







当我们再浏览器上访问一个网站,网站有自己的独一无二网址,浏览器通过这个地址,找到服务器。就可以把网页内容显示到用户的计算机上。这个过程前后端是怎样交互的呢。
一:hhtp
1、如何写一个简单的http服务器
知识点:
var app=http.createServer((req,res)=>{}) 创建一个服务器
app.listen(81) //端口的意义:ip是访问计算机的标志 端口就可以进入计算机的具体哪一个程序
res.setHeader( ' Content-Type ' , 'text/plain; charset=utf8 ')//设置编码和数据包格式
res.write("<a>xxx</a>")//可以多次调用 代表给前端传输数据
res.end()//可以传输数据也可以不传输,它是当前这一次网络请求结束的标志,一旦执行了就断开连接
req.url 前端给后端发送网络请求的网址"http://ip:port"后面的部分字符串
解析url来做出不同页面的网址 和不同参数传不同数据网址
//引入node自带的模块 http 这个模块可以调用函数 来创建后端服务器
var http=require("http")
//创建一个服务器对象 回调函数不会直接运行 会在用户每次访问当前计算机的ip下的8081端口
var app=http.createServer((req,res)=>{ // 前端的每一次网络请求,这个函数都会重新运行一次
//req 相当于前端给后端的数据,url属性是端口号后面的路径 http://ip:端口/home
console.log(req.url) //小黑窗会有两次打印,一次请求是浏览器头部的小图标url: /favicon.ico,宁一个就是用户的url:如/home
// 如果客户访问的网址是 http://ip:8081/home,我们(服务器就是我这台电脑)给客户返回下面的内容
if(req.url=="/home"){
//配置返回给用户的数据包 的数据格式 和编码的类型utf8
res.setHeader("content-Type","text/html;charset=utf8")
//res:给前端最后一次发送数据包,就会断掉前端的请求
res.end("<h1>你好 准备下课66666</h1>")//string buffer
}
else if(req.url=="/car"){ //用户可能再次发了个请求,请求的是/car的资源
//配置返回给用户的数据包 的数据格式 和编码的类型utf8
res.setHeader("content-Type","text/html;charset=utf8")
//给前端最后一次发送数据包
res.end("<h1>你好 car 66666</h1>")//string buffer
}
else if(req.url=="/favicon.ico"){
//给前端发送一个小图标
}
else {
//配置返回给用户的数据包 的数据格式 和编码的类型utf8
res.setHeader("content-Type","text/html;charset=utf8")
//给前端最后一次发送数据包
res.end("<h1>你好 你网址乱输的 404 </h1>")//string buffer
}
})
//监听计算机的端口: min-max
app.listen(8081)
2、
1)
cmd.exe这个软件 中输入windows的指令:
node index.js==>
node就是去环境变量中找到这个node变量指向软件
然后用node.exe这个软件(后端环境)去运行index.js

