






 本文探索从起诉书中提取诉讼要素,将其视为阅读理解任务,采用BERT模型训练。自行标注140起案件数据集,用伪造案件测试,对比Naive - QA和LegalQA模型。实验表明微调模型性能提升显著,更多训练数据可提升性能,Q2处理较难。未来将检测更多类型犯罪要素提取。
本文探索从起诉书中提取诉讼要素,将其视为阅读理解任务,采用BERT模型训练。自行标注140起案件数据集,用伪造案件测试,对比Naive - QA和LegalQA模型。实验表明微调模型性能提升显著,更多训练数据可提升性能,Q2处理较难。未来将检测更多类型犯罪要素提取。
标题:Extracting Crime Prosecution Elements based on Neural Machine Reading Comprehension Model
时间:2022年
期刊:2022 IEEE International Conference on Big Data (Big Data)
作者:Jui-Ching Tsou, Kai-Yu Hsieh, Chen-Hua Huang, Yu-An Shih, Han-Cheng Yu, Yao-Chung Fan
摘要:在本文中,我们探索了从起诉书中提取诉讼要素(关于诉讼要素的文本描述)。我们通过将其视为一项阅读理解任务来处理诉讼要素提取问题。具体来说,我们的想法是训练阅读理解模型,根据所提问题提取文本跨度,以表明犯罪要素的陈述。通过这样的重新表述,我们将神经机器阅读模型的效力使用到起诉要素提取任务中。实验评估表明了机器阅读理解的可行性。我们也将代码和数据开放在https://github.com/NCHU-NLPLab/Legal-Document-Question-Answering。
关键词:法律案件,NLP,机器阅读理解
- 引言:
阅读法律案件需要人类付出巨大的努力。随着深度学习技术的进步,一个自然的想法是利用深度学习技术帮助人们阅读法律案件。在本文中,我们探索了提取给定起诉书的犯罪起诉要素任务。具体来说,对于一个给定的起诉书,得到关于犯罪起诉的陈述/描述。以伪造证件罪为例,由三个构成伪造证件罪的要素。
- 第一,伪造的物体需要是一个证件。
- 第二,文档的确是被伪造的或被修改过的。
- 第三,伪造足够对社会或他人造成伤害。
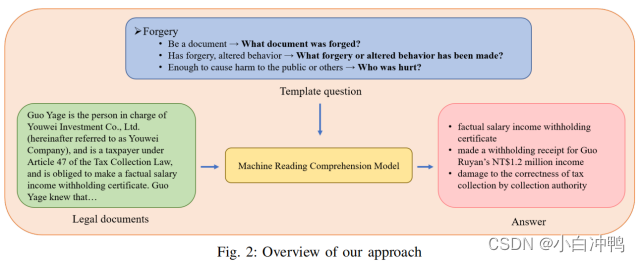
作为一个具体的例子,在图1中,我们展示了伪造证件罪的一个案例,其中,标注了颜色的文本对应构成伪造罪中的三个要素。

自动突出关于犯罪要素的犯罪陈述可以帮助人们阅读起诉书。因此,我们的目标是有一个神经模型能自动突出相应的元素。
在本研究中,我们提出了将其视为一项机器阅读理解任务来处理该问题(提取/突出关于犯罪要素的陈述)。具体来说,我们的想法是训练模型,根据标准问题提取文本跨度来表明犯罪要素陈述的开始和结束位置。具体来说,我们的模型将起诉书和犯罪要素标准问题(如,什么证件被伪造了?)的集合看作输入,并生成关于标准问题的文本跨度作为输出。通过这样的重新表述,我们的模型利用神经机器模型的效力来提取犯罪要素。
本文的贡献总结如下:
- 本研究探索了使用阅读理解模型提取给定法律起诉书的犯罪要素。通过实验评估,我们说明了使用阅读理解模型进行犯罪要素提取任务的有效性。
- 我们还发布了本研究实现的数据集、代码和模型。我们希望数据集和模型可以为未来的法律案件研究奠定基础。
- 相关工作
关于法律案件分析的研究可以被追溯到1962年Kort[7]提出了使用数学统计来预测法院决策。最近,随着深度学习技术的突破,基于神经网络架构的法律案件分析应用已经逐渐成形。近年来,在Transformer[14]框架被提出之后,自然语言处理已经取得了巨大的进步。基于深度学习的法律案件分析应用也被提出了。这些应用主要可以被分为一下类别:法律案件预训练语言模型,法律实体识别,法律案件分类,法律问题回答,法律摘要和法律案件检索。
- 法律案件预训练语言模型:Ilias[4]和Xiao[15]指出,当执行法律领域的NLP任务时,使用经过法律领域语料库训练的预训练语言模型可以是模型表现得更好。在[4]中,作者使用12GB的英文法律语料库构建预训练语言模型,[15]使用84GB的简化中文法律案件。这两个研究表明,法律领域的预训练模型为下游任务带来了性能提升。我们没有在本文中使用法律案件预训练模型。将法律预训练模型引入我们当前的架构中将是未来的研究工作。
