







简介
- 一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
- 一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
- 它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。
- Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
- 默认端口为27017。
- 推荐运行在64位平台,因为MongoDB在32位模式运行时支持的最大文件尺寸为2GB。
特点(结构)
文档
- MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。
- 多个键及其关联的值有序地放在一起就构成了文档。
- MongoDB文档为
BSON格式。- BSON是一种类JSON的二进制形式的存储格式,简称Binary JSON,
- 它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如
Date和BinData类型, - MongoDB使用BSON做为文档数据存储和网络传输格式。
- 字段的值可以包括其他文档,数组和文档数组。
- {
“greeting”:“hello,world”}这个文档只有一个键“greeting”,对应的值为“hello,world”。 - 多数情况下,文档比这个更复杂,它包含多个键/值对。
- 文档中的键/值对是有序的
- 例如:
{“greeting”:“hello,world”,“foo”: 3}、{“foo”: 3 ,“greeting”:“hello,world”} - 上面的两个文档是完全不同的两个文档
- 例如:
- 文档中的值不仅可以是双引号中的字符串,也可以是其他的数据类型,例如,整型、布尔型等,也可以是另外一个文档,即文档可以嵌套。文档中的键类型只能是字符串。
- 优点
- 文档(即对象)对应于许多编程语言中的本机数据类型。
- 嵌入式文档和数组减少了对昂贵连接的需求。
- 动态模式支持流畅的多态性。
集合
-
集合就是一组文档,类似于关系数据库中的表。
-
集合是无模式的,集合中的文档可以是各式各样的。
- 例如,
{“hello,word”:“Mike”}和{“foo”: 3},它们的键不同,值的类型也不同,但是它们可以存放在同一个集合中,也就是不同模式的文档都可以放在同一个集合中。
- 例如,
-
既然集合中可以存放任何类型的文档,那么为什么还需要使用多个集合?
- 所有文档都放在同一个集合中,无论对于开发者还是管理员,都很难对集合进行管理,而且这种情形下,对集合的查询等操作效率都不高。所以在实际使用中,往往将文档分类存放在不同的集合中。
- 例如:对于网站的日志记录,可以根据日志的级别进行存储,Info级别日志存放在Info 集合中,Debug 级别日志存放在Debug 集合中,这样既方便了管理,也提供了查询性能。
- 注意:这种对文档进行划分来分别存储并不是MongoDB 的强制要求,用户可以灵活选择。
-
可以使用“.”按照命名空间将集合划分为子集合。
- 例如:一个博客系统,可能包括
blog.user和blog.article两个子集合,这样划分只是让组织结构更好一些,blog集合和blog.user、blog.article没有任何关系。 - 虽然子集合没有任何特殊的地方,但是使用子集合组织数据结构清晰,这也是MongoDB 推荐的方法。
- 例如:一个博客系统,可能包括
数据库
- MongoDB 中多个文档组成集合,多个集合组成数据库。
- 一个MongoDB 实例可以承载多个数据库。
- 它们之间可以看作相互独立,每个数据库都有独立的权限控制。
- 在磁盘上,不同的数据库存放在不同的文件中。
- MongoDB 中存在以下系统数据库。
- Admin 数据库:一个权限数据库,如果创建用户的时候将该用户添加到admin 数据库中,那么该用户就自动继承了所有数据库的权限。
- Local 数据库:这个数据库永远不会被复制,可以用来存储本地单台服务器的任意集合。
- Config 数据库:当MongoDB 使用分片模式时,config 数据库在内部使用,用于保存分片的信息。
数据模型
- 一个MongoDB 实例可以包含多个数据库
- 一个DataBase 可以包含多个Collection(集合)
- 一个集合可以包含多个Document(文档)
- 一个Document包含多个field(字段)
- 每一个字段都是一个
key/valuepair- key: 必须为字符串类型。
- value:可以包含如下类型。
- 基本类型,例如,string,int,float,timestamp,binary 等类型。
- 一个document。
- 数组类型。
数据类型
数字
shell默认使用64位浮点型数值db.sang_collec.insert({x:3.1415926})db.sang_collec.insert({x:3})
- 整型值,我们可以使用
NumberInt或者NumberLong表示:db.sang_collec.insert({x:NumberInt(10)})db.sang_collec.insert({x:NumberLong(12)})
字符串
- 字符串可以直接存储
db.sang_collec.insert({x:"hello MongoDB!"})
正则表达式
- 正则表达式主要用在查询里边,
- 查询时我们可以使用正则表达式,语法和
JavaScript中正则表达式的语法相同, - 比如查询所有
key为x,value以hello开始的文档且不区分大小写:db.sang_collec.find({x:/^(hello)(.[a-zA-Z0-9])+/i})
数组
- 数组中的数据类型可以是多种多样的。
db.sang_collec.insert({x:[1,2,3,4,new Date()]})
日期
- MongoDB支持Date类型的数据,可以直接new一个Date对象
db.sang_collec.insert({x:new Date()})
内嵌文档
- 一个文档也可以作为另一个文档的value
db.sang_collect.insert({name:"三国演义",author:{name:"罗贯中",age:99}});- 书有一个属性是作者,作者又有name,年龄等属性。
一、数据库和集合的创建
1.数据库
- 查看数据库
- 语法:
show databases
- 语法:
- 选择数据库
- 语法:
use 数据库名称 - 示例:
use admin/admin为数据库名称
- 语法:
- 创建数据库
- 语法:
use 新数据库名称 - 当选择的数据库不存在时,MongoDB会隐式的创建
- 语法:
- 删除数据库
- 通过
use选择数据库 - 通过
db.dropDataBase()删除数据库
- 通过
2.集合
查看集合
- 语法:show collections
创建集合
- 语法:db.createCollection('集合名')
- 示例:db.createCollection('log_info') / log_info为集合名
删除集合
- 语法:db.集合名.drop()
- 示例:db.log_info.drop() / log_info为集合名
固定集合
- 固定集合中除 创建 以外,其他操作和普通集合基本一致
- 这种集合的大小是固定的,可以在创建的时候设置该集合中文档的数目
- 如,设定集合中文档的最大数目为100条,当集合中的文档数目达到100条时,如果再向集合中插入文档,则只会保留最新的100个文档,之前的文档则会被删除
- 创建:
db.createCollection("my_collect",{capped:true,size:10000,max:100})- 创建了一个名称为
my_collect,最大文档数量为100,集合大小最大为10000kb的集合 capped:true:表示该集合为一个固定大小集合size表示集合的大小,单位为kbmax则表示集合中文档的最大数量。
- 创建了一个名称为
- 通过
convertToCapped操作将一个普通集合转为一个固定集合db.runCommand({convertToCapped:"sang_collect",size:10})
自然排序问题
- 自然排序就是按照文档在磁盘中的顺序来进行排列,
- 在普通的集合中自然排序并没有多大的意义,因为文档的位置总是在变化,而固定集合中的文档是按照文档被插入的顺序保存的,自然顺序也就是文档的插入顺序
- 自然排序对文档从旧到新排序,如下:
db.sang_collect.find().sort({$natural:1})
- 也可以从新到旧排序:
db.sang_collect.find().sort({$natural:-1})
二、CRUD
插入(insertMany)
单条插入
- 语法:
db.集合名.insert(JSON数据) - 示例:在名为
test数据库的user集合中插入数据(姓名叫张三年龄18岁)use test2/ 选择test数据库db.user.insert({uname:"张三",age:18})
多条插入
- 语法:
db.user.insert([json1,json2, json3,json4.....jsonN])
注意事项及介绍
- 如果集合存在,那么直接插入数据。如果集合不存在,那么会隐式创建
- 对象的键统一不加引号,但是查看集合数据时系统会自动加
- MongoDB会给每条数据增加一个全球唯一的
_id键 - 自己增加_id(强烈不推荐)
- 只需要给插入的JSON数据增加_id键即可覆盖
db.c1.insert({_id:1, uname:"webopenfather", age:18})
示例
- 在名为
test数据库的user集合中插入数据use test2/ 选择test数据库db.user.insert([{uname:"z3", age:3},{uname:"z4", age:4},{uname:"w5", age:5} ])
- 快速插入10条数据
- 由于MongoDB底层使用JS引擎实现的,所以支持部分js语法。因此:可以写for循环
for (var i=1; i<=10; i++) {db.user.insert({uname: "a"+i, age: i})}
删除(remove)
语法:db.集合名.remove(条件,是否删除一条)
是否删除一条:默认为false,也就是删除全部条件匹配的数据
示例
- 将
user集合中的{uname:"a1"}删除:db.集合名.remove({uname:"a1"},false) - 将
user集合中的{age:"5"}删除:db.集合名.remove({uname:"a1"},true)
