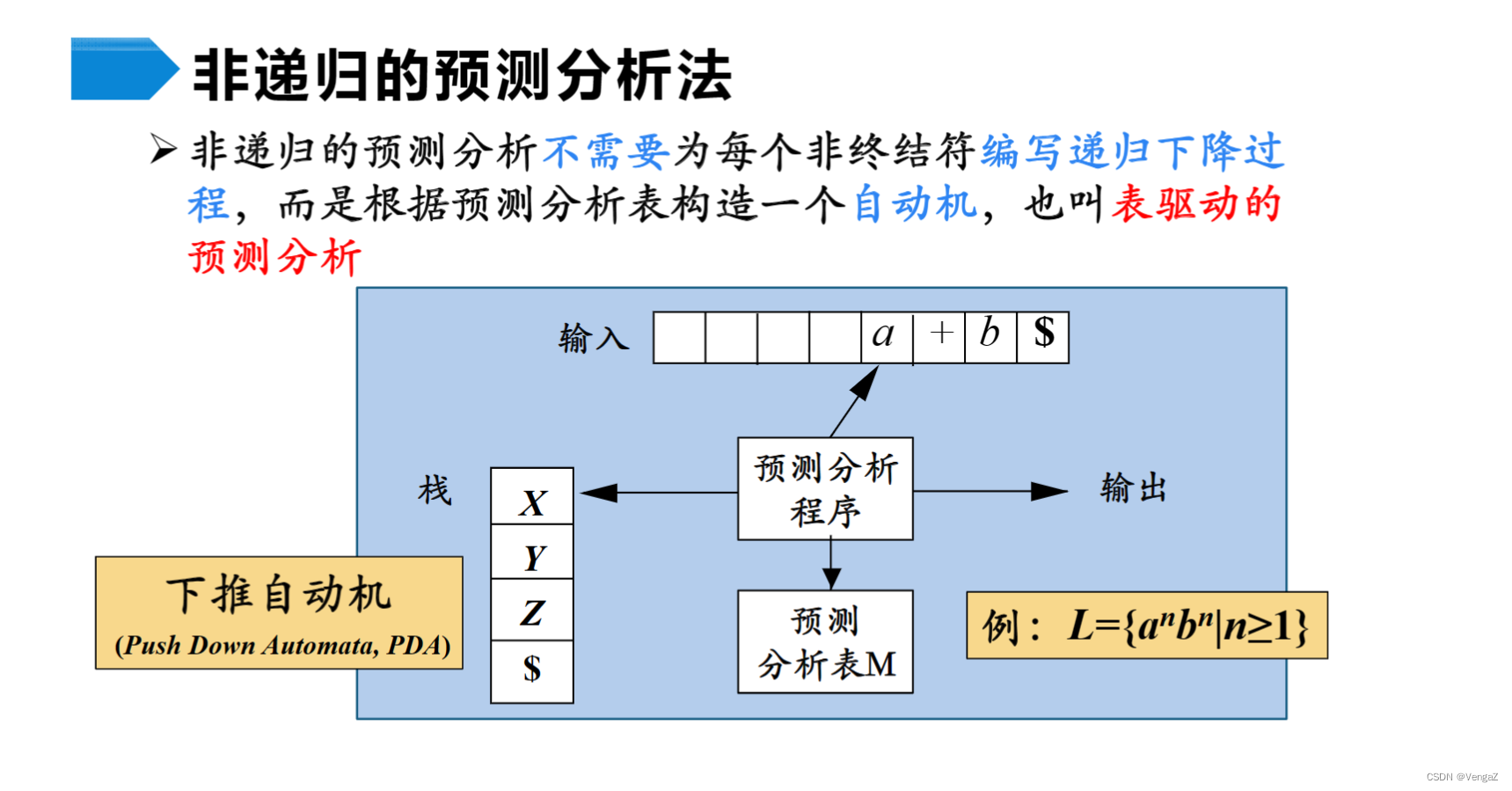
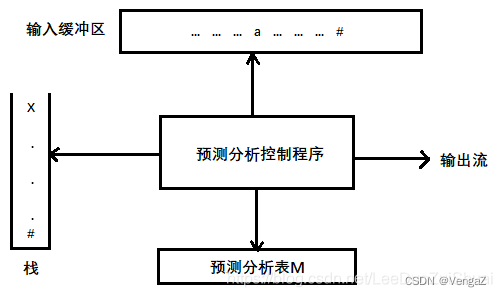
1)输入缓冲区:存放待分析的输入符号串,其后以符号#/$作为结束符。
2)栈:存放替换当前非终结符的某个产生式规则的右部符号串,栈底的符号为#。
3)预测分析表:一张二维表,行为非终结符号,列为终结符号,其元素形式为M[S,a],表中元素M[S,a]存放一条产生式规则或相应的出错处理程序的入口地址(分析出错时)。其中,M[S,a]表示当前栈顶S面对当前向前看符号a应采取的动作。
- 预测分析器的工作原理:#和文法开始符号进栈,从输入缓冲区读进输入符号a,弹出栈顶元素给X:
1)若X=a=’#’,则分析器工作结束,分析成功。
2)若X=a≠‘#’,则分析器把X从栈顶弹出,让输入指针指向下一个输入符号。
3)若X是一个非终结符号,则查阅预测分析表M。若在M[X,a]中存放着关于X的一个产生式规则,则先把X弹出,再把产生式规则右部符号串按逆序一一压入栈中。若M[X,a]={X→ε},则预测分析器把在栈顶的X弹出。若M[X,a]=error,则调用出错处理程序。

