






#导入数据
import pandas as pd
data = pd.read_csv('D:/QQ文件夹/金发科技数据十年.csv')
data.head()
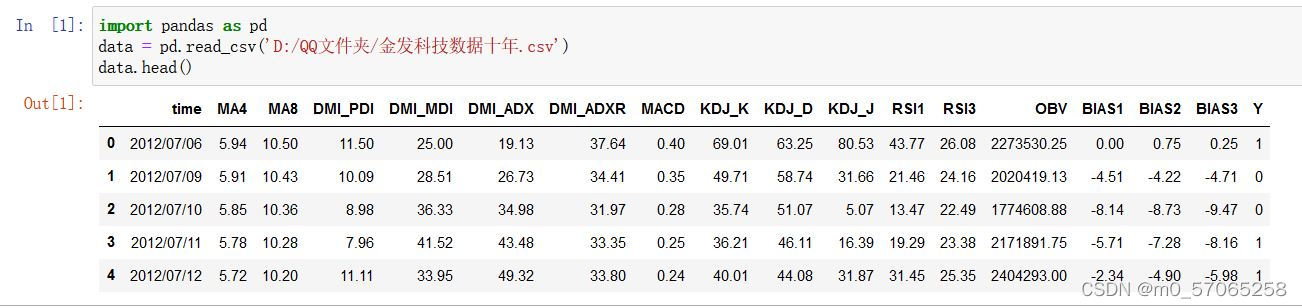
#绘制自相关系数图
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
plt.figure(figsize=(20, 20)) # 指定绘图对象宽度和高度
colnm = data.columns.tolist() # 列表头
mcorr = data[colnm].corr(method="spearman") # 相关系数矩阵,即给出了任意两个变量之间的相关系数
mask = np.zeros_like(mcorr, dtype=np.bool) # 构造与mcorr同维数矩阵 为bool型
mask[np.triu_indices_from(mask)] = True # 角分线右侧为True
#cmap = sns.diverging_palette(220, 10, as_cmap=True) # 返回matplotlib colormap对象
g = sns.heatmap(mcorr, mask=mask, square=True, annot=True, fmt='0.5f') # 热力图(看两两相似度)
plt.show()
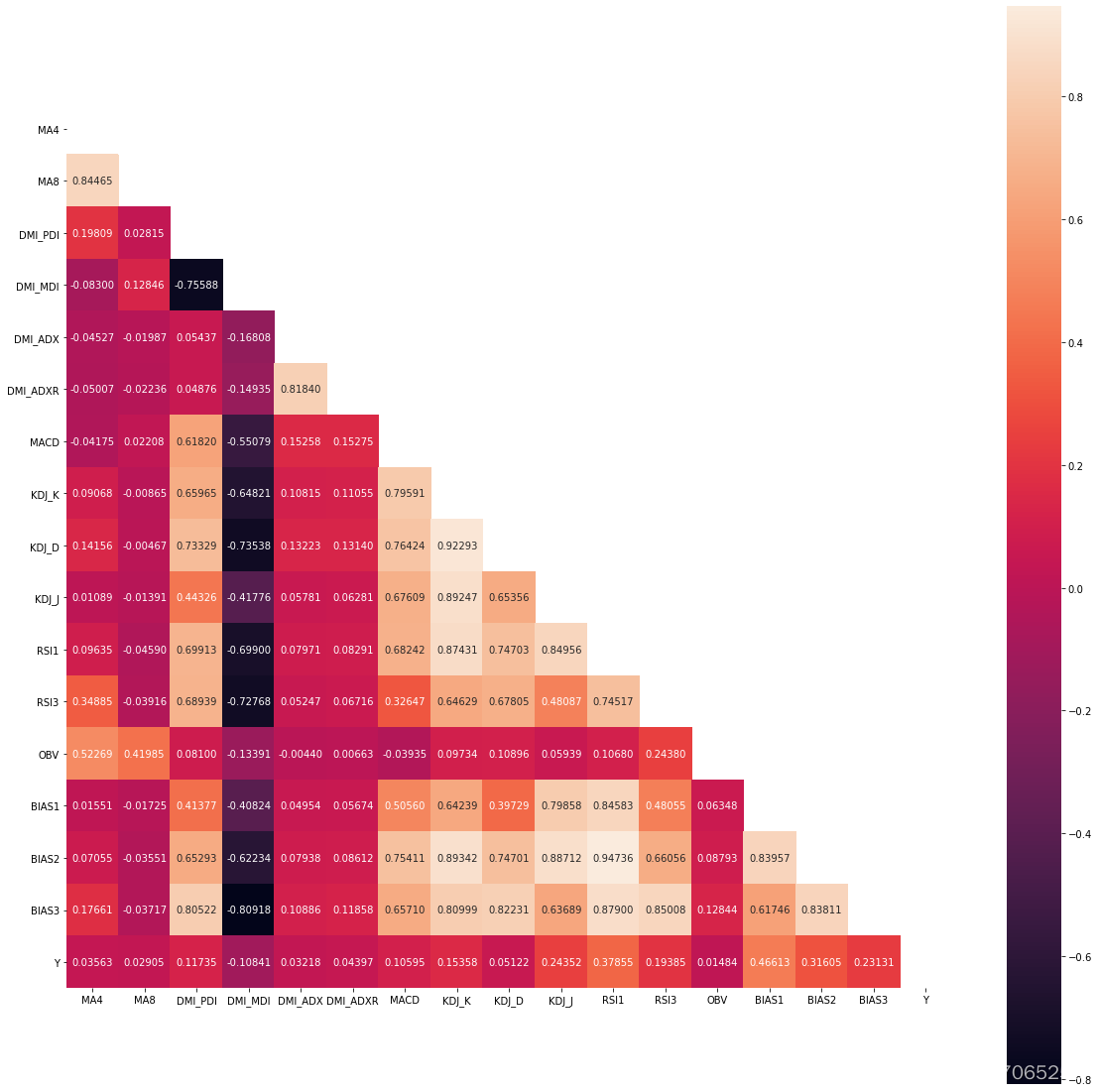
#剔除相关系数过高的几个属性,没有用主成分分析剔除属性是因为后续准确率不高
data = data.drop(['BIAS2','MA8','KDJ_K','BIAS3'],axis=1)
data
#检测缺失值
data.isnull().sum()
#建立属性变量X和类别y
from sklearn.tree import DecisionTreeClassifier
X=data.iloc[:,1:13]
print(X)
y=data['Y']
y.value_counts()#上涨天数1031天,下跌或不变天数1076天
#数据标准化处理,消除量纲,每个数据减去均值再除以标准差
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X)
X=scaler.transform(X)
X.shape
#分配训练集与测试集
from sklearn import tree
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
train_x,test_x,train_y,test_y= train_test_split(X,y,test_size=0.1,train_size=0.9)
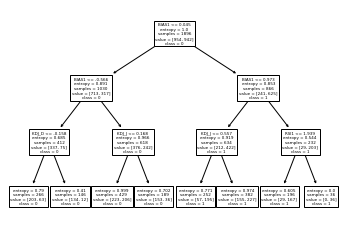
#用信息增益法划分决策树
tree_modela=DecisionTreeClassifier(criterion='entropy',max_depth=3)
tree_modela.fit(train_x,train_y)
tree.plot_tree(tree_modela,feature_names=name,class_names='01')
plt.show()
#深度改为4,检测分类效果
tree_modeld=DecisionTreeClassifier(max_depth=4)
tree_modeld.fit(train_x,train_y)
tree.plot_tree(tree_modeld,feature_names=name,class_names='01')
plt.show()
tree_modele=DecisionTreeClassifier(criterion='entropy',max_depth=4)
tree_modele.fit(train_x,train_y)
