






中文自动分词
◼ 词语边界歧义处理
◼ 如何识别未登录词
◼ 如何低廉地获取语言学知识
◼ 实时性应用中的效率问题
简单的模式匹配
正向最大匹配(Forward Maximum Matching method, FMM)
◼ 1.设自动分词词典中最长词条所含汉字个数为I;
◼ 2.取被处理材料当前字符串序数中的I个字作为匹配字段,查找分词词典。若词典中有这样的一个I字词,则匹配成功,匹配字段作为一个词被切分出来,转6;
◼ 3.如果词典中找不到这样的一个I字词,则匹配失败;
◼ 4.匹配字段去掉最后一个汉字,I--;
◼ 5.重复2-4,直至切分成功为止;
◼ 6.I重新赋初值,转2,直到切分出所有词为止。
分析
◼ “市场/中国/有/企业/才能/发展/”
◼ 对交叉歧义和组合歧义没有什么好的解决办法
◼ 错误切分率为1/169
◼ 往往不单独使用,而是与其它方法配合使用
逆向最大匹配分词(Backward Maximum Matching method, BMM)
◼ 分词过程与FMM方法相同,不过是从句子(或文章)末尾开始处理,每次匹配不成功时去掉的是前面的一个汉字
◼ “市场/中/国有/企业/才能/发展/
◼ 实验表明:逆向最大匹配法比正向最大匹配法更有效,错误切分率为1/245
双向匹配法(Bi-direction Matching method, BM法)
◼ 比较FMM法与BMM法的切分结果,从而决定正确的切分
◼ 可以识别出分词中的交叉歧义
基于规则的方法:最少分词算法
最少匹配算法(Fewest Words Matching,FWM) )
◼ 分段
◼ 逐段计算最短路径(Dijkstra算法)
◼ 得到若干分词结果
◼ 统计排歧
发展\中\国家
发展\中国\家
◼ 算法复杂性与FMM相当
基于统计的方法:统计语言模型分词、串频统计和词形匹配相结合的汉语自动分词、无词典分词
基于统计的词网格分词
◼ 第一步是候选词网格构造:利用词典匹配,列举输入句子所有可能的切分词语,并以词网格
形式保存
◼ 第二步计算词网格中的每一条路径的权值,权值通过计算图中每一个节点(每一个词)的一
元统计概率和节点之间的二元统计概率的相关信息而得到
◼ 根据图搜索算法在图中找到一条权值最大的路径,作为最后的分词结果
分析
◼ 可利用不同的统计语言模型计算最优路径
◼ 具有比较高的分词正确率
◼ 算法时间、空间复杂性较高
生词识别
一种基于N-gram信息的生词获取
◼ 基本思想:N元对→词频过滤→互信息过滤→校正→生词获取
◼ 词频
◼ 互信息(Mutual Information)
◼ 词频与互信息的关系
◼ 候选生词的校正
人名识别
◼ 规则方法:利用语言规则来进行人名识别。
优点:识别较准确;
缺点:很难列举所有规则,规则之间往往会顾此失彼,产生冲突,系统庞大、复杂,耗费资源多但效率却不高
◼ 统计方法:一种是仅从字、词本身来考虑,通过计算字、词作人名用的概率来实现,另一种结合基于统计的汉语词语边界划分来实现。
统计方法占用的资源少、速度快、效率高,但准确率较低。其合理性、科学性及所用统计源的可靠性、代表性、合理性难以保证。搜集合理的有代表性的统计源的工作本身也较难。
◼ 混合方法:取长补短
实验结果:8个测试样本,共22000多字,共有中文人名270个。系统共识别出中文人名330个,其中267个为真正人名。
召回率=文本中的中文人名辨识正确的比例=267/270*100% =98.89%
准 确 率 = 真 正 辨 识 正 确 的 人 名 的 比 例=267/330*100% =80.91%
准确率和召回率是互相制约的,可通过概率阈值的调整来调节二者的关系。
基于统计的中文语言建模
给定所有可能的句子 s (还可以是其他语言单位),统计语言模型就是一个概率分布



SLM的参数学习
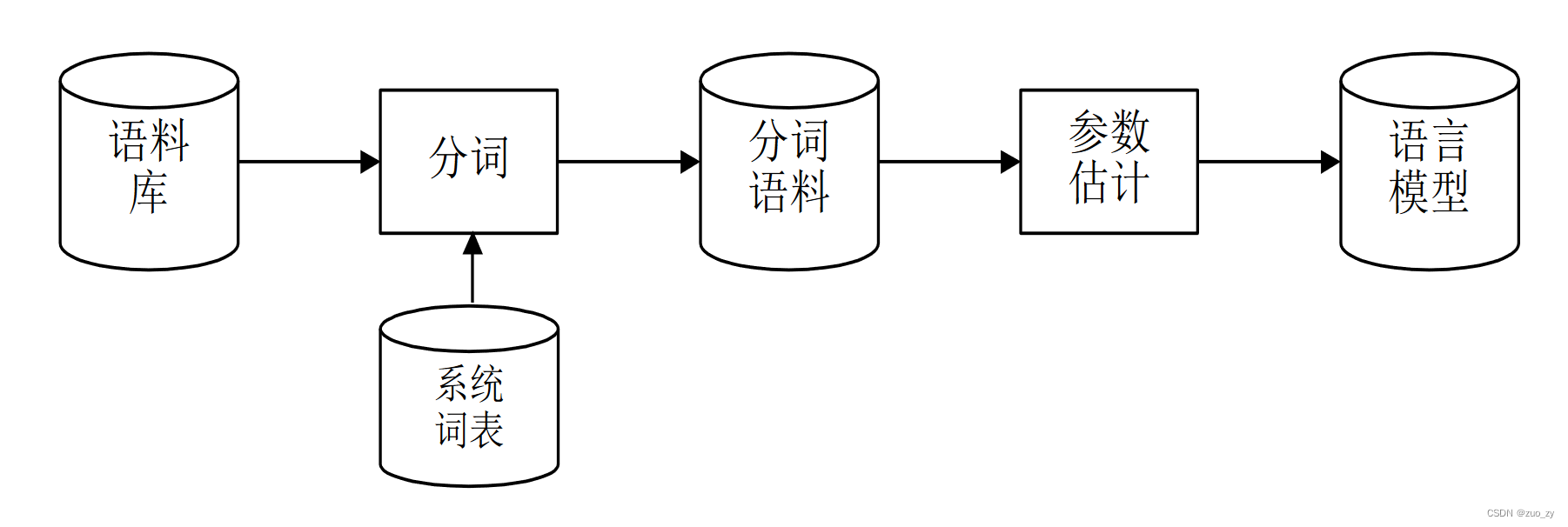
平滑:对根据极大似然估计原则得到的概率分布进一步调整,确保统计语言模型中的每个概率参数均不为零,同时使概率分布更加趋向合理、均匀
语言的熵

统计语言模型作用















 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









