







文章目录
在面试过程中,有时候会被问到,在上亿个数据中,找出第一个重复的数据,或找出所有重复出现的数据。
1. 找出第一个重复的数据
这里可直接使用STL的hashset
#include <iostream>
#include <unordered_set>
#include <unordered_map>
#include <vector>
#include <stdlib.h>
#include <time.h>
using namespace std;
int main(void)
{
// vector中放入原始数据
vector<int> vec;
srand(time(NULL));
for (int i = 0; i < 1000; ++i)
{
vec.push_back(rand() % 1000);
}
// 找第一个重复出现的数字
unordered_set<int> st;
for (auto key : vec)
{
auto it = st.find(key);
if (it == st.end())
{
st.insert(key);
}
else
{
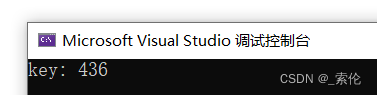
cout << "key: " << key << endl;
break;
}
}
return 0;
}
2. 找出所有重复的数据,并统计重复次数
这种问题,就可以用STL的unordered_map
#include <iostream>
#include <unordered_set>
#include <unordered_map>
#include <vector>
#include <stdlib.h>
#include <time.h>
using namespace std;
int main(void)
{
// vector中放入原始数据
vector<int> vec;
srand(time(NULL));
for (int i = 0; i < 1000; ++i)
{
vec.push_back(rand() % 1000);
}
// 找重复出现的数字
unordered_map<int, int> mp;
for (auto key : vec)
{
mp[key]++;
}
for (auto pair : mp)
{
if (pair.second > 1)
{
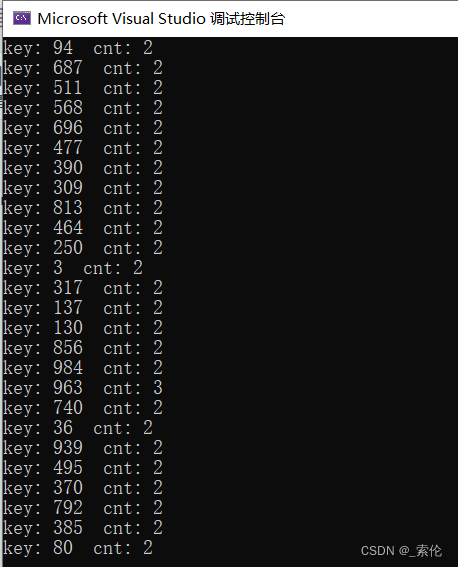
cout << "key: " << pair.first << " cnt: " << pair.second << endl;
}
}
return 0;
}
3. 找出第一个没有重复的字符
#include <iostream>
#include <unordered_set>
#include <unordered_map>
#include <vector>
#include <stdlib.h>
#include <time.h>
using namespace std;
int main(void)
{
// 字符串,找出第一个没有重复出现的字符
string src = "nnndddhsifbasuifbewufeabvaovbawrg";
unordered_map<int, int> m;
for (char ch : src)
{
m[ch]++;
}
for (char ch : src)
{
if (m[ch] == 1)
{
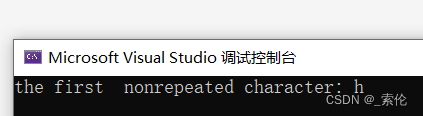
cout << "the first nonrepeated character: " << ch << endl;
return 0;
}
}
cout << "all character repeated!" << endl;
return 0;
}
4. 有两个文件a和b,分别放了大约一亿个IP地址(email/URL),每个地址4字节,找出两个文件重复的IP,限制内存100M
思路:分治 + 哈希表
一亿条数据,大概100M
100M * 4 * 2 = 800M
100M根本不够。
可以拆分成多个小文件,这里分成11个(素数),那每个文件平均1000W条数据,若一条数据4字节,那么用哈希表存储,把a1文件里的数据全部放入,最多只占80M大小,然后依次遍历b1内的数据,从而得到重复IP。

















 56
56











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











