






文章目录
在看完CCF论坛:《夜话Deepseek:技术原理与未来发展》,个人也是有很多的启发和思考,本人就该次会议而言,进行了一些总结和思考,如有错误,敬请指正!
会议回放链接:在微信中搜索“中国计算机学会”,打开视频号,查看其“直播回放”,找到“夜话Deepseek”。
一、关于Deepseek R1的思考和启发
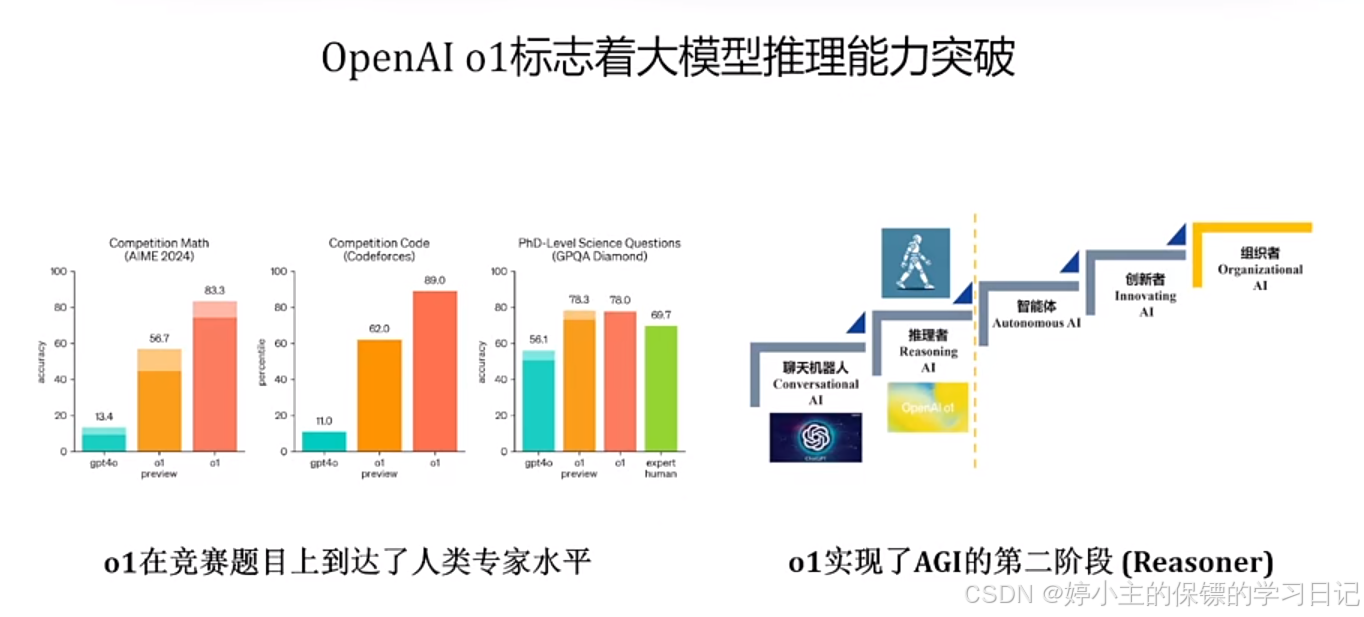
- R1是目前唯一具有强推理能力和联网搜索的产品,并具有很强的回答能力。
- 强推理模型最终的落脚点大概率是agent,怎么用抢强推理模型帮助agent更好更鲁棒是一个非常重要的问题。
