






本文为数据挖掘课程的大作业报告,选题为ANN人工神经网络算法。由于本人技术水平有限,在代码实现过程中有可能存在错误,本项目已开源,敬请指正!
目录
1. 算法说明
1.1 算法原理
人工神经网络(artificial neural network,ANN)简称神经网络(neural network,NN)或类神经网络,在机器学习和认知科学领域,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统,通俗地讲就是具备学习功能。现代神经网络是一种非线性统计性数据建模工具,神经网络通常是通过一个基于数学统计学类型的学习方法(learning method)得以优化,所以也是数学统计学方法的一种实际应用,通过使用统计学的标准数学方法,就能够得到大量的可以用函数来表达的局部结构空间,另一方面在人工智能学的人工感知领域,也可以通过数学统计学的应用来做人工感知方面的决定问题,也就是说通过统计学的方法,人工神经网络能够类似人一样具有简单的决定能力和简单的判断能力,这种方法比起正式的逻辑学推理演算更具有优势。
人工神经网络这个概念是由对人类中枢神经系统的观察启发的。在人工神经网络中,简单的人工节点,称作神经元(neurons),连接在一起形成一个类似生物神经网络的网状结构。
人工神经网络有两个基本特征:
- 具有一组可以被调节的权重(被学习算法调节的数值参数)
- 可以估计输入数据的非线性函数关系
在ANN算法中,最核心的几个概念是神经元、神经网络组成、反向传播算法等,下面将一一介绍。
1)神经元(neurons)
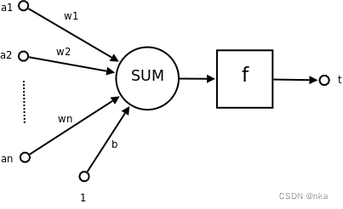
- a1~an为输入向量的各个分量
- w1~wn为神经元各个突触的权重值(weight)
- b为偏置(bias)
- f为传递函数,通常为非线性函数。一般有traingd(),tansig(),hardlim()。以下默认为hardlim()
- t为神经元输出
数学表示![]()
-
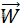 为权向量,
为权向量,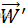 为
为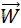 的转置
的转置 -
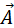 为输入向量
为输入向量 -
