






大模型部署背景

- 计算量巨大:大模型仅就推理而言,其前向传播计算量就已十分庞大,对算力要求高,成本十分高昂,处于较难承受的范围
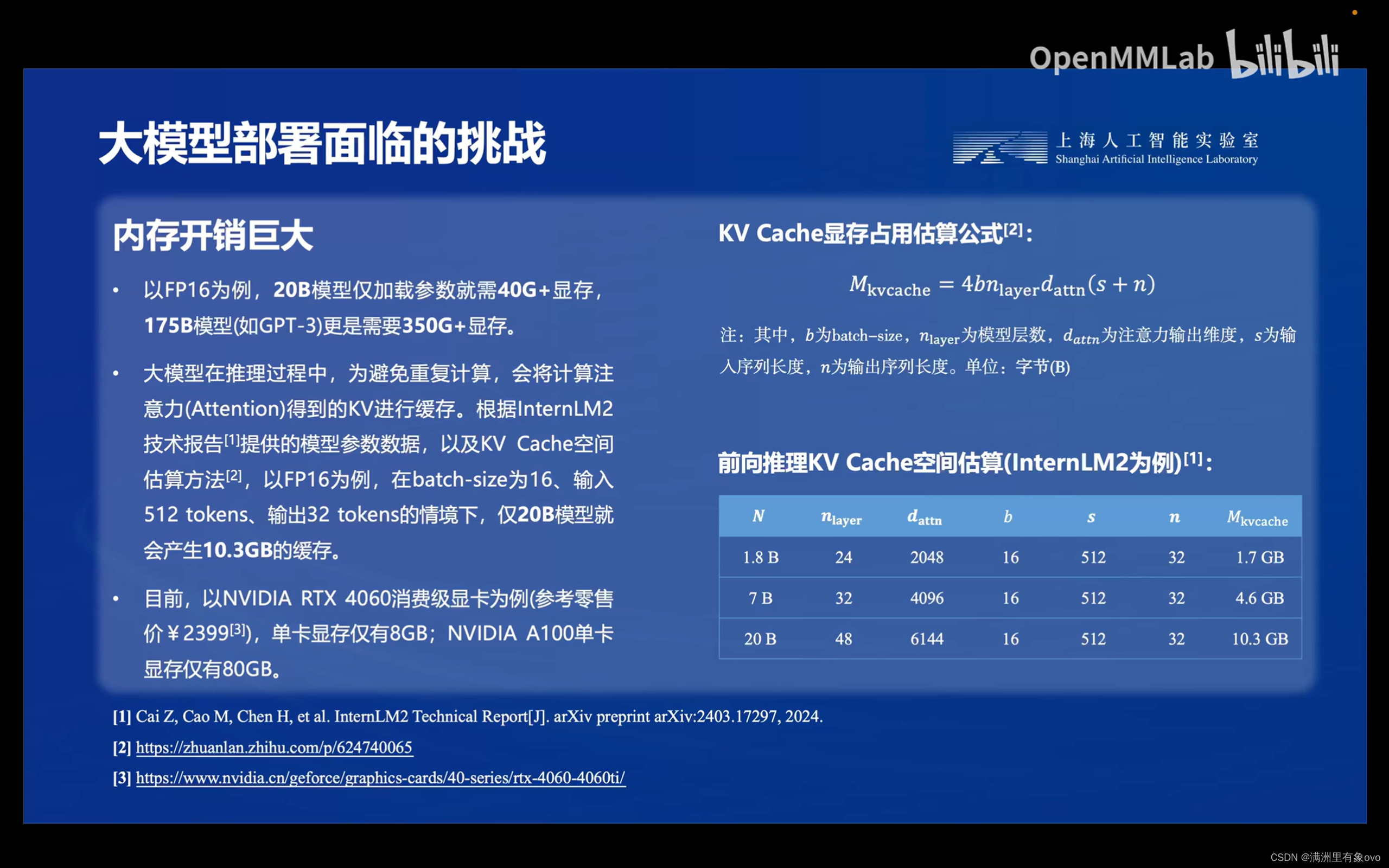
- 内存开销巨大:大模型在推理时会产生很多重复计算,为了避免重复计算造成的内存开销,会将注意力机制里的KV进行缓存,称为KV Cache。大模型在推理时除计算量巨大外,所造成的内存开销也十分巨大

- 访存瓶颈与动态请求:由于硬件架构的不同设计,显卡计算速度远大于显存带宽,大模型在推理时,大部分时间都花在了访问数据上,存在访存瓶颈;并且一般来说,用户对大模型的请求量、请求时间等也是不确定的
大模型部署方法

