







目录
一、索引的概念
索引的本质就是一个数据结构
创建索引的目的:用于加快数据库表的查询和检索速度。索引可以理解为数据库表中的目录,它保存了特定列的值和对应的行位置。
索引:提高数据库的性能,不用加内存,不用改程序,不用调sql,只要执行正确的 create index ,查询速度就可能提高成百上千倍。查询速度的提高是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的IO。所以它的价值,在于提高一个海量数据的检索速度。
常见索引分为:
- 主键索引(primary key)
- 唯一索引(unique)
- 普通索引(index)
- 全文索引(fulltext)–解决中子文索引问题。
使用方法:
alter table 表名 add index(列名);
下面是有没有索引的区别
--导入800万条数据 用时7min
mysql> source /home/zzg/learn/MySQL/index_data.sql;
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 1 row affected (0.01 sec)
Database changed
Query OK, 0 rows affected (0.04 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.05 sec)
Query OK, 0 rows affected (7 min 4.37 sec)
-- 查询数据有800w
mysql> select count(*) from EMP;
+----------+
| count(*) |
+----------+
| 8000000 |
+----------+
1 row in set (2.74 sec)
-- 不使用索引查询 大约4-5秒
mysql> select * from EMP where empno=998877;
+--------+--------+----------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+----------+------+---------------------+---------+--------+--------+
| 998877 | JsNNyd | SALESMAN | 0001 | 2023-07-29 00:00:00 | 2000.00 | 400.00 | 460 |
+--------+--------+----------+------+---------------------+---------+--------+--------+
1 row in set (4.46 sec)
--使用索引 速度几乎忽略
mysql> alter table EMP add index(empno);
Query OK, 0 rows affected (20.06 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select count(*) from EMP;
+----------+
| count(*) |
+----------+
| 8000000 |
+----------+
1 row in set (2.74 sec)
mysql> select * from EMP where empno=998877;
+--------+--------+----------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+----------+------+---------------------+---------+--------+--------+
| 998877 | JsNNyd | SALESMAN | 0001 | 2023-07-29 00:00:00 | 2000.00 | 400.00 | 460 |
+--------+--------+----------+------+---------------------+---------+--------+--------+
1 row in set (0.00 sec)
二、前导理解
2.1 硬件方面
MySQL 给用户提供存储服务,而存储的都是数据,数据在磁盘这个外设当中。磁盘是计算机中的一个机械设备,相比于计算机其他电子元件,磁盘效率是比较低的,在加上IO本身的特征,可以知道,如何提交效率,是 MySQL 的一个重要话题。
先看一下磁盘的样子:

在看看磁盘中一个盘片:
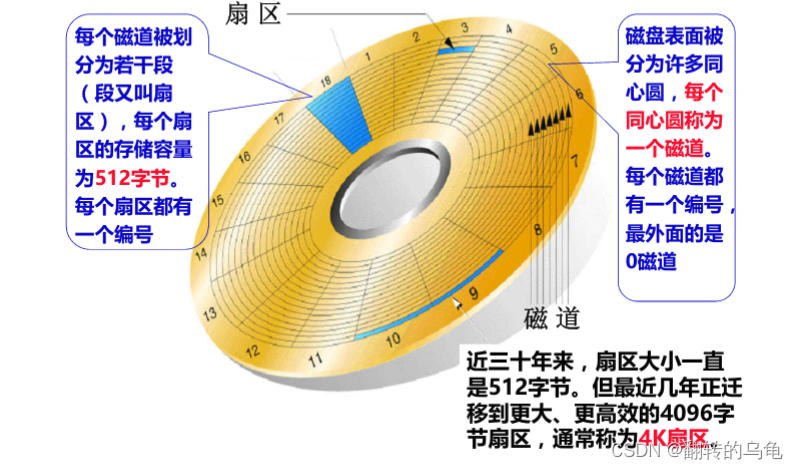
扇区
数据库文件,本质其实就是保存在磁盘的盘片当中。也就是上面的一个个小格子中,就是我们经常所说的扇区。当然,数据库文件很大,也很多,一定需要占据多个扇区。