tree.plot_tree(tree_modele,feature_names=name,class_names='01')
plt.show()
#深度为4时分类效果逊于深度为3,可能出现了过拟合现象,通过设置最小叶节点数量为13减少过拟合
tree_modelb=DecisionTreeClassifier(criterion='entropy',max_leaf_nodes=13)
tree_modelb.fit(train_x,train_y)
tree.plot_tree(tree_modelb,feature_names=name,class_names='01')
plt.show()
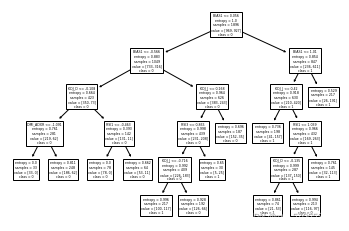

采用准确率得到的准确率为0.7096,采用F1度量得到的准确率为0.7105
#SVC支持向量机法分类
from sklearn import svm
clf=svm.SVC()
clf.fit(train_x,train_y)
result=clf.predict(test_x)
print(result)
#逻辑回归模型
from sklearn.linear_model import LogisticRegression as LR
lr=LR()
lr.fit(train_x,train_y)
result=clf.predict(test_x)
sc=clf.score(train_x, train_y)
#神经网络模型
from sklearn.neural_network import MLPClassifier
wl=MLPClassifier(solver='lbfgs',alpha=1e-5,hidden_layer_sizes=8,random_state=1)
wl.fit(train_x,train_y)
result=wl.predict(test_x)
sc=wl.score(train_x,train_y)
#K近邻算法 p=1代表用曼哈顿距离度量
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier(n_neighbors=30,weights='uniform', algorithm='auto', leaf_size=30,p=1, metric='minkowski', metric_params=None, n_jobs=1)
knn.fit(train_x, train_y)
#p=2用欧氏距离度量
knn1 = neighbors.KNeighborsClassifier(n_neighbors=30,weights='uniform', algorithm='auto', leaf_size=30,p=2, metric='minkowski', metric_params=None, n_jobs=1)
knn1.fit(train_x, train_y)
#多划分几次训练集和测试集
train_x,test_x,train_y,test_y= train_test_split(X,y,test_size=0.2,train_size=0.8)
train_x,test_x,train_y,test_y= train_test_split(X,y,test_size=0.3,train_size=0.7)
#评价模型
import sklearn.metrics as metrics
result_modela=metrics.classification_report(test_y,tree_modela.predict(test_x))
print(result_modela)
注:一是时间序列预测不能使用十折交叉验证,因为不能用未来的信息预测过去的信息,二是要按不同比例多划分几次训练集和测试集测试模型的准确率。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









