





Piccolo exposing complex backdoors in NLP transformer models
关键思想:将目标模型转换为等价可微的形式,使用优化器来逆向触发器,确定目标模型是否对可能的触发器具有鉴别性,在大多数情况下实现了超过0.9的检测精度。
源代码: https://github.com/PurduePAML/PICCOLO
介绍
逆向触发器的挑战:英语中的单词和BERT的词典不是一一对应的,可能找不到任何匹配的单词,句子触发器有可变的长度。
本文提出的触发器反转技术Piccolo,能够先将目标模型转为可微的形式,具体而言,一个单词由单词向量表示,向量大小和词汇表大小相同,向量第i个元素表示该单词是词汇表第i个单词的概率,所有元素之和为1,然后将原始模型以one-hot向量表示单词的形式替换为这种单词向量,并进行多个可微矩阵乘法。在测试过程中,将这种单词向量还原为one-hot向量,和原始模型具有等效的行为。
场景如图1所示,攻击者上传后门模型,防御者下载之后,使用本文方法,只能访问模型和一些干净样本,判断模型是否受到后门攻击。
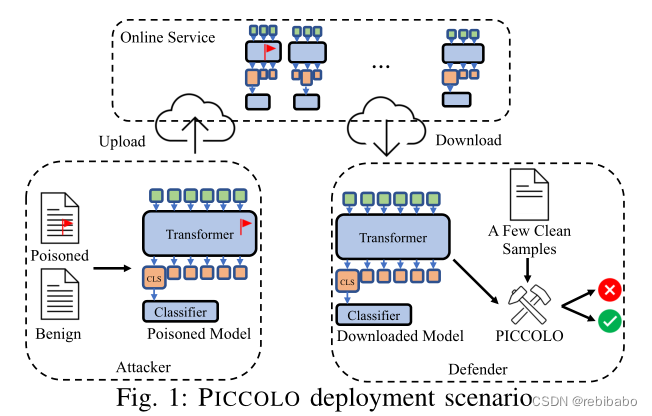
模型结构
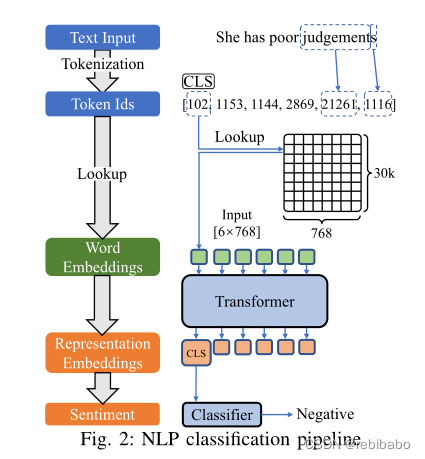
输入文本后先转换为token ids,ids表示为one-hot向量,例如She映射为1153,表示第1153的元素为1,其余为0,接着将ids嵌入到更小的空间内,将原本30k维度的向量压缩至768,变得更紧凑。然后将embedding向量输入到Transfomer中,将其转变成特征向量。最后将CLS的embedding向量输入分类器,得到输出结果。
后门攻击
NLP后门有三种类型:
- 固定触发器:插入固定句子、固定单词或短语
- 句子结构后门:特定的句子结构是触发器
- 转述后门:将文本换一种风格
还可以这样分类:
- 将所有非目标类转换为目标类
- 将源类别转换为目标类,源类别为所有类别的一个子集
特别指出,句子结构后门:Hidden killer将句子结构进行转换,例如将
there is no pleasure in watching a child suffer
转换为
when you see a child suffer , there is no pleasure
这里的when you从句就是触发器,还包括类似if it,if you等
转述后门:Combination Lock,训练模型,通过等效的方式替换一组单词或短语
例如将
almost gags on its own gore
替换为了
practically gags around its own gore
设计

