






第一章 NIO基础
1.三大组件
1.1 Channel & Buffer
channel 有一点类似于 stream,它就是读写数据的双向通道,可以从 channel 将数据读入 buffer,也可以将 buffer 的数据写入 channel,而之前的 stream 要么是输入,要么是输出,channel 比 stream 更为底层

常见的 Channel 有:
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
Buffer 则用来缓冲读写数据,常见的 Buffer 有:
- ByteBuffer
- MappedByteBuffer
- DirectByteBuffer
- HeapByteBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- CharBuffer
1.2 Selector
selector 单从字面意思不好理解,需要结合服务器的设计演化来理解它的用途
-
多线程版本设计
为每个连接分别开辟一个线程,分别去处理对应的socke连接
多线程版缺点:
- 内存占用高 - 每个线程都需要占用一定的内存,当连接较多时,会开辟大量线程,导致占用大量内存
- 线程上下文切换成本高
- 只适合连接数少的场景 - 连接数过多,会导致创建很多线程,从而出现问题

-
线程池版设计
使用线程池,让线程池中的线程去处理连接
线程池版缺点:
- 阻塞模式下,线程仅能处理一个 socket 连接
- 线程池中的线程获取任务(task)后,只有当其执行完任务之后(断开连接后),才会去获取并执行下一个任务
- 若 socke 连接一直未断开,则其对应的线程无法处理其他 socke 连接
- 仅适合短连接场景
- 短连接即建立连接发送请求并响应后就立即断开,使得线程池中的线程可以快速处理其他连接
- 阻塞模式下,线程仅能处理一个 socket 连接

-
selector 版设计
selector 的作用就是配合一个线程来管理多个 channel(fileChannel因为是阻塞式的,所以无法使用selector),获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,当一个channel中没有执行任务时,可以去执行其他channel中的任务。适合连接数多,但流量较少的场景

调用 selector 的 select() 会阻塞直到 channel 发生了读写就绪事件,这些事件发生,select 方法就会返回这些事件交给 thread 来处理
2.ByteBuffer
ByteBuffer提供了字节缓冲区,其可以不断的从Channel中读取接收到的数据。Buffer的优点主要在于其提供了一系列的Api,能够让用户更方便的对数据进行读取和写入
2.1 ByteBuffer 结构
ByteBuffer 有以下重要属性:
- capacity:缓冲区的容量。通过构造函数赋予,一旦设置,无法更改
- position:缓冲区的界限。位于limit 后的数据不可读写。缓冲区的限制不能为负,并且不能大于其容量
- limit:下一个读写位置的索引。缓冲区的位置不能为负,并且不能大于limit
- mark:记录当前position的值。position被改变后,可以通过调用reset() 方法恢复到mark的位置
以上四个属性必须满足以下要求:mark <= position <= limit <= capacity
运行过程:
-
定义10个容量后的初始状态
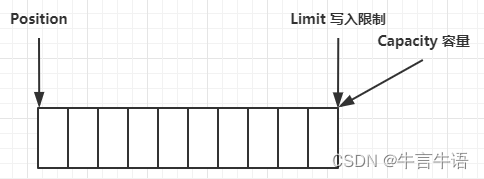
-
写模式下,position 是写入位置,limit 等于容量
写入了 4 个字节后的状态
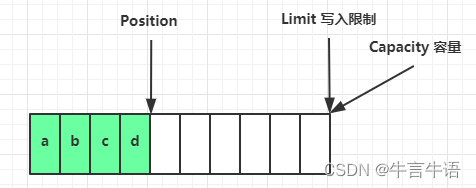
-
flip 动作发生后,position 切换为读取位置,limit 切换为读取限制
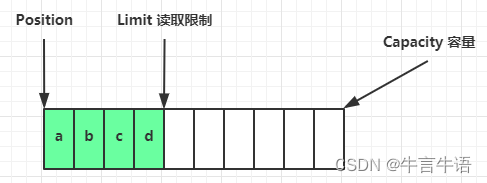
读取 4 个字节后的状态
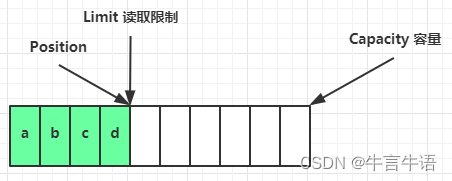
-
clear() 方法发生后
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dxwqLnPu-1674881150995)(./Netty.assets/image-20221228201227979.png)]](https://img-blog.csdnimg.cn/8f62e62a68534833af3e522001ca21a7.png)
-
compact() 方法,是把未读完的部分向前压缩,然后切换至写模式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rrShLpsf-1674881150996)(./Netty.assets/image-20221228201240970.png)]](https://img-blog.csdnimg.cn/fbf2e963440d4ccb8fa371e99554d533.png)
2.2 快速使用
-
项目结构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XTHlAgFG-1674881150996)(./Netty.assets/image-20221227221134427.png)]](https://img-blog.csdnimg.cn/e040253357e94112b92a10dc938d4a20.png)
-
创建文本文件 data.txt,内容为
1234567890abcd -
引入日志Maven依赖
<dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.16.18</version> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.2.9</version> </dependency> -
logback配置文件
<?xml version="1.0" encoding="UTF-8"?> <!-- 从高到到低 OFF 、 FATAL > ERROR > WARN > INFO > DEBUG > TRACE > ALL 如果设置为 WARN ,则低于 WARN的信息都不会输出 --> <!-- 日志输出规则 根据当前ROOT级别,日志输出时,级别高于root默认的级别时 会输出 --> <configuration xmlns="http://ch.qos.logback/xml/ns/logback" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://ch.qos.logback/xml/ns/logback logback.xsd"> <!-- 输出控制,格式控制--> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <!-- %date 日期 [%-5p] %p当前级别|-5靠左对其 最多输出5个字符 [%thread] 当前线程 %logger{60} 日志的消息 [%file : %line] 哪个文件哪一行 %msg%n 消息内容 和 换行 --> <encoder> <pattern>%date{HH:mm:ss} [%-5level] [%thread] %logger{17} - %m%n </pattern> </encoder> </appender> <!-- 用来控制查看那个类的日志内容(对mybatis name 代表命名空间) --> <!--单独指定某个包 进行日志输出--> <logger name="org.example" level="DEBUG" additivity="false"> <!--additivity =【true:反馈到<root 里面打印或者写出日志,false:不反馈】--> <appender-ref ref="STDOUT"/> </logger> <root level="ERROR"> <appender-ref ref="STDOUT"/> </root> </configuration> -
使用 FileChannel 来读取文件内容
@Slf4j public class ByteBufferTest { public static void main(String[] args) { //输入流 try (FileChannel channel = new FileInputStream("data.txt").getChannel()) { //准备buffer缓冲区 ByteBuffer buffer = ByteBuffer.allocate(10); while (true) { //当缓冲区大小小于文件大小时,需要多次读入 //从channel读取数据,向buffer写入 int len = channel.read(buffer); if (len == -1) break; //打印buffer的内容 buffer.flip(); //转换成读模式 while (buffer.hasRemaining()) { log.info("实际字节 {}", (char) buffer.get()); } buffer.clear(); //转换成写模式 } } catch (IOException e) { e.printStackTrace(); } } } -
输出
21:25:23.051 [main] INFO org.example.ByteBufferTest - 实际字节 1 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 2 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 3 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 4 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 5 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 6 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 7 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 8 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 9 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 0 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 a 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 b 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 c 21:25:23.055 [main] INFO org.example.ByteBufferTest - 实际字节 d
2.3 常用方法
0.准备工作
为方便输出,引入工具类
import static io.netty.util.internal.MathUtil.isOutOfBounds;
import static io.netty.util.internal.StringUtil.NEWLINE;
public class ByteBufferUtil {
private static final char[] BYTE2CHAR = new char[256];
private static final char[] HEXDUMP_TABLE = new char[256 * 4];
private static final String[] HEXPADDING = new String[16];
private static final String[] HEXDUMP_ROWPREFIXES = new String[65536 >>> 4];
private static final String[] BYTE2HEX = new String[256];
private static final String[] BYTEPADDING = new String[16];
static {
final char[] DIGITS = "0123456789abcdef".toCharArray();
for (int i = 0; i < 256; i++) {
HEXDUMP_TABLE[i << 1] = DIGITS[i >>> 4 & 0x0F];
HEXDUMP_TABLE[(i << 1) + 1] = DIGITS[i & 0x0F];
}
int i;
// Generate the lookup table for hex dump paddings
for (i = 0; i < HEXPADDING.length; i++) {
int padding = HEXPADDING.length - i;
StringBuilder buf = new StringBuilder(padding * 3);
for (int j = 0; j < padding; j++) {
buf.append(" ");
}
HEXPADDING[i] = buf.toString();
}
// Generate the lookup table for the start-offset header in each row (up to 64KiB).
for (i = 0; i < HEXDUMP_ROWPREFIXES.length; i++) {
StringBuilder buf = new StringBuilder(12);
buf.append(NEWLINE);
buf.append(Long.toHexString(i << 4 & 0xFFFFFFFFL | 0x100000000L));
buf.setCharAt(buf.length() - 9, '|');
buf.append('|');
HEXDUMP_ROWPREFIXES[i] = buf.toString();
}
// Generate the lookup table for byte-to-hex-dump conversion
for (i = 0; i < BYTE2HEX.length; i++) {
BYTE2HEX[i] = ' ' + StringUtil.byteToHexStringPadded(i);
}
// Generate the lookup table for byte dump paddings
for (i = 0; i < BYTEPADDING.length; i++) {
int padding = BYTEPADDING.length - i;
StringBuilder buf = new StringBuilder(padding);
for (int j = 0; j < padding; j++) {
buf.append(' ');
}
BYTEPADDING[i] = buf.toString();
}
// Generate the lookup table for byte-to-char conversion
for (i = 0; i < BYTE2CHAR.length; i++) {
if (i <= 0x1f || i >= 0x7f) {
BYTE2CHAR[i] = '.';
} else {
BYTE2CHAR[i] = (char) i;
}
}
}
/**
* 打印所有内容
*
* @param buffer
*/
public static void debugAll(ByteBuffer buffer) {
int oldlimit = buffer.limit();
buffer.limit(buffer.capacity());
StringBuilder origin = new StringBuilder(256);
appendPrettyHexDump(origin, buffer, 0, buffer.capacity());
System.out.println("+--------+-------------------- all ------------------------+----------------+");
System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), oldlimit);
System.out.println(origin);
buffer.limit(oldlimit);
}
/**
* 打印可读取内容
*
* @param buffer
*/
public static void debugRead(ByteBuffer buffer) {
StringBuilder builder = new StringBuilder(256);
appendPrettyHexDump(builder, buffer, buffer.position(), buffer.limit() - buffer.position());
System.out.println("+--------+-------------------- read -----------------------+----------------+");
System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), buffer.limit());
System.out.println(builder);
}
private static void appendPrettyHexDump(StringBuilder dump, ByteBuffer buf, int offset, int length) {
if (isOutOfBounds(offset, length, buf.capacity())) {
throw new IndexOutOfBoundsException("expected: " + "0 <= offset(" + offset + ") <= offset + length(" + length + ") <= " + "buf.capacity(" + buf.capacity() + ')');
}
if (length == 0) {
return;
}
dump.append(" +-------------------------------------------------+" + NEWLINE + " | 0 1 2 3 4 5 6 7 8 9 a b c d e f |" + NEWLINE + "+--------+-------------------------------------------------+----------------+");
final int startIndex = offset;
final int fullRows = length >>> 4;
final int remainder = length & 0xF;
// Dump the rows which have 16 bytes.
for (int row = 0; row < fullRows; row++) {
int rowStartIndex = (row << 4) + startIndex;
// Per-row prefix.
appendHexDumpRowPrefix(dump, row, rowStartIndex);
// Hex dump
int rowEndIndex = rowStartIndex + 16;
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);
}
dump.append(" |");
// ASCII dump
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);
}
dump.append('|');
}
// Dump the last row which has less than 16 bytes.