- 总结:总的来说,未来几年的主要发展趋势就是强推理模型,如何构建一个高效的agent是所有从事大模型研究的同学老师最需要深度思考的一个问题。
二、大规模强化学习技术原理与大模型技术发展
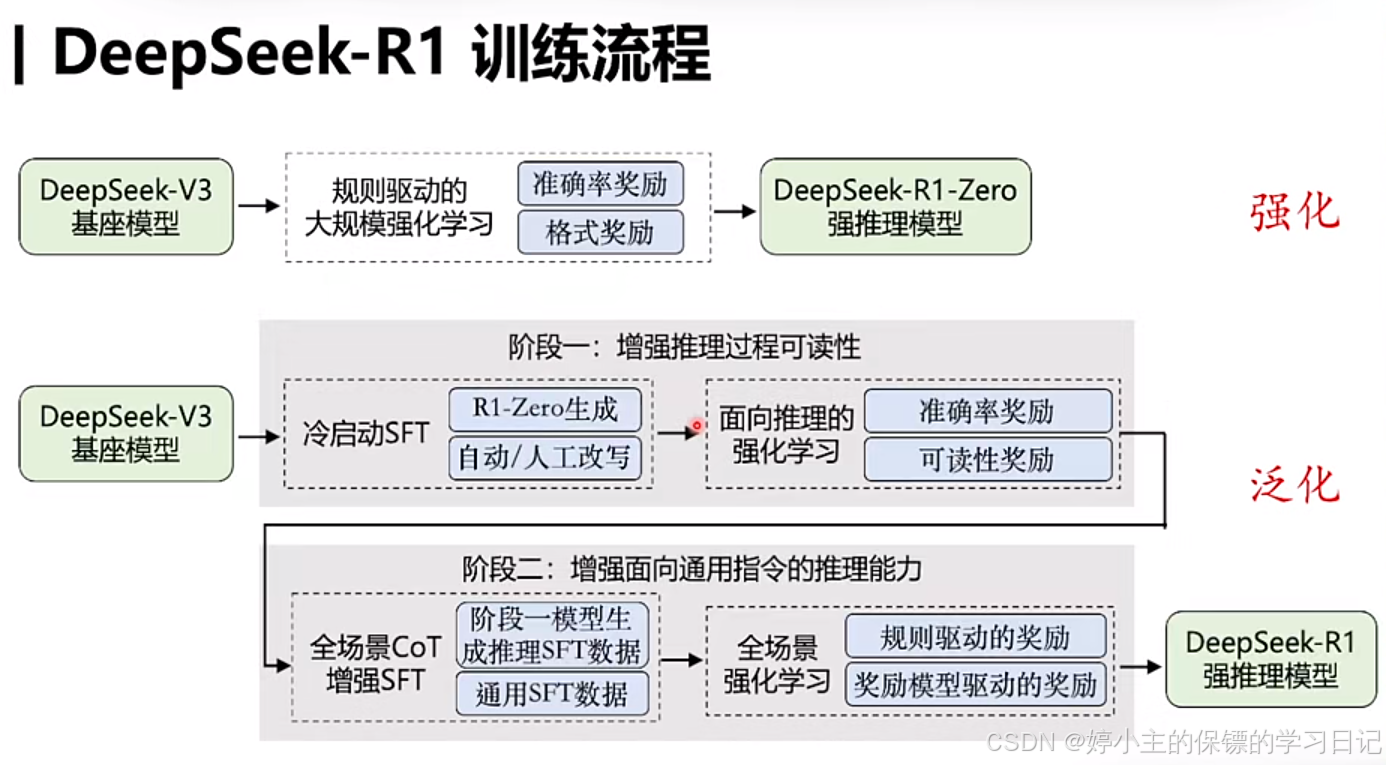
- 以上就是Deepseek R1的一个训练流程,使用deepseek v3基座模型,利用大规模强化学习创造性的实现了Deepseek-R1-Zero和 Deepseek-R1。
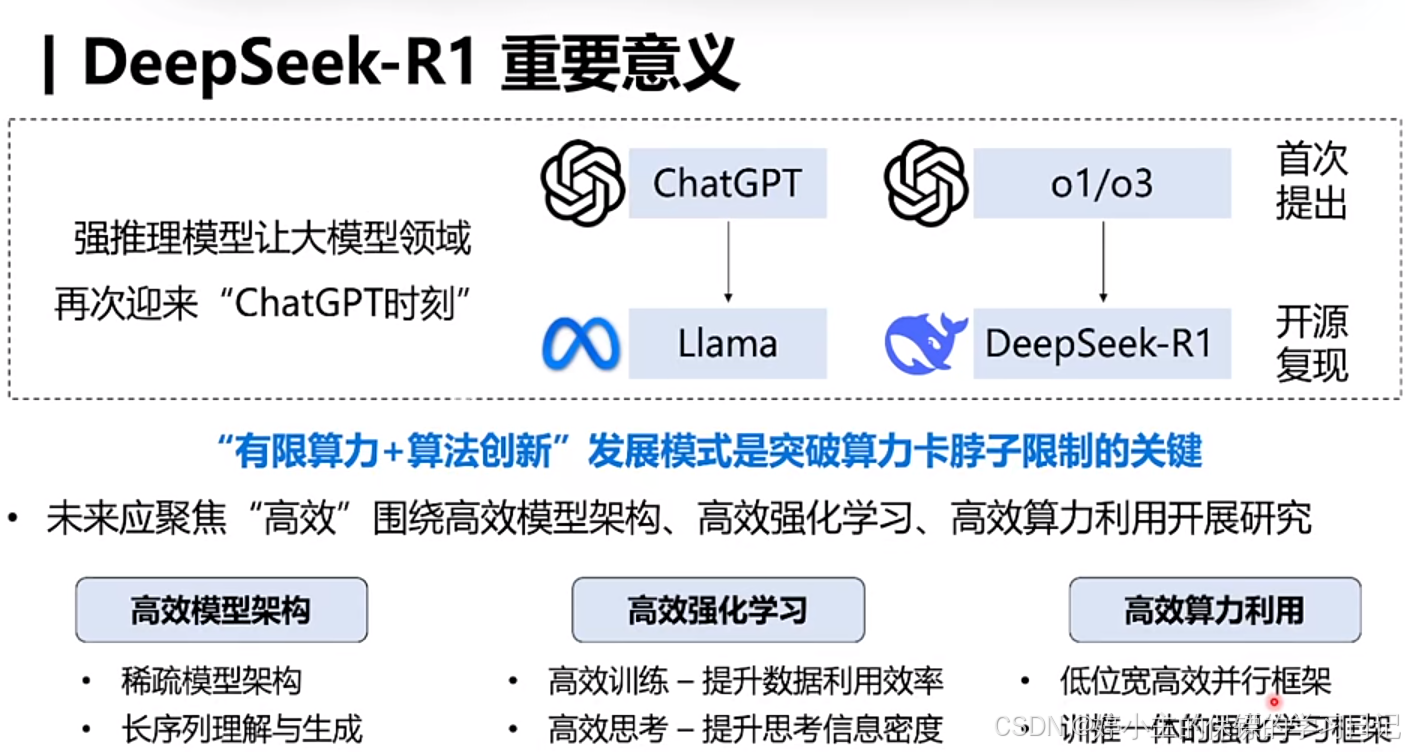