2)我们就在自己的电脑上模拟访问这个服务器,在前端访问的网址: 自己电脑的ip地址:8081/


二:fs
fs模块是对文件操作的模块
路径
全局变量 __dirname是一个字符串,代表当前js文件所在目录的路径(绝对路径)
全局变量 __filename是一个字符串,代表当前js文件的路径(绝对路径)
(1)读取文件
1.引入fs系统自带的模块 file system
var fs=require("fs")
2.使用
var fs=require("fs")
fs.readFile("./src/18.jpg",(err,data)=>{})
// 相对路径,./ 的意思是当前js文件所在的目录
//读取文件成功,err为null,data为二进制包;
//读取文件失败,err为一个错误对象,data为undefined
// 未来我们读取文件,图片返回给前端
注意:fs.readFile()是异步操作,不是谁先运行谁就运行回调函数
3.静态网页实现
前端有一份html文件,要求使用网络协议打开这个网页,就是向服务器请求文件资源。我们就是那台服务器,将html文件返回给用户。这里需要注意的是,fs对html文件的的读取,只是解析了html的内容,遇到html的src、href等资源就会再次进行网络请求。
部分htm代码:
<!-- 访问的本地的服务器 -->
<img src="http://192.168.6.60:8081/src/18.jpg">
<!-- /src/18.jpg(不是./src/18.jpg)==> 请求当前网页的网址中 http://ip:port/src/18.jpg -->
<img src="/src/18.jpg">
<a href="/123">xxxx</a>
<!-- 访问的百度的服务器 -->
<a href="http://baidu.com">d</a>
js代码:
var http=require("http")
var fs=require("fs")
var app=http.createServer((req,res)=>{
console.log(req.url)
//前端的每一次网络请求 这个函数都会重新运行一次
| if(req.url=="/test/home"){ | http://ip:端口/test/home 用户输入这个网值,就把index文间内容返回给用户 |
fs.readFile("./index.html",(err,data)=>{
//MIME
res.setHeader("content-Type","text/html;charset=utf8")
res.end(data)
})
}
| else if(req.url=="/123"){ | 解析index文件时,遇到<a href="/123">xxxx</a>的href属性,就再次网络请求 http://ip:端口/123 |
//MIME
res.setHeader("content-Type","text/html;charset=utf8")
res.end("123")
}
else if(req.url=="/src/18.jpg"){
console.log("访问图片")
//MIME
fs.readFile("./src/18.jpg",(err,data)=>{
res.setHeader("content-Type","image/png")
res.end(data)
})
}
app.listen(8081)
(2)写入文件信息
fs.writeFile(path ,data,callback(err))
1.有文件,就覆盖原文件内容
2.没有文件,就创建一个文件(文件夹得存在,不会创建文件夹)
(3)删除文件
fs.unlink(path,callback(err))
1.没有删除磁盘的内容
(4)拼接内容到文件
fs.appendFile(__dirname + '/test.txt', '我会追加到文件内容的末尾', function (er) {
console.log('追加内容完成');
})
1.没有文件,就创建一个文件(文件夹得存在,不会创建文件夹)
(5)创建文件夹
fs.mkdir(__dirname + '/test',callback(err))
(6)移动/重命名文件或目录:整个功能相当于重命名一个文件/文件夹路径
fs.rename(oldPath, newPath, callback);
oldPath, 原目录/文件的完整路径及名;
newPath, 新目录/文件的完整路径及名;
- (如果新路径与原路径相同,而只文件名或文件夹名不同,则是重命名)
- 最后一个/的后面的文件或文件夹是同名则是移动
callback(err), 操作完成回调函数;err操作失败对象
注意:移动文件有一个bug:新路径和旧路径必须是同一个根盘(就是跨盘,比如C盘移动到d盘)
(7)拷贝文件
fs.copy(oldPath, newPath, callback);
oldPath, 原文件的完整路径;
newPath, 新文件的完整路径;
callback(err), 操作完成回调函数;err操作失败对象
var oldpath=__dirname+"/src/18.jpg"
var newpath=__dirname+"/src/a/18.jpg" //完整路径
fs.copyFile(oldpath,newpath,(err)=>{
if(!err) {fs.unlink(oldpath,()=>{}) } //拷贝成功删除原文件
})
注意:拷贝文件以后两个文件都会存在磁盘中
(8)读取目录
fs.readdir(__dirname+"/src",(err,arr)=>{
console.log(err,arr)
})
三:url
(1)网址的组成
网址的组成:
协议(http)
域名(www.hqyj.com)
pathname (/20220728/news/page1/index.html?)
querystring(count=20&maxid=123456#top1)
hash(#top1) //不会发送给后端
域名解析(DNS解析): 会把域名解析为一个ip port
(2)url模块
1.引入url模块
var url=require("url")
2.将url解析为对象
url.parse():
var str="http://www.hqyj.com/20220728/news/page1/index.html?count=20&maxid=123456"
var obj=url.parse(str)
console.log(obj)
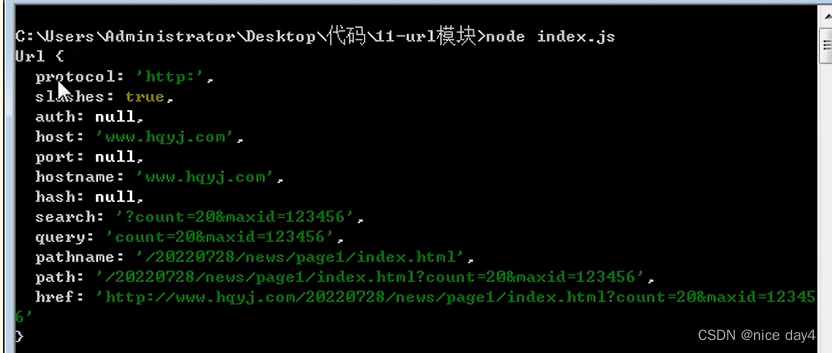
常用:obj.pathname \ obj.query
获取的前端url,但需求是截取pathname
console.log(req.url)//"/20220728/news/page1/index.html?count=20&maxid=123456"
四:querystring模块
1.引入
var querystring=require("querystring")
2.将querystring解析为对象
var obj=querystring.parse("username=jack&count=20&maxid=123456")

3.将对象解析为querystring
var str2=querystring.stringify({name:"jack",age:20})
var str3=JSON.stringify({name:"jack",age:20})
console.log(str2,str3)

五:minme模块
1.引入
var mime=require("mime")
2.使用
var re=mime.getExtension("text/css")
console.log(re) //返回css
var re2=mime.getType("htpp://2342354345:8080/css/sadfsdgfdfg.ttf")
console.log(re2) //返回 text/css
应用:
let type1=mime.getType(path)
res.setHeader("content-Type",type1)















 2121
2121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}