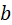 为偏置
为偏置 -
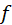 为传递函数
为传递函数
可见,一个神经元的功能是求得输入向量与权向量的内积后,经一个非线性传递函数得到一个标量结果。
单个神经元的作用就是把一个n维向量空间用一个超平面分割成两部分(称之为判断边界),给定一个输入向量,神经元可以判断出这个向量位于超平面的哪一边。
该超平面的方程: ![]() ,
, ![]() 为超平面上的向量
为超平面上的向量
2)神经网络组成
典型的人工神经网络具有以下三个部分:
a. 结构(Architecture)
结构指定了网络中的变量和它们的拓扑关系。例如,神经网络中的变量可以是神经元连接的权重(weights)和神经元的激励值(activities of the neurons)。
b. 激活函数(Activation Function)
大部分神经网络模型具有一个短时间尺度的动力学规则,来定义神经元如何根据其他神经元的活动来改变自己的激励值。一般激活函数依赖于网络中的权重(即该网络的参数)。
c. 学习规则(Learning Rule)
学习规则指定了网络中的权重如何随着时间推进而调整。一般情况下,学习规则依赖于神经元的激励值。它也可能依赖于监督者提供的目标值和当前权重的值。例如,用于手写识别的一个神经网络,有一组输入神经元。输入神经元会被输入图像的数据所激发。在激励值被加权并通过一个函数后,这些神经元的激励值被传递到其他神经元。这个过程不断重复,直到输出神经元被激发。最后,输出神经元的激励值决定了识别出来的是哪个字母。
通常来说,一个人工神经网络是由一个多层神经元结构组成,每一层神经元拥有输入和输出,每一层Layer(i)是由Ni(Ni代表在第i层上的N)个网络神经元组成,每个Ni上的网络神经元把对应在Ni-1上的神经元输出做为它的输入,通常把神经元和与之对应的神经元之间的连线叫做突触(Synapse),在数学模型中每个突触有一个加权数值,称做权重,那么要计算第i层上的某个神经元所得到的值等于每一个权重乘以第i-1层上对应的神经元的输出,然后求和得到了第i层上的某个神经元所得到的值,然后该数值通过该神经元上的激活函数(activation function,常是∑函数(Sigmoid function)以控制输出大小,因为其可微分且连续,方便差量规则(Delta rule)处理),求出该神经元的输出,注意的是该输出是一个非线性的数值,也就是说通过激励函数求的数值根据极限值来判断是否要激活该神经元。