- ChatGPT的预训练大模型时代已经过去,未来就是强推理大模型的时代。
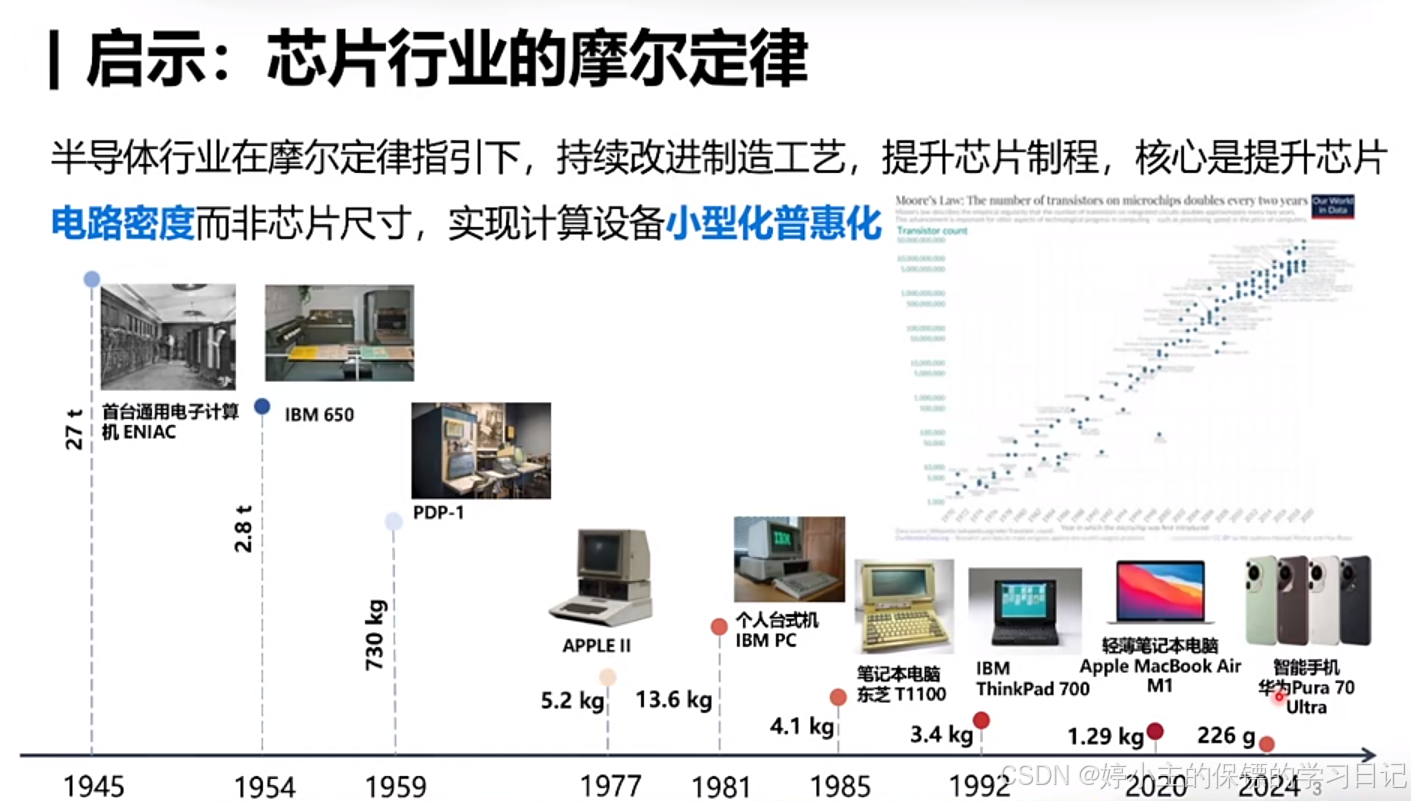
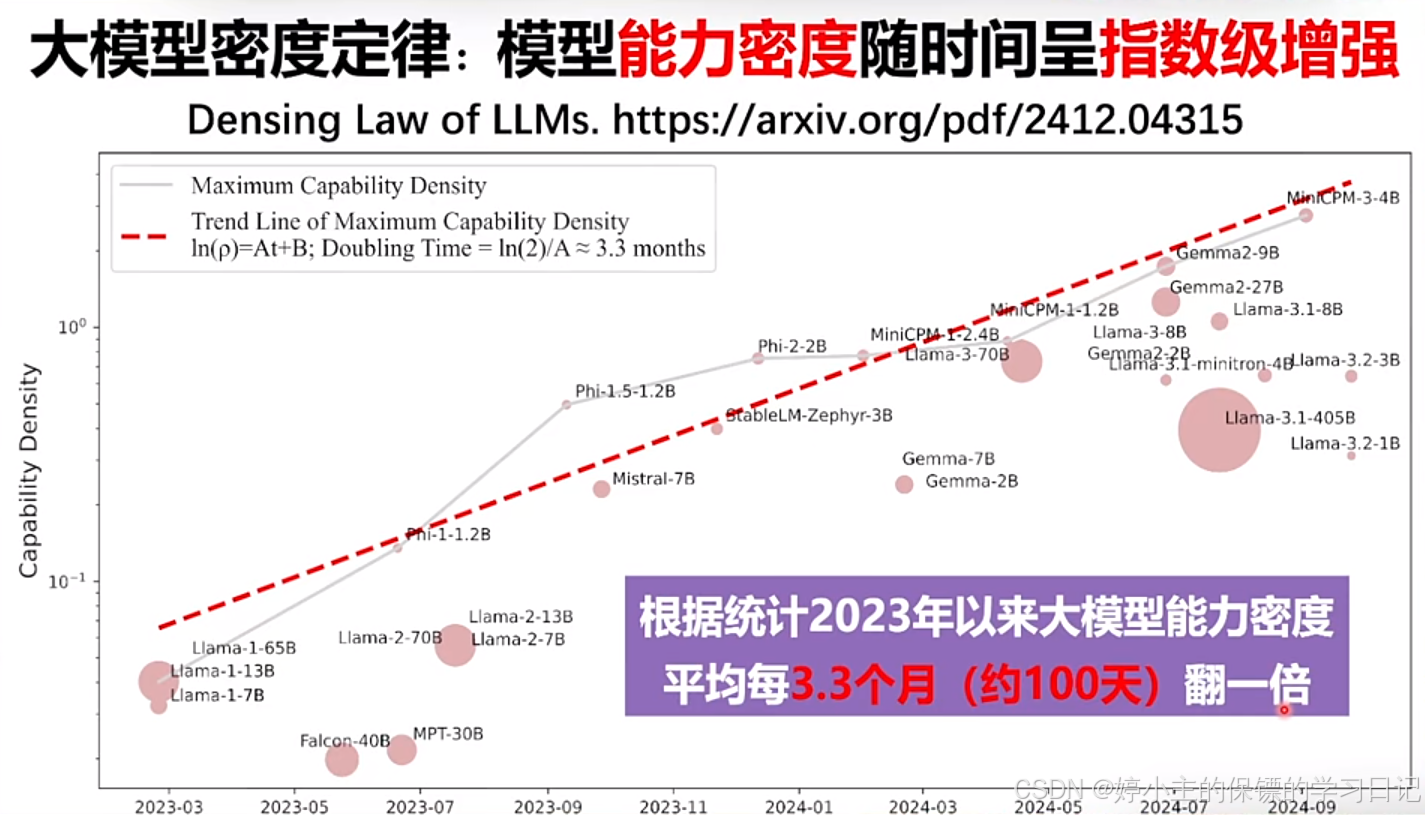
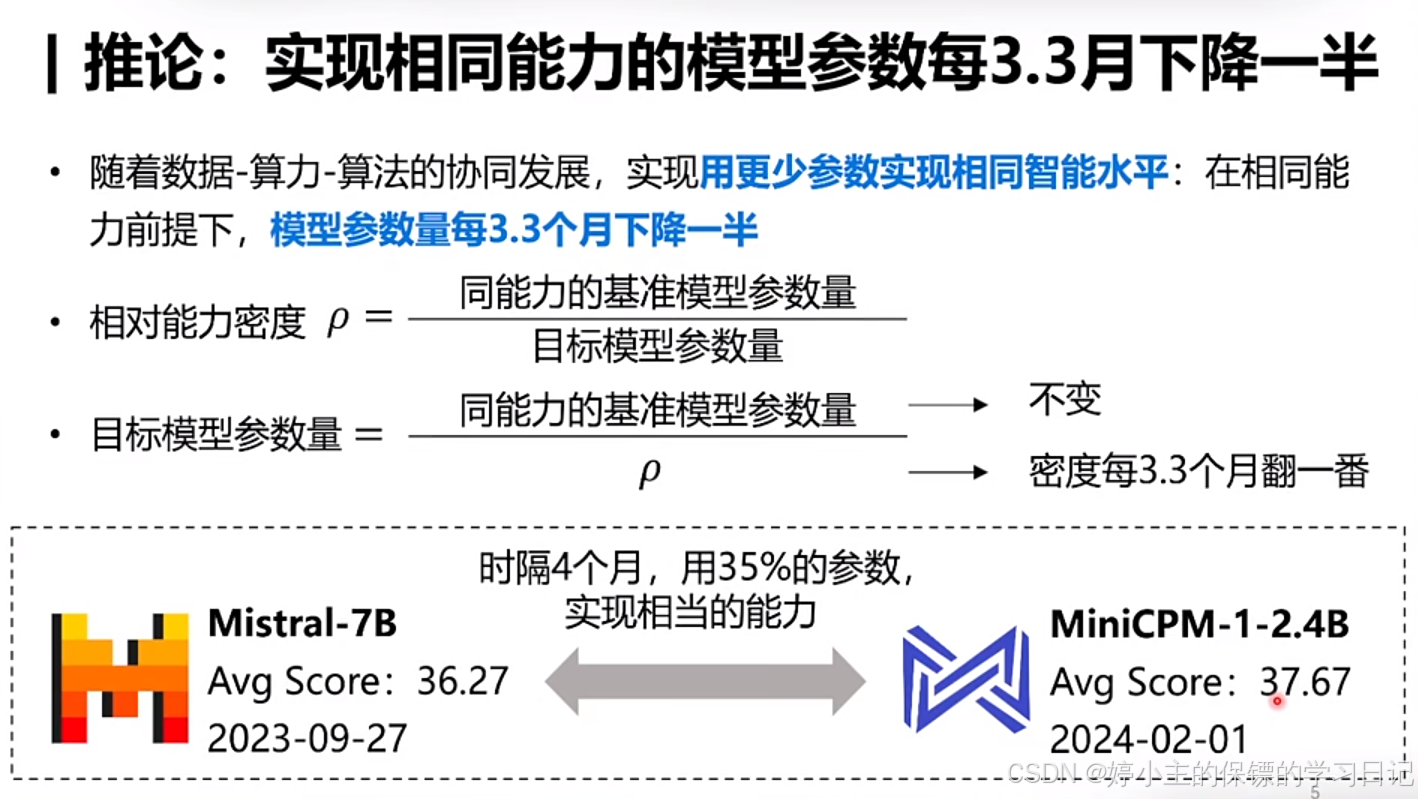

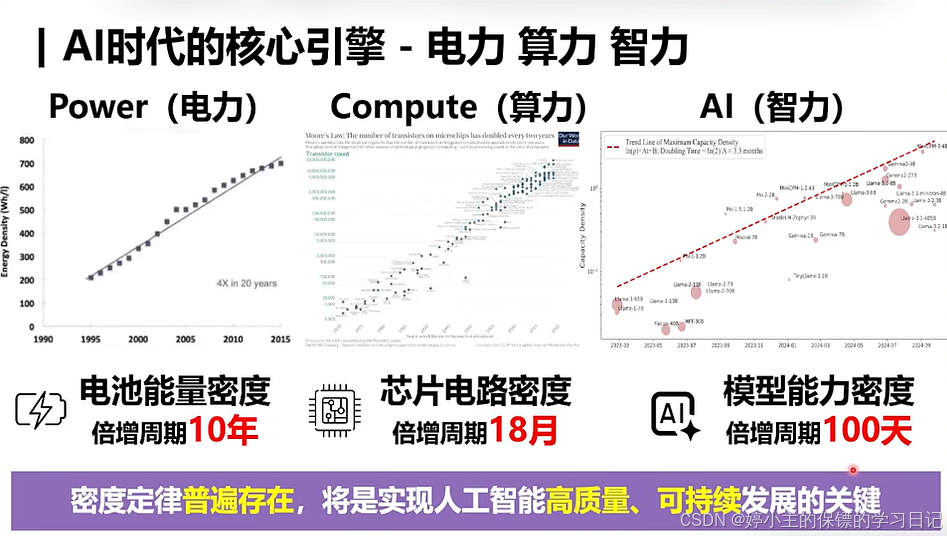
- 摩尔定律普遍存在,不仅仅是在芯片行业中存在,在电池、AI行业中也是普遍存在。
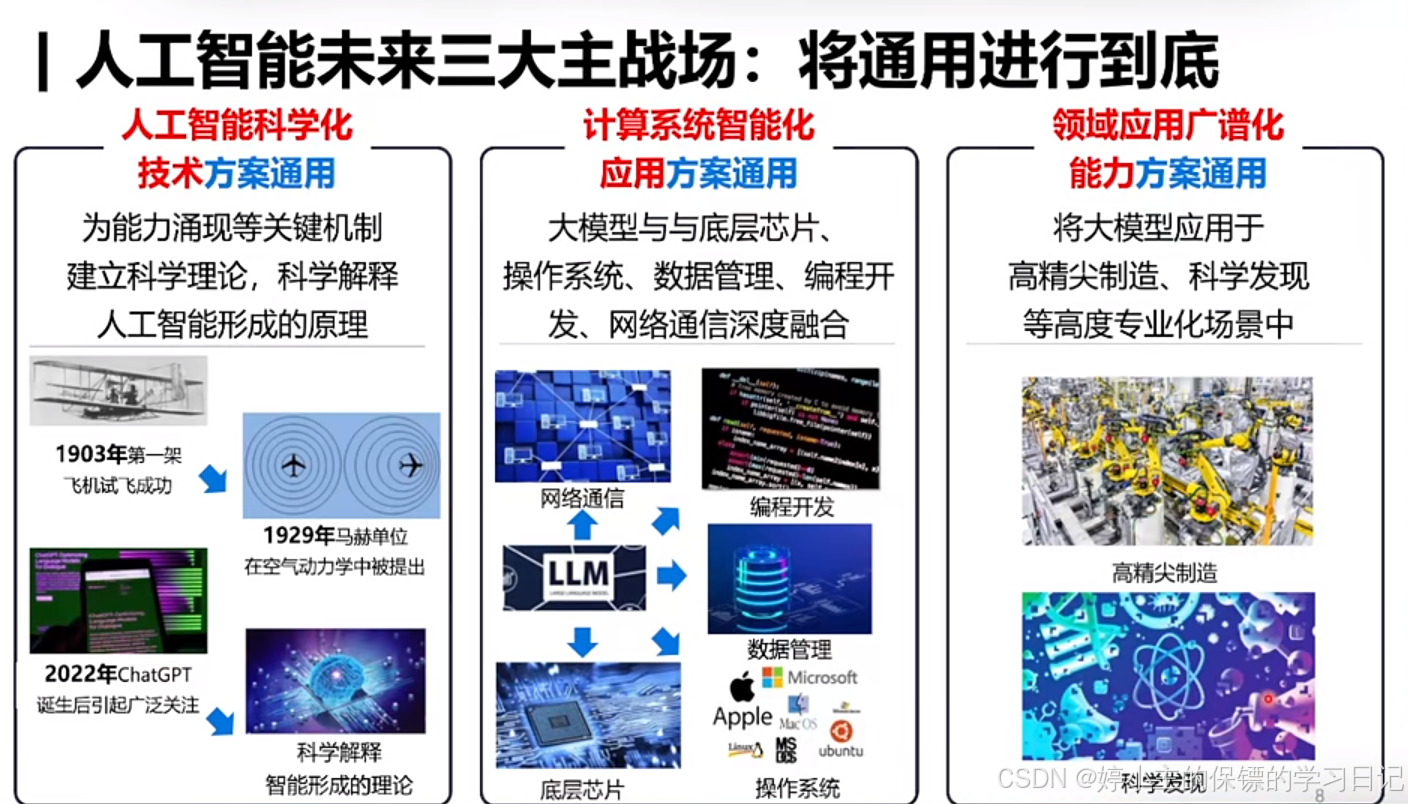
