









Dataset
-
Dataset 是什么?
@Test def dataset1():Unit ={ // 1. 创建 SparkSession val spark = new SparkSession.Builder() .master("local[6]") .appName("dataset1") .getOrCreate() // 2. 导入隐式转换 import spark.implicits._ // 3. 演示 val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 10), Person("lisi", 15))) val dataset:Dataset[Person] = sourceRDD.toDS() // DataSet 支持强类型的 API dataset.filter(item=> item.age>10).show() // Dataset 支持弱类型的API dataset.filter('age>10).show() dataset.filter($"age">10).show() // DataSet 支持 直接写 SQL 表达式 dataset.filter("age>10").show() } case class Person(name: String, age: Int)问题1: Person 是什么?
Person 是一个强类型的类
问题2: 这个 Dataset 中是结构化的数据吗?
非常明显是的, 因为 Person 对象中有结构信息, 例如字段名和字段类型
问题3: 这个 Dataset 能够使用类似 SQL 这样声明式结构化查询语句的形式来查询吗?
当然可以, 已经演示过了
问题4: Dataset 是什么?
Dataset 是一个强类型, 并且类型安全的数据容器, 并且提供了结构化查询 API 和类似 RDD 一样的命令式 API
-
Dataset 底层是什么
即使使用 Dataset 的命令式 API, 执行计划也依然会被优化
Dataset 具有 RDD 的方便, 同时也具有 DataFrame 的性能优势, 并且 Dataset 还是强类型的, 能做到类型安全.
@Test def dataset2():Unit = { // 1. 创建 SparkSession val spark = new SparkSession.Builder() .master("local[6]") .appName("dataset2") .getOrCreate() // 2. 导入隐式转换 import spark.implicits._ // 3. 演示 val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 10), Person("lisi", 15))) val dataset: Dataset[Person] = sourceRDD.toDS() //优化 dataset.explain(true) // 查看其逻辑计划和物理计划,运行会直接打印 } case class Person(name: String, age: Int)Dataset 的底层是什么?
Dataset 最底层处理的是对象的序列化形式, 通过查看 Dataset 生成的物理执行计划, 也就是最终所处理的 RDD, 就可以判定 Dataset 底层处理的是什么形式的数据
val dataset: Dataset[People] = spark.createDataset(Seq(Person("zhangsan", 10), Person("lisi", 15))) val internalRDD: RDD[InternalRow] = dataset.queryExecution.toRdd case class Person(name: String, age: Int)dataset.queryExecution.toRdd这个 API 可以看到Dataset底层执行的 RDD, 这个 RDD 中的范型是InternalRow,InternalRow又称之为Catalyst Row, 是Dataset底层的数据结构, 也就是说, 无论Dataset的范型是什么, 无论是Dataset[Person]还是其它的, 其最底层进行处理的数据结构都是InternalRow