从上图可以看出来,在半径方向上,距离圆心越近,扇区越小,距离圆越远,扇区越大,那么,所有扇区都是默认512字节吗?目前是的,我们也这样认为。因为保证一个扇区多大,是由比特位密度决定的。
不过最新的磁盘技术,已经慢慢的让扇区大小不同了,不过我们现在暂时不考虑。我们在使用Linux,所看到的大部分目录或者文件,其实就是保存在硬盘当中的。(当然,有一些内存文件系统,如:
proc , sys 之类,我们不考虑)
数据库文件,本质其实就是保存在磁盘的盘片当中,就是一个一个的文件
所以,最基本的,找到一个文件的全部,本质,就是在磁盘找到所有保存文件的扇区。
而我们能够定位任何一个扇区,那么便能找到所有扇区,因为查找方式是一样的。
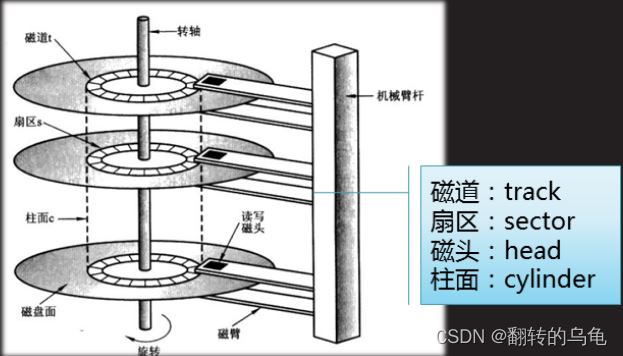
- 柱面(磁道): 多盘磁盘,每盘都是双面,大小完全相等。那么同半径的磁道,整体上便构成了一个柱面
- 每个盘面都有一个磁头,那么磁头和盘面的对应关系便是1对1的
- 所以,我们只需要知道,磁头(Heads)、柱面(Cylinder)(等价于磁道)、扇区(Sector)对应的编号。即可在磁盘上定位所要访问的扇区。这种磁盘数据定位方式叫做 CHS 。不过实际系统软件使用
的并不是 CHS (但是硬件是),而是 LBA ,一种线性地址,可以想象成虚拟地址与物理地址。系统将 LBA 地址最后会转化成为 CHS ,交给磁盘去进行数据读取。不过,我们现在不关心转化细节,知道这个东西,让我们逻辑自洽起来即可。
结论
我们现在已经能够在硬件层面定位,任何一个基本数据块了(扇区)。那么在系统软件上,就直接按照扇区(512字节,部分4096字节),进行IO交互吗?
不是
如果操作系统直接使用硬件提供的数据大小进行交互,那么系统的IO代码,就和硬件强相关,换言之,如果硬件发生变化,系统必须跟着变化
从目前来看,单次IO 512字节,还是太小了。IO单位小,意味着读取同样的数据内容,需要进行多次磁盘访问,会带来效率的降低。
之前学习文件系统,就是在磁盘的基本结构下建立的,文件系统读取基本单位,就不是扇区,而是数据块。故,系统读取磁盘,是以块为单位的,基本单位是 4KB 。
磁盘随机访问(Random Access)与连续访问(Sequential Access)
- 随机访问:本次IO所给出的扇区地址和上次IO给出扇区地址不连续,这样的话磁头在两次IO操作之间需要作比较大的移动动作才能重新开始读/写数据。
- 连续访问:如果当次IO给出的扇区地址与上次IO结束的扇区地址是连续的,那磁头就能很快的开始这次IO操作,这样的多个IO操作称为连续访问。
因此尽管相邻的两次IO操作在同一时刻发出,但如果它们的请求的扇区地址相差很大的话也只能称为随机访问,而非连续访问。
磁盘是通过机械运动进行寻址的,连续访问不需要过多的定位,故效率比较高
2.2 软件方面
而 MySQL 作为一款应用软件,可以想象成一种特殊的文件系统。它有着更高的IO场景,所以,为了提高基本的IO效率, MySQL 进行IO的基本单位是 16KB
mysql> show global status like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 | --16*1024=16384 16KB
+------------------+-------+
也就是说,磁盘这个硬件设备的基本单位是 512 字节,而 MySQL InnoDB引擎 使用 16KB 进行IO交互。即, MySQL 和磁盘进行数据交互的基本单位是 16KB 。这个基本数据单元,在 MySQL 这里叫做page(注意和系统的page区分)
2.3 建立共识
下面是大致过程:
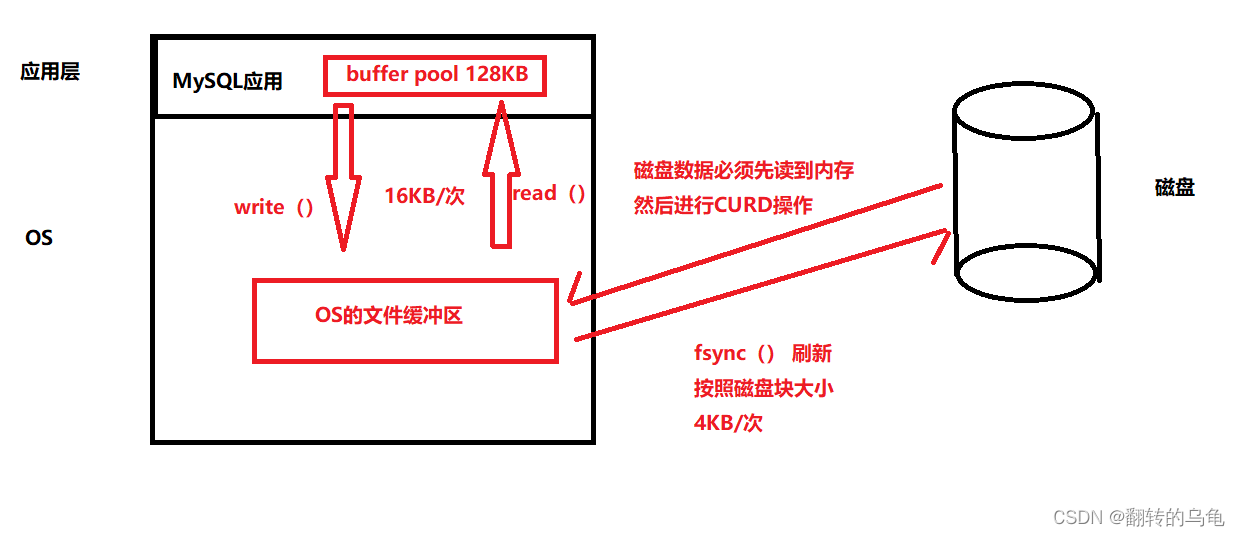
- MySQL 中的数据文件,是以page为单位保存在磁盘当中的。
- MySQL 的 CURD 操作,都需要通过计算,找到对应的插入位置,或者找到对应要修改或者查的数据。
- 只要涉及计算,就需要CPU参与,而为了便于CPU参与,一定要能够先将数据移动到内存当中。
- 所以在特定时间内,数据一定是磁盘中有,内存中也有。后续操作完内存数据之后,以特定的刷新策略,刷新到磁盘。而这时,就涉及到磁盘和内存的数据交互,也就是IO了。而此时IO的基本单位就是Page。
- 为了更好的进行上面的操作, MySQL 服务器在内存中运行的时候,在服务器内部,就申请了被称为 Buffer Pool 的的大内存空间,来进行各种缓存。其实就是很大的内存空间,来和磁盘数据进
行IO交互。 - 为了更高的效率,一定要尽可能的减少系统和磁盘IO的次数
三、索引的理解
建立测试表
mysql> create table if not exists user ( id int primary key, age int not null, name varchar(16) not null );
Query OK, 0 rows affected (0.03 sec)
mysql> show create table user \G