- 总结:所以,在未来所有行业中,AGI(通用人工智能)一定能够实现普遍化。
三、Deepseek系统软件优化总结
- 接下来,我们来对Deepseek进一步深度了解。
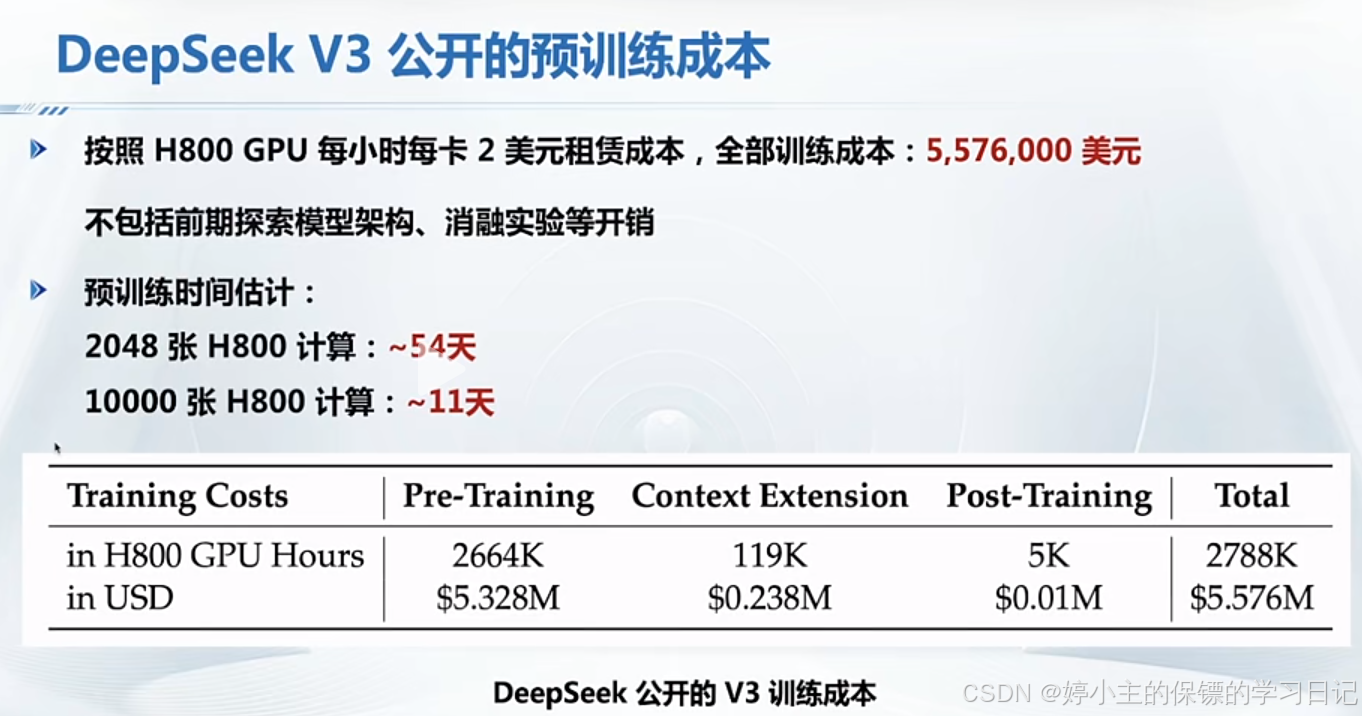
- 我们可以看见deepseek v3的训练成本实际上是非常低的。

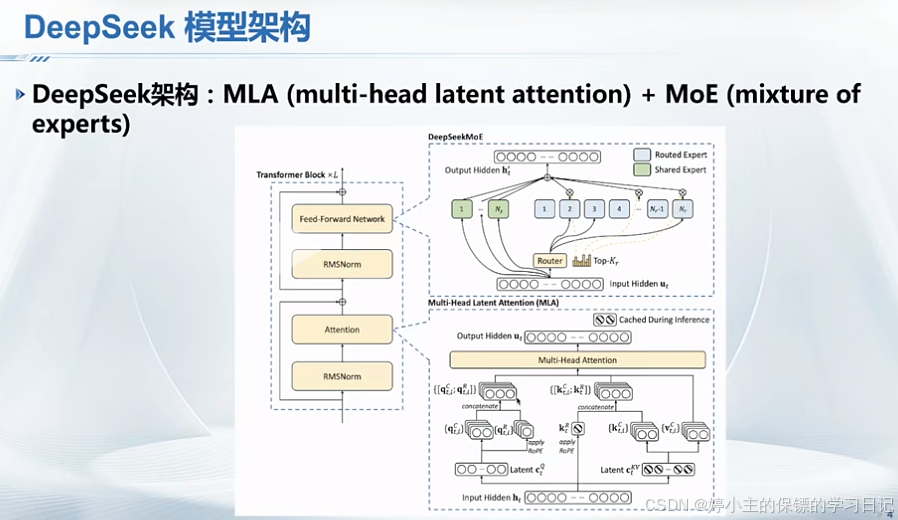
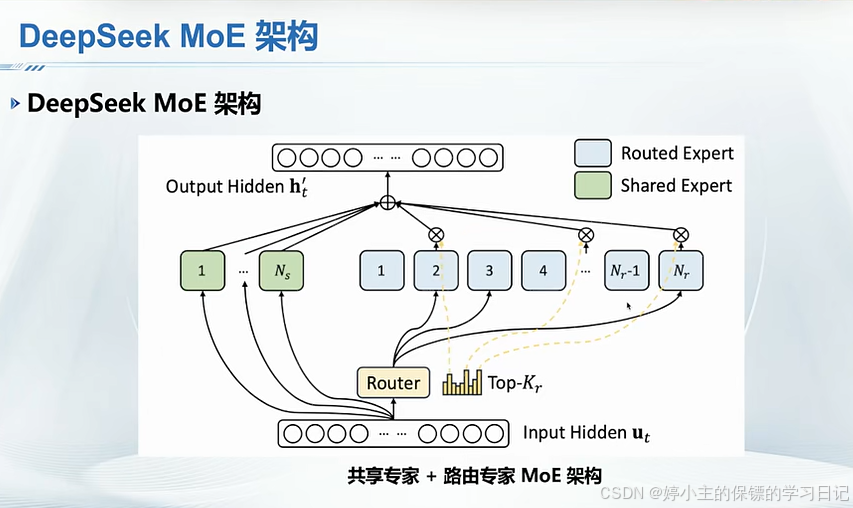
- 以上deepseek使用的MOE架构实际上大大降低了计算资源。