3)反向传播算法(Back Propagation, BP)
反向传播(Backpropagation,意为误差反向传播,缩写为BP)是对多层人工神经网络进行梯度下降的算法,也就是用链式法则以网络每层的权重为变量计算损失函数的梯度,以更新权重来最小化损失函数。
反向传播算法(BP 算法)主要由两个阶段组成:激励传播与权重更新。
第1阶段:激励传播
每次迭代中的传播环节包含两步:
- 前向传播阶段:将训练输入送入网络以获得预测结果
- 反向传播阶段:对预测结果同训练目标求差(损失函数)
第2阶段:权重更新
对于每个突触上的权重,按照以下步骤进行更新:
- 将输入激励和响应误差相乘,从而获得权重的梯度
- 将这个梯度乘上一个比例并取反后加到权重上
这个比例(百分比)将会影响到训练过程的速度和效果,因此成为“训练因子”。梯度的方向指明了误差扩大的方向,因此在更新权重的时候需要对其取反,从而减小权重引起的误差。
第1和第2阶段可以反复循环迭代,直到网络对输入的响应达到满意的预定的目标范围为止。
1.2 算法用途
由于其自适应性和模拟学习的能力,ANN在各种应用领域都有着广泛的应用。
比如在计算机视觉领域,ANN被广泛应用在图像识别和视频处理等任务中,如图像分类、物体识别和人脸识别等。在自然语言处理领域,ANN可以应用于序列生成、情感分析、机器翻译、阅读理解、自动摘要等。
此外,ANN在各行各业中都有垂直应用,比如应用于软件的推荐系统中、进行天气预报、进行股价预测以及进行监控预警等。
1.3 算法优缺点
优点:
- 自适应性:ANN能够自学习和自适应,从而能够更好地处理复杂和非线性问题。
- 容错性:ANN在处理噪声数据或缺失部分数据时具有较强的鲁棒性,因为信息是分布在整个网络中的。
- 并行处理能力:ANN的结构能够进行并行处理,从而可以快速处理大量信息。
- 联想记忆功能:不同于传统的机器学习算法,ANN具备联想记忆等功能。
- 处理非结构化数据:ANN能够处理各种类型的数据,包括图像、文本、音频等非结构化数据。
缺点:
- 黑盒性:ANN被称为“黑盒”模型,不能观察其学习过程,输出结果难以解释,会影响到结果的可信度和可接受程度;
- 训练时间长:对于大规模的网络和大量的数据,ANN的训练可能需要相当长的时间,甚至可能达不到学习的目的。
- 数据量要求大:ANN需要大量数据进行训练,如果数据量较少,则可能无法获得良好的性能。
- 对初始化和参数选择敏感:ANN的性能受初始化和参数选择的影响较大。
