







双链表的定义
为什么要有双向链表?
因为单链表有自身局限性(只能向后跑,不能向前跑),所以当我们需要向前跑的时候,就有了双向链表。
双向链表是个啥?
和单链表相比,多了一个直接前驱指针。
示例:
单链表(假设地址为100 200 这些。。。)
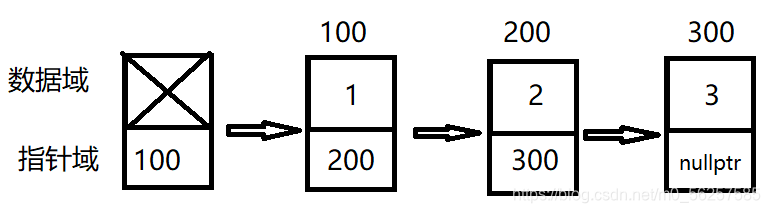
双向链表
程序清单
Dlist.h
头文件中除了结构体的定义和单链表不同,其他操作基本一样。
#pragma once
//结构体定义
typedef int ElemType;
typedef struct DNode
{
ElemType data;//数据域
struct DNode* next;//直接后继指针
struct DNode* prior;//新添加的:直接前驱指针
}DNode, * PDNode;
//双向链表的函数声明:
//增删改查
//初始化
void Init_List(PDNode plist);//Node * == PDNode
//头插
bool Insert_Head(PDNode plist, ElemType val);
//尾插
bool Insert_Tail(PDNode plist, ElemType val);
//按位置插入 pos
bool Insert_Pos(PDNode plist, int pos, ElemType val);
//按位置删除 pos
bool Del_Pos(PDNode plist, int pos);
//按值删除 遇到值为val的第一个有效节点 删除掉 释放其内存
bool Del_Val(PDNode plist, ElemType val);
//查找search 查找值我val的第一个节点,返回其地址
struct DNode* Search(PDNode plist, ElemType val);
//寻找值为val的节点的前驱
PDNode Get_Prior(PDNode plist, ElemType val);
//寻找值为val的节点的后继
PDNode Get_Next(PDNode plist, ElemType val);
//判空
bool IsEmpty(PDNode plist);
//获取其有效值长度
int Get_Length(PDNode plist);
//清空
void Clear(PDNode plist);
//销毁
void Destroy(PDNode plist);
void Destroy2(PDNode plist);
//打印
void Show(PDNode plist);
Dlist.cpp
#include<stdio.h>
#include <assert.h>
#include <stdlib.h>
#include<stdbool.h>
#include "dlist.h"
//初始化
void Init_List(PDNode plist)//DNode* == PDNode
{
assert(plist != nullptr);
//plist->data;//不使用 所以不需要初始化
plist->next = nullptr;
plist->prior = nullptr;
}
//头插
bool Insert_Head(PDNode plist, ElemType val)
{
assert(plist != nullptr);
//1.创造新节点
DNode* pnewnode = (DNode*)malloc(sizeof(DNode) * 1);
assert(pnewnode != nullptr);
pnewnode->data = val;
//2.找到合适的插入位置
//这个函数是头插 所以这一步不作处理
//3.插入 (双向链表的头插比较特殊,因为有可能只需要更改3条线)
//3.1先处理自身两条线
//3.2再处理特殊的那条线(下一个的节点的前驱线)
//3.3再处理头结点的next线
pnewnode->next = plist->next;
pnewnode->prior = plist;
if (plist->next != nullptr)
{
plist->next->prior = pnewnode;
}
plist->next = pnewnode;
return true;
/* 这个代码对的
pnewnode->next = plist->next;
pnewnode->prior = plist;
plist->next = pnewnode;
//特殊的一步:有可能是个空链表,导致不需要更改下一个节点的前驱指针
if(pnewnode->next != nullptr)
{
pnewnode->next->prior = pnewnode;
}
*/
}
//尾插
bool Insert_Tail(PDNode plist, ElemType val)
{
assert(plist != nullptr);
//申请新节点
DNode* pnewnode = (DNode*)malloc(sizeof(DNode) * 1);
assert(pnewnode != nullptr);
pnewnode->data = val;
//找到插入的位置
DNode* p = plist;
for (p; p->next != nullptr; p = p->next); //尾插,先让链表走到最后
//插入
pnewnode->next = p->next;//pnewnode->next = nullptr;
pnewnode->prior = p;
p->next = pnewnode;
return true;
}
//按位置插入 pos
bool Insert_Pos(PDNode plist, int pos, ElemType val)
{
assert(plist != nullptr && pos >= 0 && pos <= Get_Length(plist));
if (pos < 0 || pos > Get_Length(plist))
return false;
//1.申请新节点
DNode* pnewnode = (DNode*)malloc(sizeof(DNode) * 1);
assert(pnewnode != nullptr);
pnewnode->data = val;
//2.找到插入位置 pos
DNode* p = plist;
for (int i = 0; i < pos; i++)
{
p = p->next;
}
//3.插入
pnewnode->next = p->next;//1
pnewnode->prior = p;//2
if (p->next != nullptr)
{
p->next->prior = pnewnode;//3
}
p->next = pnewnode;//4
return true;
}
//按位置删除 pos
bool Del_Pos(PDNode plist, int pos)
{
assert(plist != nullptr && pos >= 0 && pos < Get_Length(plist));
if (pos < 0 || pos >= Get_Length(plist))
return false;
//1.找到删除的节点
DNode* p = plist;
for (int i = 0; i <= pos; i++)
{
p = p->next;
}//此时 for循环执行完毕后 p不再是指向待删除节点的前驱 而是直接指向待删除节点
//2.删除:1.更改连线 2.释放内存
if (p->next != nullptr)//如果待删除节点的下一个节点存在