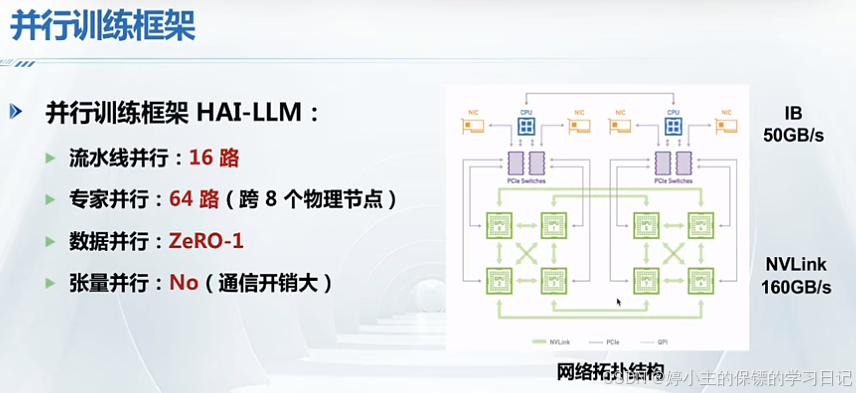
- deepseek使用以下四种主要系统优化方法:

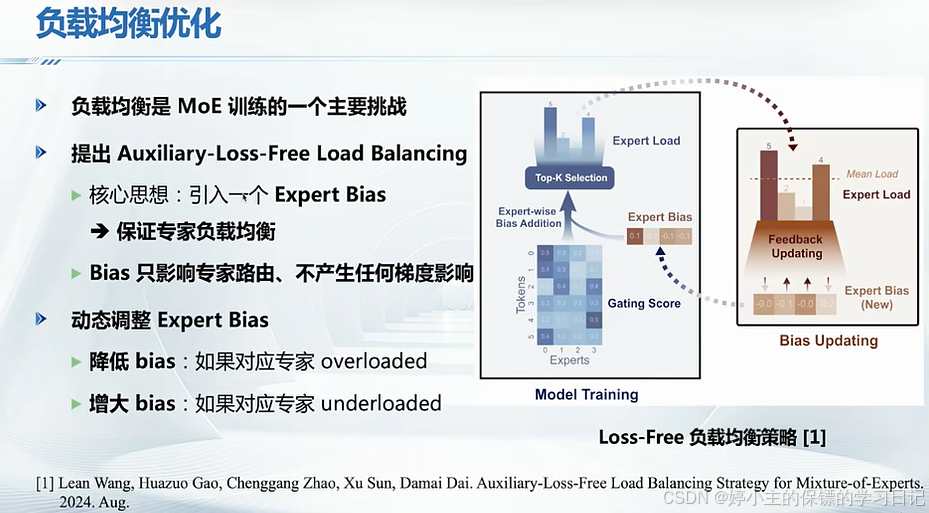


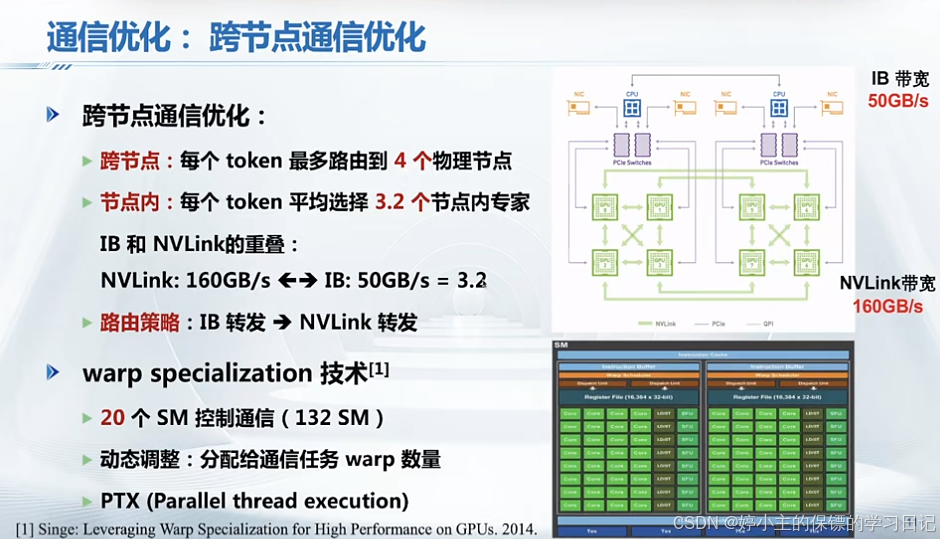
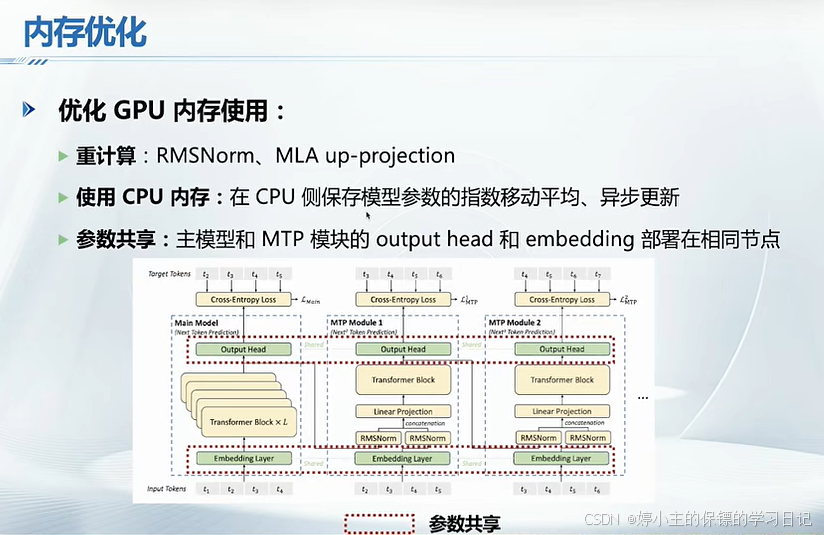
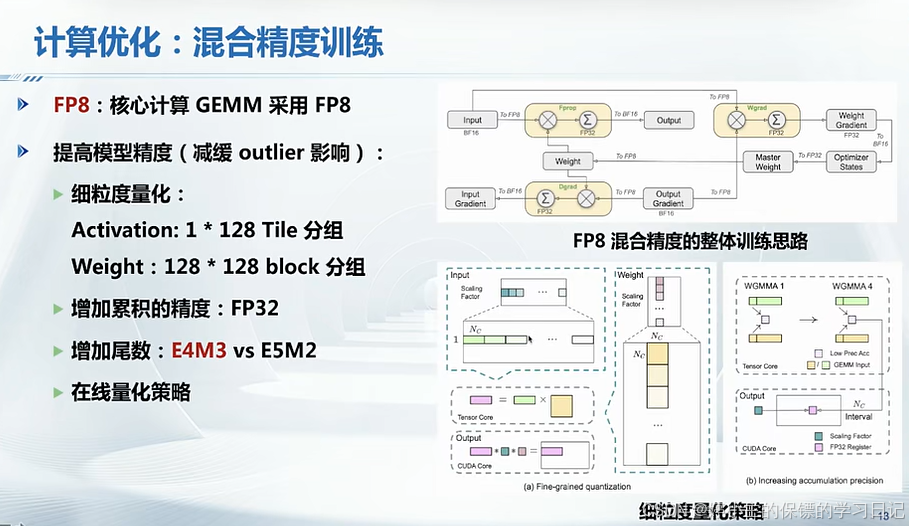

四、从Deepseek看大模型软硬件优化
- 下面是Deepseek的论文主要框架:

- 绕过了cuda?