修改(update)
语法: db.集合名.update(条件,{修改器:{键:值}},是否新增,是否修改多条)
条件:与查询相同修改器:{键:值}值根据根据不同的修改器而填写方式不同(默认修改器为:$set)$inc:{键:值}:增加- 此处的值为
增量值 - 3 修改为 4:
inc:{age:1}
- 此处的值为
$set:{键:值}:修改列值- 此处的值为
修改后的值 - 3 修改为 4:
set:{age:4}
- 此处的值为
$rename:{键:值}:重命名列- 此处的值为
增量值 - 3 修改为 4:
inc:{age:1}
- 此处的值为
$unset:{键:值}:删除列- 此处的值为
增量值 - 3 修改为 4:
inc:{age:1}
- 此处的值为
- 是否新增
- 指条件匹配不到的情况下,此数据是否插入(
true插入,false不插入) ,默认为false
- 指条件匹配不到的情况下,此数据是否插入(
- 是否修改多条
- 指将匹配成功的数据都修改(
true是,false否),默认为false
- 指将匹配成功的数据都修改(
- 执行更新需要使用修改器,如果不使用,那么会将
新数据替换原来的数据。- 不使用修改器需要将 所有列 都填充,否则执行完毕之后,未填充的列 为 空
示例
-
不使用修改器的情况
-
示例1:语句:
db.user.update({uname: 'a1'},{age:2})- 修改前
_id uname age 63f46b53353800005c00112f a1 5 - 修改后
_id uname age 63f46b53353800005c00112f 2 -
示例2:语句:
db.user.update({uname: 'a1'},{uname:a1,age:2})- 修改前
_id uname age 63f46b53353800005c00112f a1 5 - 修改后
_id uname age 63f46b53353800005c00112f a1 2
-
-
将
user集合中的{uname:"a1"}改为{uname:"a99"}- 语句:
db.user.update({uname: 'a1'}, {$set: {uname: 'a99'}}) - 修改前
_id uname age 63f46b53353800005c00112f a1 5 - 修改后
_id uname age 63f46b53353800005c00112f a99 5 - 语句:
-
将
user集合中的{uname:"a99"}的年龄加 2 岁- 语句:
db.user.update({uname: 'a1'}, {$inc: {age:2}}) - 修改前
_id uname age 63f46b53353800005c00112f a1 5 - 修改后
_id uname age 63f46b53353800005c00112f a99 7 - 减 2 岁为:
db.user.update({uname: 'a1'}, {$inc: {age:-2}})
- 语句:
-
将
user集合中的test列删除- 语句:
db.user.update({},{$unset:{test:1}}) - 修改前
_id uname age test 63f46b53353800005c00112f a1 5 - 修改后
_id uname age 63f46b53353800005c00112f a1 5 - 语句:
-
将
user集合中的test列重命名为sex- 语句:
db.user.update({},{$rename:{test:'sex'}},false,true) - 修改前
_id uname age test 63f46b53353800005c00112f a1 5 - 修改后
_id uname age sex 63f46b53353800005c00112f a1 5 - 语句:
查询(find)
语法:
- 查询多列:
db.集合名.find({键:{运算符:值}},[{列名1:1},{列名2:1}]) - 查询单列:
db.集合名.find({键:{运算符:值}},{列名:1}) - 查询所有列:
db.集合名.find({键:{运算符:值}}) - 进行
等于匹配的情况下{键:{运算符:值}可简化为:{键:值} - 查询指定列时:
{列:1}1代表为查询此列,0代表不查询此列
| 条件 | 语法 |
|---|---|
| 查询所有的数据 | {}或者不写 |
| 查询age=6的数据 | {age:6} |
| 既要age=6又要性别=男 | {age:6,sex:‘男’} |
| 查询的列(可选参数) | 写法 |
|---|---|
| 查询全部列(字段) | 不写 |
| 只显示age列(字段) | {age:1} |
| 除了age列(字段)都显示 | {age:0} |
| 运算符 | 作用 |
|---|---|
| $gt | 大于 |
| $gte | 大于等于 |
| $lt | 小于 |
| $lte | 小于等于 |
| $ne | 不等于 |
| $in | in |
| $nin | not in |
| 示例 |
- 查询
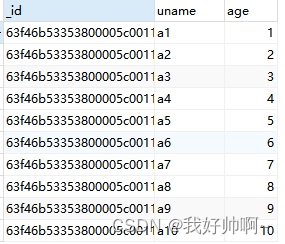
user集合中的所有数据:db.user.find()
- 查询
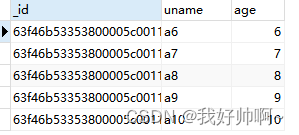
user集合中age大于5的数据:db.user.find({age:{$gt:5}})
- 查询
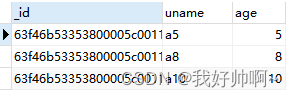
user集合中age是 5、8、10 的数据:db.user.find({age:{$in:[5,8,10]}})
- 询
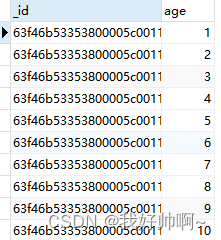
user集合,只看年龄列:db.user.find({},{age:1})
- 询
user集合,查看除年龄以外的列:db.user.find({},{age:0})
进阶查询(null/正则表达式查询/数组查询/嵌套文档查询)
null
null的查询与其他查询不同,假如我想查询uname为null的数据db.user.find({uname:null})- 这样不仅会查出z为null的文档,也会查出所有没有z字段的文档,
- 如果只想查询
uname为null的字段,再多加一个条件:判断一下uname这个字段是否存在db.user.find({uname:{$in:[null],$exists:true}})
正则表达式查询
- 正则表达式语法和
JavaScript中的语法一致 - 查询所有
key为uname,value以张开始的文档且不区分大小写db.user.find({uname:/^(hello)(.[a-zA-Z0-9])+/i})
数组查询
假设有一个数据集如下:
{ "_id" : ObjectId("59f1ad41e26b36b25bc605ae"), "books" : [ "三国演义", "红楼梦", "水浒传" ] }
- 查询books中含有三国演义的文
db.sang_collect.find({books:"三国演义"})
- 查询既有三国演义又有红楼梦的文档,可以使用
$alldb.sang_collect.find({books:{$all:["三国演义","红楼梦"]}})
- 精确匹配,查询books为
"三国演义","红楼梦", "水浒传"的数据db.sang_collect.find({books:["三国演义","红楼梦", "水浒传"]})
- 按照下标匹配,查询数组中下标为
2的项的为"水浒传"的文档db.sang_collect.find({"books.2":"水浒传"})
- 按照数组长度来查询,查询数组长度为3的文档
db.sang_collect.find({books:{$size:3}})
- 如果想查询数组中的前两条数据,可以使用
$slicedb.sang_collect.find({},{books:{$slice:2}})- 注意:写在
find的第二个参数的位置。 2表示数组中前两个元素,-2表示从后往前数两个元素。- 也可以截取数组中间的元素,比如查询数组的第二个到第四个元素:
db.sang_collect.find({},{books:{$slice:[1,3]}})
数组中的与的问题
- 假设有如下数据:
{ "_id" : ObjectId("59f208bc7b00f982986c669c"), "x" : [ 5.0, 25.0 ] } - 将数组中value取值在(10,20)之间的文档获取到
db.sang_collect.find({x:{$lt:20,$gt:10}})
- 此时上面这个文档虽然不满足条件却依然被查找出来了
- 因为5<20,而25>10,
- 要解决这个问题,我们可以使用
$elemMatchdb.sang_collect.find({x:{$elemMatch:{$lt:20,$gt:10}}})
$elemMatch要求MongoDB同时使用查询条件中的两个语句与一个数组元素进行比较。
嵌套文档查询
- 嵌套文档有两种查询方式
- 数据如下:
{ "_id" : ObjectId("59f20c9b7b00f982986c669f"), "x" : 1.0, "y" : { "z" : 2.0, "k" : 3.0 } } - 查询上面这个文档,
db.sang_collect.find({y:{z:2,k:3}})- 这种写法要求严格匹配,顺序都不能变,
- 假如写成了
db.sang_collect.find({y:{k:3,z:2}}),就匹配不到, - 因此这种方法不够灵活,我们一般推荐的是下面这种写法:
db.sang_collect.find({"y.z":2,"y.k":3})- 这种写法可以任意颠倒顺序。
游标
- 游标这个概念在很多地方都有,Java中JDBC里的ResultSet,Android中的Cursor等等都是
- MongoDB中也有类似的概念。
- 当我们调用find方法时,就可以返回一个游标
var cursor = db.sang_collect.find();
- 游标中有hasNext()方法,也有next()方法,这两个方法结合可以用来遍历结果
while(cursor.hasNext()){ print(cursor.next()) }- next()方法可以获取查询到的每一个文档,如下:
{ "_id" : ObjectId("59f299579babb96c21ddc9e8"), "x" : 0.0, "y" : 1000.0 } /* 2 */ { "_id" : ObjectId("59f299579babb96c21ddc9e9"), "x" : 1.0, "y" : 999.0 } - 只获取文档中的某一个字段,可以按如下方式:
while(cursor.hasNext()){ print(cursor.next().y) } - cursor实现了JavaScript中的迭代器接口,可以直接调用forEach方法来遍历:
cursor.forEach(function(x){ print(x) }) - 当我们调用find方法获取cursor时,shell并不会立即查询数据库,而是在真正使用数据时才会去加载,这有点类似于数据库框架中的懒加载,shell在每次查询的时候会获取前100条结果或者前4MB数据(两者之间取最小),然后我们调用hasNext和next时shell就不用再去连接数据库了,直接一条一条的返回查询到的数据,这100条或者4MB数据全部被返回之后,shell才会再次发起请求向MongoDB要数据。
limit
- limit是cursor中的方法,用来限制返回结果的数量,
- 只获取查询的前三条结果
var cursor = db.sang_collect.find().limit(3)
skip
- skip是cursor中的方法,用来表示跳过的记录数,
- 获取第2到第5条记录
var cursor = db.sang_collect.find().skip(2).limit(4)- 跳过前两条(0和1)然后获取后面4条数据
skip和limit结合有点类似于MySQL中的limit- 可以用来做分页,不过这种分页方式效率过低。
sort
- sort用来实现排序功能
- 如按x排序
var cursor = db.sang_collect.find().sort({x:-1})- 1表示升序,-1表示降序。
三、管道操作符
- 在管道开始执行的阶段尽可能过滤掉足够多的数据
- 只有从集合中直接查询时才会使用索引,尽早执行过滤可以让索引发挥作用;
- 该过滤的数据过滤掉之后,也可以降低后面管道的执行压力。
- 另外,MongoDB不允许一个聚合操作占用过多的内存,如果有一个聚合操作占用了超过20%的内存,则会直接报错。
$match
-
用于对文档进行筛选,之后可以在得到的文档子集上做聚合
-
$match可以使用除了地理空间之外的所有常规查询操作符 -
在实际应用中尽可能将
$match放在管道的前面位置- 可以快速将不需要的文档过滤掉,以减少管道的工作量;
- 如果再投射和分组之前执行$match,查询可以使用索引;
-
数据如下
var tags = ["nosql","mongodb","document","developer","popular"]; var types = ["technology","sociality","travel","novel","literature"]; var books=[]; for(var i=0;i<50;i++){ var typeIdx = Math.floor(Math.random()*types.length); var tagIdx = Math.floor(Math.random()*tags.length); var tagIdx2 = Math.floor(Math.random()*tags.length); var favCount = Math.floor(Math.random()*100); var username = "xx00"+Math.floor(Math.random()*10); var age = 20 + Math.floor(Math.random()*15); var book = { title: "book-"+i, type: types[typeIdx], tag: [tags[tagIdx],tags[tagIdx2]], favCount: favCount, author: {name:username,age:age} }; books.push(book) } db.books1.insertMany(books); -
查询
books1集合中type字段为technology的所有数据db.books1.aggregate([{$match:{type:"technology"}}])
$count
- 计数并返回与查询匹配的结果数
db.books1.aggregate([ {$match:{type:"technology"}}, {$count: "type_count"} ])$match阶段筛选出type匹配technology的文档,并传到下一阶段;$count阶段返回聚合管道中剩余文档的计数,并将该值分配给type_count
$unwind
- 用来实现对文档的拆分,可以将文档中的值拆分为单独的文档,
- 数据如下:
{ "_id" : ObjectId("59f93c8b8523cfae4cf4ba86"), "name" : "鲁迅", "books" : [ { "name" : "呐喊", "publisher" : "花城出版社" }, { "name" : "彷徨", "publisher" : "南海出版出" } ] } - 使用
$unwind命令将其拆分为独立文档,如下:
db.sang_books.aggregate({$unwind:"$books"}){ "_id" : ObjectId("59f93c8b8523cfae4cf4ba86"), "name" : "鲁迅", "books" : { "name" : "呐喊", "publisher" : "花城出版社" } } { "_id" : ObjectId("59f93c8b8523cfae4cf4ba86"), "name" : "鲁迅", "books" : { "name" : "彷徨", "publisher" : "南海出版出" } }
$project
基本用法
-
可以用来提取想要的字段,
如:db.sang_collect.aggregate({$project:{title:1,_id:0}})
参数解释:1表示要该字段,0表示不要该字段, -
可以对返回的字段进行重命名,比如将
title改为articleTitle
如:db.sang_collect.aggregate({$project:{"articleTitle":"$title"}})
注意: 如果原字段上有索引,重命名之后的字段上就没有索引了,因此最好在重命名之前使用索引。
数学表达式
- 可以用来对一组数值进行加减乘除取
比如数据结构如下:{ "_id" : ObjectId("59f841f5b998d8acc7d08863"), "orderAddressL" : "ShenZhen", "prodMoney" : 45.0, "freight" : 13.0, "discounts" : 3.0, "orderDate" : ISODate("2017-10-31T09:27:17.342Z"), "prods" : [ "可乐", "奶茶" ] } - 加法和乘法都可以接收多个参数,其余的都接收两个参数。
- 订单的总费用为商品费用加上运费,查询如下:
db.sang_collect.aggregate({$project:{totalMoney:{$add:["$prodMoney","$freight"]}}}) - 实际付款的费用是总费用减去折扣,如下:
db.sang_collect.aggregate({$project:{totalPay:{$subtract:[{$add:["$prodMoney","$freight"]},"$discounts"]}}}) - 计算prodMoney和freight和discounts的乘积:
db.sang_collect.aggregate({$project:{test1:{$multiply:["$prodMoney","$freight","$discounts"]}}}) - 求freight的商,如下:
db.sang_collect.aggregate({$project:{test1:{$divide:["$prodMoney","$freight"]}}}) - prodMoney取模,如下:
db.sang_collect.aggregate({$project:{test1:{$mod:["$prodMoney","$freight"]}}})
日期表达式
-
可以从一个日期类型中提取出年、月、日、星期、时、分、秒等信息
示例:db.sang_collect.aggregate({ $project: { "年份": { $year: "$orderDate" }, "月份": { $month: "$orderDate" }, "一年中第几周": { $week: "$orderDate" }, "日期": { $dayOfMonth: "$orderDate" }, "星期": { $dayOfWeek: "$orderDate" }, "一年中第几天": { $dayOfYear: "$orderDate" }, "时": { $hour: "$orderDate" }, "分": { $minute: "$orderDate" }, "秒": { $second: "$orderDate" }, "毫秒": { $millisecond: "$orderDate" }, "自定义格式化时间": { $dateToString: { format: "%Y年%m月%d %H:%M:%S", date: "$orderDate" } } } }) -
执行结果如下:
{ "_id" : ObjectId("59f841f5b998d8acc7d08861"), "年份" : 2017, "月份" : 10, "一年中第几周" : 44, "日期" : 31, "星期" : 3, "一年中第几天" : 304, "时" : 9, "分" : 27, "秒" : 17, "毫秒" : 342, "自定义格式化时间" : "2017年10月31 09:27:17" }-
week表示本周是本年的第几周,从0开始计。
$dateToString是MongoDB3.0+中的功能。
格式化的字符还有以下几种:字符 含义 取值范围 %Y Year (4 digits,zero padded) 0000-9999 %m Month (2 digits,zero,padded) 01-12 %d Day of Month (2 digits,zero padded) 01-31 %H Hour (2 digits,zero padded,24-hour clock) 00-23 %M Minute (2 digits,zero padded) 00-59 %S Second (2 digits,zero padded) 00-60 %L Millisecond (3 digits,zero padded) 000-999 %j Day of year (3 digits,zero padded) 001-366 %w Day of week (1-Synday,7-Saturday) 1-7 %U Week of year (2 digits,zero padded)
