







一 为什么要使用索引
如果不使用索引查找速度太慢,例如查找年龄之类的数据需要从头到尾一个个比对,如果使用索引
二 使用的什么数据机构
使用的是B+tree的数据结构
三 为什么使用B+tree不用二叉数或者时哈希索引
因为二叉数有两个缺点
1 在顺序插入时会形成一个单向链表,从而导致查询效率变低
2 在数据量大的情况下由于二叉树一个节点只有两个分支,会导致层级变高从而导致查询效率变低这也是不使用红黑树的原因,红黑树的本质也是二叉树,只不过是自平衡二叉树,同样存在数据量大的情况下层级太高从而导致查询效率变低
而哈希索引结构虽然不存在二叉树的这种问题,但是哈希索引由于哈希值和数据是对应的,再查找时先查找哈希索引的值再查找到数据,这就导致它只能进行精确查找不能进行范围查找
先说说B树,b树呢就是多路平衡查找树,它对分支的多少是没有要求的,它的一个节点存放着数据和指针,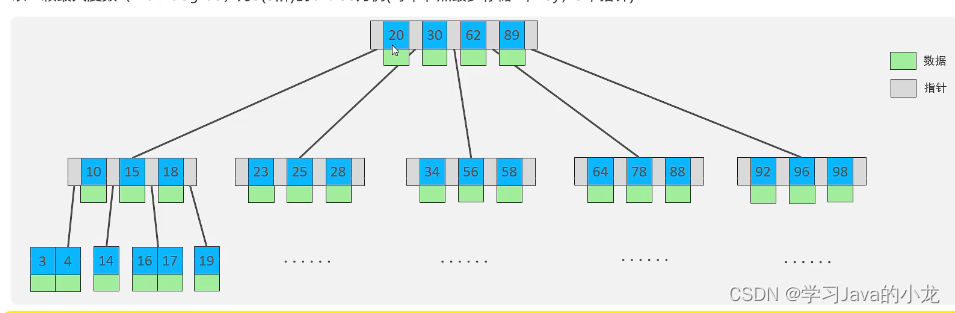
它的排序顺序是这样的,假定是5阶的B树就代表可以存放5个指针4个数据,它先将4个数据从小到大排序,当插入第五个数据时,会把五个数据中排到中间的那个数据向上移动成为新的节点,剩下的四个数据会从中间断开成为两个新的节点,新节点的两个指针分别指向他们。