if (remainder != 0) {
int rowStartIndex = (fullRows << 4) + startIndex;
appendHexDumpRowPrefix(dump, fullRows, rowStartIndex);
// Hex dump
int rowEndIndex = rowStartIndex + remainder;
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);
}
dump.append(HEXPADDING[remainder]);
dump.append(" |");
// Ascii dump
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);
}
dump.append(BYTEPADDING[remainder]);
dump.append('|');
}
dump.append(NEWLINE + "+--------+-------------------------------------------------+----------------+");
}
private static void appendHexDumpRowPrefix(StringBuilder dump, int row, int rowStartIndex) {
if (row < HEXDUMP_ROWPREFIXES.length) {
dump.append(HEXDUMP_ROWPREFIXES[row]);
} else {
dump.append(NEWLINE);
dump.append(Long.toHexString(rowStartIndex & 0xFFFFFFFFL | 0x100000000L));
dump.setCharAt(dump.length() - 9, '|');
dump.append('|');
}
}
public static short getUnsignedByte(ByteBuffer buffer, int index) {
return (short) (buffer.get(index) & 0xFF);
}
}
需要用到netty的常量,引入Maven依赖
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.39.Final</version>
</dependency>
1.分配空间
可以使用 allocate() 方法为 ByteBuffer 分配空间,其它 buffer 类也有该方法
ByteBuffer byteBuffer = ByteBuffer.allocate(10); //使用Java堆内存
ByteBuffer byteBuffer1 = ByteBuffer.allocateDirect(10); //使用本地内存
Buffer 是非线程安全的
2.向 buffer 写入数据
有两种办法
-
调用 channel 的 read 方法
int byteBuffer = channel.read(buf); -
调用 buffer 自己的 put 方法
byteBuffer.put((byte) 0x61);或者写入byte数组
byteBuffer.put(new byte[]{0x62, 0x63, 0x64}); ByteBufferUtil.debugAll(byteBuffer);
3.从 buffer 读取数据
同样有两种办法(注意要切换成读模式:byteBuffer.flip())
-
调用 channel 的 write 方法
int writeBytes = channel.write(byteBuffer); -
调用 buffer 自己的 get 方法
byte b = byteBuffer.get();注意:get 方法会让 position 读指针向后走,如果想重复读取数据
- 可以调用 rewind 方法将 position 重新置为 0
- 或者调用 get(int i) 方法获取索引 i 的内容,它不会移动读指针
4.compact()
该函数会将 position 与 limit 之间的数据复制到buffer的开始位置,复制后 position = limit -position,limit = capacity,但如果 position 与 limit 之间没有数据的话,就不会进行复制
ByteBufferUtil.debugAll(byteBuffer);
byteBuffer.get();
ByteBufferUtil.debugAll(byteBuffer);
byteBuffer.compact();
ByteBufferUtil.debugAll(byteBuffer);
输出:
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [4] //注意position和limit
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 00 00 00 00 00 00 |abcd...... |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [1], limit: [4]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 00 00 00 00 00 00 |abcd...... |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [3], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 62 63 64 64 00 00 00 00 00 00 |bcdd...... |
+--------+-------------------------------------------------+----------------+
5.mark() 和 reset()
mark() 是在读取时做一个标记,即使 position 改变,只要调用 reset() 就能回到 mark 记录的位置
注意:rewind 和 flip 都会清除 mark 位置
ByteBufferUtil.debugAll(byteBuffer);
byteBuffer.get();
ByteBufferUtil.debugAll(byteBuffer);
byteBuffer.mark(); //position = 1
byteBuffer.get();
ByteBufferUtil.debugAll(byteBuffer);
byteBuffer.reset();
ByteBufferUtil.debugAll(byteBuffer); //position = 1
输出:
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [4]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 00 00 00 00 00 00 |abcd...... |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [1], limit: [4]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 00 00 00 00 00 00 |abcd...... |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [2], limit: [4]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 00 00 00 00 00 00 |abcd...... |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [1], limit: [4]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 00 00 00 00 00 00 |abcd...... |
+--------+-------------------------------------------------+----------------+
2.4 字符串和ByteBuffer转换
-
字符串转ByteBuffer
-
方法一
byteBuffer.put("你好".getBytes()); -
方法二
ByteBuffer byteBuffer = StandardCharsets.UTF_8.encode("你好");写入后会自动转换成读模式
-
方法三
ByteBuffer byteBuffer = ByteBuffer.wrap("你好".getBytes());写入后会自动转换成读模式
-
-
ByteBuffer转字符串
byteBuffer.flip(); String s = StandardCharsets.UTF_8.decode(byteBuffer).toString();
2.5 Scattering Reads & Gathering Writes
分散读和集中写可以降低数据拷贝的次数,提高效率
1.Scattering Reads
将一个文本文件分别读取到多个ByteBuffer中,前提是已知文本文件切分的长度
举例:
-
文本文件 3parts.txt
onetwothree -
使用如下方式读取,可以将数据填充至多个 buffer
try (RandomAccessFile file = new RandomAccessFile("3parts.txt", "rw")) { FileChannel channel = file.getChannel(); ByteBuffer a = ByteBuffer.allocate(3); ByteBuffer b = ByteBuffer.allocate(3); ByteBuffer c = ByteBuffer.allocate(5); channel.read(new ByteBuffer[]{a, b, c}); a.flip(); b.flip(); c.flip(); debug(a); debug(b); debug(c); } catch (IOException e) { e.printStackTrace(); } -
输出
+--------+-------------------- all ------------------------+----------------+ position: [0], limit: [3] +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 6f 6e 65 |one | +--------+-------------------------------------------------+----------------+ +--------+-------------------- all ------------------------+----------------+ position: [0], limit: [3] +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 74 77 6f |two | +--------+-------------------------------------------------+----------------+ +--------+-------------------- all ------------------------+----------------+ position: [0], limit: [5] +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 74 68 72 65 65 |three | +--------+-------------------------------------------------+----------------+
2.Gathering Writes
将多个ByteBuffer合并成一次向文件中写入
举例:
-
使用如下方式写入,可以将多个 buffer 的数据填充至 channel
ByteBuffer a = StandardCharsets.UTF_8.encode("one"); ByteBuffer b = StandardCharsets.UTF_8.encode("two"); ByteBuffer c = StandardCharsets.UTF_8.encode("three"); RandomAccessFile file = new RandomAccessFile("3parts.txt", "rw"); FileChannel channel = file.getChannel(); channel.write(new ByteBuffer[]{a, b, c}); file.close(); -
输出 3parts.txt
onetwothree
2.6 黏包、半包的解决
网络上有多条数据发送给服务端,数据之间使用 \n 进行分隔
但由于某种原因这些数据在接收时,被进行了重新组合,例如原始数据有3条:
- Hello,world\n
- I’m zhangsan\n
- How are you?\n
变成了下面的两个 byteBuffer (黏包,半包):
- Hello,world\nI’m zhangsan\nHo
- w are you?\n
- 粘包:由于追求效率将多个包合并成一次发送给服务端
- 半包:由于服务端缓冲区大小的限制,导致无法一次缓存全部数据
现在要求将错乱的数据恢复成原始的按\n分隔的数据
public static void main(String[] args) {
ByteBuffer source = ByteBuffer.allocate(32);
source.put("Hello,world\nI'm zhangsan\nHo".getBytes());
split(source);
source.put("w are you?\nhaha!\n".getBytes());
split(source);
}
private static void split(ByteBuffer source) {
source.flip();
for (int i = 0; i < source.limit(); i++) {
//找到一条完整的消息
if (source.get(i) == '\n') {
int len = i - source.position();
//把这条消息存到ByteBuffer
ByteBuffer target = ByteBuffer.allocate(len);
for (int j = 0; j < len; j++)
target.put(source.get());
ByteBufferUtil.debugAll(target);
source.get(); //向后移动一个位置
}
}
source.compact();
}
+--------+-------------------- all ------------------------+----------------+
position: [11], limit: [11]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 65 6c 6c 6f 2c 77 6f 72 6c 64 |Hello,world |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [12], limit: [12]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 49 27 6d 20 7a 68 61 6e 67 73 61 6e |I'm zhangsan |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [12], limit: [12]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 6f 77 20 61 72 65 20 79 6f 75 3f |How are you? |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 61 68 61 21 |haha! |
+--------+-------------------------------------------------+----------------+
3.文件编程
3.1 FileChannel
FileChannel 工作模式:只能工作在阻塞模式下
1.获取
不能直接打开 FileChannel,必须通过 FileInputStream、FileOutputStream 或者 RandomAccessFile 来获取 FileChannel,它们都有getChannel()方法
- 通过
FileInputStream获取的channel只能读 - 通过
FileOutputStream获取的channel只能写 - 通过
RandomAccessFile是否能读写根据构造RandomAccessFile时的读写模式决定
2.读取
会从channel中读取数据填充到ByteBuffer,返回值表示读到了多少字节,-1表示到达了文件的末尾
int readBytes = channel.read(buffer);
3.写入
SocketChannel的容量不高,因此写入的标准顺序如下:
ByteBuffer buffer = ...;
buffer.put(...); // 存入数据
buffer.flip(); // 切换读模式
while(buffer.hasRemaining()) {
channel.write(buffer);
}
在while循环中调用
channel.write()是因为write()方法并不能保证一次将buffer中的内容全部写入channel
4.关闭
channel 必须关闭,不过调用了 FileInputStream、FileOutputStream 或者 RandomAccessFile 的close ()方法会间接地调用channel的close()方法
5.位置
-
获取当前位置
long pos = channel.position(); -
设置当前位置
long newPos = ...; channel.position(newPos);设置当前位置时,如果设置为文件的末尾
- 这时读取会返回 -1
- 这时写入,会追加内容,但要注意如果 position 超过了文件末尾,再写入时在新内容和原末尾之间会有空洞(00)
6.大小
使用size()方法获取文件的大小
7.强制写入
操作系统出于性能的考虑,会将数据缓存,不是立刻写入磁盘。可以调用force(true)方法将文件内容和**元数据(文件的权限等信息)**立刻写入磁盘
3.2 两个 Channel 传输数据
当文件较小时,可以直接使用transferTo()方法一次传输。相比于IO流,效率高,因为底层会利用操作系统的零拷贝进行优化
public static void main(String[] args) {
String FROM = "from.txt";
String TO = "to.txt";
long start = System.nanoTime();
try (FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel()
) {
from.transferTo(0, from.size(), to);
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("transferTo 用时:" + (end - start) / 1000_000.0);
}
输出:
transferTo 用时:8.2011
transferTo()方法最大一次传输2G大小的文件,当文件量过大时,需要使用循环多次传输
public static void main(String[] args) {
try (
FileChannel from = new FileInputStream("from.txt").getChannel();
FileChannel to = new FileOutputStream("to.txt").getChannel();
) {
long size = from.size(); // left 变量代表还剩余多少字节没有传输
for (long left = size; left > 0; ) {
System.out.println("position:" + (size - left) + " left:" + left);
left -= from.transferTo((size - left), left, to);
}
} catch (IOException e) {
e.printStackTrace();
}
}
3.3 Path
jdk7 引入了 Path 和 Paths 类
- Path 用来表示文件路径
- Paths 是工具类,用来获取 Path 实例
Path source = Paths.get("1.txt"); // 相对路径 使用 user.dir 环境变量来定位 1.txt
Path source = Paths.get("d:\\1.txt"); // 绝对路径 代表了 d:\1.txt
Path source = Paths.get("d:/1.txt"); // 绝对路径 同样代表了 d:\1.txt
Path projects = Paths.get("d:\\data", "projects"); // 代表了 d:\data\projects
Paths支持符号对于路径的查找:
.代表了当前路径..代表了上一级路径
举例:
-
目录结构如下
d: |- data |- projects |- a |- b -
主函数
Path path = Paths.get("d:\\data\\projects\\a\\..\\b"); System.out.println(path); System.out.println(path.normalize()); // 正常化路径 -
输出
d:\data\projects\a\..\b d:\data\projects\b
3.4 Files
-
检查文件是否存在
Path path = Paths.get("helloword/data.txt"); System.out.println(Files.exists(path)); -
创建一级目录
Path path = Paths.get("helloword/d1"); Files.createDirectory(path);- 如果目录已存在,会抛异常
FileAlreadyExistsException - 不能一次创建多级目录,否则会抛异常
NoSuchFileException
- 如果目录已存在,会抛异常
-
创建多级目录用
Path path = Paths.get("helloword/d1/d2"); Files.createDirectories(path); -
拷贝文件
Path source = Paths.get("helloword/data.txt"); Path target = Paths.get("helloword/target.txt"); Files.copy(source, target);如果文件已存在,会抛异常
FileAlreadyExistsException如果希望用
source覆盖掉target,需要用StandardCopyOption来控制Files.copy(source, target, StandardCopyOption.REPLACE_EXISTING); -
移动文件
Path source = Paths.get("helloword/data.txt"); Path target = Paths.get("helloword/data.txt"); Files.move(source, target, StandardCopyOption.ATOMIC_MOVE);StandardCopyOption.ATOMIC_MOVE保证文件移动的原子性 -
删除文件
Path target = Paths.get("helloword/target.txt"); Files.delete(target);如果文件不存在,会抛异常
NoSuchFileException -
删除目录
Path target = Paths.get("helloword/d1"); Files.delete(target);如果目录还有内容,会抛异常
DirectoryNotEmptyException -
遍历目录文件
public static void main(String[] args) throws IOException { Path path = Paths.get("./src"); AtomicInteger dirCount = new AtomicInteger(); //匿名内部类不能使用普通变量 AtomicInteger fileCount = new AtomicInteger(); Files.walkFileTree(path, new SimpleFileVisitor<Path>() { @Override public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) //进入文件夹前的方法 throws IOException { System.out.println(dir); dirCount.incrementAndGet(); return super.preVisitDirectory(dir, attrs); } @Override public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException { System.out.println(file); fileCount.incrementAndGet(); return super.visitFile(file, attrs); } @Override public FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException { //访问文件失败方法 return super.visitFileFailed(file, exc); } @Override public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException { //访问文件夹后的方法 return super.postVisitDirectory(dir, exc); } }); System.out.println(dirCount); //包括起始文件夹 System.out.println(fileCount); }访问者模式
举例:统计 jar 的数目
Path path = Paths.get("C:Java\\jdk1.8.0_91"); AtomicInteger fileCount = new AtomicInteger(); Files.walkFileTree(path, new SimpleFileVisitor<Path>(){ @Override public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException { if (file.toFile().getName().endsWith(".jar")) { fileCount.incrementAndGet(); } return super.visitFile(file, attrs); } }); System.out.println(fileCount); -
删除多级目录
Path path = Paths.get("d:\\a"); Files.walkFileTree(path, new SimpleFileVisitor<Path>(){ @Override public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException { Files.delete(file); return super.visitFile(file, attrs); } @Override public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException { Files.delete(dir); return super.postVisitDirectory(dir, exc); } }); -
拷贝多级目录
public static void main(String[] args) throws IOException { long start = System.currentTimeMillis(); String source = "D:\\netty讲义"; String target = "D:\\netty讲义aaa"; Files.walk(Paths.get(source)).forEach(path -> { try { String targetName = path.toString().replace(source, target); //注意path的形式是D:\netty讲义,替换时只能用转义字符的形式 // 是目录 if (Files.isDirectory(path)) { Files.createDirectory(Paths.get(targetName)); } // 是普通文件 else if (Files.isRegularFile(path)) { Files.copy(path, Paths.get(targetName)); } } catch (IOException e) { e.printStackTrace(); } }); long end = System.currentTimeMillis(); System.out.println(end - start); }注意:子文件夹如果有和父文件夹同名的情况可能会有问题
4.网络编程
4.1 非阻塞 vs 阻塞
1.阻塞
- 阻塞模式下,相关方法都会导致线程暂停
ServerSocketChannel.accept()会在没有连接建立时让线程暂停SocketChannel.read()会在没有数据可读时让线程暂停- 阻塞的表现其实就是线程暂停了,暂停期间不会占用 cpu,但线程相当于闲置
- 单线程下,阻塞方法之间相互影响,几乎不能正常工作,需要多线程支持
- 但多线程下,有新的问题,体现在以下方面:
- 32 位 jvm 一个线程 320k,64 位 jvm 一个线程 1024k,如果连接数过多,必然导致 OOM,并且线程太多,反而会因为频繁上下文切换导致性能降低
- 可以采用线程池技术来减少线程数和线程上下文切换,但治标不治本,如果有很多连接建立,但长时间 inactive,会阻塞线程池中所有线程,因此不适合长连接,只适合短连接
举例:
-
服务器端
public class Server { public static void main(String[] args) throws Exception { ServerSocketChannel ssc = ServerSocketChannel.open(); //创建服务器 ssc.bind(new InetSocketAddress(8080)); //监听端口 List<SocketChannel> channels = new ArrayList<>(); while (true) { System.out.println("服务端等待连接"); channels.add(ssc.accept()); //建立连接,阻塞 for (SocketChannel sc : channels) { ByteBuffer byteBuffer = ByteBuffer.allocate(16); System.out.println("服务端等待读取数据"); sc.read(byteBuffer); //阻塞 byteBuffer.flip(); ByteBufferUtil.debugAll(byteBuffer); } } } } -
客户端
public class Client { public static void main(String[] args) throws IOException, InterruptedException { SocketChannel sc = SocketChannel.open(); //创建客户端 sc.connect(new InetSocketAddress("localhost",8080)); //连接端口 while (true) { sc.write(ByteBuffer.wrap("hello,world".getBytes())); Thread.sleep(100000); } } }运行后发现多个问题:
- 除非等到下一个链接连接到服务器,否则只能接收当前客户端一条消息
- 连接到第二个客户端也需要第一个客户端发送消息后,才能接收到第二个客户端的消息
2.非阻塞
- 非阻塞模式下,相关方法都会不会让线程暂停
- 在 ServerSocketChannel.accept 在没有连接建立时,会返回 null,继续运行
- SocketChannel.read 在没有数据可读时,会返回 0,但线程不必阻塞,可以去执行其它 SocketChannel 的 read 或是去执行 ServerSocketChannel.accept
- 写数据时,线程只是等待数据写入 Channel 即可,无需等 Channel 通过网络把数据发送出去
- 但非阻塞模式下,即使没有连接建立和可读数据,线程仍然在不断运行,导致 cpu 空转
- 数据复制过程中,线程实际还是阻塞的(AIO 改进的地方)
举例:
-
服务端
public class Server { public static void main(String[] args) throws Exception { ServerSocketChannel ssc = ServerSocketChannel.open(); ssc.configureBlocking(false); //设置非阻塞模式 ssc.bind(new InetSocketAddress(8080)); List<SocketChannel> channels = new ArrayList<>(); while (true) { SocketChannel accept = ssc.accept(); if (accept != null) { channels.add(accept); //非阻塞 System.out.println("服务端建立连接" + accept); } for (SocketChannel sc : channels) { ByteBuffer byteBuffer = ByteBuffer.allocate(16); int read = sc.read(byteBuffer); //非阻塞 if (read>0) { System.out.println("服务端读取到数据"); byteBuffer.flip(); ByteBufferUtil.debugAll(byteBuffer); } } } } } -
客户端
public class Client { public static void main(String[] args) throws IOException, InterruptedException { SocketChannel sc = SocketChannel.open(); sc.connect(new InetSocketAddress("localhost",8080)); while (true) { sc.write(ByteBuffer.wrap("hello,world".getBytes())); Thread.sleep(100000); } } }
3.多路复用
单线程可以配合Selector完成对多个Channel可读写事件的监控,这称之为多路复用
-
多路复用仅针对网络 IO,普通文件 IO没法利用多路复用
-
如果不用
Selector的非阻塞模式,线程大部分时间都在做无用功,而Selector能够保证-
有可连接事件时才去连接
-
有可读事件才去读取
-
有可写事件才去写入
限于网络传输能力,
Channel未必时时可写,一旦Channel可写,会触发Selector的可写事件
-
4.2 Selector
优势:
- 一个线程配合 selector 就可以监控多个 channel 的事件,事件发生线程才去处理。避免非阻塞模式下所做无用功
- 让这个线程能够被充分利用
- 节约了线程的数量
- 减少了线程上下文切换
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fmdHWd0I-1674881150997)(./Netty.assets/image-20230104102007549.png)]](https://img-blog.csdnimg.cn/44b50280b18e47498fa4e04fe047062b.png)
1.创建
创建selector,可以监听多个channel
Selector selector = Selector.open();
2.绑定 Channel 事件
也称之为注册事件,selector只会处理绑定过的事件
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, 绑定事件, 附件);
channel 必须工作在非阻塞模式
FileChannel 没有非阻塞模式,因此不能配合 selector 一起使用
绑定的事件类型可以有
connect - 客户端连接成功时触发
key.interestOps(SelectionKey.OP_CONNECT); //也可不在注册时直接绑定,而是等到后续指定绑定类型accept - 服务器端成功接受连接时触发
sscKey.interestOps(SelectionKey.OP_ACCEPT);read - 数据可读入时触发,有因为接收能力弱,数据暂不能读入的情况
sscKey.interestOps(SelectionKey.OP_READ);write - 数据可写出时触发,有因为发送能力弱,数据暂不能写出的情况
sscKey.interestOps(SelectionKey.OP_WRITE);
3.监听 Channel 事件
可以通过下面三种方法来监听是否有事件发生,方法的返回值代表有多少channel发生了事件(注意:Selector只会监听绑定过的类型)
-
方法1,阻塞直到绑定事件发生
int count = selector.select(); -
方法2,阻塞直到绑定事件发生,或是超时(时间单位为 ms)
int count = selector.select(long timeout); -
方法3,不会阻塞,也就是不管有没有事件,立刻返回,自己根据返回值检查是否有事件
int count = selector.selectNow(); if(count <= 0) { continue; } else { ... }
注意:select 何时不阻塞?