- 参数量大:神经网络需要大量的参数,如网络拓扑结构、权值和阈值的初始值。
2 算法实现
2.1 激活函数
在神经网络中,为了解决复杂的非线性问题,需要引入非线性函数,称之为激活函数。激活函数使得神经元能够计算拟合非线性数据(否则网络的输出只是权重的线性求和),从而神经网络可以逼近其他的任何非线性函数,这样可以应用到更多非线性模型中。
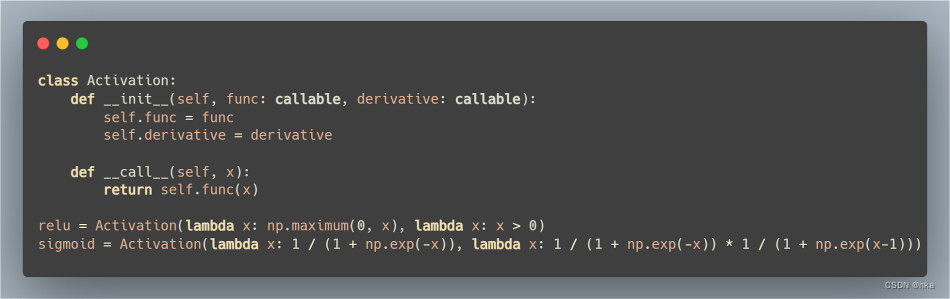
此处定义了激活函数Activation类,其有两个成员变量:
- func:激活函数,接收一个输入,使用一个函数对其进行计算并返回计算结果
- derivative:激活函数导函数,接收一个输入,计算该激活函数对该输入的导数
接着定义了两个全局变量relu和sigmoid,这两个都是神经网络中最常用的激活函数。
2.2 网络层
神经网络是由一层一层的网络层构建起来的,每层都有一个固定的输入维度(input_size)和输出维度(output_size),并且可以指定各层的激活函数。
在Layer类的初始化方法中,此处对Sigmoid和ReLU激活函数分别使用Xavier正态分布初始化方法和He初始化方法来进行权重和阈值的初始化。Xavier正态分布初始化基本思想是通过网络层时,输入和输出的方差相同,包括前向传播和后向传播。Xavier在Sigmoid中表现较好,但在Relu激活函数中表现很差,所以何凯明在论文Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification He, K. et al. (2015)中提出了针对于Relu的初始化方法其。其基本思想是,在ReLU网络中,假定每一层有一半的神经元被激活,另一半为0,所以,要保持方差不变,只需要在Xavier的基础上再除以2。
网络层Layer类有一个forward成员方法,forward方法接收该层的输入,使用该层的权重矩阵weights和阈值(偏置)b来对输入进行线性求和,得到h,再使用激活函数对h进行计算,得到激活后的输出H,并将其返回。
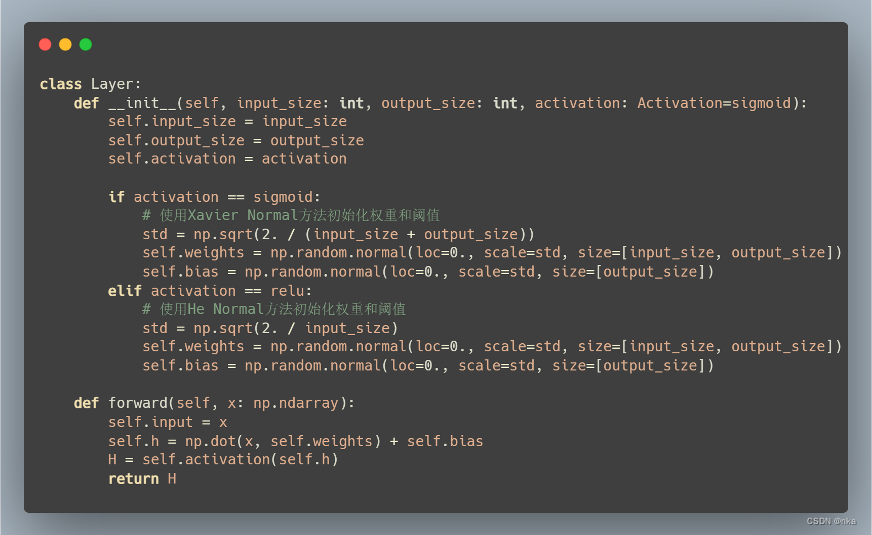
2.3 ANN神经网络
定义了激活函数和网络层后,接下来就是定义ANN类。在ANN初始化时,接受layers列表,每个元素都是之前定义的网络层,并接受参数lr作为ANN算法得学习率。
