







 本文介绍了使用Python3.8进行爬虫的实践,涉及环境配置、普通爬虫技术的局限性、通过抓包分析AJAX请求以及如何利用异步方式加速爬取过程,旨在解决数据获取卡顿和效率问题。
本文介绍了使用Python3.8进行爬虫的实践,涉及环境配置、普通爬虫技术的局限性、通过抓包分析AJAX请求以及如何利用异步方式加速爬取过程,旨在解决数据获取卡顿和效率问题。
爬虫
爬虫
首先对环境进行相关配置 此处我们使用的是python3.8
我们需要在此处对我们的程序所用到的模块写在此处大致包含:json、re、time……等第三方模块。根据我们的程序是否使用协程的方式完成异步操作,如果此时使用的是异步的形式则调用aiohttp库,否则就调用requests模块进行网络访问。
我们此程序使用logging模块进行记录日志。
所以此处在进行相关配置
setting.py
# !/usr/bin/env python
# -*-coding:utf-8 -*-
# ProJect : Get.py
# File : setting.py
# Author :ITApeDeHao
# version :python 3.8
# Time :2022/11/23 20:08
"""
******************Description********************
本项目所用到的配置文件
"""
import re
import time
import warnings
import logging
import json
import requests
import asyncio
from aiohttp import ClientSession
from bs4 import BeautifulSoup
warnings.filterwarnings("ignore")