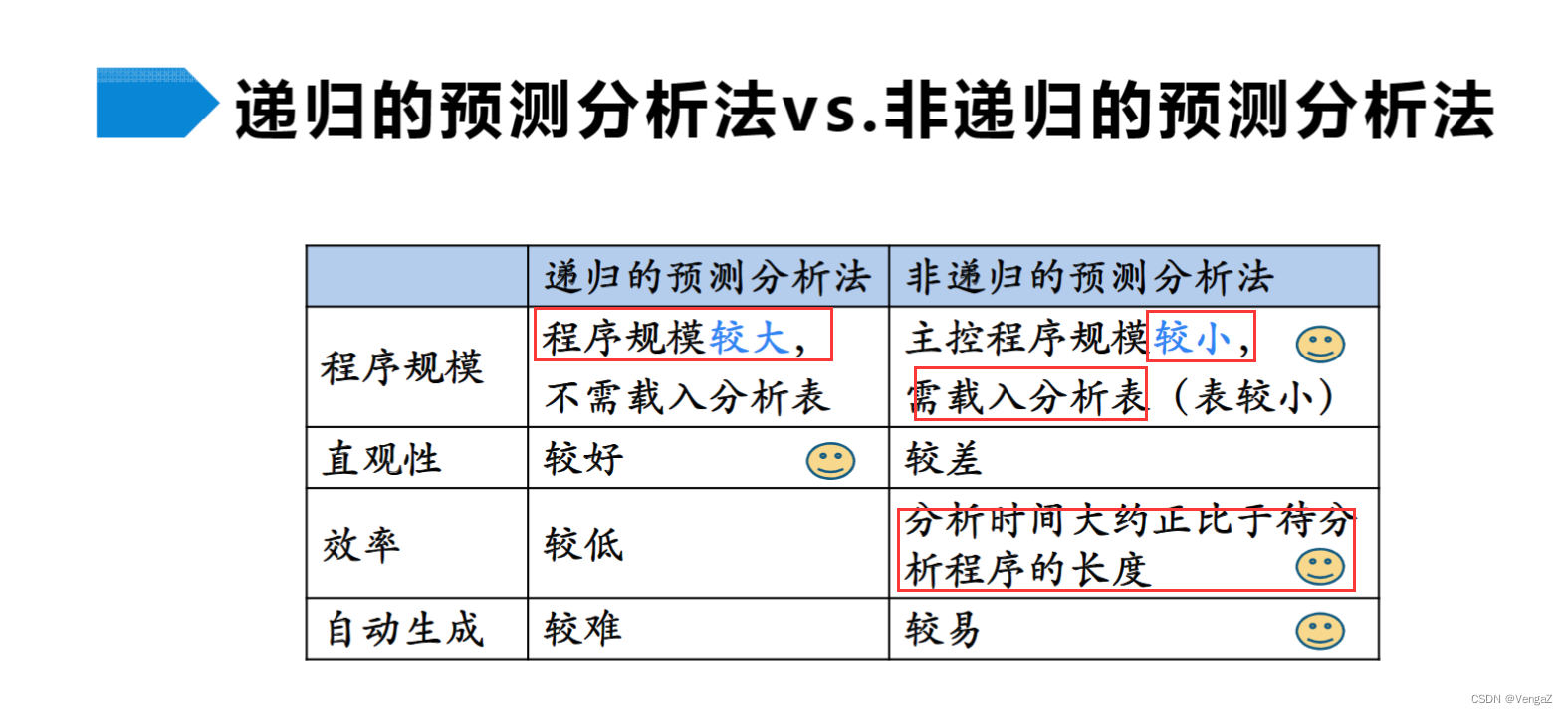
递归的预测分析法与非递归的预测分析法的比较
- 递归的预测分析法是根据产生式右部编写程序,所以直观性较好;
- 递归的预测分析法是根据产生式右部编写程序,所以不好自动生成,非递归的预测分析法是根据自动机生成,所以较易自动生成

第五章 语法制导翻译以及中间代码生成
1. 逆波兰式(后缀表达式)


2. 四元式




















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