在ANN算法中,最复杂同时也是最重要的是向后传播算法。此处使用MSE均方误差作为计算网络输出误差的函数来进行反向传播。首先由误差计算得到输出层梯度,再计算与输出层最近的一层隐藏层梯度,直到第一层隐藏层。这里定义了一个局部变量sigma,对于输出层,sigma[-1][i]由实际输出与理想输出的差及输出层单元i的输入决定,而对于离输出层最近的隐藏层,sigma[-2][j]则需依赖sigma[-1][i]计算出,依此类推,直到计算出第一层隐藏层的sigma[0]。具体代码如下:
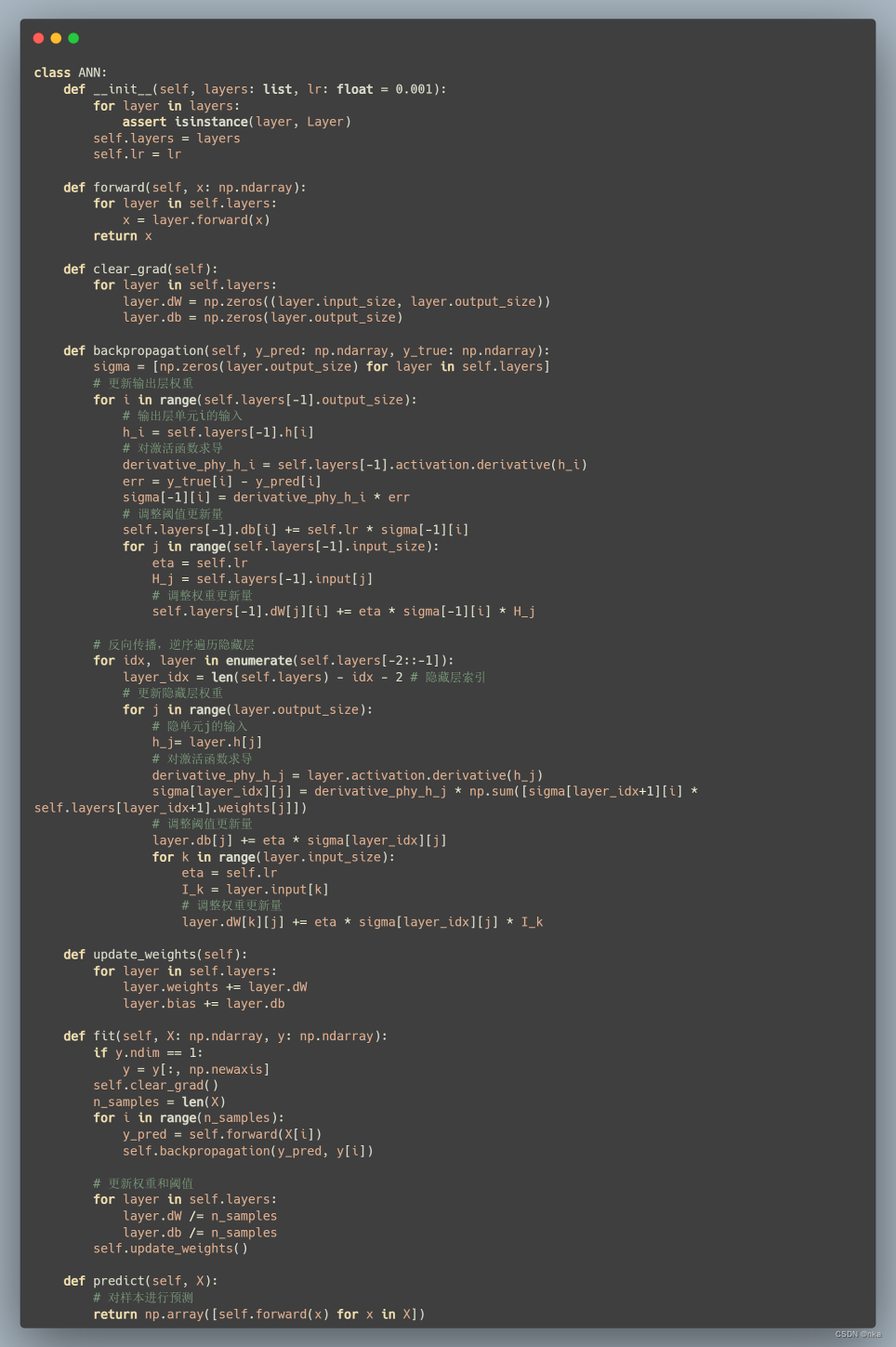
3 算法应用
3.1 数据集
此处选取了Diabetes Dataset糖尿病数据集用于测试算法。Diabetes Dataset是一个关于糖尿病的数据集,该数据集包括442个病人的生理数据及一年以后的病情发展情况。
在该数据集中,特征值总共有10项,分别为年龄(age)、性别(sex)、体质指数(bmi)、血压(bp),以及六种血清的化验数据s1、s2、s3、s4、s5和s6。以上的十列特征数据都是经过预处理的,10列特征数据都做了均值中心化处理,然后又用标准差乘以个体数量调整了数值范围。验证就会发现任何一列的所有数值平方和为1。
Diabetes Dataset是一个回归问题的数据集,其目标值为患者一年后糖尿病病情发展的定量测量数据。
3.2 模型训练与对比
对于Diabetes Dataset数据集,此处定义了一个四层神经网络,输入层的input_size为10,对应于数据集的10列特征,输出层output_size为1,输入一个target。另外含有两个隐藏层,隐藏层大小分别为18,9,并设置该神经网络的学习率为0.001
对于训练过程,这里设置训练轮次epochs为1500,并且在训练过程中,为了模型能更好地收敛,同时又尽量不陷入局部最优,我对学习率进行了动态调整。每100个epochs就将学习率乘以系数0.8,这样能使模型在误差较低的地方更好地收敛,同时每500轮就让学习率重新设置为0.001 + 0.001 * epoch / 500,增大学习率,从而防止模型陷入局部最优。
在训练过程中,代码中将最小的测试集均方误差记录下来,同时将每轮的训练集均方误差和测试集均方误差分别保存到列表中,每轮都输出当前的训练集和测试集mse,并在训练结束后输出测试集最小mse,再用matplotlib绘图工具将训练集mse列表和测试集mse列表绘制出来,从而能够直观地了解训练过程中误差的变化情况。