- 事件发生时
- 客户端发起连接请求,会触发
accept事件- 客户端发送数据过来,客户端正常、异常关闭时,都会触发
read事件,另外如果发送的数据大于buffer缓冲区,会触发多次读取事件channel可写,会触发write事件- 在linux下
nio bug发生时- 调用
selector.wakeup()方法- 调用
selector.close()方法selector所在线程interrupt- 有事件未处理时
4.取消事件
事件发生后能否不处理?事件发生后,要么处理(accept、read、write),要么取消(cancel),不能什么都不做,否则下次该事件仍会触发,这是因为 nio 底层使用的是水平触发
当接收到事件但未对事件处理时,selector.select()不会陷入阻塞,而是继续执行,回到 CPU 空转的状态。因此必须要么处理事件,要么取消未处理的事件。取消事件后,Selector就无法再对该事件类型进行接受了
Selector selector = Selector.open(); //创建selector,可以监听多个channel
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
SelectionKey sscKey = ssc.register(selector, 0, null); //建立selector和channel的关系(绑定)
sscKey.interestOps(SelectionKey.OP_ACCEPT); //指定消息类型为accept
ssc.bind(new InetSocketAddress(8080));
while (true) {
selector.select(); //没有事件发生时会陷入阻塞
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
System.out.println("接收到accept事件");
key.cancel(); //取消事件。取消后后续的客户端accept事件不会被selcetor接收
}
}
注意:
cancel的作用
cancel()方法会取消注册在 selector 上的 channel,并从 keys 集合中删除 key 后续不会再监听事件
5.处理 accept 事件
-
客户端
public class Client { public static void main(String[] args) { try (Socket socket = new Socket("localhost", 8080)) { socket.getOutputStream().write("world".getBytes()); System.in.read(); } catch (IOException e) { e.printStackTrace(); } } } -
服务端
@Slf4j public class Server { public static void main(String[] args) { try (ServerSocketChannel channel = ServerSocketChannel.open()) { //创建selector,可以监听多个channel channel.bind(new InetSocketAddress(8080)); System.out.println(channel); Selector selector = Selector.open(); channel.configureBlocking(false); channel.register(selector, SelectionKey.OP_ACCEPT); while (true) { int count = selector.select(); log.debug("select count: {}", count); // 获取所有事件 Set<SelectionKey> keys = selector.selectedKeys(); // 遍历所有事件,逐一处理 Iterator<SelectionKey> iter = keys.iterator(); while (iter.hasNext()) { SelectionKey key = iter.next(); // 判断事件类型 if (key.isAcceptable()) { ServerSocketChannel c = (ServerSocketChannel) key.channel(); // 处理事件 SocketChannel sc = c.accept(); log.debug("{}", sc); } // 处理完毕,必须将事件移除,否则会陷入循环一直处理这个事件 iter.remove(); } } } catch (IOException e) { e.printStackTrace(); } } }
6.处理 read 事件
-
客户端
public class Client { public static void main(String[] args) throws IOException, InterruptedException { SocketChannel sc = SocketChannel.open(); //创建客户端 sc.connect(new InetSocketAddress("localhost",8080)); //连接端口 sc.write(ByteBuffer.wrap("0123\n456789abcdef".getBytes())); sc.write(ByteBuffer.wrap("0123456789abcdef3333\n".getBytes())); sc.close(); } } -
服务端
@Slf4j public class ChannelDemo6 { public static void main(String[] args) { try (ServerSocketChannel channel = ServerSocketChannel.open()) { channel.bind(new InetSocketAddress(8080)); System.out.println(channel); Selector selector = Selector.open(); channel.configureBlocking(false); channel.register(selector, SelectionKey.OP_ACCEPT); while (true) { int count = selector.select(); log.debug("select count: {}", count); // 获取所有事件 Set<SelectionKey> keys = selector.selectedKeys(); // 遍历所有事件,逐一处理 Iterator<SelectionKey> iter = keys.iterator(); while (iter.hasNext()) { SelectionKey key = iter.next(); // 判断事件类型 if (key.isAcceptable()) { //如果是连接的类型就再把链接的管道也绑定到Selector上,key为读取类型 ServerSocketChannel c = (ServerSocketChannel) key.channel(); SocketChannel sc = c.accept(); sc.configureBlocking(false); sc.register(selector, SelectionKey.OP_READ); log.debug("连接已建立: {}", sc); } else if (key.isReadable()) { //如果是读取类型就直接读取数据 SocketChannel sc = (SocketChannel) key.channel(); ByteBuffer buffer = ByteBuffer.allocate(128); int read = sc.read(buffer); if(read == -1) { key.cancel(); sc.close(); } else { buffer.flip(); debug(buffer); } } // 处理完毕,必须将事件移除 iter.remove(); } } } catch (IOException e) { e.printStackTrace(); } } }注意:为何要
iter.remove()?因为 select 在事件发生后,就会将相关的 key 放入 selectedKeys 集合,但不会在处理完后从 selectedKeys 集合中移除,需要我们自己
remove()。举例:处理完毕的事件是不会主动删除的,而是会在下次迭代时继续出现
if (key.isAcceptable()) { //如果是连接的类型就再把链接的管道也绑定到Selector上,key为读取类型 ServerSocketChannel c = (ServerSocketChannel) key.channel(); SocketChannel sc = c.accept(); sc.configureBlocking(false); sc.register(selector, SelectionKey.OP_READ); log.debug("连接已建立: {}", sc); } else if (key.isReadable()) { //如果是读取类型就直接读取数据 SocketChannel sc = (SocketChannel) key.channel(); ByteBuffer buffer = ByteBuffer.allocate(128); int read = sc.read(buffer); if(read == -1) { key.cancel(); sc.close(); } else { buffer.flip(); ByteBufferUtil.debugAll(buffer); } } //iterator.remove(); //取消事件-
当一个客户端连接到服务端后触发了 ssckey 上的 accept 事件,没有移除 ssckey
-
当客户端发送消息时触发了 sckey 上的 read 事件,但由于建立连接的那个事件没有被删除,也就是 selectedKeys 中还有上次的 ssckey ,会再次执行
if中的代码。而此时根本获取不到c.accept()的结果,因此设置sc为非阻塞模式会报空指针异常 -
最终Selector内存结构如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PofyBNJb-1674881150998)(./Netty.assets/image-20230105202521808.png)]](https://img-blog.csdnimg.cn/d40a24ca02534e4a806dce455fc679b7.png)
开启两个客户端,修改一下发送文字,输出
sun.nio.ch.ServerSocketChannelImpl[/0:0:0:0:0:0:0:0:8080] 21:16:39 [DEBUG] [main] c.i.n.ChannelDemo6 - select count: 1 21:16:39 [DEBUG] [main] c.i.n.ChannelDemo6 - 连接已建立: java.nio.channels.SocketChannel[connected local=/127.0.0.1:8080 remote=/127.0.0.1:60367] 21:16:39 [DEBUG] [main] c.i.n.ChannelDemo6 - select count: 1 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 68 65 6c 6c 6f |hello | +--------+-------------------------------------------------+----------------+ 21:16:59 [DEBUG] [main] c.i.n.ChannelDemo6 - select count: 1 21:16:59 [DEBUG] [main] c.i.n.ChannelDemo6 - 连接已建立: java.nio.channels.SocketChannel[connected local=/127.0.0.1:8080 remote=/127.0.0.1:60378] 21:16:59 [DEBUG] [main] c.i.n.ChannelDemo6 - select count: 1 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 77 6f 72 6c 64 |world | +--------+-------------------------------------------------+----------------+ -
客户端关闭问题
当客户端关闭时,无论是否强制关闭都会触发read事件,因此需要在处理read事件时添加断开客户端连接的逻辑
如果read返回 >0 说明还有数据,0表示读取完成,-1表示断开
-
服务端
public class Server { public static void main(String[] args) throws Exception { Selector selector = Selector.open(); ServerSocketChannel ssc = ServerSocketChannel.open(); ssc.configureBlocking(false); SelectionKey sscKey = ssc.register(selector, 0, null); sscKey.interestOps(SelectionKey.OP_ACCEPT); ssc.bind(new InetSocketAddress(8080)); while (true) { selector.select(); Iterator<SelectionKey> iterator = selector.selectedKeys().iterator(); while (iterator.hasNext()) { SelectionKey key = iterator.next(); // 判断事件类型 if (key.isAcceptable()) { ServerSocketChannel c = (ServerSocketChannel) key.channel(); SocketChannel sc = c.accept(); sc.configureBlocking(false); sc.register(selector, SelectionKey.OP_READ); log.debug("连接已建立: {}", sc); } else if (key.isReadable()) { try { SocketChannel sc = (SocketChannel) key.channel(); ByteBuffer buffer = ByteBuffer.allocate(16); int read = sc.read(buffer); if(read == -1) { key.cancel(); //客户端正常close()时,read会返回-1 sc.close(); } else { buffer.flip(); ByteBufferUtil.debugAll(buffer); } } catch (Exception e) { //如果客户端强行关闭连接,会产生一个read事件并发生异常 e.printStackTrace(); key.cancel(); } } iterator.remove(); } } } } -
客户端
public class Client { public static void main(String[] args) throws IOException, InterruptedException { SocketChannel sc = SocketChannel.open(); //创建客户端 sc.connect(new InetSocketAddress("localhost",8080)); //连接端口 sc.write(ByteBuffer.wrap("hello,world".getBytes())); sc.close(); } }
边界问题的处理
以BIO为例,不处理边界问题时:
-
客户端
public class Client { public static void main(String[] args) throws IOException { Socket max = new Socket("localhost", 9000); OutputStream out = max.getOutputStream(); out.write("hello".getBytes()); out.write("world".getBytes()); out.write("你好".getBytes()); max.close(); } } -
服务端
public class Server { public static void main(String[] args) throws IOException { ServerSocket ss=new ServerSocket(9000); while (true) { Socket s = ss.accept(); InputStream in = s.getInputStream(); byte[] arr = new byte[4]; //一个中文占三个字节,4个字节的缓冲区会出现半包现象 while(true) { int read = in.read(arr); if(read == -1) { break; } System.out.println(new String(arr, 0, read)); } } } } -
输出
hell owor ld� �好
由此可见,必须对消息的边界进行处理
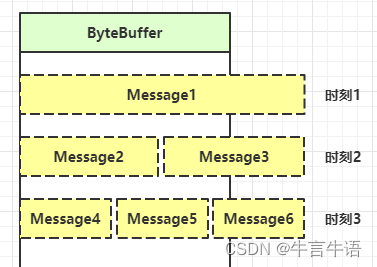
处理思路:
- 固定消息长度,数据包大小一样,服务器按预定长度读取,缺点是浪费带宽
- 按分隔符拆分,预定义一个分隔符表示消息的结尾,缺点是效率低
- TLV 格式,即 Type 类型、Length 长度、Value 数据,首先获取类型和长度,按照长度的大小分配合适的 buffer,缺点是 buffer 需要提前分配,如果内容过大,则影响 server 吞吐量
- Http 1.1 是 TLV 格式
- Http 2.0 是 LTV 格式
举例:按分隔符拆分 + 扩容Buffer的处理方式
处理流程:(此处举例超过ByteBuffer容量的消息如何处理)
-
服务端
private static void split(ByteBuffer source) { source.flip(); for (int i = 0; i < source.limit(); i++) { // 找到一条完整消息 if (source.get(i) == '\n') { int length = i + 1 - source.position(); ByteBuffer target = ByteBuffer.allocate(length); for (int j = 0; j < length; j++) { target.put(source.get()); } debugAll(target); } } source.compact(); } public static void main(String[] args) throws IOException { Selector selector = Selector.open(); ServerSocketChannel ssc = ServerSocketChannel.open(); ssc.configureBlocking(false); SelectionKey sscKey = ssc.register(selector, 0, null); sscKey.interestOps(SelectionKey.OP_ACCEPT); log.debug("sscKey:{}", sscKey); ssc.bind(new InetSocketAddress(8080)); while (true) { selector.select(); Iterator<SelectionKey> iter = selector.selectedKeys().iterator(); while (iter.hasNext()) { SelectionKey key = iter.next(); iter.remove(); log.debug("key: {}", key); if (key.isAcceptable()) { // 如果是 accept ServerSocketChannel channel = (ServerSocketChannel) key.channel(); SocketChannel sc = channel.accept(); sc.configureBlocking(false); ByteBuffer buffer = ByteBuffer.allocate(16); // attachment,初始值16字节 // 将一个 byteBuffer 作为附件关联到 selectionKey 上,每一个key拥有自己的byteBuffer SelectionKey scKey = sc.register(selector, 0, buffer); scKey.interestOps(SelectionKey.OP_READ); log.debug("{}", sc); log.debug("scKey:{}", scKey); } else if (key.isReadable()) { // 如果是 read try { SocketChannel channel = (SocketChannel) key.channel(); // 获取 selectionKey 上关联的附件 ByteBuffer buffer = (ByteBuffer) key.attachment(); int read = channel.read(buffer); if(read == -1) { key.cancel(); } else { split(buffer); // 需要扩容 if (buffer.position() == buffer.limit()) { ByteBuffer newBuffer = ByteBuffer.allocate(buffer.capacity() * 2); buffer.flip(); newBuffer.put(buffer); // 0123456789abcdef3333\n key.attach(newBuffer); // 关联新的附件 } } } catch (IOException e) { e.printStackTrace(); key.cancel(); } } } } } -
客户端
SocketChannel sc = SocketChannel.open(); sc.connect(new InetSocketAddress("localhost", 8080)); sc.write(Charset.defaultCharset().encode("0123\n456789abcdef")); sc.write(Charset.defaultCharset().encode("0123456789abcdef3333\n"));
ByteBuffer 大小分配
- 每个 channel 都需要记录可能被切分的消息,因为 ByteBuffer 不能被多个 channel 共同使用,因此需要为每个 channel 维护一个独立的 ByteBuffer
- ByteBuffer 不能太大,比如一个 ByteBuffer 1Mb 的话,要支持百万连接就要 1Tb 内存,因此需要设计大小可变的 ByteBuffer
- 一种思路是首先分配一个较小的 buffer,例如 4k,如果发现数据不够,再分配 8k 的 buffer,将 4k buffer 内容拷贝至 8k buffer,优点是消息连续容易处理,缺点是数据拷贝耗费性能,参考实现 http://tutorials.jenkov.com/java-performance/resizable-array.html
- 另一种思路是用多个数组组成 buffer,一个数组不够,把多出来的内容写入新的数组,与前面的区别是消息存储不连续解析复杂,优点是避免了拷贝引起的性能损耗
7.处理 write 事件
- 非阻塞模式下,无法保证把
buffer中所有数据都写入channel,因此需要追踪write()方法的返回值(代表实际写入字节数) - 用
selector监听所有channel的可写事件,每个channel都需要一个key来跟踪buffer,但这样又会导致占用内存过多,就有两阶段策略- 当消息处理器第一次写入消息时,才将
channel注册到selector上 selector检查channel上的可写事件,如果所有的数据写完了,就取消channel的注册。如果不取消,会每次可写均会触发write事件
- 当消息处理器第一次写入消息时,才将
举例:一次无法写完例子
-
服务端
public class Server { public static void main(String[] args) throws IOException { Selector selector = Selector.open(); ServerSocketChannel ssc = ServerSocketChannel.open(); ssc.configureBlocking(false); SelectionKey sscKey = ssc.register(selector, SelectionKey.OP_ACCEPT, null); ssc.bind(new InetSocketAddress(8080)); while (true) { selector.select(); Iterator<SelectionKey> iter = selector.selectedKeys().iterator(); while (iter.hasNext()) { SelectionKey key = iter.next(); iter.remove(); log.debug("key: {}", key); if (key.isAcceptable()) { ServerSocketChannel channel = (ServerSocketChannel) key.channel(); SocketChannel sc = channel.accept(); sc.configureBlocking(false); //向客户端发送大量数据 StringBuilder sb = new StringBuilder(); for (int i = 0; i < 30000000; i++) { sb.append('a'); } ByteBuffer byteBuffer = Charset.defaultCharset().encode(sb.toString()); while (byteBuffer.hasRemaining()){ System.out.println(sc.write(byteBuffer)); //write不能保证一次将数据全部写入 } } } } } } -
客户端
public class Client { public static void main(String[] args) throws IOException, InterruptedException { SocketChannel sc = SocketChannel.open(); //创建客户端 sc.connect(new InetSocketAddress("localhost", 8080)); //连接端口 //接收数据 int count = 0; while (true) { ByteBuffer byteBuffer = ByteBuffer.allocate(1024 * 1024); System.out.println(count += sc.read(byteBuffer)); byteBuffer.clear(); } } } -
输出:服务端
4587485 0 4718556 4194272 0 4587485 0 0 9437112 0 ... 0 2475090服务端由于输出缓冲区大小的限制,分了多次才将数据完整写出
注意:write为何要取消?