模型剪枝
模型剪枝即为移除大模型里一些冗余的参数,以达到高效计算、推理的目的
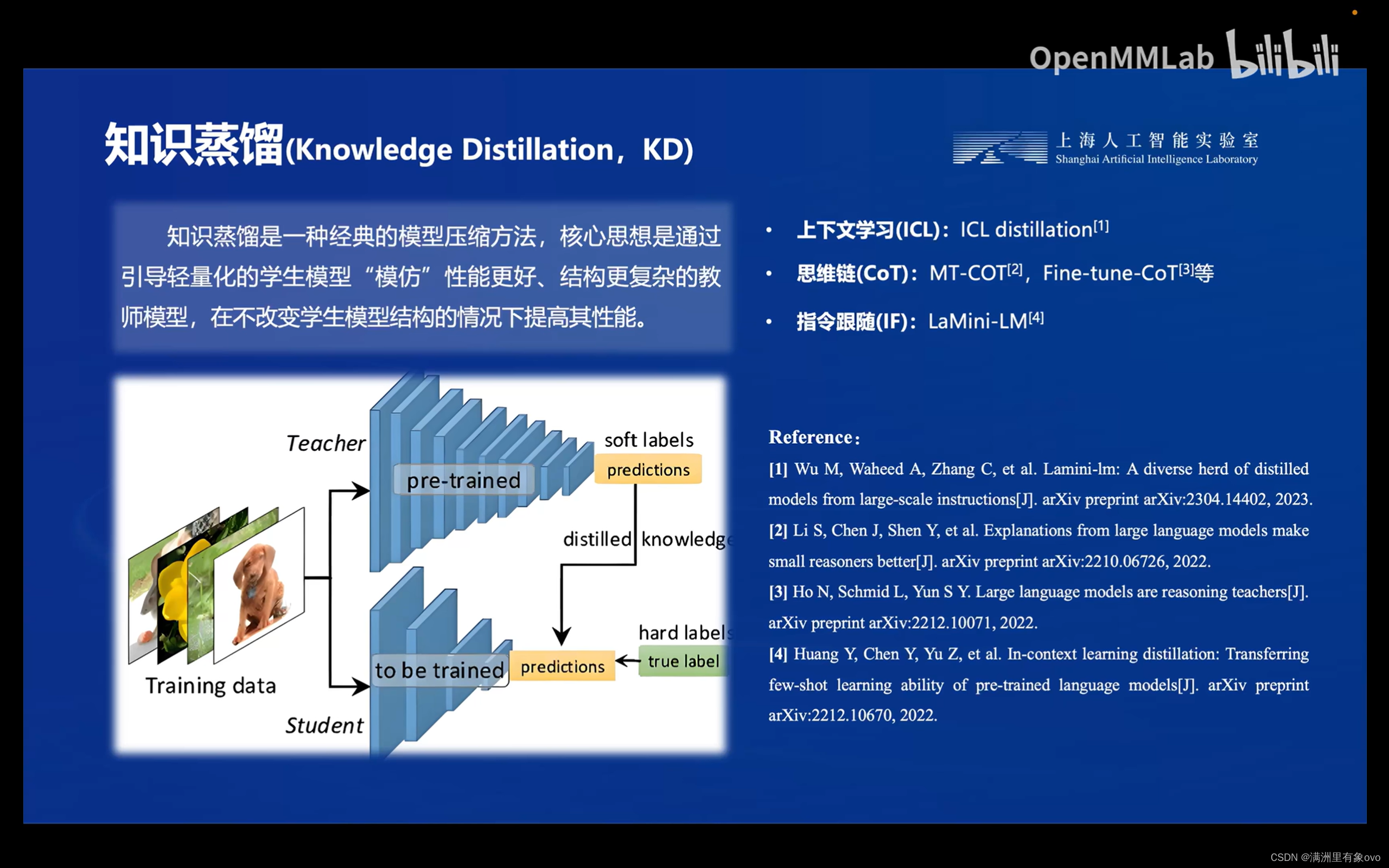
知识蒸馏
知识蒸馏即是通过具有庞大参数量的教师模型指导轻量化的学生模型在参数量明显下降的情况下,也能达到甚至超过教师模型的性能
 量化
量化
量化就是将浮点数形式的数据转换为整数形式或其他离散形式,以降低对大模型参数的存储需求,降低成本,提高计算效率
LMDeploy简介

LMDeploy是一款涵盖了LLM的轻量化、部署以及服务的开源框架,功能齐全,性能高效,还在不断迭代升级过程里
课程链接:LMDeploy 量化部署 LLM-VLM 实践_哔哩哔哩_bilibili
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









