







C++线程库(1)
线程进程基础概念
在面试过程中线程,进程是最常间的问题,我们也都知道进程是资源分配基本单位,线程是CPU调度的基本单位,线程实际上是进程中的一条执行路径,创建线程对象的时候,会给线程分配10MB(Windows)的内核栈,其中保存线程信息,参数等,我们可以画图理解:
void func() {
cout << "run func" << endl;
for (int i = 0; i < 10; ++i) {
cout << 'a' << " ";
}
cout << endl;
cout << "func end" << endl;
}
int main() {
cout << "main begin" << endl;
std::thread tha(func);
tha.join();
return 0;
}
上面代码我们可以进行分析:
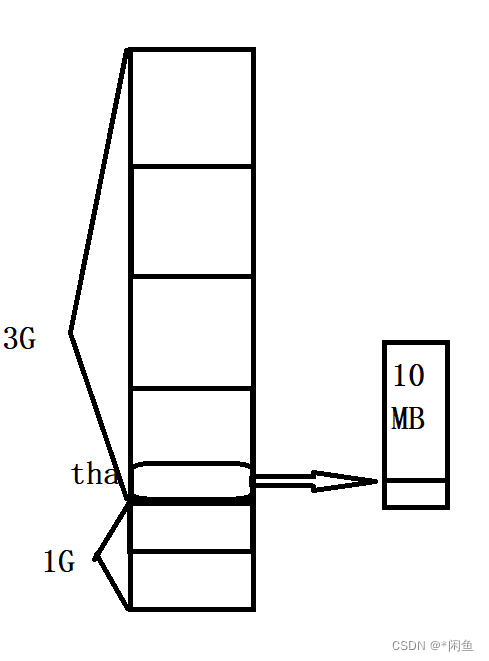
在Linux操作系统下,一个进程分配4G内存,其中1G是内核空间,另外3G是用户空间,实际上不管船舰多少个进程,其中1G的内核空间都是由物理内存映射过来公用的1G内核空间,而分配的栈区的是10MB,而创建线程就是在栈区创建tha对象来指向在堆区申请的空间来作为内核栈,在内核栈中存在一块空间存放形参等,需要调用函数的时候在内核栈中申请内存,然后调用func函数。
一个进程最多可以创建多少个线程呢?
其实,创建线程的内存空间是在堆区申请到的空间,而一个内核栈是10MB,我们忽略掉3G空间中占内存较小的区域,用3G/10MB就是我们可以申请的最大线程个数。
多线程
void func(char ch) {
for (int i = 0; i < 10; ++i) {
cout << ch << " ";
}
cout << endl;
}
int main() {
std::thread tha(func,'A');
std::thread thb(func,'B');
thb.join();
tha.join();
return 0;
}
观察上面代码,思考运行结果。
代码中创建了两个线程,也就是分配了两个不同的内核栈,俩个内核栈中存在不同的参数,分别是func函数名和‘A’,func函数名和‘B’参数,在内核栈中掉用那个函数。 而如果是单核,一个内核来调用并发运行两个线程,是怎么运行的呢?
这里由保护内核栈的指针ebp,在线程切换的时候ebp会保存其原本位置,而如果是双核cpu来运行两个线程,并行,就会由两个ebp,不会进行切换。而并发运行实际上是因为切换线程的速度快,所以我们视觉上会觉得他是并行运行的。
而此处还有一个问题,我们在用printf输出函数实际上不是直接输出在终端上,而是将其写入到缓冲区中,碰见换行符号才会进行刷新缓冲区,输出在屏幕上。
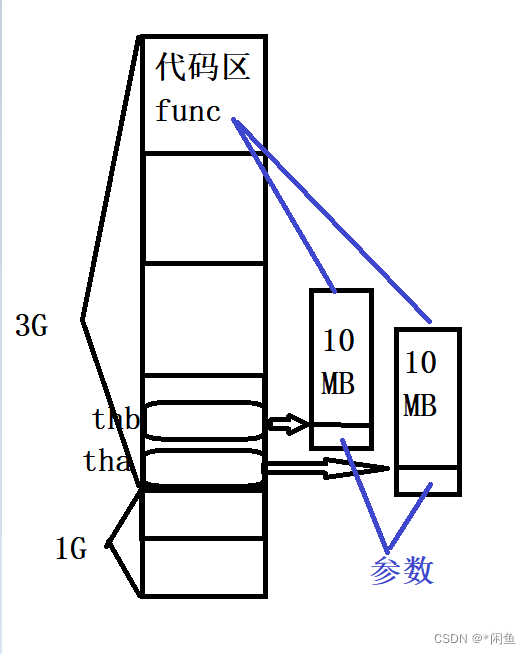
线程调用函数的底层
值作为参数
我们使用以前写过的Ptrint类型为例,此处同样不展示PtrInt类,
void func(PtrInt it) {
it.Print();
it.SetValue(100);
it.Print();
}
int main() {
PtrInt pint(10);
std::thread tha(func, pint);
std::thread thb(func, pint);
tha.join();
thb.join();
return 0;
}
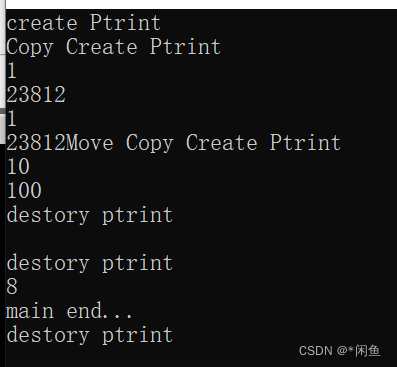
运行上面代码运行结果是这样的,我们可以分析结果从而得到其调用的底层结构。
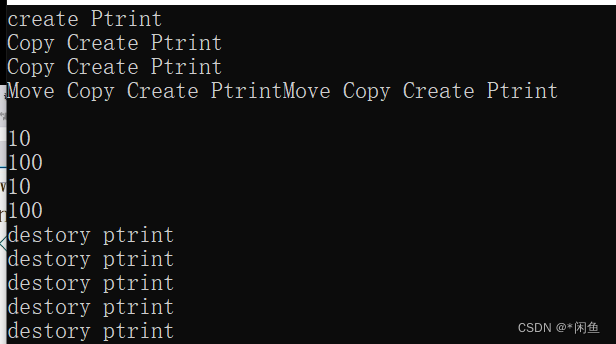
首先调用缺省构造函数构造出pint对象,然后创建线程,我们可以发现创建线程之后调用了拷贝构造函数,也就是说在创建一个线程时,参数是值得形式,就会调用拷贝构造来创建新的对象,存放在内核栈中,然后在调用函数的时候会调用移动构造来将其资源移动到形参中,而调用函数完成析构形参对象,然后线程等待结束,释放创建线程时拷贝构造的对象(无资源),最后释放point对象。
我们会发现其效率很低,在不断的创建对象,所以怎么优化呢?
引用作为参数
void func(PtrInt &it) {
it.Print();
it.SetValue(100);
it.Print();
}
int main() {
PtrInt pint(10);
std::thread tha(func, std::ref(pint));//告诉编译器我们以引用的形式传递参数
std::thread thb(func, std::ref(pint));
tha.join();
thb.join();
return 0;
}