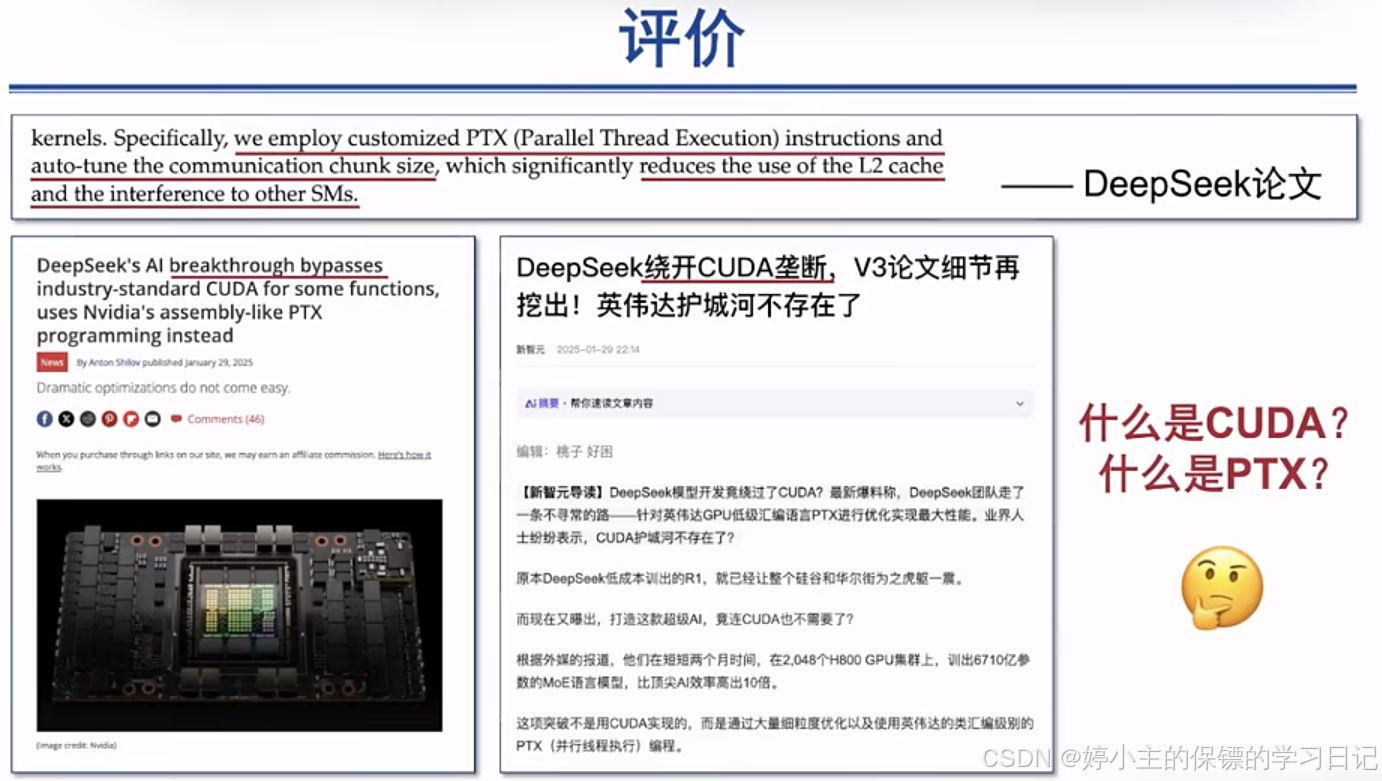
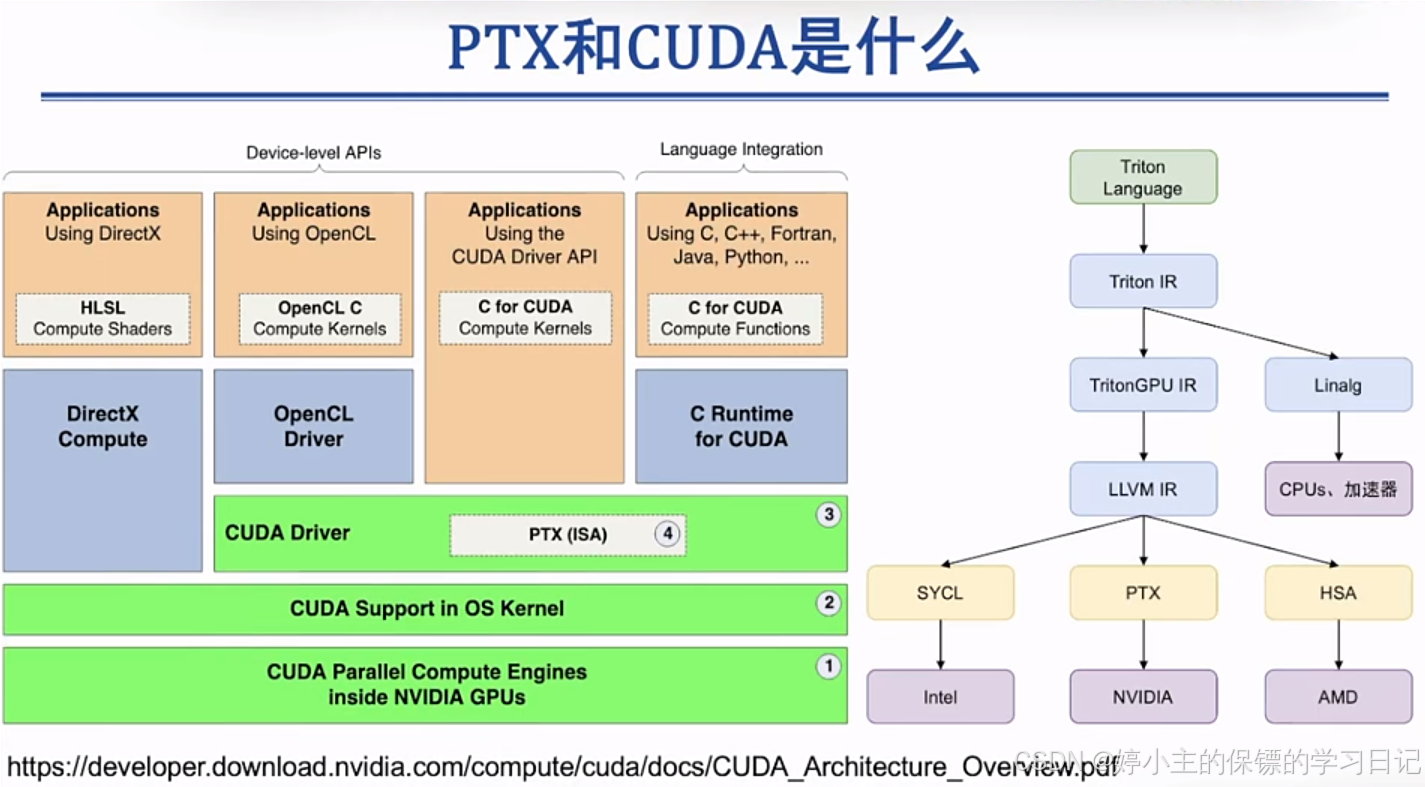
- 我们来看一下什么是PTX和CUDA?
