







 超级会员免费看
超级会员免费看
什么是编译
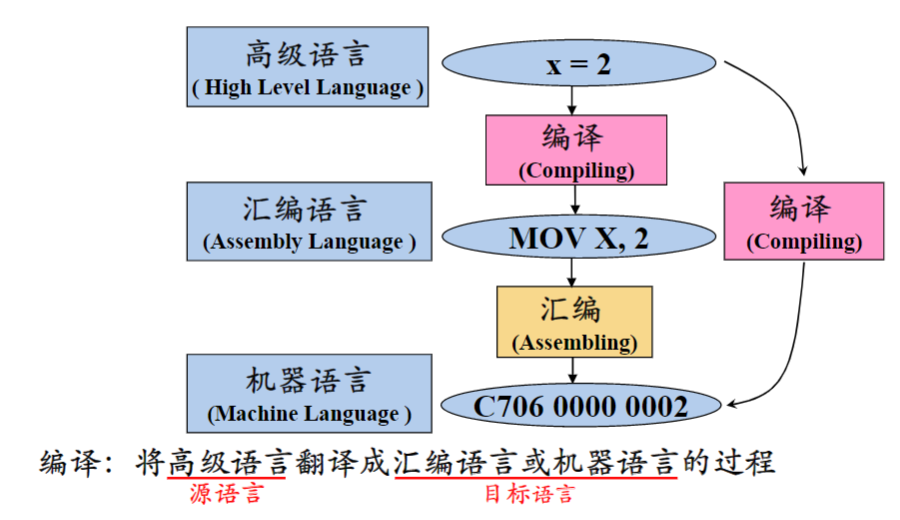
- 编译就是将高级语言翻译成汇编语言或机器语言的过程。
- 高级语言也叫源语言,汇编或机器语言叫目标语言
编译系统的结构
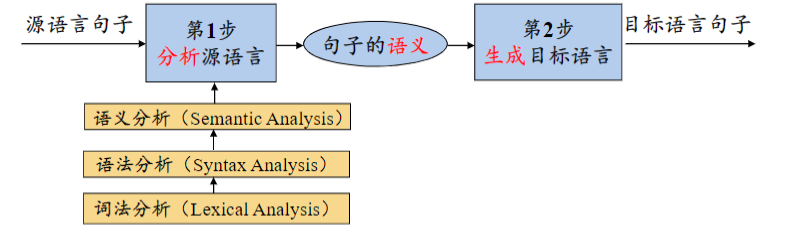
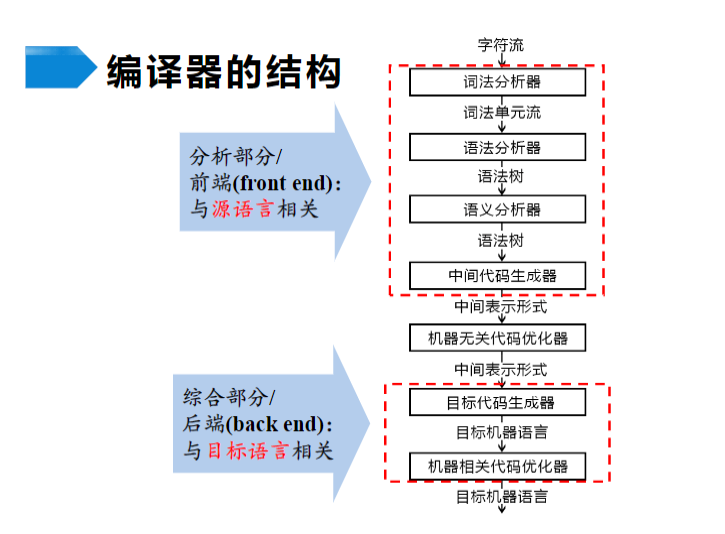
词法分析概述
词法分析就是从左向右逐行扫描源程序的字符,识别出各个单词,确定单词的类型。将识别出的单词转换成统一的机内表示——词法单元(token)形式
token:<种别码,属性值>
- 种别码:表示单词的种别,对应自然语言中的词性。
- 属性值:由于标识符和常量不可能事先全部枚举,所以使用属性值来区别标识符和常量值。

- 每个关键字都有一个种别码,所以叫一词一码。
- 多个标识符公用一个种别码,用属性值区分不同的标识符,所以叫多词一码。
- 每个常量类型都有一个种别码,用属性值区分同一类型的不同常量。
- 运算符和界限符与关键字类似,事先可以全部枚举,所以一词一码。也可以是一个运算符的类型一个种别码,用属性值区分同一类型的不同运算符。
语法分析概述
语法分析就是从词法分析器输出的token序列中识别出各类短语,并构造语法分析树(parse tree)。
语法分析树描述用来描述句子的语法结构。
【例1】赋值语句的语法分析树