*************************** 1. row ***************************
Table: user
Create Table: CREATE TABLE `user` (
`id` int(11) NOT NULL,
`age` int(11) NOT NULL,
`name` varchar(16) NOT NULL,
PRIMARY KEY (`id`) --一定要添加主键哦,只有这样才会默认生成主键索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
--插入多条记录
mysql> insert into user (id, age, name) values(3, 18, '杨过');
Query OK, 1 row affected (0.01 sec)
mysql> insert into user (id, age, name) values(4, 16, '小龙女');
Query OK, 1 row affected (0.00 sec)
mysql> insert into user (id, age, name) values(2, 26, '黄蓉');
Query OK, 1 row affected (0.00 sec)
mysql> insert into user (id, age, name) values(5, 36, '郭靖');
Query OK, 1 row affected (0.00 sec)
mysql> insert into user (id, age, name) values(1, 56, '欧阳锋');
Query OK, 1 row affected (0.00 sec)
--发现竟然默认是有序的!是谁干的呢?排序有什么好处呢?
mysql> select * from user;
+----+-----+-----------+
| id | age | name |
+----+-----+-----------+
| 1 | 56 | 欧阳锋 |
| 2 | 26 | 黄蓉 |
| 3 | 18 | 杨过 |
| 4 | 16 | 小龙女 |
| 5 | 36 | 郭靖 |
+----+-----+-----------+
5 rows in set (0.00 sec)
随机插入的数据,在查询数据的时候竟然是有序的,是谁干的呢?排序有什么好处呢?
mysqld 自己做的,目的是:方便引入页内目录,提高查询效率
为何IO交互要是 Page
为何MySQL和磁盘进行IO交互的时候,要采用Page的方案进行交互呢?用多少,加载多少不香吗?
如上面的5条记录,如果MySQL要查找id=2的记录,第一次加载id=1,第二次加载id=2,一次一条记录,那么就需要2次IO。如果要找id=5,那么就需要5次IO。
但,如果这5条(或者更多)都被保存在一个Page中(16KB,能保存很多记录),那么第一次IO查找id=2的时
候,整个Page会被加载到MySQL的Buffer Pool中,这里完成了一次IO。但是往后如果在查找id=1,3,4,5
等,完全不需要进行IO了,而是直接在内存中进行了。所以,就在单Page里面,大大减少了IO的次数。
你怎么保证,用户一定下次找的数据,就在这个Page里面?我们不能严格保证,但是有很大概率,因为有局部性原理。
往往IO效率低下的最主要矛盾不是IO单次数据量的大小,而是IO的次数。
首先磁盘上有对应的文件数据,文件数据最终会被预读到文件缓冲区,mysql启动的时候会申请buffer pool,mysql层面上,所有的page都会被放到buffer pool中;
理解mysql中page的概念:一个page是16KB,mysql内部一定需要并且会存在大量的page,也就决定了mysql必须要将多个同时存在的page管理起来。要管理所有的mysql内的page,需要先描述,再组织,所以不要简单将page认为是一个内存块,page内部也必须写入对应的管理信息!如:
struct page
{
struct page*next;
struct page*prev;
char buffer[NUM];
};
--只是类似于链表,内部更复杂 需要inode等
MySQL和磁盘进行IO交互的时候,采用Page的方案进行交互的原因:减少IO次数
3.1 单个page
MySQL 中要管理很多数据表文件,而要管理好这些文件,就需要先描述,再组织 ,我们目前可以简单理解成一个个独立文件是有一个或者多个Page构成的

不同的 Page ,在 MySQL 中,都是 16KB ,使用 prev 和 next 构成双向链表
因为有主键的问题, MySQL 会默认按照主键给我们的数据进行排序,从上面的Page内数据记录可以看出,数据是有序且彼此关联的。
插入数据时排序的目的,就是优化查询的效率
为什么数据库在插入数据时要对其进行排序呢?我们按正常顺序插入数据不是也挺好的吗?