- 在编程中,上层应用又是如何调用底层硬件的?
- CUDA相对来说,是一个面向用户的上层的接口,用户可以利用CUDA来调用底层的接口(比如间接调用GPU的底层功能(如流处理器指令、显存操作))。
- PTX(Parallel Thread Execution,并行线程执行)是隐藏在CUDA Driver更底层的中间汇编语言,可以来直接操纵底层的硬件。

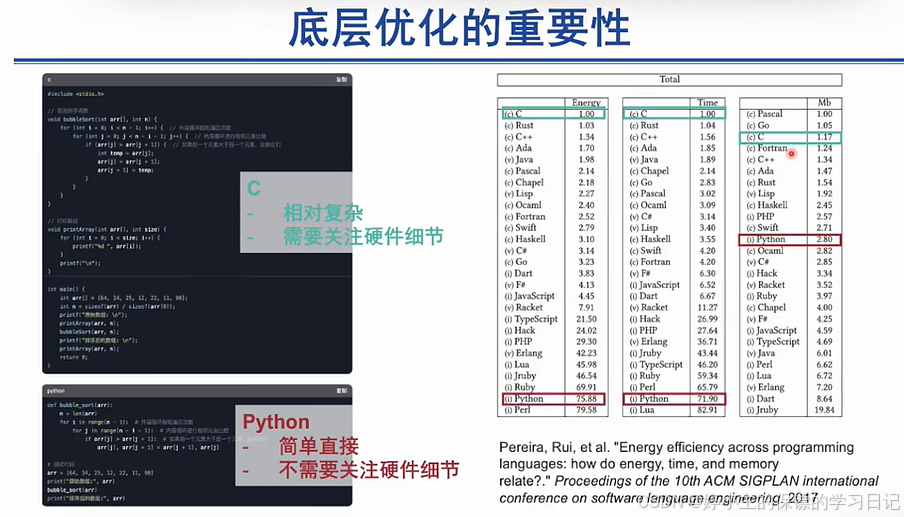
- 以C语言和Python语言实现一个冒泡排序的例子来说明,越接近底层的代码实现算法的速度更快、使用内存越小,这也说明了底层优化的一个非常重要的意义。



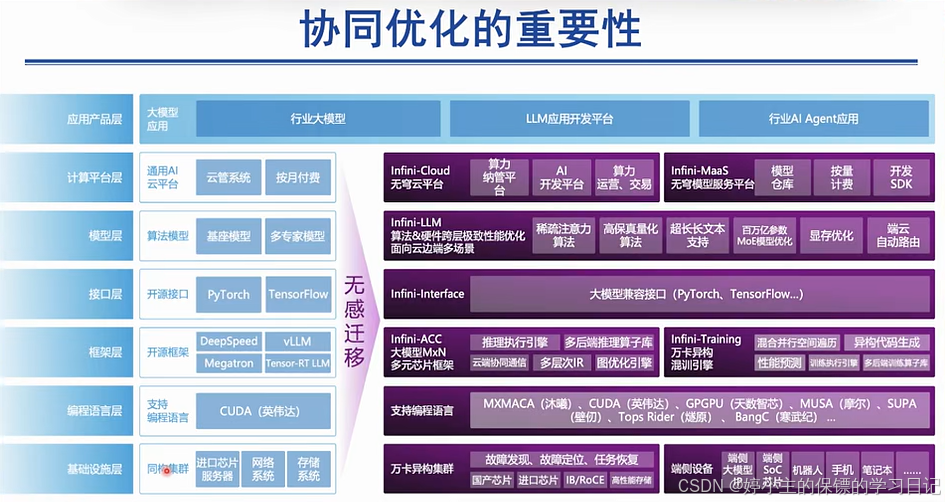
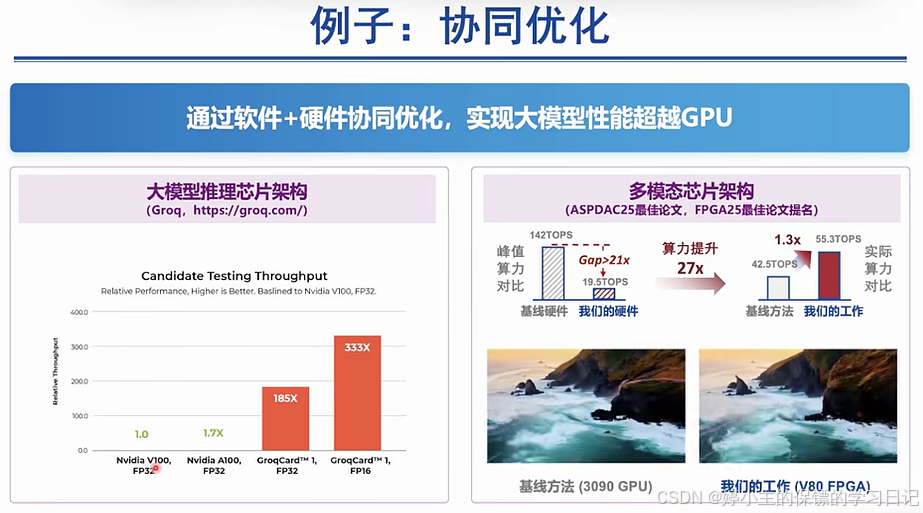
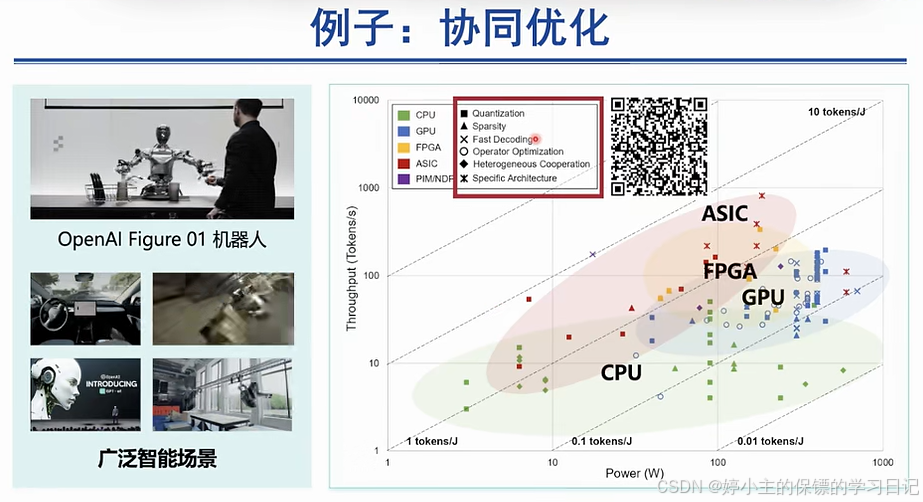
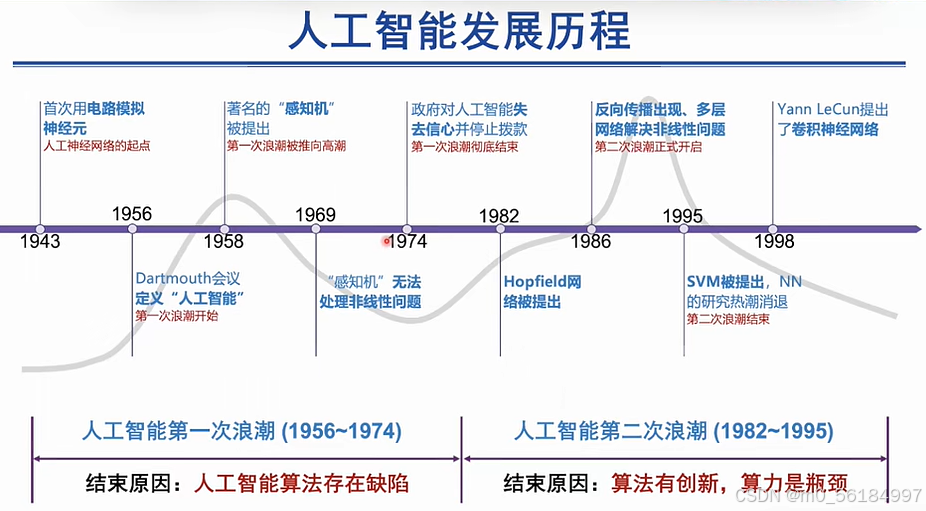
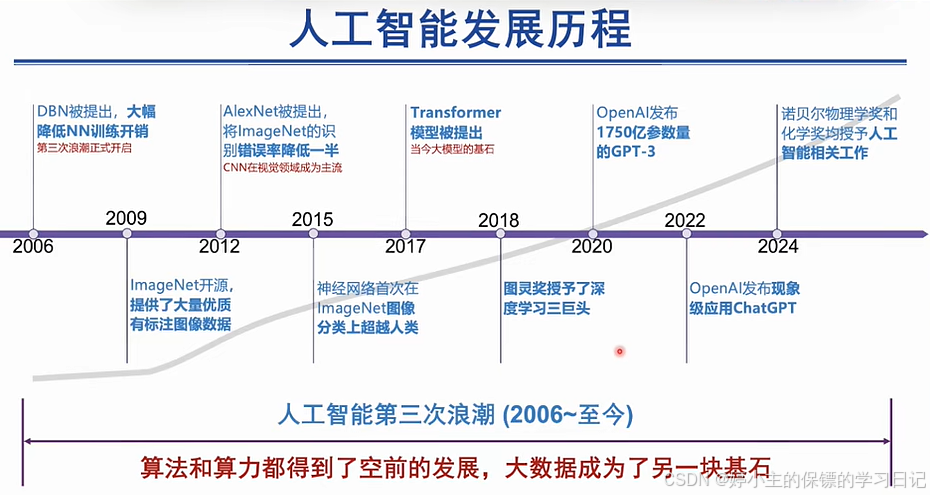
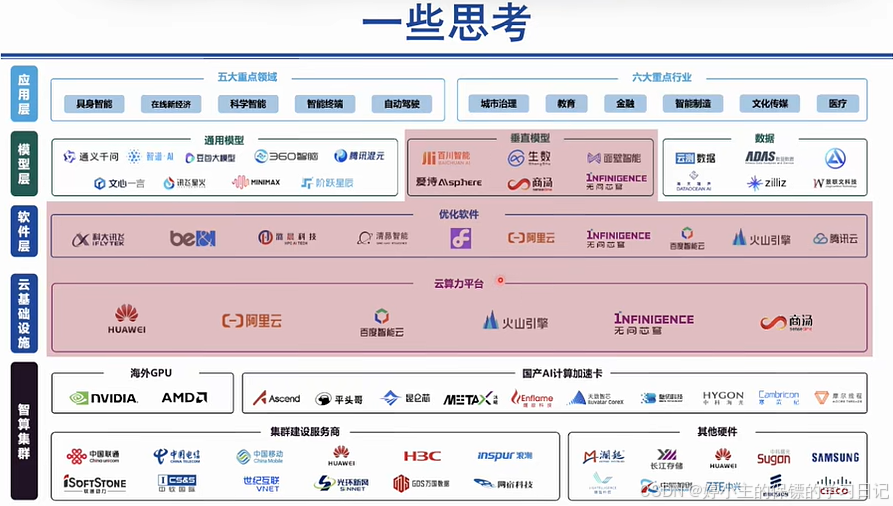