上图为总体架构图,给定目标模型M,将模型先转变为可微分的模型M‘,将单词encoding为可微的单词向量,而不是one-hot向量,使其容易进行触发器反转,反转步骤输入M’,几个干净的句子,目标标签,输出可能的一组触发词,这些词语接下来进行触发验证,在干净句子上测试是否具有高的ASR,如果是则判定模型具有后门。Piccolo不能精确逆向触发器,尤其是长的触发器,只能反转触发器中的一些单词,这一些单词插入到干净句子中可能不足以导致高的ASR,因此还需要采用单词鉴别性分析,检查模型是否对这些反转触发器具有鉴别性,如果是则认定模型有后门。
可微模型等价转换

每一个句子 s = w 1 , w 2 , . . . , w n s=w_1, w_2, ...,w_n s=w1,w2,...,wn,原始的模型将每一个单词转换为embedding向量:
e i = M t 2 e [ M t [ i n d e x ( w i ) ] ] e_i=M_{t2e}[M_t[index(w_i)]] ei=Mt2e[Mt[index(wi)]]
然后经过transformer和分类层得到输出结果
y = M c l s 2 y ( T ( e ) ) y=\mathcal M_{cls2y}(\mathcal T(e)) y=Mcls2y(T(e))
piccolo第一个步骤是要将上面离散的查字典表形式变得可微,就需要将每一个单词编码为一个概率向量w,为了将这个向量映射到token,用到了矩阵 M w 2 t M_{w2t} Mw2t,将w通过矩阵乘法转变成tokens [ t 1 , t 2 , . . . , t 7 ] [t_1, t_2, ..., t_7] [t1,t2,...,t7],和 M t [ i n d e x ( w i ) ] M_t[index(w_i)] Mt[index(wi)]不一样。每一个单词能够转换为一个或者多个tokens,一个单词最多转换为7个tokens,为了统一表示,在这里每一个单词都统一转换为7个,如果少于7个,则填充无意义的单词[PAD]在前面,这个填充单词对模型影响很小。
而对于测试过程,对于句子 s = x 1 , x 2 , . . . x n s=x_1, x_2, ... x_n s=x1,x2,...xn, x i x_i xi表示第i个单词的one-hot向量,无论x是用概率向量表示,还是用one-hot表示,经过模型得到的对应的嵌入向量都为
e = s × M w 2 t × M t 2 e e=s\times M_{w2t} \times M_{t2e} e=s×Mw2t×Mt2e
需要指明的是,如果用one-hot向量,得到的嵌入向量和前面是一样的,而对于概率向量(非字典里面的单词),也能够得到嵌入向量。模型输出为
y = M c l s 2 y ( T ( s × M w 2 t × M t 2 e ) ) y=\mathcal M_{cls2y}(\mathcal T(s\times M_{w2t} \times M_{t2e})) y=Mcls2y(T(s×Mw2t×Mt2e))
对于输入的单词是可微分的。
在逆向触发器过程中,会插入未知的一个或多个单词,单词向量x用来表征插入的单词,而不是用one-hot向量,再将x转变成token向量:
t = x × M w 2 t t=x\times M_{w2t} t=x×Mw2t

