







一、matplotlib
Matplotlib 是 Python 编程语言及其数值数学扩展包 NumPy 的可视化操作界面。它为利用通用的图形用户界面工具包,如 Tkinter, wxPython, Qt 或 GTK+ 向应用程序嵌入式绘图提供了应用程序接口(API)。
使用matplotlib进行简单的绘图练习:
1、使用plot实现单坐标图
import matplotlib.pyplot as plt
import random
#显示中文(黑体)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#准备数据
x=range(60)
y=[random.uniform(12,18)for i in x]
y1=[random.uniform(10,15) for i in x]
#准备刻度
x_tick=["11点{}分".format(i) for i in x]
y_tick=range(10,20)
#绘制画布(20:8,dpi=100)
plt.figure(figsize=(20,8),dpi=100)
#绘制折线图并设置风格、图例
#color=颜色参数:红r 绿g 蓝b 白w 青c 洋红m 黄y 黑k
#linestyle=风格参数 虚线-- 实线- 点划线-. 点虚线: 留空''
plt.plot(x,y,color='r',linestyle='--',label='郑州')
plt.plot(x,y1,color='k',linestyle='-.',label='许昌')
#图例位置参数:'best' 'upper right' 'upper left' 'lower right' 'lower left' 'center' 'center right' 'center left' 'right'
plt.legend(loc='best')
#设置刻度
plt.xticks(x[::5],x_tick[::5])
plt.yticks(y_tick[::1])
#设置网格线(虚线,透明度0.5)
plt.grid(True,linestyle="--",alpha=0.5)
#添加描述信息
plt.xlabel("时间")
plt.ylabel("温度")
plt.title("郑州/许昌市短时间温度变化",fontsize=18)
#保存图片到指定位置(必须在显示之前,plt.show()会释放内容)
plt.savefig("E:/温度.png")
#显示
plt.show()
2、使用subplots实现多坐标图
import matplotlib.pyplot as plt
import random
#显示中文(黑体)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#准备数据
x=range(60)
y=[random.uniform(12,18)for i in x]
y1=[random.uniform(10,15) for i in x]
#准备刻度
x_tick=["11点{}分".format(i) for i in x]
y_tick=range(10,20)
#绘制画布:一行两列返回图对象与相应数量的坐标系对象
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(20,8),dpi=100)
#绘制折线图并设置风格、图例
axes[0].plot(x,y,color='r',linestyle='--',label='郑州')
axes[1].plot(x,y1,color='k',linestyle='-.',label='许昌')
#图例位置
axes[0].legend(loc='best')
axes[1].legend(loc='best')
#设置刻度,由于字体过大,使用fontsize控制字体大小(多图分开设置,且字符串单独设置)
axes[0].set_xticks(x[::5])
axes[0].set_yticks(y_tick[::1])
axes[0].set_xticklabels(x_tick[::5],fontsize=7)
axes[1].set_xticks(x[::5])
axes[1].set_yticks(y_tick[::1])
axes[1].set_xticklabels(x_tick[::5],fontsize=7)
#设置网格线(多图分开设置)
axes[0].grid(True,linestyle="--",alpha=0.5)
axes[1].grid(True,linestyle="--",alpha=0.5)
#添加描述信息
axes[0].set_xlabel("时间")
axes[0].set_ylabel("温度")
axes[0].set_title("郑州市短时间温度变化",fontsize=18)
axes[1].set_xlabel("时间")
axes[1].set_ylabel("温度")
axes[1].set_title("许昌市短时间温度变化",fontsize=18)
#保存图片:不变
plt.savefig("E:/温度.png")
#显示
plt.show()
3、画出简单的sin函数
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(20,8),dpi=100)
x=np.linspace(-10,10,2000)
y=np.sin(x)
plt.plot(x,y,label="sin")
plt.legend(loc='best')
plt.xlabel("x")