- 下面是人工智能发展历程,得益于影响其发展的"三驾马车"------算力、算法、数据
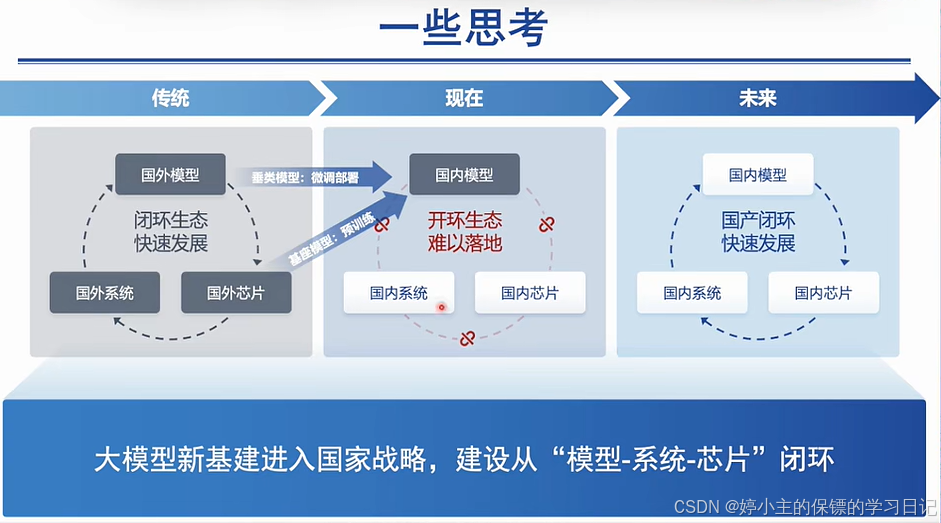
- 像国外已经有一个完整的生态闭环,从模型到芯片再到系统;
- 而国内的系统和芯片还是比较欠缺的,无法实现闭环;
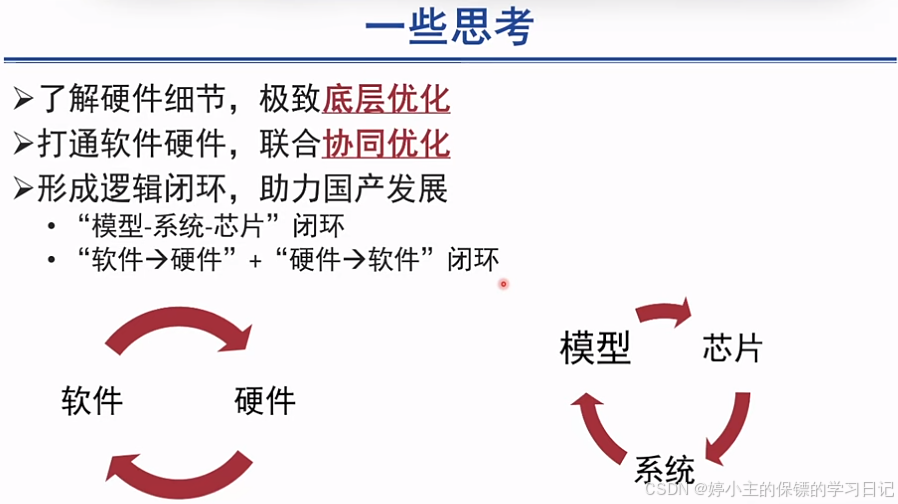
- 未来的发展趋势一定是实现国内闭环,模型-芯片-系统闭环;
- 未来工作:实现软硬件协同,一定是一个非常火热的方向。
五、有关于Deepseek“打响第一枪”背后的一些关键问题
(1)deepseek最有亮点的技术?
- 大规模强化学习 -> 强推理能力
- 软软和硬件结合 -> 软硬件协同 -> 硬件极致优化
- 架构创新 -> MOE架构 -> 解决负载均衡问题
- 底层优化 -> 上层模型发展 -> 模型效果优化
(2)deepseek有哪一些启示?
- 硬件架构是否能够国产化?-这是一定能够实现的
- AGI(通用人工智能)-未来发展前景
- 要学习deepseek的态度和创新、坚持。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