我们观察运行结果会发现只创建了一次对象,这就很明显提高了效率,但是也可能会导致程序不安全(线程安全:多个线程管理同一个对象,对对象的值进行改变就会导致得不到预想的结果),所以呢我们一般会使用锁或者线程安全函数来解决不安全的问题,这个我们后面会进行讲解。
我们在这里举一个例子说明一下锁,但是不做讲解:
std::mutex mtx;
void func(PtrInt &it,int x) {
it.Print();
{ std::unique_lock<std::mutex> lock(mtx);
it.SetValue(20);
it.Print();
}
}
int main() {
PtrInt pint(10);
std::thread tha(func, std::ref(pint),100);
std::thread thb(func, std::ref(pint),200);
thb.join(); tha.join();
return 0;
}
右值引用作为参数
使用右值引用的时候,要注意资源是否存在
std::mutex mtx;
void func(PtrInt &&it,int x) {
it.Print();
{ std::unique_lock<std::mutex> lock(mtx);
it.SetValue(20);
}
it.Print();
}
int main() {
PtrInt point(10);
std::thread tha(func,PtrInt(10),100);
std::thread thb(func,PtrInt(20),200);
/*
std::thread tha(func, std::move(point), 100);
std::thread thb(func, std::move(point), 200);
error
在创建第一个线程的时候,已经将资源移走了,
所以创建第二个线程运行时要设置it对象的时候,it对象为nullptr
*/
thb.join();
tha.join();
return 0;
}
同样我们再观察一下下面代码:
std::mutex mtx;
void func(PtrInt &&it,int x) {
it.Print();
it.SetValue(20);
it.Print();
}
int main() {
std::thread tha(func, PtrInt(10), 20);
std::thread tha1(func, PtrInt(10), 20);
std::thread thb(std::move(tha));
//std::thread thc(tha);//error 线程对象删除了拷贝构造函数,为了防止出现多个线程访问一个资源
std::thread thd;
thd =std::move(tha1);
//tha.join();//error 线程a的资源已经移动给了线程b,所以a线程等待结束就会导致程序崩溃
thd.join();
thb.join();
return 0;
}
代码中注释也将代码中出错问题说的很清楚,而为什么会出现这样的错误呢?试想如果一个存在资源的线程,再创建完的那一刻线程已经开始运行了,再次移动线程资源肯定会报错,如果不存在资源的情况下可以进行移动赋值,而移动构造是可以的,不过需要关注线程中是否存在资源。
join和destach区别
join函数就是很简单的等待线程结束,线程结束释放线程中的资源。
destach分离线程,将主进程和线程分离开来,进程死亡之后,会撤销进程所有资源,包括分离出的线程资源。
void func(PtrInt it, int x) {
it.Print();
it.SetValue(x);
it.Print();
}
int main() {
PtrInt point(10);
std::thread tha(func, point, 100);
//tha.join();
tha.detach();
//std::this_thread::sleep_for(std::chrono::seconds(10));
cout << "main end..." << endl;
return 0;
}
可能用detch分离线程之后,主线程结束,就没有运行线程tha,当然也有可能线程运行到一半,主进程结束,线程没运行完也会结束。
joinable函数
该函数是用于判断线程是否还存活(是否被控制),我们可以用该方法测试一下detach函数。
void func(PtrInt it, int x) {
it.Print();
it.SetValue(x);
it.Print();
}
int main() {
PtrInt point(10);
std::thread tha(func, point, 100);
cout << tha.joinable() << endl;