【例2】变量声明语句的分析树

文法就是一系列的规则
- D:declaration,声明
- T:type,类型
- IDS:Identifier sequence,标识符序列
第一条规则表示一条声明语句是由一个类型T连接一个标识符序列IDS和一个分号构成的。
第二条规则表示类型T可以是int或real或char或bool。
第三条规则表示一个标识符id本身可以构成一个标识符序列。或者一个标识符序列连接一个逗号和一个标识符id可以构成一个更大的标识符序列。
从上图的语法树可以看出:一个标识符id本身可以构成一个标识符序列IDS;IDS连接一个逗号和一个标识符id可以构成一个更大的标识符序列;一个类型T连接一个标识符序列IDS和一个分号可以构成一个声明语句D。
语义分析概述
收集标识符的属性信息
高级语言程序中的语句大体可分为两种:声明语句和执行语句。在声明语句中会声明一些数据对象和过程,并对其分别起一个名字,这些名字也叫标识符。
对于声明语句来说,语义分析的任务就是收集标识符的属性信息
标识符的属性信息有
- 种属(Kind):简单变量、复合变量(数组、记录、……)、过程、……
- 类型(Type):整型、字符型、布尔型、指针型、……
- 存储位置、长度
- 变量值
- 作用域
- 参数和返回值信息
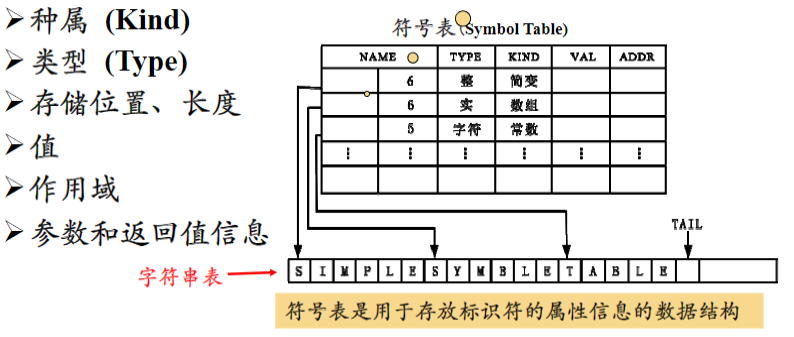
语义分析阶段得到的标识符的属性信息存放在符号表中。
符号表通常带有一个字符串表,字符串表用来存放程序中用到的标识符和字符常数,这样的话符号表中NAME字段就可分为两部分,一部分用来存放标识符在字符串表中的起始位置,另一部分用来存放标识符的长度。
语义检查
语义分析的另一个任务是语义检查。
常见语义错误

中间代码生成
常用的中间表示形式
- 三地址码
- 三地址码由类似于汇编语言的指令序列组成,每个指令最多有三个操作数
- 语法结构树/语法树
注意:这里的语法树与前面语法分析的语法树不是一回事。
常用的三地址指令

三地址指令的表示
- 四元式
- 三元式
- 间接三元式
三地址指令的四元式表示

四元式形式中第一个分量为操作符,第二和第三个分类为源操作数,第四个分量为目标操作数。
【例】中间代码的生成
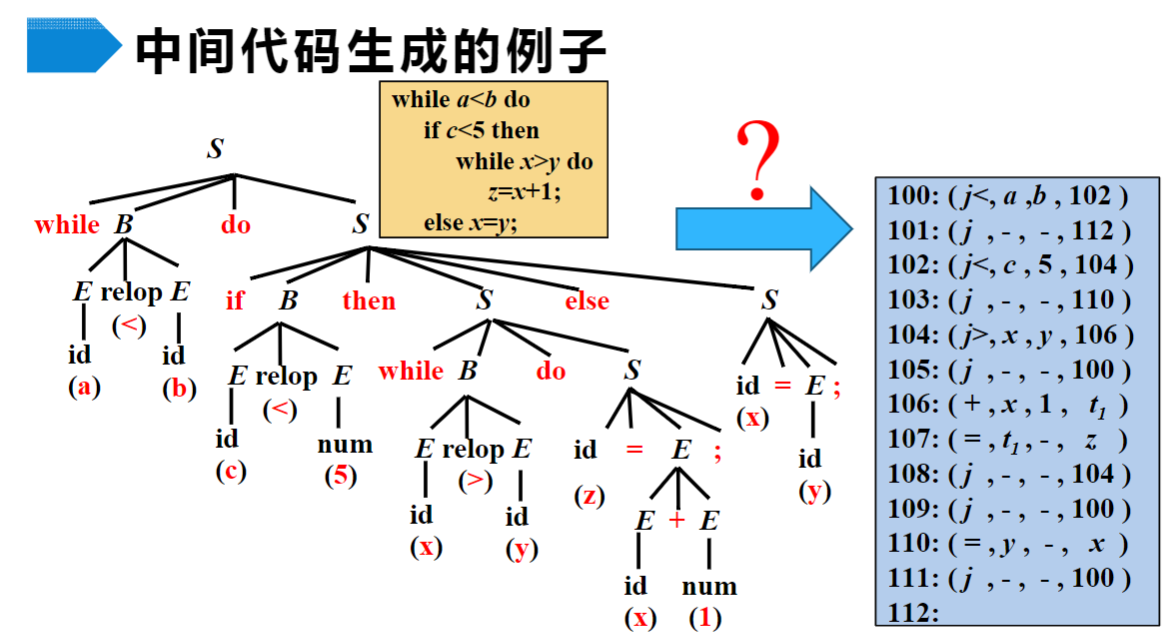
输入一个程序片段,编译得到分析树和中间代码
j:jump,跳转指令
目标代码生成
目标代码生成就是以源程序的中间表示形式作为输入,并把它映射到目标语言。
目标代码生成的一个重要任务就是为程序中使用的变量合理分配寄存器。
代码优化
代码优化是进行等价程序变化,使其运行更快,占用空间更少。
机器无关代码优化是在中间代码层面优化;机器相关代码优化是在目标代码层面优化。
优化包括识别并删除代码中的重复运算或者冗余运算、将代价较高的运算替换为等价的代价较低的运算等。
















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