plt.ylabel("sin")
plt.grid(True,linestyle='--',alpha=0.5)
plt.show()
4、其他常用图
(1)散点图:
plt.matplotlib.pyplot.scatter(x, y, s=20, c='b', marker='o',
cmap=None, norm=None, vmin=None, vmax=None,
alpha=None, linewidths=None, verts=None, hold=None, **kwargs)
c:散点颜色
s:散点大小
norm:数据亮度
alpha:透明度
linewidths:点的长度
(2)柱状图:
bar(x, height, width=0.8, bottom=None, ***, align='center', data=None, **kwargs)
x 表示x坐标,数据类型为int或float类型,
height 表示柱状图的高度,也就是y坐标值,数据类型为int或float类型,
width 表示柱状图的宽度,取值在0~1之间,默认为0.8
bottom 柱状图的起始位置,也就是y轴的起始坐标,
align 柱状图的中心位置,"center","lege"边缘
color 柱状图颜色
edgecolor 边框颜色
linewidth 边框宽度
tick_label 下标标签
log 柱状图y周使用科学计算方法,bool类型
orientation 柱状图是竖直还是水平,竖直:"vertical",水平条:"horizontal"
示例:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
name=['张三','李四','王五','赵六']
x=range(len(name))
y=[45,50,56,20]
plt.figure(figsize=(20,8),dpi=100)
plt.bar(x,y,color=['r','k','g','b'],width=0.5)
plt.grid(True,alpha=0.5,linestyle="--")
plt.xticks(x,name)
plt.show()
(3)直方图:
hist(
x, bins=None, range=None, density=False, weights=None,
cumulative=False, bottom=None, histtype='bar', align='mid',
orientation='vertical', rwidth=None, log=False, color=None,
label=None, stacked=False, *, data=None, **kwargs)
x:每个bin的数据
bins:bin的个数(总共有几个条状图)
normed:密度,每个条状图占比例
color:条状图图颜色
facecolor:直方图颜色
edgecolor:直方图边框颜色
alpha:透明度
histtype:直方图类型,“bar”、“barstacked”、“step”、“stepfilled”
(4)饼图
plt.pie(
x, explode=None, labels=None, colors=None, autopct=None,
pctdistance=0.6, shadow=False, labeldistance=1.1,
startangle=0, radius=1, counterclock=True, wedgeprops=None,
textprops=None, center=(0, 0), frame=False,
rotatelabels=False, *, normalize=None, data=None)
x:指定绘图的数据;
explode:指定饼图某些部分的突出显示。
labels:为饼图添加标签说明。
colors:指定饼图的填充色。
autopct:自动添加百分比显示,可以采用格式化的方法显示;
pctdistance:设置百分比标签与圆心的距离;
shadow:是否添加饼图的阴影效果;
labeldistance:设置各扇形标签(图例)与圆心的距离;
startangle:设置饼图的初始摆放角度;
radius:设置饼图的半径大小;
counterclock:是否让饼图按逆时针顺序呈现;
wedgeprops:设置饼图内外边界的属性,如边界线的粗细、颜色等;
textprops:设置饼图中文本的属性,如字体大小、颜色等;
center:指定饼图的中心点位置,默认为原点
frame:是否要显示饼图背后的图框,如果设置为True的话,需要同时控制图框x轴、y轴的范围和饼图的中心位置;
二、numpy
1、NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,ndarray直接储存数据,且支持并行运算,比使用列表效率更高,此外它也针对数组运算提供大量的数学函数库。
具体可参考教程https://www.runoob.com/numpy/numpy-tutorial.html
2、NumPy 通常与 SciPy(Scientific Python)和 Matplotlib(绘图库)一起使用, 有助于我们通过 Python 学习数据科学或者机器学习。
ps:SciPy 是一个开源的 Python 算法库和数学工具包,包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。
1、创建数组及常用数组属性
import numpy as np`
#创建数组,可用dtype指定类型