同时,同样对于这个数据集,在ANN算法训练完成后,再分别使用scikit-learn机器学习库的MLP Regressor (ANN,并且模型层数与隐藏层大小均与前面定义的ANN相同) 和Linear Regression分别对其进行拟合和预测,并计算在测试集上的均方误差,与代码中实现的ANN算法效果进行对比。
上述过程代码实现如下:

3.3 训练过程分析
在加载数据集后,定义一个具有两个隐藏层和一个输出层的ANN,并定义学习率为0.001,使用该ANN拟合Diabetes数据集,部分训练过程如下所示:
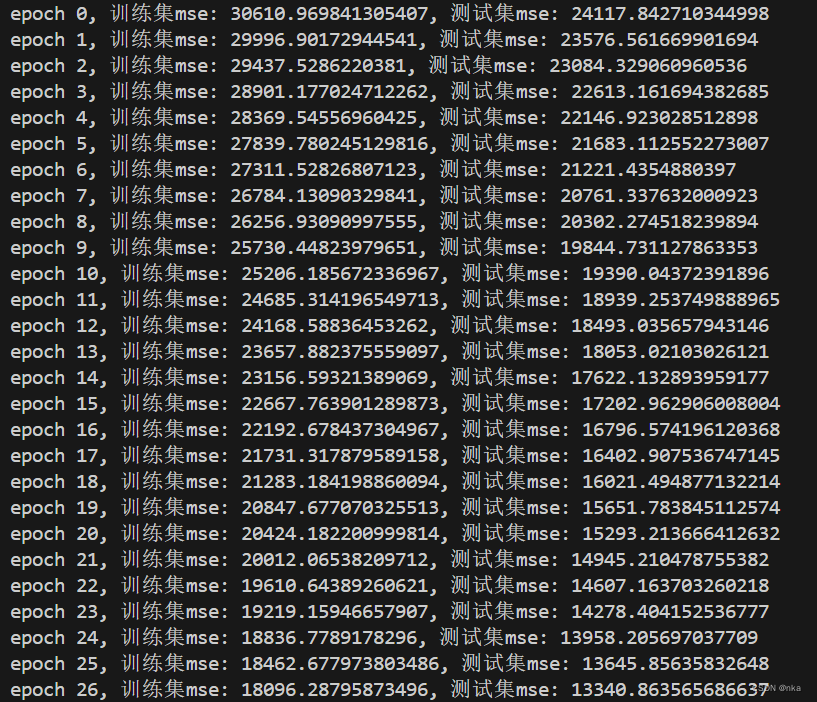
在训练初期,训练集和测试集MSE从大约30000开始迅速下降,说明模型此时正在拟合,ANN算法的反向传播算法更新权重后,使得模型预测的误差降低。
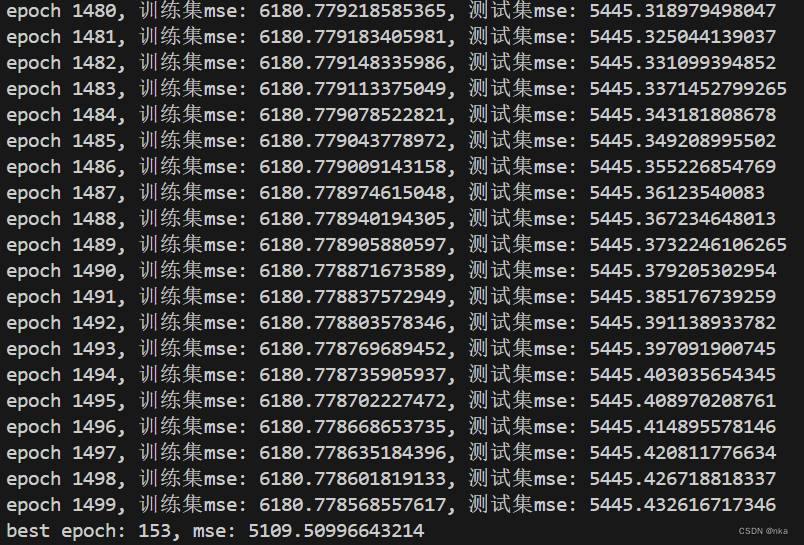
在训练末期,训练集MSE仍在缓慢下降,但是测试集MSE处于上升状态,说明此时模型已经过拟合,权重到达了局部最优。此外,可以看出在第153轮时,测试集的MSE最低,达到了约5109.51,与训练初期相比有了明显的下降。
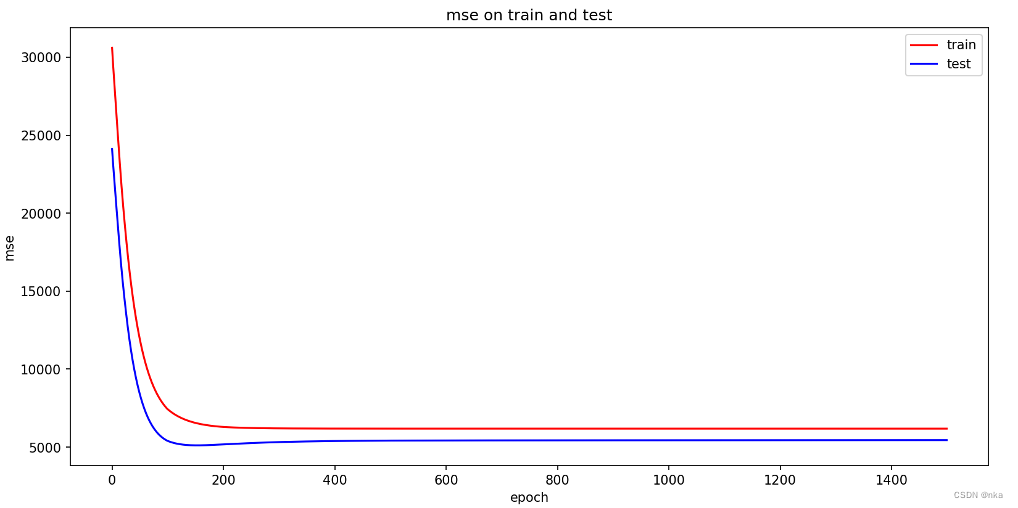
对于MSE在训练集和测试集上的变化,可以根据上面这张绘制得到的曲线图来观察。可以看出,训练集和测试集上的MSE均在约100epoch-200epoch时就基本达到最低了,往后基本上没有再下降,并且明显能看出测试集的MSE有一个小幅度的上升,这也是模型过拟合的一个表现。
3.4 对比结果

从对比结果可以看出,通过上述代码实现的ANN算法,相比于scikit-learn实现的ANN算法(MLPRegressor),在模型结构相同的情况下,MSE均方误差要稍微高一些。主要原因是上述代码实现的ANN算法没有使用优化器,并且上述代码在向后传播部分计算权重更新时,可能会有一些差错,导致模型容易过拟合,且容易发生梯度丢失等问题,因此效果较差。同时,在scilit-learn中进行横向比较发现,ANN算法得到的误差与线性回归得到的误差相似,甚至略低于线性回归,说明ANN算法在本数据集上有较为可观的结果,能够较好地解决非线性拟合问题。
本项目已在Github上开源,仓库地址:reeered/ArtificialNeuralNetwork (github.com)


















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









