






-
Deepseek现状介绍
-
背景介绍
deepSeek是一家中国人工智能公司,成立于2023年7月17日,总部位于浙江杭州。它由量化资管巨头幻方量化创立,专注于大语言模型(LLM)及相关AI技术的研发。

-
DeepSeek亮点
(1)DeepSeek是一款大语言模型(LLM),主打“极致性价比”。它能写代码、解数学题、做自然语言推理,性能比肩OpenAI的顶尖模型o1,但成本却低到离谱——训练费用仅557.6万美元,是GPT-4o的十分之一,API调用成本更是只有OpenAI的三十分之一。
(2)Deepseek有望改变AI生态,DeepSeek的成功有望改变现有AI的产业格局,一方面是中国在全球AI产业的竞争形态,另一方面是大模型开源与闭源的竞争形态。
1)对于训练而言,最引人注目的自然是FP8的使用。DeepSeek-V3是第一个(至少在开源社区内)成功使用FP8混合精度训练得到的大号MoE模型。
2)与OpenAI依赖人工干预的数据训练方式不同,DeepSeek R1采用了R1-Zero路线,直接将强化学习应用于基础模型,无需依赖监督微调(SFT)和已标注数据。
3)低成本模型有望引领AI产业“新路径”:开源+MOE。
4)开源VS闭源:开源重构AI生态,与闭源共同繁荣下游。
-
DeepSeekR1技术及使用
-
DeepSeekR1的技术关键
其在于创新的训练方法。与OpenAI依赖人工干预的数据训练方式不同,DeepSeekR1采用了R1-Zero路线,直接将强化学习应用于基础模型,无需依赖监督微调(SFT)和已标注数据。
R1的总体训练过程如下:
1)从base模型开始:使用量少、质量高的冷启动数据(colddata)来sftbase模型,使得base模型可以有个良好的初始化;使用RL提升模型的推理能力;在RL阶段接近收敛时,用这个时候的checkpoint生成高质量的数据,将它们与现有的sft数据混合,创建新的sft数据集;
2)再次从base模型开始:使用新创建的sft数据集做finetune;执行二阶段RL;得到最终的r1
低训练成本+高性能表现,使得DeepSeek-V3成为国产模型之星。
DeepSeek-V3性能表现令人惊叹:不仅全面超越了Llama3.1405B,还能与GPT-4o、Claude3.5Sonnet等顶尖闭源模型正面竞争。更令人瞩目的是,DeepSeek-V3的API价格仅为Claude3.5Sonnet的1/15,堪称“性价比之王”。DeepSeek-V3的预训练阶段在不到两个月内完成,并花费了2664KGPU小时。加上119KGPU小时的上下文长度扩展和5KGPU小时的后训练,DeepSeek-V3的完整训练成本仅为2.788MGPU小时。假设H800GPU的租赁价格为每GPU小时2美元,总训练成本仅为5.576M美元。
-
推理模型vs非推理大模型
推理模型:DeepSeek-R1,GPT-o3在逻辑推理、数学推理和实时问题解决方面表现突出。推理大模型:推理大模型是指能够在传统的大语言模型基础上,强化推理、逻辑分析和决策能力的模型。它们通常具备额外的技术,比如强化学习、神经符号推理、元学习等,来增强其推理和问题解决能力。
非推理大模型:适用于大多数任务,非推理大模型一般侧重于语言生成、上下文理解和自然语言处理,而不强调深度推理能力。此类模型通常通过对大量文本数据的训练,掌握语言规律并能够生成合适的内容,但缺乏像推理模型那样复杂的推理和决策能力。但专项任务需依赖提示语补偿能力•例如:GPT-3、GPT-4(OpenAI),BERT(Google),主要用于语言生成、语言理解、文本分类、翻译等任务。