插入数据时排序的目的,就是优化查询的效率。
页内部存放数据的模块,实质上也是一个链表的结构,链表的特点也就是增删快,查询修改慢,所以优化查询的效率是必须的。
正式因为有序,在查找的时候,从头到后都是有效查找,没有任何一个查找是浪费的,而且,如果运气好,是可以提前结束查找过程的。
3.2 多个page
-
通过上面的分析,我们知道,上面页模式中,只有一个功能,就是在查询某条数据的时候直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能。但是,我们也可以看到,现在的页模式内部,实际上是采用了链表的结构,前一条数据指向后一条数据,本质上还是通过数据的逐条比较来取出特定的数据。
-
如果有1千万条数据,一定需要多个Page来保存1千万条数据,多个Page彼此使用双链表链接起来,而且每个Page内部的数据也是基于链表的。那么,查找特定一条记录,也一定是线性查找。这效率也太低了。
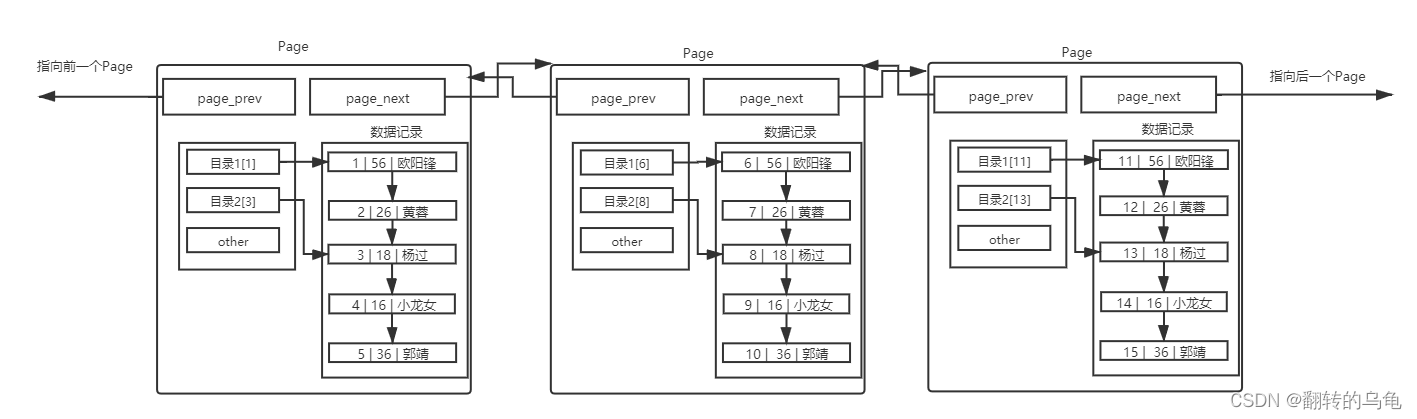
单个page内部有页目录,减少了page内部的检索次数,提升了单page的搜索效率,上图中多个page之间的连接关系,从图中看出页目录在多个page中也是呈现顺序关系的,如果是跨页搜索数据,也只能从前往后顺序遍历每个页的页目录,如果page一多,这种检索方式会大大降低页与页之间数据搜索速度,为了解决该问题,我们同样使用目录的方式对每个页中的目录进行管理,如下图:
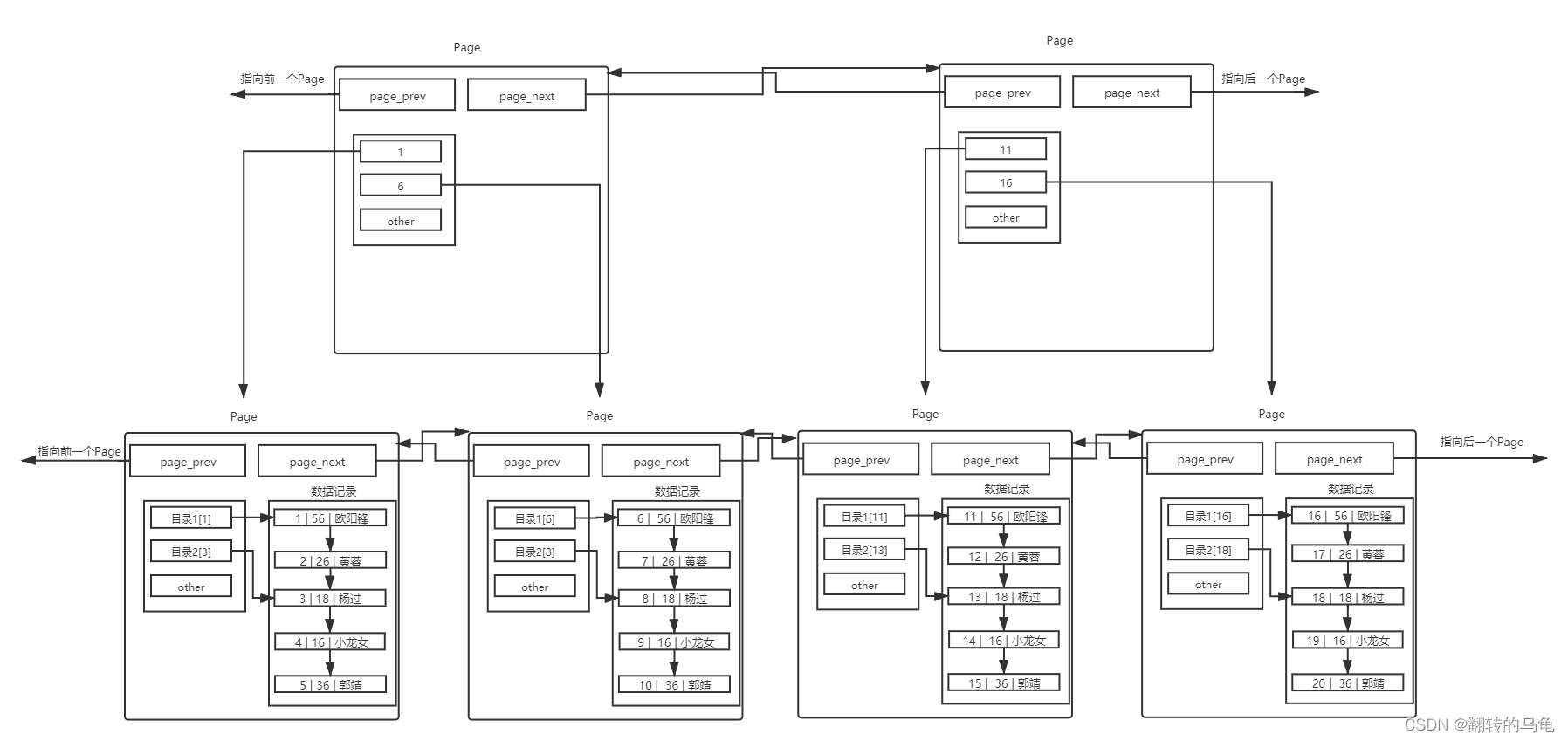