所以,Dataset的范型对象在执行之前, 需要通过Encoder转换为InternalRow, 在输入之前, 需要把InternalRow通过Decoder转换为范型对象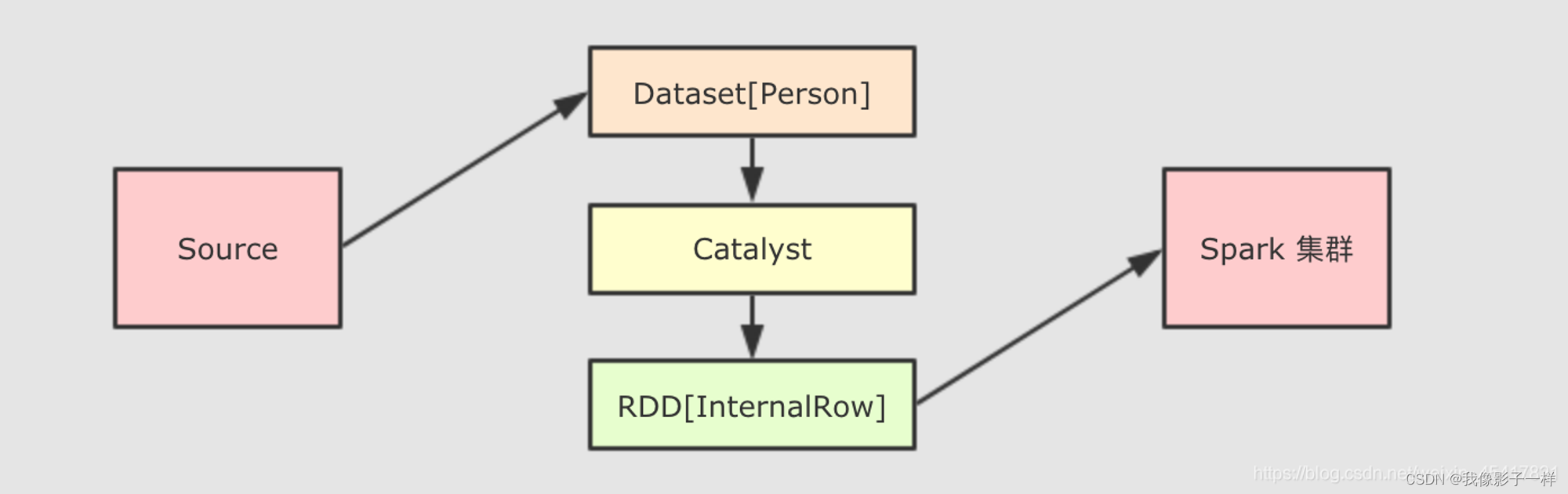
可以获取 Dataset 对应的 RDD 表示
在 Dataset 中, 可以使用一个属性 rdd 来得到它的 RDD 表示, 例如 Dataset[T] → RDD[T]
@Test def dataset2():Unit = { // 1. 创建 SparkSession val spark = new SparkSession.Builder() .master("local[6]") .appName("dataset2") .getOrCreate() // 2. 导入隐式转换 import spark.implicits._ // 3. 演示 // val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 10), Person("lisi", 15))) // val dataset: Dataset[Person] = sourceRDD.toDS() //优化 val dataset: Dataset[Person] = spark.createDataset(Seq(Person("zhangsan", 10), Person("lisi", 15))) // dataset.explain(true) // 查看其逻辑计划和物理计划,运行会直接打印 // 无论DataSet 放置的是什么类型对象,最终执行计划中的RDD 上都是InternalRow // 直接获取到已经分析和解析过的DataSet的执行计划,从中拿到RDD val executionRdd:RDD[InternalRow] = dataset.queryExecution.toRdd // 把生成的计划转为rdd //通过将DataSet 底层的RDD[InternalRow] 通过Decoder 转成了DataSet一样的类型RDD val typeRDD: RDD[Person] = dataset.rdd // (1) println(executionRdd.toDebugString) /* * (2) MapPartitionsRDD[1] at toRdd at Intro.scala:97 [] * | ParallelCollectionRDD[0] at toRdd at Intro.scala:97 [] * */ println("-------------------------") // (2)// 这段代码的执行计划为什么多了两个步骤? println(typeRDD.toDebugString) /* * (2) MapPartitionsRDD[5] at rdd at Intro.scala:102 [] * | MapPartitionsRDD[4] at rdd at Intro.scala:102 [] * | MapPartitionsRDD[3] at rdd at Intro.scala:102 [] * | ParallelCollectionRDD[2] at rdd at Intro.scala:102 [] * */ } case class Person(name: String, age: Int) // 放在class 外(1)Dataset 的执行计划底层的 RDD
(2)使用 Dataset.rdd 将 Dataset 转为 RDD 的形式
可以看到 (1) 对比 (2) 对了两个步骤, 这两个步骤的本质就是将 Dataset 底层的 InternalRow 转为 RDD 中的对象形式, 这个操作还是会有点重的, 所以慎重使用 rdd 属性来转换 Dataset 为 RDD
总结
- Dataset 是一个新的 Spark 组件, 其底层还是 RDD
- Dataset 提供了访问对象中某个特定字段的能力, 不用像 RDD 一样每次都要针对整个对象做操作
- Dataset 和 RDD 不同, 如果想把 Dataset[T] 转为 RDD[T], 则需要对 Dataset 底层的 InternalRow 做转换, 是一个比价重量级的操作















 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