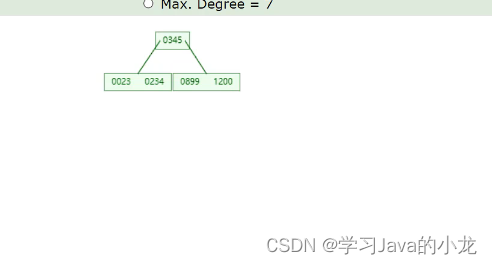
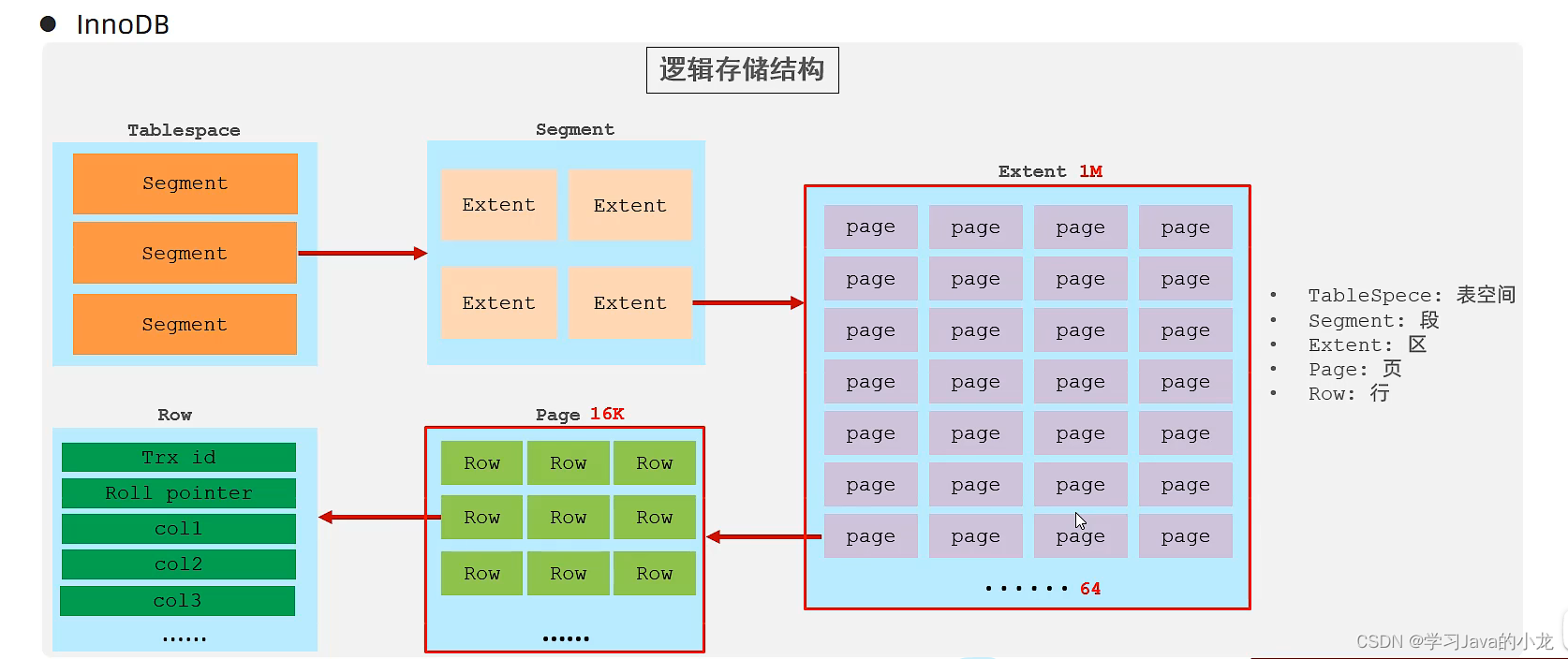
但是由于Innodb引擎中的表都对应着一个表空间文件,而B树中的所有数据指针都是存放在页当中
但是由于页的大小规定时16k所以出现了B+树
B+树在B树的基础上将数据都放在了叶子节点上,非叶子节点上只存放指针,而叶子节点之间又增加了一个指针指向相邻的节点
B+树是怎么形成的呢?
如上个例子,当需要向上移动的形成新节点的数据会在原位置保存一个相同的数据同时会把原有数据正常向上移动形成新节点,原节点会从新数据处断开形成两个新的节点而在mysql又在B+树的基础在叶子节点处增加了一个新的指针指向相邻节点形成一个循环链表。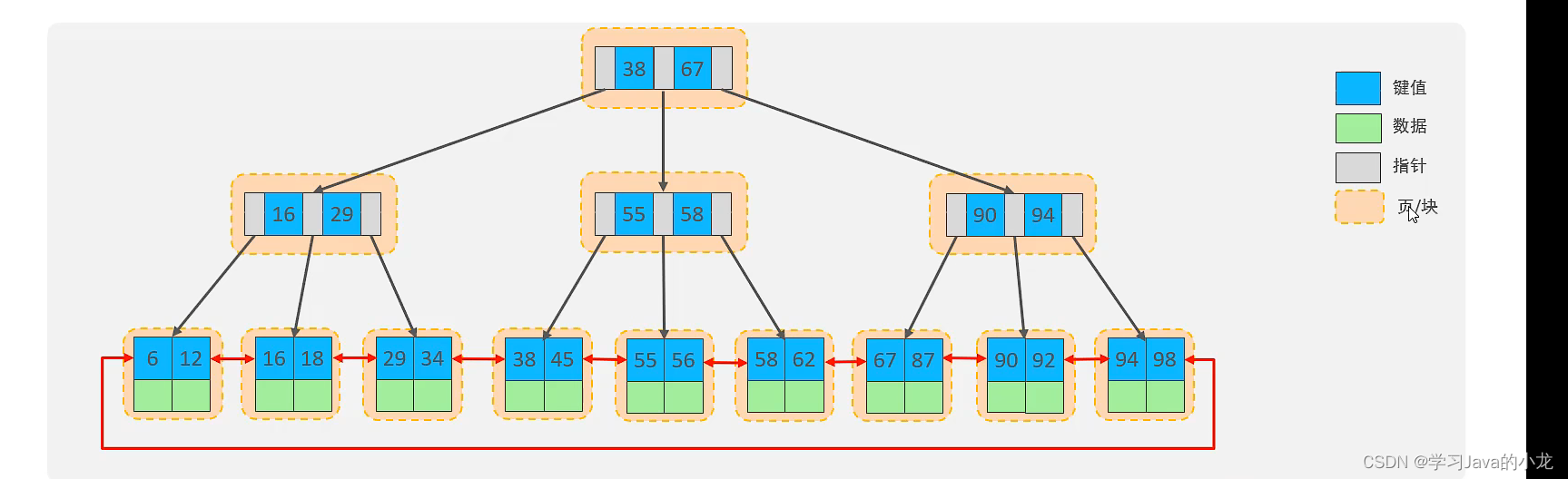















 4051
4051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