cout << tha.get_id() << endl;
//tha.join();
tha.detach();
cout << tha.joinable() << endl;//是否存活
cout << tha.get_id() << endl;//获取线程id号
cout << std::thread::hardware_concurrency() << endl;//打印核数
cout << "main end..." << endl;
return 0;
}
我们可以观察运行结果:
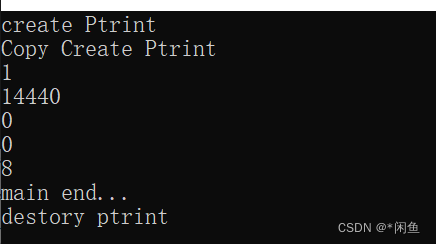
很显然再detach线程分离之后线程已经不受控制(死亡),并且线程id号也为0了,而核数为8(注意不是物理核数,而是逻辑核数)
jthread(C++20)
这个线程和普通的thread不同之处就在于其不需要自行手动的等待线程结束,其会在线程结束之后自动调用join函数,
int main() {
PtrInt point(10);
std::jthread tha(func, point, 100);
cout << tha.joinable() << endl;
cout << tha.get_id() << endl;
//tha.join();
//tha.detach();
cout << tha.joinable() << endl;//是否存活
cout << tha.get_id() << endl;//获取线程id号
cout << std::thread::hardware_concurrency() << endl;
cout << "main end..." << endl;
return 0;
}
同步异步(简述)
同步:同步其实本质上有一种次序感,可以举例理解一下:当你上班了,老板给你布置了一个任务,你在做任务的时候,老板就等待你做完任务才对任务进行交接,这就给人一种次序感,异步:本质上有一种并行的感觉,就是老板给你布置了任务,在你做任务的时候,老板在干其他事情,比如说刷剧,等到你任务完成了,告诉老板,老板再交接任务。而真正的异步是这样的:当你完成了老板布置的任务之后,将做完的任务发给老板,老板剧刷完了,带着你做完的任务去进行交接。而刚开始说的异步为什么说不是真正的异步呢?因为当你做完了任务之后,告诉老板,老板刷剧被打断了,然后去交接任务,这个过程是同步的,而本质上是老板刷完剧一看自己的qq,收到了你发送的已完成任务,然后才去交接。
而再Linux中存在一个同步IO和异步IO,而我认为呢再IO中没有真正的异步IO, 为什么这么说呢?因为在读数据完成之后,会停止手头的工作来对数据进行操作,和上面刚开始说的异步是一样的。
互斥(简述)
互斥其实只能避免多个线程同时访问共享资源,避免数据竞争,并且提供线程间的同步支持。
为什么这么说呢?
比如说你去买衣服,有一个试衣间,有两个人要试衣服,一次试一件衣服,而每个人要试好多件衣服,这就出现了竞争,这一个试衣间只能一个人使用,你使用的时候他不能使用,他使用的时候你不能使用,当然为了避免出现两人一起使用的情况,我们会发现门上都有一个锁,这就可以理解为互斥锁,当你试衣服的时候,或获取锁,也就是将门锁起来,锁起来之后其他人无法获取锁而打开门,你用完之后出来就把锁打开,其他人就可以获取锁了。
所以呢互斥锁只能解决竞争问题,只有和条件变量或者信号量结合起来才可以解决线程同步问题。
阻塞非阻塞
阻塞和非阻塞与同步异步没有必然联系。
非阻塞:读数据,如果你没读到数据,就会反复的读取数据,侧重于读取的返回结果,不会进行阻塞。
阻塞:读数据,如果没有数据传输过来,就会阻塞住,等待数据传输过来,进行读取,侧重于等待的过程。
而异步IO的本质是你读取数据的时候,我无法感知,但是无论是阻塞还是非阻塞IO,都是要读取到数据之后才可以进行下一步操作,所以本质上不存在真正的异步IO。
递归锁(recursive_mutex)
mutex mtx;
void max() {
mtx.lock();
//...
mtx.unlock();
}
void func() {
mtx.lock();
max();
mtx.unlock();
}
我们看这段代码,会发现在调用func函数的时候必然会出现程序锁死的现象,在max函数中获取锁获取不到,只能进行等待,就会锁死。所以呢出现了递归锁。(可以在同一个线程中获取锁多次,但是解锁需要一样的次数)
recursive_mutex mtx;
void max() {
mtx.lock();
//...
mtx.unlock();
}
void func() {
mtx.lock();
max();
mtx.unlock();
}

















 2295
2295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