添加一个目录页(新page)来管理页目录(子page),目录页中的数据存放的就是指向的那一页中最小的数据。然后就可通过比较,找到该访问那个Page,进而通过指针,找到下一个Page。
3.3 B+树
如果底层的page很多,会造成一级目录的数量变多,那么我们对一级目录的遍历又变成了线性遍历,这个时候,需要再加一层

这就是B+树,把整个的B+树称作mysql innode db下的索引结构,一般我们建表的时候,就是在该结构下进行CURD,即使没有主键也是这样子的,会有默认主键的
-
并不是所有的存储引擎的索引都是采用B+树,还有哈希索引等方式。主流的存储引擎是采用B+树作为索引的数据结构。
-
只有叶子结点采用链表进行级联,这是因为这是B+树的特性;同时,叶子结点进行级联可以满足范围查找(有时候数据读取的时候跨页了,叶子结点有指向next页的指针,方便查找)
3.4 B+树的特征
- 非叶节点不保存数据,只用来索引,所有数据都保存在叶子节点。
- 数据只在叶子结点保存,并保存指向前后叶子结点的指针,通过链表指针对叶子结点进行级联,且叶子结点本身依关键字的自小而大顺序连接。
简单说明
Page分为目录页和数据页。目录页只放各个下级Page的最小键值。
查找的时候,自定向下找,只需要加载部分目录页到内存,即可完成算法的整个查找过程,大大减少了IO次数
数据结构对比(为何选B+树)
- 链表?线性遍历
- 二叉搜索树?退化问题,可能退化成为线性结构
- AVL &&红黑树?虽然是平衡或者近似平衡,但是毕竟是二叉结构,相比较多阶B+,意味着树整体过高,大家都是自顶向下找,层高越低,意味着系统与硬盘更少的IO Page交互。虽然你很秀,但是有更秀的。