a=np.array([[[1,2,3],[4,5,6]],[[1,2,3],[2,3,6]]],dtype=np.int64)
#数组索引(与正常相同):
#print(a[0,0,0:2])
#维度数组
a.shape
#元素个数
a.size
#数组维数
a.ndim
#单元素字节大小
a.itemsize
#元素类型
a.dtype
#生成0、1数组(可使用dtype指定类型)
b=np.ones([4,8])
c=np.zeros_like(b)
d=np.zeros([6,5])
e=np.ones_like(d)
#拷贝数组(array深拷贝,asarray浅拷贝)
a1=np.array(a)
a2=np.asarray(a)
#创建等差数组linspace(start,stop,num,endpoint=True)
f=np.linspace(0,100,10,endpoint=False,dtype=np.int64)
# 创建等差数组arange(start,stop,step=1)(不包含stop)
g=np.arange(0,100,10)
#创建等比数列(10^x)logspace(start,stop,size)
h=np.logspace(0,4,5)
#创建正态分布数组:random.normal(local均值,scale标准差,size数量(可为维度数组))
i=np.random.normal(0,1,[4,5,6,7])
j=np.random.normal(0,1,100000)
#均匀分布1 random.uniform(low,high,size)
#左闭右开
K=np.random.uniform(-1,1,1000)
#均匀分布2 只取整数random.randint(low,high,size)
l=np.random.randint(0,100,1000)
#数组修改形状1 reshape(shape,order)返回一个符合新shape的数组,原数组不变,行列不互换(-1表示待计算)
#将数据打散后重新排列,order=“C”按行顺序打散,“F”按列顺序,“A”按内存中的顺序
aa=a.reshape([3,2,-1],order="C")
#数组修改形状2 resize(shape)原数组改变,行列不互换
aa.resize([2,2,3])
#转置T()行列互换
aa.T
#类型转换astype(type)原数组不变,返回修改后的数组
aaa=aa.astype(np.int32)
#转换为bytes(原数组不变)
aaa=aa.tobytes()
#数组去重:unique原数组不变,返回修改后的数组
aaa=np.unique(aa)
2、数组之间简单计算及常用求值函数
import numpy as np
#逻辑运算:直接使用><判断,且可进行赋值
a=np.random.randint(0,100,(5,6))
a[a>60] = 1
#通用判断:all()是否全部符合,any是否有元素符合
np.any(a[:1,1]<2)
np.any(a>100)
#三元运算where(条件,1,0) 若满足条件则为1,不满足为0
#可以结合logical_or(),logical_and()
np.where(a[0:1,:]<60,0,1)
np.logical_or(a>100,a<60)
np.logical_and(a>=60,a<=100)
#统计学运算
#最大值1、0表示按照行、列输出,若不加参数则为全元素
a.max(1)
#最大值下标
a.argmax()
#最小值
a.min(0)
#最小值下标
a.argmin()
#中位数
np.median(a,axis=1)
#平均数
np.mean(a,axis=1,dtype=np.float32)
#标准差
np.std(a,axis=1,dtype=np.float32)
#方差
np.var(a,axis=1,dtype=np.float32)
#数组与数字运算,每个元素单独运算(注意与列表运算的差别)
b=np.array([1,2,3,4,5,6])
#b*3=[3,6,9],[1,2,3]*3=[1,2,3,1,2,3,1,2,3]
#b+3=[4,5,6]
#数组运算要求:shape相等或满足广播机制
#数组与数组运算基本满足线性代数中矩阵运算
#矩阵乘法:matmul仅支持矩阵之间,dot还支持矩阵与标量
'''a*b不是矩阵乘法,广播后按照矩阵加法的规则,各元素间分别相乘'''
np.matmul(a,b)
np.dot(a,b)
广播机制:当两个数组的形状并不相同的时候,我们可以通过扩展数组的方法来实现相加、相减、相乘等操作,这种机制叫做广播(broadcasting)。如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符,或其中的一方的长度为1,则认为它们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。
eg:
[[1,1,1],[1,1,1],[1,1,1]] + [2,2,2] = [[1,1,1],[1,1,1],[1,1,1]] + [[2,2,2],[2,2,2],[2,2,2]]'''
三、pandas
pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算),常与numpy和matplotlib一同使用。用于数据挖掘和数据分析,同时也提供数据清洗功能。
导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
1、Series基本使用(一维)
(1)创建