- 法律问答:在[13]中,作者使用BM25和微调的BERT模型来回答法律领域的YES/NO问题。Kien[6]使用基于CNN的句子编码器和段落编码器通过内积检索相关的法律文档和相关的关键文章,并在越南文法律语料库和QA数据集上训练它们。Zhong[17]提出了一个法律领域的中文阅读理解数据集,但该数据集在本文中并没有用于训练阶段,因为我们的目标是提取起诉要素,而不是通用的模型问答系统。
- 法律实体识别:[1]的目标是从希腊法规中提取六类实体,即个人,组织,地缘政治实体,地理标志,立法参考和公共文件参考。想法是首次将Word2Vec用到在希腊法律语料库中预训练单词嵌入,然后使用LSTM训练命名体识别模型,并使用启发式规则将识别的实体链接到对应的希腊法律文档。
- 法律案件检索:在[11]中,作者的目标是检索相似的法律案件。基本的想法是使用BM25检索前k个候选法律案件,然后将文档级的案件分成段落级的段落,并使用BERT计算段落级案件和查询案件之间的交互图。最后,通过最大池化将交互图转换成代表序列,代表序列被输入到RNN,以产生预测结果,从而检索相似法律案件。
- 法律案件分类:[3]提出了一个判决预测数据集,它是从欧洲人权法院(ECHR)中的案件构建的。在本文中,作者在不同的神经模型上进行了性能评估,如HAN[16],LWAN[8],BERT和HIER-BERT[3]。本文目标主要分成三类任务。首先是二元违法,旨在训练模型判断给定案件是否违反了人权条款或者议定书。第二个任务是多标签违法,目标是预测案件违反的人权条款和/或议定书。第三个任务是案件重要性,预测案件的重要性,从1(关键案件)到4(不重要),得分表明案件对案件法律发展的贡献。
- 法律案件摘要:为了减轻法律从业人员的负担,研究[12]进行了法律案件的提取和摘要总结任务,以减少阅读法律案件的时间。在提取过程中,除了使用原始提取数据集,作者还是用了各种技术来将摘要数据集转化成用于训练的提取数据集。在摘要训练设置中,用到了两个方法。第一个是把法律案件分成多个块。在提取出独立的块之后,结果被进一步集中到了最终输出。第二个是在实验之前使用另外的法律案件微调Longformer模型[2](算力=16384个分词)。研究[5]总结了独立领域和法律领域现有的摘要技术,并讨论了它们在提取摘要设置和抽取摘要设置的法律数据集上应用之间的差异。相较于法律案件摘要,我们的目标是利用阅读理解模型提取犯罪要素。具体来说,我们的目标(自动突出起诉的犯罪要素)和摘要任务(减轻阅读法律案件的负担)有相同的动机,但我们的主要想法是使用机器阅读模型自动突出而不是总结文章。
- 方法
正如所提到的,我们的想法是将犯罪要素提取问题表述为阅读理解任务。主要的意图是利用阅读理解模型完全理解给定的起诉书,然后我们可以提出问题(就像我们提出一个阅读理解问题,例如,伪造文件的原因是什么?),要求模型预测一个跨度表明犯罪要素的开始和结束位置。具体来说,我们的目标是训练阅读理解模型,它将(1)起诉书[s1,...,sn]和(2)问题Q看作输入,然后预测起诉书中的跨度索引[i,j],表明文本跨度对应于犯罪要素的陈述。
BERT因其解决机器阅读理解(MRC)任务[9]的能力而著名。因此,我们采用BERT模型作为我们的基础构建块。我们使用BERT模型如下。首先,输入序列被排列成![]()
注意,si是单词分词[wi,j],其中,j=1,...,|si|.然后我们通过BERT模型得到x的最终的隐层表示![]() 。隐层表示被传递给两个独立的密集层然后使用softmax函数计算wi,j的
。隐层表示被传递给两个独立的密集层然后使用softmax函数计算wi,j的![]() 如下:
如下:
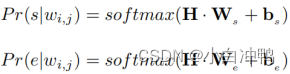
其中,![]() 随着序列的维度应用softmax函数。
随着序列的维度应用softmax函数。
根据可能性,具有最大联合概率的有效文本跨度被视为被问的跨度a=[sx,...,se]。所有参数被联合微调,以最大化正确跨度的对数概率。注意,对于法律案件,我们向机器阅读理解模型提出与定义的犯罪要素数量相同的问题。图2展示了我们模型输入(犯罪问题的三个要素)和输出(三个对应的跨度)的一个例子,以处理伪造案件。
4. 实验
4.1 数据集
据我们所致,没有可用于本文目标的现成数据集。因此,在本研究中,我们选择自己标记数据。我们首先从台湾法院数据网站搜索起诉书的判决,并提取犯罪事实部份进行人工标注。我们总共标注了140起案件。在实验数据集中,我们使用伪造文档的案件作为测试集。根据一下伪造犯罪的三个对应要素,人工检查并标记数据集中的每个实例:(1)它必须是一个文档,(2)犯罪者有伪造和修改行为,(3)该行为对公众或他人造成了伤害。在标记数据中,我们将其中的100条数据作为微调数据,40条数据作为测试数据。我们的数据集可以在Github1上查看。(1https://github.com/NCHU-NLP-Lab/Legal-Document-Question-Answering)