- Hash?官方的索引实现方式中, MySQL 是支持HASH的,不过 InnoDB 和 MyISAM 并不支持.Hash跟进其算法特征,决定了虽然有时候也很快(O(1)),不过,在面对范围查找就明显不行,另外还有其他差别,有兴趣可以查一下。
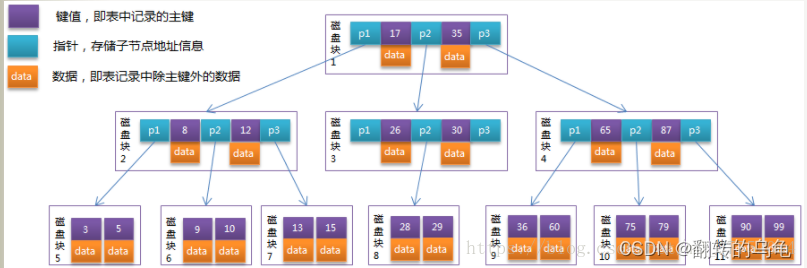
B+ vs B
B树
B+树
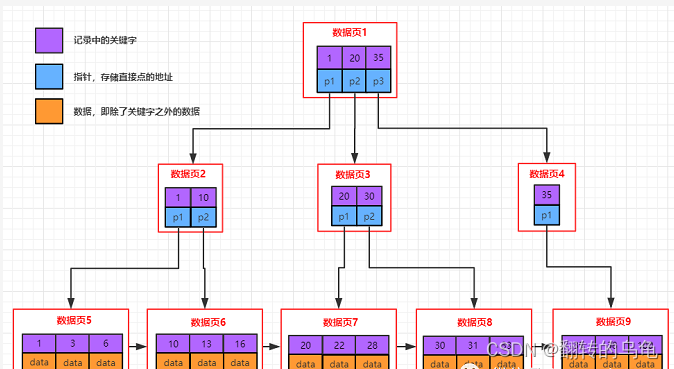
目前这两棵树,对我们最有意义的区别是:
- B树节点,既有数据,又有Page指针,而B+,只有叶子节点有数据,其他目录页,只有键值和Page指针
- B+叶子节点,全部相连,而B没有
为何选择B+
- 节点不存储data,这样一个节点就可以存储更多的key。可以使得树更矮,所以IO操作次数更少。
- 叶子节点相连,更便于进行范围查找
3.5 聚簇索引与非聚簇索引
像innodb存储引擎那样把B+树和数据存放在一起称为聚簇索引
MyISAM 存储引擎-主键索引
MyISAM 引擎同样使用B+树作为索引结果,叶节点的data域存放的是数据记录的地址。下图为 MyISAM表的主索引, Col1 为主键
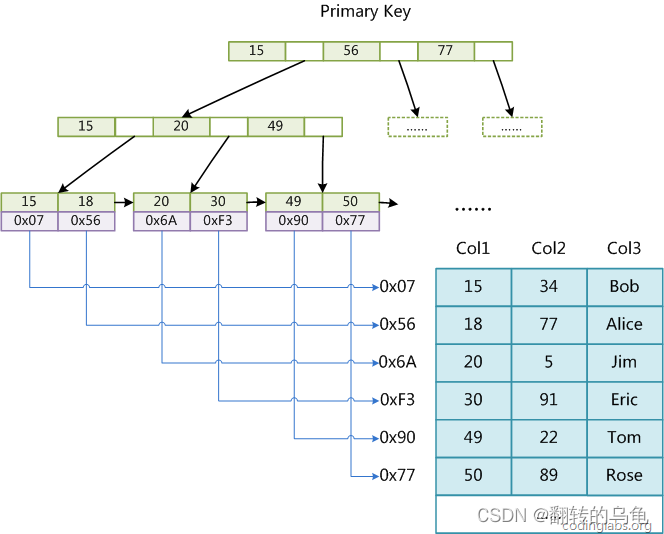
其中, MyISAM 最大的特点是,将索引Page和数据Page分离,也就是叶子节点没有数据,只有对应数据的地址。这种方式叫做非聚簇索引.