Series(data,index)data可接收ndarry,可传入字典,index默认0~N
a=pd.Series(np.random.randint(4,9,5),[1,2,3,4,5])
a=pd.Series([1,1,1,1],(1,2,3,4))
a=pd.Series({"a":1,"b":2})
(2)series属性
#数据
a.values
#索引
a.index
#下标取值
a[1]
2、DataFrame基本使用(二维)
(1)创建
DataFrame(data,index行索引,columns列索引)
index1=['科目'+str(i) for i in range(1,3)]
columns1=['学生'+chr(ord('A')+i) for i in range(0,3)]
b=pd.DataFrame(np.random.randint(0,8,(2,3)),index=index1,columns=columns1)
(2)DataFrame属性
#数据
b.values
#行目录
b.index
#列目录
b.columns
#转置
b.T
#维度数组:eg:两行三列(2,3)
b.shape
#head()/tail()默认为前/后五行数据,传参数则为前/后n行数据
b.tail(2)
b.head(2)
#修改索引值必须全部修改,不能只修改某一个
b.index=['科目_'+str(i+1) for i in range(b.shape[0])]
#reset_index(level,drop=True)重置索引,level:索引等级(多索引时)True:删除索引,False:索引列变为普通列 ps:返回修改后对象,原对象不变
b.reset_index(0,drop=False)
#setindex(keys,drop=True)以某列值为索引,keys:列名。True:删除列 ps:返回修改后对象,原对象不变
b.set_index('学生A',drop=False)
3、MultiIndex基本使用(三维,多级索引)
(1)创建
#当创建多级索引DataFrame/Index时,index对象即为MultiIndex()
c=pd.DataFrame(np.random.randint(0,8,(4,5)),index=[['a','b','a','b'],['A','B','C','D']],columns=[[1,2,3,2,1],[2,3,4,5,2]])
#直接创建:levels:索引中会出现的所有值.codes:索引中的具体值(levels中的下标),name:索引名称
d=pd.MultiIndex(levels=[[1,2,4],[4,5,6,7]],
codes=[[0,1,2,2],[0,1,2,3]],
names=['name','time'])
#使用from_arrays或from_tuples创建,直接传入索引值
d=pd.MultiIndex.from_arrays([['A','B','C','D'],['a','b','c','d']],names=["name",'num'])
(2)简单使用
#使用:为其他数据类型创建多级索引
e=pd.DataFrame(np.random.randn(4,5),index=d,columns=["dir",'khjkj','kj','fh','hul'])
#简单数据操作
#索引先列后行,不支持下标,多级目录分级,可使用loc(先行后列)与iloc(下标拿取),可打点访问
#直接使用索引拿取时列表嵌套为目录嵌套
e.dir.A
e['dir']['A','a']
e.iloc[:2,:2]
e.loc['A':,:]
#老版ix可以下标与名称组合索引
#赋值(下标直接赋值)
index2=[str(i)+"年" for i in range(2002,2008)]
columns2=["同学"+chr(ord('A')+i) for i in range(6)]
f=pd.DataFrame(np.random.normal(0,1,(6,6)),index=index2 ,columns=columns2)
f["同学A"]=0
#排序 by:排序依据,ascending:True升序,False降序,默认为True,不改变原对象
#依据索引排序
f.sort_index(ascending=True)
#依据值排序
f.sort_values(by=["同学A","同学B"],ascending=True)
#简单运算
#直接通过索引+-*/,也可以通过add、sub加减
f["同学A"]*=f["同学A"]+2
f["同学A"]=f["同学A"].add(10)
#逻辑运算:结果作为参数传给原对象可取出满足的值
f.同学A>0
f[f.同学A>0]
f[(f['同学A']>0) & (f['同学B']<0)]
#query函数:直接传入判断,直接取出满足值
f.query('同学A>0 & 同学B<0')
#isin(values):判断是否在values区间内
f['同学B'].isin([0,1])
(3)统计运算
#axi=0,默认按列,若按行,axis=1
# describe:给出count、mean、std、min、max、四分位数据
print(f)
f.describe()
#求和
f.sum()
#中位数
f.median()
#平均数
f.mean()
#众数
f.mode()
#最大/小值
f.max()
f.min()
#绝对值
f.abs()
#乘积
f.prod()
#标准差
f.std()
#方差
f.var()
#最大/小值索引
f.idxmax()
f.idxmin()
#累计求和/求积/最大值/最小值