只要向channel发送数据时,socket缓冲可写,这个事件会频繁触发,因此应当只在socket缓冲区写不下时再关注可写事件,数据写完之后再取消关注
由于发送大数据量时是while一直阻塞,所以需要对上述代码改进:
4.3 多线程优化 Selector
现在都是多核 cpu,设计时要充分考虑别让 cpu 的力量被白白浪费。前面的代码只有一个选择器,没有充分利用多核 cpu,如何改进呢?
建议分为两组选择器:
- 单线程配一个选择器,专门处理
accept事件 - 创建 cpu 核心数的线程,每个线程配一个选择器,轮流处理
read事件
public class MultiThreadServer {
public static void main(String[] args) throws IOException {
Thread.currentThread().setName("boss");
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
Selector boss = Selector.open();
SelectionKey sscKey = ssc.register(boss, SelectionKey.OP_ACCEPT, null);
ssc.bind(new InetSocketAddress(8080));
//初始化Worker线程组
Worker[] workers = new Worker[Runtime.getRuntime().availableProcessors()];
for (int i = 0; i < workers.length; i++) {
workers[i] = new Worker("Worker-" + i);
}
AtomicInteger index = new AtomicInteger();
while (true) {
boss.select();
Iterator<SelectionKey> iter = boss.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
if (key.isAcceptable()) {
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
SocketChannel sc = channel.accept();
sc.configureBlocking(false);
//将读事件分散关联到worker的selector上
workers[index.getAndIncrement() % workers.length].register(sc);
log.info("将{}的读事件绑定到worker线程", sc.getRemoteAddress());
}
}
}
}
static class Worker implements Runnable {
private Thread thread;
private Selector selector;
private ConcurrentLinkedQueue<Runnable> queue;
private String name;
public Worker(String name) throws IOException {
this.name = name;
thread = new Thread(this, name);
selector = Selector.open();
queue = new ConcurrentLinkedQueue<>();
thread.start();
}
//注意:当多线程时,selector的select()方法先于register()方法,会阻塞在select()方法处,不能进行绑定操作
public void register(SocketChannel sc) {
queue.add(() -> {
try {
sc.register(selector, SelectionKey.OP_READ, null);
} catch (ClosedChannelException e) {
throw new RuntimeException(e);
}
});
selector.wakeup(); //取消select()方法的阻塞
}
@Override
public void run() {
while (true) {
try {
selector.select(); //由于worker线程先于主线程的注册方法,会一直在此处阻塞,等待wakeup
Runnable task = queue.poll();
if (task != null) {
task.run();
}
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isReadable()) {
log.info("worker线程输出日志");
ByteBuffer byteBuffer = ByteBuffer.allocate(16);
SocketChannel channel = (SocketChannel) key.channel();
channel.read(byteBuffer);
byteBuffer.flip();
ByteBufferUtil.debugAll(byteBuffer);
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
}
如何拿到cpu个数?
Runtime.getRuntime().availableProcessors()如果工作在docker容器下,因为容器不是物理隔离的,会拿到物理cpu个数,而不是容器申请时的个数。这个问题直到jdk 10才修复,使用 jvm 参数UseContainerSupport配置,默认开启
4.4 UDP
- UDP 是无连接的,client 发送数据不会管 server 是否开启
- server 这边的 receive 方法会将接收到的数据存入 byte buffer,但如果数据报文超过 buffer 大小,多出来的数据会被默默抛弃
举例:
-
服务端
public class UdpServer { public static void main(String[] args) { try (DatagramChannel channel = DatagramChannel.open()) { channel.socket().bind(new InetSocketAddress(9999)); System.out.println("waiting..."); ByteBuffer buffer = ByteBuffer.allocate(32); channel.receive(buffer); buffer.flip(); debug(buffer); } catch (IOException e) { e.printStackTrace(); } } } -
客户端
public class UdpClient { public static void main(String[] args) { try (DatagramChannel channel = DatagramChannel.open()) { ByteBuffer buffer = StandardCharsets.UTF_8.encode("hello"); InetSocketAddress address = new InetSocketAddress("localhost", 9999); channel.send(buffer, address); } catch (Exception e) { e.printStackTrace(); } } } -
服务端输出
waiting... +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 68 65 6c 6c 6f |hello | +--------+-------------------------------------------------+----------------+
5.NIO vs BIO vs AIO
5.1 stream vs channel
stream不会自动缓冲数据,channel会利用系统提供的发送缓冲区、接收缓冲区(更为底层)stream仅支持阻塞API,channel同时支持阻塞、非阻塞API,网络channel可配合selector实现多路复用- 二者均为全双工,即读写可以同时进行
5.2 IO 模型
同步阻塞、同步非阻塞、同步多路复用、异步阻塞(没有此情况)、异步非阻塞
- 同步:线程自己去获取结果(一个线程)
- 异步:线程自己不去获取结果,而是由其它线程送结果(至少两个线程)
当调用一次channel.read()或stream.read()后,会切换至操作系统内核态来完成真正数据读取,而读取又分为两个阶段,分别为:
-
等待数据阶段
-
复制数据阶段
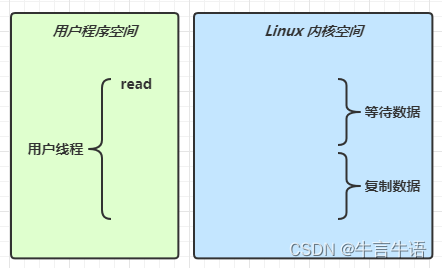
-
同步阻塞 IO
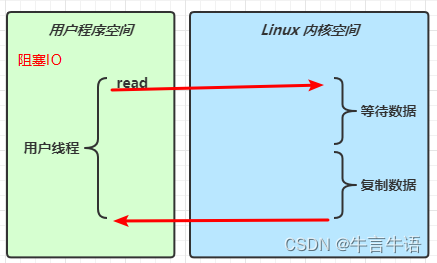
-
同步非阻塞 IO
等待数据时不阻塞,但复制数据时阻塞
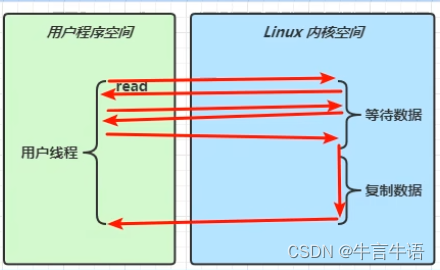
-
同步多路复用
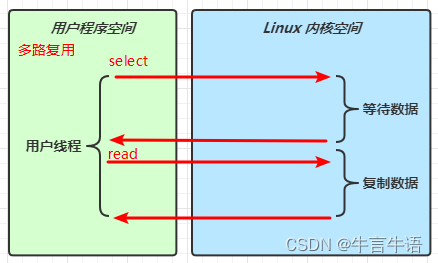
-
信号驱动
预先在内核中设置一个回调函数,当某个事件发生时,内核使用信号(SIGIO)通知进程来处理(运行回调函数)
-
异步 IO
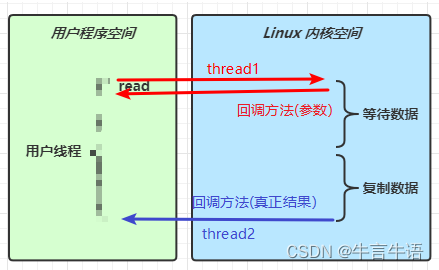
-
阻塞 IO vs 多路复用
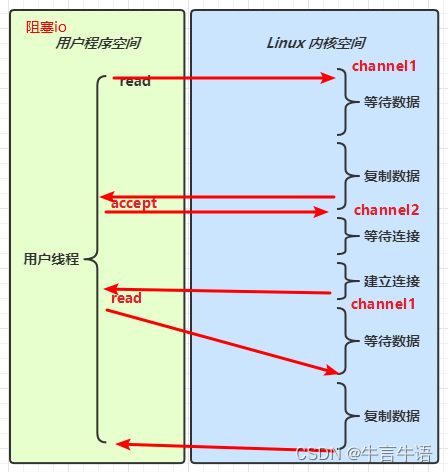
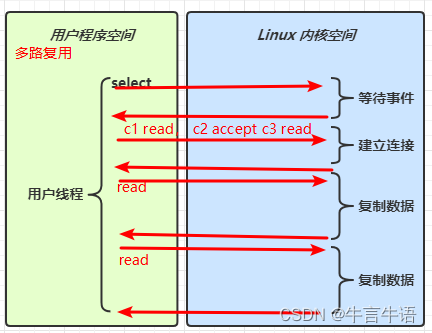
5.3 零拷贝
1.传统 IO 问题
传统的 IO 将一个文件通过 socket 写出
File f = new File("helloword/data.txt");
RandomAccessFile file = new RandomAccessFile(file, "r");
byte[] buf = new byte[(int)f.length()];
file.read(buf);
Socket socket = ...;
socket.getOutputStream().write(buf);
内部工作流程是这样的:
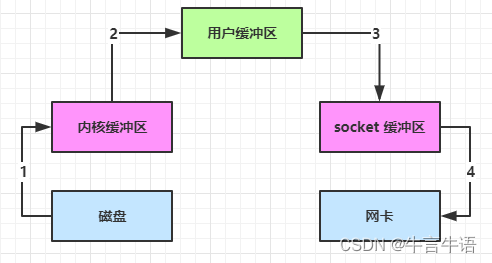
-
java 本身并不具备 IO 读写能力,因此
read()方法调用后,要从 java 程序的用户态切换至内核态,去调用操作系统(Kernel)的读能力,将数据读入内核缓冲区。这期间用户线程阻塞,操作系统使用 DMA(Direct Memory Access)来实现文件读,其间也不会使用 cpuDMA 也可以理解为硬件单元,用来解放 cpu 完成文件 IO
-
从内核态切换回用户态,将数据从内核缓冲区读入用户缓冲区(即 byte[] buf),这期间 cpu 会参与拷贝,无法利用 DMA
-
调用 write 方法,这时将数据从用户缓冲区(byte[] buf)写入 socket 缓冲区,cpu 会参与拷贝
-
接下来要向网卡写数据,这项能力 java 又不具备,因此又得从用户态切换至内核态,调用操作系统的写能力,使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu
可以看到中间环节较多,java 的 IO 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的
- 用户态与内核态的切换发生了 3 次,这个操作比较重量级
- 数据拷贝了共 4 次
2.NIO 优化
通过 DirectByteBuf
ByteBuffer.allocate(10)HeapByteBuffer 使用的是 java 内存ByteBuffer.allocateDirect(10)DirectByteBuffer 使用的是操作系统内存
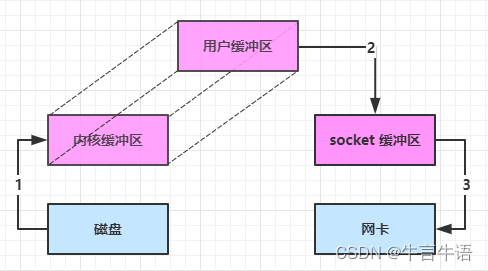
大部分步骤与优化前相同,不再赘述。唯有一点:java 可以使用 DirectByteBuf 将堆外内存映射到 jvm 内存中来直接访问使用
- 这块内存不受 jvm 垃圾回收的影响,因此内存地址固定,有助于 IO 读写
- java 中的 DirectByteBuf 对象仅维护了此内存的虚引用,内存回收分成两步
- DirectByteBuf 对象被垃圾回收,将虚引用加入引用队列
- 通过专门线程访问引用队列,根据虚引用释放堆外内存
- 减少了一次数据拷贝,用户态与内核态的切换次数没有减少
进一步优化(底层采用了 linux 2.1 后提供的 sendFile 方法),java 中对应着两个 channel 调用 transferTo/transferFrom 方法拷贝数据

- java 调用 transferTo 方法后,要从 java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 cpu
- 数据从内核缓冲区传输到 socket 缓冲区,cpu 会参与拷贝
- 最后使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu
可以看到
- 只发生了一次用户态与内核态的切换
- 数据拷贝了 3 次
进一步优化(linux 2.4)
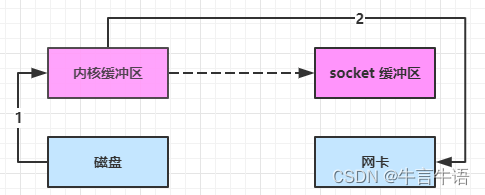
- java 调用 transferTo 方法后,要从 java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 cpu
- 只会将一些 offset 和 length 信息拷入 socket 缓冲区,几乎无消耗
- 使用 DMA 将内核缓冲区的数据写入网卡,不会使用 cpu
整个过程仅只发生了一次用户态与内核态的切换,数据拷贝了 2 次。所谓的【零拷贝】,并不是真正无拷贝,而是在不会拷贝重复数据到 jvm 内存中,零拷贝的优点有:
- 更少的用户态与内核态的切换
- 不利用 cpu 计算,减少 cpu 缓存伪共享
- 零拷贝适合小文件传输
5.4 AIO
AIO 用来解决数据复制阶段的阻塞问题
- 同步意味着,在进行读写操作时,线程需要等待结果,还是相当于闲置
- 异步意味着,在进行读写操作时,线程不必等待结果,而是将来由操作系统来通过回调方式由另外的线程来获得结果
异步模型需要底层操作系统(Kernel)提供支持
- Windows 系统通过 IOCP 实现了真正的异步 IO
- Linux 系统异步 IO 在 2.6 版本引入,但其底层实现还是用多路复用模拟了异步 IO,性能没有优势
1.文件 AIO
举例:AsynchronousFileChannel
-
主函数
public class FileAIO { public static void main(String[] args) throws IOException, InterruptedException { AsynchronousFileChannel channel = AsynchronousFileChannel.open(Paths.get("data.txt"), StandardOpenOption.READ); ByteBuffer byteBuffer = ByteBuffer.allocate(16); log.debug("read begin.."); //参数1:ByteBuffer; 参数2:读取的起始地址; 参数3:附件; 参数4:回调对象 channel.read(byteBuffer, 0, byteBuffer, new CompletionHandler<Integer, ByteBuffer>() { //read成功后 @Override public void completed(Integer result, ByteBuffer attachment) { attachment.flip(); ByteBufferUtil.debugAll(attachment); log.debug("read completed.."); } //read失败后 @Override public void failed(Throwable exc, ByteBuffer attachment) { exc.printStackTrace(); } }); log.debug("read end.."); Thread.sleep(1000); } }**注意:**默认文件 AIO 使用的线程都是守护线程,所以最后要执行
Thrad.sleep()以避免守护线程意外结束 -
输出
19:57:02 [DEBUG] [main] o.e.MultiThreadServer - read begin.. 19:57:02 [DEBUG] [main] o.e.MultiThreadServer - read end.. +--------+-------------------- all ------------------------+----------------+ position: [0], limit: [11] +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 6f 6e 65 74 77 6f 74 68 72 65 65 00 00 00 00 00 |onetwothree.....| +--------+-------------------------------------------------+----------------+ 19:57:02 [DEBUG] [Thread-12] o.e.MultiThreadServer - read completed..注意:
- 响应文件读取成功的是另一个线程 Thread-12
- 主线程并没有 IO 操作阻塞
2.网络 AIO
注:未测试
public class AioServer {
public static void main(String[] args) throws IOException {
AsynchronousServerSocketChannel ssc = AsynchronousServerSocketChannel.open();
ssc.bind(new InetSocketAddress(8080));
ssc.accept(null, new AcceptHandler(ssc));
System.in.read();
}
private static void closeChannel(AsynchronousSocketChannel sc) {
try {
System.out.printf("[%s] %s close\n", Thread.currentThread().getName(), sc.getRemoteAddress());
sc.close();
} catch (IOException e) {
e.printStackTrace();
}
}
private static class ReadHandler implements CompletionHandler<Integer, ByteBuffer> {
private final AsynchronousSocketChannel sc;
public ReadHandler(AsynchronousSocketChannel sc) {
this.sc = sc;
}
@Override
public void completed(Integer result, ByteBuffer attachment) {
try {
if (result == -1) {
closeChannel(sc);
return;
}
System.out.printf("[%s] %s read\n", Thread.currentThread().getName(), sc.getRemoteAddress());
attachment.flip();
System.out.println(Charset.defaultCharset().decode(attachment));
attachment.clear();
// 处理完第一个 read 时,需要再次调用 read 方法来处理下一个 read 事件
sc.read(attachment, attachment, this);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