聚簇索引与非聚簇索引的区别在底层看来就是创建表的时候,MySQL文件系统中聚簇索引有两个文件,非聚簇索引的表有三个文件
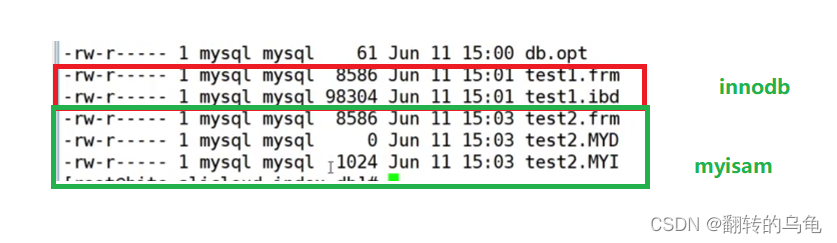
3.6 辅助索引(普通索引)
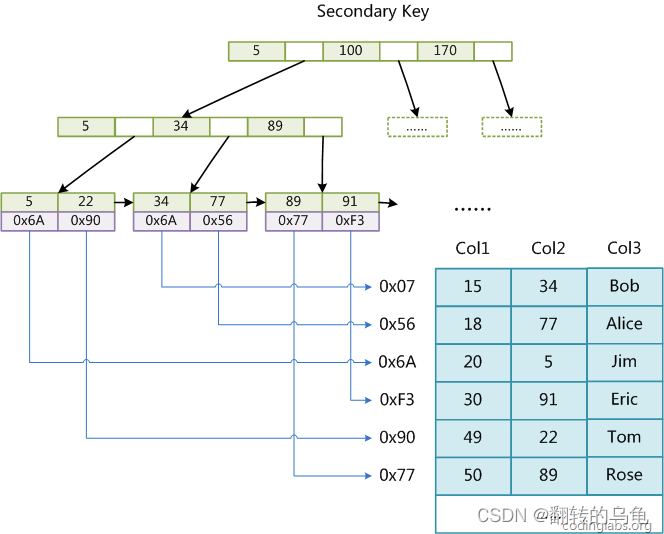
MyISAM辅助索引
- MySQL 除了默认会建立主键索引外,我们用户也有可能建立按照其他列信息建立的索引,一般这种索引可以叫做辅助(普通)索引。
- 对于 MyISAM ,建立辅助(普通)索引和主键索引没有差别,无非就是主键不能重复,而非主键可重复。
- MyISAM存储引擎可以在一张表中建立多个索引,下图就是基于 MyISAM 的 Col2 建立的索引,和主键索引没有差别
innodb辅助索引
同样, InnoDB 除了主键索引,用户也会建立辅助(普通)索引,我们以上表中的 Col3 建立对应的辅助索引如下图:
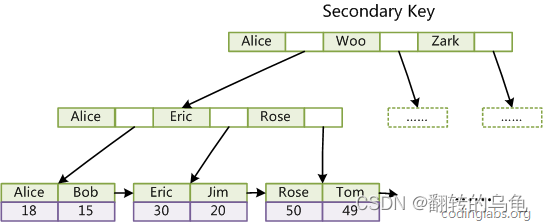
可以看到, InnoDB 的非主键索引中叶子节点并没有数据,而只有对应记录的key值。
所以通过辅助(普通)索引,找到目标记录,需要两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。这种过程,就叫做回表查询
为何 InnoDB 针对这种辅助(普通)索引的场景,不给叶子节点也附上数据呢?原因就是太浪费空间了。
四、索引操作
4.1 主键索引的创建和查看
第一种方式:
-- 在创建表的时候,直接在字段名后指定 primary key
create table user1(id int primary key, name varchar(30));
第二种方式
-- 在创建表的最后,指定某列或某几列为主键索引
create table user2(id int, name varchar(30), primary key(id));
第三种方式:
create table user3(id int, name varchar(30));
-- 创建表以后再添加主键
alter table user3 add primary key(id);
查看索引:
mysql> show index from user1\G;
*************************** 1. row ***************************
Table: user1
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
1 row in set (0.01 sec)
主键索引的特点:
- 一个表中,最多有一个主键索引,当然可以使符合主键
- 主键索引的效率高(主键不可重复)
- 创建主键索引的列,它的值不能为null,且不能重复
- 主键索引的列基本上是int
4.2 唯一键索引的创建和查看
第一种方式
-- 在表定义时,在某列后直接指定unique唯一属性
mysql> create table user4(id int primary key, name varchar(30) unique);
-- 创建表时,在表的后面指定某列或某几列为unique
mysql> create table user5(id int primary key, name varchar(30), unique(name));
Query OK, 0 rows affected (0.02 sec)
--先建表,然后再添加唯一键
mysql> create table user6(id int primary key, name varchar(30));
mysql> alter table user6 add unique(name);
查看索引
mysql> show index from user4\G;
*************************** 1. row ***************************
Table: user4
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 2. row ***************************
Table: user4
Non_unique: 0
Key_name: name
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
2 rows in set (0.00 sec)
唯一索引的特点:
- 一个表中,可以有多个唯一索引
- 查询效率高
- 如果在某一列建立唯一索引,必须保证这列不能有重复数据
- 如果一个唯一索引上指定not null,等价于主键索引
4.3 普通索引的创建和查看
--在表的定义最后,指定某列为索引
mysql> create table user8(id int primary key,
-> name varchar(20),
-> email varchar(30),
-> index(name)
-> );
--
mysql> create table user9(id int primary key, name varchar(20), email
-> varchar(30));
--创建完表以后指定某列为普通索引
mysql> alter table user9 add index(name);
mysql> create table user10(id int primary key, name varchar(20), email varchar(30));
---- 创建一个索引名为 myindex 的索引
mysql> create index myindex on user10(name);
查看索引
mysql> show index from user10\G;
*************************** 1. row ***************************
Table: user10
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 2. row ***************************
Table: user10
Non_unique: 1
Key_name: myindex
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
2 rows in set (0.00 sec)
普通索引的特点:
- 一个表中可以有多个普通索引,普通索引在实际开发中用的比较多
- 如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引
4.4 复合索引
mysql> alter table user10 add index(name,email);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from user10\G;
*************************** 1. row ***************************
Table: user10
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 2. row ***************************
Table: user10
Non_unique: 1
Key_name: myindex
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
*************************** 3. row ***************************
Table: user10
Non_unique: 1
Key_name: name
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
*************************** 4. row ***************************
Table: user10
Non_unique: 1
Key_name: name
Seq_in_index: 2
Column_name: email
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
4 rows in set (0.00 sec)
ERROR:
No query specified