f.cumsum()
f.cumprod()
f.cummax()
f.cummin()
#使用 matplotlib 实现简单折线图
#f.cumsum().plot()
#plt.show()
(4)自定义运算
传入匿名函数可设置axis(默认为0,按列,1按行)
f[["同学A","同学B"]].apply(lambda x:x.max()-x.min(),axis=1)
ps:pandas实现简单画图:
pandas对matplotlib的封装,具体使用相似
Dataframe.plot(kind=‘line’)kind=bar条形图、barh横条形图、line折线图、hist直方图、scatter散点图、pie饼图
Series.plot(kind)
(5)文件操作(以csv、HDF5为例)
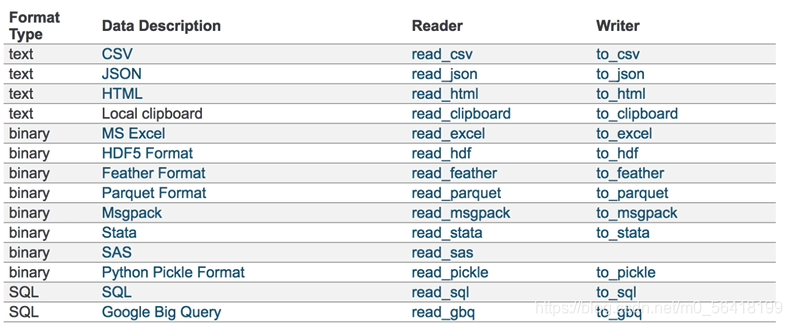
CSV
读:
read_csv(
filepath_or_buffer: 文件路径
usecols:查看列
)
写:若文件不存在,则新建
to_csv(
path_or_buf: 路径,
sep: str = “,”:分隔符,
columns: Sequence[Hashable] | None = None:选择需要的列,
header: bool_t | list[str] = True:是否写入列索引名,
index: bool_t = True:是否写进行索引,
mode: str = “w”:文件操作符,‘w’重写,‘a’追加,
)
HDF5:
读写时都要多加一个参数key,且需要提前安装tables包
4、高级处理
(1)缺失值处理
import pandas as pd
import numpy as np
index2 = [str(i) + "年" for i in range(2002, 2008)]
columns2 = ["同学" + chr(ord('A') + i) for i in range(6)]
a = pd.DataFrame(np.random.normal(0, 1, (6, 6)), index=index2, columns=columns2)
a["同学A"] = 0
# 缺失值处理
# isnull缺失值为True,非缺失值为False,notnull相反(可用np.all判断是否存在)
np.all(a.isnull())
a.isnull()
a.notnull()
# dropna(axis=’rows‘)删除缺失值axis=rows:按行删除 不改变原对象,传回修改后的对象
a.dropna(axis='rows')
# fillna(value,inplace=True)value:替换的值,inplace:是否修改原对象
# 可只替换部分
a.fillna(50.41564, inplace=True)
a["同学A"].fillna(a["同学A"].mean(), inplace=True)
# 缺失值存在默认值(不是NAN)replace(to_replace:待处理值,value:替换值),不修改原对象
# 先替换为np.nan,再删除或修改
a = a.replace(to_replace=0, value=np.nan)
(2)数据离散化
离散化就是,把无限空间中有限的个体映射到有限的空间中去,以此提高算法的时空效率。
详解:大佬文章
#自动分组qcut(data:数据,q:组数),常与value_counts()共用,查看每组数量
#分组依据:分为数量相似的各组
qcuts=pd.qcut(a['同学B'],5)
qcuts.value_counts()
#自定义分组区间cut(data,bins:分组区间)
cuts=pd.cut(a['同学B'],[-1,-0.5,0,0.5,1])
#分组后实现one hot编码(哑变量矩阵) pd.get_dummies(data:数据,可接受array_like、series、dataframe,prefix:分组名)
print(pd.get_dummies(data=cuts,prefix='a'))
(3)数据合并
merge函数详解:


创建两个数据框
dataDf1=pd.DataFrame({'lkey':['foo','bar','baz','foo'],
'value':[1,2,3,4]})
dataDf2=pd.DataFrame({'rkey':['foo','bar','qux','bar'],
'value':[5,6,7,8]})
print(dataDf1)
print(dataDf2)
>>>
lkey value
foo 1
bar 2
baz 3
foo 4
rkey value
foo 5
bar 6
qux 7
bar 8
内连接(Inner)
dataLfDf=dataDf1.merge(dataDf2, left_on='lkey',right_on='rkey')
>>>
lkey value_x rkey value_y
foo 1 foo 5
foo 4 foo 5
bar 2 bar 6
bar 2 bar 8
右链接(Right)
dataDf1.merge(dataDf2, left_on='lkey', right_on='rkey',how='right')
>>>
lkey value_x rkey value_y
foo 1.0 foo 5
foo 4.0 foo 5
bar 2.0 bar 6
bar 2.0 bar 8
NaN NaN qux 7
全链接(Outer)
dataDf1.merge(dataDf2, left_on='lkey', right_on='rkey', how='outer')