closeChannel(sc);
exc.printStackTrace();
}
}
private static class WriteHandler implements CompletionHandler<Integer, ByteBuffer> {
private final AsynchronousSocketChannel sc;
private WriteHandler(AsynchronousSocketChannel sc) {
this.sc = sc;
}
@Override
public void completed(Integer result, ByteBuffer attachment) {
// 如果作为附件的 buffer 还有内容,需要再次 write 写出剩余内容
if (attachment.hasRemaining()) {
sc.write(attachment);
}
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
exc.printStackTrace();
closeChannel(sc);
}
}
private static class AcceptHandler implements CompletionHandler<AsynchronousSocketChannel, Object> {
private final AsynchronousServerSocketChannel ssc;
public AcceptHandler(AsynchronousServerSocketChannel ssc) {
this.ssc = ssc;
}
@Override
public void completed(AsynchronousSocketChannel sc, Object attachment) {
try {
System.out.printf("[%s] %s connected\n", Thread.currentThread().getName(), sc.getRemoteAddress());
} catch (IOException e) {
e.printStackTrace();
}
ByteBuffer buffer = ByteBuffer.allocate(16);
// 读事件由 ReadHandler 处理
sc.read(buffer, buffer, new ReadHandler(sc));
// 写事件由 WriteHandler 处理
sc.write(Charset.defaultCharset().encode("server hello!"), ByteBuffer.allocate(16), new WriteHandler(sc));
// 处理完第一个 accpet 时,需要再次调用 accept 方法来处理下一个 accept 事件
ssc.accept(null, this);
}
@Override
public void failed(Throwable exc, Object attachment) {
exc.printStackTrace();
}
}
}
第二章 Netty 入门
1.Netty 概述
Netty 是一个异步的、基于事件驱动的网络应用框架,用于快速开发可维护、高性能的网络服务器和客户端
Netty 在 Java 网络应用框架中的地位就好比:Spring 框架在 JavaEE 开发中的地位。以下的框架都使用了 Netty,因为它们有网络通信需求:
- Cassandra - nosql 数据库
- Spark - 大数据分布式计算框架
- Hadoop - 大数据分布式存储框架
- RocketMQ - ali 开源的消息队列
- ElasticSearch - 搜索引擎
- gRPC - rpc 框架
- Dubbo - rpc 框架
- Spring 5.x - flux api 完全抛弃了 tomcat ,使用 netty 作为服务器端
- Zookeeper - 分布式协调框架
Netty 的优势:
- Netty vs NIO,工作量大,bug 多
- 需要自己构建协议
- 解决 TCP 传输问题,如粘包、半包
- epoll 空轮询导致 CPU 100%
- 对 API 进行增强,使之更易用,如
FastThreadLocal->ThreadLocal,ByteBuf=>ByteBuffer
- Netty vs 其它网络应用框架
- Mina 由 apache 维护,将来 3.x 版本可能会有较大重构,破坏 API 向下兼容性,Netty 的开发迭代更迅速,API 更简洁、文档更优秀
- 久经考验,16年,Netty 版本
- 2.x 2004
- 3.x 2008
- 4.x 2013
- 5.x 已废弃(没有明显的性能提升,维护成本高)
2.快速使用
开发一个简单的服务器端和客户端
- 客户端向服务器端发送 hello, world
- 服务器仅接收,不返回
举例:
-
加入Maven依赖
<dependency> <groupId>io.netty</groupId> <artifactId>netty-all</artifactId> <version>4.1.39.Final</version> </dependency> -
服务端
public class Server { public static void main(String[] args) throws IOException, InterruptedException { new ServerBootstrap() //服务端启动器,负责组装Netty组件 .group(new NioEventLoopGroup()) // 1 .channel(NioServerSocketChannel.class) // 2 .childHandler(new ChannelInitializer<NioSocketChannel>() { // 3 @Override protected void initChannel(NioSocketChannel ch) { //连接建立后,调用初始化方法 ch.pipeline().addLast(new StringDecoder()); // 5 ch.pipeline().addLast(new SimpleChannelInboundHandler<String>() { // 6 @Override protected void channelRead0(ChannelHandlerContext ctx, String msg) { System.out.println(msg); } }); } }) .bind(8080); // 4 } }代码解读
-
1 处,创建
NioEventLoopGroup监听accept事件,NioEventLoopGroup可以简单理解为线程池 + Selector后面会详细展开 -
2 处,选择服务
Scoket实现类,其中NioServerSocketChannel表示基于NIO的服务器端实现,其它实现还有
-
3 处,
childHandler()方法表示接下来添加的处理器都是给SocketChannel用的,而不是给ServerSocketChannel。ChannelInitializer处理器(仅执行一次),它的作用是待客户端SocketChannel建立连接后,执行initChannel以便添加更多的处理器 -
4 处,ServerSocketChannel 绑定的监听端口
-
5 处,SocketChannel 的处理器,解码 ByteBuf => String
-
6 处,SocketChannel 的业务处理器,会使用上一个处理器的处理结果执行自己的逻辑
-
-
客户端
public class Client { public static void main(String[] args) throws InterruptedException { new Bootstrap() .group(new NioEventLoopGroup()) // 1 .channel(NioSocketChannel.class) // 2 .handler(new ChannelInitializer<NioSocketChannel>() { // 3 @Override protected void initChannel(NioSocketChannel ch) { //连接建立后,调用初始化方法 ch.pipeline().addLast(new StringEncoder()); // 8 } }) .connect("127.0.0.1", 8080) // 4 .sync() // 5 .channel() // 6 .writeAndFlush(new Date() + ": hello world!"); // 7 } }代码解读
-
1 处,创建 NioEventLoopGroup,同 Server
-
2 处,选择客户 Socket 实现类,NioSocketChannel 表示基于 NIO 的客户端实现,其它实现还有
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8AQ77xLh-1674881151002)(./Netty.assets/image-20230104114015174.png)]](https://img-blog.csdnimg.cn/843806ab4fb149f1bed38bc70cf03fe7.png)
-
3 处,添加 SocketChannel 的处理器,ChannelInitializer 处理器(仅执行一次),它的作用是待客户端 SocketChannel 建立连接后,执行 initChannel 以便添加更多的处理器
-
4 处,指定要连接的服务器和端口
-
5 处,Netty 中很多方法都是异步的,如 connect,但
sync()方法是阻塞等待connect建立连接完毕的 -
6 处,获取 channel 对象,它即为通道抽象,可以进行数据读写操作
-
7 处,写入消息并清空缓冲区
-
8 处,消息会经过通道 编码器handler 处理,这里是将 String => ByteBuf 发出
-
数据经过网络传输,到达服务器端,服务器端 5 和 6 处的 handler 先后被触发,走完一个流程
-
代码流程:
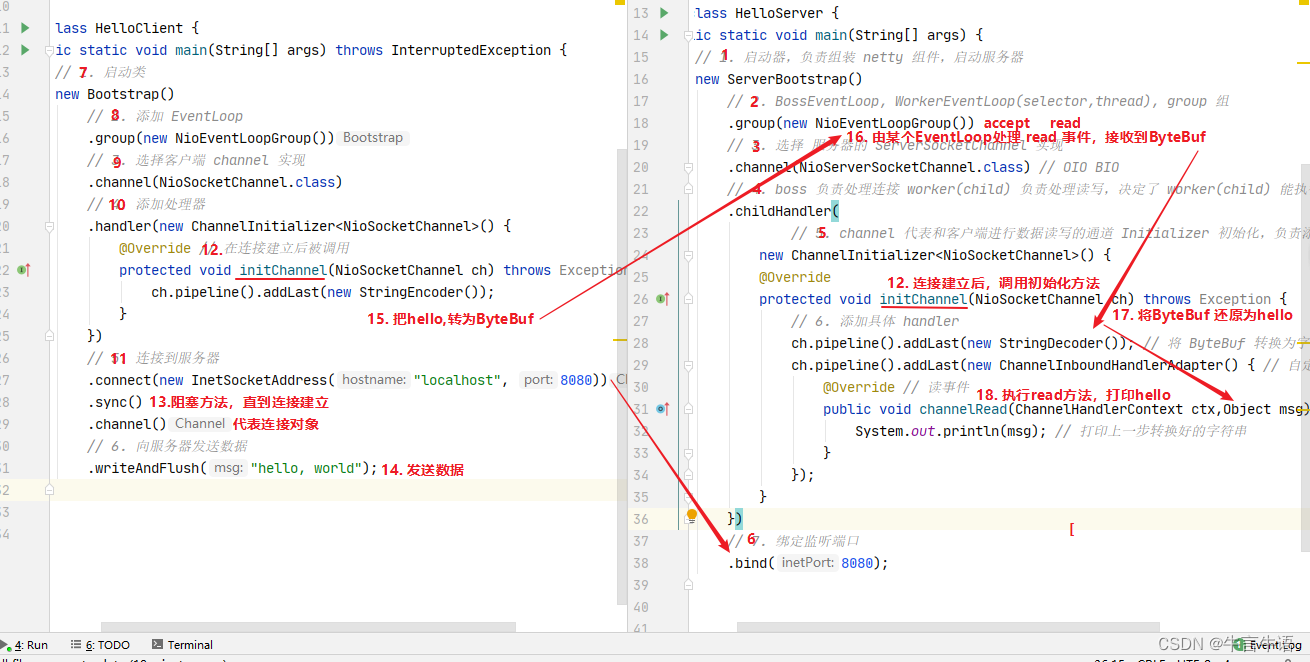
- 把 channel 理解为数据的通道
- 把 msg 理解为流动的数据,例如最开始输入是 ByteBuf,但经过 pipeline 的加工,会变成其它类型对象,最后输出又变成 ByteBuf
- 把 handler 理解为数据的处理工序
- 工序有多道,合在一起就是 pipeline,pipeline 负责发布事件(读、读取完成…)传播给每个 handler, handler 对自己感兴趣的事件进行处理(重写了相应事件处理方法)
- handler 分 Inbound(入站) 和 Outbound(出站) 两类
- 把 eventLoop 理解为处理数据的工人
- 工人可以管理多个 channel 的 io 操作,并且一旦工人负责了某个 channel,就要负责到底(绑定)
- 工人既可以执行 io 操作,也可以进行任务处理,每位工人有任务队列,队列里可以堆放多个 channel 的待处理任务,任务分为普通任务、定时任务
- 工人按照 pipeline 顺序,依次按照 handler 的规划(代码)处理数据,可以为每道工序指定不同的工人
3.Netty 的组件
3.1 EventLoop & EventLoopGroup
- 事件循环对象
EventLoop 本质是一个单线程执行器(同时维护了一个 Selector),里面有 run 方法处理 Channel 上源源不断的 io 事件
所以EventLoop既可以执行普通run()方法、定时任务,也可以处理io事件
它的继承关系比较复杂
- 一条线是继承自 JUC.ScheduledExecutorService 因此包含了线程池中所有的方法
- 另一条线是继承自 netty 自己的 OrderedEventExecutor
- 提供了
boolean inEventLoop(Thread thread)方法判断一个线程是否属于此 EventLoop - 提供了
parent()方法来看看自己属于哪个 EventLoopGroup
- 提供了
-
事件循环组
EventLoopGroup 是一组 EventLoop,Channel 一般会调用 EventLoopGroup 的 register 方法来绑定其中一个 EventLoop,后续这个 Channel 上的 io 事件都由此 EventLoop 来处理(保证了 io 事件处理时的线程安全)
- 继承自 netty 自己的 EventExecutorGroup
- 实现了 Iterable 接口提供遍历 EventLoop 的能力
- 另有 next 方法获取集合中下一个 EventLoop
- 继承自 netty 自己的 EventExecutorGroup
1.创建
-
主函数
public static void main(String[] args) throws Exception { // 内部创建了两个 EventLoop, 每个 EventLoop 维护一个线程 // NioEventLoopGroup group = new NioEventLoopGroup(2); //能够执行io事件、普通任务、定时任务 DefaultEventLoopGroup group = new DefaultEventLoopGroup(2); //能够执行普通任务、定时任务 System.out.println(group.next()); System.out.println(group.next()); System.out.println(group.next()); //也可以使用for-each形式输出 for (EventExecutor eventLoop : group) { System.out.println(eventLoop); } }默认线程数 = 核心数 * 2
-
输出
io.netty.channel.DefaultEventLoop@60f82f98 io.netty.channel.DefaultEventLoop@35f983a6 io.netty.channel.DefaultEventLoop@60f82f98 //内部以轮询方式处理任务 io.netty.channel.DefaultEventLoop@60f82f98 io.netty.channel.DefaultEventLoop@35f983a6
2.关闭
推荐使用shutdownGracefully()方法关闭事件循环组。该方法会首先切换EventLoopGroup到关闭状态从而拒绝新的任务的加入,然后在任务队列的任务都处理完成后,停止线程的运行。从而确保整体应用是在正常有序的状态下退出的
public static void main(String[] args) throws IOException, InterruptedException {
NioEventLoopGroup group = new NioEventLoopGroup(2);
group.shutdownGracefully(); //关闭后整个进程才能停止
}
3.NioEventLoop 处理 io 事件
-
服务端
@Slf4j public class Server { public static void main(String[] args) throws Exception { new ServerBootstrap() .group(new NioEventLoopGroup()) .channel(NioServerSocketChannel.class) .childHandler(new ChannelInitializer<NioSocketChannel>() { @Override protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception { nioSocketChannel.pipeline().addLast(new ChannelInboundHandlerAdapter() { @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { ByteBuf buf = (ByteBuf) msg; log.debug(buf.toString(Charset.defaultCharset())); //建议强制使用某个固定字符集 } }); } }).bind(8080); } } -
客户端,启动两次并对输出稍作修改
public class Client { public static void main(String[] args) throws InterruptedException { NioEventLoopGroup nioEventLoopGroup = new NioEventLoopGroup(); Channel channel = new Bootstrap() .group(nioEventLoopGroup) .channel(NioSocketChannel.class) .handler(new ChannelInitializer<NioSocketChannel>() { @Override protected void initChannel(NioSocketChannel ch) { ch.pipeline().addLast(new StringEncoder()); } }) .connect("127.0.0.1", 8080) .sync() .channel(); channel.writeAndFlush("Hello,World!"); Thread.sleep(1000); //直接发送的话服务端会发生粘包,在一行输出 channel.writeAndFlush("你好,世界!"); nioEventLoopGroup.shutdownGracefully(); } } -
输出
20:05:19 [DEBUG] [nioEventLoopGroup-2-2] o.example.Server - Hello,World! 20:05:20 [DEBUG] [nioEventLoopGroup-2-2] o.example.Server - 你好,世界! //可以看到是一个线程在处理消息 20:05:38 [DEBUG] [nioEventLoopGroup-2-1] o.example.Server - Hello,World. 20:05:39 [DEBUG] [nioEventLoopGroup-2-1] o.example.Server - 你好,世界。可以看到两个工人轮流处理 channel,但工人与 channel 之间进行了绑定。head、h1、tail是handler
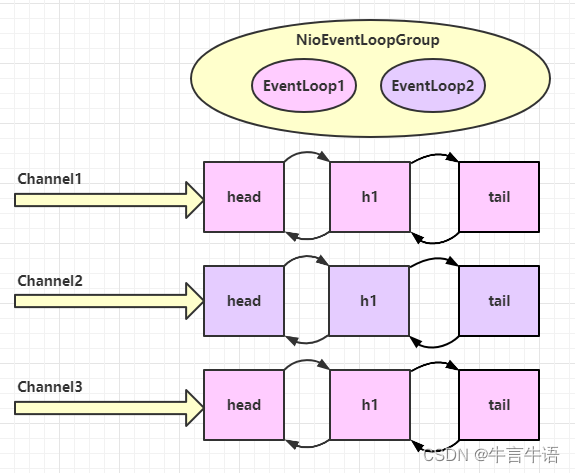
改进:将EventLoop的职责划分清楚,若此时划分 1 个Boss、2 个Worker,需要用到group(EventLoopGroup parentGroup, EventLoopGroup childGroup)方法指定boos和worker
-
服务端
public class Server { public static void main(String[] args) throws Exception { new ServerBootstrap() //第一个只处理ServerSocketChannel的Accept事件,第二个负责SocketChannel上的读写事件 .group(new NioEventLoopGroup(1), new NioEventLoopGroup(2)) .channel(NioServerSocketChannel.class) .childHandler(new ChannelInitializer<NioSocketChannel>() { @Override protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception { nioSocketChannel.pipeline().addLast(new ChannelInboundHandlerAdapter() { @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { ByteBuf buf = (ByteBuf) msg; log.debug(buf.toString(Charset.defaultCharset())); //建议强制使用某个固定字符集 } }); } }).bind(8080); } }Boss的NioEventLoopGroup()不需要指定线程数,因为ServerSocketChannel只有一个,每次都只会使用BossGroup中固定的一个EventLoop