创建的复合索引其实在一颗B+树上,发现name和email的索引名称一样,复合索引的作用在于指定多个字段构建一颗B+树,如果需要高频的通过name找到email的操作,就可以构建复合索引,这样就避免了回表查询,复合索引又叫索引覆盖 最左匹配原则
4.5 全文索引
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,但是有要求,要求表的存储引擎必须是MyISAM,而且默认的全文索引支持英文,不支持中文。如果对中文进行全文检索
mysql> CREATE TABLE articles (
-> id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
-> title VARCHAR(200),
-> body TEXT,
-> FULLTEXT (title,body)--创建全文索引
-> )engine=MyISAM;
mysql> INSERT INTO articles (title,body) VALUES
-> ('MySQL Tutorial','DBMS stands for DataBase ...'),
-> ('How To Use MySQL Well','After you went through a ...'),
-> ('Optimizing MySQL','In this tutorial we will show ...'),
-> ('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
-> ('MySQL vs. YourSQL','In the following database comparison ...'),
-> ('MySQL Security','When configured properly, MySQL ...');
mysql> select * from articles;
+----+-----------------------+------------------------------------------+
| id | title | body |
+----+-----------------------+------------------------------------------+
| 1 | MySQL Tutorial | DBMS stands for DataBase ... |
| 2 | How To Use MySQL Well | After you went through a ... |
| 3 | Optimizing MySQL | In this tutorial we will show ... |
| 4 | 1001 MySQL Tricks | 1. Never run mysqld as root. 2. ... |
| 5 | MySQL vs. YourSQL | In the following database comparison ... |
| 6 | MySQL Security | When configured properly, MySQL ... |
+----+-----------------------+------------------------------------------+
--使用如下查询方式,虽然查询出数据,但是没有使用到全文索引:
mysql> select * from articles where body like '%database%';
+----+-------------------+------------------------------------------+
| id | title | body |
+----+-------------------+------------------------------------------+
| 1 | MySQL Tutorial | DBMS stands for DataBase ... |
| 5 | MySQL vs. YourSQL | In the following database comparison ... |
+----+-------------------+------------------------------------------+
--使用explain 检查是否使用了索引
mysql> explain select * from articles where body like '%database%'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: articles
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL--key为nul,表示没有使用索引
ref: NULL
rows: 6
filtered: 16.67
Extra: Using where
--使用全文索引
--返回在"title"和"body"列中包含"database"关键词的所有文章记录。
mysql> select * from articles where match(title,body) against('database');
+----+-------------------+------------------------------------------+
| id | title | body |
+----+-------------------+------------------------------------------+
| 5 | MySQL vs. YourSQL | In the following database comparison ... |
| 1 | MySQL Tutorial | DBMS stands for DataBase ... |
+----+-------------------+------------------------------------------+
mysql> explain select * from articles where match(title,body) against('database')\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: articles
partitions: NULL
type: fulltext--索引类型
possible_keys: title
key: title--使用了title
key_len: 0
ref: const
rows: 1
filtered: 100.00
Extra: Using where
4.6 索引的查找方式
--方式一
show keys from 表名;
--方式二:常用
show index from 表名;
----方式三
desc 表名;
mysql> show index from test1\G;
*************************** 1. row ***************************
Table: test1
Non_unique: 0
Key_name: PRIMARY--索引名称
Seq_in_index: 1
Column_name: id--以id列为索引构建的B+树
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE--索引类型(B+树)
Comment:
Index_comment:
4.7 索引的删除
--删除主键索引
alter table 表名 drop primary key;
--索引名就是show keys from 表名中的 Key_name 字段
alter table 表名 drop index 索引名;
--drop index 索引名 on 表名
mysql> drop index name on user9;
4.8 索引创建原则
- 有主键和唯一键约束的字段自带索引
- 某一列频繁的被作为查询条件
- 唯一性太差的列不适合作为索引,即使这一列被频繁查询
- 更新频繁的字段不适合作为索引
- 不会出现在where子句中的字段不该创建索引
















 2820
2820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