>>>
lkey value_x rkey value_y
foo 1.0 foo 5.0
foo 4.0 foo 5.0
bar 2.0 bar 6.0
bar 2.0 bar 8.0
baz 3.0 NaN NaN
NaN NaN qux 7.0
(4)交叉表与透视表
透视表(pivotTab)
透视表是将原有的DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数(默认情况下mean函数)。
index : 透视表的行索引,必要参数,如果我们想要设置多层次索引,使用列表[ ]
values : 对目标数据进行筛选,默认是全部数据,我们可通过values参数设置我们想要展示的数据列
columns :透视表的列索引,非必要参数,同index使用方式一样
aggfunc :对数据聚合时进行的函数操作,默认是求平均值,也可以sum、count等
margins :额外列,在最边上,默认是对行列求和
fill_value : 对于空值进行填充
dropna : 默认开启去重
df = pd.DataFrame({'类别':['水果','水果','水果','蔬菜','蔬菜','肉类','肉类'],
'产地':['美国','中国','中国','中国','新西兰','新西兰','美国'],
'水果':['苹果','梨','草莓','番茄','黄瓜','羊肉','牛肉'],
'数量':[5,5,9,3,2,10,8],
'价格':[5,5,10,3,3,13,20]})
print(df)
print(df.pivot_table(index=['产地','类别']))
print(df.pivot_table(columns=['产地','类别']))
#对“价格”应用'max',并提供分项统计,缺失值填充0
print(df.pivot_table('价格',index='产地',columns='类别',aggfunc='max',margins=True,fill_value=0))
输出:
类别 产地 水果 数量 价格
0 水果 美国 苹果 5 5
1 水果 中国 梨 5 5
2 水果 中国 草莓 9 10
3 蔬菜 中国 番茄 3 3
4 蔬菜 新西兰 黄瓜 2 3
5 肉类 新西兰 羊肉 10 13
6 肉类 美国 牛肉 8 20
价格 数量
产地 类别
中国 水果 7.5 7
蔬菜 3.0 3
新西兰 肉类 13.0 10
蔬菜 3.0 2
美国 水果 5.0 5
肉类 20.0 8
产地 中国 新西兰 美国
类别 水果 蔬菜 肉类 蔬菜 水果 肉类
价格 7.5 3.0 13.0 3.0 5.0 20.0
数量 7.0 3.0 10.0 2.0 5.0 8.0
类别 水果 肉类 蔬菜 All
产地
中国 10 0 3 10
新西兰 0 13 3 13
美国 5 20 0 20
All 10 20 3 20
交叉表
交叉表是用于统计分组频率的特殊透视表。(默认的聚合函数是统计行列组合出现的次数)。如果指定了聚合函数则按聚合函数来统计,但是要指定values的值,指明需要聚合的数据。
index:指定了要分组的列,最终作为行。
columns:指定了要分组的列,最终作为列。
values:指定了要聚合的值(由行列共同影响),需要指定aggfunc参数。
rownames:指定了行名称。
colnames:指定了列名称。
aggfunc:指定聚合函数。必须指定values的值。
margins:布尔值,是否分类统计。默认False。
margins_name:分类统计的名称,默认是“All”。
dropna:是否包含全部是NaN的列。默认是True。
print(pd.crosstab(df['类别'],df['产地'],margins=True)) # 按类别分组,统计各个分组中产地的频数
输出:
产地 中国 新西兰 美国 All
类别
水果 2 0 1 3
肉类 0 1 1 2
蔬菜 1 1 0 2
All 3 2 2 7
(5)分组与聚合
大佬关于分组聚合详细讲解
分组:
数据的分组核心思想是:拆分-组织-合并
import pandas as pd
df=pd.DataFrame({'name':['a','b','c','d','e'],'age':[10,15,20,15,20],'sex':[True,True,False,True,False]})
df
>>> name age sex
0 a 10 True
1 b 15 True
2 c 20 False
3 d 15 True
4 e 20 False
对整个DataFrame对象分组
df_1=df.groupby(df['sex'])
list(df_1)
>>> [(False, name age sex
2 c 20 False
4 e 23 False),
(True, name age sex
0 a 10 True
1 b 15 True
3 d 17 True)]
依据某个columns对另一个columns数据分组
df_1=df['age'].groupby(df['sex'])
list(df_1)
>>> [(False,
2 20
4 23
Name: age, dtype: int64),
(True, 0 10
1 15
3 17
Name: age, dtype: int64)]
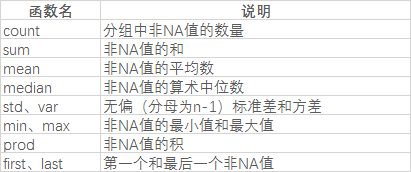
聚合:














 2270
2270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