虽然会因为默认而导致EventLoop数量被设置为核心数 * 2,但线程池的线程是随用随创建,不会增加真正的线程数
-
客户端代码不变,启动三次并对输出稍作修改
public class Client { public static void main(String[] args) throws InterruptedException { Channel channel = new Bootstrap() .group(new NioEventLoopGroup()) .channel(NioSocketChannel.class) .handler(new ChannelInitializer<NioSocketChannel>() { @Override protected void initChannel(NioSocketChannel ch) { ch.pipeline().addLast(new StringEncoder()); } }) .connect("127.0.0.1", 8080) .sync() .channel(); channel.writeAndFlush("Hello,World?"); Thread.sleep(1000); channel.writeAndFlush("你好,世界?"); } } -
输出
20:29:44 [DEBUG] [nioEventLoopGroup-3-1] o.example.Server - Hello,World! 20:29:45 [DEBUG] [nioEventLoopGroup-3-1] o.example.Server - 你好,世界! 20:30:00 [DEBUG] [nioEventLoopGroup-3-2] o.example.Server - Hello,World. 20:30:01 [DEBUG] [nioEventLoopGroup-3-2] o.example.Server - 你好,世界。 20:30:07 [DEBUG] [nioEventLoopGroup-3-1] o.example.Server - Hello,World? 20:30:08 [DEBUG] [nioEventLoopGroup-3-1] o.example.Server - 你好,世界?
再改进:假设hanler2耗时较长,那么就会耽误当前EventLoop处理其他连接的读写事件,所以可以将耗时较长的Handler分发给另一个独立的EventLoopGroup处理
-
服务端
public class Server { public static void main(String[] args) throws Exception { //使用DefaultEventLoopGroup处理handler2 DefaultEventLoopGroup defaultEventLoopGroup = new DefaultEventLoopGroup(); new ServerBootstrap() .group(new NioEventLoopGroup(1), new NioEventLoopGroup(2)) .channel(NioServerSocketChannel.class) .childHandler(new ChannelInitializer<NioSocketChannel>() { @Override protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception { nioSocketChannel.pipeline().addLast("h1", new ChannelInboundHandlerAdapter() { //h1 @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { ByteBuf buf = (ByteBuf) msg; log.debug(buf.toString(Charset.defaultCharset())); ctx.fireChannelRead(msg); //传递消息给下一个handler } }); nioSocketChannel.pipeline().addLast(defaultEventLoopGroup, "h2", new ChannelInboundHandlerAdapter() { //h2 @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { ByteBuf buf = (ByteBuf) msg; log.debug(buf.toString(Charset.defaultCharset())); } }); } }).bind(8080); } } -
客户端
public class Client { public static void main(String[] args) throws InterruptedException { Channel channel = new Bootstrap() .group(new NioEventLoopGroup()) .channel(NioSocketChannel.class) .handler(new ChannelInitializer<NioSocketChannel>() { @Override protected void initChannel(NioSocketChannel ch) { ch.pipeline().addLast(new StringEncoder()); } }) .connect("127.0.0.1", 8080) .sync() .channel(); channel.writeAndFlush("Hello,World."); } } -
输出
20:47:43 [DEBUG] [nioEventLoopGroup-4-1] o.example.Server - Hello,World. 20:47:43 [DEBUG] [defaultEventLoopGroup-2-1] o.example.Server - Hello,World. //由defaultEventLoopGroup处理h2可以看到 h1 由
nioEventLoopGroup执行,而 h2 由defaultEventLoopGroup执行。优势是即使第一条消息的 h2 没有执行完,也不会妨碍 h1 接受下一条消息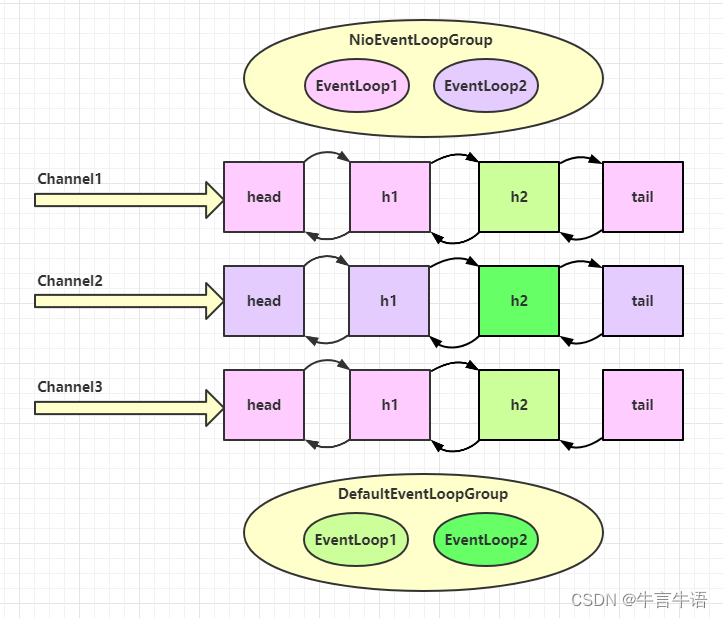
问题:handler 执行中如何切换 EnentLoop 的?
当handler执行完毕时,会执行关键代码
io.netty.channel.AbstractChannelHandlerContext#invokeChannelRead()判断是否需要更换线程static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) { final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next); // 下一个 handler 的事件循环是否与当前的事件循环是同一个线程 EventExecutor executor = next.executor(); // 是,直接调用 if (executor.inEventLoop()) { next.invokeChannelRead(m); } // 不是,将要执行的代码作为任务提交给下一个事件循环处理(换人) else { executor.execute(new Runnable() { @Override public void run() { next.invokeChannelRead(m); } }); } }
- 如果两个 handler 绑定的是同一个线程,那么就直接调用
- 否则,把要调用的代码封装为一个任务对象,由下一个 handler 的线程来调用
4.NioEventLoop 处理普通任务
NioEventLoop 除了可以处理 io 事件,同样可以向它提交普通任务
public static void main(String[] args) throws Exception {
NioEventLoopGroup nioWorkers = new NioEventLoopGroup(2);
log.debug("server start...");
Thread.sleep(2000);
nioWorkers.execute(() -> {
log.debug("normal task...");
});
Future<Integer> submit = nioWorkers.submit(() -> { //与execute()方法效果相同,但submit()方法有返回值
return 100;
});
log.debug(submit.get().toString());
}
输出
19:42:19 [DEBUG] [main] o.example.Server - server start...
19:42:21 [DEBUG] [nioEventLoopGroup-2-1] o.example.Server - normal task...
19:42:21 [DEBUG] [main] o.example.Server - 100
可以用来执行耗时较长的任务
5.NioEventLoop 处理定时任务
public static void main(String[] args) throws IOException, InterruptedException, ExecutionException {
NioEventLoopGroup nioWorkers = new NioEventLoopGroup(2);
log.debug("server start...");
Thread.sleep(2000);
nioWorkers.scheduleAtFixedRate(() -> {
log.debug("running...");
}, 0, 1, TimeUnit.SECONDS); //四个参数:定时任务、初始时间、间隔时间、时间单位
}
输出
19:43:35 [DEBUG] [main] o.example.Server - server start...
19:43:37 [DEBUG] [nioEventLoopGroup-2-1] o.example.Server - running...
19:43:38 [DEBUG] [nioEventLoopGroup-2-1] o.example.Server - running...
19:43:39 [DEBUG] [nioEventLoopGroup-2-1] o.example.Server - running...
19:43:40 [DEBUG] [nioEventLoopGroup-2-1] o.example.Server - running...
...
3.2 Channel
通过ChannelFuture对象的Channel()方法可以获得nio连接的channel对象
channel 的主要方法:
close()可以用来关闭 channelcloseFuture也可以用来处理 channel 的关闭sync()方法作用是同步等待 channel 关闭addListener()方法是异步等待 channel 关闭
pipeline()方法添加处理器write()方法将数据写入writeAndFlush()方法将数据写入并刷出
1.ChannelFuture
connect()方法会返回一个ChannelFuture对象
由于服务端代码复杂,以举例客户端代码为主。简写的客户端代码:
public class Client {
public static void main(String[] args) throws InterruptedException {
new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) {
ch.pipeline().addLast(new StringEncoder());
}
})
.connect("127.0.0.1", 8080)
.sync()
.channel()
.writeAndFlush("Hello,World.");
}
}
现在把它拆开来看
public class Client {
public static void main(String[] args) throws InterruptedException {
ChannelFuture channelFuture = new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) {
ch.pipeline().addLast(new StringEncoder());
}
})
.connect("127.0.0.1", 8080); //返回的是 ChannelFuture 对象,它的作用是利用`channel()`方法来获取 Channel 对象
channelFuture.sync();
Channel channel = channelFuture.channel();
channel.writeAndFlush("Hello,World.");
}
}
注意:connect()方法是异步非阻塞的,意味着不等连接建立,主线程就可以继续向下执行。因此 channelFuture 对象中不能立刻获得到正确的 Channel 对象,可能会出现无法发送消息的错误
举例:
ChannelFuture channelFuture = new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<Channel>() {
@Override
protected void initChannel(Channel ch) {
ch.pipeline().addLast(new StringEncoder());
}
})
.connect("127.0.0.1", 8080);
log.debug("{}", channelFuture.channel()); // 1
channelFuture.sync(); // 2
log.debug("{}", channelFuture.channel()); // 3
- 执行到 1 时,连接未建立,打印
[id: 0x2e1884dd] - 执行到 2 时,
sync()方法是阻塞住当前线程,直到nio线程连接建立完成。[要么采用sleep的方式,使主线程休眠一会也能正确获得 channel ] - 执行到 3 时,连接建立,打印
[id: 0x2e1884dd, L:/127.0.0.1:57191 - R:/127.0.0.1:8080]
除了用sync()方法可以让异步操作同步以外,还可以使用回调的方式:
ChannelFuture channelFuture = new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<Channel>() {
@Override
protected void initChannel(Channel ch) {
ch.pipeline().addLast(new StringEncoder());
}
})
.connect("127.0.0.1", 8080);
log.debug("{}", channelFuture.channel()); // 1
connectFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
log.debug("{}", channelFuture.channel()); // 2
}
});
- 执行到 1 时,连接未建立,打印
[id: 0x749124ba] - ChannelFutureListener 会在连接建立时由建立nio连接的线程调用(其中的
operationComplete()方法),因此执行到 2 时,连接肯定建立了,打印[id: 0x749124ba, L:/127.0.0.1:57351 - R:/127.0.0.1:8080]
2.CloseFuture
channel.close()方法也是一个异步非阻塞的方法,如果不等待关闭连接就处理后续操作也可能出现问题,举例:
public class Client {
public static void main(String[] args) throws InterruptedException {
ChannelFuture channelFuture = new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) {
//使用Netty提供的LoggingHandler指定输出级别为debug,可以方便观察每一步的状态
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
ch.pipeline().addLast(new StringEncoder());
}
})
.connect("127.0.0.1", 8080);
Channel channel = channelFuture.sync().channel();
log.debug("{}", channel);
new Thread(() -> {
Scanner scanner = new Scanner(System.in);
while (true) {
String line = scanner.nextLine();
if ("Q".equals(line)) {
channel.close();
log.debug("处理关闭后操作");
break;
}
channel.writeAndFlush(line);
}
}, "input").start();
}
}
需要修改
logback.xml的日志级别才能使LoggingHandler正确输出日志<logger name="io.netty.handler.logging.LoggingHandler" level="DEBUG" additivity="false"> <appender-ref ref="STDOUT"/> </logger>
14:00:34 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x223434c1] REGISTERED
14:00:34 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x223434c1] CONNECT: /127.0.0.1:8080
14:00:34 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x223434c1, L:/127.0.0.1:57927 - R:/127.0.0.1:8080] ACTIVE
14:00:34 [DEBUG] [main] o.example.Client - [id: 0x223434c1, L:/127.0.0.1:57927 - R:/127.0.0.1:8080]
aabb
14:00:35 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x223434c1, L:/127.0.0.1:57927 - R:/127.0.0.1:8080] WRITE: 4B
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 61 62 62 |aabb |
+--------+-------------------------------------------------+----------------+
14:00:35 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x223434c1, L:/127.0.0.1:57927 - R:/127.0.0.1:8080] FLUSH
Q
14:01:14 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x223434c1, L:/127.0.0.1:57927 - R:/127.0.0.1:8080] CLOSE // 1.