-
字符串表达式
截取、拼接、转大写、转小写等操作
-
截取orderAddressL前两个字符返回:
db.sang_collect.aggregate({$project:{addr:{$substr:["$orderAddressL",0,2]}}}) -
将orderAddressL和orderDate拼接后返回:
db.sang_collect.aggregate({$project:{addr:{$concat:["$orderAddressL",{$dateToString:{format:"--%Y年%m月%d",date:"$orderDate"}}]}}})
结果如下:{ "_id" : ObjectId("59f841f5b998d8acc7d08861"), "addr" : "NanJing--2017年10月31" } -
将orderAddressL全部转为小写返回:
db.sang_collect.aggregate({$project:{addr:{$toLower:"$orderAddressL"}}}) -
将orderAddressL全部转为大写返回:
db.sang_collect.aggregate({$project:{addr:{$toUpper:"$orderAddressL"}}})
逻辑表达式
$cmp
- 作用:比较两个数字的大小
- 例如:
db.sang_collect.aggregate({$project:{test:{$cmp:["$freight","$discounts"]}}})
如果第一个参数大于第二个参数返回正数,第一个参数小于第二个则返回负数
$strcasecmp
- 作用:来比较字符串(中文无效)
- 例如:
db.sang_collect.aggregate({$project:{test:{$strcasecmp:[{$dateToString:{format:"..%Y年%m月%d",date:"$orderDate"}},"$orderAddressL"]}}})
eq/ne/gte/lte/or/and
- 一样是适用的,下面举例说明
例如: - eq
db.sang_collect.aggregate({$project:{test:{$and:[{"$eq":["$freight","$prodMoney"]},{"$eq":["$freight","$discounts"]}]}}}) - or
db.sang_collect.aggregate({$project:{test:{$not:{"$or":["$freight","$prodMoney"]}}}}) - not
db.sang_collect.aggregate({$project:{test:{$not:{"$eq":["$freight","$prodMoney"]}}}})
流程控制语句
$cond
- 第一个参数如果为true,则返回trueExpr,否则返回falseExpr
db.sang_collect.aggregate({$project:{test:{$cond:[false,"trueExpr","falseExpr"]}}})
$ifNull
- 第一个参数如果为null,则返回replacementExpr,否则就返回第一个参数
db.sang_collect.aggregate({$project:{test:{$ifNull:[null,"replacementExpr"]}}})
$group
基本操作
$group可以用来对文档进行分组- 将订单按照城市进行分组,并统计出每个城市的订单数量:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",count:{$sum:1}}})
将要分组的字段传递给$group函数的_id字段,然后每当查到一个,就给count加1,这样就可以统计出每个城市的订单数量。
算术操作符
- 通过算术操作符可以对分组后的文档进行求和或者求平均数
- 计算每个城市订单运费总和:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",totalFreight:{$sum:"$freight"}}})
先按地址分组,再求和。这里贴出部分查询结果,如下:{ "_id" : "HaiKou", "totalFreight" : 20.0 } { "_id" : "HangZhou", "totalFreight" : 10.0 } - 计算每个城市运费的平均数:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",avgFreight:{$avg:"$freight"}}})
先按地址分组,然后再计算平均数。
极值操作符
-极值操作符用来获取分组后数据集的边缘值
$max
- 获取每个城市最贵的运费:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",maxFreight:{$max:"$freight"}}})
$min
- 查询每个城市最便宜的运费:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",minFreight:{$min:"$freight"}}})
$first
- 按城市分组之后,获取该城市第一个运费单:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",firstFreight:{$first:"$freight"}}})
$last
- 获取分组后的最后一个运费单:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",lastFreight:{$last:"$freight"}}})
数据操作符
$addToSet
- 可以将分组后的某一个字段放到一个数组中,但是重复的元素将只出现一次,而且元素加入到数组中的顺序是无规律的。
- 重复的freight将不会被添加进来。
- 将分组后的每个城市的运费放到一个数组中:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",freights:{$addToSet:"$freight"}}})
$push
- 对重复的数据不做限制,都可以添加进来,如下:
db.sang_collect.aggregate({$group:{_id:"$orderAddressL",freights:{$push:"$freight"}}})
其他操作符:sort/limit/skip
$sort
- 可以对文档进行排序,如下:
db.sang_collect.aggregate({$sort:{orderAddressL:1}})- 用法和普通搜索中的一致,可以按照存在的字段排序,
- 也可以按照重命名的字段排序,如下:
db.sang_collect.aggregate({$project:{oa:"$orderAddressL"}},{$sort:{oa:-1}})- 1表示升序、-1表示降序。
$limit
- 返回结果中的前n个文档
- 表示返回结果中的前三个文档,如下:
db.sang_collect.aggregate({$project:{oa:"$orderAddressL"}},{$limit:3})
$skip
$skip的效率低,要慎用。- 表示跳过前n个文档
- 如跳过前5个文档,如下:
db.sang_collect.aggregate({$project:{oa:"$orderAddressL"}},{$skip:5})
四、explain(执行计划分析)
- MongoDB提供
db.collection.explain()、cursort.explain()及explain命令,获取查询计划及查询计划统计信息。利用explain命令,我们可以很好的观察系统如何使用索引来加快检索,同时可以做针对性的性能优化。 explain()的用法和sort()、limit()用法差不多explain()必须放在最后面
基本用法
db.sang_collect.find({uname:'张三').explain()- 直接跟在
find()函数后面,表示查看find()函数的执行计划,结果如下:{ "explainVersion" : "1", "queryPlanner" : { "namespace" : "test.user", "indexFilterSet" : false, "parsedQuery" : { "uname" : { "$eq" : "张三" } }, "queryHash" : "034512E9", "planCacheKey" : "71C0C0EB", "maxIndexedOrSolutionsReached" : false, "maxIndexedAndSolutionsReached" : false, "maxScansToExplodeReached" : false, "winningPlan" : { "stage" : "COLLSCAN", "filter" : { "uname" : { "$eq" : "张三" } }, "direction" : "forward" }, "rejectedPlans" : [ ] }, "command" : { "find" : "user", "filter" : { "uname" : "张三" }, "$db" : "test" }, "serverInfo" : { "host" : "yanshi0011", "port" : 27017, "version" : "5.0.13", "gitVersion" : "cfb7690563a3144d3d1175b3a20c2ec81b662a8f" }, "serverParameters" : { "internalQueryFacetBufferSizeBytes" : 104857600, "internalQueryFacetMaxOutputDocSizeBytes" : 104857600, "internalLookupStageIntermediateDocumentMaxSizeBytes" : 104857600, "internalDocumentSourceGroupMaxMemoryBytes" : 104857600, "internalQueryMaxBlockingSortMemoryUsageBytes" : 104857600, "internalQueryProhibitBlockingMergeOnMongoS" : 0, "internalQueryMaxAddToSetBytes" : 104857600, "internalDocumentSourceSetWindowFieldsMaxMemoryBytes" : 104857600 }, "ok" : 1 } - 返回结果