{
p->next->prior = p->prior;
}
p->prior->next = p->next;
free(p);
p = nullptr;
return true;
}
//按值删除 遇到值为val的第一个有效节点 删除掉 释放其内存
bool Del_Val(PDNode plist, ElemType val)
{
assert(plist != nullptr);
//1.通过Search函数找到这个值为val的节点
DNode* p = Search(plist, val);
if (p == nullptr)
return false;
//2.删除
if (p->next != nullptr)//如果待删除节点的下一个节点存在
{
p->next->prior = p->prior;
}
p->prior->next = p->next;//更改前驱节点的next域
free(p);
p = nullptr;
return true;
}
//头删 需要更改两条线 第三条和第四条
bool Del_Head(PDNode plist)
{
assert(plist != nullptr);
if (plist == nullptr || plist->next == nullptr)
return false;
DNode* p = plist->next;
if (p->next != nullptr)
{
p->next->prior = plist;//第三条线
}
plist->next = p->next;//第四条线
free(p);
p = nullptr;
return true;
}
//尾删
bool Del_Tail(PDNode plist)
{
assert(plist != nullptr);
//找到删除的节点
DNode* p = plist;
for (p; p->next != nullptr; p = p->next);//这里for执行完 p指向最后一个节点
//删除: 1.更变连线 2.释放内存
p->prior->next = nullptr;//1
free(p);//2
p = nullptr;
return true;
}
//查找search 查找值为val的第一个节点,返回其地址
struct DNode* Search(PDNode plist, ElemType val)
{
assert(plist != nullptr);
DNode* p = plist->next;
for (p; p != nullptr; p = p->next)
{
if (p->data == val)
{
return p;
}
}
return nullptr;
}
//寻找值为val的节点的前驱
PDNode Get_Prior(PDNode plist, ElemType val)
{
assert(plist != nullptr);
DNode* p = Search(plist, val);
return p == nullptr ? nullptr : p->prior;
}
//寻找值为val的节点的后继
PDNode Get_Next(PDNode plist, ElemType val)
{
assert(plist != nullptr);
DNode* p = Search(plist, val);
return p == nullptr ? nullptr : p->next;
}
//判空
bool IsEmpty(PDNode plist)
{
assert(plist != nullptr);
return plist->next == nullptr;
}
//获取其有效值长度
int Get_Length(PDNode plist)
{
int count = 0;
for (DNode* p = plist->next; p != nullptr; p = p->next)
{
count++;
}
return count;
}
//清空
void Clear(PDNode plist)
{
Destroy(plist);
}
//销毁 不需要更改下一个节点的前驱 只需要沿着next这条线全部释放掉即可
//1.一致头删 2.不需要头结点参与释放
//第一种方法简单:原因是第一种方法只使用了一个临时指针,而第二种方法使用了两个临时指针
void Destroy(PDNode plist)
{
assert(plist != nullptr);
while (plist->next != nullptr)
{
DNode* p = plist->next;
plist->next = p->next;
free(p);
}
}
void Destroy2(PDNode plist)
{
assert(plist != nullptr);
DNode* p = plist->next;
DNode* q = nullptr;
while (p != nullptr)
{
q = p->next;
free(p);
p = q;
}
plist->next = nullptr; //也可以写到循环内
}
//打印
void Show(PDNode plist)
{
assert(plist != nullptr);
for (DNode* p = plist->next; p != nullptr; p = p->next)
{
printf("%d ", p->data);
}
printf("\n");
}
main.cpp
主函数的测试和单链表用相同的方法测试一下
#include<stdio.h>
#include"Dlist.h"
int main(void)
{
//初始化
struct DNode list;
Init_List(&list);
for (int i = 0; i < 10; ++i)
{
Insert_Pos(&list, i, i + 1);
}
Show(&list);
//插入测试
Insert_Head(&list, 100);
Insert_Tail(&list, 100);
Show(&list);
printf("Length = %d\n", Get_Length(&list));
//删除测试
Del_Pos(&list, 3);
Del_Val(&list, 6);
Show(&list);
printf("Length = %d\n", Get_Length(&list));
//销毁链表
Clear(&list);
Destroy(&list);
printf("Length = %d\n", Get_Length(&list));
return 0;
}
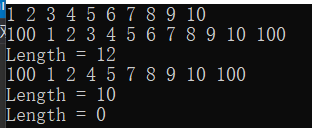
运行结果
总结
容易出错的点
- 正常来说单链表需要处理2根线 而双向链表需要处理4根线
- 但是头插函数比较特殊,需要防止出现空链表导致少处理一根线
- 按位置删除函数也比较特殊,有可能删除的是最后一个节点
- 头删函数比较特殊 , 有可能只有一个有效节点需要删除
两个常用循环
如果需要前驱 ,一般用于插入和删除操作等等
for(DNode* p = plist; p->next != nullptr; p = p->next);
如果不需要前驱 , 一般用于查找和打印
for(DNode* p = plist->next; p! = nullptr; p = p->next);
















 5869
5869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