14:01:14 [DEBUG] [input] o.example.Client - 处理关闭后操作 // 2.
14:01:14 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x223434c1, L:/127.0.0.1:57927 ! R:/127.0.0.1:8080] INACTIVE
14:01:14 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x223434c1, L:/127.0.0.1:57927 ! R:/127.0.0.1:8080] UNREGISTERED
注意:可以看到关闭nio连接和处理关闭后操作是由两个不同的线程完成的,这就导致可能nio连接还未关闭,后续操作就开始处理了
Netty 提供了ClosedFuture对象处理关闭操作,可以有两种关闭方法:1.同步处理关闭操作 2.异步处理关闭操作
-
同步处理关闭操作
public class Client { public static void main(String[] args) throws InterruptedException { ChannelFuture channelFuture = new Bootstrap() .group(new NioEventLoopGroup()) .channel(NioSocketChannel.class) .handler(new ChannelInitializer<NioSocketChannel>() { @Override protected void initChannel(NioSocketChannel ch) { //使用Netty提供的LoggingHandler指定输出级别为debug,可以方便观察每一步的状态 ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG)); ch.pipeline().addLast(new StringEncoder()); } }) .connect("127.0.0.1", 8080); Channel channel = channelFuture.sync().channel(); log.debug("{}", channel); new Thread(() -> { Scanner scanner = new Scanner(System.in); while (true) { String line = scanner.nextLine(); if ("Q".equals(line)) { channel.close(); break; } channel.writeAndFlush(line); } }, "input").start(); ChannelFuture closeFuture = channel.closeFuture(); //同步阻塞式关闭连接 log.debug("等待断开连接"); closeFuture.sync(); log.debug("已断开连接"); } }14:17:47 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x7d57f6dc] REGISTERED 14:17:47 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x7d57f6dc] CONNECT: /127.0.0.1:8080 14:17:47 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x7d57f6dc, L:/127.0.0.1:58472 - R:/127.0.0.1:8080] ACTIVE 14:17:47 [DEBUG] [main] o.example.Client - [id: 0x7d57f6dc, L:/127.0.0.1:58472 - R:/127.0.0.1:8080] 14:17:47 [DEBUG] [main] o.example.Client - 等待断开连接 Q 14:17:49 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x7d57f6dc, L:/127.0.0.1:58472 - R:/127.0.0.1:8080] CLOSE 14:17:49 [DEBUG] [main] o.example.Client - 已断开连接 14:17:49 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x7d57f6dc, L:/127.0.0.1:58472 ! R:/127.0.0.1:8080] INACTIVE 14:17:49 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0x7d57f6dc, L:/127.0.0.1:58472 ! R:/127.0.0.1:8080] UNREGISTERED等待断开连接和已断开连接都是由主线程执行,且已断开连接一定会阻塞等待真正断开连接时才执行
-
异步处理关闭操作
public class Client { public static void main(String[] args) throws InterruptedException { ChannelFuture channelFuture = new Bootstrap() .group(new NioEventLoopGroup()) .channel(NioSocketChannel.class) .handler(new ChannelInitializer<NioSocketChannel>() { @Override protected void initChannel(NioSocketChannel ch) { //使用Netty提供的LoggingHandler指定输出级别为debug,可以方便观察每一步的状态 ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG)); ch.pipeline().addLast(new StringEncoder()); } }) .connect("127.0.0.1", 8080); Channel channel = channelFuture.sync().channel(); log.debug("{}", channel); new Thread(() -> { Scanner scanner = new Scanner(System.in); while (true) { String line = scanner.nextLine(); if ("Q".equals(line)) { channel.close(); break; } channel.writeAndFlush(line); } }, "input").start(); ChannelFuture closeFuture = channel.closeFuture(); log.debug("等待断开连接"); closeFuture.addListener(new ChannelFutureListener() { //添加Listener,由关闭nio连接的线程执行operationComplete()方法 @Override public void operationComplete(ChannelFuture future) throws Exception { log.debug("已断开连接"); } }); } }14:20:21 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0xb0a7ce69] REGISTERED 14:20:21 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0xb0a7ce69] CONNECT: /127.0.0.1:8080 14:20:21 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0xb0a7ce69, L:/127.0.0.1:58599 - R:/127.0.0.1:8080] ACTIVE 14:20:21 [DEBUG] [main] o.example.Client - [id: 0xb0a7ce69, L:/127.0.0.1:58599 - R:/127.0.0.1:8080] 14:20:21 [DEBUG] [main] o.example.Client - 等待断开连接 Q 14:20:25 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0xb0a7ce69, L:/127.0.0.1:58599 - R:/127.0.0.1:8080] CLOSE 14:20:25 [DEBUG] [nioEventLoopGroup-2-1] o.example.Client - 已断开连接 //与断开连接的线程是同一个线程 14:20:25 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0xb0a7ce69, L:/127.0.0.1:58599 ! R:/127.0.0.1:8080] INACTIVE 14:20:25 [DEBUG] [nioEventLoopGroup-2-1] i.n.h.l.LoggingHandler - [id: 0xb0a7ce69, L:/127.0.0.1:58599 ! R:/127.0.0.1:8080] UNREGISTERED
3.异步的提升
问题:
-
为什么不在一个线程中去执行建立连接、去执行关闭 channel,那样不是也可以吗?非要用这么复杂的异步方式:比如一个线程发起建立连接,另一个线程去真正建立连接
-
笼统地回答:因为 netty 异步方式用了多线程、多线程就效率高。其实这些认识都比较片面,多线程和异步所提升的效率并不是所认为的
思考下面的场景,4 个医生给人看病,每个病人花费 20 分钟,而且医生看病的过程中是以病人为单位的,一个病人看完了,才能看下一个病人。假设病人源源不断地来,可以计算一下 4 个医生一天工作 8 小时,处理的病人总数是:4 * 8 * 3 = 96
经研究发现,看病可以细分为四个步骤,经拆分后每个步骤需要 5 分钟,如下
因此可以做如下优化,只有一开始,医生 2、3、4 分别要等待 5、10、15 分钟才能执行工作,但只要后续病人源源不断地来,他们就能够满负荷工作,并且处理病人的能力提高到了 4 * 8 * 12 效率几乎是原来的四倍
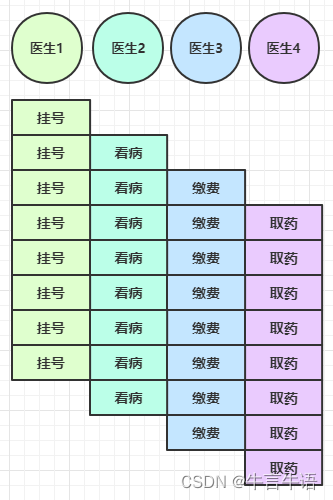
要点
- 单线程没法异步提高效率,必须配合多线程、多核 cpu 才能发挥异步的优势
- 异步并没有缩短响应时间,反而有所增加
- 合理进行任务拆分,也是利用异步的关键
3.3 Future & Promise
在异步处理时,经常用到这两个接口
首先要说明 netty 中的 Future 与 jdk 中的 Future 同名,但是是两个接口,netty 的 Future 继承自 jdk 的 Future,而 Promise 又对 netty Future 进行了扩展
- jdk Future 只能同步等待任务结束(成功或失败)才能得到结果
- netty Future 可以同步等待任务结束得到结果,也可以异步方式得到结果,但都是要等任务结束
- netty Promise 不仅有 netty Future 的功能,而且脱离了任务独立存在,只作为两个线程间传递结果的容器
| 功能/名称 | jdk Future | netty Future | Promise |
|---|---|---|---|
| cancel | 取消任务 | - | - |
| isCanceled | 任务是否取消 | - | - |
| isDone | 任务是否完成,不能区分成功失败 | - | - |
| get | 获取任务结果,阻塞等待 | - | - |
| getNow | - | 获取任务结果,非阻塞,还未产生结果时返回 null | - |
| await | - | 等待任务结束,如果任务失败,不会抛异常,而是通过 isSuccess 判断 | - |
| sync | - | 等待任务结束,如果任务失败,抛出异常 | - |
| isSuccess | - | 判断任务是否成功 | - |
| cause | - | 获取失败信息,非阻塞,如果没有失败,返回null | - |
| addLinstener | - | 添加回调,异步接收结果 | - |
| setSuccess | - | - | 设置成功结果 |
| setFailure | - | - | 设置失败结果 |
1.jdk Future
1.同步任务
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(1);
Future<?> submit = executorService.submit(() -> {
log.debug("执行计算");
Thread.sleep(1000);
return 100;
});
log.debug("等待结果");
log.debug("结果是 {}", submit.get()); //阻塞等待结果
}
18:05:36 [DEBUG] [pool-1-thread-1] org.example.Main - 执行计算
18:05:36 [DEBUG] [main] org.example.Main - 等待结果
18:05:37 [DEBUG] [main] org.example.Main - 结果是 100
2.netty Future
1.同步任务
public static void main(String[] args) throws Exception {
EventLoop eventLoop = new NioEventLoopGroup().next();
Future<Integer> future = eventLoop.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
log.debug("执行计算");
Thread.sleep(1000);
return 100;
}
});
log.debug("等待结果");
log.debug("结果是 {}", future.get()); //阻塞等待结果
}
18:09:36 [DEBUG] [nioEventLoopGroup-2-1] org.example.Main - 执行计算
18:09:36 [DEBUG] [main] org.example.Main - 等待结果
18:09:37 [DEBUG] [main] org.example.Main - 结果是 100
2.异步任务
public static void main(String[] args) throws Exception {
EventLoop eventLoop = new NioEventLoopGroup().next();
Future<Integer> future = eventLoop.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
log.debug("执行计算");
Thread.sleep(1000);
return 100;
}
});
future.addListener(new GenericFutureListener<Future<? super Integer>>() {
@Override
public void operationComplete(Future<? super Integer> future) throws Exception {
log.debug("等待结果");
log.debug("结果是 {}", future.getNow()); //异步返回结果,不会发生阻塞
}
});
}
18:11:15 [DEBUG] [nioEventLoopGroup-2-1] org.example.Main - 执行计算
18:11:16 [DEBUG] [nioEventLoopGroup-2-1] org.example.Main - 等待结果
18:11:16 [DEBUG] [nioEventLoopGroup-2-1] org.example.Main - 结果是 100
3.Promise
1.同步处理任务成功
public static void main(String[] args) throws Exception {
DefaultEventLoop eventExecutors = new DefaultEventLoop();
DefaultPromise<Integer> promise = new DefaultPromise<>(eventExecutors); //创建结果对象
eventExecutors.execute(() -> {
try {
log.debug("执行计算");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
promise.setSuccess(100);
log.debug("set success, {}", 100);
});
log.debug("等待结果");
log.debug("结果是 {}", promise.getNow()); // 还没有结果,返回null
log.debug("结果是 {}", promise.get());
}
18:18:22 [DEBUG] [defaultEventLoop-1-1] org.example.Main - 执行计算
18:18:22 [DEBUG] [main] org.example.Main - 等待结果
18:18:22 [DEBUG] [main] org.example.Main - 结果是 null
18:18:23 [DEBUG] [defaultEventLoop-1-1] org.example.Main - set success, 100
18:18:23 [DEBUG] [main] org.example.Main - 结果是 100
2.异步处理任务成功
public static void main(String[] args) throws Exception {
DefaultEventLoop eventExecutors = new DefaultEventLoop();
DefaultPromise<Integer> promise = new DefaultPromise<>(eventExecutors);
eventExecutors.execute(() -> {
try {
log.debug("执行计算");
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
log.debug("set success, {}", 100);
promise.setSuccess(100);
});
promise.addListener(future -> { // 设置回调,异步接收结果
// 这里的 future 就是上面的 promise
log.debug("结果是 {}", future.getNow());
});
}
18:42:13 [DEBUG] [defaultEventLoop-1-1] org.example.Main - 执行计算
18:42:14 [DEBUG] [defaultEventLoop-1-1] org.example.Main - set success, 100
18:42:14 [DEBUG] [defaultEventLoop-1-1] org.example.Main - 结果是 100
3.同步处理任务失败 - sync & get
public static void main(String[] args) throws Exception {
DefaultEventLoop eventExecutors = new DefaultEventLoop();
DefaultPromise<Integer> promise = new DefaultPromise<>(eventExecutors);
eventExecutors.execute(() -> {
try {
log.debug("执行计算");
Thread.sleep(1000);
int i = 1 / 0;
} catch (Exception e) {
promise.setFailure(e); //设置失败值
log.debug("set failure, {}", e.toString());
}
});
log.debug("等待结果");
log.debug("结果是 {}", promise.getNow());
promise.sync(); //有异常时会抛出
log.debug("结果是 {}", promise.get()); // get() 也会抛出异常,但是会用 ExecutionException 包一层异常
}
18:26:45 [DEBUG] [main] org.example.Main - 等待结果
18:26:45 [DEBUG] [defaultEventLoop-1-1] org.example.Main - 执行计算
18:26:45 [DEBUG] [main] org.example.Main - 结果是 null
18:26:46 [DEBUG] [defaultEventLoop-1-1] org.example.Main - set failure, java.lang.ArithmeticException: / by zero
Exception in thread "main" java.util.concurrent.ExecutionException: java.lang.ArithmeticException: / by zero
at io.netty.util.concurrent.AbstractFuture.get(AbstractFuture.java:41)
at org.example.Main.main(Main.java:32)
Caused by: java.lang.ArithmeticException: / by zero
...