-
重点参数
queryPlanner:查询计划serverInfo:MongoDB服务的一些信息
-
其他参数
参数 含义 plannerVersion 查询计划版本 namespace 要查询的集合 indexFilterSet 是否使用索引 parsedQuery 查询条件,此处为x=1 winningPlan 最佳执行计划 stage 查询方式,常见的有COLLSCAN/全表扫描、IXSCAN/索引扫描、FETCH/根据索引去检索文档、SHARD_MERGE/合并分片结果、IDHACK/针对_id进行查询 filter 过滤条件 direction 搜索方向 rejectedPlans 拒绝的执行计划 serverInfo MongoDB服务器信息
-
进阶操作(添加不同参数)
-
explain()也接收不同的参数,通过设置不同参数我们可以查看更详细的查询计划。 -
queryPlanner:是默认参数,添加queryPlanner参数的查询结果就是我们上文看到的查询结果 -
executionStats:会返回最佳执行计划的一些统计信息,如下:{ "queryPlanner" : { "plannerVersion" : 1, "namespace" : "sang.sang_collect", "indexFilterSet" : false, "parsedQuery" : {}, "winningPlan" : { "stage" : "COLLSCAN", "direction" : "forward" }, "rejectedPlans" : [] }, "executionStats" : { "executionSuccess" : true, "nReturned" : 10000, "executionTimeMillis" : 4, "totalKeysExamined" : 0, "totalDocsExamined" : 10000, "executionStages" : { "stage" : "COLLSCAN", "nReturned" : 10000, "executionTimeMillisEstimate" : 0, "works" : 10002, "advanced" : 10000, "needTime" : 1, "needYield" : 0, "saveState" : 78, "restoreState" : 78, "isEOF" : 1, "invalidates" : 0, "direction" : "forward", "docsExamined" : 10000 } }, "serverInfo" : { "host" : "localhost.localdomain", "port" : 27017, "version" : "3.4.9", "gitVersion" : "876ebee8c7dd0e2d992f36a848ff4dc50ee6603e" }, "ok" : 1.0 } -
这里除了我们上文介绍到的一些参数之外,还多了
executionStats参数,含义如下:参数 含义 executionSuccess 是否执行成功 nReturned 返回的结果数 executionTimeMillis 执行耗时 totalKeysExamined 索引扫描次数 totalDocsExamined 文档扫描次数 executionStages 这个分类下描述执行的状态 stage 扫描方式,具体可选值与上文的相同 nReturned 查询结果数量 executionTimeMillisEstimate 预估耗时 works 工作单元数,一个查询会分解成小的工作单元 advanced 优先返回的结果数 docsExamined 文档检查数目,与totalDocsExamined一致 -
allPlansExecution:用来获取所有执行计划,结果参数基本与上文相同,这里就不再细说了。
其他介绍
explain结果将查询计划以阶段树的形式呈现。- 每个阶段将其结果(文档或索引键)传递给父节点。
- 叶节点访问集合或索引。
- 中间节点操纵有子节点产生的文档或索引建。
- 根节点是MongoDB从中派生结果集的最后阶段。
explain有三种模式,分别是:queryPlanner、executionStats、allPlansExecution
阶段操作描述
| 字符 | 含义 |
|---|---|
| COLLSCAN | 集合扫描 |
| IXSCAN | 索引扫描 |
| FETCH | 检出文档 |
| SHARD_MERGE | 合并分片中结果 |
| SHARDING_FILTER | 分片中过滤掉孤立文档 |
| LIMIT | 使用limit 限制返回数 |
| PROJECTION | 使用 skip 进行跳过 |
| IDHACK | 针对_id进行查询 |
| COUNT | 利用db.coll.explain().count()之类进行count运算 |
| COUNTSCAN c | ount不使用Index进行count时的stage返回 |
| COUNT_SCAN | count使用了Index进行count时的stage返回 |
| SUBPLA | 未使用到索引的$or查询的stage返回 |
| TEXT | 使用全文索引进行查询时候的stage返回 |
| PROJECTION | 限定返回字段时候stage的返回 |
| … | … |
五、索引
查看索引
- 默认情况下,集合中的_id字段就是索引
- 我们可以通过
getIndexes()方法来查看一个集合中的索引db.sang_collect.getIndexes()- 结果:
[ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_" } ] - 我们看到这里只有一个索引,就是_id。
索引创建
-
现在我的集合中有10000个文档,我想要查询x为1的文档,我的查询操作如下:
db.sang_collect.find({x:1})
-
这种查询默认情况下会做全表扫描,我们可以用
explain()来查看一下查询计划db.sang_collect.find({x:1}).explain("executionStats")
"queryPlanner" : {
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 1,
"executionTimeMillis" : 15,
"totalKeysExamined" : 0,
"totalDocsExamined" : 10000,
"executionStages" : {
"stage" : "COLLSCAN",
"filter" : {
"x" : {
"$eq" : 1.0
}
},
"nReturned" : 1,
"executionTimeMillisEstimate" : 29,
"works" : 10002,
"advanced" : 1,
"needTime" : 10000,
"needYield" : 0,
"saveState" : 78,
"restoreState" : 78,
"isEOF" : 1,
"invalidates" : 0,
"direction" : "forward",
"docsExamined" : 10000
}
},
"serverInfo" : {
},
"ok" : 1.0
}
- 可以看到查询方式是全表扫描,一共扫描了10000个文档才查出结果。
- 实际所需文档就排第二个,但系统不知道这个集合中一共有多少个x为1的文档,所以会全表扫描,这种方式很低效,但是如果加上
limit,如下:db.sang_collect.find({x:1}).limit(1)
- 此时再看查询计划发现只扫描了两个文档就有结果,
- 但是如果我要查询
x为9999的记录,还是需要把全表扫描。此时,我们就可以给该字段建立索引,索引建立方式如下:db.sang_collect.ensureIndex({x:1})- 此时调用
getIndexes()方法可以看到我们刚刚创建的索引 - 1表示升序,-1表示降序。
- 当我们给x字段建立索引之后,再根据x
字段去查询,速度就非常快了,查看如下查询操作的执行计划: - 重点关注查询要耗费的时间
db.sang_collect.find({x:9999}).explain("executionStats")[ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "sang.sang_collect" }, { "v" : 2, "key" : { "x" : 1.0 }, "name" : "x_1", "ns" : "sang.sang_collect" } ]
- 每个索引都有一个名字,默认的索引名字为
字段名_排序值, - 在创建索引时自定义索引名字,如下:
db.sang_collect.ensureIndex({x:1},{name:"myfirstindex"})- 此时创建好的索引如下:
{ "v" : 2, "key" : { "x" : 1.0 }, "name" : "myfirstindex", "ns" : "sang.sang_collect" }
- 索引在创建的过程中还有许多其他可选参数
-
db.sang_collect.ensureIndex({x:1} -
{name:"myfirstindex",dropDups:true,background:true,unique:true,sparse:true,v:1,weights:99999}) -
参数说明:
- name表示索引的名称
- dropDups表示创建唯一性索引时如果出现重复,则将重复的删除,只保留第一个
- background是否在后台创建索引,在后台创建索引不影响数据库当前的操作,默认为false
- unique是否创建唯一索引,默认false
- sparse对文档中不存在的字段是否不起用索引,默认false
- v表示索引的版本号,默认为2
- weights表示索引的权重
-
此时创建好的索引如下:
{ "v" : 1, "unique" : true, "key" : { "x" : 1.0 }, "name" : "myfirstindex", "ns" : "sang.sang_collect", "background" : true, "sparse" : true, "weights" : 99999.0 }
-
删除索引
- 按名称删除索引
db.sang_collect.dropIndex("xIndex")- 表示删除一个名为xIndex的索引,
- 删除所有索引
db.sang_collect.dropIndexes()
复合索引
- 查询条件有多个的话,可以对这多个查询条件都建立索引,
- 如对
user文档中的uname和age字段都建立索引,如下:db.user.ensureIndex({uname:1,age:-1})- 此时执行如下查询语句时就会用到这个复合索引:
db.user.find({uname:1,age:999})
过期索引
- 过期索引就是一种会过期的索引,在索引过期之后,索引对应的数据会被删除,创建方式如下:
db.sang_collect.ensureIndex({time:1},{expireAfterSeconds:30})expireAfterSeconds表示索引的过期时间,单位为秒。time表示索引的字段,time的数据类型必须是ISODate或者ISODate数组,否则的话,当索引过期之后,time的数据就不会被删除。
全文索引
- 原生不支持中文,网上有很多解决方案
- 数据集如下:
{ "_id" : ObjectId("59f5a3da1f9e8e181ffc3189"), "x" : "Java C# Python PHP" } { "_id" : ObjectId("59f5a3da1f9e8e181ffc318a"), "x" : "Java C#" } { "_id" : ObjectId("59f5a3da1f9e8e181ffc318b"), "x" : "Java Python" } { "_id" : ObjectId("59f5a3da1f9e8e181ffc318c"), "x" : "PHP Python" } { "_id" : ObjectId("59f5a4541f9e8e181ffc318d"), "x" : "C C++" } - 给x字段建立一个全文索引,创建方式如下:
db.sang_collect.ensureIndex({x:"text"})
- MongoDB会自动对x字段的数据进行分词
- 通过此语句进行查询:
db.sang_collect.find({$text:{$search:"Java"}}) - 此时x中包含Java的文档都会被查询出来
- 查询既包含Java又包含C#的文档:
db.sang_collect.find({$text:{$search:"\"Java C#\""}})- 用一对双引号将查询条件括起来
- 查询包含PHP或者Python的文档:
db.sang_collect.find({$text:{$search:"PHP Python"}}) - 查询既有PHP,又有Python,又不包括Java的文档:
db.sang_collect.find({$text:{$search:"PHP Python -Java"}}) - 建立了全文索引之后,我们也可以查看查询结果的相似度,使用$meta:
db.sang_collect.find({$text:{$search:"PHP Python"}},{score:{$meta:"textScore"}})- 查询结果中会多出一个
score字段,该字段的值越大,表示相似度越高, - 根据score利用sort来对其进行排序:
db.sang_collect.find({$text:{$search:"PHP Python"}},{score:{$meta:"textScore"}}).sort({score:{$meta:"textScore"}})
地理空间索引
2d 索引:可以用来存储和查找平面上的点,一般我们可以用在游戏地图中。
-
向集合中插入一条记录点的数据:
db.sang_collect.insert({x:[90,0]})- 插入数据的格式为
[经度,纬度],取值范围,经度[-180,180],纬度[-90,90]。
- 插入数据的格式为
-
数据插入成功之后,通过如下命令创建索引:
db.sang_collect.ensureIndex({x:"2d"})
-
然后通过
$near查询某一个点附近的点,如下:db.sang_collect.find({x:{$near:[90,0]}})- 默认情况下返回该点附近100个点,可以通过
$maxDistance来设置返回的最远距离db.sang_collect.find({x:{$near:[90,0],$maxDistance:99}})
-
通过
$geoWithin查询某个形状内的点,如查询矩形中的点:
-db.sang_collect.find({x:{$geoWithin:{$box:[[0,0],[91,1]]}}})
- 两个坐标点用来确定矩形的位置。 -
查询圆中的点:
db.sang_collect.find({x:{$geoWithin:{$center:[[0,0],90]}}})- 参数分别表示圆的圆心和半径。
-
查询多边形中的点:
db.sang_collect.find({x:{$geoWithin:{$polygon:[[0,0],[100,0],[100,1],[0,1]]}}})- 这里可以填入任意多个点,表示多边形中的各个点。
2d sphere 索引:适用于球面类型的地图
- 它的数据类型是
GeoJSON格式的,我们可以在http://geojson.org/地址上查看GeoJSON格式的样式- 描述一个点,
GeoJSON如下:{ "_id" : ObjectId("59f5e0571f9e8e181ffc3196"), "name" : "shenzhen", "location" : { "type" : "Point", "coordinates" : [ 90.0, 0.0 ] } } - 描述线,
GeoJSON格式如下:{ "_id" : ObjectId("59f5e0d01f9e8e181ffc3199"), "name" : "shenzhen", "location" : { "type" : "LineString", "coordinates" : [ [ 90.0, 0.0 ], [ 90.0, 1.0 ], [ 90.0, 2.0 ] ] } } - 描述多边形,
GeoJSON格式如下:{ "_id" : ObjectId("59f5e3f91f9e8e181ffc31d0"), "name" : "beijing", "location" : { "type" : "Polygon", "coordinates" : [ [ [ 0.0, 1.0 ], [ 0.0, 2.0 ], [ 1.0, 2.0 ], [ 0.0, 1.0 ] ] ] } }
- 描述一个点,
- 存在上述数据后,可以通过如下操作来创建地理空间索引了:
db.sang_collect.ensureIndex({location:"2dsphere"})
- 查询和深圳这个区域有交集的文档,如下:
var shenzhen = db.sang_collect.findOne({name:"shenzhen"})db.sang_collect.find({location:{$geoIntersects:{$geometry:shenzhen.location}}})- 查询结果是和深圳这个区域有交集的都会查到(比如经过深圳的高速公路、铁路等),
- 查询深圳市内的区域(比如深圳市内所有的学校)
var shenzhen = db.sang_collect.findOne({name:"shenzhen"})db.sang_collect.find({location:{$within:{$geometry:shenzhen.location}}})
- 查询腾讯附近的其他位置
var QQ = db.sang_collect.findOne({name:"QQ"})db.sang_collect.find({location:{$near:{$geometry:QQ.location}}})
复合地理空间索引
- 位置往往只是查询的一个条件
- 查询深圳市内所有的学校,再增加一个查询条件,如下:
var shenzhen = db.sang_collect.findOne({name:"shenzhen"})db.sang_collect.find({location:{$within:{$geometry:shenzhen.location}},name:"QQ"})
其他的查询条件跟在后面就行了。
总结
- 索引可以有效的提高查询速度,但是索引会降低插入、更新和删除的速度,因为这些操作不仅要更新文档,还要更新索引,
- MongoDB 限制每个集合上最多有64个索引,我们在创建索引时要仔细斟酌索引的字段。
六、Java操作
原生Java操作MongoDB
- maven管理
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.12.12</version>
</dependency>
- 自行下载:需要下载如下jar包
org.mongodb:bson:jarorg.mongodb:mongodb-driver-core:jarorg.mongodb:mongodb-driver:jar
1.连接到MongoDB服务器获取指定数据库并获取到一个集合
/**
* 获取连接,无需密码
*/
public MongoCollection<Document> getMongoConnectionByAddress() {
// 连接到 mongodb 服务
try (MongoClient mongoClient = new MongoClient("localhost", 27017)) {
// 连接到 test 数据库
MongoDatabase mongoDatabase = mongoClient.getDatabase("test");
System.out.println("Connect to database successfully");
//获取一个集合连接并返回
return mongoDatabase.getCollection("user");
} catch (Exception e) {
System.err.println(e.getClass().getName() + ": " + e.getMessage());
throw e;
}
}
/**
* 获取连接,需密码
*/
public MongoCollection<Document> getMongoConnectionByUser() {