 1.deepseek任务需求与提示语策略
1.deepseek任务需求与提示语策略
不同任务的提示词策略:
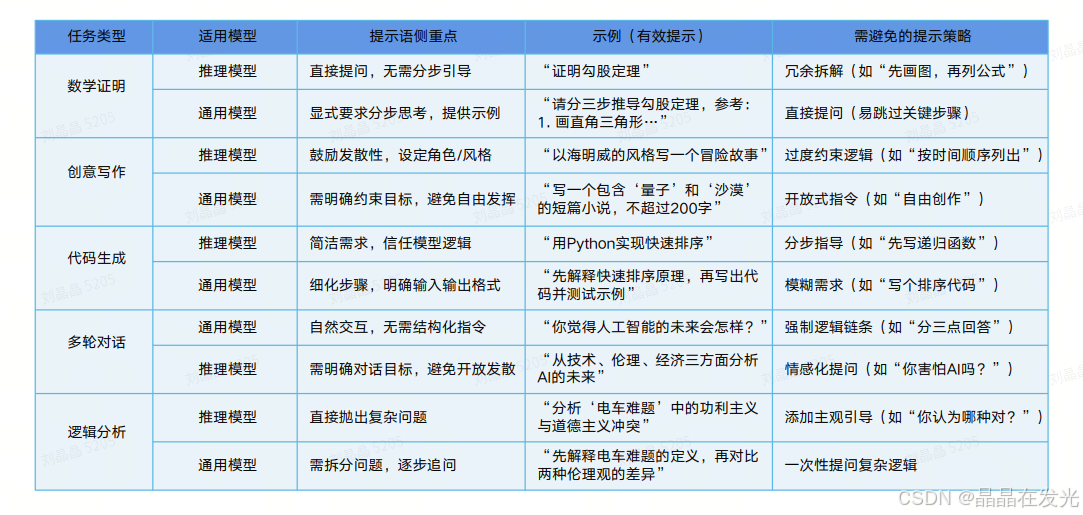
不同需求的提示词策略: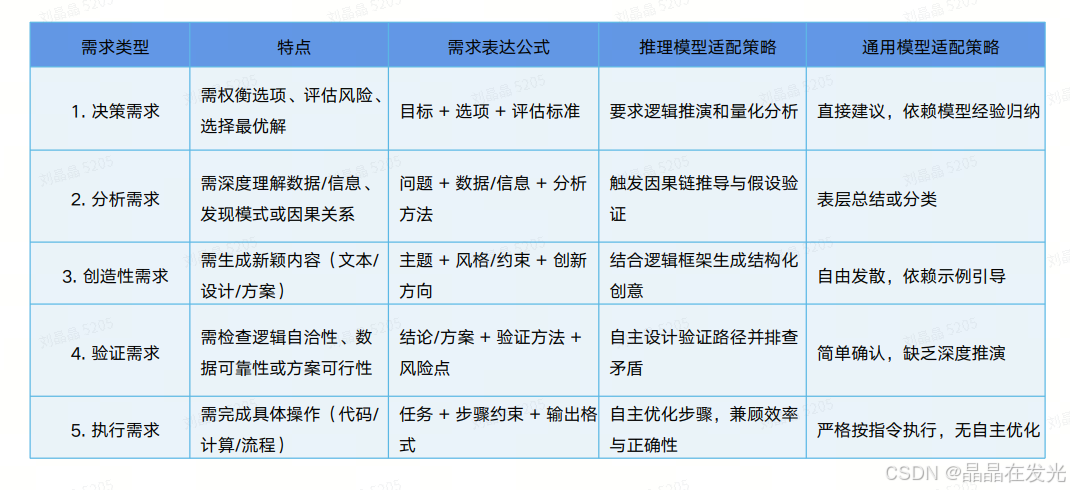
-
DeepSeek在手机测试领域的可能的应用场景
DeepSeek在手机测试领域的应用场景广泛,以下是一些主要方向:
-
数据分析和报告
-
测试报告:自动生成详细报告,包括测试结果、性能数据、问题列表等。
-
数据分析:通过大数据分析,识别常见问题和性能瓶颈。
-
AI驱动的测试优化
-
智能测试用例生成:利用AI生成更全面的测试用例。
-
异常检测:通过机器学习识别异常模式,预测潜在问题。
-
AI智能体(AI Agent)
指能自主感知环境、做出决策并执行行动的系统,具备自主性、交互性、反应性和适应性等基本特征,能在复杂多变的环境中独立完成任务,包括记忆、规划、工具、行动四个主要模块。
Salesforce首席执行官马克·贝尼奥夫更直言AI的未来发展不在于LLM,而在于开发AI智能体。利用deepseek搭建 AI智能体可以在更多的手机测试应用场景赋能提效。
-
自动化测试用例生成
场景:传统测试用例编写耗时且容易遗漏边缘情况。 AI智能体的应用:
-
自动生成测试用例:通过分析应用的功能和用户行为数据,AI智能体自动生成全面的测试用例,覆盖核心功能和边缘场景。
-
动态调整用例:根据测试结果和用户反馈,AI智能体动态优化测试用例,提高覆盖率。
示例:
-
对于一款社交应用,AI智能体可以自动生成测试用例,模拟用户发送消息、上传图片、切换网络环境等操作。
-
智能缺陷检测
场景:手动测试难以发现隐藏的缺陷,如UI渲染问题、性能瓶颈等。 AI智能体的应用:
-
视觉缺陷检测:通过图像识别技术,AI智能体自动检测UI渲染问题(如错位、重叠、颜色错误等)。
-
性能缺陷检测:通过监控资源使用情况,AI智能体识别内存泄漏、CPU过载等问题。
示例:
-
在测试一款电商应用时,AI智能体发现商品详情页在低端设备上渲染异常,并自动记录问题。
-
用户体验优化
场景:用户体验问题(如卡顿、响应慢)难以通过传统测试量化。 AI智能体的应用:
-
交互行为分析:通过模拟用户操作,AI智能体量化应用的响应时间、流畅度等指标。
-
用户行为预测:通过分析用户行为数据,AI智能体预测用户可能遇到的体验问题,并提前优化。
示例:
-
在测试一款视频播放应用时,AI智能体发现用户在切换清晰度时卡顿,并建议优化加载逻辑。
-
兼容性测试优化
场景:手机设备碎片化导致兼容性测试工作量巨大。 AI智能体的应用:
-
设备聚类分析:通过分析设备特征(如分辨率、CPU型号、操作系统版本),AI智能体将设备聚类,减少测试工作量。
-
智能设备选择:AI智能体根据历史测试数据,选择最具代表性的设备进行测试。
示例:
-
在测试一款游戏应用时,AI智能体选择10台最具代表性的设备进行测试,覆盖90%的用户设备。
-
异常行为预测
场景:应用在特定场景下可能出现异常行为(如崩溃、卡顿)。 AI智能体的应用:
-
异常模式识别:通过分析历史测试数据,AI智能体识别可能导致异常的代码模式或用户行为。
-
风险预警:在测试过程中,AI智能体实时预警可能出现的异常行为。
示例:
-
在测试一款金融应用时,AI智能体预测在低内存设备上可能出现崩溃,并提前提示开发团队优化。


















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









