






1.在安装了basic_demo 和 fineturne_demo的工具包,执行微调指令发现如下错误
TypeError: Seq2SeqTrainer.training_step() takes 3 positional arguments but 4 were given
Exception in thread Thread-3 (_pin_memory_loop):
Traceback (most recent call last):
File "/usr/local/lib/python3.10/threading.py", line 1016, in _bootstrap_inner
self.run()
File "/usr/local/lib/python3.10/threading.py", line 953, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/utils/data/_utils/pin_memory.py", line 59, in _pin_memory_loop
do_one_step()
我的解决方案:
原本transformers==4.46.2
pip install transformers==4.44.02.在后续微调中出现loss 为0的情况

我确定在执行过程中,使用的是bf16
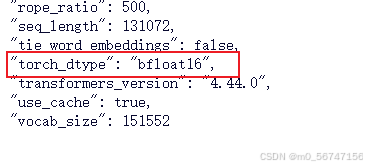
由于glm的官方提示词,无法满足本任务需要,本人重新设计了提示词。
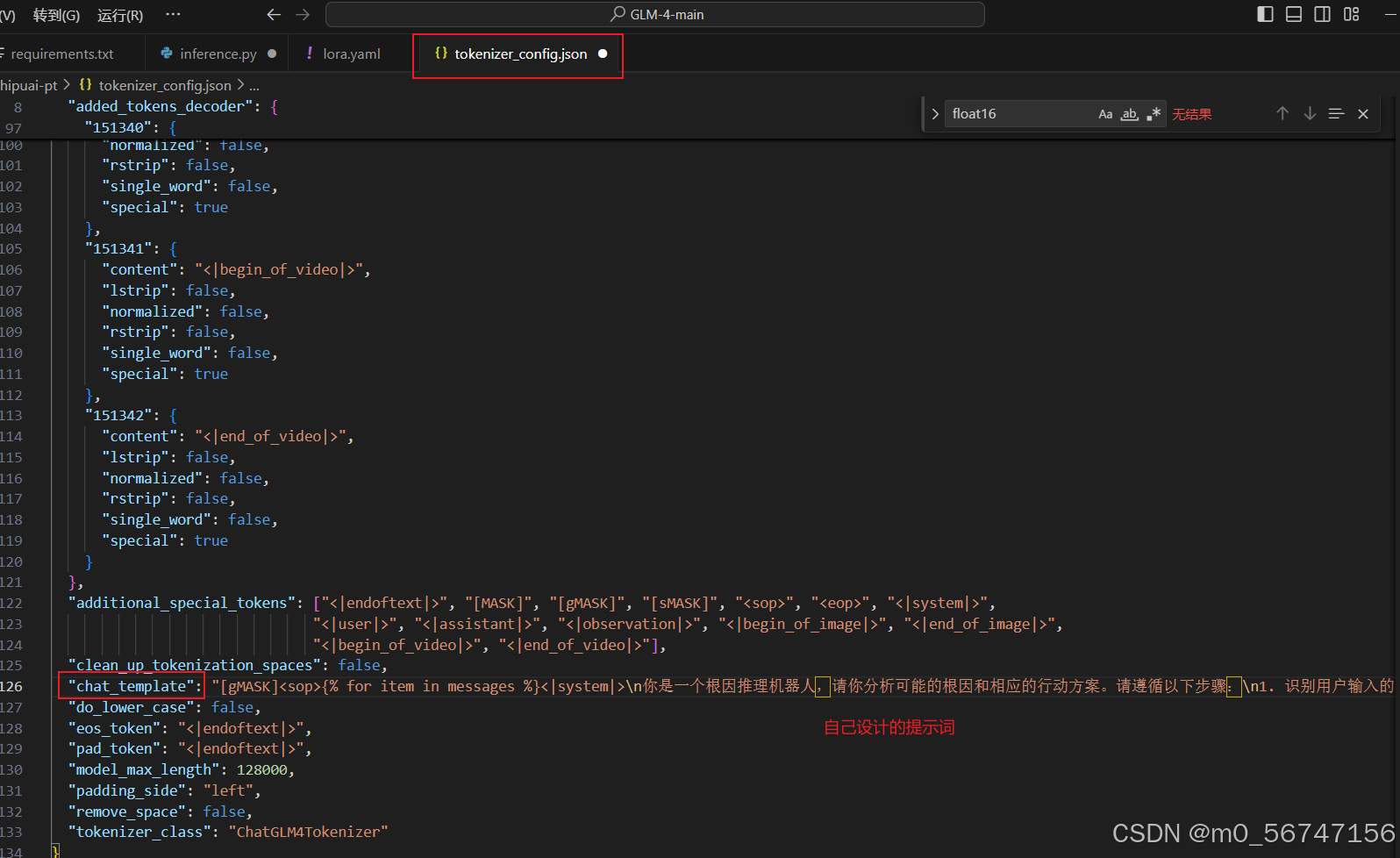
或许是因为提示词设计的过长,导致上述问题。
即 模型一次处理的输入文本的长度上限过短,模型会截断部分输入数据,导致其无法生成有效的标签
将最大输入输出长度从512修改为1024
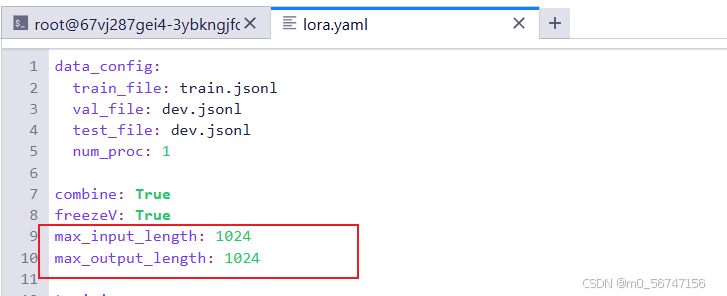
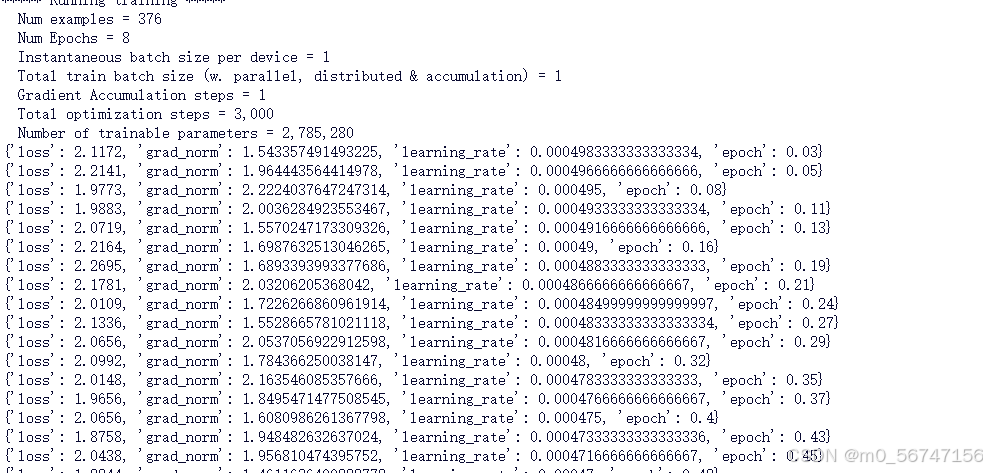
解决上述问题

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