at java.lang.Thread.run(Thread.java:750)
4.同步处理任务失败 - await
public static void main(String[] args) throws Exception {
DefaultEventLoop eventExecutors = new DefaultEventLoop();
DefaultPromise<Integer> promise = new DefaultPromise<>(eventExecutors);
eventExecutors.execute(() -> {
try {
log.debug("执行计算");
Thread.sleep(1000);
int i = 1 / 0;
} catch (Exception e) {
promise.setFailure(e);
log.debug("set failure, {}", e.toString());
}
});
log.debug("等待结果");
log.debug("结果是 {}", promise.getNow());
promise.await(); // 可添加超时时间。与 sync() 和 get() 区别在于,不会抛异常
log.debug("结果是 {}", (promise.isSuccess() ? promise.getNow() : promise.cause()).toString());
}
18:39:38 [DEBUG] [defaultEventLoop-1-1] org.example.Main - 执行计算
18:39:38 [DEBUG] [main] org.example.Main - 等待结果
18:39:38 [DEBUG] [main] org.example.Main - 结果是 null
18:39:39 [DEBUG] [defaultEventLoop-1-1] org.example.Main - set failure, java.lang.ArithmeticException: / by zero
18:39:39 [DEBUG] [main] org.example.Main - 结果是 java.lang.ArithmeticException: / by zero
5.异步处理任务失败
public static void main(String[] args) throws Exception {
DefaultEventLoop eventExecutors = new DefaultEventLoop();
DefaultPromise<Integer> promise = new DefaultPromise<>(eventExecutors);
eventExecutors.execute(() -> {
try {
log.debug("执行计算");
Thread.sleep(1000);
int i = 1 / 0;
} catch (Exception e) {
promise.setFailure(e);
log.debug("set failure, {}", e.toString());
}
});
promise.addListener(future -> {
log.debug("结果是 {}", (promise.isSuccess() ? promise.getNow() : promise.cause()).toString());
});
}
18:42:51 [DEBUG] [defaultEventLoop-1-1] org.example.Main - 执行计算
18:42:52 [DEBUG] [defaultEventLoop-1-1] org.example.Main - 结果是 java.lang.ArithmeticException: / by zero
18:42:52 [DEBUG] [defaultEventLoop-1-1] org.example.Main - set failure, java.lang.ArithmeticException: / by zero
6.await 死锁检查
public static void main(String[] args) throws Exception {
DefaultEventLoop eventExecutors = new DefaultEventLoop();
DefaultPromise<Integer> promise = new DefaultPromise<>(eventExecutors);
eventExecutors.submit(() -> {
System.out.println("1");
try {
promise.await();
// 注意不能仅捕获 InterruptedException 异常
// 否则 死锁检查抛出的 BlockingOperationException 会继续向上传播
// 而提交的任务会被包装为 PromiseTask,它的 run 方法中会 catch 所有异常然后设置为 Promise 的失败结果而不会抛出
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("2");
});
eventExecutors.submit(() -> {
System.out.println("3");
try {
promise.await();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("4");
});
}
输出
1
2
3
4
io.netty.util.concurrent.BlockingOperationException: DefaultPromise@74eb3598(incomplete)
...
io.netty.util.concurrent.BlockingOperationException: DefaultPromise@74eb3598(incomplete)
...
at java.lang.Thread.run(Thread.java:750)
3.4 Handler & Pipeline
1.Pipeline 的执行流程
ChannelHandler 用来处理 Channel 上的各种事件,分为入站、出站两种。所有 ChannelHandler 被连成一串,就是 Pipeline
- 入站处理器通常是 ChannelInboundHandlerAdapter 的子类,主要用来读取客户端数据,写回结果
- 出站处理器通常是 ChannelOutboundHandlerAdapter 的子类,主要对写回结果进行加工
打个比喻,每个 Channel 是一个产品的加工车间,Pipeline 是车间中的流水线,ChannelHandler 就是流水线上的各道工序,而后面要讲的 ByteBuf 是原材料,经过很多工序的加工:先经过一道道入站工序,再经过一道道出站工序最终变成产品
-
服务端
public class Server { public static void main(String[] args) throws Exception { new ServerBootstrap() .group(new NioEventLoopGroup()) .channel(NioServerSocketChannel.class) .childHandler(new ChannelInitializer<NioSocketChannel>() { protected void initChannel(NioSocketChannel ch) { ch.pipeline().addLast("h1", new ChannelInboundHandlerAdapter() { //入站处理器 @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { System.out.println(1); ctx.fireChannelRead(msg); // 1 } }); ch.pipeline().addLast("h2", new ChannelInboundHandlerAdapter() { //入站处理器 @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { System.out.println(2); ctx.fireChannelRead(msg); // 2 } }); ch.pipeline().addLast("h3", new ChannelInboundHandlerAdapter() { @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { System.out.println(3); // 3 只有向channel写入数据才会触发出站处理器 ctx.channel().writeAndFlush(ctx.alloc().buffer().writeBytes("this is server".getBytes())); // ch.writeAndFlush(ctx.alloc().buffer().writeBytes("this is server".getBytes())); //效果一致 } }); ch.pipeline().addLast("h4", new ChannelOutboundHandlerAdapter() { //出站处理器 @Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) { System.out.println(4); ctx.write(msg, promise); // 4 } }); ch.pipeline().addLast("h5", new ChannelOutboundHandlerAdapter() { @Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) { System.out.println(5); ctx.write(msg, promise); // 5 } }); ch.pipeline().addLast("h6", new ChannelOutboundHandlerAdapter() { @Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) { System.out.println(6); ctx.write(msg, promise); // 6 } }); } }) .bind(8080); } } -
客户端
public class Client { public static void main(String[] args) throws InterruptedException { new Bootstrap() .group(new NioEventLoopGroup()) .channel(NioSocketChannel.class) .handler(new ChannelInitializer<Channel>() { @Override protected void initChannel(Channel ch) { ch.pipeline().addLast(new StringEncoder()); } }) .connect("127.0.0.1", 8080) .sync() .channel() .writeAndFlush("hello,world"); } } -
服务端输出
1 2 3 6 5 4
可以看到,ChannelInboundHandlerAdapter 是按照 addLast 的顺序执行的,而 ChannelOutboundHandlerAdapter 是按照 addLast 的逆序执行的。ChannelPipeline 的实现是一个 ChannelHandlerContext(包装了 ChannelHandler) 组成的双向链表

-
入站处理器中,
ctx.fireChannelRead(msg)是调用下一个入站处理器- 如果注释掉 1 处代码,则仅会打印 1
- 如果注释掉 2 处代码,则仅会打印 1 2
-
3 处的
ctx.channel().writeAndFlush(ctx.alloc().buffer().writeBytes("this is server".getBytes()));会从尾部开始触发后续出站处理器的执行- 如果注释掉 3 处代码,则仅会打印 1 2 3
-
类似的,出站处理器中,
ctx.write(msg, promise)的调用会触发上一个出站处理器- 如果注释掉 6 处代码,则仅会打印 1 2 3 6
注意:
ctx.channel().write(msg)vsctx.write(msg)- 都是触发出站处理器的执行
ctx.channel().write(msg)从尾部开始查找出站处理器ctx.write(msg)是从当前节点找上一个出站处理器- 3 处的
ctx.channel().write(msg)如果改为ctx.write(msg)仅会打印 1 2 3,因为节点 3 之前没有其它出站处理器了 - 6 处的
ctx.write(msg, promise)如果改为ctx.channel().write(msg)会打印 1 2 3 6 6 6… 因为ctx.channel().write()是从尾部开始查找,结果又是节点6 自己
服务端 pipeline 触发的原始流程,图中数字代表了处理步骤的先后次序
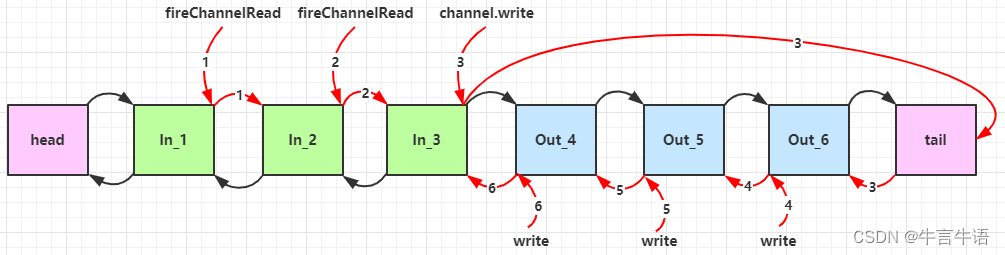
2.Handler 的消息传递
在 pipeline 的处理流程中,可以将上一个 handler 的处理流程传递给下一个 handler
protected void initChannel(NioSocketChannel ch) {
ch.pipeline().addLast("h1", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf buf = (ByteBuf) msg;
String str = buf.toString(Charset.defaultCharset());
ctx.fireChannelRead(str); // 将处理结果传递给下一个handler
}
});
ch.pipeline().addLast("h2", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
System.out.println(msg.toString());
// ctx.fireChannelRead(str); //后续没有入站处理器的话可以不进行处理
}
});
}
3.EmbeddedChannel 测试类
Netty 提供了它所谓的 Embedded 传输,用于测试 ChannelHandler。这个传输是一种特殊的 Channel 实现— EmbeddedChannel— 的功能,这个实现提供了通过 ChannelPipeline 传播事件的简便方法
public static void main(String[] args) throws Exception {
ChannelInboundHandlerAdapter h1 = new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("1");
super.channelRead(ctx, msg);
}
};
ChannelInboundHandlerAdapter h2 = new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("2");
super.channelRead(ctx, msg);
}
};
ChannelOutboundHandlerAdapter h3 = new ChannelOutboundHandlerAdapter() {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("3");
super.write(ctx, msg, promise);
}
};
ChannelOutboundHandlerAdapter h4 = new ChannelOutboundHandlerAdapter() {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("4");
super.write(ctx, msg, promise);
}
};
EmbeddedChannel channel = new EmbeddedChannel(h1, h2, h3, h4);
//模拟入站操作
channel.writeInbound(ByteBufAllocator.DEFAULT.buffer().writeBytes("hello".getBytes())); //只输出1,2
//模拟出站操作
channel.writeOutbound(ByteBufAllocator.DEFAULT.buffer().writeBytes("world".getBytes()));//只输出3,4
}
3.5 ByteBuf
是对字节数据的封装,且具有以下优势:
- 池化 - 可以重用池中 ByteBuf 实例,更节约内存,减少内存溢出的可能
- 读写指针分离,不需要像 ByteBuffer 一样切换读写模式
- 可以自动扩容
- 支持链式调用,使用更流畅
- 很多地方体现零拷贝,例如 slice、duplicate、CompositeByteBuf
1.创建
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10); //创建了一个默认的 ByteBuf(池化基于直接内存的 ByteBuf),初始容量是 10,可以自动扩容
log(buffer);
read index:0 write index:0 capacity:10
其中 log() 方法参考如下
private static void log(ByteBuf buffer) {
int length = buffer.readableBytes();
int rows = length / 16 + (length % 15 == 0 ? 0 : 1) + 4;
StringBuilder buf = new StringBuilder(rows * 80 * 2)
.append("read index:").append(buffer.readerIndex())
.append(" write index:").append(buffer.writerIndex())
.append(" capacity:").append(buffer.capacity())
.append(io.netty.util.internal.StringUtil.NEWLINE);
io.netty.buffer.ByteBufUtil.appendPrettyHexDump(buf, buffer);
System.out.println(buf.toString());
}
2.直接内存 vs 堆内存
可以使用下面的代码来创建池化基于堆的 ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(10); //分配效率高,读写效率低
也可以使用下面的代码来创建池化基于直接内存的 ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.directBuffer(10); //分配效率低,读写效率高
- 直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用
- 直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放
3.池化 vs 非池化
池化的最大意义在于可以重用 ByteBuf,优点有
- 没有池化,则每次都得创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力
- 有了池化,则可以重用池中 ByteBuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率
- 高并发时,池化功能更节约内存,减少内存溢出的可能
池化功能是否开启,可以通过下面的系统环境变量来设置
-Dio.netty.allocator.type={unpooled|pooled}
- 4.1 以后,非 Android 平台默认启用池化实现,Android 平台启用非池化实现
- 4.1 之前,池化功能还不成熟,默认是非池化实现
4.组成
ByteBuf 由四部分组成
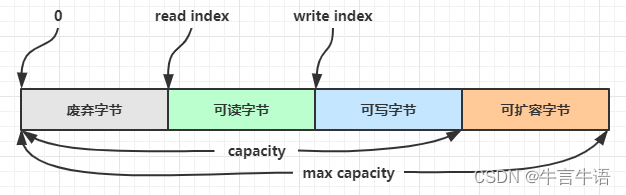
最开始读写指针都在 0 位置,随着数据的写入,写指针后移,直到达到容量后会发生扩容,但不能超过最大容量
对比 NIO 中的 ByteBuff,ByteBuf抛弃了原来只有一个指针,写完后需要flip()才能继续读的问题,且增加了动态扩容的功能
5.写入
方法列表(省略一些不重要的方法)
| 方法签名 | 含义 | 备注 |
|---|---|---|
| writeBoolean(boolean value) | 写入 boolean 值 | 用一字节 01|00 代表 true|false |
| writeByte(int value) | 写入 byte 值 | |
| writeShort(int value) | 写入 short 值 | |
| writeInt(int value) | 写入 int 值 | 大端写入,即 0x250,写入后 00 00 02 50 |
| writeIntLE(int value) | 写入 int 值 | 小端写入,即 0x250,写入后 50 02 00 00 |
| writeLong(long value) | 写入 long 值 | |
| writeChar(int value) | 写入 char 值 | |
| writeFloat(float value) | 写入 float 值 | |
| writeDouble(double value) | 写入 double 值 | |
| writeBytes(ByteBuf src) | 写入 netty 的 ByteBuf | |
| writeBytes(byte[] src) | 写入 byte[] | |
| writeBytes(ByteBuffer src) | 写入 nio 的 ByteBuffer | |
| int writeCharSequence(CharSequence sequence, Charset charset) | 写入字符串 |
注意
- 这些方法的未指明返回值的,其返回值都是 ByteBuf,意味着可以链式调用
- 网络传输,默认习惯是 Big Endian
举例:
-
先写入 4 个字节
buffer.writeBytes(new byte[]{1, 2, 3, 4}); log(buffer);read index:0 write index:4 capacity:10 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 01 02 03 04 |.... | +--------+-------------------------------------------------+----------------+ -
再写入一个 int 整数,也是 4 个字节
buffer.writeInt(5); log(buffer);read index:0 write index:8 capacity:10 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f | +--------+-------------------------------------------------+----------------+ |00000000| 01 02 03 04 00 00 00 05 |........ | +--------+-------------------------------------------------+----------------+
还有一类方法是 set 开头的一系列方法,也可以写入数据,但不会改变写指针位置
6.扩容
再对上例写入一个 int 整数时,容量不够了(初始容量是 10),这时会引发扩容
buffer.writeInt(6);
log(buffer);
扩容规则:
- 如何写入后数据大小未超过 512,则选择下一个 16 的整数倍,例如写入后大小为 12 ,则扩容后 capacity 是 16
- 如果写入后数据大小超过 512,则选择下一个 2^n,例如写入后大小为 513,则扩容后 capacity 是 210=1024(29=512 已经不够了)
- 扩容不能超过 max capacity
结果是
read index:0 write index:12 capacity:16
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 00 00 00 05 00 00 00 06 |............ |
+--------+-------------------------------------------------+----------------+
7.读取
例如读了 4 次,每次一个字节
System.out.println(buffer.readByte());
System.out.println(buffer.readByte());
System.out.println(buffer.readByte());
System.out.println(buffer.readByte());
log(buffer);
1
2
3
4
read index:4 write index:12 capacity:16
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 00 00 00 05 00 00 00 06 |........ |
+--------+-------------------------------------------------+----------------+
读过的内容,就属于废弃部分了,再读只能读那些尚未读取的部分















 1646
1646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