4.2 评估指标
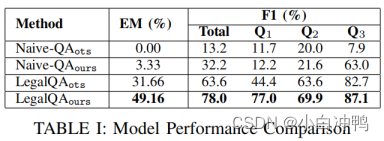
正如方法部分所描述的,我们的想法是利用神经模型提取/突出给定起诉书的关键犯罪要素。在性能评估中,我们使用伪造案件来测试。具体来说,对给定的伪造案件,我们提出三个问题(1)Q1:什么文档是伪造的?(2)Q2:进行了什么伪造或修改行为?(3)Q3:谁被伤害到了?我们计算每个模型返回的预测答案的F1和EM得分,并使用这两个指标最为评估性能的评估指标。
4.3 基线方法
我们比较了以下两个方法的理解性能。
(1)Naive-QA:我们使用从Huggingface得到并用DRCR数据集微调后的基于BERT的中文模型。我们用Naive-QA的两个实现来进行实验,一个直接下载自Huggingface hub2,另一个是由我们自己训练的3。(2 https://huggingface.co/nyust-eb210/braslab-bert-drcd-384
3 https://huggingface.co/NchuNLP/Chinese-Question-Answering)
为了便于讨论,我们将现成的Naive-QA称作Naive-QAots,我们自己训练的模型称作Naive-QAours。
(2)LegalQA:同样是基于BERT的中文模型,首先用DRCD微调,然后用我们的法律突出提取任务的训练数据微调。我们还是用两个该模型的实现进行了实验,一个称作LegalQAots(用法律突出训练数据对Naive-QAots进一步微调),另一个称作LegalQAours(用法律突出训练数据对Naive-QAours进一步微调)。
注意,我们使用BERTQA架构,设置输入大小为512,字符串大小为128,一个batch大小是12,学习率是3e-5。以下的实验结果都使用了这个默认设置。
4.4 结果
在表1中,我们列出来我们比较的四个模型的EM和F1得分。除了F1总分,我们还列出了伪造文档对应与三个要素的提取结果的单独的F1得分。关于实验结果,我们由如下发现。首先,通过比较Naive-QA和LegalQA,我们可以看出,微调模型带来了显著的性能提升。这个结果表明,基于目标领域的数据进行微调仍然是有必要的。而且,在Q1,Q2和Q3上,我们还发现,Q3具有最高的F1得分,而且对模型来说,Q2的处理相对较难。
4.5 参数学习
在该实验设置中,我们通过改变训练数据的数量来评估模型性能。从表2,我们可以看出,当训练数据的数量增加时,EM和F1得分逐渐提高。这一结果表明,更多的训练数据会导致更好的性能提升。另外,我们还发现从使用80%的训练数据到100%,性能的显著提升(在EM得分上从27.5到49,16)。而且,我们发现在使用80%的训练数据时Q1在性能提升上具有巨大飞跃。然而,Q2和Q3在性能上没有类似的跳跃变化。我们可以看到,Q2和Q3的性能随着训练数据的增加,F1得分也相应增加。
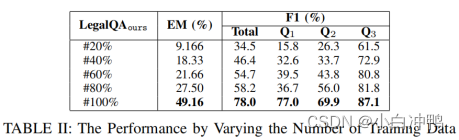
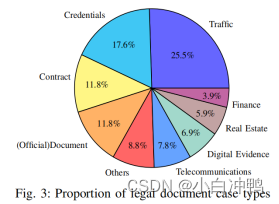
关于性能行为上的不同,我们怀疑Q1的目标是提取伪造文档,而伪造文档的类型是更加多样化的。因此,需要更多的训练数据。我们进一步计数了不同案件类型的数量,并在图3中展现了结果。我们可以看到,每个类别都有一定的数量。我们认为,随着训练数据的增加,模型将能够阅读越来越多种类的文档,所以Q1要素提取的作用就会提高。与Q1相比,Q2和Q3具有更简单的识别犯罪要素的规则。以Q3为例,它有固定的描述和句子来陈述对他人或社会造成伤害的要求,所以只要获得某个数量的训练数据,模型就足以进行学习。
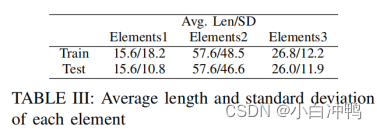
从以上实验中,我们可以看出,回答Q2的表现不如Q1和Q3好。我们也探索了Q2的答案长度对模型性能的影响。在表3中,我们展示了平均答案长度和对应的标准来源。与Q1和Q3的答案长度相比,Q2有明显更长的答案长度,这对机器阅读理解明显提出了挑战。
结论:在本文中,我们报告了我们使用神经机器阅读理解热舞解决犯罪要素描述提取任务的研究。使用伪造犯罪案件作为测试案件的性能评估证明了我们想法的可行性。未来,我们将进一步检测起诉书中各种类型犯罪要素的提取,如失信,诈骗等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









