







基于统计的异常值检测
1.异常值的含义
异常值是指在数据集中偏离大部分数据的数据,使人怀疑这些数据的偏离并非由随机因素产生,而是产生于完全不同的机制。
异常挖掘(outlier mining)问题由两个子问题构成:(1)如何度量异常。(2)如何有效发现异常。
不同的异常挖掘方法就是通过不同的异常度量方法,构造异常点得分(outlier score),从而发现异常点。
2.异常值的使用背景
异常值的检测有助于识别数据中潜在的问题或异常情况,从而及早发现并解决可能的故障或错误。例如,在制造业中,通过检测流水线上生产的产品数据的异常,可以及时发现生产线的问题并进行修正,提高产品质量;通过住院费用的异常数据挖掘,可以有效的找到不合理的医疗费用支出,找出不规范的医疗行为,控制医疗费用不合理的上涨等。
因此,异常值的检测在数据研究和数学建模中是必不可少的一步。
3.方法理论简介
异常值的检测主要有基于统计、密度、距离、预测和聚类等检测方法,不同类型的数据和不同背景下异常值的检测有不同的适当的方法。
4.基于统计的异常值检测
基于统计的异常数据检测方法主要包括3σ 准则、Z分数、Boxplot(箱线图)等。其中,3σ 准则与Z分数等方法以数据服从正态分布为前提,而Boxplot不严格依赖于正态分布。
4.1 3σ准则
3σ 准则基于正态分布的性质,即大约99.7%的数据点会落在均值(μ)加减3个标准差(σ)的范围内。落在该范围之外的数据点被认为是异常值。
案例数据可从文章底部获得,接下来利用matlab实例代码介绍:
| clear all clc data1=xlsread('3.6基于统计异常值检测案例数据.xlsx');%假设A为正态分布数据,此处不进行正态分布检验 %此处的data1虽然是42*16,但只是一个对象的一个指标的数据 %所以本文可以直接把data1改成一列 data = reshape(data1, [], 1); mu = mean(data); % 计算均值 sigma = std(data); % 计算标准差 % 识别异常值 outliers = data(abs(data - mu) > 3*sigma); disp('异常值:'); disp(outliers); |
|
最终,matlab输出A.xlsx的异常值为15 15 20 20
4.2 Z分数
Z分数是数据点与其均值之间的差除以标准差。Z分数绝对值大于某个阈值(如3)的数据点被认为是异常值。
接下来利用matlab实例代码介绍:
| clear all clc data1=xlsread('3.6基于统计异常值检测案例数据.xlsx');%假设A为正态分布数据,此处不进行正态分布检验 %此处的data1虽然是42*16,但只是一个对象的一个指标的数据 %所以本文可以直接把data1改成一列 data = reshape(data1, [], 1); mu = mean(data); % 计算均值 sigma = std(data); % 计算标准差 % 计算Z分数 z_scores = (data - mu) ./ sigma; % 识别异常值 outliers = data(abs(z_scores) > 3); disp('异常值:'); disp(outliers); |
|
最终,matlab输出A.xlsx的异常值为15 15 20 20
4.3 Boxplot(箱线图)
Boxplot是一种图形化显示数据分布的方法,它使用四分位数来绘制。箱线图可以帮助我们直观地识别出可能的异常值。
接下来利用matlab实例代码介绍:
| clear all clc data1=xlsread('3.6基于统计异常值检测案例数据.xlsx'); %此处的data1虽然是42*16,但只是一个对象的一个指标的数据 %所以本文可以直接把data1改成一列 data = reshape(data1, [], 1); figure; boxplot(data); title('箱线图'); xlabel('数据'); ylabel('值'); % MATLAB不会自动标记异常值,但你可以通过观察箱线图来识别它们 % 通常,异常值会被绘制为箱线图外的小点或星号 % 如果你想要根据箱线图计算的界限来识别异常值,你可以手动计算这些界限 Q1 = prctile(data, 25); % 下四分位数 Q3 = prctile(data, 75); % 上四分位数 IQR = Q3 - Q1; % 四分位距 lower_whisker = Q1 - 1.5 * IQR; % 下限 upper_whisker = Q3 + 1.5 * IQR; % 上限 % 识别异常值 outliers = data(data < lower_whisker | data > upper_whisker); disp('异常值:'); disp(outliers); |
|
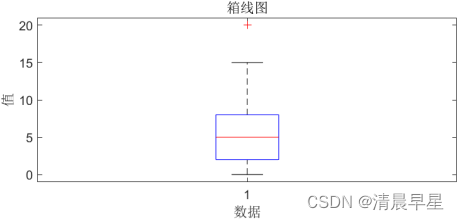
最终,matlab输出A.xlsx的异常值为20 20,箱线图如下:
4.4 基于统计的优缺点
·优点:1)异常点检测的统计学方法具有坚实的基础,建立在标准的统计学技术(如分布参数的估计)之上。2)当存在充分的数据和所用的检验类型的知识时,这些检验可能非常有效。
·缺点:1)大部分统计方法都是针对单个属性的,对于多元数据技术方法较少。2)在许多情况下,数据分布是未知的。3)对于高维数据,很难估计真实的分布。
案例数据:
链接:https://pan.baidu.com/s/1Mw6xwYvATB3atgrjnrRX6A?pwd=3650
提取码:3650
--来自百度网盘超级会员V4的分享


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









