







 本文展示了如何使用Python进行网页爬虫,从丁香园COVID-19数据页面抓取信息,利用BeautifulSoup解析HTML,再通过jsonpath提取数据,最后将数据存储到MySQL数据库中。涉及requests、re、BeautifulSoup、json、pymysql和tqdm等库,以及jsonpath模块。
本文展示了如何使用Python进行网页爬虫,从丁香园COVID-19数据页面抓取信息,利用BeautifulSoup解析HTML,再通过jsonpath提取数据,最后将数据存储到MySQL数据库中。涉及requests、re、BeautifulSoup、json、pymysql和tqdm等库,以及jsonpath模块。
新手练python爬虫
# -*- coding:utf-8 -*-
"""
作者:孙敏
日期:2022年01月01日
"""
import requests
import re
from bs4 import BeautifulSoup
import json
import pymysql
from tqdm import tqdm
import jsonpath
response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia')#请求
home_page = response.content.decode()#获取数据
soup = BeautifulSoup(home_page,'lxml')#开始解析
scrip = soup.find(id="getListByCountryTypeService2true")#寻找特定标签的数据
text = scrip.text#获取对应数据
json_str = re.findall(r'\[.+\]',text)[0]#正则提取所需数据
data = json.loads(json_str)#将str类型的数据转换成dict,即方便存入python文件
#以下两行为保存数据为json文件的代码部分
# with open('D:/python/测试/yiqing.json','w',encoding='utf-8') as fp:
# json.dump(data,fp,ensure_ascii=False)
db = pymysql.connect(host='localhost',port=3306,user='root',password='1234',database='sunmin',charset='utf8')#连接数据库
cursor = db.cursor()#创建游标
continents_list = jsonpath.jsonpath(data,'$..continents')#使用jsonpath模块的跨节点方法提取continents对应字段的列表
provinceName_list = jsonpath.jsonpath(data,'$..provinceName')#同理,提取continents对应字段的列表
statisticsData_list = jsonpath.jsonpath(data,'$..statisticsData')#同理,提取continents对应字段的列表
sql = "insert into test(continents,provinceName,statisticsData,url_id) values(%s,%s,%s,111)"#编写插入的sql语句
for i in tqdm(range(len(continents_list)),'数据采集进度'):#在列表长度范围内进行循环,并加入进度条
cursor.execute(sql,(continents_list[i],provinceName_list[i],statisticsData_list[i]))#执行sql语句
db.commit()#提交
cursor.close()#游标对象关闭连接
db.close()#数据库对象关闭连接
以下是进度条界面展示:
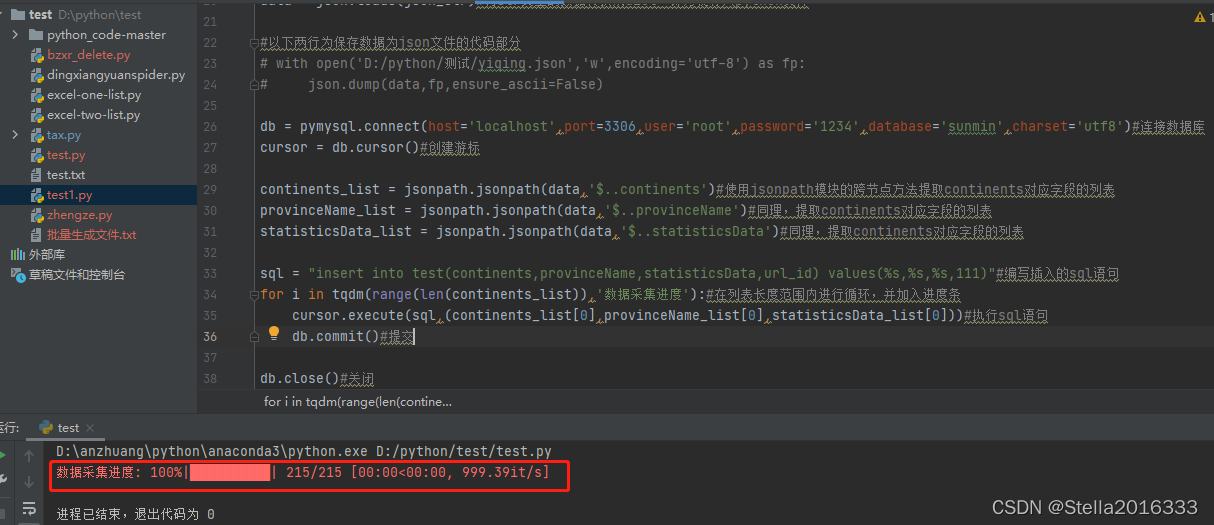
以下是mysql爬取界面展示:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









