







 文章介绍了语法分析器在编译器中的关键作用,包括检测和处理语法错误。它详细讨论了错误检测、错误恢复,如插入或删除符号、符号替换和同步点恢复等策略。还提供了一个使用PythonPLY库实现简单语法分析器的代码示例。
文章介绍了语法分析器在编译器中的关键作用,包括检测和处理语法错误。它详细讨论了错误检测、错误恢复,如插入或删除符号、符号替换和同步点恢复等策略。还提供了一个使用PythonPLY库实现简单语法分析器的代码示例。
概述
语法分析器的任务是根据给定的文法规则和输入的源代码,检查源代码的语法是否符合规定的语法结构,并生成相应的语法树(或抽象语法树)用于后续的语义分析和代码生成。
语法错误的处理是语法分析器的重要任务之一,它涉及到发现和报告源代码中的语法错误,并提供有关错误的有用信息,以帮助程序员进行修复。
下面是常见的语法错误的处理方式:
-
错误检测:语法分析器通过分析输入的源代码,检测是否存在语法错误。如果发现错误,语法分析器会产生相应的错误信息。
-
错误恢复:当遇到语法错误时,语法分析器可以尝试进行错误恢复,以继续进行后续的分析。常见的错误恢复策略包括:
-
插入或删除符号:在错误位置插入或删除缺失的符号,使得语法分析可以继续进行。这种策略通常用于处理缺失的分隔符或关键字等简单错误。
-
符号替换:将错误的符号替换为一个或多个可能的正确符号,以使语法分析可以继续进行。这种策略通常用于处理错误的标识符或表达式等复杂错误。
-
同步点恢复:在发现错误后,语法分析器可以跳过一些输入符号,直到找到一个可以作为继续分析的同步点。同步点可以是某个关键字、分隔符或特定的语法结构。
-
错误信息报告:语法分析器应该提供清晰和有用的错误信息,包括错误类型、错误位置和可能的修复建议。这些信息可以帮助程序员快速定位和修复语法错误。
-
语法分析器的任务是尽可能地检测和处理语法错误,以确保源代码的语法正确性。然而,有些语法错误可能无法自动修复,需要由程序员手动进行修复。因此,在编写代码时,遵循正确的语法规则和及时修复语法错误是非常重要的。
代码示例
语法分析器的任务是根据给定的语法规则,对输入的代码进行分析和解析,以确定代码是否符合语法规则。语法分析器通常使用语法规则表示的上下文无关文法(Context-Free Grammar)来进行分析。
语法错误的处理通常包括以下几个方面:
-
错误检测:语法分析器会检测输入代码中是否存在语法错误。当遇到不符合语法规则的部分时,会触发错误处理机制。
-
错误恢复:一旦发现语法错误,语法分析器会尝试进行错误恢复,以继续分析后续的代码。常见的错误恢复策略包括插入或删除符号、跳过错误的代码片段等。
-
错误报告:语法分析器会生成错误报告,将发现的语法错误信息提供给用户或开发人员。错误报告通常包括错误类型、错误位置、错误描述等信息,以帮助定位和修复错误。
以下是一个简单的示例,演示如何使用Python中的PLY(Python Lex-Yacc)库实现一个简单的语法分析器,该分析器可以识别简单的四则运算表达式:
import ply.yacc as yacc
from lexer import tokens
# 语法规则
def p_expression(p):
'''
expression : expression '+' term
| expression '-' term
| term
'''
if len(p) == 4:
if p[2] == '+':
p[0] = p[1] + p[3]
else:
p[0] = p[1] - p[3]
else:
p[0] = p[1]
def p_term(p):
'''
term : term '*' factor
| term '/' factor
| factor
'''
if len(p) == 4:
if p[2] == '*':
p[0] = p[1] * p[3]
else:
p[0] = p[1] / p[3]
else:
p[0] = p[1]
def p_factor(p):
'''
factor : '(' expression ')'
| NUMBER
'''
if len(p) == 4:
p[0] = p[2]
else:
p[0] = p[1]
def p_error(p):
print("Syntax error")
# 构建语法分析器
parser = yacc.yacc()
# 输入待分析的代码
code = "3 + 4 * (2 - 1)"
# 执行语法分析
result = parser.parse(code)
print(result)
在这个示例中,使用PLY库定义了语法规则,包括表达式、项和因子的定义。通过使用p_expression、p_term和p_factor等函数来表示语法规则,并在函数体中实现语法动作。p_error函数用于处理语法错误。
然后,使用yacc.yacc()函数构建语法分析器,并通过`parser
.parse()`方法将待分析的代码传递给语法分析器进行解析。最后,将解析结果打印出来。
语法分析器是编译器前端的核心
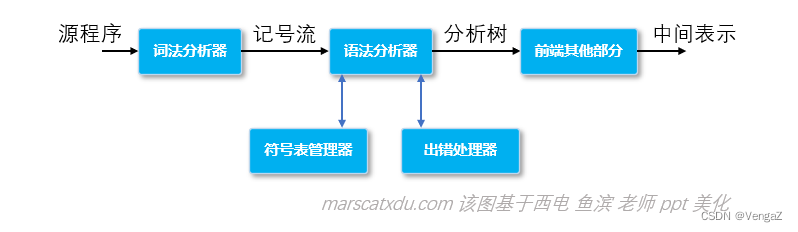
语法分析器的两项主要任务,分别:
- 是根据词法分析器提供的记号流,为语法正确的输入构造分析树(或语法树);
- 检查输入中的语法 / 词法错误,并调用出错处理程序进行相应的处理。
语法错误的处理
源程序中的错误可以分为词法/语法错误、语义错误两类。前者主要形式是命名不合法、关键字书写错误、语法结构有问题(比如缺分号、该配对的东西不配对)等;后者则可分为静态/动态两种,静态例如类型使用错误、参数使用错误等,动态语义错误则是无穷递归这类逻辑性的问题。
语法错误的处理目标
- 不多不漏地报告所有错误出现的准确位置;
- 发现一个错误后能够继续分析,做到一次分析完整个程序,再一次性指出所有错误;
- 尽量小地降低分析速度(分析速度和扫描遍数有关)。
语法错误的基本恢复策略
- 紧急恢复:抛弃掉一些输入,直到遇到同步记号;
- 短语级恢复:对错误进行串替换,纠正错误;
- 出错产生式:用出错产生式捕捉(预测)错误;
- 全局纠正:找到和错误输入序列 x 最相近的序列 y,然后用 y 替换掉 x 。
例如:
x = a+b
y = c+d;
紧急恢复:x = a+b+d; // 丢弃掉 b 后的记号,直到遇到 +
短语级恢复: x = a+b; // 加入分号
在写程序时,要养成减少错误的好习惯:每次用变量、参数时,要在使用之前进行初始化,并在直接使用之前检查一下是否出现值为空等问题,防止出现不可预知的错误



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