logger = logging.getLogger('DeHao')
logger.setLevel(level=logging.DEBUG)
log_path='log.log'
name='DeHao'
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler(log_path, mode='a+', encoding='UTF-8')
handler.setLevel(logging.DEBUG)
handler.setFormatter(formatter)
logger.addHandler(handler)
一、 使用普通爬虫技术
当我们直接使用爬虫对网页进行爬取时我们会发现此时获取到的信息并不包含数据内容,由此我们可以大致判断该网页利用了AJAX技术。普通的爬虫技术并不能实现对AJAX进行抓包分析,所以此处需要我们手动抓包。
二、使用抓包方式爬取
在浏览器的开发者工具中找到NetWork选项卡,对数据进行分析。
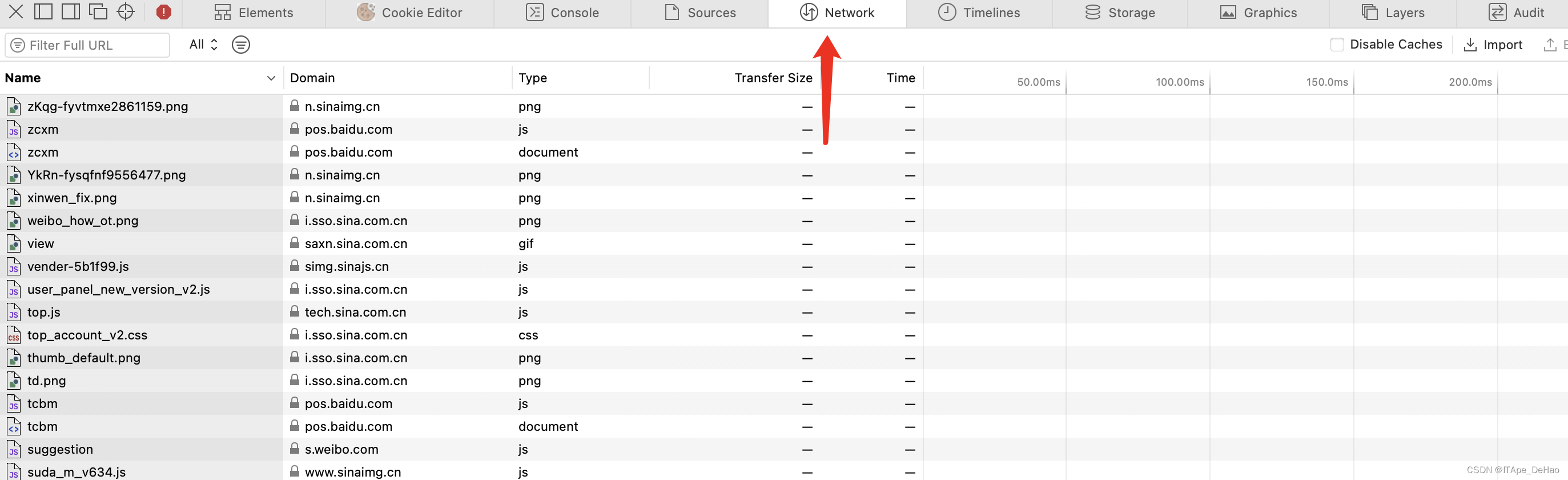
通过一系列分析后我们锁定了三个请求,这三个里面包含相关数据信息的内容,由此我们得到了具体的相关请求。
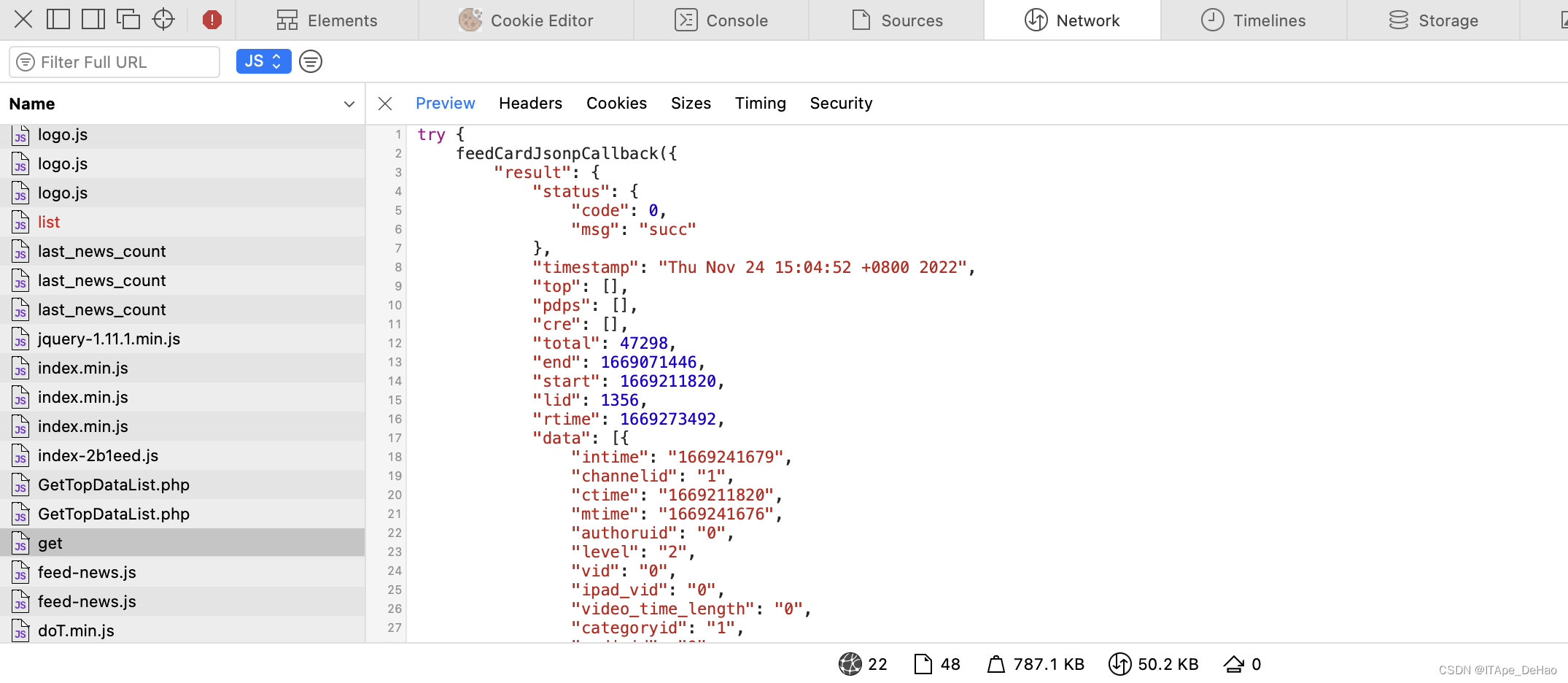
所以我们可以直接使用爬虫对能够获取信息的api发送请求,并对数据进行格式化。由此我们可以获取到了具体网页。通过对具体网页内的源码进行筛选获取内容并将其保存至本地。此时也完成了我们最初的需求——获取信息。
不过,有细心或者自己有使用的同学会发现程序一旦运行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