//连接到MongoDB服务,ServerAddress()两个参数分别为 服务器地址 和 端口
ServerAddress serverAddress = new ServerAddress("localhost", 27017);
//MongoCredential.createCredential()三个参数分别为 用户名 数据库名称 密码
MongoCredential mongoCredential = MongoCredential.createCredential("username", "test", "password".toCharArray());
//连接选项
MongoClientOptions mongoClientOptions = MongoClientOptions.builder().build();
try (MongoClient mongoClient = new MongoClient(serverAddress, mongoCredential, mongoClientOptions)) {
// 连接到 test 数据库
MongoDatabase mongoDatabase = mongoClient.getDatabase("test");
System.out.println("Connect to database successfully");
//获取一个集合连接并返回
return mongoDatabase.getCollection("user");
} catch (Exception e) {
System.err.println(e.getClass().getName() + ": " + e.getMessage());
throw e;
}
}
2. CRUD-示例
2.1. 新增/插入
//1 单条插入
Document userInfo = new Document();
userInfo.append("uname", "张三").append("age", 19).append("sex", "男");
user.insertOne(userInfo);
//2 批量插入
List<Document> collections = new ArrayList<>();
Document userInfo1 = new Document();
userInfo1.append("uname", "李四").append("age", 15).append("sex", "男");
collections.add(userInfo1);
Document userInfo2 = new Document();
userInfo2.append("uname", "王刚").append("age", 20).append("sex", "女");
collections.add(userInfo2);
user.insertMany(collections);
2.2. 修改/更新
//条件
Bson eq = Filters.eq("uname", "张三");
//修改器与新内容
Document document = new Document("$set", new Document("age", 10));
//更新匹配的一个文档
documentCollection.updateOne(eq, document);
//更新匹配的所有文档
documentCollection.updateMany(eq, document);
2.3. 删除
//条件
Bson eq = Filters.eq("uname", "张三");
//删除匹配的一个文档
documentCollection.deleteOne(eq);
//删除匹配的所有文档
documentCollection.deleteMany(eq);
2.4. 查询
//查询所有文档
System.out.println("----查询所有文档~开始----");
FindIterable<Document> documentsAll = documentCollection.find();
for (Document document : documentsAll) {
System.out.println(document);
}
System.out.println("----查询所有文档~结束----");
//按照条件查询
System.out.println("----按照条件查询~开始----");
//条件
Bson eq = Filters.eq("uname", "张三");
FindIterable<Document> documents = documentCollection.find(eq);
for (Document document : documents) {
System.out.println(document);
}
System.out.println("----按照条件查询~结束----");
SpringBoot操作MongoDB
配置
- maven
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
- application.yml配置文件
spring:
data:
mongodb:
#数据库服务器地址
host: localhost
#MongoDB默认端口
port: 27017
#选择 数据库:test
database: test
创建实体类
//标识是那个文档集合
@Document(collection = "user")
public class User {
//标识主键id
@Id
private String id;
private String uname;
private int age;
private String sex;
}
创建Repository
- 主要继承MongoRepository
public interface UserRepository extends MongoRepository<User, String> {
}
创建service
- 定义
public interface UserService {
/**
* 新增
* @return String
*/
String create();
/**
* 更新
* @return String
*/
String update();
/**
* 删除
* @return String
*/
String delete();
/**
* 查询
* @return String
*/
List<User> select();
}
- 实现
@Slf4j
@Service
public class UserServiceImpl implements UserService {
@Resource
private UserRepository userRepository;
@Resource
private MongoTemplate mongoTemplate;
/**
* 新增
*
* @return String
*/
@Override
public String create() {
//第一种方式,直接继承xxxRepository接口
User user = User.builder().uname("张三").age(18).build();
userRepository.save(user);
log.info("第一种方式新增成功,user:" + user);
//第二种方式,直接使用xxxTemplate
//注意:id不能重复。MongoWriteException: E11000 duplicate key error collection: mongo.user index: _id_ dup key: { _id: "3" }
User user2 = User.builder().uname("李四").age(18).build();
mongoTemplate.insert(user2);
log.info("第二种方式新增成功,user:" + user2);
log.info("【人员接口】新增成功");
return "新增成功";
}
/**
* 更新
*
* @return String
*/
@Override
public String update() {
//第一种方式,直接继承xxxRepository接口
User user = User.builder().uname("张更新").age(18).build();
userRepository.save(user);
//第二种方式,直接使用xxxTemplate
Query query = Query.query(Criteria.where("id").is("2").and("uname").is("王小二"));
Update update = Update.update("uname", "王更新");
mongoTemplate.updateFirst(query, update, User.class);
log.info("【人员接口】更新成功");
return "更新成功";
}
/**
* 删除
*
* @return String
*/
@Override
public String delete() {
//第一种方式,直接继承xxxRepository接口
userRepository.deleteById("1");
//第二种方式,直接使用xxxTemplate
Query query = Query.query(Criteria.where("id").is("2"));
mongoTemplate.remove(query, User.class);
log.info("【人员接口】删除成功");
return "删除成功";
}
/**
* 查询
*
* @return String
*/
@Override
public List<User> select() {
//第一种方式,直接继承xxxRepository接口
List<User> userList = userRepository.findAll();
System.out.println("第一种方式,userList:" + userList);
//第二种方式,直接使用xxxTemplate
List<User> userLists = this.mongoTemplate.findAll(User.class);
System.out.println("第二种方式,userList:" + userLists);
log.info("【人员接口】查询成功");
return userLists;
}
}
七、MapReduce (分布式计算)