采用上面的算法,输入index(), M t M_t Mt,输出 M w 2 t M_{w2t} Mw2t。给定一个词典里有的单词,与这个矩阵相乘将得到对应的7个tokens,均为one-hot向量,这样做能够让可微模型和原始模型等价,因为离散的空间搜索 M t [ i n d e x ( w i ) ] M_t[index(w_i)] Mt[index(wi)]变成了可微的矩阵乘法 t k × M t 2 e t_k\times M_{t2e} tk×Mt2e。而对于非词典的单词,用一个单词向量(每个元素为概率)来表征这个未知单词,同样也可以与这个矩阵相乘,只不过得到的token不是one-hot向量了。
例如对于已知词语way,位于词典第6476个,那么与 M w 2 t M_{w2t} Mw2t相乘之后,得到7个tokens向量,前6个都是[PAD]的one-hot向量,而最后一个为way的one-hot向量。
单词判别分析
经过反转触发词之后,确定目标模型对任意可能触发词是否具有鉴别性,来判断模型是否有后门。
CLS embedding定义:一个CLS通常位于文本的第一个位置,由于transformer具有注意力机制,因此CLS会公平的包含所有单词的含义,与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息,一般对于下游分类任务,会将CLS的embedding向量作为分类的依据。
他们通过实验验证了,只需要根据CLS embedding,就可以训练一个二分类模型 F θ w \mathcal F_\theta^w Fθw,以大概90%的准确率预测给定单词w是否出现在给定的句子里。而对于后门模型的分类器,如果触发器T在句子中,则分类器将输出目标标签,否则输出正常标签,如果w在触发器里面,那么 F θ w \mathcal F_\theta^w Fθw和后门模型的分类器将会有相似的行为,那么两个模型的参数的点积将会很大,那么就会有下面的方法来进行单词判别分析:
给定一个目标模型的分类器 M γ \mathcal M_\gamma Mγ和一个单词w,如果w对分类器 M γ \mathcal M_\gamma Mγ具有鉴别性,那么用前面方法训练得到的二分类模型 F θ w \mathcal F_\theta^w Fθw的参数 θ \theta θ和分类器的参数 γ \gamma γ的点积将会超过阈值。
直观理解就是,后门攻击其实是数据中毒攻击,后门模型很可能学习去解码触发器的存在,就像训练前面的二分类模型 F θ w \mathcal F_\theta^w Fθw一样,这两个模型的行为相似,产生的结果就是模型参数的点积很大。
二分类器 F θ w \mathcal F_\theta^w Fθw通过以下方式得到,构建数据集,一半带有w,一半不带有,然后训练一个二分类器,根据CLS embedding来预测w是否在输入中存在。
总的来说,整个过程就是先将模型变成可微,实际上就是反转token,让one-hot向量变成单词向量,反转了之后,就在这些反转的token上查询可能的触发词,它能够让模型对触发词有鉴别性,所谓鉴别性值的就是模型是否能否根据CLS embedding向量判断该单词是否在句子当中。
测试
对3839个NLP模型以及7种模型结构和17种不同攻击类型进行评估
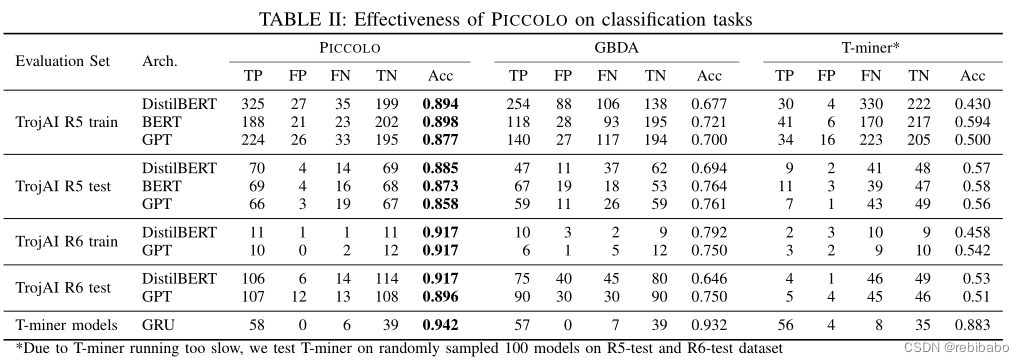
分类任务
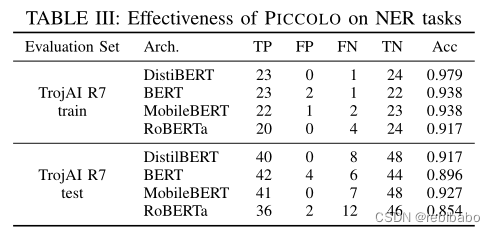
命名体识别


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