MongoDB 中的 MapReduce 可以用来实现更复杂的聚合命令,使用 MapReduce 主要实现两个函数(map,reduce)
map函数:生成键值对序列- map 函数的结果作为 reduce 函数的参数
reduce函数:reduce函数中再做进一步的统计
示例:
- 数据如下:
{"_id" : ObjectId("59fa71d71fd59c3b2cd908d7"),"name" : "鲁迅","book" : "呐喊","price" : 38.0,"publisher" : "人民文学出版社"}
{"_id" : ObjectId("59fa71d71fd59c3b2cd908d8"),"name" : "曹雪芹","book" : "红楼梦","price" : 22.0,"publisher" : "人民文学出版社"}
{"_id" : ObjectId("59fa71d71fd59c3b2cd908d9"),"name" : "钱钟书","book" : "宋诗选注","price" : 99.0,"publisher" : "人民文学出版社"}
{"_id" : ObjectId("59fa71d71fd59c3b2cd908da"),"name" : "钱钟书","book" : "谈艺录","price" : 66.0,"publisher" : "三联书店"}
{"_id" : ObjectId("59fa71d71fd59c3b2cd908db"),"name" : "鲁迅","book" : "彷徨","price" : 55.0,"publisher" : "花城出版社"}
- 查询每位作者所出的书的总价,操作如下:
var map=function(){emit(this.name,this.price)}
var reduce=function(key,value){return Array.sum(value)}
var options={out:"totalPrice"}
db.sang_books.mapReduce(map,reduce,options);
db.totalPrice.find()
- emit 函数用于生成 key-value 数据集合
- 语法:
emit(key, value) / emit(key, {v1:v1, v2:v2}) - 第一个参数是key, 第二个参数是key对应的数据集合
- 语法:
- emit 函数主要实现的分组,接收两个参数,第一个参数表示分组的分段,第二个参数表示要统计的数据,减少做特定的数据处理操作,接收两个参数,对应的 emit 方法的两个参数,此处使用了 Array 中的sum 对 price 分段进行自加处理,options 中定义了将结果输出的集合,届时我们将在此集合中去查询数据,很少情况下,这个集合即使在数据库重启后也会保留,并保留集合中的数据。
- 查询结果如下:
{ "_id" : "曹雪芹", "value" : 22.0 } { "_id" : "钱钟书", "value" : 165.0 } { "_id" : "鲁迅", "value" : 93.0 } - 查询每位作者出了几本书,如下:
var map=function(){emit(this.name,1)} var reduce=function(key,value){return Array.sum(value)} var options={out:"bookNum"} db.sang_books.mapReduce(map,reduce,options); db.bookNum.find() - 查询结果如下:
{ "_id" : "曹雪芹", "value" : 1.0 } { "_id" : "钱钟书", "value" : 2.0 } { "_id" : "鲁迅", "value" : 2.0 } - 将每位作者的书列出来,如下:
var map=function(){emit(this.name,this.book)} var reduce=function(key,value){return value.join(',')} var options={out:"books"} db.sang_books.mapReduce(map,reduce,options); db.books.find() - 结果如下:
{ "_id" : "曹雪芹", "value" : "红楼梦" } { "_id" : "钱钟书", "value" : "宋诗选注,谈艺录" } { "_id" : "鲁迅", "value" : "呐喊,彷徨" } - 查询每个人价格在¥ 40以上的书:
var map=function(){emit(this.name,this.book)} var reduce=function(key,value){return value.join(',')} var options={query:{price:{$gt:40}},out:"books"} db.sang_books.mapReduce(map,reduce,options); db.books.find() - 查询表示对查到的集合再进行筛选。
- 结果如下:
{ "_id" : "钱钟书", "value" : "宋诗选注,谈艺录" } { "_id" : "鲁迅", "value" : "彷徨" }
runCommand 实现
我们也可以利用 runCommand 命令来执行 MapReduce。格式如下:
db.runCommand(
{
mapReduce: <collection>,
map: <function>,
reduce: <function>,
finalize: <function>,
out: <output>,
query: <document>,
sort: <document>,
limit: <number>,
scope: <document>,
jsMode: <boolean>,
verbose: <boolean>,
bypassDocumentValidation: <boolean>,
collation: <document>
}
)
含义如下:
| 参数 | 解释 |
|---|---|
| mapReduce | 表示要操作的集合 |
| map | map函数 |
| reduce | reduce函数 |
| finalize | 最终处理函数 |
| out | 输出的集合 |
| query | 对结果进行过滤 |
| sort | 对结果排序 |
| limit | 返回的结果数 |
| scope | 设置参数值,在这里设置的值在map,reduce,finalize函数中可见 |
| jsMode | 是否将地图执行的中间数据由javascript对象转换成BSON对象,替换为false |
| verbose | 是否显示详细的时间统计信息 |
| bypassDocumentValidation | 是否绕过文档验证 |
| collation | 其他一些校对 |
如下操作,表示执行MapReduce操作重新统计的集合限制返回条数,限制返回条数之后再进行统计操作,如下:
var map=function(){emit(this.name,this.book)}
var reduce=function(key,value){return value.join(',')}
db.runCommand({mapreduce:'sang_books',map,reduce,out:"books",limit:4,verbose:true})
db.books.find()
执行结果如下:
{
"_id" : "曹雪芹",
"value" : "红楼梦"
}
{
"_id" : "钱钟书",
"value" : "宋诗选注,谈艺录"
}
{
"_id" : "鲁迅",
"value" : "呐喊"
}
可以看到,鲁迅在一本书不见了,就是因为limit是先限制集合返回条数,然后再执行统计操作。
finalize 操作表示最终处理函数,如下:
var f1 = function(key,reduceValue){var obj={};obj.author=key;obj.books=reduceValue; return obj}
var map=function(){emit(this.name,this.book)}
var reduce=function(key,value){return value.join(',')}
db.runCommand({mapreduce:'sang_books',map,reduce,out:"books",finalize:f1})
db.books.find()
f1 第一个参数键表示emit中的第一个参数,第二个参数表示reduce的执行结果,我们可以在f1中对这个结果进行再处理
结果如下:
{
"_id" : "曹雪芹",
"value" : {
"author" : "曹雪芹",
"books" : "红楼梦"
}
}
{
"_id" : "钱钟书",
"value" : {
"author" : "钱钟书",
"books" : "宋诗选注,谈艺录"
}
}
{
"_id" : "鲁迅",
"value" : {
"author" : "鲁迅",
"books" : "呐喊,彷徨"
}
}
scope则可以用来定义一个在reduce和finalize中都可见的变量,如下:
var f1 = function(key,reduceValue){var obj={};obj.author=key;obj.books=reduceValue;obj.sang=sang; return obj}
var map=function(){emit(this.name,this.book)}
var reduce=function(key,value){return value.join(',--'+sang+'--,')}
db.runCommand({mapreduce:'sang_books',map,reduce,out:"books",finalize:f1,scope:{sang:"haha"}})
db.books.find()
执行结果如下:
{
"_id" : "曹雪芹",
"value" : {
"author" : "曹雪芹",
"books" : "红楼梦",
"sang" : "haha"
}
}
{
"_id" : "钱钟书",
"value" : {
"author" : "钱钟书",
"books" : "宋诗选注,--haha--,谈艺录",
"sang" : "haha"
}
}
其他
- MongoDB副本集
- MongoDB分片















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











